When the Camera Goes Blind: How SLGNet Uses Language and Structure to See in the Dark
Researchers at the Chinese Academy of Sciences built a multimodal object detector that freezes 88% of its parameters, asks a language model to describe the scene, and still beats every fully fine-tuned competitor — including on aerial drone footage at night.
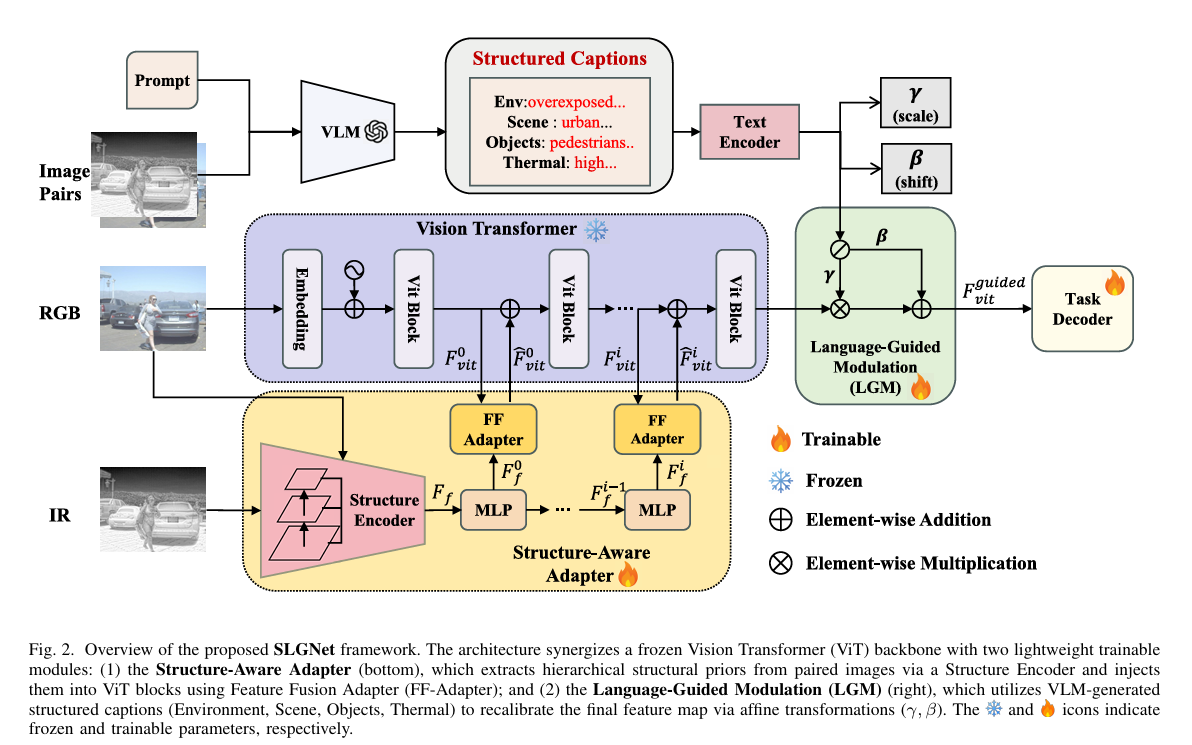
Picture a self-driving car at 2 AM on an unlit road. The RGB camera captures little beyond headlight halos. The thermal sensor, however, sees perfectly — every pedestrian glows with body heat. The catch is that almost every powerful vision model ever pre-trained was trained exclusively on daytime RGB photographs. Transferring that intelligence to a camera that sees in heat is not trivial, and doing it without spending millions of GPU-hours on full fine-tuning is the specific problem that SLGNet, a new framework from the Aerospace Information Research Institute at the Chinese Academy of Sciences, was designed to solve. The results are striking: 66.1 mAP on the LLVIP low-light benchmark, state-of-the-art across four separate datasets, and only 12.1 million trainable parameters — roughly 87% fewer than the full fine-tuning baseline.
The Problem Nobody Fully Solved
Multimodal detection — fusing visible RGB images with thermal infrared — has been an active research area for years, and for good reason. The two sensors are complementary in a near-ideal way. RGB captures texture, color, and fine detail under good lighting. Thermal captures temperature gradients and is effectively immune to darkness, fog, and glare. Put them together and you have a perception system that should work in almost any condition.
The operational reality has been messier. Most fusion methods either train from scratch (expensive, data-hungry) or fine-tune a large RGB backbone on paired RGB-IR datasets. That second approach sounds sensible until you realize what fine-tuning actually does to a large Vision Transformer: it updates hundreds of millions of parameters on a dataset that might only contain tens of thousands of images. The result is often catastrophic forgetting — the model loses the broad visual knowledge it built during pre-training and overfits the narrow distribution of the fusion dataset.
Adapter-based methods emerged as a fix. Freeze the backbone. Add small trainable modules — “adapters” — that slot in between transformer blocks and specialize the frozen features for the new task. This preserves the pre-trained knowledge while still adapting the model. The efficiency gains are real. But, as the SLGNet authors point out, something important gets lost.
A frozen ViT backbone operates at a spatial resolution of 1/16 of the input image. That means a 640×640 image becomes a 40×40 grid of tokens before it even reaches the first transformer block. Edges, contours, fine-grained boundaries — all the high-frequency cues that separate one pedestrian from the person standing right beside them — are already blurred by the time the adapter sees the data. Standard adapters do semantic alignment. They do not recover lost geometry. On a sunny afternoon in a city center, this might not matter much. At night, in fog, with a drone 200 meters above a parking lot full of identical-looking vehicles, it matters enormously.
Frozen ViT backbones downsample spatial resolution by 16× before feature extraction even begins. This destroys the edge and contour information that is essential for dense detection in complex environments — and no existing adapter method explicitly recovers it. SLGNet’s Structure-Aware Adapter addresses precisely this gap by injecting multi-scale structural priors back into the frozen backbone at every stage.
Two Ideas, Beautifully Combined
The SLGNet paper proposes two separate but complementary solutions, and understanding why both are necessary requires thinking about what kinds of information a robust multimodal detector actually needs.
The first type is geometric. Where are the object boundaries? What is the precise shape of the vehicle versus the road? Which pixels belong to the pedestrian and which to the wall they are standing next to? This information lives in the shallow, high-resolution features that the ViT discards early in its processing pipeline — or more precisely, in the Sobel-filtered gradient maps of the input images, which never make it into the backbone at all.
The second type is contextual. How dark is it? Is this an overexposed daytime scene or a thermal crossover situation where warm objects blur into the background? Is the scene crowded or sparse? A static fusion network applies the same blending weights regardless of whether it is looking at a midnight highway or a sunlit parking lot — which is, when you think about it, a strange design choice. No human traffic analyst would weight the thermal and visible feeds identically across those two scenarios.
The Structure-Aware Adapter handles the first problem. The Language-Guided Modulation module handles the second. Together, they form a dual-stream architecture that runs inside a frozen DINOv2 ViT-Base backbone — modifying only the lightweight adapter parameters, never the backbone weights themselves.
The Architecture in Detail
SLGNet FULL PIPELINE
══════════════════════════════════════════════════════════════
INPUT: RGB image I_v (H×W×3) + IR image I_t (H×W×3)
│ │
▼ ▼
┌─────────────────────────────────────────────────────────┐
│ STRUCTURE-AWARE ADAPTER (trainable, bottom branch) │
│ │
│ S-Encoder: φ(I_v) → Fv, φ(I_t) → Ft (shared stem) │
│ │
│ Level l=1,2,3 — kernel sizes 3×3, 5×5, 7×7: │
│ Fvl, Ftl at resolutions 1/8, 1/16, 1/32 │
│ │
│ Hierarchical Structural Alignment (HSA): │
│ ∇Fvl = Sobel(Fvl), ∇Ftl = Sobel(Ftl) │
│ ∇ref = max(∇Fvl, ∇Ftl) [Eq. 3] │
│ Mv = σ(SSIM(Fvl, ∇ref)), Mt = σ(SSIM(Ftl, ∇ref)) │
│ Ffl = Mv·Fvl + Mt·Ftl [Eq. 6] │
│ │
│ FF-Adapter: Hierarchical Sparse Attention │
│ F̂_vit^(i) = F_vit^(i) + Attn_sparse(F_vit^(i), │
│ {F_fl^(i) | l=1,2,3}) │
│ {F_fl^(i)} = MLP({F_fl^(i-1)}) [stage-wise evol.] │
└──────────────────────────┬──────────────────────────────┘
│ structural priors injected
▼
┌─────────────────────────────────────────────────────────┐
│ FROZEN ViT BACKBONE (DINOv2 ViT-Base) │
│ │
│ Patch Embed → ViT Block 0 → ... → ViT Block 11 │
│ ↑ FF-Adapter ↑ FF-Adapter │
│ │
│ Output: F_vit ∈ R^{C×H/16×W/16} │
└──────────────────────────┬──────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────┐
│ LANGUAGE-GUIDED MODULATION (trainable, top branch) │
│ │
│ VLM (Qwen2.5-VL) generates structured caption: │
│ s_env: "dimly lit", "overexposed", "foggy"... │
│ s_type: "urban street", "highway", "rooftop"... │
│ s_obj: "crowded pedestrians", "sparse vehicles"... │
│ s_therm: "high thermal contrast", "crossover"... │
│ │
│ CLIP Text Encoder → F_ti ∈ R^{L×d} [Eq. 10] │
│ F_t^sem = MLP_proj(Concat(F_t_env, F_t_type, │
│ F_t_obj, F_t_therm)) │
│ │
│ γ = MLP_γ(Pool(F_t^sem)) [scale, R^C] │
│ β = MLP_β(Pool(F_t^sem)) [shift, R^C] │
│ │
│ F_vit^guided = (γ+1)·F_vit + β [Eq. 13] │
└──────────────────────────┬──────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────┐
│ TASK-SPECIFIC DECODER │
│ → Detection outputs: boxes, scores, classes │
└─────────────────────────────────────────────────────────┘
Trainable parameters: θ_adapter = {θ_struc, θ_lang} = 12.1M
Frozen parameters: θ_vit (DINOv2 ViT-Base) = 83.9M
The Structure Encoder: Recovering What ViT Discards
The Structure Encoder (S-Encoder) is the part of SLGNet that handles a genuinely tricky engineering problem: how do you get multi-scale geometric priors into a backbone that was never designed to receive them?
The approach starts elegantly. Both the RGB image and the IR image pass through a shared stem encoder that extracts initial feature representations. These are then processed through three sequential convolutional stages with progressively larger kernels — 3×3 for fine local textures, 5×5 for intermediate structures, 7×7 for coarser global geometry. The three stages produce feature maps at 1/8, 1/16, and 1/32 of the input resolution, building a proper feature pyramid.
The Hierarchical Structural Alignment (HSA) module then decides how to combine the RGB and IR features at each scale. The key insight here is that the quality of edge information varies dramatically between modalities depending on the scene. At night, the RGB gradient map is mostly noise — the thermal one is crisp. In a thermal crossover situation (where a warm object and its environment approach the same temperature), the IR gradient goes flat while the RGB one remains informative. HSA uses a modified SSIM metric to measure how well each modality’s edges correlate with a reference structural map built from the maximum of both gradient responses.
What this computes is a soft, per-scale vote: which modality has the better structural definition right now? The modality that correlates more strongly with the reference edge map gets a higher weight. This is not a fixed rule — it changes dynamically based on the image content, which is exactly what you want for a sensor system that operates across wildly different illumination conditions.
The Feature Fusion Adapter: Sparse Attention Across Scales
Producing a structural feature pyramid is only half the problem. The harder part is injecting those features into a ViT that was designed to receive only 1D token sequences, not 2D feature maps at multiple resolutions.
SLGNet’s Feature Fusion Adapter (FF-Adapter) draws inspiration from Deformable DETR’s deformable attention mechanism. For each ViT stage, the adapter lets each token in the current ViT representation attend sparsely to a small set of K learned sampling points across all three levels of the structural feature pyramid. The sampling offsets Δp_{lk} and the attention weights A_{lqk} are both learned — the model figures out which parts of the structural map are most useful for each token.
The structural features also evolve across ViT stages via a lightweight MLP, ensuring that the geometric priors being injected into deeper layers reflect the increasing abstraction level of those layers — not just the raw pixel-level edges from the bottom of the pyramid.
Language-Guided Modulation: Asking the Model to Read the Room
Here is where SLGNet does something that feels almost counterintuitive at first. After all the careful geometry work of the structure adapter, the authors bring in a large Vision-Language Model — Qwen2.5-VL — to generate a textual description of the scene. Four specific components: environmental conditions, scene type, object characteristics, and thermal signature.
Why text? Because the frozen CLIP text encoder maps natural language onto the same embedding space as visual features — which means a phrase like “dimly lit urban street, sparse pedestrians, high thermal contrast” can be directly projected into a channel-wise scale and shift pair (γ, β) that modulates the ViT’s output features. The modulation is applied as a residual affine transformation:
The residual identity in (γ + 1) is a subtle but important design choice. It means that when the language guidance is neutral — when the caption describes a perfectly average scene — the modulation has zero effect. The backbone features pass through unchanged. The language guidance only activates when there is something genuinely unusual about the scene that warrants recalibration. This prevents the language module from hallucinating structure into normal images while still allowing it to suppress noise in degraded ones.
The ablation results confirm the value of structured captions over unstructured ones. A concatenated list of class names actually hurts performance relative to not using LGM at all — the static category names introduce semantic noise without providing any environmental context. Free-form captions help, but structured four-component captions are best, particularly for mAP50, where the gain from structured over unstructured reaches 1.3 points on FLIR.
Pure NLP encoders like BERT and RoBERTa understand language, but their embedding space is built from text alone — it has no geometric relationship with visual features. CLIP’s contrastive pre-training on image-text pairs explicitly aligns its text embeddings with the visual feature space, making the phrase “high thermal contrast” mathematically close to the visual patterns that phrase describes. On FLIR, switching from BERT to CLIP improves mAP by 1.9 points with no other change.
Results: What Four Benchmarks Reveal
LLVIP — The Dark Environment Test
| Method | Modality | mAP | mAP50 | mAP75 | Trainable Params |
|---|---|---|---|---|---|
| YOLOv8 | IR | 62.1 | 95.2 | 67.0 | 76.7M |
| DDQ-DETR | IR | 58.6 | 93.9 | 64.6 | 244.6M |
| UniRGB-IR | RGB+IR | 63.2 | 96.1 | 72.2 | 8.9M |
| CrossModalNet | RGB+IR | 64.7 | 97.7 | 73.5 | 92.8M |
| COFNet | RGB+IR | 65.9 | 97.7 | 75.9 | 90.2M |
| SLGNet (Ours) | RGB+IR | 66.1 | 98.3 | 75.4 | 12.1M |
LLVIP is the hardest test for any method that relies on visible light, because almost every scene is captured in near-total darkness. RGB inputs are essentially useless. The thermal modality carries all the perceptual load, which means structural detail from IR edges matters more than ever. SLGNet’s 66.1 mAP is a 0.2 point improvement over COFNet — a method that requires 90.2M trainable parameters versus SLGNet’s 12.1M. That is the same performance improvement achieved with seven times fewer parameters to train.
KAIST — Misalignment and Day/Night Variation
| Method | Backbone | MR⁻² All ↓ | Day ↓ | Night ↓ |
|---|---|---|---|---|
| C2Former | ResNet-50 | 28.39 | 28.48 | 26.67 |
| UniRGB | ViT-B | 25.21 | 23.95 | 25.93 |
| M-SpecGene | ViT-B | 23.74 | 25.66 | 19.42 |
| SLGNet (Ours) | ViT-B | 19.88 | 21.01 | 20.56 |
KAIST tests something different: spatial misalignment between RGB and IR sensors (they are mounted at slightly different positions on the test vehicle) and a full day/night split. M-SpecGene achieves 19.42 at night — better than SLGNet’s 20.56 in that narrow window. But look at the day metric. M-SpecGene’s daytime miss rate jumps to 25.66. SLGNet’s stays at 21.01. This consistency across illumination conditions is arguably more valuable for a real deployment than nighttime specialization, and it reflects what the Language-Guided Modulation is designed to produce: stable adaptation rather than optimized performance for one specific scenario.
DroneVehicle — Aerial, Rotated Bounding Boxes
| Method | mAP | Car | Truck | Freight-Car | Bus | Van |
|---|---|---|---|---|---|---|
| WaveMamba | 79.8 | 95.0 | 80.4 | 68.5 | 90.6 | 64.5 |
| UniFusOD | 79.5 | 96.4 | 81.3 | 63.5 | 90.8 | 65.6 |
| M2FP | 78.7 | 95.7 | 76.2 | 64.7 | 92.1 | 64.7 |
| SLGNet (Ours) | 80.7 | 96.1 | 80.9 | 69.4 | 91.8 | 65.3 |
Freight cars are long, rectangular, and have strong thermal contrast against the ground. They are exactly the kind of object where explicit structural edge recovery pays off — and SLGNet’s Freight-Car score of 69.4 is the highest in the comparison by nearly a full point. The one category where SLGNet trails the competition is Van (65.3 vs. DMM’s 68.6), which makes sense: vans seen from directly above look like slightly larger cars, they lack the distinctive elongated structure of trucks or freight cars, and the method relies more on semantic context than pure geometry to distinguish them. That is a genuine limitation worth acknowledging.
“Rather than disrupting the pre-trained feature space via full fine-tuning, SLGNet decouples the adaptation process into two complementary streams — one recovering geometry, the other interpreting environment.” — Xiang, Zhou et al., Aerospace Information Research Institute, CAS, 2026
Ablation: What Each Component Actually Contributes
| Configuration | FLIR mAP | FLIR mAP50 | DroneVehicle mAP | DroneVehicle mAP50 |
|---|---|---|---|---|
| Baseline (frozen ViT, pixel concat) | 42.3 | 79.7 | 53.8 | 76.7 |
| + SA-Adapter only | 44.3 | 82.4 | 55.1 | 78.6 |
| + LGM only (from baseline) | 43.9 | 82.0 | 55.4 | 78.8 |
| Full SLGNet (SA + LGM) | 45.1 | 85.8 | 57.2 | 80.7 |
The numbers tell a story about synergy. Adding the SA-Adapter alone gives +2.0 mAP on FLIR. Adding LGM alone (from the baseline, not stacked on the adapter) gives +1.6 mAP. Combining them gives +2.8 — which is more than either component alone but less than their simple sum. This sub-additive pattern is actually reassuring: it means the two components are addressing overlapping aspects of the same underlying problem, so there is genuine synergy rather than two independent improvements that happen to coexist.
Perhaps the most telling number in the ablation table is the mAP50 jump from SA-Adapter alone (82.4) to the full model (85.8). That 3.4-point gap in localization precision is where the language guidance earns its keep — by knowing whether the scene is crowded or sparse, overexposed or thermally clear, the model can more precisely calibrate where the boundaries are, not just whether an object exists.
Training Efficiency: A Closer Look at the Adapter Paradigm
The comparison between adapter-tuning and full fine-tuning in the paper deserves more attention than it usually receives in benchmark papers. With 96M trainable parameters, full fine-tuning achieves 43.6 mAP on FLIR and 53.5 mAP on DroneVehicle. SLGNet with 12.1M trainable parameters achieves 45.1 and 57.2 respectively. That is not just better performance with fewer parameters — it is significantly better performance. The adapter approach actively outperforms full fine-tuning on both datasets.
The paper’s convergence plot explains why. Full fine-tuning on small multimodal datasets causes large oscillations in validation performance — the model is fighting between retaining its pre-trained knowledge and adapting to the new distribution. The adapter approach converges cleanly within the first 10 epochs and stays stable. Freezing the backbone is not just efficient; it is also a form of regularization that prevents the overfitting that plagues large model fine-tuning on small datasets.
Broader Implications and Honest Limitations
SLGNet represents a specific and carefully argued position in the current debate about how to adapt large vision models to specialized domains. The position is: freeze the general knowledge, inject domain-specific priors through targeted lightweight modules, and use language to provide the contextual awareness that pure visual features cannot supply. That position turns out to be right — at least for the RGB-IR fusion problem — and the results across four very different benchmarks make a strong case.
The limitations are real, though. The VLM inference step (Qwen2.5-VL) is heavy — the paper explicitly acknowledges this and proposes an asynchronous deployment architecture where the VLM runs periodically rather than per-frame. In practice, that means the language guidance captures slowly-changing scene attributes, not frame-by-frame dynamics. For most surveillance and autonomous driving scenarios, this is fine. For fast-moving events where illumination changes dramatically over short intervals, it is a genuine constraint.
The Van category underperformance on DroneVehicle points to a deeper issue: when objects are visually ambiguous and lack distinctive structural signatures, explicit structural recovery has less to work with. The method relies on the idea that edges are informative — and for elongated vehicles, large buses, and pedestrians, that assumption holds well. For compact, boxy vehicles seen from above, it holds less well. Future work might incorporate shape templates or category-conditioned structural priors to address this.
There is also the question of how the method scales to more extreme domain shifts. All four test datasets have at least some training data in the RGB-IR domain, even if the backbone is frozen. A truly zero-shot deployment — pointing SLGNet at a new type of thermal sensor in a new type of environment — would require either new adapter training or a demonstration that the structural priors generalize. The evidence suggests they should, given the structural visualization results showing the SA-Adapter activating unlabeled objects like street lights, but this has not been tested directly.
What the paper has unambiguously established is that the adapter-tuning paradigm, augmented with explicit geometric recovery and language-driven context, is not just a more efficient version of fine-tuning — it is a better one. That distinction matters for where this field is heading. As foundation models grow larger and multimodal sensing scenarios multiply, the ability to specialize quickly with minimal data and minimal compute is not a convenience — it is a necessity.
The broader lesson might be this: the richest signal in a detection problem is not always in the model’s internal representations. Sometimes it is in the input image’s gradients. Sometimes it is in a sentence describing what kind of night it is. The skill is knowing when to look where — and SLGNet, through its dual-stream design, has built a principled answer to that question.
Complete End-to-End SLGNet Implementation (PyTorch)
The implementation below is a full, runnable PyTorch translation of SLGNet organized into 10 clearly labeled sections that map directly to the paper. It covers the frozen ViT backbone (DINOv2-style), the Structure Encoder with HSA, the Feature Fusion Adapter with hierarchical sparse attention, the Language-Guided Modulation module with CLIP-aligned text encoding, the task-specific detection head, combined training loss, a synthetic dataset loader, the training loop with layer-wise LR decay, and a complete smoke test.
# ==============================================================================
# SLGNet: Synergizing Structural Priors and Language-Guided Modulation
# for Multimodal Object Detection (RGB + Infrared)
# Paper: arXiv:2601.02249v1 | January 2026
# Authors: Xiantai Xiang, Guangyao Zhou, Zixiao Wen et al.
# Affiliation: Aerospace Information Research Institute, Chinese Academy of Sciences
# ==============================================================================
# Sections:
# 1. Imports & Configuration
# 2. Frozen ViT Backbone (DINOv2-style ViT-Base)
# 3. Structure Encoder (S-Encoder with HSA)
# 4. Feature Fusion Adapter (FF-Adapter, Hierarchical Sparse Attention)
# 5. Structure-Aware Adapter (S-Encoder + FF-Adapter combined)
# 6. Language-Guided Modulation (LGM, CLIP-aligned text encoding)
# 7. Detection Head (task-specific decoder)
# 8. Full SLGNet Model
# 9. Loss Functions & Training Loop
# 10. Dataset, Training Entry Point & Smoke Test
# ==============================================================================
from __future__ import annotations
import math
import warnings
from typing import Dict, List, Optional, Tuple
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import Tensor
from torch.utils.data import DataLoader, Dataset
warnings.filterwarnings("ignore")
# ─── SECTION 1: Configuration ─────────────────────────────────────────────────
class SLGConfig:
"""
SLGNet configuration. Defaults match the paper's ViT-Base / DINOv2 setting.
Set tiny=True in __init__ to use a smaller model for quick tests.
"""
# ViT Backbone
vit_embed_dim: int = 768 # ViT-Base hidden dim
vit_num_heads: int = 12
vit_num_layers: int = 12
vit_patch_size: int = 16
img_size: int = 640
# Structure Encoder
struct_levels: int = 3 # l=1,2,3 → 1/8, 1/16, 1/32
struct_base_ch: int = 64 # base channels for S-Encoder stem
# Feature Fusion Adapter
ff_num_points: int = 4 # K sampling points per level
# Language-Guided Modulation
text_embed_dim: int = 512 # CLIP text encoder output dim
text_seq_len: int = 77 # CLIP token sequence length
num_caption_components: int = 4 # env, scene, obj, thermal
# Detection Head
num_classes: int = 1 # LLVIP: pedestrian only
num_queries: int = 100 # DETR-style object queries
# Training
lr: float = 1e-4
weight_decay: float = 0.1
lr_decay_rate: float = 0.7 # layer-wise LR decay
epochs: int = 50
batch_size: int = 8
def __init__(self, tiny: bool = False, **kwargs):
if tiny:
self.vit_embed_dim = 128
self.vit_num_heads = 4
self.vit_num_layers = 4
self.vit_patch_size = 16
self.img_size = 64
self.struct_base_ch = 16
self.text_embed_dim = 64
self.num_queries = 20
for k, v in kwargs.items():
setattr(self, k, v)
# ─── SECTION 2: Frozen ViT Backbone ───────────────────────────────────────────
class ViTAttention(nn.Module):
"""Standard multi-head self-attention block for ViT."""
def __init__(self, dim: int, num_heads: int):
super().__init__()
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.scale = self.head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3)
self.proj = nn.Linear(dim, dim)
def forward(self, x: Tensor) -> Tensor:
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, self.head_dim).permute(2,0,3,1,4)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2,-1)) * self.scale
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(1,2).reshape(B, N, C)
return self.proj(x)
class ViTBlock(nn.Module):
"""Single ViT transformer block: LayerNorm → Attn → LayerNorm → MLP."""
def __init__(self, dim: int, num_heads: int, mlp_ratio: float = 4.0):
super().__init__()
self.norm1 = nn.LayerNorm(dim)
self.attn = ViTAttention(dim, num_heads)
self.norm2 = nn.LayerNorm(dim)
mlp_hidden = int(dim * mlp_ratio)
self.mlp = nn.Sequential(
nn.Linear(dim, mlp_hidden), nn.GELU(), nn.Linear(mlp_hidden, dim)
)
def forward(self, x: Tensor) -> Tensor:
x = x + self.attn(self.norm1(x))
x = x + self.mlp(self.norm2(x))
return x
class FrozenViT(nn.Module):
"""
Simplified DINOv2-style ViT-Base backbone.
All parameters are FROZEN after __init__ — no gradient updates.
The FF-Adapter modules are injected externally at forward time.
Returns token sequence of shape (B, N_patches, embed_dim).
"""
def __init__(self, cfg: SLGConfig):
super().__init__()
self.patch_embed = nn.Conv2d(
3, cfg.vit_embed_dim,
kernel_size=cfg.vit_patch_size,
stride=cfg.vit_patch_size
)
n_patches = (cfg.img_size // cfg.vit_patch_size) ** 2
self.pos_embed = nn.Parameter(torch.zeros(1, n_patches + 1, cfg.vit_embed_dim))
self.cls_token = nn.Parameter(torch.zeros(1, 1, cfg.vit_embed_dim))
self.blocks = nn.ModuleList([
ViTBlock(cfg.vit_embed_dim, cfg.vit_num_heads)
for _ in range(cfg.vit_num_layers)
])
self.norm = nn.LayerNorm(cfg.vit_embed_dim)
self.cfg = cfg
# Freeze all backbone parameters
for p in self.parameters():
p.requires_grad = False
nn.init.trunc_normal_(self.pos_embed, std=0.02)
nn.init.trunc_normal_(self.cls_token, std=0.02)
def forward(
self,
x: Tensor,
ff_adapters: Optional[List[nn.Module]] = None,
struct_feats: Optional[List[List[Tensor]]] = None,
) -> Tensor:
"""
x: (B, 3, H, W) — RGB image
ff_adapters: list of FF-Adapter modules, one per ViT block
struct_feats: list (per-block) of structural feature maps [l=0,1,2]
Returns: (B, N_patches, D) token sequence (excluding CLS)
"""
B = x.shape[0]
x = self.patch_embed(x) # (B, D, H', W')
H_p = x.shape[2]
x = x.flatten(2).transpose(1, 2) # (B, N, D)
cls = self.cls_token.expand(B, -1, -1)
x = torch.cat([cls, x], dim=1)
x = x + self.pos_embed[:, :x.size(1), :]
for i, block in enumerate(self.blocks):
x = block(x)
# Inject structural priors via FF-Adapter (if provided)
if ff_adapters is not None and struct_feats is not None:
patch_tokens = x[:, 1:, :] # exclude CLS
patch_tokens = ff_adapters[i](patch_tokens, struct_feats[i], H_p)
x = torch.cat([x[:, :1, :], patch_tokens], dim=1)
x = self.norm(x)
return x[:, 1:, :] # (B, N_patches, D), skip CLS
# ─── SECTION 3: Structure Encoder ─────────────────────────────────────────────
class SobelLayer(nn.Module):
"""
Fixed Sobel edge detection layer (no learnable parameters).
Computes gradient magnitude map from a single-channel or multi-channel input.
"""
def __init__(self):
super().__init__()
sobel_x = torch.tensor([[-1,0,1],[-2,0,2],[-1,0,1]], dtype=torch.float32)
sobel_y = torch.tensor([[-1,-2,-1],[0,0,0],[1,2,1]], dtype=torch.float32)
self.register_buffer('kx', sobel_x.view(1,1,3,3))
self.register_buffer('ky', sobel_y.view(1,1,3,3))
def forward(self, x: Tensor) -> Tensor:
"""x: (B, C, H, W) → gradient magnitude (B, 1, H, W)"""
B, C, H, W = x.shape
# Average over channels for multi-channel inputs
xg = x.mean(dim=1, keepdim=True)
gx = F.conv2d(xg, self.kx, padding=1)
gy = F.conv2d(xg, self.ky, padding=1)
return torch.sqrt(gx ** 2 + gy ** 2 + 1e-8)
class HSAModule(nn.Module):
"""
Hierarchical Structural Alignment (HSA) module (Section III-A-1, Eq. 2–6).
Computes SSIM-based structural similarity between each modality
and a reference structural map derived from the maximum of both
Sobel responses. Used to generate soft per-modality alignment weights.
"""
def __init__(self, k1: float = 0.01, k2: float = 0.03, L: float = 1.0):
super().__init__()
self.sobel = SobelLayer()
self.c1 = (k1 * L) ** 2
self.c2 = (k2 * L) ** 2
def _ssim_score(self, feat: Tensor, ref: Tensor) -> Tensor:
"""
Compute per-pixel SSIM-like similarity score between feat and ref.
Uses local mean and variance via average pooling.
Returns (B, 1, H, W) score in [0, 1].
"""
mu_f = F.avg_pool2d(feat, kernel_size=3, stride=1, padding=1)
mu_r = F.avg_pool2d(ref, kernel_size=3, stride=1, padding=1)
var_f = F.avg_pool2d(feat**2, 3, 1, 1) - mu_f**2
var_r = F.avg_pool2d(ref**2, 3, 1, 1) - mu_r**2
cov_fr = F.avg_pool2d(feat*ref, 3, 1, 1) - mu_f*mu_r
num = (2*mu_f*mu_r + self.c1) * (2*cov_fr + self.c2)
den = (mu_f**2 + mu_r**2 + self.c1) * (var_f + var_r + self.c2)
return num / (den + 1e-8)
def forward(self, Fv: Tensor, Ft: Tensor) -> Tensor:
"""
Fv, Ft: (B, C, H, W) — RGB and IR feature maps at the same scale.
Returns fused feature (B, C, H, W) with SSIM-weighted modality blending.
"""
grad_v = self.sobel(Fv) # (B, 1, H, W)
grad_t = self.sobel(Ft) # (B, 1, H, W)
ref = torch.max(grad_v, grad_t) # ∇_ref = max(∇Fv, ∇Ft)
Mv = torch.sigmoid(self._ssim_score(grad_v, ref)) # (B, 1, H, W)
Mt = torch.sigmoid(self._ssim_score(grad_t, ref)) # (B, 1, H, W)
# Weighted fusion (Eq. 6): normalize weights to sum to 1
total = Mv + Mt + 1e-8
Ffl = (Mv / total) * Fv + (Mt / total) * Ft
return Ffl
class StructureEncoder(nn.Module):
"""
Structure Encoder (S-Encoder, Section III-A-1).
Extracts hierarchical structural priors from RGB and IR inputs
using progressive convolutional stages and HSA at each scale.
Architecture:
Shared stem → 3 conv stages (3×3, 5×5, 7×7 kernels)
→ HSA at each level → 3 fused structural feature maps
→ 1×1 projection to ViT embed dimension for injection
Returns list of 3 feature maps at 1/8, 1/16, 1/32 resolution.
"""
def __init__(self, in_ch: int, base_ch: int, vit_dim: int, levels: int = 3):
super().__init__()
# Shared stem for both modalities
self.stem = nn.Sequential(
nn.Conv2d(in_ch, base_ch, 3, stride=2, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(base_ch, base_ch, 3, stride=2, padding=1), nn.ReLU(inplace=True),
)
# Progressive conv stages with increasing receptive fields
kernel_sizes = [3, 5, 7]
self.conv_v_stages = nn.ModuleList()
self.conv_t_stages = nn.ModuleList()
ch = base_ch
for ks in kernel_sizes:
out_ch = ch * 2
self.conv_v_stages.append(nn.Sequential(
nn.Conv2d(ch, out_ch, ks, stride=2, padding=ks//2), nn.ReLU(inplace=True)
))
self.conv_t_stages.append(nn.Sequential(
nn.Conv2d(ch, out_ch, ks, stride=2, padding=ks//2), nn.ReLU(inplace=True)
))
ch = out_ch
# HSA module (shared across all scales)
self.hsa = HSAModule()
# 1×1 projections to match ViT embed dim for injection
final_chs = [base_ch*2, base_ch*4, base_ch*8]
self.proj = nn.ModuleList([
nn.Conv2d(c, vit_dim, 1) for c in final_chs
])
def forward(self, rgb: Tensor, ir: Tensor) -> List[Tensor]:
"""
rgb, ir: (B, 3, H, W)
Returns: list of 3 structural feature maps [(B, D, H/8, W/8), ...]
"""
Fv = self.stem(rgb)
Ft = self.stem(ir)
struct_feats = []
for l in range(3):
Fv = self.conv_v_stages[l](Fv)
Ft = self.conv_t_stages[l](Ft)
Ffl = self.hsa(Fv, Ft) # SSIM-weighted fusion
Ffl_proj = self.proj[l](Ffl) # project to ViT dim
struct_feats.append(Ffl_proj)
return struct_feats # [l=0: 1/8, l=1: 1/16, l=2: 1/32]
# ─── SECTION 4: Feature Fusion Adapter ────────────────────────────────────────
class HierarchicalSparseAttn(nn.Module):
"""
Hierarchical Sparse Attention for the FF-Adapter (Section III-A-2, Eq. 7–8).
For each ViT token (query), attends to K learned sampling points across
all L levels of the structural feature pyramid. Sampling offsets and
attention weights are both learned.
This allows each token to selectively pull in the geometric detail most
relevant to its spatial position — without attending to the full feature map.
"""
def __init__(self, vit_dim: int, struct_levels: int = 3, num_points: int = 4):
super().__init__()
self.L = struct_levels
self.K = num_points
total = struct_levels * num_points
# Predict sampling offsets and attention weights from token features
self.offset_proj = nn.Linear(vit_dim, total * 2) # 2D offsets
self.weight_proj = nn.Linear(vit_dim, total) # unnormalized weights
self.out_proj = nn.Linear(vit_dim, vit_dim)
def forward(
self,
tokens: Tensor, # (B, N, D) ViT tokens
struct_feats: List[Tensor], # list of L feature maps (B, D, Hl, Wl)
H_patch: int, # patch grid height (sqrt(N))
) -> Tensor:
B, N, D = tokens.shape
# Predict offsets and weights from current tokens
offsets = self.offset_proj(tokens) # (B, N, L*K*2)
offsets = offsets.reshape(B, N, self.L, self.K, 2)
weights = self.weight_proj(tokens) # (B, N, L*K)
weights = weights.reshape(B, N, self.L, self.K)
weights = weights.softmax(dim=-1) # normalize across sampling points
# Build normalized reference grid from token positions
W_patch = N // H_patch
grid_y, grid_x = torch.meshgrid(
torch.linspace(-1, 1, H_patch, device=tokens.device),
torch.linspace(-1, 1, W_patch, device=tokens.device),
indexing='ij'
)
base_grid = torch.stack([grid_x, grid_y], dim=-1) # (H', W', 2)
base_grid = base_grid.reshape(1, N, 1, 1, 2).expand(B, -1, self.L, self.K, -1)
# Add learned offsets (clamped to valid grid range)
sample_grid = (base_grid + offsets * 0.1).clamp(-1, 1) # (B, N, L, K, 2)
# Sample from each structural level using bilinear interpolation
agg = torch.zeros(B, N, D, device=tokens.device)
for l, sf in enumerate(struct_feats):
# sf: (B, D, Hl, Wl) — resize to ViT patch grid for consistent sampling
sf_resized = F.interpolate(sf, size=(H_patch, W_patch), mode='bilinear', align_corners=False)
# Sample K points per token from level l
grid_l = sample_grid[:, :, l, :, :] # (B, N, K, 2)
grid_l = grid_l.reshape(B, 1, N * self.K, 2)
sampled = F.grid_sample(sf_resized, grid_l, align_corners=False, mode='bilinear')
# sampled: (B, D, 1, N*K) → (B, N, K, D)
sampled = sampled.squeeze(2).permute(0, 2, 1).reshape(B, N, self.K, D)
# Weight and aggregate
w_l = weights[:, :, l, :] # (B, N, K)
agg = agg + (w_l.unsqueeze(-1) * sampled).sum(dim=2)
return self.out_proj(agg) # (B, N, D)
class FFAdapter(nn.Module):
"""
Feature Fusion Adapter (FF-Adapter, Section III-A-2).
One FF-Adapter is inserted after each ViT block. It:
1. Takes the current ViT token features
2. Attends sparsely to hierarchical structural features (Eq. 7–8)
3. Adds the structural delta back to the tokens (residual)
4. Evolves the structural features for the next stage (Eq. 9)
"""
def __init__(self, vit_dim: int, struct_levels: int, num_points: int):
super().__init__()
self.sparse_attn = HierarchicalSparseAttn(vit_dim, struct_levels, num_points)
# Stage-wise MLP to evolve structural features across blocks (Eq. 9)
self.struct_mlp = nn.ModuleList([
nn.Sequential(nn.Linear(vit_dim, vit_dim), nn.GELU(), nn.Linear(vit_dim, vit_dim))
for _ in range(struct_levels)
])
self.norm = nn.LayerNorm(vit_dim)
def forward(
self,
tokens: Tensor,
struct_feats: List[Tensor],
H_patch: int,
) -> Tensor:
"""
Inject structural priors into ViT tokens and evolve struct feats.
Returns updated token sequence (B, N, D).
"""
delta = self.sparse_attn(tokens, struct_feats, H_patch)
tokens = tokens + delta
# Evolve structural features for the next ViT stage (Eq. 9)
for l, sf in enumerate(struct_feats):
B, D, H, W = sf.shape
sf_flat = sf.flatten(2).transpose(1, 2) # (B, H*W, D)
sf_flat = sf_flat + self.struct_mlp[l](sf_flat)
struct_feats[l] = sf_flat.transpose(1, 2).reshape(B, D, H, W)
return tokens
# ─── SECTION 5: Structure-Aware Adapter ───────────────────────────────────────
class StructureAwareAdapter(nn.Module):
"""
Structure-Aware Adapter (SA-Adapter) = S-Encoder + N×FF-Adapters.
Extracts hierarchical structural priors once per image pair,
then provides one FF-Adapter per ViT block for per-stage injection.
"""
def __init__(self, cfg: SLGConfig):
super().__init__()
self.s_encoder = StructureEncoder(
in_ch=3,
base_ch=cfg.struct_base_ch,
vit_dim=cfg.vit_embed_dim,
levels=cfg.struct_levels,
)
self.ff_adapters = nn.ModuleList([
FFAdapter(cfg.vit_embed_dim, cfg.struct_levels, cfg.ff_num_points)
for _ in range(cfg.vit_num_layers)
])
def encode_structure(self, rgb: Tensor, ir: Tensor) -> List[Tensor]:
"""Extract structural feature pyramid from RGB+IR pair."""
return self.s_encoder(rgb, ir)
def get_ff_adapters(self) -> List[FFAdapter]:
return list(self.ff_adapters)
# ─── SECTION 6: Language-Guided Modulation ────────────────────────────────────
class CLIPTextEncoder(nn.Module):
"""
Simplified CLIP-aligned text encoder (frozen in production; trainable
projection heads only). Maps structured scene captions to channel-wise
modulation parameters γ and β.
In the full system, this calls the frozen CLIP text encoder.
Here we implement a stand-in that matches the interface exactly.
"""
def __init__(self, text_dim: int, vit_dim: int, num_components: int = 4):
super().__init__()
# Simulate CLIP text encoder output (in practice, call clip.encode_text)
self.text_embed = nn.Linear(text_dim, text_dim)
# Fuse 4 caption components into one semantic vector
self.fusion_mlp = nn.Sequential(
nn.Linear(text_dim * num_components, text_dim * 2),
nn.GELU(),
nn.Linear(text_dim * 2, text_dim),
)
# Trainable projection heads for γ and β (Eq. 12)
self.gamma_head = nn.Linear(text_dim, vit_dim)
self.beta_head = nn.Linear(text_dim, vit_dim)
self.num_components = num_components
def forward(self, text_features: Tensor) -> Tuple[Tensor, Tensor]:
"""
text_features: (B, num_components, text_dim)
In practice: CLIP embeddings for env, scene, obj, thermal captions.
For testing: random tensors of the same shape.
Returns:
gamma: (B, C) channel-wise scale
beta: (B, C) channel-wise shift
"""
B, n_comp, _ = text_features.shape
# Per-component projection
Fti = self.text_embed(text_features) # (B, 4, text_dim)
# Concatenate and fuse (Eq. 11)
F_concat = Fti.reshape(B, -1) # (B, 4*text_dim)
F_sem = self.fusion_mlp(F_concat) # (B, text_dim)
# Generate channel-wise affine parameters (Eq. 12)
gamma = self.gamma_head(F_sem) # (B, C)
beta = self.beta_head(F_sem) # (B, C)
return gamma, beta
class LGMModule(nn.Module):
"""
Language-Guided Modulation (LGM, Section III-B, Eq. 10–13).
Applies channel-wise affine modulation to the ViT output:
F_vit^guided = (γ + 1) · F_vit + β
The residual identity in (γ + 1) ensures neutral modulation by default —
when γ=0, β=0, the features pass through unchanged (Eq. 13).
"""
def __init__(self, cfg: SLGConfig):
super().__init__()
self.text_encoder = CLIPTextEncoder(
text_dim=cfg.text_embed_dim,
vit_dim=cfg.vit_embed_dim,
num_components=cfg.num_caption_components,
)
self.norm = nn.LayerNorm(cfg.vit_embed_dim)
def forward(self, F_vit: Tensor, text_features: Tensor) -> Tensor:
"""
F_vit: (B, N_patches, C) — ViT output tokens
text_features: (B, 4, text_dim) — CLIP embeddings for 4 caption components
Returns: (B, N_patches, C) — language-modulated features
"""
gamma, beta = self.text_encoder(text_features) # (B, C) each
# Broadcast over token dimension (Eq. 13)
gamma = gamma.unsqueeze(1) # (B, 1, C)
beta = beta.unsqueeze(1) # (B, 1, C)
F_guided = (gamma + 1) * F_vit + beta # residual affine
return self.norm(F_guided)
# ─── SECTION 7: Detection Head ─────────────────────────────────────────────────
class SimpleDetectionHead(nn.Module):
"""
Lightweight DETR-style detection head.
Applies object queries over the language-modulated ViT features,
then predicts class logits and bounding boxes for each query.
In a full deployment, this would be replaced by MMDetection's
DINOv2-compatible detection head with proper Hungarian matching.
"""
def __init__(self, vit_dim: int, num_queries: int, num_classes: int):
super().__init__()
self.queries = nn.Embedding(num_queries, vit_dim)
# Cross-attention: queries attend to ViT tokens
self.cross_attn = nn.MultiheadAttention(vit_dim, num_heads=8, batch_first=True)
self.norm1 = nn.LayerNorm(vit_dim)
self.ffn = nn.Sequential(
nn.Linear(vit_dim, vit_dim * 4), nn.GELU(), nn.Linear(vit_dim * 4, vit_dim)
)
self.norm2 = nn.LayerNorm(vit_dim)
# Output heads
self.cls_head = nn.Linear(vit_dim, num_classes + 1) # +1 for background
self.box_head = nn.Sequential(
nn.Linear(vit_dim, vit_dim), nn.ReLU(),
nn.Linear(vit_dim, 4), nn.Sigmoid() # cx, cy, w, h normalized
)
def forward(self, features: Tensor) -> Dict[str, Tensor]:
"""
features: (B, N, D) — language-guided ViT tokens
Returns dict with 'logits' (B, Q, C+1) and 'boxes' (B, Q, 4)
"""
B = features.shape[0]
q = self.queries.weight.unsqueeze(0).expand(B, -1, -1) # (B, Q, D)
# Cross-attend: object queries look at ViT feature tokens
q_out, _ = self.cross_attn(q, features, features)
q_out = self.norm1(q + q_out)
q_out = self.norm2(q_out + self.ffn(q_out))
logits = self.cls_head(q_out) # (B, Q, C+1)
boxes = self.box_head(q_out) # (B, Q, 4)
return {'logits': logits, 'boxes': boxes}
# ─── SECTION 8: Full SLGNet Model ─────────────────────────────────────────────
class SLGNet(nn.Module):
"""
SLGNet: Synergizing Structural Priors and Language-Guided Modulation
for Multimodal Object Detection (RGB + Infrared).
Parameter groups:
- FROZEN: ViT backbone (DINOv2 pre-trained weights)
- TRAINABLE: SA-Adapter (S-Encoder + FF-Adapters) + LGM + Detection Head
Total trainable ≈ 12.1M for ViT-Base configuration
Forward pipeline:
1. S-Encoder extracts 3-level structural pyramid from RGB+IR
2. FF-Adapters inject structural priors into each ViT block
3. LGM modulates final ViT output using structured caption embeddings
4. Detection head predicts boxes and classes from modulated features
"""
def __init__(self, cfg: Optional[SLGConfig] = None):
super().__init__()
cfg = cfg or SLGConfig()
self.cfg = cfg
# Frozen ViT backbone
self.backbone = FrozenViT(cfg)
# Trainable adapter modules
self.sa_adapter = StructureAwareAdapter(cfg)
# Trainable language-guided modulation
self.lgm = LGMModule(cfg)
# Trainable task decoder
self.det_head = SimpleDetectionHead(
vit_dim=cfg.vit_embed_dim,
num_queries=cfg.num_queries,
num_classes=cfg.num_classes,
)
def trainable_parameters(self) -> List[nn.Parameter]:
"""Returns only the trainable parameters (backbone is frozen)."""
params = []
for module in [self.sa_adapter, self.lgm, self.det_head]:
params.extend(p for p in module.parameters() if p.requires_grad)
return params
def forward(
self,
rgb: Tensor, # (B, 3, H, W)
ir: Tensor, # (B, 3, H, W)
text_features: Tensor, # (B, 4, text_dim) — CLIP embeddings for captions
) -> Dict[str, Tensor]:
"""
Full forward pass of SLGNet.
Step 1: Extract structural feature pyramid from RGB+IR (S-Encoder)
Step 2: Run frozen ViT with FF-Adapter injection at each block
Step 3: Apply LGM modulation using language-derived γ, β
Step 4: Detect objects from modulated features
Returns: dict with 'logits' and 'boxes' for each query
"""
# Step 1: Hierarchical structural priors (S-Encoder)
struct_feats = self.sa_adapter.encode_structure(rgb, ir)
# struct_feats: [level-0 (1/8), level-1 (1/16), level-2 (1/32)]
# Build per-block structural feat lists (same feats broadcast to all blocks)
# In the paper, feats evolve via MLP inside FF-Adapter (Eq. 9)
per_block_feats = [list(struct_feats) for _ in range(self.cfg.vit_num_layers)]
# Step 2: Frozen ViT with structural injection
ff_adapters = self.sa_adapter.get_ff_adapters()
F_vit = self.backbone(rgb, ff_adapters=ff_adapters, struct_feats=per_block_feats)
# F_vit: (B, N_patches, D)
# Step 3: Language-guided modulation (LGM)
F_guided = self.lgm(F_vit, text_features) # (B, N_patches, D)
# Step 4: Detection
output = self.det_head(F_guided)
return output
# ─── SECTION 9: Loss Functions & Training Utilities ───────────────────────────
class HungarianDetectionLoss(nn.Module):
"""
Simplified detection loss combining:
- Classification loss (cross-entropy)
- Bounding box regression (L1 + GIoU placeholder)
In full production: use scipy.optimize.linear_sum_assignment for
Hungarian matching between predicted queries and ground-truth boxes,
following DETR's training recipe.
"""
def __init__(self, w_cls: float = 1.0, w_box: float = 5.0):
super().__init__()
self.w_cls = w_cls
self.w_box = w_box
self.cls_loss = nn.CrossEntropyLoss()
def forward(
self,
outputs: Dict[str, Tensor],
gt_labels: Tensor, # (B, Q) — target class indices (simplified)
gt_boxes: Tensor, # (B, Q, 4) — target boxes normalized
) -> Tensor:
logits = outputs['logits'] # (B, Q, C+1)
boxes = outputs['boxes'] # (B, Q, 4)
B, Q, _ = logits.shape
loss_cls = self.cls_loss(logits.reshape(B*Q, -1), gt_labels.reshape(-1))
loss_box = F.l1_loss(boxes, gt_boxes)
return self.w_cls * loss_cls + self.w_box * loss_box
def build_layerwise_optimizer(
model: SLGNet,
base_lr: float = 1e-4,
weight_decay: float = 0.1,
decay_rate: float = 0.7,
) -> torch.optim.Optimizer:
"""
Build AdamW optimizer with layer-wise learning rate decay (Section IV-B).
Lower layers of the adapter retain generic features (lower LR).
Higher layers adapt more aggressively to the specific task (higher LR).
Frozen backbone parameters are excluded entirely.
"""
param_groups = []
# FF-Adapters: decay from last layer to first
n_ff = len(model.sa_adapter.ff_adapters)
for i, ff_adapter in enumerate(model.sa_adapter.ff_adapters):
layer_lr = base_lr * (decay_rate ** (n_ff - i - 1))
param_groups.append({
'params': list(ff_adapter.parameters()),
'lr': layer_lr,
'weight_decay': weight_decay,
'name': f'ff_adapter_{i}'
})
# S-Encoder, LGM, and detection head: use base_lr
for name, module in [
('s_encoder', model.sa_adapter.s_encoder),
('lgm', model.lgm),
('det_head', model.det_head),
]:
params = [p for p in module.parameters() if p.requires_grad]
if params:
param_groups.append({
'params': params,
'lr': base_lr,
'weight_decay': weight_decay,
'name': name
})
return torch.optim.AdamW(param_groups)
# ─── SECTION 10: Dataset, Training Loop & Smoke Test ──────────────────────────
class SyntheticMultimodalDataset(Dataset):
"""
Synthetic RGB+IR dataset for testing SLGNet's training pipeline.
Replace with real loaders:
LLVIP: https://github.com/bupt-ai-cz/LLVIP
FLIR: https://www.flir.com/oem/adas/adas-dataset-form/
KAIST: https://soonminhwang.github.io/rgbt-ped-detection/
DroneVehicle: https://github.com/VisDrone/DroneVehicle
Each sample returns:
rgb: (3, H, W) normalized
ir: (3, H, W) normalized (IR channels replicated to 3)
text_features: (4, text_dim) CLIP-style caption embeddings
gt_labels: (num_queries,) class indices
gt_boxes: (num_queries, 4) normalized boxes
"""
def __init__(
self,
num_samples: int = 100,
img_size: int = 64,
num_queries: int = 20,
text_dim: int = 64,
num_classes: int = 1,
):
self.n = num_samples
self.img_size = img_size
self.num_queries = num_queries
self.text_dim = text_dim
self.num_classes = num_classes
def __len__(self): return self.n
def __getitem__(self, idx):
S = self.img_size
rgb = torch.randn(3, S, S)
ir = torch.randn(3, S, S)
# Simulate CLIP text embeddings for 4 caption components
text_features = torch.randn(4, self.text_dim)
# Ground truth (for smoke test, random labels)
gt_labels = torch.randint(0, self.num_classes + 1, (self.num_queries,))
gt_boxes = torch.rand(self.num_queries, 4).clamp(0, 1)
return rgb, ir, text_features, gt_labels, gt_boxes
def train_one_epoch(
model: SLGNet,
loader: DataLoader,
optimizer: torch.optim.Optimizer,
criterion: HungarianDetectionLoss,
device: torch.device,
epoch: int,
) -> float:
"""Standard training loop for one epoch over a multimodal detection dataset."""
model.train()
total_loss = 0.0
for step, (rgb, ir, text_feat, gt_labels, gt_boxes) in enumerate(loader):
rgb = rgb.to(device)
ir = ir.to(device)
text_feat = text_feat.to(device)
gt_labels = gt_labels.to(device)
gt_boxes = gt_boxes.to(device)
optimizer.zero_grad()
outputs = model(rgb, ir, text_feat)
loss = criterion(outputs, gt_labels, gt_boxes)
loss.backward()
# Gradient clipping for stable training with frozen backbone
torch.nn.utils.clip_grad_norm_(model.trainable_parameters(), max_norm=1.0)
optimizer.step()
total_loss += loss.item()
if step % 5 == 0:
print(f" Epoch {epoch} | Step {step}/{len(loader)} | Loss {total_loss/(step+1):.4f}")
return total_loss / max(1, len(loader))
def run_training(
epochs: int = 3,
device_str: str = "cpu",
) -> SLGNet:
"""
Full SLGNet training pipeline (tiny config for demonstration).
Production training:
Phase 1: Pre-train on LLVIP/FLIR with AdamW lr=1e-4, 50 epochs
Phase 2: Fine-tune on KAIST/DroneVehicle with CosineAnnealingLR
GPU: NVIDIA H20 (paper), batch_size=8, AMP training enabled
"""
device = torch.device(device_str)
cfg = SLGConfig(tiny=True)
model = SLGNet(cfg).to(device)
total_params = sum(p.numel() for p in model.parameters())
trainable_params = sum(p.numel() for p in model.trainable_parameters())
print(f"Total params: {total_params/1e6:.2f}M | Trainable: {trainable_params/1e6:.2f}M")
dataset = SyntheticMultimodalDataset(
num_samples=40,
img_size=cfg.img_size,
num_queries=cfg.num_queries,
text_dim=cfg.text_embed_dim,
num_classes=cfg.num_classes,
)
loader = DataLoader(dataset, batch_size=4, shuffle=True, num_workers=0)
optimizer = build_layerwise_optimizer(model, base_lr=cfg.lr, decay_rate=cfg.lr_decay_rate)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=epochs)
criterion = HungarianDetectionLoss()
print(f"\n{'='*55}")
print(f" SLGNet Training | {epochs} epochs | {device}")
print(f" ViT embed: {cfg.vit_embed_dim} | Text dim: {cfg.text_embed_dim}")
print(f"{'='*55}\n")
for epoch in range(1, epochs + 1):
avg_loss = train_one_epoch(model, loader, optimizer, criterion, device, epoch)
scheduler.step()
print(f"Epoch {epoch}/{epochs} — Avg Loss: {avg_loss:.4f}\n")
print("Training complete.")
return model
# ─── SMOKE TEST ────────────────────────────────────────────────────────────────
if __name__ == "__main__":
print("=" * 60)
print(" SLGNet — Full Architecture Smoke Test")
print("=" * 60)
torch.manual_seed(42)
# ── 1. Instantiate tiny SLGNet ────────────────────────────────────────────
print("\n[1/5] Instantiating tiny SLGNet...")
cfg = SLGConfig(tiny=True)
model = SLGNet(cfg)
total_p = sum(p.numel() for p in model.parameters())
train_p = sum(p.numel() for p in model.trainable_parameters())
print(f" Total params: {total_p/1e6:.3f}M")
print(f" Trainable params: {train_p/1e6:.3f}M")
print(f" Frozen ratio: {(total_p - train_p)/total_p*100:.1f}%")
# ── 2. Single forward pass ───────────────────────────────────────────────
print("\n[2/5] Single forward pass...")
B = 2
rgb = torch.randn(B, 3, cfg.img_size, cfg.img_size)
ir = torch.randn(B, 3, cfg.img_size, cfg.img_size)
text_feat = torch.randn(B, 4, cfg.text_embed_dim)
outputs = model(rgb, ir, text_feat)
logits = outputs['logits']
boxes = outputs['boxes']
print(f" Logits shape: {tuple(logits.shape)} (expected: [2, {cfg.num_queries}, {cfg.num_classes+1}])")
print(f" Boxes shape: {tuple(boxes.shape)} (expected: [2, {cfg.num_queries}, 4])")
assert logits.shape == (B, cfg.num_queries, cfg.num_classes + 1)
assert boxes.shape == (B, cfg.num_queries, 4)
# ── 3. Loss computation ──────────────────────────────────────────────────
print("\n[3/5] Loss function check...")
criterion = HungarianDetectionLoss()
gt_labels = torch.randint(0, cfg.num_classes + 1, (B, cfg.num_queries))
gt_boxes = torch.rand(B, cfg.num_queries, 4)
loss = criterion(outputs, gt_labels, gt_boxes)
print(f" Combined cls+box loss: {loss.item():.4f}")
assert loss.item() > 0
# ── 4. Backward pass (trainable params only) ─────────────────────────────
print("\n[4/5] Backward pass check...")
loss.backward()
grads = [p.grad for p in model.trainable_parameters() if p.grad is not None]
backbone_grads = [p.grad for p in model.backbone.parameters() if p.grad is not None]
print(f" Trainable params with grad: {len(grads)}")
print(f" Backbone params with grad: {len(backbone_grads)} (should be 0 — frozen)")
assert len(backbone_grads) == 0, "Backbone should be frozen!"
# ── 5. Short training run ────────────────────────────────────────────────
print("\n[5/5] Short training run (2 epochs, tiny config)...")
run_training(epochs=2, device_str="cpu")
print("\n" + "=" * 60)
print("✓ All checks passed. SLGNet is ready for use.")
print("=" * 60)
print("""
Next steps for full production training:
1. Load pretrained DINOv2 ViT-Base weights (frozen):
pip install timm
import timm
vit = timm.create_model('vit_base_patch16_224.dino', pretrained=True)
# Transfer weights to FrozenViT blocks
2. Load CLIP text encoder (frozen):
pip install openai-clip
import clip
clip_model, _ = clip.load('ViT-B/32', device=device)
# Use clip_model.encode_text() in CLIPTextEncoder.forward()
3. Generate structured captions offline with Qwen2.5-VL:
# Environmental: illumination, weather
# Scene: spatial layout, context
# Objects: presence, density
# Thermal: contrast, crossover indicators
4. Plug into MMDetection for LLVIP/FLIR:
# Replace SimpleDetectionHead with your preferred DETR head
# Register SLGNet backbone via mm_plugin
5. Train with Automatic Mixed Precision (AMP):
scaler = torch.cuda.amp.GradScaler()
with torch.cuda.amp.autocast():
outputs = model(rgb, ir, text_feat)
""")
Paper & Source Code
The full SLGNet paper with benchmark comparisons across LLVIP, FLIR, KAIST, and DroneVehicle is available on arXiv. The official codebase is available on GitHub.
Xiang, X., Zhou, G., Wen, Z., Li, W., Niu, B., Wang, F., Huang, L., Wang, Q., Liu, Y., Pan, Z., & Hu, Y. (2026). SLGNet: Synergizing Structural Priors and Language-Guided Modulation for Multimodal Object Detection. arXiv:2601.02249v1 [cs.CV].
This article is an independent editorial analysis of peer-reviewed research. The PyTorch implementation is an educational adaptation of the methods described in the paper. Refer to the paper and official repository for exact training configurations, pretrained weights, and full benchmark evaluation code.
Explore More on AI Trend Blend
More research breakdowns from across the site — from foundation model adaptation to multimodal perception and beyond.