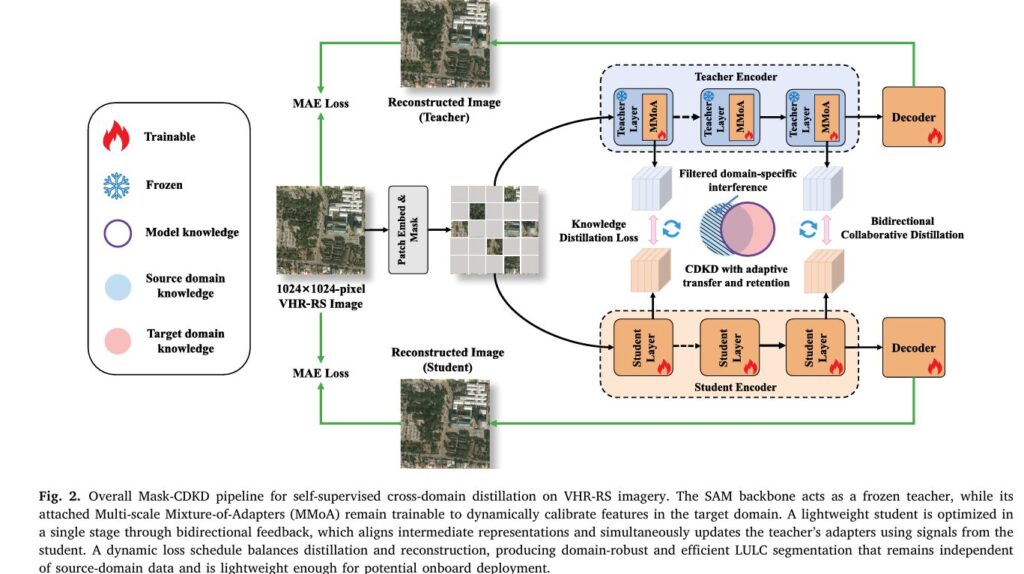
Mask-CDKD: Source-Free Knowledge Distillation from SAM for Satellite Onboard Land Cover Mapping
Mask-CDKD: Source-Free Knowledge Distillation from SAM for Satellite Onboard Land Cover Mapping | AI Trend Blend Satellite AI & Remote Sensing · ISPRS J. Photogramm. Remote Sens. 236 (2026) 1–21 · Wuhan University / Emory · 28 min read Teaching a Satellite to See the World Without Labels: How Mask-CDKD Squeezes SAM Into a 30M-Parameter […]