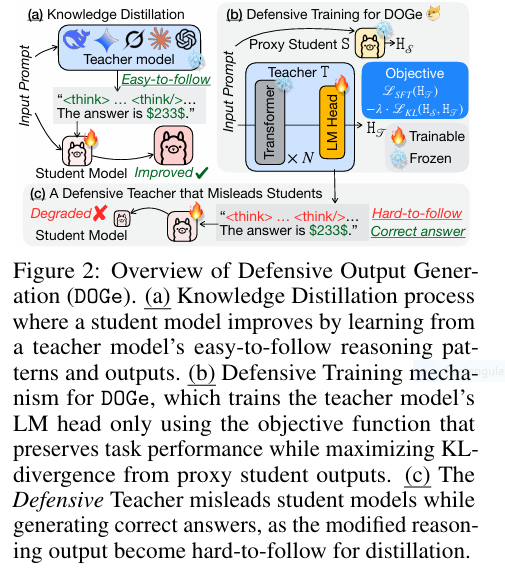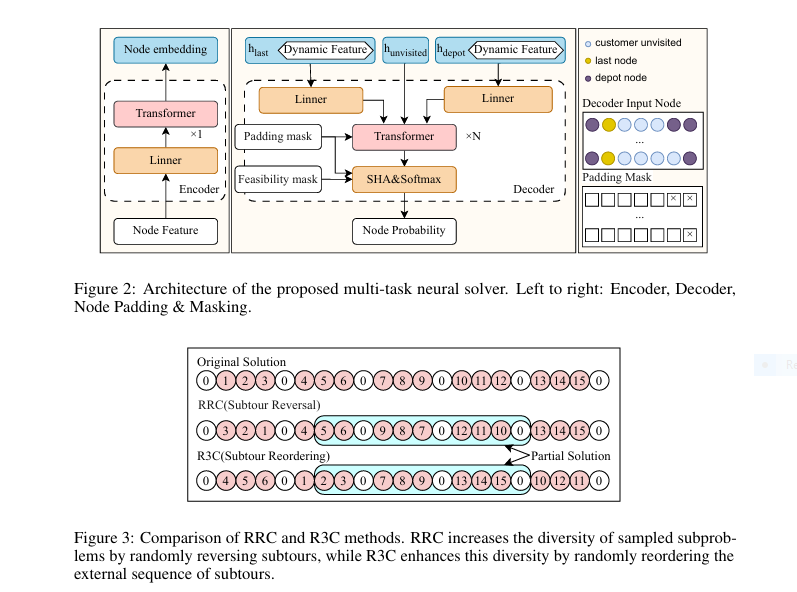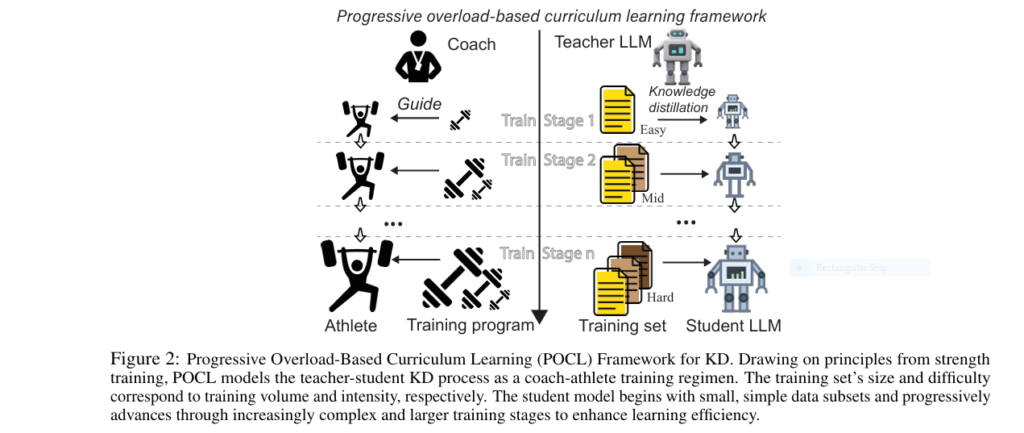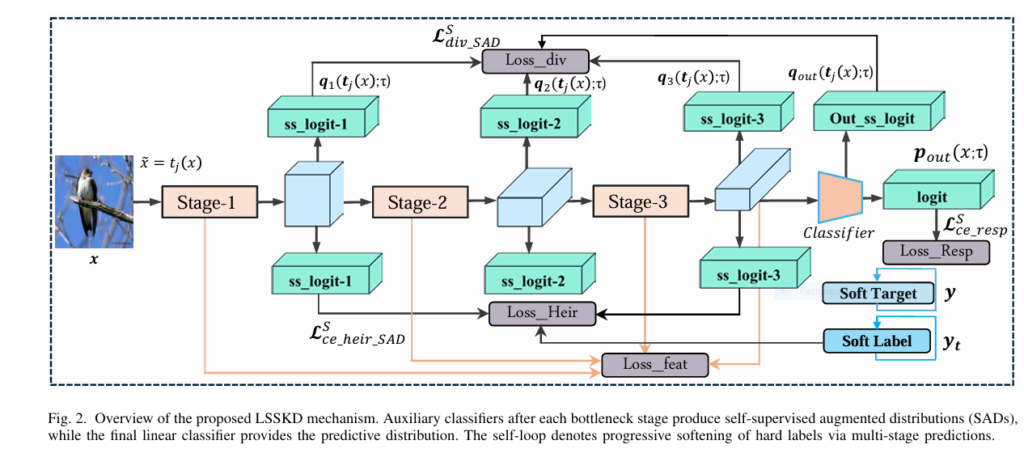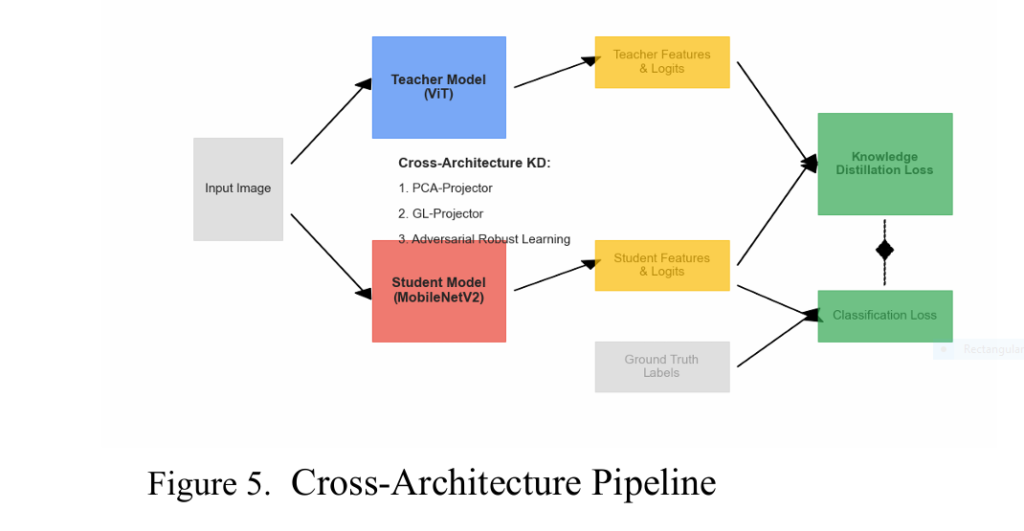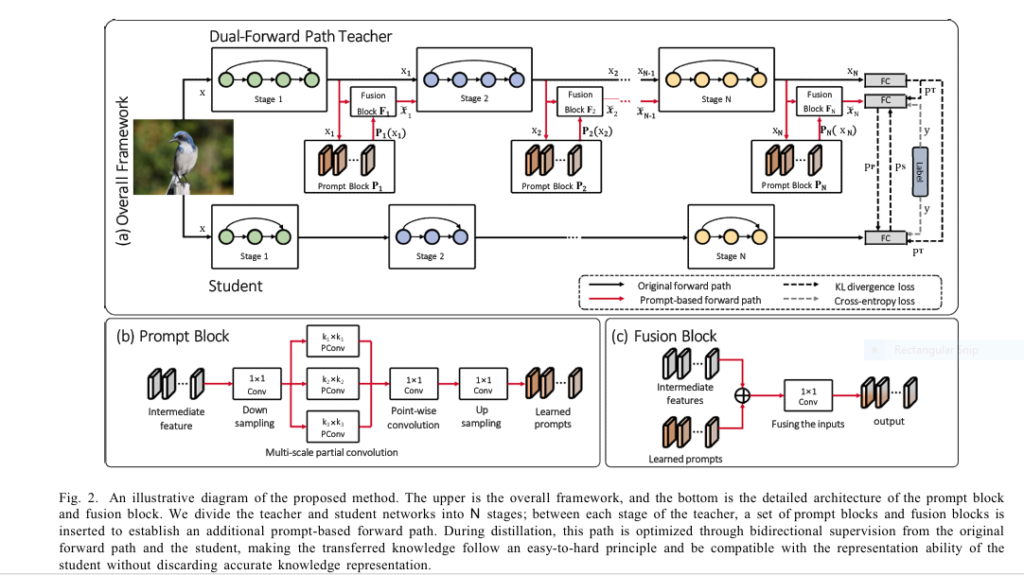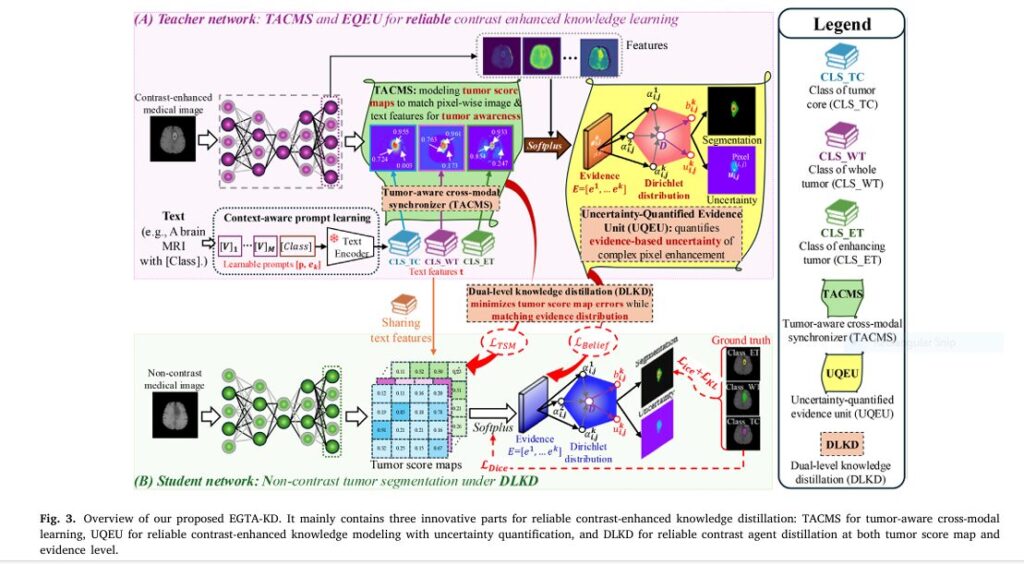
Revolutionary AI Breakthrough: Non-Contrast Tumor Segmentation Saves Lives & Avoids Deadly Risks
Imagine detecting deadly tumors without injecting risky contrast agents. A revolutionary AI framework called EGTA-KD is making this possible, achieving near-perfect segmentation (90.8% accuracy) on non-contrast scans while eliminating allergic reactions and kidney damage linked to traditional methods. This isn’t futuristic hype – it’s validated across brain, liver, and kidney tumors in major clinical datasets. The Deadly Cost of Current […]