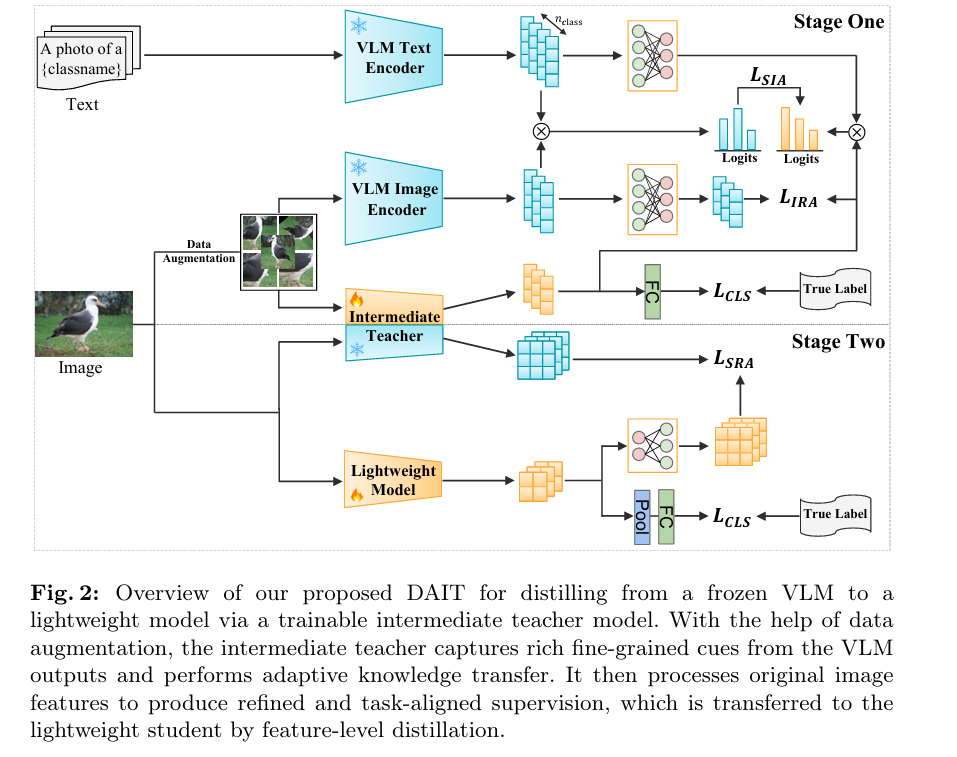
DAIT: Distilling CLIP into Tiny Classifiers with an Adaptive Intermediate Teacher
DAIT: Distilling CLIP into Tiny Classifiers with an Adaptive Intermediate Teacher | AI Trend Blend AITrendBlend Machine Learning Computer Vision About Fine-Grained Vision · Model Compression · arXiv:2603.15166 | Nanjing Normal University · Westlake University (2026) · 20 min read DAIT: Why You Should Never Ask CLIP to Directly Teach ResNet-18 — And What to […]
DAIT: Distilling CLIP into Tiny Classifiers with an Adaptive Intermediate Teacher Read More »