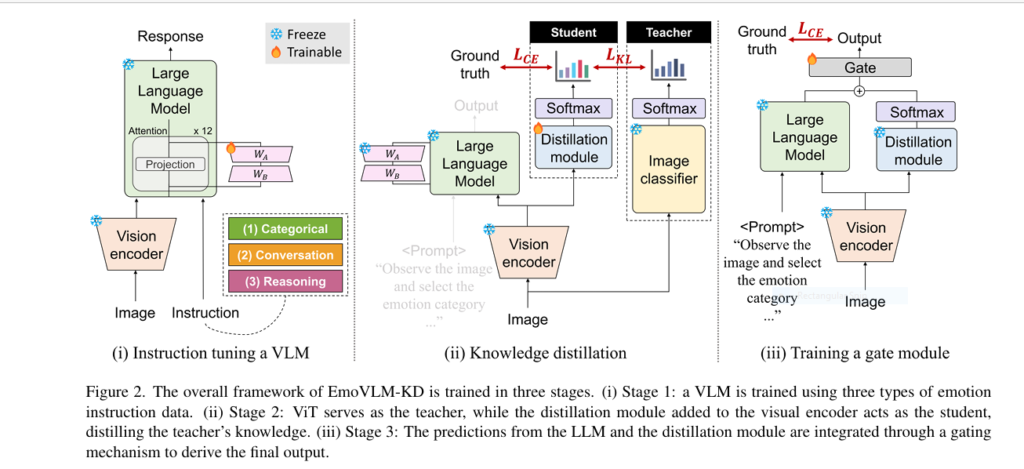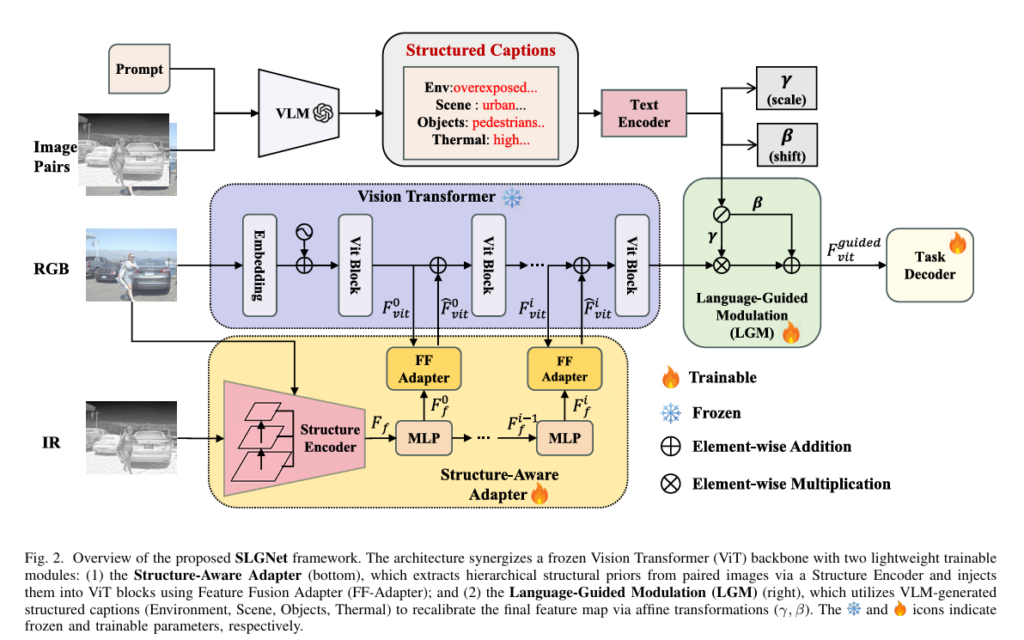
SLGNet: Structural Priors and Language-Guided Modulation for Multimodal Object Detection
SLGNet: Structural Priors and Language-Guided Modulation for Multimodal Object Detection | AI Trend Blend AITrendBlend Machine Learning Computer Vision About Computer Vision · arXiv:2601.02249 · January 2026 · 22 min read When the Camera Goes Blind: How SLGNet Uses Language and Structure to See in the Dark Researchers at the Chinese Academy of Sciences built […]
SLGNet: Structural Priors and Language-Guided Modulation for Multimodal Object Detection Read More »