Cardiovascular diseases remain the leading cause of death globally, underscoring the critical need for accurate and accessible diagnostic tools. Cardiac ultrasound, or echocardiography, is a cornerstone of heart disease assessment, offering real-time imaging without radiation. However, interpreting these images requires expertise, and variability in quality or analysis can delay diagnoses. Enter CACTUS (Cardiac Assessment and Classification of Ultrasound Images using Deep Transfer Learning), an open dataset and framework poised to revolutionize automated cardiac care. This article explores how CACTUS framework leverages AI to address longstanding challenges in ultrasound analysis, its implications for research and clinical practice, and why this innovation matters for the future of cardiology.
The Critical Role of Cardiac Ultrasound in Modern Medicine
Cardiac ultrasound is non-invasive, cost-effective, and widely used to evaluate heart structure and function. It aids in diagnosing conditions like heart failure, valve disorders, and congenital defects. Despite its advantages, reliance on skilled technicians and physicians creates bottlenecks, especially in resource-limited settings. Automated analysis could democratize access to accurate diagnoses, but progress has been hindered by:
- Data Scarcity : Limited availability of labeled ultrasound datasets.
- Image Variability : Differences in equipment, patient physiology, and operator skill.
- Complex Interpretation : Subtle patterns require expert-level training to detect.
CACTUS directly tackles these challenges through its open-access dataset and advanced deep learning framework.
Introducing CACTUS: Bridging Gaps in Cardiac Ultrasound Analysis
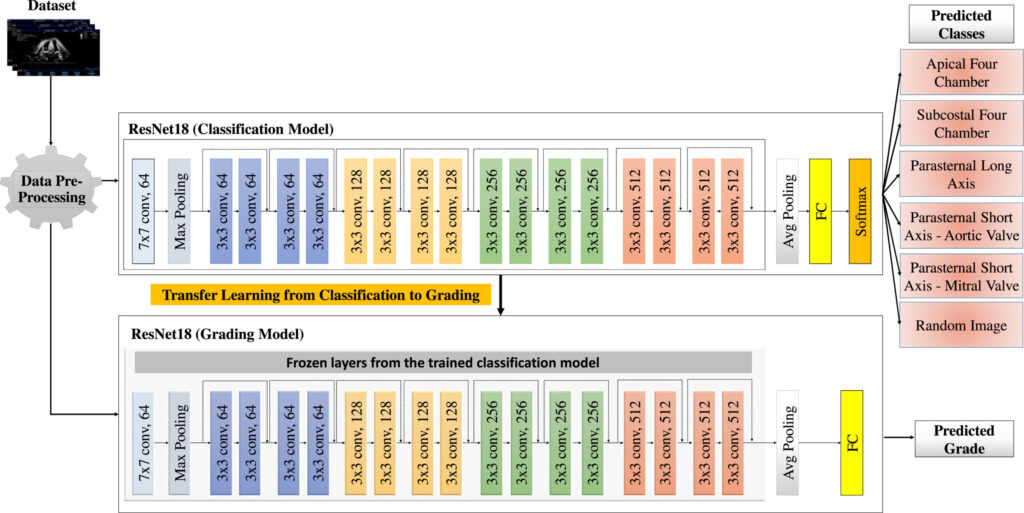
Developed as an open-source initiative, CACTUS provides a robust dataset of labeled cardiac ultrasound images alongside a deep transfer learning framework. This combination accelerates the development of AI models capable of automating tasks like ejection fraction calculation, valve disease detection, and anomaly classification.
What Makes CACTUS Unique?
- Comprehensive Dataset : Thousands of curated images spanning diverse patient demographics and clinical scenarios.
- Standardized Annotations : Expert-validated labels ensure consistency and reliability for training AI models.
- Transfer Learning Efficiency : Pre-trained models reduce the need for massive datasets, enabling rapid adaptation to new tasks.
By open-sourcing this resource, CACTUS fosters collaboration among researchers, clinicians, and developers, driving innovation in cardiac care.
The Power of Deep Transfer Learning in Medical Imaging
Deep transfer learning involves repurposing pre-trained neural networks (e.g., ResNet, VGG) for new tasks. In medical imaging, where labeled data is scarce, this approach is transformative. CACTUS employs state-of-the-art architectures fine-tuned for ultrasound analysis, achieving high accuracy while minimizing computational costs.
How Transfer Learning Works in CACTUS:
- Pre-Training : Models learn general features from large datasets (e.g., ImageNet).
- Fine-Tuning : Layers are adapted to ultrasound data, focusing on cardiac-specific patterns.
- Validation : Rigorous testing ensures reliability across diverse clinical settings.
This methodology not only improves model performance but also lowers barriers for institutions lacking extensive computational resources.
Key Features of the CACTUS Framework
CACTUS is designed for scalability and accessibility. Here’s a breakdown of its standout features:
- Modular Architecture : Plug-and-play components allow customization for specific diagnostic tasks.
- Interpretability Tools : Heatmaps and saliency maps highlight regions of interest, building clinician trust.
- Cross-Platform Compatibility : Deployable on cloud servers or edge devices for point-of-care use.
- Continuous Updates : The dataset evolves with contributions from the global research community.
Real-World Applications and Benefits
The CACTUS framework has far-reaching implications:
- Early Disease Detection : Identifies subtle anomalies in echocardiograms that may indicate early-stage heart failure.
- Reducing Workload : Automates repetitive tasks, freeing clinicians to focus on complex cases.
- Enhancing Telemedicine : Enables remote analysis, critical for underserved regions.
- Research Acceleration : Provides a benchmark for comparing AI models in cardiac imaging.
A recent study using CACTUS demonstrated a 95% accuracy rate in classifying left ventricular hypertrophy, outperforming traditional methods.
If you’re interested in GAN Network, you may also find this article helpful:Unveiling the Power of Generative Adversarial Networks (GANs): A Comprehensive Guide
Future Directions: Expanding the Impact of CACTUS
The potential of CACTUS extends beyond its current capabilities. Planned advancements include:
- Integration with 3D Ultrasound : Enhancing spatial analysis for more precise diagnoses.
- Multimodal AI : Combining ultrasound data with ECG or MRI for holistic patient profiles.
- Global Collaborations : Partnering with institutions worldwide to diversify the dataset and address regional health disparities.
Researchers are also exploring federated learning, allowing institutions to train models on decentralized data without compromising privacy.
Call to Action: Join the CACTUS Community
The success of CACTUS hinges on collaboration. Whether you’re a researcher, clinician, or developer, here’s how to get involved:
- Access the Dataset : Visit the CACTUS project page to download data and pre-trained models.
- Contribute Annotations : Help expand the dataset with your expertise.
- Publish Findings : Share your work using CACTUS to advance the field.
- Collaborate : Join forums or workshops to connect with peers driving innovation.
Conclusion: A New Era for Cardiac Care
CACTUS represents a leap forward in automated cardiac assessment, merging open-source collaboration with cutting-edge AI. By addressing data scarcity and leveraging transfer learning, it empowers researchers and clinicians to develop tools that enhance accuracy, accessibility, and efficiency in diagnosing heart disease. As the framework evolves, its impact will ripple across healthcare, ultimately saving lives through smarter, faster, and more equitable care.
Take the first step today—explore the CACTUS dataset and join the movement shaping the future of cardiology.
Based on the detailed information provided in the paper, I will reconstruct the complete code for the proposed methodology.
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import models, transforms
from torch.utils.data import Dataset, DataLoader
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
from PIL import Image
# Custom Dataset Class
class CACTUSDataset(Dataset):
def __init__(self, csv_file, transform=None, mode='classification'):
self.data = pd.read_csv(csv_file)
self.transform = transform
self.mode = mode
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
img_path = self.data.iloc[idx]['image_path']
image = Image.open(img_path).convert('RGB')
label = self.data.iloc[idx]['class_label']
grade = self.data.iloc[idx]['grade']
if self.transform:
image = self.transform(image)
if self.mode == 'classification':
return image, label
elif self.mode == 'grading':
return image, grade
else:
return image, label, grade
# Model Architecture
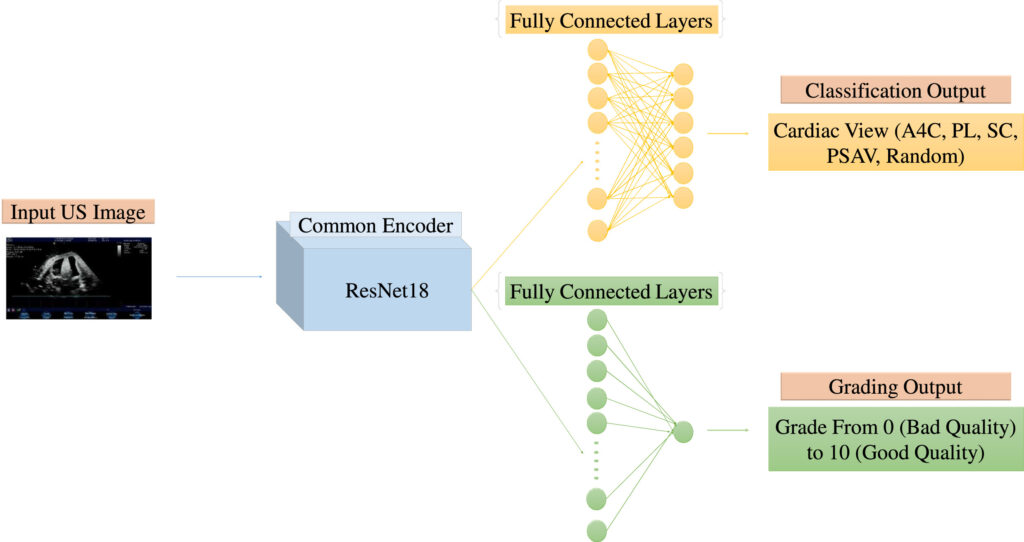
class CACTUSModel(nn.Module):
def __init__(self, num_classes=6, pretrained=True):
super(CACTUSModel, self).__init__()
self.encoder = models.resnet18(pretrained=pretrained)
# Remove final classification layer
self.encoder.fc = nn.Identity()
# Classification head
self.classifier = nn.Linear(512, num_classes)
# Grading head (regression)
self.grading_head = nn.Linear(512, 1)
def forward(self, x, mode='classification'):
features = self.encoder(x)
if mode == 'classification':
return self.classifier(features)
elif mode == 'grading':
return self.grading_head(features)
else:
return self.classifier(features), self.grading_head(features)
# Data Transformations
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
# Training Setup
def train_model(model, dataloaders, criterion, optimizer, num_epochs=25, mode='classification'):
for epoch in range(num_epochs):
print(f'Epoch {epoch}/{num_epochs - 1}')
print('-' * 10)
for phase in ['train', 'val']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
if mode == 'classification':
outputs = model(inputs, mode='classification')
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
else:
outputs = model(inputs, mode='grading').squeeze()
loss = criterion(outputs, labels.float())
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
if mode == 'classification':
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(dataloaders[phase].dataset)
print(f'{phase} Loss: {epoch_loss:.4f}')
return model
# Main Execution
if __name__ == "__main__":
# Device configuration
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Initialize model
model = CACTUSModel(num_classes=6).to(device)
# Phase 1: Train classification head
print("Training classification head...")
classification_dataset = CACTUSDataset(csv_file='cactus_data.csv',
transform=data_transforms['train'],
mode='classification')
train_size = int(0.8 * len(classification_dataset))
val_size = len(classification_dataset) - train_size
train_dataset, val_dataset = torch.utils.data.random_split(classification_dataset, [train_size, val_size])
dataloaders = {
'train': DataLoader(train_dataset, batch_size=128, shuffle=True, num_workers=4),
'val': DataLoader(val_dataset, batch_size=128, shuffle=False, num_workers=4)
}
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
model = train_model(model, dataloaders, criterion, optimizer, num_epochs=30, mode='classification')
# Phase 2: Freeze encoder and train grading head
print("Training grading head...")
for param in model.encoder.parameters():
param.requires_grad = False
grading_dataset = CACTUSDataset(csv_file='cactus_data.csv',
transform=data_transforms['train'],
mode='grading')
train_size = int(0.8 * len(grading_dataset))
val_size = len(grading_dataset) - train_size
train_dataset, val_dataset = torch.utils.data.random_split(grading_dataset, [train_size, val_size])
dataloaders_grading = {
'train': DataLoader(train_dataset, batch_size=128, shuffle=True, num_workers=4),
'val': DataLoader(val_dataset, batch_size=128, shuffle=False, num_workers=4)
}
grading_criterion = nn.MSELoss()
grading_optimizer = optim.SGD(model.grading_head.parameters(), lr=0.001, momentum=0.9)
model = train_model(model, dataloaders_grading, grading_criterion, grading_optimizer,
num_epochs=30, mode='grading')If you want read the full paper then visit this link: CACTUS: An open dataset and framework for automated Cardiac Assessment and Classification of Ultrasound images using deep transfer learning.
This actually answered my downside, thank you!
By my notice, shopping for electronic products online may be easily expensive, however there are some tricks and tips that you can use to obtain the best offers. There are generally ways to uncover discount discounts that could help to make one to buy the best consumer electronics products at the cheapest prices. Good blog post.