Brain tumors are among the most challenging medical conditions to diagnose and treat. Their complexity, coupled with the need for precise classification, demands cutting-edge solutions that can support clinicians in making informed decisions. In recent years, deep learning has emerged as a game-changer in medical imaging, offering unprecedented accuracy and efficiency. One groundbreaking advancement in this field is DEF-SwinE2NET , a novel architecture designed for brain tumor classification using multi-model fusion and preprocessing optimization.
In this article, we’ll explore how DEF-SwinE2NET works, its key features, and why it stands out as a revolutionary tool for brain tumor detection and classification. Whether you’re a researcher, healthcare professional, or simply curious about advancements in AI-driven healthcare, this article will provide valuable insights into the future of medical diagnostics.
The Challenge: Why Brain Tumor Classification Is So Difficult
Brain tumors exhibit high intra-class variability (differences within the same tumor type) and low inter-class similarity (overlaps between tumor types), making them notoriously hard to classify. Additional hurdles include:
- Limited datasets: Medical imaging data is often small and imbalanced.
- Noise and low contrast: MRI scans require meticulous preprocessing to highlight tumor boundaries.
- Computational complexity: Traditional CNNs struggle to capture both local and global features efficiently.
Existing models like ResNet, DenseNet, and VGGNet have shown promise but fall short in handling multi-scale features and long-range dependencies critical for precise diagnosis.
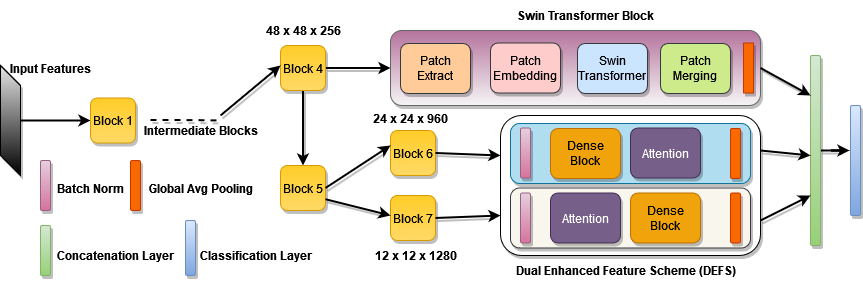
Introducing DEF-SwinE2NET: A Hybrid Deep Learning Powerhouse
DEF-SwinE2NET addresses these challenges through a fusion of state-of-the-art technologies:
1. EfficientNetV2S: The Lightweight Backbone
- Why It Matters: EfficientNetV2S balances accuracy and efficiency, using compound scaling to optimize depth, width, and resolution.
- Key Features:
- Fused-MB Conv Layers: Accelerate training while maintaining performance.
- Swish Activation: Smoother gradients for better feature extraction.
2. Swin Transformer: Capturing Global Context
- Shifted Window Mechanism: Breaks images into non-overlapping patches, enabling the model to learn hierarchical patterns and long-range dependencies.
- Advantage Over CNNs: Traditional convolutional layers focus on local features; Swin Transformer excels at global context, crucial for tumors with irregular boundaries.
3. Dual Enhanced Features Scheme (DEFS): Precision Through Innovation
- Dense Block with Dilated Convolutions: Expands the receptive field without increasing parameters, capturing multi-scale tumor features.
- Dual Attention Mechanism:
- Spatial Attention: Identifies critical regions (e.g., tumor edges).
- Channel Attention: Enhances relevant feature maps while suppressing noise.
Preprocessing Optimization: Laying the Foundation for Accuracy
Before training, MRI images undergo rigorous preprocessing to improve model performance:
- Median Filtering: Reduces noise while preserving edges.
- CLAHE (Contrast-Limited Adaptive Histogram Equalization): Enhances local contrast to highlight subtle tumor details.
- Laplacian Edge Enhancement: Sharpens boundaries for clearer feature extraction.
- Image Cropping: Removes irrelevant background data, focusing solely on the tumor region.
- Data Augmentation: Techniques like rotation, flipping, and brightness adjustment combat overfitting.
Results: DEF-SwinE2NET Outperforms State-of-the-Art Models
The model was tested on three benchmark datasets (Kaggle and Figshare), achieving:
- 99.43% Accuracy: Highest among competing models.
- 99.39% Sensitivity: Minimizes false negatives, critical in medical diagnostics.
- 99.41% F1-Score: Balances precision and recall.
Key Comparisons
| Model | Accuracy | Sensitivity |
|---|---|---|
| Traditional CNN | 93–98% | 91–97% |
| ResNet/DenseNet | 96–98% | 95–98% |
| DEF-SwinE2NET | 99.43% | 99.39% |
Ablation studies confirmed the DEFS and Swin Transformer boost performance by 3–4% over baseline EfficientNetV2S.
Clinical Implications: Transforming Brain Tumor Diagnosis
- Early Detection: High sensitivity ensures tumors are identified at earlier stages.
- Personalized Treatment: Accurate classification (glioma, meningioma, pituitary) guides targeted therapies.
- Real-World Applicability: The model’s efficiency makes it viable for integration into clinical workflows.
Limitations and Future Work:
- Computational Overhead: DEF-SwinE2NET’s added layers may increase inference time.
- Dataset Diversity: Further validation on larger, multi-institutional datasets is needed.
Why DEF-SwinE2NET Stands Out in Medical AI
- Explainability: Grad-CAM visualizations show the model focuses on tumor regions, building trust among clinicians.
- Scalability: Adaptable to varying image resolutions and modalities (e.g., CT scans).
- Robustness: Preprocessing and augmentation techniques ensure reliability across noisy datasets.
If you’re interested in Skin Cancer Classification with Transformer Model, you may also find this article helpful: SILP: A Breakthrough in Skin Lesion Classification and Skin Cancer Detection
Conclusion: The Future of AI in Medical Imaging
DEF-SwinE2NET exemplifies the transformative power of AI in medical diagnostics. By combining advanced deep learning techniques with meticulous preprocessing, it delivers unparalleled accuracy and efficiency in brain tumor classification. As we continue to refine and expand this technology, the future of healthcare looks brighter than ever.
Stay tuned for updates on DEF-SwinE2NET and other groundbreaking innovations in AI-driven medicine. Your feedback and engagement are invaluable—let’s shape the future of healthcare together!
Call to Action: Join the Revolution in Medical AI
Are you excited about the possibilities of AI in healthcare? Whether you’re a researcher looking to collaborate, a clinician eager to integrate advanced tools into your practice, or a student interested in pursuing a career in medical AI, now is the time to get involved!
- Researchers : Dive deeper into the DEF-SwinE2NET architecture by accessing the full paper here .
- Clinicians : Explore how DEF-SwinE2NET can transform your diagnostic workflows and improve patient outcomes.
- Students : Start your journey in AI and healthcare by learning about deep learning frameworks like TensorFlow and PyTorch.
Together, we can revolutionize healthcare and ensure that cutting-edge technologies like DEF-SwinE2NET reach those who need them most.
Based on the detailed information provided in the paper, I will reconstruct the complete code for the proposed Vision DEF-SwinE2NET model .
from tensorflow.keras import layers
class Attention_block(layers.Layer):
def __init__(self):
super(Attention_block, self).__init__()
def build(self, input_shape):
channels = input_shape[-1]
self.avg_pool = layers.GlobalAveragePooling2D()
self.spatial_attention = layers.Dense(channels, activation='sigmoid')
self.channel_attention = layers.Dense(channels, activation='sigmoid')
self.channel_attention_output = layers.Dense(channels, activation='sigmoid')
def call(self, inputs):
spatial = self.avg_pool(inputs)
spatial = self.spatial_attention(spatial)
spatial = layers.Multiply()([inputs, spatial])
channel = self.channel_attention(inputs)
channel = self.channel_attention_output(channel)
channel = layers.Multiply()([inputs, channel])
attention_weights = layers.Multiply()([spatial, channel])
return attention_weightsfrom tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, concatenate, GlobalAveragePooling2D, Dense, Input
class DenseBlockWithDilation(tf.keras.layers.Layer):
def __init__(self, num_filters=1280, growth_rate=12):
super(DenseBlockWithDilation, self).__init__()
self.num_filters = num_filters
self.growth_rate = growth_rate
def build(self, input_shape):
self.dilated_conv1 = Conv2D(filters=self.num_filters, kernel_size=(3, 3), padding='same', activation='swish',
kernel_initializer='he_normal', dilation_rate=2)
self.dilated_conv2 = Conv2D(filters=self.growth_rate, kernel_size=(3, 3), padding='same', activation='swish',
kernel_initializer='he_normal', dilation_rate=2)
self.batch_norm = BatchNormalization()
def call(self, inputs):
output = inputs
dilated_outputs = []
for i in range(self.growth_rate):
dilated_conv1 = self.dilated_conv1(output)
dilated_conv2 = self.dilated_conv2(dilated_conv1)
dilated_outputs.append(dilated_conv2)
dilated_outputs = concatenate(dilated_outputs, axis=-1) # Concatenate along the last axis
output = concatenate([output, dilated_outputs], axis=-1) # Concatenate backbone output with dilated outputs
output = self.batch_norm(output)
return outputpatch_size = (4,4) # 2-by-2 sized patches
dropout_rate = 0.5 # Dropout rate
num_heads = 8 # Attention heads
embed_dim = 64 # Embedding dimension
num_mlp = 128 # MLP layer size
qkv_bias = True # Convert embedded patches to query, key, and values
window_size = 4 # Size of attention window
shift_size = 1 # Size of shifting window
image_dimension = 48 # Initial image size / Input size of the transformer model
num_patch_x = image_dimension // patch_size[0]
num_patch_y = image_dimension // patch_size[1]
image_size=384from keras import layers
from tensorflow.keras import backend
def window_partition(x, window_size):
_, height, width, channels = x.shape
patch_num_y = height // window_size
patch_num_x = width // window_size
x = tf.reshape(
x, shape=(-1, patch_num_y, window_size, patch_num_x, window_size, channels)
)
x = tf.transpose(x, (0, 1, 3, 2, 4, 5))
windows = tf.reshape(x, shape=(-1, window_size, window_size, channels))
return windows
def window_reverse(windows, window_size, height, width, channels):
patch_num_y = height // window_size
patch_num_x = width // window_size
x = tf.reshape(
windows,
shape=(-1, patch_num_y, patch_num_x, window_size, window_size, channels),
)
x = tf.transpose(x, perm=(0, 1, 3, 2, 4, 5))
x = tf.reshape(x, shape=(-1, height, width, channels))
return x
class DropPath(layers.Layer):
def __init__(self, drop_prob=None, **kwargs):
super(DropPath, self).__init__(**kwargs)
self.drop_prob = drop_prob
def call(self, inputs, training=None):
if self.drop_prob == 0.0 or not training:
return inputs
else:
batch_size = tf.shape(inputs)[0]
keep_prob = 1 - self.drop_prob
input_rank = tf.rank(inputs)
path_mask_shape = tf.concat([[batch_size], tf.ones([input_rank - 1], dtype=tf.int32)], axis=0)
path_mask = tf.floor(
backend.random_bernoulli(shape=path_mask_shape, p=keep_prob)
)
outputs = (
tf.math.divide(tf.cast(inputs, dtype=tf.float32), keep_prob) * path_mask
)
return outputs
def get_config(self):
config = super().get_config()
config.update(
{
"drop_prob": self.drop_prob,
}
)
return configclass PatchExtract(layers.Layer):
def __init__(self, patch_size, **kwargs):
super().__init__(**kwargs)
self.patch_size_x = patch_size[0]
self.patch_size_y = patch_size[0]
def call(self, images):
batch_size = tf.shape(images)[0]
patches = tf.image.extract_patches(
images=images,
sizes=(1, self.patch_size_x, self.patch_size_y, 1),
strides=(1, self.patch_size_x, self.patch_size_y, 1),
rates=(1, 1, 1, 1),
padding="VALID",
)
patch_dim = tf.shape(patches)[-1] if patches is not None else None
patch_num = tf.shape(patches)[1] if patches is not None else None
if patch_dim is not None and patch_num is not None:
return tf.reshape(patches, (batch_size, patch_num * patch_num, patch_dim))
else:
return patches
def get_config(self):
config = super().get_config()
config.update(
{
"patch_size_y": self.patch_size_y,
"patch_size_x": self.patch_size_x,
}
)
return config
def get_config(self):
config = super().get_config()
config.update(
{
"patch_size_y": self.patch_size_y,
"patch_size_x": self.patch_size_x,
}
)
return config
class PatchEmbedding(layers.Layer):
def __init__(self, num_patch, embed_dim, **kwargs):
super().__init__(**kwargs)
self.num_patch = num_patch
self.proj = layers.Dense(embed_dim)
self.pos_embed = layers.Embedding(input_dim=num_patch, output_dim=embed_dim)
def call(self, patch):
pos = tf.range(start=0, limit=self.num_patch, delta=1)
return self.proj(patch) + self.pos_embed(pos)
def get_config(self):
config = super().get_config()
config.update(
{
"num_patch": self.num_patch,
}
)
return config
class PatchMerging(layers.Layer):
def __init__(self, num_patch, embed_dim):
super().__init__()
self.num_patch = num_patch
self.embed_dim = embed_dim
self.linear_trans = layers.Dense(2 * embed_dim, use_bias=False)
def call(self, x):
height, width = self.num_patch
_, _, C = x.get_shape().as_list()
x = tf.reshape(x, shape=(-1, height, width, C))
feat_maps = x
x0 = x[:, 0::2, 0::2, :]
x1 = x[:, 1::2, 0::2, :]
x2 = x[:, 0::2, 1::2, :]
x3 = x[:, 1::2, 1::2, :]
x = tf.concat((x0, x1, x2, x3), axis=-1)
x = tf.reshape(x, shape=(-1, (height // 2) * (width // 2), 4 * C))
return self.linear_trans(x), feat_maps
def get_config(self):
config = super().get_config()
config.update({"num_patch": self.num_patch, "embed_dim": self.embed_dim})
return config
class WindowAttention(layers.Layer):
def __init__(
self,
dim,
window_size,
num_heads,
qkv_bias=True,
dropout_rate=0.0,
return_attention_scores=False,
**kwargs
):
super().__init__(**kwargs)
self.dim = dim
self.window_size = window_size
self.num_heads = num_heads
self.scale = (dim // num_heads) ** -0.5
self.return_attention_scores = return_attention_scores
self.qkv = layers.Dense(dim * 3, use_bias=qkv_bias)
self.dropout = layers.Dropout(dropout_rate)
self.proj = layers.Dense(dim)
def build(self, input_shape):
self.relative_position_bias_table = self.add_weight(
shape=(
(2 * self.window_size[0] - 1) * (2 * self.window_size[1] - 1),
self.num_heads,
),
initializer="zeros",
trainable=True,
name="relative_position_bias_table",
)
super().build(input_shape)
def get_config(self):
config = super().get_config()
config.update(
{
"dim": self.dim,
"window_size": self.window_size,
"num_heads": self.num_heads,
"scale": self.scale,
}
)
return config
def get_relative_position_index(self, window_height, window_width):
x_x, y_y = tf.meshgrid(range(window_height), range(window_width))
coords = tf.stack([y_y, x_x], axis=0)
coords_flatten = tf.reshape(coords, [2, -1])
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]
relative_coords = tf.transpose(relative_coords, perm=[1, 2, 0])
x_x = (relative_coords[:, :, 0] + window_height - 1) * (2 * window_width - 1)
y_y = relative_coords[:, :, 1] + window_width - 1
relative_coords = tf.stack([x_x, y_y], axis=-1)
return tf.reduce_sum(relative_coords, axis=-1)
def call(self, x, mask=None):
_, size, channels = x.shape
head_dim = channels // self.num_heads
x_qkv = self.qkv(x)
x_qkv = tf.reshape(x_qkv, shape=(-1, size, 3, self.num_heads, head_dim))
x_qkv = tf.transpose(x_qkv, perm=(2, 0, 3, 1, 4))
q, k, v = x_qkv[0], x_qkv[1], x_qkv[2]
q = q * self.scale
k = tf.transpose(k, perm=(0, 1, 3, 2))
attn = q @ k
relative_position_index = self.get_relative_position_index(
self.window_size[0], self.window_size[1]
)
relative_position_bias = tf.gather(
self.relative_position_bias_table, relative_position_index, axis=0
)
relative_position_bias = tf.transpose(relative_position_bias, [2, 0, 1])
attn = attn + tf.expand_dims(relative_position_bias, axis=0)
if mask is not None:
nW = mask.get_shape()[0]
mask_float = tf.cast(
tf.expand_dims(tf.expand_dims(mask, axis=1), axis=0), tf.float32
)
attn = (
tf.reshape(attn, shape=(-1, nW, self.num_heads, size, size))
+ mask_float
)
attn = tf.reshape(attn, shape=(-1, self.num_heads, size, size))
attn = tf.nn.softmax(attn, axis=-1)
else:
attn = tf.nn.softmax(attn, axis=-1)
attn = self.dropout(attn)
x_qkv = attn @ v
x_qkv = tf.transpose(x_qkv, perm=(0, 2, 1, 3))
x_qkv = tf.reshape(x_qkv, shape=(-1, size, channels))
x_qkv = self.proj(x_qkv)
x_qkv = self.dropout(x_qkv)
if self.return_attention_scores:
return x_qkv, attn
else:
return x_qkvclass SwinTransformer(layers.Layer):
def __init__(
self,
dim,
num_patch,
num_heads,
window_size=7,
shift_size=0,
num_mlp=1024,
qkv_bias=True,
dropout_rate=0.0,
**kwargs,
):
super(SwinTransformer, self).__init__(**kwargs)
self.dim = dim
self.num_patch = num_patch
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.num_mlp = num_mlp
self.norm1 = layers.LayerNormalization(epsilon=1e-5)
self.attn = WindowAttention(
dim,
window_size=(self.window_size, self.window_size),
num_heads=num_heads,
qkv_bias=qkv_bias,
dropout_rate=dropout_rate,
)
self.drop_path = (
DropPath(dropout_rate) if dropout_rate > 0.0 else tf.identity
)
self.norm2 = layers.LayerNormalization(epsilon=1e-5)
self.mlp = keras.Sequential(
[
layers.Dense(num_mlp),
layers.Activation(keras.activations.swish),
layers.Dropout(dropout_rate),
layers.Dense(dim),
layers.Dropout(dropout_rate),
]
)
if min(self.num_patch) < self.window_size:
self.shift_size = 0
self.window_size = min(self.num_patch)
def build(self, input_shape):
if self.shift_size == 0:
self.attn_mask = None
else:
height, width = self.num_patch
h_slices = (
slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None),
)
w_slices = (
slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None),
)
mask_array = jnp.zeros((1, height, width, 1))
count = 0
for h in h_slices:
for w in w_slices:
mask_array[:, h, w, :] = count
count += 1
mask_array = tf.convert_to_tensor(mask_array)
# mask array to windows
mask_windows = window_partition(mask_array, self.window_size)
mask_windows = tf.reshape(
mask_windows, shape=[-1, self.window_size * self.window_size]
)
attn_mask = tf.expand_dims(mask_windows, axis=1) - tf.expand_dims(
mask_windows, axis=2
)
attn_mask = tf.where(attn_mask != 0, -100.0, attn_mask)
attn_mask = tf.where(attn_mask == 0, 0.0, attn_mask)
self.attn_mask = tf.Variable(initial_value=attn_mask, trainable=False)
def call(self, x):
height, width = self.num_patch
_, num_patches_before, channels = x.shape
x_skip = x
x = self.norm1(x)
x = tf.reshape(x, shape=(-1, height, width, channels))
if self.shift_size > 0:
shifted_x = tf.roll(
x, shift=[-self.shift_size, -self.shift_size], axis=[1, 2]
)
else:
shifted_x = x
x_windows = window_partition(shifted_x, self.window_size)
x_windows = tf.reshape(
x_windows, shape=(-1, self.window_size * self.window_size, channels)
)
attn_windows = self.attn(x_windows, mask=self.attn_mask)
attn_windows = tf.reshape(
attn_windows, shape=(-1, self.window_size, self.window_size, channels)
)
shifted_x = window_reverse(
attn_windows, self.window_size, height, width, channels
)
if self.shift_size > 0:
x = tf.roll(
shifted_x, shift=[self.shift_size, self.shift_size], axis=[1, 2]
)
else:
x = shifted_x
x = tf.reshape(x, shape=(-1, height * width, channels))
x = self.drop_path(x)
x = tf.cast(x_skip, dtype=tf.float32) + tf.cast(x, dtype=tf.float32)
x_skip = x
x = self.norm2(x)
x = self.mlp(x)
x = self.drop_path(x)
x = tf.cast(x_skip, dtype=tf.float32) + tf.cast(x, dtype=tf.float32)
return xfrom tensorflow import keras
IMG_SIZE = 384
growth_rate = 12
class CastLayer(layers.Layer):
def __init__(self, target_dtype, **kwargs):
super(CastLayer, self).__init__(**kwargs)
self.target_dtype = target_dtype
def call(self, inputs):
return tf.cast(inputs, dtype=self.target_dtype)
class Ensemble_Classifier(tf.keras.Model):
def __init__(self, dim, **kwargs):
super(Ensemble_Classifier, self).__init__(**kwargs)
# Defining all trainable layers in __init__ / build
self.base = tf.keras.applications.EfficientNetV2S(weights='imagenet',include_top=False, input_shape=img_shape)
self.multi_output_cnn = keras.Model(
self.base.inputs,
[self.base.get_layer("block4a_expand_activation").output,self.base.get_layer("block6a_expand_activation").output, self.base.output],
name="efficientnetV2S",
)
num_filters = self.base.output_shape[-1]
# Add DenseBlock with Dilated Convolutions at the end
self.dense_block_dilation = DenseBlockWithDilation(num_filters=num_filters, growth_rate=growth_rate)
self.dense_block_dilation1 = DenseBlockWithDilation(num_filters=num_filters, growth_rate=growth_rate)
# Keras Built-in
self.cast_layer = CastLayer(target_dtype=tf.float32)
self.batch_norm = layers.BatchNormalization()
self.batch_norm1 = layers.BatchNormalization()
self.batch_norm2 = layers.BatchNormalization()
self.attention = Attention_block()
self.attention1 = Attention_block()
# Neck
self.patch_extract = PatchExtract(patch_size)
self.patch_embedds = PatchEmbedding(num_patch_x * num_patch_y, embed_dim)
self.patch_merging = PatchMerging(
(num_patch_x, num_patch_y), embed_dim=embed_dim
)
# swin blocks containers
self.swin_sequences = keras.Sequential(name="swin_blocks")
for i in range(shift_size):
self.swin_sequences.add(
SwinTransformer(
dim=embed_dim,
num_patch=(num_patch_x, num_patch_y),
num_heads=num_heads,
window_size=window_size,
shift_size=i,
num_mlp=num_mlp,
qkv_bias=qkv_bias,
dropout_rate=dropout_rate,
)
)
# Head
#self.dense_layer = layers.Dense(1024, activation=tf.nn.relu)
self.classifier = layers.Dense(class_count, activation='softmax')
def call(self, input_tensor, training=False, **kwargs):
if training is None:
training = K.learning_phase()
# Base Inputs
base_first,base_mid, base_out = self.multi_output_cnn(input_tensor)
base_out = self.batch_norm(base_out)
# Swin Transformer
swin_tranformer = self.patch_extract(base_first)
swin_tranformer = self.patch_embedds(swin_tranformer)
swin_tranformer = self.swin_sequences(self.cast_layer(swin_tranformer))
swin_tranformer, swin_top = self.patch_merging(swin_tranformer)
dense_bd = self.dense_block_dilation(base_mid)
# Attention And Dense Modules
attn_out= self.attention(dense_bd)
attn_out = self.batch_norm1(attn_out)
attn_out1 = self.attention1(base_out)
attn_out1 = self.batch_norm2(attn_out1)
dense_bd1 = self.dense_block_dilation1(attn_out1)
# GAP And Merge
gap = tf.keras.layers.GlobalAveragePooling2D()(attn_out)
gap1 = tf.keras.layers.GlobalAveragePooling2D()(dense_bd1)
gap2 = tf.keras.layers.GlobalAveragePooling1D()(swin_tranformer)
merge = layers.Concatenate(axis=-1)([gap,gap1,gap2])
#x = self.dense_layer(merge)
#x = self.dropout(x, training=training)
x = self.classifier(merge)
if not training:
return x, base_out, swin_top, attn_out, dense_bd1
return x
# AFAIK: The most convenient method to print model.summary() in suclassed model
def build_graph(self):
x = keras.Input(shape=(IMG_SIZE, IMG_SIZE,3))
return keras.Model(inputs=[x], outputs=self.call(x))
Pingback: Revolutionizing Cardiac Care with the CACTUS Framework