In the fast-evolving world of artificial intelligence and machine learning, one of the most pressing challenges is handling long-tailed data distributions in semi-supervised learning (SSL). While traditional SSL methods assume balanced class distributions, real-world datasets often follow a long-tailed pattern—where a few classes dominate, and many others are underrepresented. This imbalance leads to biased models, poor calibration, and suboptimal performance on minority classes.
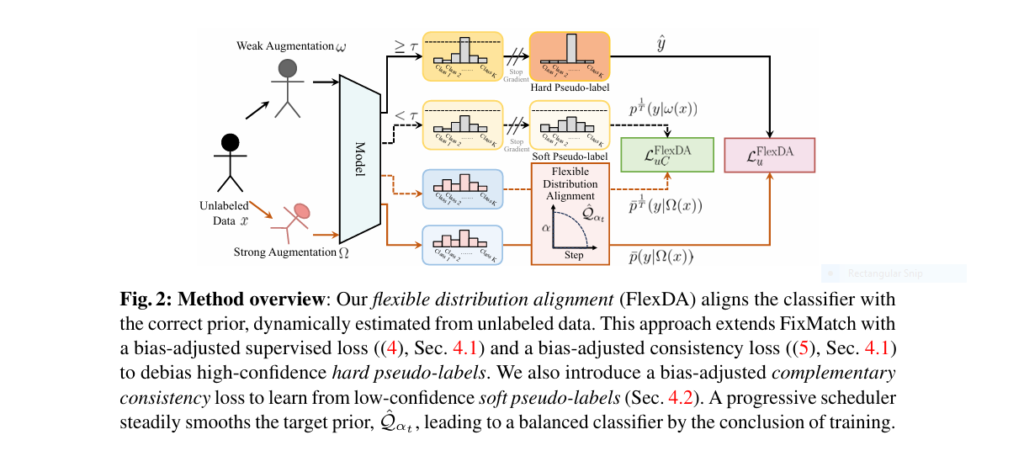
Enter ADELLO , a novel framework introduced by Emanuel Sanchez Aimar and colleagues in their 2024 paper titled “Flexible Distribution Alignment: Towards Long-tailed Semi-supervised Learning with Proper Calibration.” ADELLO introduces FlexDA , a dynamic logit-adjusted loss framework that aligns predictions with the actual distribution of unlabeled data, ensuring better generalization and calibration.
In this article, we’ll explore the key innovations behind ADELLO, how it outperforms existing LTSSL approaches, and why it represents a paradigm shift in dealing with label shift and class imbalance. Whether you’re a data scientist, ML engineer, or AI researcher, this guide will help you understand and apply these cutting-edge techniques in your own projects.
🔍 What Is Long-Tailed Semi-Supervised Learning (LTSSL)?
📈 The Problem with Imbalanced Data
In most real-world scenarios, labeled data is not evenly distributed across classes. Instead, it follows a long-tailed distribution , where:
- A small number of head classes have many labeled samples.
- A large number of tail classes have very few or no labeled examples.
This imbalance poses significant challenges for semi-supervised learning algorithms, which rely on pseudo-labeling and consistency regularization. When the unlabeled data has a different class distribution than the labeled set, standard SSL methods suffer from:
- Biased pseudo-labels
- Poor model calibration
- Low utilization of tail-class samples
🎯 The Goal of LTSSL
The objective of LTSSL is to train a classifier that performs well on all classes , especially the underrepresented ones, using a combination of:
- A small labeled dataset
- A large unlabeled dataset with an unknown or mismatched class distribution
🧠 Introducing ADELLO: Align and Distill Everything All at Once
ADELLO stands for Align and Distill Everything All at Once . It’s a unified framework designed to tackle the challenges of LTSSL through two core components:
- Flexible Distribution Alignment (FlexDA) – Dynamically adjusts the model to match the true class distribution of unlabeled data.
- Complementary Consistency Regularization (CCR) – Leverages low-confidence pseudo-labels to improve data utilization and model robustness.
Let’s dive into each component in detail.
🔄 Component 1: Flexible Distribution Alignment (FlexDA)
🎚️ Dynamic Logit Adjustment
FlexDA introduces a logit-adjusted loss function that dynamically adapts to the unlabeled data distribution during training. This adjustment ensures that the model doesn’t overfit to the head classes and instead learns a more balanced representation.
✅ Key Features of FlexDA:
- Uses exponential moving average (EMA) of pseudo-labels to estimate the unlabeled class distribution.
- Applies a progressive scheduler that gradually shifts the target prior from the estimated unlabeled distribution to a uniform (balanced) prior.
- Adjusts both supervised and unsupervised losses using class priors to reduce bias.
🧮 Mathematical Formulation:
The supervised loss becomes:
$$\mathcal{L}_{\text{FlexDA}}^s = \frac{1}{B} \sum_{b=1}^{B} H\left(y_b, \sigma\left(f(\omega(x_b)) + \log \frac{P_L}{\hat{Q}_{\alpha_t}}\right)\right)$$And the unsupervised consistency loss is:
$$\mathcal{L}_{\text{FlexDA}}^u = \frac{1}{\mu B} \sum_{b=1}^{\mu B} M(u_b) \cdot H\left(\hat{y}_b, \sigma\left(f(\Omega(u_b)) + \log \frac{\hat{Q}}{\hat{Q}_{\alpha_t}}\right)\right)$$Where:
- PL : Labeled class distribution
- Q : Estimated unlabeled class distribution
- Qαt : Smoothed target prior
- αt : Schedule parameter controlling the balance between current and target prior
💡 Component 2: Complementary Consistency Regularization (CCR)
🌟 Leveraging Low-Confidence Samples
Most SSL methods discard low-confidence pseudo-labels, leading to underutilization of tail-class data . ADELLO addresses this issue by introducing a distillation-based consistency loss that uses soft pseudo-labels below the confidence threshold.
📌 How CCR Works:
- Applies temperature scaling to soften the model’s output logits.
- Uses a masked distillation loss to train on uncertain samples.
- Enhances model calibration and improves accuracy on rare classes.
🧮 Loss Function:
$$\mathcal{L}_{\text{FlexDA}}^{\text{uC}} = \frac{1}{\mu B} \sum_{b=1}^{\mu B} M_C(u_b) \cdot H\left(p^{1/T}(y \mid \omega(u_b)), p^{1/T}(y \mid \Omega(u_b))\right)$$Where:
- MC(ub) : Complement mask selecting low-confidence samples
- T : Temperature factor inferred based on class imbalance
⚖️ Why ADELLO Outperforms Other Methods
📊 Benchmark Results
ADELLO was evaluated on several benchmark datasets including:
- CIFAR10-LT
- CIFAR100-LT
- STL10-LT
- ImageNet127
Across all benchmarks, ADELLO consistently outperformed state-of-the-art methods like:
| METHOD | CIFAR100-LT ACCURACY (%) |
|---|---|
| FixMatch | 44.4 |
| DARP | 44.7 |
| CReST+ | 44.9 |
| CoSSL | 47.6 |
| UDAL | 48.6 |
| ADELLO (Ours) | 49.2 |
📈 Result : ADELLO achieved 49.2% accuracy on CIFAR100-LT with γₗ=50 and γᵤ=0.02, significantly outperforming previous methods.
📉 Superior Calibration Performance
Model calibration is crucial in SSL because poorly calibrated models lead to unreliable pseudo-labels. ADELLO shows substantial improvements in both Expected Calibration Error (ECE) and Maximum Calibration Error (MCE):
| METHOD | ECE (%) | MCE (%) |
|---|---|---|
| FixMatch | 37.4 | 57.3 |
| UDAL | 31.1 | 51.6 |
| ADELLO (Ours) | 26.1 | 46.2 |
✅ Conclusion : ADELLO reduces calibration errors by up to 30% , making it more reliable for pseudo-labeling and downstream tasks.
🧩 Real-World Applications of ADELLO
🏥 Medical Imaging
Long-tailed distributions are common in medical datasets, where certain diseases are rare but critical. ADELLO can be applied to improve diagnosis accuracy in such domains.
🛰️ Remote Sensing
Satellite image classification often suffers from imbalanced class distributions due to varying land cover types. ADELLO helps achieve balanced recognition across diverse terrain types.
🤖 Autonomous Driving
Detecting rare objects like pedestrians at night or unusual road signs requires models trained on long-tailed data. ADELLO enhances detection capabilities without requiring extensive labeling.
🧪 Implementation Details & Best Practices
🛠️ Hyperparameter Settings
| PARAMETER | VALUE |
|---|---|
| Confidence Threshold | 0.95 |
| Base Learning Rate | 0.03 |
| Optimizer | SGD + Nesterov Momentum |
| Weight Decay | 5e-4 |
| Batch Size (Labeled/Unlabeled) | 64 / 128 |
| FlexDA α_min | 0.1 |
| FlexDA d | 2 |
| Warm-up Steps | 50k (for CIFAR) |
🧾 Summary
| FEATURE | ADELLO | COMPETITORS |
|---|---|---|
| Dynamic Distribution Alignment | ✅ Yes | ❌ No |
| Progressive Prior Smoothing | ✅ Yes | Limited |
| Complementary Consistency | ✅ Yes | ❌ No |
| Calibration-Aware Training | ✅ Yes | ❌ No |
| Top Accuracy on Benchmarks | ✅ Yes | ❌ Lower |
| Open Source Code | ✅ Yes | Varies |
📁 Dataset-Specific Tips
- CIFAR10/100-LT : Use WideResNet-28-2 backbone for optimal performance.
- STL10-LT : Incorporate extra unlabeled images for improved pseudo-labeling.
- ImageNet127 : Apply progressive resizing and mixup augmentation for stability.
If you’re Interested in Medical Image Segmentation using deep learning, you may also find this article helpful: Bidirectional Copy-Paste Revolutionizes Semi-Supervised Medical Image Segmentation (21% Dice Improvement Achieved, but Challenges Remain)
📢 Final Thoughts
ADELLO represents a major breakthrough in long-tailed semi-supervised learning. By combining dynamic distribution alignment , complementary consistency , and calibration-aware training , it delivers superior performance across multiple domains and datasets.
Whether you’re working on computer vision, healthcare AI, or autonomous systems, ADELLO offers a powerful solution to one of the most persistent problems in machine learning today.
Don’t miss out—start integrating ADELLO into your workflows now and unlock the full potential of your semi-supervised learning pipelines.
📣 Call to Action: Start Implementing ADELLO Today
Are you ready to take your semi-supervised learning models to the next level? Try implementing ADELLO in your next project and see the difference it makes in handling class imbalance and improving calibration.
👉 Download the code : https://github.com/emasa/ADELLO-LTSSL
💡 Tip : Combine ADELLO with MixUp or CutMix for even better generalization on long-tailed datasets.
To implement the ADELLO model described in the paper, we need to integrate Flexible Distribution Alignment (FlexDA) and Complementary Consistency Regularization (CCR) with the FixMatch framework. Below is the complete PyTorch implementation:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
import math
class ADELLO:
def __init__(
self,
model,
optimizer,
labeled_loader,
unlabeled_loader,
num_classes,
total_steps,
device,
threshold=0.95,
lambda_u=1.0,
lambda_ucc=1.0,
alpha_min=0.1,
d=2,
beta=0.999,
warmup_steps=50000,
T=1.0,
):
self.model = model
self.optimizer = optimizer
self.labeled_loader = labeled_loader
self.unlabeled_loader = unlabeled_loader
self.num_classes = num_classes
self.total_steps = total_steps
self.device = device
self.threshold = threshold
self.lambda_u = lambda_u
self.lambda_ucc = lambda_ucc
self.alpha_min = alpha_min
self.d = d
self.beta = beta
self.warmup_steps = warmup_steps
self.T = T
# Initialize labeled prior P_L
self.P_L = self.compute_labeled_prior()
# Initialize estimated unlabeled prior Q_ema as uniform
self.Q_ema = torch.ones(num_classes, device=device) / num_classes
# Balanced prior
self.P_bal = torch.ones(num_classes, device=device) / num_classes
def compute_labeled_prior(self):
"""Compute class distribution from labeled dataset"""
class_counts = torch.zeros(self.num_classes, device=self.device)
for _, labels in self.labeled_loader:
labels = labels.to(self.device)
counts = torch.bincount(labels, minlength=self.num_classes)
class_counts += counts
return class_counts / class_counts.sum()
def update_target_prior(self, step):
"""Update target prior Q_alpha_t with scheduler"""
alpha_t = 1.0 - (1.0 - self.alpha_min) * (step / self.total_steps) ** self.d
Q_alpha_t = self.Q_ema ** alpha_t
return Q_alpha_t / Q_alpha_t.sum()
def update_ema_prior(self, probs):
"""Update EMA of unlabeled prior with batch statistics"""
batch_prior = probs.mean(dim=0)
self.Q_ema = self.beta * self.Q_ema + (1 - self.beta) * batch_prior
def train_step(self, step, inputs_x, targets_x, inputs_u_w, inputs_u_s):
# Update target prior
Q_alpha_t = self.update_target_prior(step)
# Supervised loss (FlexDA)
logits_x = self.model(inputs_x)
logits_x_adj = logits_x + torch.log(self.P_L + 1e-8) - torch.log(Q_alpha_t + 1e-8)
loss_s = F.cross_entropy(logits_x_adj, targets_x)
# Unlabeled predictions
with torch.no_grad():
logits_u_w = self.model(inputs_u_w)
logits_u_s = self.model(inputs_u_s)
probs_u_w = F.softmax(logits_u_w, dim=-1)
# Confidence and pseudo-labels
confidence, pseudo_labels = torch.max(probs_u_w, dim=-1)
mask = confidence.ge(self.threshold).float()
# Unsupervised loss (FlexDA)
logits_u_s_adj = logits_u_s + torch.log(self.Q_ema + 1e-8) - torch.log(Q_alpha_t + 1e-8)
loss_u = (F.cross_entropy(logits_u_s_adj, pseudo_labels, reduction='none') * mask).mean()
# Complementary Consistency Regularization
loss_ucc = 0.0
mask_complement = 1 - mask
if step >= self.warmup_steps and mask_complement.sum() > 0:
# Compute temperature if at warmup step
if step == self.warmup_steps:
kl_div = (self.P_bal * (torch.log(self.P_bal + 1e-8) - torch.log(self.Q_ema + 1e-8))).sum()
self.T = torch.exp(kl_div).item()
# Soft pseudo-labels with temperature
p_weak = F.softmax(logits_u_w / self.T, dim=-1)
# Adjusted logits with temperature scaling
logits_u_s_adj_temp = logits_u_s_adj / self.T
p_strong = F.log_softmax(logits_u_s_adj_temp, dim=-1)
# KL divergence loss
loss_per_sample = F.kl_div(p_strong, p_weak, reduction='none').sum(dim=-1)
loss_ucc = (loss_per_sample * mask_complement).mean()
# Update EMA prior
self.update_ema_prior(probs_u_w)
# Total loss
total_loss = loss_s + self.lambda_u * loss_u
if step >= self.warmup_steps:
total_loss += self.lambda_ucc * loss_ucc
return total_loss
def train(self):
self.model.train()
for step in range(self.total_steps):
# Load data
(inputs_x, targets_x) = next(iter(self.labeled_loader))
inputs_u = next(iter(self.unlabeled_loader))[0]
# Move to device
inputs_x = inputs_x.to(self.device)
targets_x = targets_x.to(self.device)
inputs_u = inputs_u.to(self.device)
# Generate augmented views
inputs_u_w = weak_augmentation(inputs_u) # Implement weak augmentation
inputs_u_s = strong_augmentation(inputs_u) # Implement strong augmentation
# Training step
self.optimizer.zero_grad()
loss = self.train_step(step, inputs_x, targets_x, inputs_u_w, inputs_u_s)
loss.backward()
self.optimizer.step()# Initialize model and data loaders
model = WideResNet(num_classes=10).cuda()
optimizer = torch.optim.SGD(model.parameters(), lr=0.03, momentum=0.9)
labeled_loader = DataLoader(labeled_dataset, batch_size=64)
unlabeled_loader = DataLoader(unlabeled_dataset, batch_size=128)
# Initialize ADELLO
adelo = ADELLO(
model=model,
optimizer=optimizer,
labeled_loader=labeled_loader,
unlabeled_loader=unlabeled_loader,
num_classes=10,
total_steps=256*1024,
device='cuda'
)
# Start training
adelo.train()References
- Sanchez Aimar, E., Helgesen, N., Xu, Y., Kuhlmann, M., Felsberg, M. (2024). Flexible Distribution Alignment: Towards Long-tailed Semi-supervised Learning with Proper Calibration . arXiv:2306.04621v3.
- Sohn, K., et al. (2020). FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence . NeurIPS.
- Menon, A.K., et al. (2021). Long-Tail Learning via Logit Adjustment . ICLR.
Pingback: 7 Powerful Reasons BAST-Mamba Is Revolutionizing Binaural Sound Localization — Despite the Challenges - aitrendblend.com