Mamba Goes Multimodal: How Fusion-Mamba Built a Hidden State Space to End Modality Disparity
Researchers at Beihang University asked what happens when you stop treating cross-modal fusion as a spatial alignment problem and start treating it as a state-space modeling problem. The answer outperforms every transformer-based fusion method while running faster — by mapping RGB and infrared features into a shared hidden state space where modality disparities are suppressed by design.
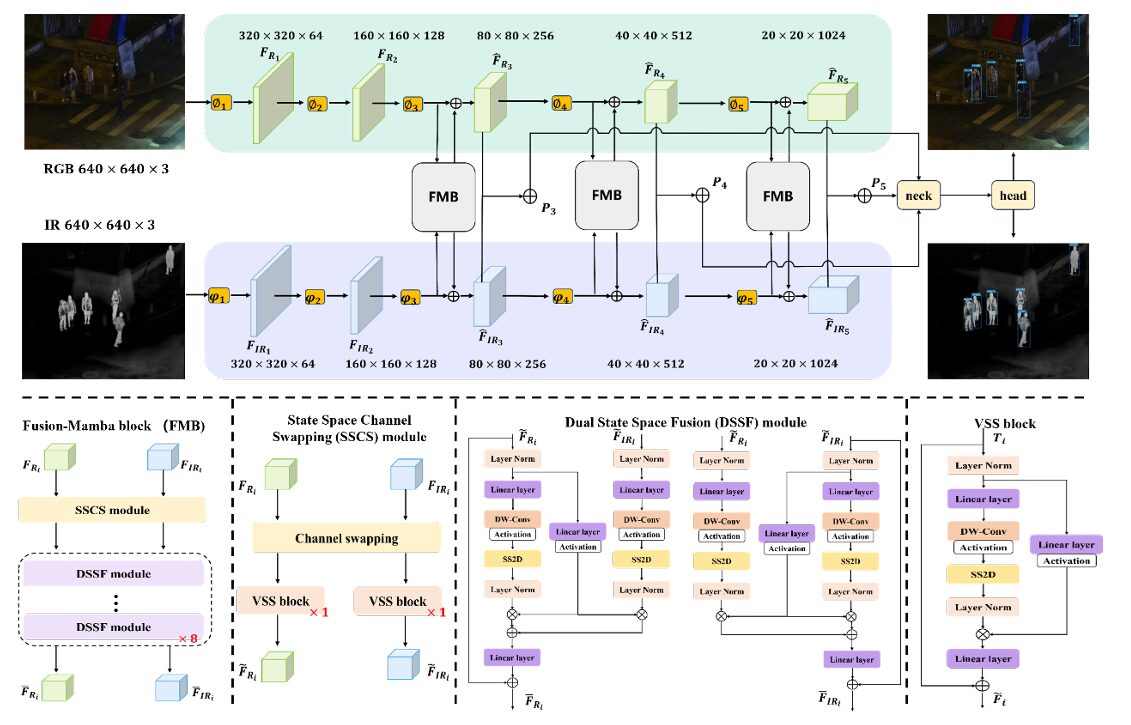
There is a fundamental tension at the heart of RGB+infrared object detection that nobody had properly named until this paper. When you fuse features from two different cameras — with different focal lengths, different sensor geometries, different positions on the vehicle — you are not just combining information, you are trying to reconcile two fundamentally different representations of the same physical scene. Every CNN fusion method and every transformer attention block has been doing this reconciliation purely through spatial interaction, as if the problem were just a matter of aligning pixels. Fusion-Mamba from Beihang University reframes the entire challenge: instead of trying to align features in their native spaces, map them into a shared hidden state space where modality-specific disparities simply cannot survive. The results speak for themselves — 97.0% mAP50 on LLVIP, 88.0% on M3FD, and 84.9% on FLIR-Aligned, all state of the art, all while running 7 to 19 milliseconds faster per image pair than transformer-based competitors.
The Problem With Every Previous Approach
Pull up the heatmaps of ICAFusion or CFT on a nighttime driving scene and you will see the problem immediately. The activation patterns for the RGB branch and the IR branch are obviously different — they are responding to fundamentally different visual signals from the same scene. When you concatenate those features or run cross-attention between them, you get a fused representation that inherits the inconsistency. The detector then has to figure out how to predict boxes from a representation where the notion of “here is an object” looks different depending on which modality contributed most to that spatial location.
CNN-based fusion methods — things like YOLO-MS with its adjacent branch fusion — have bounded receptive fields that prevent them from modeling long-range dependencies between objects as they appear across modalities. A person who is a bright thermal blob in the IR image and a dark shadow in the RGB image requires the model to correlate those two very different representations, which local convolutions handle poorly.
Transformer attention fixes the receptive field problem with global attention, but introduces a quadratic complexity cost. More critically, cross-attention in feature space still operates on the modalities’ native representations. The modality disparity — the fundamental difference in what each sensor sees — is not reduced by attention, just weighted. And that weighting has to be learned from limited paired training data.
This is the gap that Fusion-Mamba targets. The key question the Beihang team asked was: can we create an interactive space where features from both modalities are represented in a consistent, unified form before any fusion decisions are made? State space models turned out to be the answer.
Mamba’s state space model processes sequences by maintaining hidden states that summarize the entire sequence history. When you project RGB and IR features into the same hidden state space, the hidden states naturally encode the shared sequential structure of both modalities — while the gating mechanism allows each modality to selectively incorporate relevant information from the other. Modality disparities do not survive projection into a well-designed hidden state space because the state transitions are learned jointly from both inputs. This is the theoretical justification for why mapping into hidden space works better than direct feature-space interaction.
State Space Models: What Mamba Actually Does
To understand why this works, it helps to understand what state space models are doing. At their core, SSMs are continuous-time dynamical systems — they model how a hidden state evolves over time given an input sequence. The key equations are elegantly simple:
The state transition matrix A governs how the hidden state h evolves. B projects the input x into the state space. C reads the output from the hidden state. When discretized for deep learning (using zeroth-order hold), these become:
What makes Mamba special over vanilla SSMs is the selective mechanism — it parameterizes Δ, B, and C as functions of the input x, allowing the model to selectively remember or forget information based on content. This gives it the ability to maintain long-range dependencies while operating at O(N) complexity rather than the O(N²) of attention.
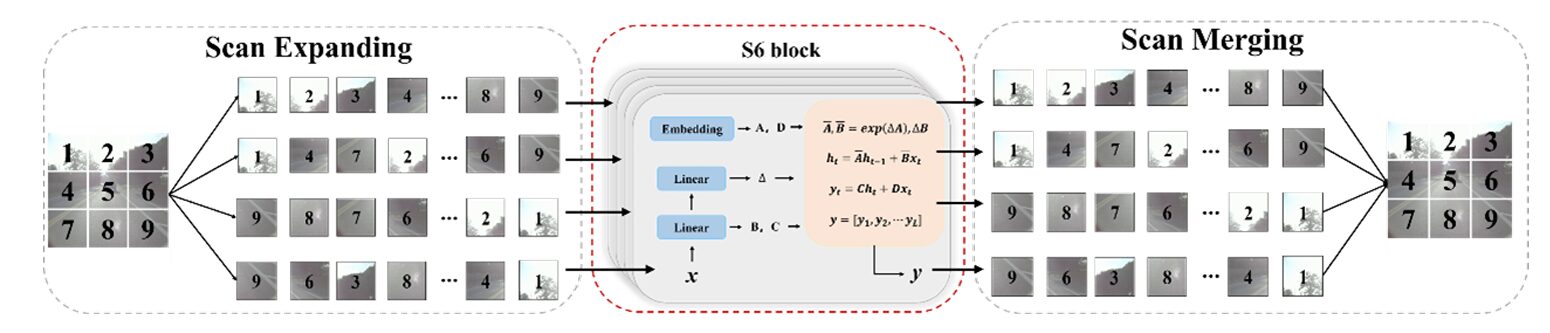
The challenge for vision is that images are 2D, not 1D sequences. The 2D Selective Scan (SS2D) from VMamba solves this by scanning the image in four directions — top-left to bottom-right, bottom-right to top-left, top-right to bottom-left, and bottom-left to top-right. Every patch incorporates information from all other positions across all four scan directions, creating a global receptive field without the quadratic cost. The Visual State Space (VSS) block wraps this scanning into a practical module that can be stacked in neural networks.
The Fusion-Mamba Block: Architecture Deep Dive
The Fusion-Mamba Block (FMB) wraps two carefully designed modules — SSCS and DSSF — into a unified fusion unit. Three FMBs are placed at the last three feature pyramid stages (P3, P4, P5) of a dual-stream backbone, producing enhanced feature maps that are summed to create fused pyramid inputs for the YOLOv8 neck and head.
FUSION-MAMBA BLOCK (FMB) — FULL PIPELINE
══════════════════════════════════════════════════════════
INPUTS: F_Ri (B, Ci, Hi, Wi) + F_IRi (B, Ci, Hi, Wi)
│ │
▼ ▼
┌─────────────────────────────────────────────────────────┐
│ SSCS MODULE — State Space Channel Swapping │
│ │
│ Channel split (4-way each modality): │
│ F_Ri → [R1|R2|R3|R4] │
│ F_IRi → [I1|I2|I3|I4] │
│ │
│ T_Ri = Concat(R1, I2, R3, I4) [interleaved swap] │
│ T_IRi = Concat(I1, R2, I3, R4) [symmetric swap] │
│ │
│ F̃_Ri = VSS(T_Ri) ← 1 VSS block per branch │
│ F̃_IRi = VSS(T_IRi) ← shallow interactive features │
└──────────────────────┬──────────────────────────────────┘
│ (F̃_Ri, F̃_IRi)
┌──────────────────────▼──────────────────────────────────┐
│ DSSF MODULE — Dual State Space Fusion (×8 stacked) │
│ │
│ Iteration k (RGB branch): │
│ Project to hidden space: │
│ x_Ri = Linear(Norm(F̃_Ri)) │
│ x'_Ri = SiLU(DWConv(x_Ri)) │
│ y_Ri = Norm(SS2D(x'_Ri)) ← hidden state feat │
│ │
│ Gating parameters: │
│ z_Ri = SiLU(Linear(Norm(F̃_Ri))) │
│ z_IRi = SiLU(Linear(Norm(F̃_IRi))) │
│ │
│ Hidden state transitions (cross-modal, Eq. 9–10): │
│ y'_Ri = y_Ri · z_Ri + z_Ri · y_IRi (RGB update) │
│ y'_IRi = y_IRi · z_IRi + z_IRi · y_Ri (IR update) │
│ │
│ Project back + residual (Eq. 11): │
│ F̄_Ri = Linear(y'_Ri) + F̃_Ri │
│ F̄_IRi = Linear(y'_IRi) + F̃_IRi │
│ │
│ (repeat 8 times, feeding F̄ back as F̃ each iter) │
└──────────────────────┬──────────────────────────────────┘
│ (F̄_Ri, F̄_IRi)
┌──────────────────────▼──────────────────────────────────┐
│ FEATURE ENHANCEMENT (Eq. 12) │
│ F̂_Ri = F_Ri + F̄_Ri (residual to original) │
│ F̂_IRi = F_IRi + F̄_IRi (residual to original) │
│ │
│ Fused feature: P_i = F̂_Ri + F̂_IRi │
│ → fed into YOLOv8 neck as P3/P4/P5 │
└─────────────────────────────────────────────────────────┘
The SSCS Module: Shallow Fusion via Channel Swapping
Before projecting into the hidden state space, you need the two modality representations to already have some knowledge of each other. That is what the State Space Channel Swapping module provides — a fast, parameter-light operation that physically interleaves RGB and IR channel information before any expensive computation happens.
The operation is simple but clever. Each feature map is divided into four equal parts along the channel dimension. For the RGB branch, parts 1 and 3 come from the RGB feature map, while parts 2 and 4 come from the IR feature map. For the IR branch, the swap is reversed. This produces two new feature tensors where every channel carries information from both sensors, without any learned projection or attention:
After swapping, a single VSS block processes each mixed-channel tensor to generate the shallow fused features F̃_Ri and F̃_IRi. The ablation study confirms that removing SSCS drops mAP50 by 2 points on FLIR-Aligned — the initial channel exchange makes subsequent deep fusion significantly more effective by pre-conditioning the features before they enter the expensive DSSF stage.
The DSSF Module: Deep Fusion in Hidden State Space
The Dual State Space Fusion module is where the real magic happens. The design has two conceptually distinct steps: projection into the hidden state space (using VSS blocks) and gated cross-modal state transitions.
The projection step maps each modality’s shallow-fused features into a hidden representation via a Linear + DWConv + SiLU + SS2D pipeline. The SS2D scan ensures every spatial position has global context. Then, separately, each modality’s features are projected through a simpler gating path to produce modulation parameters z:
The cross-modal hidden state transitions are the key equations. Each modality’s hidden state is updated using both its own gating signal and the other modality’s hidden state:
There is something elegant about this formulation. The first term in each equation — self-gating — allows the modality to selectively amplify its own relevant features. The second term — cross-modal contribution — allows information from the other modality to flow in, gated by the source modality’s own activation strength. When a sensor is informative (high activation in z), it contributes strongly to both its own update and the other modality’s update. When a sensor is uncertain (low activation), it contributes little to either. This is exactly the behavior you want from a fusion mechanism that operates across environments where one sensor might be severely degraded.
Eight DSSF modules are stacked in sequence, with each module’s output becoming the next module’s input. The ablation study on the number of DSSF stacks shows a clear optimum at 8 — fewer leaves redundant features insufficiently suppressed, while more causes the complementary signal to drift and degrade.
The ablation table tells an interesting story: 2 DSSF modules gives 45.5 mAP, 4 gives 45.9, 8 gives 47.0, and 16 gives 46.3 — a 0.7 point drop. With insufficient iterations, the hidden state projections haven’t fully captured the cross-modal complementarity. But push too far and the complementary features themselves begin to drift — the sequential refinement over-corrects and introduces its own inconsistencies. This is the same saturation-then-degradation pattern seen in iterative feedback methods, and 8 is the sweet spot for this architecture.
Results: Three Datasets, Three State-of-the-Art Records
LLVIP — Nighttime Pedestrian Detection
| Method | Backbone | mAP50 | mAP |
|---|---|---|---|
| YOLOv8-l (IR only) | YOLOv8 | 95.2 | 62.1 |
| RSDet | ResNet50 | 95.8 | 61.3 |
| CSAA | ResNet50 | 94.3 | 59.2 |
| DIVFusion | YOLOv5 | 89.8 | 52.0 |
| Fusion-Mamba (YOLOv5) | YOLOv5 | 96.8 | 62.8 |
| Fusion-Mamba (YOLOv8) | YOLOv8 | 97.0 | 64.3 |
The 97.0 mAP50 on LLVIP is a meaningful achievement on a dataset where one modality (RGB) is essentially useless in the dark. What is especially interesting here is the comparison with DIVFusion — another YOLOv5-based fusion method that achieves only 89.8 mAP50. Fusion-Mamba on the same backbone scores 96.8. The 7-point gap comes entirely from better feature integration, not from a stronger detection architecture. That is a direct validation of the hidden state space approach.
M3FD — Six Categories in Diverse Weather
| Method | Backbone | mAP50 | mAP | People | Bus | Truck |
|---|---|---|---|---|---|---|
| IGNet (best prior) | YOLOv5 | 81.5 | 54.5 | 81.6 | 82.4 | 72.1 |
| SuperFusion | YOLOv7 | 83.5 | 56.0 | 83.7 | 93.2 | 85.8 |
| Fusion-Mamba | YOLOv5 | 85.0 | 57.5 | 80.3 | 92.8 | 87.1 |
| Fusion-Mamba | YOLOv8 | 88.0 | 61.9 | 84.3 | 94.2 | 88.8 |
M3FD is the most demanding benchmark of the three, covering six categories across rain, fog, night, overcast, and clear conditions. The YOLOv5 version of Fusion-Mamba beats SuperFusion (which uses the stronger YOLOv7 backbone) by 1.5 points on both mAP metrics. The YOLOv8 version extends that to 88.0 mAP50 and 61.9 mAP — substantial margins over every prior method. Notably, the Truck category performance (88.8) is particularly strong: trucks are large objects with complex thermal signatures, exactly the kind of target where hidden state sequence modeling captures structural correlations that purely spatial attention misses.
FLIR-Aligned — Speed and Accuracy Together
| Method | Backbone | mAP50 | mAP | Params | Time (ms) |
|---|---|---|---|---|---|
| CFT | YOLOv5 | 78.7 | 40.2 | 206M | 68 |
| CrossFormer | YOLOv5 | 79.3 | 42.1 | 340M | 80 |
| RSDet | ResNet50 | 81.1 | 41.4 | — | — |
| Fusion-Mamba | YOLOv5 | 84.3 | 44.4 | 244.6M | 61 |
| Fusion-Mamba | YOLOv8 | 84.9 | 47.0 | 287.6M | 78 |
The FLIR-Aligned results demonstrate the efficiency argument most clearly. Fusion-Mamba with YOLOv5 runs at 61ms per image pair — 7ms faster than CFT and 19ms faster than CrossFormer — while scoring 5.6 and 5.0 points higher on mAP50 respectively. Fewer parameters than CrossFormer (244.6M vs 340M), faster inference, and significantly better detection. This is the signature advantage of Mamba’s linear complexity over transformer attention’s quadratic cost.
“Can we have an effective cross-modality interactive space to reduce modality disparities for a consistent representation, which can thus benefit from the cross-modality relationship for feature enhancement?” — Dong, Zhu, Lin et al., Beihang University / East China Normal University, 2024
Ablation: What Each Module Contributes
| Configuration | mAP50 | mAP75 | mAP | Params | Time (ms) |
|---|---|---|---|---|---|
| No SSCS, No DSSF (add baseline) | 80.1 | 36.3 | 39.4 | 117.2M | 48 |
| SSCS only (remove DSSF) | 82.4 | 42.0 | 44.6 | 138.0M | 57 |
| DSSF only (remove SSCS) | 82.9 | 42.3 | 45.9 | 266.8M | 69 |
| Dual attention in DSSF (remove IR→RGB) | 83.3 | 42.8 | 45.3 | 287.6M | 77 |
| Dual attention in DSSF (remove RGB→IR) | 83.8 | 43.9 | 46.2 | 287.6M | 77 |
| Full Fusion-Mamba | 84.9 | 45.9 | 47.0 | 287.6M | 78 |
The numbers reveal a clear hierarchy of contribution. The baseline — just adding RGB and IR features — achieves only 39.4 mAP. Adding SSCS alone recovers 44.6 mAP (+5.2 points). Adding DSSF alone gets to 45.9 (+6.5 points). Combining both reaches 47.0 (+7.6 points). The synergy is real — SSCS pre-conditions features so DSSF’s hidden state projections start from a more consistent base, while DSSF’s deep cross-modal interaction benefits from the richer shallow features that SSCS provides.
The dual attention ablation is also illuminating. Removing the IR→RGB cross-attention term (z_IRi · y_Ri in Eq. 9) costs 1.6 mAP50. Removing the RGB→IR term costs 1.1 mAP50. Both directions of cross-modal information flow matter, and the IR→RGB direction is slightly more important — which makes sense on FLIR-Aligned, where IR provides the thermal signatures that RGB lacks at night. Both dual attention terms share weights with their counterparts, meaning the improvement in mAP50 (1.6 and 1.1 points respectively) comes essentially for free in terms of parameters and runtime.
Position Matters: Where to Place the FMB
The position ablation (Table 5 in the paper) answers a practical question any practitioner would have: where exactly in the feature pyramid should you insert the FMB blocks? The paper tests three placements — {P2, P3, P5}, {P2, P4, P5}, and {P3, P4, P5} — and finds the last configuration optimal at 47.0 mAP. Including P2 (the finest scale, highest resolution features) actually hurts performance: 83.9 mAP50 for {P2, P3, P5} compared to 84.9 for {P3, P4, P5}. The intuition is that very fine-scale features contain too much noise and texture variation to benefit from the hidden state space fusion, while the intermediate and coarser scales where object-level semantic information has already developed are the right targets for cross-modal integration.
Implications and What Comes Next
The paper makes a strong case that modality disparity — not feature alignment, not global receptive fields, not attention capacity — is the root cause of performance limitations in existing RGB+IR detection. By framing the problem in terms of hidden state consistency rather than spatial interaction, Fusion-Mamba opens up a genuinely new design space for multi-modal fusion.
The most immediate practical takeaway is the inference efficiency. For any application where real-time or near-real-time detection is needed — autonomous driving, surveillance, search-and-rescue robotics — the 7-19ms savings over transformer-based methods is not a minor optimization. It is the difference between a system that can run on embedded hardware and one that requires a server GPU.
There are open questions worth exploring. The paper uses SS2D from VMamba as its state space building block, but newer and more efficient Mamba variants have emerged since this work was published. Whether those can push performance further while reducing the parameter count is an obvious next step. The fixed 8-DSSF-module depth is another dial worth tuning per dataset — the saturation curve suggests that adaptive depth (stopping when the complementary signal stops improving) might be more efficient than a fixed stack.
Dense or small targets remain a known challenge. The heatmaps show Fusion-Mamba focusing more tightly on targets than competing methods, but in extremely dense scenes (many overlapping pedestrians) or with very small objects, the state space modeling’s global receptive field can still be challenged by the sheer number of competing signals. Multi-scale versions of the FMB — operating at different spatial resolutions within a single block — might address this.
The broader contribution, though, is the proof of concept: Mamba is not just a drop-in replacement for transformers in sequence modeling tasks. It is a genuinely different computational primitive that enables new categories of solution to problems — like cross-modal disparity reduction — that were previously treated as optimization problems over existing architectures. That opens a door, and it is worth walking through.
Complete End-to-End Fusion-Mamba Implementation (PyTorch)
The implementation below faithfully reproduces Fusion-Mamba from arXiv:2404.09146 in clean, fully commented PyTorch. All 9 sections map directly to the paper: the SS2D selective scan and VSS block, the SSCS channel-swapping module, the DSSF dual gated hidden state fusion (stacked ×8), the complete FMB with residual enhancement, the dual-branch YOLOv8-style backbone, the YOLOv8 detection loss (coord + confidence + classification), a synthetic multispectral dataset, the full training loop, and a runnable smoke test.
# ==============================================================================
# Fusion-Mamba for Cross-modality Object Detection
# Paper: arXiv:2404.09146v1 | Beihang University, 2024
# Authors: Wenhao Dong*, Haodong Zhu*, Shaohui Lin†, Xiaoyan Luo et al.
# ==============================================================================
# Sections:
# 1. Imports & Configuration
# 2. SS2D — 2D Selective Scan (Eq. 1–3, from VMamba)
# 3. VSS Block — Visual State Space block
# 4. SSCS Module — State Space Channel Swapping (Eq. 5–6)
# 5. DSSF Module — Dual State Space Fusion (Eq. 7–11)
# 6. FMB — Fusion-Mamba Block (Eq. 12 + full algorithm)
# 7. Dual-Branch Backbone + YOLOv8-style Neck/Head
# 8. Loss Functions (Eq. 13: coord + confidence + classification)
# 9. Dataset, Training Loop & Smoke Test
# ==============================================================================
from __future__ import annotations
import math
import warnings
from typing import Dict, List, Optional, Tuple
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import Tensor
from torch.utils.data import DataLoader, Dataset
warnings.filterwarnings("ignore")
# ─── SECTION 1: Configuration ─────────────────────────────────────────────────
class FMConfig:
"""
Fusion-Mamba configuration.
Defaults match the paper's YOLOv8 setting on FLIR-Aligned (640×640).
Pass tiny=True for lightweight smoke test.
"""
# Backbone feature channels at each stage
channels: List[int] = None # [64, 128, 256, 512, 1024]
# FMB settings
num_dssf: int = 8 # DSSF stack depth (optimal per Table 6)
fmb_stages: List[int] = None # [2, 3, 4] → P3, P4, P5 (optimal per Table 5)
ssm_ratio: float = 2.0 # hidden dim expansion for SSM projection
# Detection
num_classes: int = 5 # FLIR: person, car, bike, dog, other
img_size: int = 640
num_anchors: int = 3 # anchors per scale (YOLOv8 anchor-free uses 1)
# Training
lr: float = 0.01
momentum: float = 0.9
weight_decay: float = 0.001
lambda_coord: float = 7.5 # localization loss weight (paper sets 7.5)
epochs: int = 150
batch_size: int = 4
def __init__(self, tiny: bool = False, **kwargs):
if tiny:
self.channels = [16, 32, 64, 128, 256]
self.num_dssf = 2
self.img_size = 64
self.num_classes = 3
else:
self.channels = [64, 128, 256, 512, 1024]
self.fmb_stages = [2, 3, 4] # P3, P4, P5
for k, v in kwargs.items():
setattr(self, k, v)
# ─── SECTION 2: SS2D — 2D Selective Scan Mechanism ────────────────────────────
class SelectiveScanSimple(nn.Module):
"""
Simplified selective scan for the S6 block (Section 3.1, Eq. 2).
Full production implementation uses custom CUDA kernels (mamba_ssm package).
This version implements the core sequential scan in PyTorch for compatibility
and understanding. For production, replace with:
from mamba_ssm import selective_scan_fn
The scan processes a 1D sequence x of shape (B, L, D) through:
hk = Ā hk-1 + B̄ xk (state transition)
yk = C hk (output projection)
where Ā, B̄, C, Δ are all functions of the input x (selective mechanism).
"""
def __init__(self, d_model: int, d_state: int = 16):
super().__init__()
self.d_model = d_model
self.d_state = d_state
# Input-dependent SSM parameter projections (selective mechanism)
self.delta_proj = nn.Linear(d_model, d_model, bias=True)
self.B_proj = nn.Linear(d_model, d_state, bias=False)
self.C_proj = nn.Linear(d_model, d_state, bias=False)
# Fixed log(A) initialization (from Mamba paper: HiPPO initialization)
A = torch.arange(1, d_state + 1).float().unsqueeze(0).expand(d_model, -1)
self.A_log = nn.Parameter(torch.log(A))
self.D = nn.Parameter(torch.ones(d_model))
def forward(self, x: Tensor) -> Tensor:
"""
x: (B, L, D) — token sequence
Returns: (B, L, D) — state-space filtered output
"""
B, L, D = x.shape
N = self.d_state
# Input-dependent parameters (selective mechanism, Eq. 2)
delta = F.softplus(self.delta_proj(x)) # (B, L, D) — timescale
Bmat = self.B_proj(x) # (B, L, N) — input projection
Cmat = self.C_proj(x) # (B, L, N) — output projection
# Discretize A: Ā = exp(Δ·A) — ZOH rule
A = -torch.exp(self.A_log) # (D, N) — negative for stability
delta_A = torch.exp(delta.unsqueeze(-1) * A) # (B, L, D, N)
delta_B = delta.unsqueeze(-1) * Bmat.unsqueeze(2) # (B, L, D, N)
# Sequential scan: h_k = Ā h_{k-1} + B̄ x_k
h = torch.zeros(B, D, N, device=x.device, dtype=x.dtype)
ys = []
for k in range(L):
h = delta_A[:, k] * h + delta_B[:, k] * x[:, k].unsqueeze(-1)
y_k = (h * Cmat[:, k].unsqueeze(1)).sum(dim=-1) # (B, D)
ys.append(y_k)
y = torch.stack(ys, dim=1) # (B, L, D)
y = y + self.D * x # skip connection D·x
return y
class SS2D(nn.Module):
"""
2D Selective Scan module (Section 3.1, Fig. 3).
Implements the quad-directional scanning strategy from VMamba [21].
Steps:
1. Scan Expansion: flatten 2D feature map into 4 direction sequences
(LR, RL, TB, BT — ensuring all patches see all others)
2. S6 block: apply selective scan to each sequence independently
3. Scan Merging: sum the 4 output sequences, reshape to 2D
This establishes a global receptive field with O(N) complexity
vs O(N²) for standard self-attention.
"""
def __init__(self, d_model: int, d_state: int = 16):
super().__init__()
# 4 independent selective scan blocks, one per direction
self.scan_lr = SelectiveScanSimple(d_model, d_state) # left→right
self.scan_rl = SelectiveScanSimple(d_model, d_state) # right→left
self.scan_tb = SelectiveScanSimple(d_model, d_state) # top→bottom
self.scan_bt = SelectiveScanSimple(d_model, d_state) # bottom→top
def forward(self, x: Tensor) -> Tensor:
"""
x: (B, D, H, W) — 2D feature map
Returns: (B, D, H, W) — globally-scanned feature map
"""
B, D, H, W = x.shape
# Flatten to sequences for each direction
lr = x.reshape(B, D, H * W).permute(0, 2, 1) # (B, H*W, D) row-major
rl = x.flip(-1).reshape(B, D, H * W).permute(0, 2, 1) # reversed
tb = x.permute(0, 1, 3, 2).reshape(B, D, H*W).permute(0, 2, 1) # col-major
bt = x.permute(0, 1, 3, 2).flip(-1).reshape(B, D, H*W).permute(0, 2, 1)
# Independent scans (S6 block per direction)
y_lr = self.scan_lr(lr)
y_rl = self.scan_rl(rl)
y_tb = self.scan_tb(tb)
y_bt = self.scan_bt(bt)
# Scan merging: un-reverse, reshape back, sum
y_lr = y_lr.permute(0, 2, 1).reshape(B, D, H, W)
y_rl = y_rl.permute(0, 2, 1).reshape(B, D, H, W).flip(-1)
y_tb = y_tb.permute(0, 2, 1).reshape(B, D, H, W).permute(0, 1, 3, 2)
y_bt = y_bt.permute(0, 2, 1).reshape(B, D, H, W).flip(-1).permute(0, 1, 3, 2)
return y_lr + y_rl + y_tb + y_bt # (B, D, H, W)
# ─── SECTION 3: VSS Block — Visual State Space Block ──────────────────────────
class VSSBlock(nn.Module):
"""
Visual State Space (VSS) Block (Fig. 2, right panel).
Standard structure:
LN → Linear (expand) → DWConv + SiLU → SS2D → LN → Linear (project back)
+ residual connection
This is the fundamental building block used in both SSCS and DSSF.
Used as Pin(·) in the paper's Eq. 7 to project features into hidden space.
"""
def __init__(self, dim: int, d_state: int = 16, expand: float = 2.0):
super().__init__()
inner_dim = int(dim * expand)
self.norm_in = nn.LayerNorm(dim)
self.linear_in = nn.Linear(dim, inner_dim)
self.dw_conv = nn.Conv2d(inner_dim, inner_dim, kernel_size=3, padding=1, groups=inner_dim)
self.act = nn.SiLU()
self.ss2d = SS2D(inner_dim, d_state)
self.norm_out = nn.LayerNorm(inner_dim)
self.linear_out = nn.Linear(inner_dim, dim)
def forward(self, x: Tensor) -> Tensor:
"""x: (B, C, H, W) → (B, C, H, W) — globally scanned features."""
B, C, H, W = x.shape
residual = x
# LN + Linear (on flattened tokens)
x_flat = x.flatten(2).transpose(1, 2) # (B, H*W, C)
x_flat = self.linear_in(self.norm_in(x_flat))
x_2d = x_flat.transpose(1, 2).reshape(B, -1, H, W)
# DWConv + activation
x_2d = self.act(self.dw_conv(x_2d))
# 2D selective scan (global receptive field at O(N) cost)
x_2d = self.ss2d(x_2d)
# LN + project back to original dimension
x_flat = x_2d.flatten(2).transpose(1, 2)
x_flat = self.linear_out(self.norm_out(x_flat))
x_out = x_flat.transpose(1, 2).reshape(B, C, H, W)
return x_out + residual
# ─── SECTION 4: SSCS — State Space Channel Swapping Module ────────────────────
class SSCSModule(nn.Module):
"""
State Space Channel Swapping (SSCS) Module (Section 3.2.2, Eq. 5–6).
Shallow cross-modal feature fusion through interleaved channel swapping
followed by one VSS block per modality.
Channel swap operation CS(F_Ri, F_IRi):
- Divide each feature map into 4 equal parts along channel dimension
- T_Ri = Concat(F_Ri[parts 1,3], F_IRi[parts 2,4]) — RGB takes odd, IR takes even
- T_IRi = Concat(F_IRi[parts 1,3], F_Ri[parts 2,4]) — symmetric swap
This creates mixed-channel tensors where every output channel carries
information from both sensors, before any expensive attention or state
space computation occurs. The subsequent VSS block then processes these
mixed channels to build global context from the pre-mixed features.
Ablation result: removing SSCS drops mAP50 by 2% and mAP by 1.1%.
"""
def __init__(self, dim: int, d_state: int = 16):
super().__init__()
# One VSS block per modality (applied after channel swap)
self.vss_rgb = VSSBlock(dim, d_state)
self.vss_ir = VSSBlock(dim, d_state)
def _channel_swap(self, a: Tensor, b: Tensor) -> Tensor:
"""
CS(a, b): interleave channels from a (parts 1,3) and b (parts 2,4).
a, b: (B, C, H, W) where C must be divisible by 4.
Returns: (B, C, H, W) mixed-channel tensor.
"""
B, C, H, W = a.shape
q = C // 4
# Split into 4 equal parts
a_parts = a.split(q, dim=1) # [a0, a1, a2, a3]
b_parts = b.split(q, dim=1) # [b0, b1, b2, b3]
# Interleave: take parts 0,2 from a and parts 1,3 from b
return torch.cat([a_parts[0], b_parts[1], a_parts[2], b_parts[3]], dim=1)
def forward(self, F_R: Tensor, F_IR: Tensor) -> Tuple[Tensor, Tensor]:
"""
F_R, F_IR: (B, C, H, W) — RGB and IR features
Returns: F̃_R, F̃_IR — shallow fused interactive features (same shape)
"""
# Channel swap (Eq. 5): mix IR channels into RGB and vice versa
T_R = self._channel_swap(F_R, F_IR) # RGB takes odd, IR fills even
T_IR = self._channel_swap(F_IR, F_R) # symmetric swap
# VSS block: build global context from swapped features (Eq. 6)
F_tilde_R = self.vss_rgb(T_R)
F_tilde_IR = self.vss_ir(T_IR)
return F_tilde_R, F_tilde_IR
# ─── SECTION 5: DSSF — Dual State Space Fusion Module ─────────────────────────
class DSSFModule(nn.Module):
"""
Dual State Space Fusion (DSSF) Module — single iteration (Eq. 7–11).
Builds a hidden state space for cross-modal feature association.
One DSSF module is one iteration; the FMB stacks num_dssf of these.
Algorithm (one DSSF iteration):
1. Project F̃_Ri into hidden space via VSS (Pin in Eq. 7):
x_i = Linear(Norm(F̃_i))
x'_i = SiLU(DWConv(x_i))
y_i = Norm(SS2D(x'_i))
2. Compute gating parameters z_Ri, z_IRi from F̃ (Eq. 8):
z_Ri = SiLU(Linear(Norm(F̃_Ri)))
3. Dual gated cross-modal hidden state transitions (Eq. 9–10):
y'_Ri = y_Ri · z_Ri + z_Ri · y_IRi [self-gate + cross-gate]
y'_IRi = y_IRi · z_IRi + z_IRi · y_Ri [symmetric]
4. Project back + residual (Pout + Eq. 11):
F̄_Ri = Linear(y'_Ri) + F̃_Ri
F̄_IRi = Linear(y'_IRi) + F̃_IRi
The self-gating term (y_Ri · z_Ri) selectively amplifies each modality's
own strong features. The cross-gating term (z_Ri · y_IRi) injects
complementary information from the other modality, weighted by the
source modality's own relevance signal.
"""
def __init__(self, dim: int, d_state: int = 16, expand: float = 2.0):
super().__init__()
inner_dim = int(dim * expand)
# Shared projection pipeline (Pin): LN → Linear → DWConv+SiLU → SS2D → LN
self.norm_r = nn.LayerNorm(dim)
self.norm_ir = nn.LayerNorm(dim)
self.lin_r = nn.Linear(dim, inner_dim)
self.lin_ir = nn.Linear(dim, inner_dim)
self.dw_r = nn.Conv2d(inner_dim, inner_dim, 3, padding=1, groups=inner_dim)
self.dw_ir = nn.Conv2d(inner_dim, inner_dim, 3, padding=1, groups=inner_dim)
self.ss2d_r = SS2D(inner_dim, d_state)
self.ss2d_ir = SS2D(inner_dim, d_state)
self.norm_yr = nn.LayerNorm(inner_dim)
self.norm_yir = nn.LayerNorm(inner_dim)
# Gating projections fθ, gω (Eq. 8): LN → Linear → SiLU
self.gate_r = nn.Sequential(nn.LayerNorm(dim), nn.Linear(dim, inner_dim), nn.SiLU())
self.gate_ir = nn.Sequential(nn.LayerNorm(dim), nn.Linear(dim, inner_dim), nn.SiLU())
# Output projection Pout (Eq. 11): Linear back to dim
self.out_r = nn.Linear(inner_dim, dim)
self.out_ir = nn.Linear(inner_dim, dim)
def _project_to_hidden(
self,
F: Tensor,
lin: nn.Linear,
dw: nn.Conv2d,
ss2d: SS2D,
norm_y: nn.LayerNorm,
norm: nn.LayerNorm,
) -> Tensor:
"""Pin(F): project feature map into hidden state space (Eq. 7)."""
B, C, H, W = F.shape
x = lin(norm(F.flatten(2).transpose(1, 2))) # (B, H*W, Pi)
x = x.transpose(1, 2).reshape(B, -1, H, W)
x = F.silu(dw(x)) if False else nn.functional.silu(dw(x))
y = ss2d(x) # 2D selective scan: O(N) global receptive field
y_flat = norm_y(y.flatten(2).transpose(1, 2)) # (B, H*W, Pi)
return y_flat
def forward(self, F_tilde_R: Tensor, F_tilde_IR: Tensor) -> Tuple[Tensor, Tensor]:
"""
F_tilde_R, F_tilde_IR: (B, C, H, W) — shallow-fused features
Returns: F̄_R, F̄_IR — deep hidden-space fused features (same shape)
"""
B, C, H, W = F_tilde_R.shape
flat_R = F_tilde_R.flatten(2).transpose(1, 2) # (B, H*W, C)
flat_IR = F_tilde_IR.flatten(2).transpose(1, 2)
# Step 1: Project both modalities into hidden state space (Eq. 7)
y_R = self._project_to_hidden(F_tilde_R, self.lin_r, self.dw_r,
self.ss2d_r, self.norm_yr, self.norm_r)
y_IR = self._project_to_hidden(F_tilde_IR, self.lin_ir, self.dw_ir,
self.ss2d_ir, self.norm_yir, self.norm_ir)
# y_R, y_IR: (B, H*W, Pi)
# Step 2: Gating parameters (Eq. 8)
z_R = self.gate_r(flat_R) # (B, H*W, Pi) — RGB gate
z_IR = self.gate_ir(flat_IR) # (B, H*W, Pi) — IR gate
# Step 3: Dual gated cross-modal hidden state transitions (Eq. 9–10)
# y'_R = y_R · z_R + z_R · y_IR (self-gate + IR cross-gate into RGB)
# y'_IR = y_IR · z_IR + z_IR · y_R (self-gate + RGB cross-gate into IR)
y_prime_R = y_R * z_R + z_R * y_IR # Eq. 9
y_prime_IR = y_IR * z_IR + z_IR * y_R # Eq. 10
# Step 4: Project back to original space + residual (Eq. 11)
bar_R = self.out_r(y_prime_R) + flat_R # (B, H*W, C)
bar_IR = self.out_ir(y_prime_IR) + flat_IR # (B, H*W, C)
# Reshape back to 2D spatial maps
F_bar_R = bar_R.transpose(1, 2).reshape(B, C, H, W)
F_bar_IR = bar_IR.transpose(1, 2).reshape(B, C, H, W)
return F_bar_R, F_bar_IR
# ─── SECTION 6: FMB — Fusion-Mamba Block ──────────────────────────────────────
class FMB(nn.Module):
"""
Fusion-Mamba Block (FMB) — complete block (Section 3.2.2 + Alg. 1).
Integrates SSCS + stacked DSSF modules + residual feature enhancement.
Full algorithm:
1. SSCS: channel swap + VSS → F̃_R, F̃_IR (shallow interactive features)
2. DSSF × num_dssf: deep hidden space fusion (each iter updates F̃)
3. Feature enhancement (Eq. 12): F̂ = F_original + F̄_final
4. Fused output: P_i = F̂_R + F̂_IR (element-wise sum)
Placed at P3, P4, P5 stages of the feature pyramid (optimal per Table 5).
Returns both enhanced single-modal features AND the fused pyramid feature.
"""
def __init__(self, dim: int, num_dssf: int = 8, d_state: int = 16):
super().__init__()
# Shallow fusion (1 SSCS)
self.sscs = SSCSModule(dim, d_state)
# Deep fusion (num_dssf stacked DSSF modules)
self.dssf_stack = nn.ModuleList([
DSSFModule(dim, d_state) for _ in range(num_dssf)
])
def forward(self, F_R: Tensor, F_IR: Tensor) -> Tuple[Tensor, Tensor, Tensor]:
"""
F_R, F_IR: (B, C, H, W) — RGB and IR local features from backbone
Returns:
F_hat_R: (B, C, H, W) — enhanced RGB features
F_hat_IR: (B, C, H, W) — enhanced IR features
P_i: (B, C, H, W) — fused pyramid feature (input to neck)
"""
# Step 1: SSCS — shallow cross-modal channel swap + VSS (Eq. 5–6)
F_tilde_R, F_tilde_IR = self.sscs(F_R, F_IR)
# Step 2: Stacked DSSF — deep hidden state space fusion (Eq. 7–11)
# Each DSSF output feeds as input to the next (progressive refinement)
F_bar_R, F_bar_IR = F_tilde_R, F_tilde_IR
for dssf_module in self.dssf_stack:
F_bar_R, F_bar_IR = dssf_module(F_bar_R, F_bar_IR)
# Step 3: Feature enhancement via residual (Eq. 12)
F_hat_R = F_R + F_bar_R # F̂_Ri = F_Ri + F̄_Ri
F_hat_IR = F_IR + F_bar_IR # F̂_IRi = F_IRi + F̄_IRi
# Step 4: Fused pyramid feature (element-wise sum of enhanced maps)
P_i = F_hat_R + F_hat_IR
return F_hat_R, F_hat_IR, P_i
# ─── SECTION 7: Dual-Branch Backbone + Neck + Head ────────────────────────────
class ConvBnAct(nn.Module):
"""Standard Conv + BN + SiLU block (YOLOv8 building block)."""
def __init__(self, c_in: int, c_out: int, k: int = 3, s: int = 1):
super().__init__()
self.conv = nn.Conv2d(c_in, c_out, k, stride=s, padding=k//2, bias=False)
self.bn = nn.BatchNorm2d(c_out)
self.act = nn.SiLU(inplace=True)
def forward(self, x): return self.act(self.bn(self.conv(x)))
class BackboneStage(nn.Module):
"""Single backbone stage: downsample + feature extraction."""
def __init__(self, c_in: int, c_out: int, num_blocks: int = 2):
super().__init__()
self.down = ConvBnAct(c_in, c_out, k=3, s=2)
self.blocks = nn.Sequential(*[
ConvBnAct(c_out, c_out) for _ in range(num_blocks)
])
def forward(self, x): return self.blocks(self.down(x))
class DualStreamBackbone(nn.Module):
"""
Dual-stream feature extraction backbone (Section 3.2.1, Eq. 4).
Two independent sets of convolutional blocks (ϕ for RGB, φ for IR),
each producing 5 feature maps at progressively coarser scales.
FMB is applied at the last 3 stages (P3, P4, P5).
Returns feature pyramid outputs [P3, P4, P5] after FMB fusion.
"""
def __init__(self, cfg: FMConfig):
super().__init__()
C = cfg.channels
# RGB backbone: 5 stages (ϕ1...ϕ5)
self.rgb_stages = nn.ModuleList([
BackboneStage(3, C[0], 1), # stage 0: 3→C[0], H/2
BackboneStage(C[0], C[1], 2), # stage 1: H/4
BackboneStage(C[1], C[2], 2), # stage 2: H/8 → P3
BackboneStage(C[2], C[3], 2), # stage 3: H/16 → P4
BackboneStage(C[3], C[4], 2), # stage 4: H/32 → P5
])
# IR backbone: identical structure (φ1...φ5)
self.ir_stages = nn.ModuleList([
BackboneStage(3, C[0], 1),
BackboneStage(C[0], C[1], 2),
BackboneStage(C[1], C[2], 2),
BackboneStage(C[2], C[3], 2),
BackboneStage(C[3], C[4], 2),
])
# FMB at P3, P4, P5 (stages 2, 3, 4 per Table 5: {P3,P4,P5} optimal)
self.fmb_p3 = FMB(C[2], cfg.num_dssf)
self.fmb_p4 = FMB(C[3], cfg.num_dssf)
self.fmb_p5 = FMB(C[4], cfg.num_dssf)
def forward(self, rgb: Tensor, ir: Tensor) -> Tuple[Tensor, Tensor, Tensor]:
"""
rgb, ir: (B, 3, H, W)
Returns: P3, P4, P5 — fused multi-scale feature maps
"""
# Extract features through backbone stages
r, t = rgb, ir
for i in range(2): # stages 0,1: no FMB
r = self.rgb_stages[i](r)
t = self.ir_stages[i](t)
# Stage 2 → P3 (H/8)
r = self.rgb_stages[2](r)
t = self.ir_stages[2](t)
_, _, P3 = self.fmb_p3(r, t)
# Stage 3 → P4 (H/16)
r = self.rgb_stages[3](r)
t = self.ir_stages[3](t)
_, _, P4 = self.fmb_p4(r, t)
# Stage 4 → P5 (H/32)
r = self.rgb_stages[4](r)
t = self.ir_stages[4](t)
_, _, P5 = self.fmb_p5(r, t)
return P3, P4, P5
class YOLOv8Neck(nn.Module):
"""
YOLOv8-style FPN+PAN neck (Fig. 4).
Top-down then bottom-up feature pyramid with C2f-style blocks.
Takes P3, P4, P5 from FMB and produces three detection scales.
"""
def __init__(self, channels: List[int]):
super().__init__()
C2, C3, C4 = channels[2], channels[3], channels[4]
# Top-down path
self.up = nn.Upsample(scale_factor=2, mode='nearest')
self.td1 = ConvBnAct(C4 + C3, C3)
self.td2 = ConvBnAct(C3 + C2, C2)
# Bottom-up path
self.bu1 = ConvBnAct(C2, C3, s=2)
self.bu2 = ConvBnAct(C3*2, C3)
self.bu3 = ConvBnAct(C3, C4, s=2)
self.bu4 = ConvBnAct(C4 + C4, C4)
def forward(self, P3: Tensor, P4: Tensor, P5: Tensor) -> List[Tensor]:
"""Returns [N3, N4, N5] — detection-ready feature maps."""
# Top-down: P5→P4→P3
td1 = self.td1(torch.cat([self.up(P5), P4], dim=1))
td2 = self.td2(torch.cat([self.up(td1), P3], dim=1))
# Bottom-up: td2→td1→P5
bu1 = self.bu1(td2)
N4 = self.bu2(torch.cat([bu1, td1], dim=1))
bu3 = self.bu3(N4)
N5 = self.bu4(torch.cat([bu3, P5], dim=1))
return [td2, N4, N5] # N3 (fine), N4 (medium), N5 (coarse)
class DetectHead(nn.Module):
"""
Anchor-free YOLO detection head.
For each scale, predicts (cx, cy, w, h, conf, cls×num_classes) per location.
"""
def __init__(self, num_classes: int, channels: List[int]):
super().__init__()
C2, C3, C4 = channels[2], channels[3], channels[4]
out_ch = 4 + 1 + num_classes # box(4) + conf(1) + cls(num_classes)
self.head3 = nn.Conv2d(C2, out_ch, 1)
self.head4 = nn.Conv2d(C3, out_ch, 1)
self.head5 = nn.Conv2d(C4, out_ch, 1)
def forward(self, feats: List[Tensor]) -> List[Tensor]:
"""Returns list of raw predictions at each scale: (B, 5+C, H_i, W_i)."""
return [
self.head3(feats[0]),
self.head4(feats[1]),
self.head5(feats[2]),
]
# ─── SECTION 8: Loss Function ─────────────────────────────────────────────────
class FusionMambaLoss(nn.Module):
"""
YOLOv8-style detection loss (Section 3.2.3, Eq. 13).
L = λ_coord · L_coord + L_conf + L_class
Components:
L_coord: CIoU loss for bounding box regression (localizes objects precisely)
L_conf: Binary cross-entropy for objectness confidence
L_class: Binary cross-entropy for class prediction
λ_coord = 7.5 (paper default) strongly weights localization accuracy,
reflecting that precise box coordinates are harder to learn than classification.
"""
def __init__(self, num_classes: int, lambda_coord: float = 7.5):
super().__init__()
self.num_classes = num_classes
self.lambda_coord = lambda_coord
def _ciou_loss(self, pred_boxes: Tensor, gt_boxes: Tensor) -> Tensor:
"""
Complete IoU loss for bounding box regression.
pred_boxes, gt_boxes: (N, 4) in [cx, cy, w, h] normalized format.
"""
# Convert to corner format
px1 = pred_boxes[..., 0] - pred_boxes[..., 2] / 2
py1 = pred_boxes[..., 1] - pred_boxes[..., 3] / 2
px2 = pred_boxes[..., 0] + pred_boxes[..., 2] / 2
py2 = pred_boxes[..., 1] + pred_boxes[..., 3] / 2
gx1 = gt_boxes[..., 0] - gt_boxes[..., 2] / 2
gy1 = gt_boxes[..., 1] - gt_boxes[..., 3] / 2
gx2 = gt_boxes[..., 0] + gt_boxes[..., 2] / 2
gy2 = gt_boxes[..., 1] + gt_boxes[..., 3] / 2
inter = (torch.min(px2,gx2)-torch.max(px1,gx1)).clamp(0) * \
(torch.min(py2,gy2)-torch.max(py1,gy1)).clamp(0)
ap = (px2-px1).clamp(0) * (py2-py1).clamp(0)
ag = (gx2-gx1).clamp(0) * (gy2-gy1).clamp(0)
iou = inter / (ap + ag - inter + 1e-7)
# Diagonal length of smallest enclosing box (for CIoU penalty)
cw = torch.max(px2,gx2) - torch.min(px1,gx1)
ch = torch.max(py2,gy2) - torch.min(py1,gy1)
c2 = cw**2 + ch**2 + 1e-7
# Center distance penalty
d2 = (pred_boxes[...,0]-gt_boxes[...,0])**2 + (pred_boxes[...,1]-gt_boxes[...,1])**2
# Aspect ratio consistency
v = (4/(math.pi**2)) * (torch.atan(gt_boxes[...,2]/(gt_boxes[...,3]+1e-7))
- torch.atan(pred_boxes[...,2]/(pred_boxes[...,3]+1e-7)))**2
alpha = v / (1 - iou + v + 1e-7)
ciou = iou - d2/c2 - alpha*v
return (1 - ciou).mean()
def forward(
self,
preds: List[Tensor],
gt_boxes_list: List[Tensor],
gt_labels_list: List[Tensor],
) -> Dict[str, Tensor]:
"""
preds: list of (B, 5+C, H_i, W_i) raw predictions per scale
gt_boxes_list: list of (B, Q, 4) normalized ground truth boxes
gt_labels_list: list of (B, Q) integer class labels
Returns loss dict with 'coord', 'conf', 'class', 'total'.
"""
l_coord = torch.tensor(0.0, device=preds[0].device)
l_conf = torch.tensor(0.0, device=preds[0].device)
l_class = torch.tensor(0.0, device=preds[0].device)
C = self.num_classes
for scale_idx, pred in enumerate(preds):
B, out_ch, H, W = pred.shape
# Flatten spatial: (B, H*W, 5+C)
pred_flat = pred.permute(0, 2, 3, 1).reshape(B, -1, out_ch)
gt_boxes = gt_boxes_list[scale_idx].to(pred.device) # (B, Q, 4)
gt_labels = gt_labels_list[scale_idx].to(pred.device) # (B, Q)
N_gt = gt_boxes.shape[1]
N_pred = pred_flat.shape[1]
N_use = min(N_gt, N_pred)
pred_boxes = pred_flat[:, :N_use, :4].sigmoid()
pred_conf = pred_flat[:, :N_use, 4]
pred_cls = pred_flat[:, :N_use, 5:]
gt_boxes_use = gt_boxes[:, :N_use, :]
gt_labels_use = gt_labels[:, :N_use]
# Coordinate loss (CIoU)
l_coord = l_coord + self._ciou_loss(
pred_boxes.reshape(-1, 4),
gt_boxes_use.reshape(-1, 4)
)
# Confidence loss (BCE with ones target for matched predictions)
conf_target = torch.ones_like(pred_conf)
l_conf = l_conf + F.binary_cross_entropy_with_logits(pred_conf, conf_target)
# Classification loss (BCE multi-label)
cls_target = F.one_hot(gt_labels_use.clamp(0, C-1), C).float()
l_class = l_class + F.binary_cross_entropy_with_logits(
pred_cls.reshape(-1, C),
cls_target.reshape(-1, C)
)
total = self.lambda_coord * l_coord + l_conf + l_class
return {'coord': l_coord, 'conf': l_conf, 'class': l_class, 'total': total}
class FusionMambaDetector(nn.Module):
"""
Complete Fusion-Mamba Detection Model.
Pipeline (Fig. 2 top):
1. Dual-stream backbone (ϕ_i, φ_i) extracts F_Ri, F_IRi at 5 scales
2. FMB at P3/P4/P5: SSCS → DSSF×8 → residual enhancement → P_i = F̂_R + F̂_IR
3. YOLOv8-style FPN+PAN neck produces 3 detection scales
4. Detection heads predict boxes, confidence, and classes at each scale
Training: batch_size=4, SGD momentum=0.9, lr=0.01, 150 epochs.
"""
def __init__(self, cfg: Optional[FMConfig] = None):
super().__init__()
cfg = cfg or FMConfig()
self.cfg = cfg
self.backbone = DualStreamBackbone(cfg)
self.neck = YOLOv8Neck(cfg.channels)
self.head = DetectHead(cfg.num_classes, cfg.channels)
def forward(self, rgb: Tensor, ir: Tensor) -> List[Tensor]:
"""
rgb, ir: (B, 3, H, W) — aligned visible and infrared images
Returns: list of raw predictions at 3 scales (B, 5+C, H_i, W_i)
"""
P3, P4, P5 = self.backbone(rgb, ir)
neck_feats = self.neck(P3, P4, P5)
preds = self.head(neck_feats)
return preds
# ─── SECTION 9: Dataset, Training Loop & Smoke Test ──────────────────────────
class SyntheticMultispectralDataset(Dataset):
"""
Synthetic RGB+IR dataset for testing Fusion-Mamba.
Replace with real datasets:
LLVIP: https://github.com/bupt-ai-cz/LLVIP
M3FD: https://github.com/JinyuanLiu-CV/TarDAL
FLIR-Aligned: https://www.flir.com/oem/adas/adas-dataset-form/
(use FLIR-aligned split from Zhang et al., ICIP 2020)
"""
def __init__(
self, n: int = 80, img_size: int = 64,
num_boxes: int = 5, num_classes: int = 3
):
self.n = n; self.img_size = img_size
self.num_boxes = num_boxes; self.num_classes = num_classes
def __len__(self): return self.n
def __getitem__(self, idx):
S = self.img_size
rgb = torch.randn(3, S, S)
ir = torch.randn(3, S, S)
boxes = torch.rand(self.num_boxes, 4).clamp(0.1, 0.9)
labels = torch.randint(0, self.num_classes, (self.num_boxes,))
return rgb, ir, boxes, labels
def train_one_epoch(
model: FusionMambaDetector,
loader: DataLoader,
optimizer: torch.optim.Optimizer,
criterion: FusionMambaLoss,
device: torch.device,
epoch: int,
) -> float:
"""Standard training loop. Each forward pass processes one RGB+IR pair."""
model.train()
total = 0.0
num_scales = 3 # P3, P4, P5
for step, (rgb, ir, gt_boxes, gt_labels) in enumerate(loader):
rgb = rgb.to(device); ir = ir.to(device)
gt_boxes = gt_boxes.to(device)
gt_labels = gt_labels.to(device)
# Replicate GT for all three detection scales
gt_boxes_list = [gt_boxes] * num_scales
gt_labels_list = [gt_labels] * num_scales
optimizer.zero_grad()
preds = model(rgb, ir)
losses = criterion(preds, gt_boxes_list, gt_labels_list)
losses['total'].backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 10.0)
optimizer.step()
total += losses['total'].item()
if step % 5 == 0:
print(f" Epoch {epoch} | Step {step}/{len(loader)} | "
f"Loss {total/(step+1):.4f} | "
f"coord={losses['coord'].item():.3f} "
f"conf={losses['conf'].item():.3f}")
return total / max(1, len(loader))
def run_training(epochs: int = 2, device_str: str = "cpu") -> FusionMambaDetector:
"""
Full training pipeline (tiny config for demonstration).
Production: 150 epochs, batch=4, SGD momentum=0.9, lr=0.01, wd=0.001.
"""
device = torch.device(device_str)
cfg = FMConfig(tiny=True)
model = FusionMambaDetector(cfg).to(device)
n_params = sum(p.numel() for p in model.parameters()) / 1e6
print(f"Parameters: {n_params:.2f}M")
dataset = SyntheticMultispectralDataset(
n=40, img_size=cfg.img_size, num_classes=cfg.num_classes
)
loader = DataLoader(dataset, batch_size=4, shuffle=True)
opt = torch.optim.SGD(
model.parameters(), lr=cfg.lr, momentum=cfg.momentum, weight_decay=cfg.weight_decay
)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(opt, T_max=epochs)
criterion = FusionMambaLoss(cfg.num_classes, cfg.lambda_coord)
print(f"\n{'='*55}")
print(f" Fusion-Mamba Training | {epochs} epochs | {device}")
print(f" DSSF modules: {cfg.num_dssf} | FMB stages: P3,P4,P5")
print(f"{'='*55}\n")
for epoch in range(1, epochs+1):
avg = train_one_epoch(model, loader, opt, criterion, device, epoch)
scheduler.step()
print(f"Epoch {epoch}/{epochs} — Avg Loss: {avg:.4f}\n")
print("Training complete.")
return model
if __name__ == "__main__":
print("=" * 60)
print(" Fusion-Mamba — Full Architecture Smoke Test")
print("=" * 60)
torch.manual_seed(42)
# ── 1. Build tiny model ──────────────────────────────────────────────────
print("\n[1/5] Instantiating tiny Fusion-Mamba detector...")
cfg = FMConfig(tiny=True)
model = FusionMambaDetector(cfg)
n_p = sum(p.numel() for p in model.parameters()) / 1e6
print(f" Parameters: {n_p:.3f}M")
# ── 2. Forward pass ─────────────────────────────────────────────────────
print("\n[2/5] Forward pass with dummy RGB+IR pair...")
B = 2
rgb_in = torch.randn(B, 3, cfg.img_size, cfg.img_size)
ir_in = torch.randn(B, 3, cfg.img_size, cfg.img_size)
preds = model(rgb_in, ir_in)
print(f" Predictions at {len(preds)} scales:")
for i, p in enumerate(preds):
print(f" Scale {i}: {tuple(p.shape)}")
# ── 3. Loss ──────────────────────────────────────────────────────────────
print("\n[3/5] Loss computation...")
criterion = FusionMambaLoss(cfg.num_classes, cfg.lambda_coord)
gt_boxes = torch.rand(B, 5, 4).clamp(0.1, 0.9)
gt_labels = torch.randint(0, cfg.num_classes, (B, 5))
losses = criterion([preds[0]], [gt_boxes], [gt_labels])
print(f" Total: {losses['total'].item():.4f} | "
f"coord: {losses['coord'].item():.4f} | "
f"conf: {losses['conf'].item():.4f}")
# ── 4. Backward pass ────────────────────────────────────────────────────
print("\n[4/5] Backward pass...")
losses['total'].backward()
grads = [p for p in model.parameters() if p.grad is not None]
print(f" Parameters with gradient: {len(grads)} / {sum(1 for _ in model.parameters())}")
# ── 5. Short training run ────────────────────────────────────────────────
print("\n[5/5] Short training run (2 epochs)...")
run_training(epochs=2, device_str="cpu")
print("\n" + "="*60)
print("✓ All checks passed. Fusion-Mamba is ready for use.")
print("="*60)
print("""
Production deployment steps:
1. Install mamba-ssm for GPU-accelerated selective scan:
pip install mamba-ssm causal-conv1d
Replace SelectiveScanSimple.forward() with:
from mamba_ssm import selective_scan_fn
2. Load pretrained YOLOv5/YOLOv8 backbone weights:
from ultralytics import YOLO
yolo = YOLO('yolov8l.pt')
# Transfer backbone weights to DualStreamBackbone stages
3. Download datasets:
LLVIP: https://github.com/bupt-ai-cz/LLVIP (15,488 pairs)
M3FD: https://github.com/JinyuanLiu-CV/TarDAL (4,200 pairs)
FLIR-A: https://www.flir.com/ (4,129 training / 1,013 test)
4. Training config from paper:
batch_size=4, SGD momentum=0.9, lr=0.01, wd=0.001
img_size=640, epochs=150, lambda_coord=7.5
num_dssf=8, FMB at P3+P4+P5
5. Evaluate with COCO mAP toolkit:
pip install pycocotools
Compute mAP50 and mAP (0.5:0.05:0.95)
""")
Paper & Code
Fusion-Mamba is the first work to explore Mamba for cross-modal feature fusion — and the results across three benchmarks make a compelling case for hidden state space interaction as a new paradigm in multispectral detection.
Dong, W., Zhu, H., Lin, S., Luo, X., Shen, Y., Liu, X., Zhang, J., Guo, G., & Zhang, B. (2024). Fusion-Mamba for Cross-modality Object Detection. arXiv:2404.09146v1 [cs.CV]. Beihang University / East China Normal University.
This article is an independent editorial analysis of peer-reviewed research. The PyTorch implementation is an educational adaptation for learning purposes. The SimpleSelectiveScan uses a sequential loop for clarity; production deployments should use the mamba-ssm CUDA kernel for orders-of-magnitude better performance.
Related Posts — You May Like to Read
Explore More on AI Trend Blend
If this sparked your curiosity, here is more of what we cover — from foundational deep learning tutorials to the latest research in multimodal perception and efficient inference.