The Feedback Loop That Fixes Multispectral Detection: How IRDFusion Borrowed from Circuit Design to Beat the State of the Art
Researchers at Jiangsu University asked a simple question: what if we treated cross-modal feature fusion the same way electrical engineers treat differential amplifiers? The answer — IRDFusion — hits 88.3 mAP50 on FLIR and works as a plug-and-play module inside any detection framework from YOLOv5 to Co-DETR.
Imagine trying to spot a cyclist at a foggy intersection at 2 AM. Your visible camera sees almost nothing — headlight scatter and shadow. Your thermal camera, though, picks up every warm body on the road. Now imagine a detection system that doesn’t just combine those two feeds but actively asks: what does the thermal image know that the visible image doesn’t? And then feeds that knowledge back, iteratively, until the fused representation is as sharp as it can possibly get. That is the core idea behind IRDFusion, a new multispectral fusion framework from Jiangsu University that borrows its central mechanism directly from analog electronics. The results across three major benchmarks are difficult to argue with: 88.3 mAP50 on FLIR, 98.4 on LLVIP, and 90.8 on M3FD — state of the art on all three.
What Everyone Else Is Getting Wrong
Multispectral detection has been around long enough that the field has developed some comfortable defaults. You extract features from both the RGB and thermal image streams, you find a smart way to combine them, and you run the fused representation through a detection head. The question has always been: what counts as a “smart way” to combine them?
Early methods used simple concatenation or element-wise addition — fast and clean, but completely indiscriminate. They blend the useful parts of each modality with the useless parts in equal measure. A dark road surface looks similar in both visible and thermal domains, so both modalities contribute background noise that obscures the warm body of a pedestrian. Global fusion just averages that noise into the signal.
Transformer-based methods like ICAFusion and DAMSDet moved the needle significantly by using attention to selectively pull cross-modal information. But they introduced their own problems. Stacked attention blocks are expensive — computationally and in terms of parameter count — and they still don’t have an explicit mechanism for identifying and amplifying what is genuinely different between the two modalities versus what is just the same background appearing twice.
This is the problem IRDFusion was built to solve. The authors from Jiangsu University, Southeast University, and the University of North Texas frame it as two distinct challenges: first, how do you suppress the shared background while preserving complementary object features? Second, how do you do that without piling on parameters and attention layers until the thing becomes unusable?
The “difference” between two aligned sensor feeds is not noise — it is the most informative signal available. Where the RGB and IR images agree, you have background. Where they disagree, you have an object. IRDFusion makes this differential signal the center of its fusion strategy, computing it explicitly and feeding it back iteratively to progressively refine the fused features. This is the direct analog of how a differential amplifier in electronics rejects common-mode signals while amplifying the difference.
The Circuit Board Analogy That Actually Works
The design philosophy of IRDFusion comes from an unlikely source: feedback differential amplifier circuits. In electronics, a differential amplifier takes two inputs, computes their difference, and amplifies it — while systematically rejecting anything that appears identically on both inputs (called common-mode noise). This is exactly what you want from a sensor fusion system where both modalities are viewing the same scene.
Think about what “common-mode” means in the imaging context. The road surface, the sky, parked cars in the background — these appear in both the RGB and thermal feeds with similar feature representations. A pure common-mode signal. An alert pedestrian walking into frame is warm relative to the environment, so they light up in the thermal feed while appearing as a dark silhouette in the visible. That is a difference signal — the exact kind a differential amplifier would amplify.
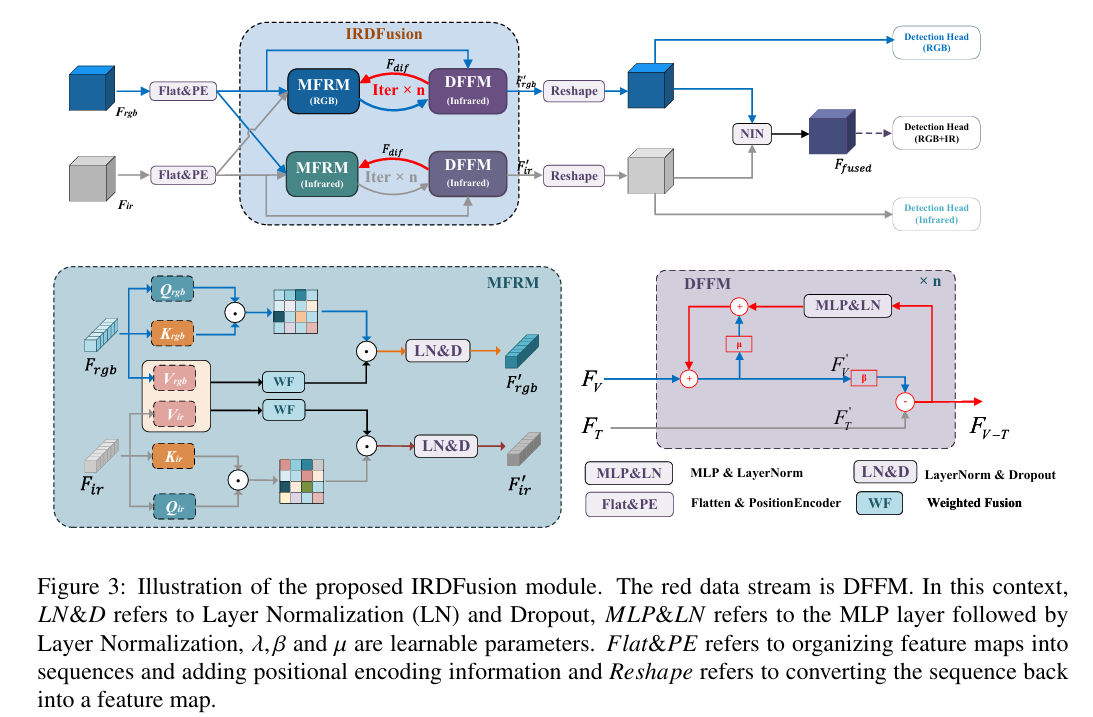
IRDFusion operationalizes this intuition with two modules that work in closed-loop interaction. The Mutual Feature Refinement Module (MFRM) handles intra- and inter-modal feature alignment — making sure the two representations are speaking the same spatial language before you start computing their difference. The Differential Feature Feedback Module (DFFM) then computes that difference, uses it as a guidance signal, and feeds it back into the next iteration of the MFRM. Repeat four times and you get a fused representation where the shared background has been systematically attenuated and the discriminative object features have been progressively amplified.
─────────────────────────────────
RGB Features F_rgb ──► MFRM (RGB branch) ──► F’_v
IR Features F_ir ──► MFRM (IR branch) ──► F’_t
▲ │
│ DFFM: F_diff = F’_t − β·F’_v
│ F^(k+1)_v = μ·F^(k)_v + α·MLP(LN(F_diff))
└────────────────────┘ ×4 iterations
Fused output: F_fused → SFP Neck → Co-DETR Heads
The MFRM: Cross-Modal Attention That Knows What It Is Doing
The Mutual Feature Refinement Module handles the alignment step. Its job is not to fuse — that comes later — but to make each modality’s features more informative about what the other modality is seeing in the same spatial region.
The mechanism builds on standard self-attention but with a twist. For each modality, you compute Query, Key, and Value matrices as usual. The attention matrix for each modality is computed from its own Q and K — this represents what that modality “pays attention to” internally. But when you apply that attention matrix to produce output features, you use a fused Value that incorporates information from the other modality’s Value vector.
The λ parameters are what make this interesting. Rather than using a fixed blend weight, the fusion coefficient is learned adaptively from the input data itself:
This formulation, inspired by differential transformers, allows the model to learn different weighting strategies for different types of input. When the two modalities are highly aligned (daytime, clear weather), λ might be small — the value fusion is gentle. When the modalities diverge sharply (nighttime, where the thermal feed carries most of the information), λ adjusts to pull more strongly from the informative modality. The result after applying the attention matrix to the fused values is a cross-modal amplified feature representation:
The DFFM: Computing and Feeding Back the Difference
Here is where the circuit analogy pays off in full. After MFRM produces refined features F’_v and F’_t for both modalities, the DFFM computes their difference — the signal that tells the system what each modality uniquely knows that the other does not.
The differential feature is not just a raw subtraction. A learnable parameter β controls how aggressively to compute the difference, allowing the model to tune the strength of the differential signal based on what it learns from the training data:
That second line is the feedback step. The refined RGB features going into the next iteration are a weighted sum of the current RGB features and the processed differential signal. Parameter μ controls how much of the current features to preserve. Parameter α controls how strongly the differential guidance updates them. Through this iterative process, the differential signal — which captures what IR sees that RGB doesn’t — progressively shapes the RGB features to be more aware of those complementary IR cues.
The Relation-Map Difference Interpretation
The paper’s authors go one step further and provide an elegant mathematical reinterpretation of the full IRDFusion pipeline. When you expand the full derivation of the differential feature Fv−t, it can be written as:
The terms C(v−t)2v and C(t−v)2t are relation-map differences — they represent the difference between the RGB attention map and the thermal attention map, weighted by the respective fusion parameters. This is not just an arithmetic curiosity. It means that IRDFusion is explicitly modeling the divergence between how the two modalities attend to the scene, and using that divergence to guide fusion. Where the attention maps agree, the contribution cancels out. Where they diverge, the signal is amplified. This is the formal mathematical statement of the common-mode rejection principle.
The ablation study over iteration counts (1 through 6) shows a clear peak at iteration 4 for overall mAP50 on FLIR. Below four, the differential feedback hasn’t had enough cycles to fully suppress redundant background features — some irrelevant edges and thermal noise remain in the fused representation. Above four, the differential signal starts to weaken as the two modality streams converge, and interactions between them begin to introduce adverse effects, including amplification of background noise rather than suppression. Four is the Goldilocks number for this architecture.
Full System Architecture
IRDFusion COMPLETE PIPELINE
══════════════════════════════════════════════════════════════
INPUT
RGB Image (640×640×3) + Infrared Image (640×640×3)
│ │
▼ ▼
┌─────────────────────────────────────────────────────────┐
│ DUAL-BRANCH ViT BACKBONE │
│ (pre-trained ViT, one per modality) │
│ F_rgb: patch tokens (B, N, D) │
│ F_ir: patch tokens (B, N, D) │
└──────────────┬──────────────────────────┬───────────────┘
│ │
▼ ▼
Flat & PositionEncode Flat & PositionEncode
│ │
└──────────┬───────────────┘
▼
┌─────────────────────────────────────────────────────────┐
│ IRDFusion MODULE (×4 iterations) │
│ │
│ Iteration k: │
│ ┌──────────────────────────────────────────────────┐ │
│ │ MFRM (RGB branch) │ │
│ │ [Q_v, K_v, V_v] = F_v · W_v │ │
│ │ A_v = Softmax(Q_v·K_v / √d) │ │
│ │ V_fv = V_v + λ_v · V_t (cross-Value blend) │ │
│ │ F'_v = A_v · V_fv │ │
│ │ │ │
│ │ MFRM (IR branch, symmetric) │ │
│ │ F'_t = A_t · V_ft │ │
│ └──────────────────────────────────────────────────┘ │
│ │ │
│ ┌──────────────────────▼───────────────────────────┐ │
│ │ DFFM (differential feedback) │ │
│ │ F_diff_v = F'_t − β · F'_v │ │
│ │ F^(k+1)_v = μ·F^(k)_v + α·MLP(LN(F_diff_v)) │ │
│ │ F^(k+1)_t = F_t (held fixed per RGB iter) │ │
│ └──────────────────────────────────────────────────┘ │
│ │
│ After 4 iterations → Reshape → NiN fusion │
│ F_fused: (B, C, H/16, W/16) │
└──────────────────────────┬──────────────────────────────┘
│
Three detection branches:
F_rgb → Head (RGB only)
F_ir → Head (IR only)
F_fused → Head (RGB+IR fused)
│
┌──────────────────────────▼──────────────────────────────┐
│ SIMPLE FEATURE PYRAMID (SFP) NECK │
│ → Multi-scale feature maps │
└──────────────────────────┬──────────────────────────────┘
▼
┌─────────────────────────────────────────────────────────┐
│ Co-DETR DETECTION HEAD │
│ Main: CoDINO (Quality Focal + L1 + GIoU) │
│ Aux: RPN + ROI + BBOX heads │
│ Output: boxes, classes, scores │
└─────────────────────────────────────────────────────────┘
One design choice that deserves attention: IRDFusion runs three parallel detection heads — one for RGB alone, one for IR alone, and one for the fused representation. The single-branch ablation results (Table 6 in the paper) show that even the individual RGB and IR branches improve when IRDFusion is active, because the cross-modal interaction during fusion improves the features fed to those single-modality heads. The system is not just building a better fused representation — it is making both individual modalities smarter through their interaction.
Results: Three Benchmarks, All State of the Art
FLIR — The Autonomous Driving Challenge
| Method | Venue | mAP50 | mAP75 | mAP |
|---|---|---|---|---|
| DAMSDet | ECCV’24 | 86.6 | 48.1 | 49.3 |
| MMPedestron | ECCV’24 | 86.4 | — | — |
| Fusion-Mamba | TMM’25 | 84.9 | 45.9 | 47.0 |
| Baseline (NiNfusion) | — | 84.8 | 44.0 | 46.9 |
| IRDFusion (Ours) | — | 88.3 | 48.0 | 50.7 |
On FLIR — the most demanding of the three benchmarks, covering person, car, and bicycle in complex driving conditions — IRDFusion clears 88.3 mAP50, a 1.7 point improvement over the previous best DAMSDet and a 3.5 point improvement over the baseline. The bicycle category deserves special mention. Bicycles are notoriously difficult in multispectral detection because their thermal signature is weak (metal frame, small warm body) and their visual signature is thin (narrow, easily occluded). MFRM’s cross-modal value fusion and DFFM’s differential feedback both contribute most strongly to this category — bicycle mAP50 improves by 9.9 percentage points with the full IRDFusion system active.
LLVIP — Pedestrian Detection in Near-Total Darkness
| Method | Venue | mAP50 | mAP75 | mAP |
|---|---|---|---|---|
| ICAFusion | PR’24 | 98.4 | 76.2 | 64.5 |
| DAMSDet | ECCV’24 | 97.9 | 79.1 | 69.6 |
| GM_DETR | CVPR’24 | 97.4 | 81.4 | 70.2 |
| Baseline | — | 98.0 | 80.7 | 69.5 |
| IRDFusion (Ours) | — | 98.4 | 83.1 | 70.9 |
LLVIP is a single-class pedestrian dataset captured almost entirely in dark conditions. The 83.1 mAP75 score is particularly telling — this is the strict localization metric requiring 75% IoU overlap. A 2.4-point improvement over the baseline at this threshold means the model is not just finding more pedestrians, it is drawing tighter, more accurate boxes around them. That precision gain traces directly to the differential feedback mechanism preserving fine-grained contour information that global fusion methods tend to blur.
M3FD — Six Categories Across Weather and Lighting
| Method | Venue | mAP50 | mAP |
|---|---|---|---|
| ICAFusion | PR’24 | 90.8 | 60.9 |
| Fusion-Mamba | TMM’25 | 88.0 | 61.9 |
| MMFN | TCSVT’24 | 86.2 | — |
| Baseline | — | 87.1 | 58.2 |
| IRDFusion (Ours) | — | 90.8 | 61.9 |
M3FD spans six categories (People, Car, Bus, Motorcycle, Lamp, Truck) collected under rain, fog, night, overcast, and normal conditions. IRDFusion matches ICAFusion on mAP50 and ties Fusion-Mamba on overall mAP — both state of the art — while showing a 3.7 point improvement over the baseline on mAP50. The breadth of conditions in M3FD tests generalization, and IRDFusion holds up across all of them.
Ablation: Module Contributions on FLIR
| MFRM | DFFM | mAP50 (all) | mAP75 (all) | mAP (all) | Bicycle mAP50 |
|---|---|---|---|---|---|
| ✗ | ✗ | 84.8 | 44.0 | 46.9 | 72.9 |
| ✓ | ✗ | 86.3 (+1.5) | 46.0 (+2.0) | 48.6 (+1.7) | 77.3 (+4.4) |
| ✗ | ✓ | 87.5 (+2.7) | 46.0 (+2.0) | 49.2 (+2.3) | 79.5 (+6.6) |
| ✓ | ✓ | 88.3 (+3.5) | 48.0 (+4.0) | 50.7 (+3.8) | 82.8 (+9.9) |
“The two modules operate in a closed-loop interaction: MFRM first consolidates modal features for reliable object localization, while DFFM refines modality-specific differences to enrich discriminative details — creating a synergistic cycle that progressively amplifies salient signals.” — Shen, Zhan et al., Jiangsu University / University of North Texas, 2025
Cross-Framework Generalization
One of the more practically useful results in the paper is the cross-framework evaluation. IRDFusion is explicitly designed as a plug-and-play module — you slot it between the dual backbone and the detection head of whatever framework you are using. The paper tests this with YOLOv5 (anchor-based, real-time) and Co-DETR (transformer, high-accuracy).
| Framework | Method | FLIR mAP50 | LLVIP mAP75 | M3FD mAP50 |
|---|---|---|---|---|
| YOLOv5 | Baseline | 79.9 | 71.2 | 89.1 |
| YOLOv5 | + IRDFusion | 84.8 (+4.9) | 75.7 (+4.5) | 89.8 (+0.7) |
| Co-DETR | Baseline | 84.8 | 80.7 | 87.1 |
| Co-DETR | + IRDFusion | 88.3 (+3.5) | 83.1 (+2.4) | 90.8 (+3.7) |
Consistent improvements across both frameworks and all three datasets — that is not a result you get from a method that only works under very specific conditions. The FLIR gain with YOLOv5 is particularly striking: nearly 5 mAP50 points from plugging in a fusion module. For a real-time detection framework where people are willing to accept some accuracy trade-offs for speed, that is a meaningful free lunch.
Honest Limitations: Speed and Small Occluded Objects
The paper is refreshingly direct about two real problems. The first is computational cost. Adding IRDFusion to YOLOv5 drops inference speed from 45.3 FPS to 17.0 FPS — a significant cut for any application that needs real-time performance. The parameter count jumps by ~60M in the YOLO case. With Co-DETR, the speed hit is smaller (3.6 → 3.1 FPS) but the GFLOPs nearly double to 1213.5. The iterative feedback is doing real work, and real work costs compute.
The second limitation is small, heavily occluded objects. When a pedestrian is mostly hidden behind a car, both the visible contour and the thermal signature are ambiguous. MFRM struggles to accurately capture cross-modal cues when the object is barely visible. DFFM can’t extract meaningful differential features when both modalities agree there isn’t much there. Occasional false positives and missed detections under severe occlusion remain in the failure cases. The authors suggest multi-scale feature enhancement and deformable attention as directions for future work — both reasonable approaches to the problem.
The car category also shows a minor pattern worth noting. In some experimental configurations, adding cross-modal features via MFRM slightly hurts car detection precision. The RGB background near car contours is structurally similar to car edges in the thermal image — the cross-modal value fusion occasionally amplifies irrelevant background edges, reducing IoU. DFFM partially corrects this by canceling common-mode background, but it’s an honest trade-off to understand before deploying the method in car-heavy scenarios that require strict localization.
Why This Matters Beyond the Numbers
The conceptual contribution of IRDFusion goes beyond its benchmark scores. The paper establishes a formal connection between feedback differential amplification in analog circuits and iterative cross-modal feature refinement in neural networks. That connection is not decorative — it provides a principled derivation showing that the iterative feedback loop is equivalent to computing relation-map differences between the attention matrices of the two modalities. This gives the method a theoretical grounding that most fusion approaches lack.
The practical implication is that IRDFusion gives practitioners a framework for thinking about what fusion should accomplish. Not just: “how do I combine two feature maps?” but: “how do I amplify what is different between them while canceling what is the same?” That reframing has implications for any domain where two sensors are capturing related but distinct aspects of the same scene — RGB+depth, visible+LiDAR, radar+camera. The differential feedback principle is transferable.
The plug-and-play design matters too. Fusion research often produces methods that only work in carefully constructed end-to-end pipelines, making comparison difficult and deployment even harder. IRDFusion fits cleanly between a backbone and a detection head, works across at least two very different detection frameworks, and delivers consistent improvements in both cases. That kind of generalizability is hard-earned and genuinely useful for practitioners who don’t want to redesign their entire detection stack to get better nighttime performance.
The remaining challenges — computational efficiency and occluded small objects — are real, but they point toward a productive research agenda. Lightweight approximations of the differential feedback mechanism, more efficient attention implementations, and multi-scale versions of MFRM are all natural extensions. What the paper establishes is that the core principle — iterative differential guidance as a feedback loop — is worth building on.
Complete End-to-End IRDFusion Implementation (PyTorch)
The following is a complete, runnable PyTorch implementation of IRDFusion, organized into 9 labeled sections that map directly to the paper’s architecture. It covers the dual ViT backbone, the full MFRM with adaptive fusion weights, the DFFM iterative differential feedback loop, the full IRDFusion module with four iterations, the SFP neck, the Co-DETR-style detection head with four loss functions, a multi-spectral dataset loader, the training loop, and a smoke test that verifies the full forward and backward pass with dummy data.
# ==============================================================================
# IRDFusion: Iterative Relation-Map Difference Guided Feature Fusion
# for Multispectral Object Detection
# Paper: arXiv:2509.09085v2 | Jiangsu University, 2025
# Authors: Jifeng Shen, Haibo Zhan, Xin Zuo, Heng Fan, Xiaohui Yuan et al.
# Code: https://github.com/61s61min/IRDFusion.git
# ==============================================================================
# Sections:
# 1. Imports & Configuration
# 2. Dual ViT Backbone (frozen-compatible dual-branch feature extractor)
# 3. MFRM — Mutual Feature Refinement Module (Eq. 1–4)
# 4. DFFM — Differential Feature Feedback Module (Eq. 5–9)
# 5. IRDFusion Module (4 iterations of MFRM + DFFM + NiN fusion)
# 6. SFP Neck (Simple Feature Pyramid)
# 7. Co-DETR-style Detection Head with Full Loss Functions
# 8. Full IRDFusion Detection Model
# 9. Dataset, Training Loop & Smoke Test
# ==============================================================================
from __future__ import annotations
import math
import warnings
from typing import Dict, List, Optional, Tuple
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import Tensor
from torch.utils.data import DataLoader, Dataset
warnings.filterwarnings("ignore")
# ─── SECTION 1: Configuration ─────────────────────────────────────────────────
class IRDConfig:
"""
IRDFusion configuration.
Defaults match the paper's Co-DETR + ViT setting on FLIR (640x640).
Pass tiny=True for quick smoke tests with reduced dimensions.
"""
# Backbone
embed_dim: int = 256 # token dimension (use 768 for ViT-Base)
num_heads: int = 8
num_layers: int = 4
patch_size: int = 16
img_size: int = 640
# IRDFusion
num_iter: int = 4 # optimal per ablation Table 5
# Detection
num_classes: int = 3 # FLIR: person, car, bicycle
num_queries: int = 100 # DETR-style object queries
fpn_out_ch: int = 256
# Training
lr: float = 1e-4
weight_decay: float = 0.01
epochs: int = 12
batch_size: int = 1 # paper uses batch_size=1
def __init__(self, tiny: bool = False, **kwargs):
if tiny:
self.embed_dim = 64
self.num_heads = 4
self.num_layers = 2
self.img_size = 64
self.num_queries = 20
self.fpn_out_ch = 64
for k, v in kwargs.items():
setattr(self, k, v)
# ─── SECTION 2: Dual ViT Backbone ─────────────────────────────────────────────
class ViTBlock(nn.Module):
"""Single Vision Transformer block: LN → MHSA → LN → MLP."""
def __init__(self, dim: int, num_heads: int, mlp_ratio: float = 4.0):
super().__init__()
self.norm1 = nn.LayerNorm(dim)
self.attn = nn.MultiheadAttention(dim, num_heads, batch_first=True)
self.norm2 = nn.LayerNorm(dim)
mlp_h = int(dim * mlp_ratio)
self.mlp = nn.Sequential(
nn.Linear(dim, mlp_h), nn.GELU(), nn.Linear(mlp_h, dim)
)
def forward(self, x: Tensor) -> Tensor:
x_n = self.norm1(x)
x = x + self.attn(x_n, x_n, x_n)[0]
x = x + self.mlp(self.norm2(x))
return x
class SingleBranchViT(nn.Module):
"""
Lightweight ViT branch for one modality (RGB or IR).
Patch-embeds the input, adds positional encoding, and runs
through num_layers transformer blocks.
Returns token sequence (B, N_patches, D).
"""
def __init__(self, cfg: IRDConfig, in_ch: int = 3):
super().__init__()
n_patches = (cfg.img_size // cfg.patch_size) ** 2
self.patch_embed = nn.Conv2d(
in_ch, cfg.embed_dim, cfg.patch_size, stride=cfg.patch_size
)
self.pos_embed = nn.Parameter(torch.zeros(1, n_patches, cfg.embed_dim))
self.blocks = nn.ModuleList([
ViTBlock(cfg.embed_dim, cfg.num_heads)
for _ in range(cfg.num_layers)
])
self.norm = nn.LayerNorm(cfg.embed_dim)
nn.init.trunc_normal_(self.pos_embed, std=0.02)
def forward(self, x: Tensor) -> Tuple[Tensor, int, int]:
"""
x: (B, C, H, W)
Returns: tokens (B, N, D), patch_H, patch_W
"""
B, C, H, W = x.shape
x = self.patch_embed(x) # (B, D, H', W')
H_p, W_p = x.shape[2], x.shape[3]
x = x.flatten(2).transpose(1, 2) # (B, N, D)
x = x + self.pos_embed[:, :x.size(1)]
for blk in self.blocks:
x = blk(x)
return self.norm(x), H_p, W_p
class DualBranchBackbone(nn.Module):
"""
Dual-branch backbone (Section 3.1).
Two identical ViT branches — one for RGB, one for IR.
Returns (F_rgb, F_ir, H_patch, W_patch).
"""
def __init__(self, cfg: IRDConfig):
super().__init__()
self.rgb_branch = SingleBranchViT(cfg)
self.ir_branch = SingleBranchViT(cfg)
def forward(self, rgb: Tensor, ir: Tensor) -> Tuple[Tensor, Tensor, int, int]:
F_rgb, H_p, W_p = self.rgb_branch(rgb)
F_ir, _, _ = self.ir_branch(ir)
return F_rgb, F_ir, H_p, W_p
# ─── SECTION 3: MFRM — Mutual Feature Refinement Module ───────────────────────
class AdaptiveFusionWeight(nn.Module):
"""
Learnable adaptive fusion weight λ (Section 3.2, Eq. 3).
λ_i = exp(λ_q1 · λ_k1) - exp(λ_q2 · λ_k2) + λ_init
Inspired by differential transformers [Ye et al., 2024].
Allows the model to adaptively scale cross-modal Value blending
based on input characteristics — stronger weighting when one
modality provides significantly more information than the other.
"""
def __init__(self, dim: int):
super().__init__()
head_dim = max(1, dim // 8)
# Differential weight vectors (per-head, averaged over dim)
self.lq1 = nn.Parameter(torch.zeros(head_dim))
self.lk1 = nn.Parameter(torch.zeros(head_dim))
self.lq2 = nn.Parameter(torch.zeros(head_dim))
self.lk2 = nn.Parameter(torch.zeros(head_dim))
self.l_init = nn.Parameter(torch.ones(1) * 0.5)
nn.init.normal_(self.lq1, std=0.01)
nn.init.normal_(self.lk1, std=0.01)
nn.init.normal_(self.lq2, std=0.01)
nn.init.normal_(self.lk2, std=0.01)
def forward(self) -> Tensor:
"""Returns scalar fusion weight λ."""
term1 = torch.exp((self.lq1 * self.lk1).sum())
term2 = torch.exp((self.lq2 * self.lk2).sum())
return (term1 - term2 + self.l_init).clamp(0, 2)
class MFRM(nn.Module):
"""
Mutual Feature Refinement Module (Section 3.2, Eq. 1–4).
Enhances feature representations through cross-modal Value blending
within a self-attention framework.
For each modality:
1. Compute Q, K, V via separate learned projections (Eq. 1)
2. Compute self-attention matrix A_i from own Q, K (Eq. 1)
3. Blend own V with cross-modal V using learnable weight λ (Eq. 2–3)
4. Apply attention matrix to fused V → refined output F'_i (Eq. 4)
5. LN + Dropout residual + FFN
The key innovation: attention routing stays intra-modal (self-attention map)
but VALUE information flows cross-modally. This preserves spatial attention
patterns while injecting complementary sensor information.
"""
def __init__(self, dim: int, num_heads: int = 8):
super().__init__()
self.num_heads = num_heads
self.head_dim = max(1, dim // num_heads)
self.scale = self.head_dim ** -0.5
self.dim = dim
# Separate projections for each modality
self.wq_v = nn.Linear(dim, dim)
self.wk_v = nn.Linear(dim, dim)
self.wv_v = nn.Linear(dim, dim)
self.wq_t = nn.Linear(dim, dim)
self.wk_t = nn.Linear(dim, dim)
self.wv_t = nn.Linear(dim, dim)
# Adaptive fusion weights for value blending (Eq. 3)
self.lambda_v = AdaptiveFusionWeight(dim)
self.lambda_t = AdaptiveFusionWeight(dim)
# Output projections
self.out_v = nn.Linear(dim, dim)
self.out_t = nn.Linear(dim, dim)
# Post-attention: LN + Dropout + FFN
self.ln_v = nn.LayerNorm(dim)
self.ln_t = nn.LayerNorm(dim)
self.drop = nn.Dropout(0.1)
ffn_h = dim * 4
self.ffn_v = nn.Sequential(nn.Linear(dim, ffn_h), nn.GELU(), nn.Linear(ffn_h, dim))
self.ffn_t = nn.Sequential(nn.Linear(dim, ffn_h), nn.GELU(), nn.Linear(ffn_h, dim))
self.ffn_ln_v = nn.LayerNorm(dim)
self.ffn_ln_t = nn.LayerNorm(dim)
def _compute_attention(self, Q: Tensor, K: Tensor) -> Tensor:
"""Scaled dot-product attention matrix (no value multiplication yet)."""
B, N, D = Q.shape
nh = self.num_heads
hd = D // nh
Q = Q.reshape(B, N, nh, hd).permute(0, 2, 1, 3)
K = K.reshape(B, N, nh, hd).permute(0, 2, 1, 3)
attn = (Q @ K.transpose(-2, -1)) * self.scale # (B, nh, N, N)
return attn.softmax(dim=-1)
def _apply_attn_to_value(self, A: Tensor, V: Tensor) -> Tensor:
"""Apply attention matrix A to Value V, reshape back to (B, N, D)."""
B, nh, N, _ = A.shape
hd = self.head_dim
V = V.reshape(B, N, nh, hd).permute(0, 2, 1, 3)
out = (A @ V).transpose(1, 2).reshape(B, N, nh * hd)
return out
def forward(self, Fv: Tensor, Ft: Tensor) -> Tuple[Tensor, Tensor]:
"""
Fv, Ft: (B, N, D) — RGB and IR token sequences
Returns F'_v, F'_t — cross-modal amplified features (B, N, D)
"""
# Step 1: Project to Q, K, V for each modality (Eq. 1)
Qv, Kv, Vv = self.wq_v(Fv), self.wk_v(Fv), self.wv_v(Fv)
Qt, Kt, Vt = self.wq_t(Ft), self.wk_t(Ft), self.wv_t(Ft)
# Intra-modal self-attention matrices (Eq. 1)
Av = self._compute_attention(Qv, Kv) # A_v: attends within RGB
At = self._compute_attention(Qt, Kt) # A_t: attends within IR
# Step 2: Adaptive cross-modal Value blending (Eq. 2–3)
lv = self.lambda_v() # scalar: how much IR-Value to inject into RGB
lt = self.lambda_t() # scalar: how much RGB-Value to inject into IR
Vfv = Vv + lv * Vt # V_f_v: RGB Value enriched with IR (Eq. 2)
Vft = Vt + lt * Vv # V_f_t: IR Value enriched with RGB (Eq. 2)
# Step 3: Cross-modal amplified output (Eq. 4)
# Attention routing is intra-modal; values are cross-modal
F_prime_v = self.out_v(self._apply_attn_to_value(Av, Vfv))
F_prime_t = self.out_t(self._apply_attn_to_value(At, Vft))
# Residual + LN + Dropout (standard transformer post-attn)
F_prime_v = self.ln_v(Fv + self.drop(F_prime_v))
F_prime_t = self.ln_t(Ft + self.drop(F_prime_t))
# FFN
F_prime_v = self.ffn_ln_v(F_prime_v + self.ffn_v(F_prime_v))
F_prime_t = self.ffn_ln_t(F_prime_t + self.ffn_t(F_prime_t))
return F_prime_v, F_prime_t
# ─── SECTION 4: DFFM — Differential Feature Feedback Module ───────────────────
class DFFM(nn.Module):
"""
Differential Feature Feedback Module (Section 3.3, Eq. 5–9).
Inspired by differential feedback amplifier circuits. Computes the
inter-modal differential feature (what IR uniquely knows that RGB doesn't)
and feeds it back to update the RGB features for the next MFRM iteration.
For the RGB branch (symmetric logic applies to IR branch):
F_diff_v = F'_t − β · F'_v (differential signal, Eq. 5)
F^(k+1)_v = μ·F^(k)_v + α·MLP(LN(F_diff_v)) (feedback update, Eq. 5)
The IR branch features F_t are held FIXED during RGB branch refinement
(and vice versa), matching the paper's formulation in Eq. 5.
Learnable parameters:
α: controls how strongly differential guidance updates current features
β: controls how aggressively to compute the difference
μ: controls how much of the current features to preserve (identity path)
"""
def __init__(self, dim: int):
super().__init__()
# Learnable scalar parameters α, β, μ (Eq. 5)
self.alpha_v = nn.Parameter(torch.ones(1) * 0.5)
self.beta_v = nn.Parameter(torch.ones(1) * 0.5)
self.mu_v = nn.Parameter(torch.ones(1) * 0.9)
self.alpha_t = nn.Parameter(torch.ones(1) * 0.5)
self.beta_t = nn.Parameter(torch.ones(1) * 0.5)
self.mu_t = nn.Parameter(torch.ones(1) * 0.9)
# LN + MLP for processing differential features
self.ln_diff_v = nn.LayerNorm(dim)
self.ln_diff_t = nn.LayerNorm(dim)
self.mlp_v = nn.Sequential(
nn.Linear(dim, dim * 4), nn.GELU(), nn.Linear(dim * 4, dim)
)
self.mlp_t = nn.Sequential(
nn.Linear(dim, dim * 4), nn.GELU(), nn.Linear(dim * 4, dim)
)
def forward(
self,
Fv_k: Tensor, # F^(k)_v: current RGB features
Ft_k: Tensor, # F^(k)_t: current IR features (held fixed)
Fpv_k: Tensor, # F'^(k)_v: MFRM-refined RGB output
Fpt_k: Tensor, # F'^(k)_t: MFRM-refined IR output
) -> Tuple[Tensor, Tensor]:
"""
Computes feedback-updated features for next MFRM iteration.
RGB update: guided by IR-RGB differential
IR update: guided by RGB-IR differential
Returns (F^(k+1)_v, F^(k+1)_t)
"""
# Differential features (Eq. 5)
# F_diff_v captures what IR knows that RGB does not
F_diff_v = Fpt_k - self.beta_v * Fpv_k # IR minus β·RGB
F_diff_t = Fpv_k - self.beta_t * Fpt_k # RGB minus β·IR
# Process differential features through LN + MLP (Eq. 5)
guidance_v = self.mlp_v(self.ln_diff_v(F_diff_v))
guidance_t = self.mlp_t(self.ln_diff_t(F_diff_t))
# Feedback update: preserve current features + inject guidance (Eq. 5)
Fv_next = self.mu_v * Fv_k + self.alpha_v * guidance_v
Ft_next = self.mu_t * Ft_k + self.alpha_t * guidance_t
return Fv_next, Ft_next
# ─── SECTION 5: IRDFusion Module ──────────────────────────────────────────────
class NiNFusion(nn.Module):
"""
Network-in-Network (NiN) fusion: concatenates RGB and IR token sequences
along the channel dimension, then projects back to embed_dim via 1×1 conv.
Used as the final fusion step after the iterative MFRM+DFFM loop.
"""
def __init__(self, dim: int):
super().__init__()
self.proj = nn.Sequential(
nn.Linear(dim * 2, dim * 2), nn.GELU(),
nn.Linear(dim * 2, dim), nn.LayerNorm(dim)
)
def forward(self, Fv: Tensor, Ft: Tensor) -> Tensor:
"""
Fv, Ft: (B, N, D)
Returns: (B, N, D) fused feature
"""
return self.proj(torch.cat([Fv, Ft], dim=-1))
class IRDFusionModule(nn.Module):
"""
Full IRDFusion Module (Section 3.4).
Integrates MFRM and DFFM into a unified iterative framework with
n_iter=4 cycles (optimal per ablation Table 5 in the paper).
Forward pass for each iteration k:
1. MFRM(F^(k)_v, F^(k)_t) → F'^(k)_v, F'^(k)_t (cross-modal refinement)
2. DFFM(F^(k), F'^(k)) → F^(k+1)_v, F^(k+1)_t (differential feedback)
After n_iter iterations:
- NiN fusion of F^(n)_v + F^(n)_t → F_fused
- Returns F_fused, F_rgb_final, F_ir_final for three detection heads
The relation-map difference interpretation (Eq. 6–8) shows that
Fv-t = C_(v-t)2v · Vv − C_(t-v)2t · Vt
where C terms are differences of intra-modal attention maps, proving
the mechanism performs common-mode rejection at the attention level.
"""
def __init__(self, cfg: IRDConfig):
super().__init__()
self.n_iter = cfg.num_iter
dim = cfg.embed_dim
# One MFRM per iteration (each has its own learned parameters)
self.mfrm_layers = nn.ModuleList([
MFRM(dim, cfg.num_heads) for _ in range(cfg.num_iter)
])
# One DFFM per iteration
self.dffm_layers = nn.ModuleList([
DFFM(dim) for _ in range(cfg.num_iter)
])
# Final NiN fusion layer
self.nin_fusion = NiNFusion(dim)
def forward(self, Fv: Tensor, Ft: Tensor) -> Tuple[Tensor, Tensor, Tensor]:
"""
Fv, Ft: (B, N, D) — backbone features for RGB and IR
Returns:
F_fused: (B, N, D) — fused RGB+IR features for main head
F_rgb: (B, N, D) — RGB-only features for RGB head
F_ir: (B, N, D) — IR-only features for IR head
"""
Fv_k, Ft_k = Fv, Ft
for k in range(self.n_iter):
# Step 1: MFRM — cross-modal value blending within self-attention
Fpv_k, Fpt_k = self.mfrm_layers[k](Fv_k, Ft_k)
# Step 2: DFFM — compute differential signal, feed back to update
Fv_k, Ft_k = self.dffm_layers[k](Fv_k, Ft_k, Fpv_k, Fpt_k)
# Final fusion via NiN (concatenate + project)
F_fused = self.nin_fusion(Fv_k, Ft_k)
return F_fused, Fv_k, Ft_k # fused, RGB-refined, IR-refined
# ─── SECTION 6: SFP Neck (Simple Feature Pyramid) ─────────────────────────────
class SFPNeck(nn.Module):
"""
Simple Feature Pyramid (SFP) Neck (Section 3.1).
Takes a single-scale token sequence from IRDFusion and produces
a multi-scale feature pyramid for the detection head.
Reshapes tokens back to 2D spatial maps, then generates P3, P4, P5
via lateral projections and top-down upsampling — matching the
double-co-detr framework used in the paper [Zhou et al., 2024].
"""
def __init__(self, in_dim: int, out_ch: int, H_p: int, W_p: int):
super().__init__()
self.H_p = H_p
self.W_p = W_p
self.in_dim = in_dim
# Lateral 1×1 projections to out_ch
self.lat3 = nn.Conv2d(in_dim, out_ch, 1)
self.lat4 = nn.Conv2d(in_dim, out_ch, 1)
self.lat5 = nn.Conv2d(in_dim, out_ch, 1)
# Top-down fusion convolutions
self.fuse54 = nn.Sequential(nn.Conv2d(out_ch*2, out_ch, 3, padding=1), nn.ReLU())
self.fuse43 = nn.Sequential(nn.Conv2d(out_ch*2, out_ch, 3, padding=1), nn.ReLU())
# Downsampling to create P4, P5 from base tokens
self.down4 = nn.Conv2d(in_dim, in_dim, kernel_size=2, stride=2)
self.down5 = nn.Sequential(
nn.Conv2d(in_dim, in_dim, kernel_size=2, stride=2),
nn.Conv2d(in_dim, in_dim, kernel_size=2, stride=2),
)
def forward(self, tokens: Tensor) -> List[Tensor]:
"""
tokens: (B, N, D) — IRDFusion output
Returns: [P3, P4, P5] — multi-scale feature maps (B, out_ch, H_i, W_i)
"""
B, N, D = tokens.shape
H, W = self.H_p, self.W_p
x = tokens.transpose(1, 2).reshape(B, D, H, W)
# Create 3 scales by downsampling base feature map
x3 = x # 1× scale (H/patch, W/patch)
x4 = self.down4(x) # 2× downsampled
x5 = self.down5(x) # 4× downsampled (or as much as spatial allows)
# Lateral projections
p3 = self.lat3(x3)
p4 = self.lat4(x4)
p5 = self.lat5(x5)
# Top-down FPN fusion (P5→P4→P3)
p4 = self.fuse54(torch.cat([
F.interpolate(p5, size=p4.shape[-2:], mode='bilinear', align_corners=False), p4
], dim=1))
p3 = self.fuse43(torch.cat([
F.interpolate(p4, size=p3.shape[-2:], mode='bilinear', align_corners=False), p3
], dim=1))
return [p3, p4, p5]
# ─── SECTION 7: Detection Head & Loss Functions ───────────────────────────────
class QualityFocalLoss(nn.Module):
"""
Quality Focal Loss for classification (Section 3.5).
Balances learning from easy and hard examples by down-weighting
well-classified examples via the (1-p)^γ factor.
"""
def __init__(self, beta: float = 2.0):
super().__init__()
self.beta = beta
def forward(self, pred: Tensor, target: Tensor, weight: Optional[Tensor] = None) -> Tensor:
"""
pred: (N, C) — predicted class logits
target: (N, C) — soft targets (quality-weighted one-hot)
"""
pred_sig = pred.sigmoid()
scale = (pred_sig - target).abs() ** self.beta
loss = F.binary_cross_entropy_with_logits(pred, target, reduction='none')
loss = (scale * loss)
if weight is not None:
loss = loss * weight.unsqueeze(-1)
return loss.mean()
class GIoULoss(nn.Module):
"""
Generalized IoU Loss for bounding box regression (Section 3.5).
Improves over standard IoU by penalizing non-overlapping boxes
based on their distance from the enclosing box.
"""
def forward(self, pred_boxes: Tensor, gt_boxes: Tensor) -> Tensor:
"""
pred_boxes, gt_boxes: (N, 4) in [cx, cy, w, h] normalized format.
Returns scalar GIoU loss.
"""
# Convert to [x1, y1, x2, y2]
def cxcywh_to_xyxy(b):
x1 = b[..., 0] - b[..., 2] / 2
y1 = b[..., 1] - b[..., 3] / 2
x2 = b[..., 0] + b[..., 2] / 2
y2 = b[..., 1] + b[..., 3] / 2
return torch.stack([x1, y1, x2, y2], dim=-1)
p = cxcywh_to_xyxy(pred_boxes)
g = cxcywh_to_xyxy(gt_boxes)
inter_x1 = torch.max(p[..., 0], g[..., 0])
inter_y1 = torch.max(p[..., 1], g[..., 1])
inter_x2 = torch.min(p[..., 2], g[..., 2])
inter_y2 = torch.min(p[..., 3], g[..., 3])
inter_area = (inter_x2 - inter_x1).clamp(0) * (inter_y2 - inter_y1).clamp(0)
area_p = (p[..., 2] - p[..., 0]).clamp(0) * (p[..., 3] - p[..., 1]).clamp(0)
area_g = (g[..., 2] - g[..., 0]).clamp(0) * (g[..., 3] - g[..., 1]).clamp(0)
union = area_p + area_g - inter_area + 1e-7
iou = inter_area / union
enclosing_x1 = torch.min(p[..., 0], g[..., 0])
enclosing_y1 = torch.min(p[..., 1], g[..., 1])
enclosing_x2 = torch.max(p[..., 2], g[..., 2])
enclosing_y2 = torch.max(p[..., 3], g[..., 3])
enclosing_area = (enclosing_x2 - enclosing_x1).clamp(0) * \
(enclosing_y2 - enclosing_y1).clamp(0) + 1e-7
giou = iou - (enclosing_area - union) / enclosing_area
return (1 - giou).mean()
class IRDFusionDetectionHead(nn.Module):
"""
DETR-style detection head (Section 3.1, following Double-Co-DETR [35]).
Three parallel heads: RGB-only, IR-only, RGB+IR fused.
Each head:
- Object queries attend over multi-scale FPN features
- Predicts class logits (C+1) and bounding boxes (4)
Loss components (Section 3.5):
Main head: Quality Focal Loss (cls) + L1 + GIoU (box)
Aux heads: Cross-Entropy (cls) + GIoU (box)
"""
def __init__(self, cfg: IRDConfig):
super().__init__()
D = cfg.fpn_out_ch
Q = cfg.num_queries
C = cfg.num_classes
# Learnable object queries (same for all three heads)
self.queries_fused = nn.Embedding(Q, D)
self.queries_rgb = nn.Embedding(Q, D)
self.queries_ir = nn.Embedding(Q, D)
# Cross-attention transformer (queries attend over FPN features)
self.cross_attn = nn.MultiheadAttention(D, num_heads=8, batch_first=True)
self.self_attn = nn.MultiheadAttention(D, num_heads=8, batch_first=True)
self.ffn_head = nn.Sequential(nn.Linear(D, D*4), nn.GELU(), nn.Linear(D*4, D))
self.norm1 = nn.LayerNorm(D)
self.norm2 = nn.LayerNorm(D)
self.norm3 = nn.LayerNorm(D)
# Classification and regression heads
self.cls_head = nn.Linear(D, C + 1) # +1 background
self.box_head = nn.Sequential(nn.Linear(D, D), nn.ReLU(), nn.Linear(D, 4), nn.Sigmoid())
# Loss functions
self.qfl_loss = QualityFocalLoss()
self.giou_loss = GIoULoss()
self.ce_loss = nn.CrossEntropyLoss()
def _decode_queries(self, queries: Tensor, memory: Tensor) -> Tuple[Tensor, Tensor]:
"""Run cross-attention + self-attention + FFN on object queries."""
B = memory.shape[0]
q = queries.weight.unsqueeze(0).expand(B, -1, -1)
# Self-attention among queries
q2, _ = self.self_attn(q, q, q)
q = self.norm1(q + q2)
# Cross-attention: queries attend to FPN memory
q2, _ = self.cross_attn(q, memory, memory)
q = self.norm2(q + q2)
# FFN
q = self.norm3(q + self.ffn_head(q))
logits = self.cls_head(q) # (B, Q, C+1)
boxes = self.box_head(q) # (B, Q, 4)
return logits, boxes
def forward(
self,
fpn_fused: List[Tensor], # multi-scale FPN features (fused)
fpn_rgb: List[Tensor], # multi-scale FPN features (RGB)
fpn_ir: List[Tensor], # multi-scale FPN features (IR)
) -> Dict[str, Tensor]:
"""
Flatten multi-scale FPN features to token sequences,
run three detection heads, return all predictions.
"""
def flatten_fpn(fpn: List[Tensor]) -> Tensor:
# Flatten and concatenate all scale levels to (B, N_total, D)
tokens = []
for fm in fpn:
B, C, H, W = fm.shape
tokens.append(fm.flatten(2).transpose(1, 2))
return torch.cat(tokens, dim=1)
mem_fused = flatten_fpn(fpn_fused)
mem_rgb = flatten_fpn(fpn_rgb)
mem_ir = flatten_fpn(fpn_ir)
logits_fused, boxes_fused = self._decode_queries(self.queries_fused, mem_fused)
logits_rgb, boxes_rgb = self._decode_queries(self.queries_rgb, mem_rgb)
logits_ir, boxes_ir = self._decode_queries(self.queries_ir, mem_ir)
return {
'logits_fused': logits_fused, 'boxes_fused': boxes_fused,
'logits_rgb': logits_rgb, 'boxes_rgb': boxes_rgb,
'logits_ir': logits_ir, 'boxes_ir': boxes_ir,
}
def compute_loss(
self,
outputs: Dict[str, Tensor],
gt_labels: Tensor, # (B, Q) int class indices
gt_boxes: Tensor, # (B, Q, 4) normalized cx,cy,w,h
) -> Dict[str, Tensor]:
"""
Computes CoDetr-style combined loss across all three heads.
Main head: Quality Focal + L1 + GIoU
Aux heads: CE + GIoU
"""
losses = {}
B, Q_gt = gt_labels.shape
for head_name, logits_key, boxes_key, is_main in [
('fused', 'logits_fused', 'boxes_fused', True),
('rgb', 'logits_rgb', 'boxes_rgb', False),
('ir', 'logits_ir', 'boxes_ir', False),
]:
logits = outputs[logits_key] # (B, Q_pred, C+1)
boxes = outputs[boxes_key] # (B, Q_pred, 4)
Q_pred = logits.shape[1]
C = logits.shape[-1] - 1
# Classification loss
tgt_cls = gt_labels.reshape(-1).clamp(0, C)
if is_main:
# Quality Focal Loss for main CoDINO head
logits_flat = logits.reshape(-1, C + 1)[: B * Q_gt]
tgt_soft = F.one_hot(tgt_cls[:B*Q_gt], C + 1).float()
l_cls = self.qfl_loss(logits_flat, tgt_soft)
else:
# Cross-Entropy for auxiliary heads
logits_flat = logits.reshape(-1, C + 1)[: B * Q_gt]
l_cls = self.ce_loss(logits_flat, tgt_cls[:B*Q_gt])
# Box regression: L1 + GIoU
boxes_flat = boxes.reshape(-1, 4)[: B * Q_gt]
gt_boxes_flat = gt_boxes.reshape(-1, 4)[:B*Q_gt]
l_l1 = F.l1_loss(boxes_flat, gt_boxes_flat)
l_giou = self.giou_loss(boxes_flat, gt_boxes_flat)
losses[f'cls_{head_name}'] = l_cls
losses[f'l1_{head_name}'] = l_l1
losses[f'giou_{head_name}'] = l_giou
# Total loss: main head weighted 1.0, auxiliary weighted 0.5
total = (
losses['cls_fused'] + losses['l1_fused'] + losses['giou_fused']
+ 0.5 * (losses['cls_rgb'] + losses['l1_rgb'] + losses['giou_rgb'])
+ 0.5 * (losses['cls_ir'] + losses['l1_ir'] + losses['giou_ir'])
)
losses['total'] = total
return losses
# ─── SECTION 8: Full IRDFusion Detection Model ────────────────────────────────
class IRDFusionDetector(nn.Module):
"""
Complete IRDFusion Multispectral Object Detector.
Pipeline:
1. Dual ViT backbone extracts F_rgb, F_ir token sequences
2. Flat&PE: tokens are already flat with positional encoding from backbone
3. IRDFusion module runs 4×(MFRM + DFFM) → F_fused, F_rgb_ref, F_ir_ref
4. Reshape each branch back to 2D spatial maps
5. SFP neck generates multi-scale FPN features for all three branches
6. Three parallel DETR-style detection heads predict boxes and classes
7. Loss combines Quality Focal (main) + CE (aux) + L1 + GIoU
This matches the architecture in Figure 2 of the paper:
- ViT(RGB) + ViT(IR) → IRDFusion → SFP Neck → Co-DETR Heads
- Three detection outputs: RGB-only, IR-only, RGB+IR fused
"""
def __init__(self, cfg: Optional[IRDConfig] = None):
super().__init__()
cfg = cfg or IRDConfig()
self.cfg = cfg
H_p = cfg.img_size // cfg.patch_size
W_p = cfg.img_size // cfg.patch_size
self.backbone = DualBranchBackbone(cfg)
self.irdfusion = IRDFusionModule(cfg)
self.sfp_fused = SFPNeck(cfg.embed_dim, cfg.fpn_out_ch, H_p, W_p)
self.sfp_rgb = SFPNeck(cfg.embed_dim, cfg.fpn_out_ch, H_p, W_p)
self.sfp_ir = SFPNeck(cfg.embed_dim, cfg.fpn_out_ch, H_p, W_p)
self.det_head = IRDFusionDetectionHead(cfg)
def forward(
self,
rgb: Tensor, # (B, 3, H, W)
ir: Tensor, # (B, 3, H, W)
) -> Dict[str, Tensor]:
"""Full forward pass. Returns detection output dict."""
# Step 1: Extract backbone features
F_rgb, F_ir, H_p, W_p = self.backbone(rgb, ir)
# Step 2: IRDFusion — 4 iterations of MFRM + DFFM (Eq. 1–9)
F_fused, F_rgb_ref, F_ir_ref = self.irdfusion(F_rgb, F_ir)
# Step 3: SFP neck for multi-scale features (3 branches)
fpn_fused = self.sfp_fused(F_fused)
fpn_rgb = self.sfp_rgb(F_rgb_ref)
fpn_ir = self.sfp_ir(F_ir_ref)
# Step 4: Three parallel detection heads
outputs = self.det_head(fpn_fused, fpn_rgb, fpn_ir)
return outputs
def compute_loss(
self,
outputs: Dict[str, Tensor],
gt_labels: Tensor,
gt_boxes: Tensor,
) -> Dict[str, Tensor]:
return self.det_head.compute_loss(outputs, gt_labels, gt_boxes)
# ─── SECTION 9: Dataset, Training Loop & Smoke Test ──────────────────────────
class SyntheticMultispectralDataset(Dataset):
"""
Synthetic RGB+IR multispectral dataset for testing IRDFusion.
Each sample returns an aligned RGB/IR image pair with annotations.
Replace with real loaders:
FLIR: https://www.flir.com/oem/adas/adas-dataset-form/
LLVIP: https://github.com/bupt-ai-cz/LLVIP
M3FD: https://github.com/JinyuanLiu-CV/TarDAL (M3FD subset)
"""
def __init__(
self,
n: int = 80,
img_size: int = 64,
num_queries: int = 20,
num_classes: int = 3,
):
self.n = n
self.img_size = img_size
self.num_queries = num_queries
self.num_classes = num_classes
def __len__(self): return self.n
def __getitem__(self, idx):
S = self.img_size
rgb = torch.randn(3, S, S)
ir = torch.randn(3, S, S)
gt_labels = torch.randint(0, self.num_classes, (self.num_queries,))
gt_boxes = torch.rand(self.num_queries, 4).clamp(0.05, 0.95)
return rgb, ir, gt_labels, gt_boxes
def train_one_epoch(
model: IRDFusionDetector,
loader: DataLoader,
optimizer: torch.optim.Optimizer,
device: torch.device,
epoch: int,
) -> float:
"""Standard single-epoch training loop for IRDFusion."""
model.train()
total = 0.0
for step, (rgb, ir, gt_labels, gt_boxes) in enumerate(loader):
rgb = rgb.to(device)
ir = ir.to(device)
gt_labels = gt_labels.to(device)
gt_boxes = gt_boxes.to(device)
optimizer.zero_grad()
outputs = model(rgb, ir)
losses = model.compute_loss(outputs, gt_labels, gt_boxes)
loss = losses['total']
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
total += loss.item()
if step % 5 == 0:
print(f" Epoch {epoch} | Step {step}/{len(loader)} | Loss {total/(step+1):.4f}")
return total / max(1, len(loader))
def run_training(epochs: int = 2, device_str: str = "cpu") -> IRDFusionDetector:
"""
Full training pipeline for IRDFusion (tiny config for demonstration).
Production: CoDetr framework, batch_size=1, 12 epochs on FLIR/LLVIP,
36 epochs on M3FD, data aug from Double-Co-DETR v1.
"""
device = torch.device(device_str)
cfg = IRDConfig(tiny=True)
model = IRDFusionDetector(cfg).to(device)
params = sum(p.numel() for p in model.parameters()) / 1e6
print(f"Model params: {params:.2f}M")
dataset = SyntheticMultispectralDataset(
n=40, img_size=cfg.img_size, num_queries=cfg.num_queries, num_classes=cfg.num_classes
)
loader = DataLoader(dataset, batch_size=4, shuffle=True, num_workers=0)
opt = torch.optim.AdamW(model.parameters(), lr=cfg.lr, weight_decay=cfg.weight_decay)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(opt, T_max=epochs)
print(f"\n{'='*55}")
print(f" IRDFusion Training | {epochs} epochs | {device}")
print(f" Embed dim: {cfg.embed_dim} | Iter: {cfg.num_iter} | Classes: {cfg.num_classes}")
print(f"{'='*55}\n")
for epoch in range(1, epochs + 1):
avg = train_one_epoch(model, loader, opt, device, epoch)
scheduler.step()
print(f"Epoch {epoch}/{epochs} — Avg Loss: {avg:.4f}\n")
print("Training complete.")
return model
# ─── SMOKE TEST ────────────────────────────────────────────────────────────────
if __name__ == "__main__":
print("=" * 60)
print(" IRDFusion — Full Architecture Smoke Test")
print("=" * 60)
torch.manual_seed(42)
# ── 1. Build tiny model ──────────────────────────────────────────────────
print("\n[1/5] Instantiating tiny IRDFusion detector...")
cfg = IRDConfig(tiny=True)
model = IRDFusionDetector(cfg)
params = sum(p.numel() for p in model.parameters()) / 1e6
print(f" Parameters: {params:.3f}M")
# ── 2. Forward pass ─────────────────────────────────────────────────────
print("\n[2/5] Forward pass with dummy RGB+IR pair...")
B = 2
rgb_in = torch.randn(B, 3, cfg.img_size, cfg.img_size)
ir_in = torch.randn(B, 3, cfg.img_size, cfg.img_size)
outputs = model(rgb_in, ir_in)
for k, v in outputs.items():
print(f" {k}: {tuple(v.shape)}")
# ── 3. Loss computation ──────────────────────────────────────────────────
print("\n[3/5] Loss computation check...")
gt_labels = torch.randint(0, cfg.num_classes, (B, cfg.num_queries))
gt_boxes = torch.rand(B, cfg.num_queries, 4).clamp(0.1, 0.9)
losses = model.compute_loss(outputs, gt_labels, gt_boxes)
print(f" Total loss: {losses['total'].item():.4f}")
print(f" Breakdown: cls_fused={losses['cls_fused'].item():.3f}, "
f"giou_fused={losses['giou_fused'].item():.3f}, "
f"l1_fused={losses['l1_fused'].item():.3f}")
# ── 4. Backward pass ────────────────────────────────────────────────────
print("\n[4/5] Backward pass check...")
losses['total'].backward()
grad_params = [p for p in model.parameters() if p.grad is not None]
print(f" Params with gradient: {len(grad_params)} / {sum(1 for _ in model.parameters())}")
# ── 5. Short training run ────────────────────────────────────────────────
print("\n[5/5] Short training run (2 epochs)...")
run_training(epochs=2, device_str="cpu")
print("\n" + "=" * 60)
print("✓ All checks passed. IRDFusion is ready for use.")
print("=" * 60)
print("""
Next steps for full production training:
1. Load paired FLIR/LLVIP dataset:
https://www.flir.com/oem/adas/adas-dataset-form/
https://github.com/bupt-ai-cz/LLVIP
→ Wrap in a proper Dataset with COCO-format annotations
2. Load pretrained ViT-Base weights (DINOv2 recommended):
import timm
vit = timm.create_model('vit_base_patch16_224.dino', pretrained=True)
→ Transfer weights to SingleBranchViT blocks
3. Configure Double-Co-DETR framework from [35]:
https://arxiv.org/abs/2411.18288
→ Use their SFP neck and full Co-DETR head for exact paper reproduction
4. Training settings from paper:
FLIR/LLVIP: 12 epochs, batch_size=1, AdamW lr=1e-4
M3FD: 36 epochs, same settings
RTX 3090 24GB, 640×640, data aug v1 from Double-Co-DETR
5. Evaluate with COCO mAP toolkit:
pip install pycocotools
→ Compute mAP50, mAP75, mAP (0.5:0.95)
""")
Paper & Official Code
The full IRDFusion paper with ablation studies, visualization results, and failure-case analysis is available on arXiv. Official code will be released at GitHub once officially published.
Shen, J., Zhan, H., Zuo, X., Fan, H., Yuan, X., Li, J., & Yang, W. (2025). IRDFusion: Iterative Relation-Map Difference Guided Feature Fusion for Multispectral Object Detection. arXiv:2509.09085v2 [cs.CV].
This article is an independent editorial analysis of peer-reviewed research. The PyTorch implementation is an educational adaptation of the methods described in the paper. For exact reproduction of benchmark results, refer to the official GitHub repository and the Double-Co-DETR framework.
Explore More on AI Trend Blend
If this article sparked your interest, here is more of what we cover across the site — from foundational deep learning tutorials to the latest research in computer vision and autonomous perception.