Why Your Machine Learning Model Gets Stuck — And How New Math Finally Fixes It
A research team from three major U.S. universities has proven for the first time that bilevel optimization algorithms can reliably escape saddle points and find true local minima — solving a problem that has quietly undermined meta-learning, hyperparameter tuning, and adversarial training for years.
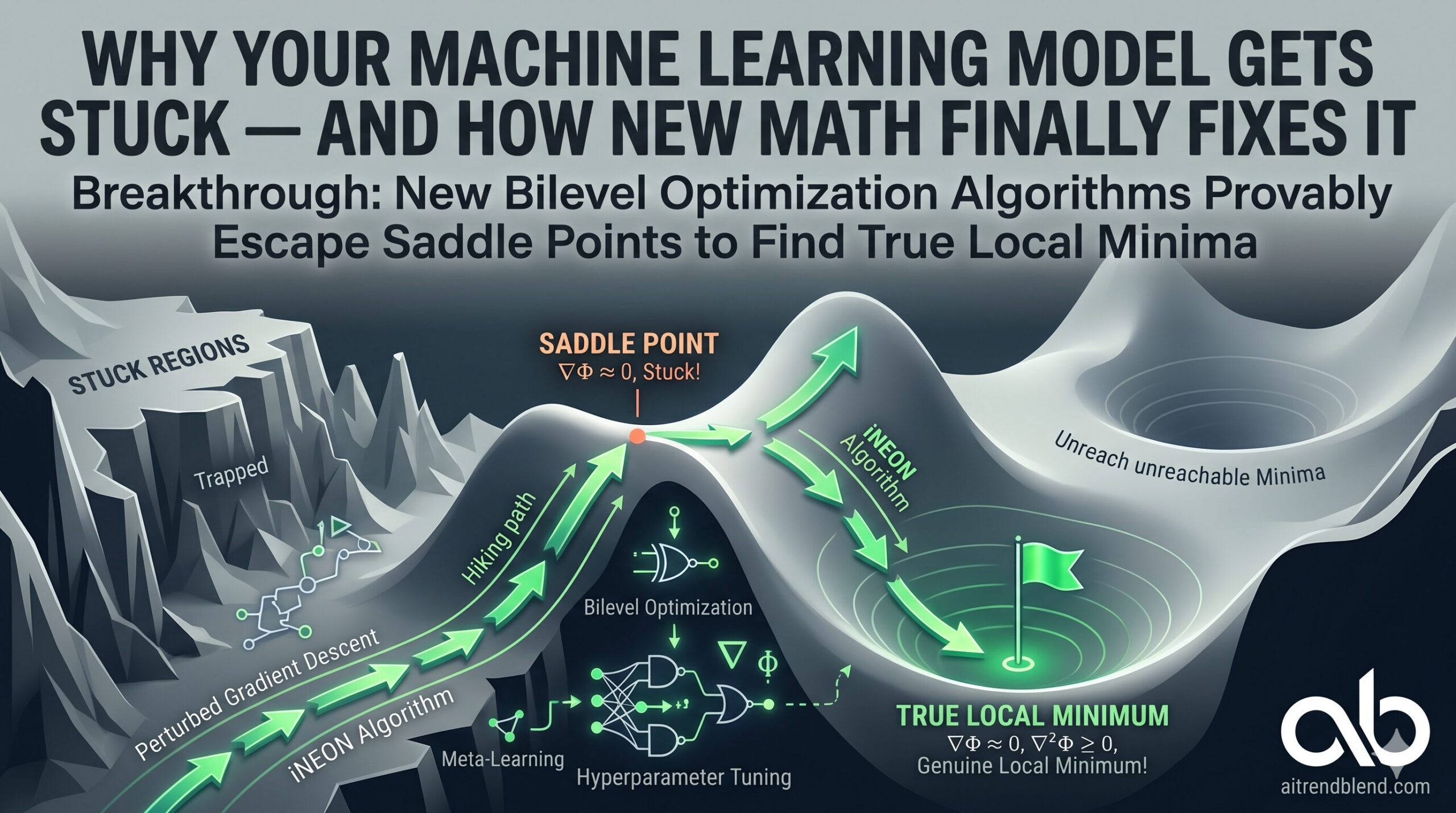
Picture a mountain landscape covered in fog. Your hiking algorithm is trying to reach the lowest valley, but it keeps getting stranded on saddle-shaped ridges — spots that look flat in every direction but are actually neither a peak nor a valley. This is the saddle point problem, and for years it has quietly trapped machine learning models in mediocre solutions. This paper proves, with full mathematical guarantees, that you can always find your way out — even in the highly complex terrain of bilevel optimization.
The Hidden Problem That Quietly Breaks Your Models
If you have ever trained a machine learning model that seemed to stop improving despite running for hundreds of iterations, you may have met a saddle point without knowing it. Saddle points are locations in a loss landscape where the gradient is zero — meaning gradient descent stalls — but the point is not actually a minimum. It is a flat, deceptive plateau surrounded by directions that go both upward and downward.
For standard, single-level optimization problems, the research community has spent the last decade building solid mathematical tools for escaping these traps. Perturbed gradient descent, for example, adds small random noise when it detects a near-zero gradient, which is usually enough to kick the algorithm off a saddle and onto a productive descent path. The theory behind this is mature and well understood.
But bilevel optimization is a fundamentally different animal. Instead of minimizing one function, you are optimizing a function whose value itself depends on the solution of a second, inner optimization problem. Formally, you want to minimize Φ(x) = f(x, y*(x)), where y*(x) is the solution to a separate inner problem: minimize g(x, y) over y. These nested problems appear everywhere in modern machine learning — in meta-learning, where the outer problem sets shared initialization and the inner problem adapts to each task; in hyperparameter optimization, where the outer problem tunes learning rates and regularizers while the inner problem trains the model; and in adversarial training, where the outer problem minimizes loss while the inner problem maximizes it.
The critical difficulty in bilevel optimization is that you can never directly compute the gradient of Φ(x). You have to approximate it using information from the inner problem, and that approximation introduces error. This error is usually manageable when you just want to find a stationary point — somewhere the gradient is close to zero. But escaping saddle points is a much stronger requirement. You need to verify not just that the gradient is small but also that the curvature in every direction is non-negative. That second-order condition is extremely sensitive to approximation errors, and until this paper, nobody had proven that bilevel optimization algorithms could satisfy it.
Every existing bilevel optimization algorithm was only guaranteed to find a point where the gradient is small — what mathematicians call a first-order stationary point. But stationary points include saddle points, and saddle points are not real solutions. They are traps. This paper provides the first algorithms guaranteed to escape those traps and reach genuine local minima, with a proof that works even under the noisy gradient approximations that bilevel optimization requires.
What Bilevel Optimization Actually Is — And Why It Matters
The bilevel optimization problem studied in this paper has the following structure. The outer, or upper-level, objective is to minimize Φ(x) = f(x, y*(x)) over x in Rᵈ, where y*(x) is the solution to the inner, or lower-level, problem of minimizing g(x, y) over y. The lower-level function g is assumed to be strongly convex in y, which guarantees that y*(x) is uniquely defined for every choice of x. The outer function f may be nonconvex in x, which is where the difficulty lives.
Computing the gradient of Φ(x) requires the chain rule through y*(x), which gives:
This formula involves two computationally expensive pieces: the exact inner solution y*(x), which requires running the inner optimizer to convergence, and the inverse Hessian [∇²ᵧᵧg]⁻¹, which is an n-by-n matrix inversion. In practice, both are approximated. The Approximate Implicit Differentiation (AID) approach approximates the Hessian inverse using a finite number of steps of the conjugate gradient method, and approximates y*(x) using a fixed number of gradient descent steps on the inner problem. The resulting estimated gradient ∇̂Φ(x) differs from the true ∇Φ(x) by an error that can be controlled but never completely eliminated.
The applications of this framework reach across the most active areas of modern machine learning. In meta-learning, the goal is to find an initialization x that allows rapid adaptation across many tasks — the outer loop optimizes the initialization while each inner loop adapts to one task. In hyperparameter optimization, x represents the hyperparameters and y represents the model weights trained under those hyperparameters. In reinforcement learning, bilevel structure arises naturally in actor-critic methods. The nested structure is not an exotic mathematical curiosity; it is the natural form of many real-world learning problems.
Why Saddle Points Are So Dangerous in Practice
It is tempting to think that a stationary point with a near-zero gradient is good enough. After all, if the gradient is tiny, the model is not moving much — how far can it be from a real minimum? The answer is: very far. Research on the loss surfaces of deep neural networks has shown that these landscapes are riddled with saddle points in high dimensions, and that many of these saddle points have loss values significantly higher than any local minimum. Getting stuck at one means your model is objectively worse than it could be.
The mathematical definition of the quality guarantee the paper proves is called an ε-local minimum. A point x qualifies as an ε-local minimum if two conditions hold simultaneously: the gradient norm ‖∇Φ(x)‖ is at most ε, and the smallest eigenvalue of the Hessian ∇²Φ(x) is at least −√(ρ_φ · ε). The second condition rules out saddle points — at a saddle, at least one eigenvalue of the Hessian is significantly negative, reflecting the direction in which the function curves downward. If you can guarantee a non-negative Hessian spectrum, you have genuinely escaped the saddle.
“Saddle points can seriously undermine the quality of solutions. Finding an ε-local minimum — a point that genuinely avoids saddle structure — is much stronger than merely converging to a stationary point, and it is much more challenging in the bilevel setting because the hypergradient approximation error interacts with the second-order conditions in nontrivial ways.” — Huang, Chen, Ji, Ma & Lai · JMLR 26 (2025)
The core difficulty is that proving the Hessian condition requires controlling approximation errors at a finer level than first-order methods naturally provide. When you perturb the iterate and check whether the function value decreases over the next T steps, you are implicitly checking whether the curvature in the perturbation direction is negative. If your gradient estimates are noisy, the test may fail even at a genuine saddle, or pass even at a good point. Controlling this interaction between approximation error and second-order geometry is the central technical challenge the paper resolves.
The Perturbed AID Algorithm — Escaping Saddles in Deterministic Bilevel Problems
The first main contribution is the perturbed Approximate Implicit Differentiation algorithm, or perturbed AID, which provably finds ε-local minima of deterministic bilevel problems. The algorithm follows a clean conceptual structure. At each outer iteration, it runs D steps of gradient descent on the inner problem to approximate y*(x), then solves the linear system for the Hessian inverse using N steps of the conjugate gradient method, and uses those approximations to construct the estimated hypergradient ∇̂Φ(x). The outer iterate x is then updated by one step of gradient descent using this estimated hypergradient.
The saddle-escaping mechanism activates when the estimated gradient norm falls below a threshold — signaling that the algorithm may be near a stationary point. At that moment, the algorithm adds random noise drawn uniformly from a ball of radius r centered at the current iterate. It then runs for at least T more steps before allowing another perturbation. The key insight, borrowed from the non-bilevel literature and carefully adapted to the bilevel setting, is that if the current point is a saddle, the random noise will almost certainly land in a direction along which the Hessian has a negative eigenvalue, and the function value will decrease by a guaranteed amount F over the next T steps. If the function value does not decrease that much, the algorithm concludes that the current point already has non-negative Hessian spectrum — making it a local minimum, not a saddle.
Under standard smoothness assumptions, with inner loop length D = O(κ log ε⁻¹) and conjugate gradient steps N = O(√κ log ε⁻¹), the perturbed AID algorithm finds an ε-local minimum of Φ(x) with probability at least 1 − δ in at most
K = Õ(κ³ ε⁻²) iterations
where κ is the condition number of the lower-level problem. The gradient complexity for f is Õ(κ³ ε⁻²) and for g is Õ(κ⁴ ε⁻²). Jacobian-vector and Hessian-vector product complexities are Õ(κ³ ε⁻²) and Õ(κ³·⁵ ε⁻²) respectively.
The proof of this result rests on two key lemmas. The first is the Inexact Descent Lemma, which shows that even with approximation error in the gradient, each step of the algorithm decreases the function value by a guaranteed amount proportional to the squared gradient norm, minus a term proportional to the squared approximation error. This establishes that the algorithm makes real progress whenever the gradient is not too small. The second is the Escaping Saddle Points Lemma, which shows that if the current point is near a saddle (small gradient but negative Hessian eigenvalue), then with high probability over the random perturbation, the function value decreases by at least F/2 within T steps. Combining these two lemmas, and bounding the number of perturbation events by the total function decrease divided by F, gives the final complexity bound.
A Bonus Result — The First Nonasymptotic Guarantee for Minimax Problems
Minimax optimization is a special case of bilevel optimization that deserves its own discussion because of how widely it appears in machine learning. Generative Adversarial Networks, adversarial robustness training, and optimal transport all reduce to problems of the form: minimize over x the function max over y of f(x, y), where f is nonconvex in x and strongly concave in y. These are exactly the problems where a generator tries to fool a discriminator, or where a model tries to be robust against the worst possible input perturbation.
The paper establishes a beautiful theoretical connection for this setting: the strict local minima of the outer function Φ(x) = max_y f(x, y) are exactly the strict local minimax points of the original minimax problem, as defined by Jin et al. (2020). Saddle points of Φ(x) cannot be strict local Nash equilibria. This means that finding a local minimum of Φ is the right mathematical goal, not just a convenient proxy.
Prior Work — Second-Order Methods
Chen et al. and Luo & Chen proved convergence to local minimax points using cubic-regularized gradient descent ascent. These methods require Hessian computations and solving nonconvex subproblems at each step — expensive and hard to scale to large models.
This Paper — Perturbed GDmax
The perturbed GDmax algorithm is a pure first-order method with no Hessian computations, no nonconvex subproblems, and a nonasymptotic convergence rate of Õ(κ²ε⁻²) gradient evaluations. This is the first such result in the minimax optimization literature.
The perturbed GDmax algorithm works by running D steps of gradient ascent in the inner loop to approximately solve the max-player problem, then using the result to estimate the outer gradient, and then adding perturbations using exactly the same mechanism as in the perturbed AID algorithm. Because the minimax setting does not require solving a linear system for a Hessian inverse — the inner problem is just gradient ascent — the algorithm is simpler, and the dependency on the condition number improves from κ³ to κ². The key improvement is that a third-order smoothness assumption on g, which is needed for the bilevel case, is not required for the minimax case. This matches the stronger structural guarantees that strong concavity in y provides.
Training a GAN is fundamentally a minimax problem. Mode collapse and training instability in GANs are often attributed to the generator getting stuck at saddle points of the outer objective. The perturbed GDmax algorithm provides the first first-order method with a mathematical guarantee that this cannot happen — that the training process will reach a local minimax point in a bounded number of steps with high probability. This is not just theoretical progress; it is a foundation for more stable GAN training algorithms.
The iNEON Algorithm — Bringing Saddle-Escaping to Stochastic Bilevel Problems
The deterministic perturbed AID algorithm is powerful, but many real-world bilevel problems are stochastic — the functions f and g are expectations over random data, and you can only evaluate them through random mini-batches. The stochastic setting introduces a new complication: even if you wanted to detect a saddle point by checking whether the Hessian has a negative eigenvalue, you cannot compute the Hessian exactly. You only have noisy estimates.
To handle this, the paper introduces the inexact NEgative-curvature-Originated-from-Noise algorithm, or iNEON. The idea behind NEON-style algorithms is elegant: instead of explicitly computing the Hessian, use the power method to extract the direction of the most negative curvature. The power method iterates matrix-vector products, and Hessian-vector products can be computed cheaply using automatic differentiation without ever forming the full Hessian matrix. The “noise” in NEON refers to the fact that random initialization of the power method is all you need to find the negative-curvature direction with high probability.
The inexact version, iNEON, adapts this idea to the bilevel setting where you cannot compute exact Hessian-vector products either — only noisy estimates through the hypergradient approximation. The iNEON update rule is:
This is essentially running gradient descent on the shifted objective Φ(x̃ + u) − Φ(x̃), where x̃ is the suspected saddle point. If the Hessian at x̃ has a sufficiently negative eigenvalue, the iterates u_k will grow in the direction of that negative eigenvalue, revealing the escape direction. The key technical result is that the approximation error in ∇̂Φ can be controlled tightly enough that iNEON still extracts the correct direction with high probability, even though it never accesses the exact gradient.
Under stochastic smoothness assumptions with bounded gradient variance σ², combining iNEON with the StocBiO algorithm finds an ε-local minimum of the stochastic bilevel problem with high probability in at most
K = Õ(κ³ ε⁻²) outer iterations
with total gradient evaluation complexities G(f,ε) = O(κ⁵ε⁻⁴) and G(g,ε) = Õ(κ¹⁰ε⁻⁴). The Jacobian- and Hessian-vector product complexities are Õ(κ⁹ε⁻⁴) and Õ(κ⁹·⁵ε⁻⁴) respectively. This is the first algorithm that provably finds local minima for stochastic bilevel optimization.
The iNEON algorithm is integrated into the StocBiO framework as a module that activates whenever the stochastic gradient norm drops below the first-order threshold. When iNEON returns a nonzero direction u_out, the outer iterate is updated by a step in that direction, guaranteed to decrease the function value. When iNEON returns zero, it certifies with high probability that the Hessian is sufficiently positive — meaning the current point is already a local minimum, not a saddle. The algorithm then terminates successfully.
What the Experiments Show
The paper validates both algorithms on carefully chosen numerical experiments designed to expose saddle-point trapping in a controlled way.
For the deterministic case, the authors use a bilevel adaptation of the Du et al. (2017) saddle-point benchmark, which constructs a function with exactly d known saddle points and one known local minimum at (4τ, 4τ, …, 4τ). This setup makes it possible to track precisely whether an algorithm escapes each saddle point. The learning curves for the perturbed AID algorithm (labeled PBO in the figures) and the standard AID-BiO baseline show a characteristic staircase pattern — long flat stretches where the algorithm is stuck at a saddle, followed by sharp vertical drops when it escapes. The perturbed AID algorithm escapes each saddle dramatically faster than the baseline, across all combinations of problem dimension d and parameters L and γ tested.
For the stochastic case, the experiments use symmetric matrix sensing, a well-studied problem where the goal is to recover a low-rank matrix from noisy linear measurements. This problem is reformulated as a stochastic bilevel problem and compared between StocBiO alone and StocBiO with iNEON. Both algorithms get stuck near a saddle in the early iterations, but StocBiO with iNEON escapes it substantially faster, reaching a solution closer to the true ground-truth matrix in the same number of iterations.
The flat-then-sharp staircase pattern in the learning curves is the visual signature of saddle-point trapping. The experiments confirm that the perturbed algorithms not only escape saddles faster in theory but also do so clearly and consistently in practice. The improvements are not marginal — in many settings, the baseline algorithm requires hundreds of additional iterations to escape a saddle that the perturbed version exits in a handful of steps.
The Key Technical Hurdles — What Makes This Proof Hard
The apparent simplicity of the perturbation idea — add noise, run T steps, check the function value — conceals substantial technical depth. Three specific challenges make the bilevel setting harder than the standard nonconvex minimization setting where saddle-escaping was previously analyzed.
The first challenge is Hessian Lipschitz continuity of the outer function Φ(x). In standard nonconvex optimization, this is often just assumed. In the bilevel setting, it must be derived from smoothness properties of f and g. The paper proves that Φ inherits Hessian Lipschitz continuity with constant ρ_φ = O(κ⁵), a fifth-power dependence on the condition number that reflects the complicated chain of composition through y*(x). This derivation requires carefully bounding how the solution map y*(x) and its first and second derivatives vary as x changes, using third-order smoothness of g as a key ingredient.
The second challenge is controlling the hypergradient approximation error at the level needed for the second-order saddle-detection test. For first-order stationarity, an approximation error of order ε/5 suffices. For the saddle-escaping test, the error must be small enough that it does not interfere with the geometric argument about how the iterate difference x_k − x’_k grows along the negative-curvature direction. The warm-start strategy — initializing the inner loop at the output of the previous inner loop — is essential for keeping this error under control across iterations without blowing up the inner loop length.
The third challenge is the probabilistic analysis of the stuck region. The proof shows that the set of perturbation directions that fail to escape a saddle — the “stuck region” — has small volume relative to the perturbation ball. Specifically, its width along the direction of minimum curvature is at most ηω, where ω grows only logarithmically with the dimension. This geometric argument, combined with the uniform distribution of the perturbation, gives the high-probability guarantee. Adapting this argument to handle the approximation errors in the bilevel setting requires showing that the geometric properties of the stuck region are not disturbed by the noise in the gradient estimates.
What This Paper Changes for Practitioners
For researchers and practitioners working with bilevel optimization in deep learning, this paper changes something fundamental about what you can claim about your algorithm’s output. Previously, you could only say that your optimizer converged to a stationary point — a location where the gradient is approximately zero. You had no guarantee that this was a local minimum rather than a saddle. In high-dimensional problems, where saddle points are abundant, this uncertainty was not theoretical nitpicking; it was a real source of failure modes.
With the algorithms in this paper, you can now claim convergence to a local minimum — a point that is not just stationary but also has non-negative curvature in all directions. This is a qualitatively stronger guarantee, and it comes at a surprisingly modest cost: the perturbed AID algorithm has the same asymptotic complexity as the original AID algorithm up to logarithmic factors, and the perturbation step is trivial to implement — just sample a uniform random vector and add it to the current iterate.
The practical implications extend across the main application areas. In meta-learning, convergence to local minima rather than saddles means better initialization quality and more reliable few-shot adaptation. In hyperparameter optimization, it means that the tuned hyperparameters are more likely to represent genuinely good configurations rather than degenerate solutions. In adversarial training, the minimax results mean that the trained model is more likely to represent a genuine local Nash equilibrium of the adversarial game rather than an unstable saddle.
Read the Full Paper
Published in the Journal of Machine Learning Research, Volume 26 (2025). Full proofs, algorithm pseudocode, and experimental details are freely available via JMLR’s open-access repository.
Minhui Huang, Xuxing Chen, Kaiyi Ji, Shiqian Ma, Lifeng Lai. Efficiently Escaping Saddle Points in Bilevel Optimization. Journal of Machine Learning Research, 26 (2025) 1–61. http://jmlr.org/papers/v26/22-0136.html
This article is an independent editorial analysis of a peer-reviewed paper. Mathematical statements paraphrase the original results; for complete proofs and precise formulations, please consult the published paper. The paper was submitted February 2022, revised January 2025, and published January 2025.
References
- [1] Z. Allen-Zhu and Y. Li. NEON2: Finding local minima via first-order oracles. Advances in Neural Information Processing Systems, 2018.
- [2] T. Chen, Y. Sun, Q. Xiao, and W. Yin. A single-timescale method for stochastic bilevel optimization. AISTATS, 2022.
- [3] Z. Chen, Q. Li, and Y. Zhou. Escaping saddle points in nonconvex minimax optimization via cubic-regularized gradient descent-ascent. arXiv:2110.07098, 2021.
- [4] S. Du, C. Jin, M. Jordan, B. Póczos, A. Singh, and J. Lee. Gradient descent can take exponential time to escape saddle points. NeurIPS, 2017.
- [5] T. Fiez, L. Ratliff, E. Mazumdar, et al. Global convergence to local minmax equilibrium in classes of nonconvex zero-sum games. NeurIPS, 2021.
- [6] L. Franceschi, P. Frasconi, S. Salzo, R. Grazzi, and M. Pontil. Bilevel programming for hyperparameter optimization and meta-learning. ICML, 2018.
- [7] S. Ghadimi and M. Wang. Approximation methods for bilevel programming. arXiv:1802.02246, 2018.
- [8] M. Hong, H.-T. Wai, Z. Wang, and Z. Yang. A two-timescale framework for bilevel optimization. arXiv:2007.05170, 2020.
- [9] C. Jin, P. Netrapalli, and M. Jordan. What is local optimality in nonconvex-nonconcave minimax optimization? ICML, 2020.
- [10] C. Jin, P. Netrapalli, R. Ge, S. Kakade, and M. Jordan. On nonconvex optimization for machine learning. Journal of the ACM, 68(2):1–29, 2021.
- [11] K. Ji, J. Yang, and Y. Liang. Bilevel optimization: Convergence analysis and enhanced design. ICML, 2021.
- [12] L. Luo and C. Chen. Finding second-order stationary point for nonconvex-strongly-concave minimax problem. arXiv:2110.04814, 2021.
- [13] Y. Xu, R. Jin, and T. Yang. First-order stochastic algorithms for escaping from saddle points in almost linear time. NeurIPS, 2018.