Introduction: Bridging the Gap Between AI and Precision Pathology
In the evolving landscape of medical imaging, Hierarchical Vision Transformers (H-ViT) are emerging as a game-changer in prostate biopsy grading , offering unprecedented accuracy and generalizability. Traditional deep learning models have struggled with real-world variability, but H-ViTs are setting new benchmarks by combining self-supervised pretraining, weakly supervised learning, and enhanced model interpretability.
This article explores 7 groundbreaking insights from recent research on AI-based prostate cancer grading , focusing on how H-ViT architectures outperform conventional methods and address critical challenges like generalization across clinical settings , label order exploitation , and interpretable decision-making .
1. The Rise of Weakly Supervised Learning in Medical Imaging
What Is Weakly Supervised Learning?
Weakly supervised learning leverages slide-level labels instead of pixel-level annotations to train deep learning models. This approach is particularly valuable in pathology, where manual annotation is labor-intensive and often impractical.
Why It Matters for Prostate Cancer Diagnosis
- Scalability : Reduces the need for extensive labeled datasets.
- Real-world applicability : Models trained this way can generalize better across diverse clinical environments.
- Cost-effectiveness : Saves time and resources in data preparation.
“Campanella et al. (2019) showed that weakly supervised models can match fully supervised ones when given sufficient data.”
2. Self-Supervised Pretraining: Unlocking Better Feature Representations
How Does Self-Supervised Pretraining Work?
Models like DINO (Deeper Inspection) allow networks to learn meaningful representations without human-labeled data. By training on large-scale histopathological images such as those from The Cancer Genome Atlas (TCGA) , these models develop robust feature extractors.
Key Findings from the Study
- Limited performance when pretrained on general cancer types due to low representation of prostate samples (~4%).
- Custom pretraining on prostate biopsies significantly improves downstream task performance.
Equation: Attention Score Normalization
Let’s formalize the attention score aggregation used in H-ViT:
$$a(x,y) = \frac{1}{N} \sum_{i=1}^{N} a_i(x,y)$$
Where ai(x,y) is the attention score at pixel (x,y) from the i-th Transformer layer.
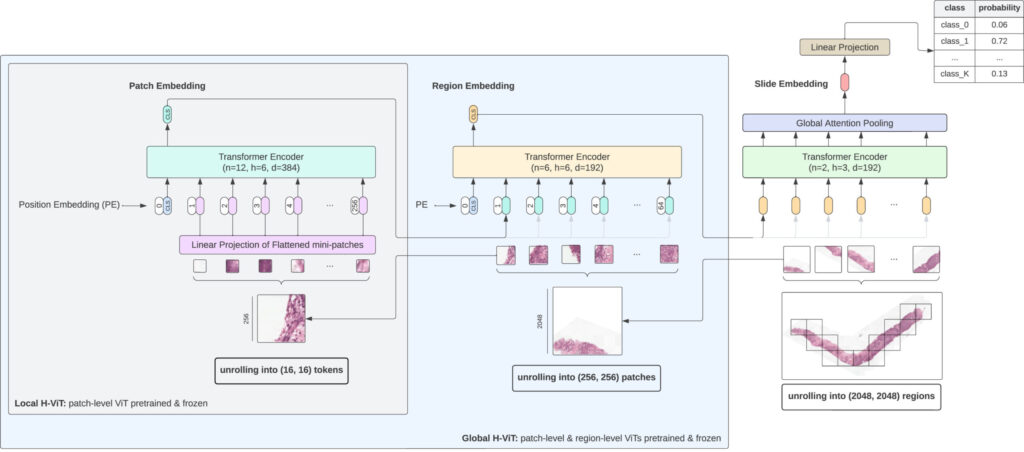
3. Hierarchical Vision Transformers: A Multi-Level Approach to Context Integration
Understanding the H-ViT Architecture
Unlike traditional convolutional neural networks (CNNs), H-ViTs operate on multiple scales—patch level, region level, and slide level—to capture both fine-grained cellular details and macroscopic tissue architecture .
Advantages Over Patch-Based Methods
| FEATURE | PATCH-BASED CNNs | H-ViT |
|---|---|---|
| Context awareness | Limited | High |
| Scalability | Moderate | Excellent |
| Interpretability | Low | High |
“Chen et al. (2022) demonstrated that H-ViTs achieve state-of-the-art results in cancer subtyping and survival prediction.”
4. Enhancing Model Interpretability with Factorized Attention Heatmaps
Why Interpretability Is Crucial in Clinical AI
Medical professionals require transparent reasoning behind AI decisions. Black-box models face resistance unless their outputs can be validated and understood.
How H-ViT Improves Explainability
By combining attention scores from multiple hierarchical levels using a factorized heatmap approach , H-ViT provides:
- Task-specific insights : Highlights regions most relevant to prostate cancer grading.
- Dynamic visualization : Adjust focus between cell-level and region-level features via parameter γ .
Equation: Factorized Attention Map
$$a(x,y) = \beta \cdot \sum_{i=1}^{N} a_i(x,y)\left[\gamma(1 – F(T_i)) + (1 – \gamma)F(T_i)\right]$$
Where F(Ti) indicates whether the i-th Transformer was fine-tuned or frozen, and β is a normalization constant.
5. Leveraging Label Order: Treating Grading as Regression
The Problem with Categorical Cross-Entropy (CE)
Traditional CE loss treats ISUP grades as independent classes, ignoring their ordinal nature. This leads to inefficient learning and poor calibration.
Regression-Based Grading Using MSE Loss
| METRIC | CE LOSS | MSE LOSS |
|---|---|---|
| Quadratic Weighted Kappa | 0.62 | 0.78 |
| Calibration | Poor | Excellent |
| Ordinal Awareness | No | Yes |
“By leveraging label order, models gain more informative supervision signals during training.”
If you’re Interested in deep learning based Skin Cancer Detection, you may also find this article helpful: 7 Revolutionary Advancements in Skin Cancer Detection (With a Powerful New AI Tool That Outperforms Existing Models)
6. Generalization Challenges in AI-Powered Prostate Grading
Why Top Models Fail in Real-World Settings
Despite high performance on internal datasets like PANDA , many AI models struggle when deployed in multi-institutional or heterogeneous clinical settings .
Solutions Offered by H-ViT
- Robust pretraining strategies
- Context-aware attention mechanisms
- Domain adaptation techniques
“Faryna et al. (2024) found only two of five top public AI algorithms achieved decent generalization.”
7. Future Directions: Augmentation, Biomarker Discovery, and Beyond
Areas for Further Research
- Pathology-specific data augmentation during pretraining and weakly supervised stages.
- Integration with molecular profiling for multi-modal diagnosis.
- Label-specific attention maps to enhance pathologist-AI collaboration.
Potential Applications
- Biomarker discovery : Identify novel prognostic features from attention patterns.
- Personalized treatment planning : Tailor therapies based on AI-extracted tumor heterogeneity.
- Telepathology support : Enable remote diagnostics in resource-limited settings.
Conclusion: The Future of Prostate Cancer Diagnosis Is Here
Hierarchical Vision Transformers are not just another deep learning architecture—they represent a paradigm shift in how we approach medical image analysis , especially in prostate cancer grading . By bridging the gap between self-supervised learning , weakly supervised training , and clinical interpretability , H-ViT sets a new standard for accuracy, generalization, and transparency .
Whether you’re a pathologist , data scientist , or healthcare leader , the implications of this technology are profound. Embracing these advancements will be key to delivering more precise, efficient, and equitable care .
Call to Action: Ready to Transform Your Diagnostic Workflow?
Are you looking to integrate AI-powered prostate grading into your practice or research?
👉 [Download our free paper: “Hierarchical Vision Transformers for prostate biopsy grading: Towards bridging the generalization gap: From Theory to Practice”]
📘 Learn how H-ViT can improve your diagnostic accuracy and reduce inter-observer variability.
💬 Book a demo with our AI pathology experts today and see how we’re helping labs worldwide achieve faster, more consistent, and explainable diagnoses .
Frequently Asked Questions (FAQ)
Q1: What is an H-ViT?
A: Hierarchical Vision Transformers (H-ViTs) are multi-scale vision models that process images at patch, region, and whole-slide levels to capture detailed contextual information.
Q2: How does weakly supervised learning work in pathology?
A: It uses slide-level labels to train models without requiring pixel-level annotations, making it scalable and cost-effective.
Q3: Can H-ViT be applied to other cancers?
A: Yes! While this study focuses on prostate cancer, H-ViT is applicable to any cancer type with available WSI data.
Q4: How accurate is AI-based Gleason grading?
A: With proper training and validation, AI models like H-ViT achieve quadratic weighted kappas above 0.85 , rivaling expert pathologists.
Below is a simplified but functional version of the Vision Transformers (H-ViT) model in PyTorch.
import torch
import torch.nn as nn
import timm # For loading pretrained ViT models
class PatchLevelTransformer(nn.Module):
def __init__(self, pretrained_model='vit_small_patch16_224', embed_dim=384):
super().__init__()
self.vit = timm.create_model(pretrained_model, pretrained=True)
self.feature_extractor = nn.Sequential(*list(self.vit.children())[:-1]) # Remove classification head
def forward(self, x):
# x: (B, num_patches, C, H, W) -> B: batch size, num_patches: patches per region
B, N, C, H, W = x.shape
x = x.view(B * N, C, H, W) # Flatten regions and patches
features = self.feature_extractor(x) # (B*N, patch_tokens, embed_dim)
features = features.view(B, N, -1, features.size(-1)) # (B, N_regions, N_patches, D)
return features
class RegionLevelTransformer(nn.Module):
def __init__(self, embed_dim=384, depth=2, num_heads=6):
super().__init__()
self.transformer = nn.TransformerEncoder(
encoder_layer=nn.TransformerEncoderLayer(d_model=embed_dim, nhead=num_heads),
num_layers=depth
)
self.region_pool = nn.Linear(embed_dim, embed_dim)
def forward(self, x):
# x: (B, N_regions, N_patches, D)
B, N_regions, N_patches, D = x.shape
x = x.view(B * N_regions, N_patches, D) # Merge batch and region dims
x = self.transformer(x) # (B*N_regions, N_patches, D)
x = x.mean(dim=1) # Pool across patches in each region
x = self.region_pool(x) # (B*N_regions, D)
x = x.view(B, N_regions, D) # Restore region dimension
return x
class SlideLevelTransformer(nn.Module):
def __init__(self, embed_dim=384, depth=2, num_heads=6, num_classes=5):
super().__init__()
self.transformer = nn.TransformerEncoder(
encoder_layer=nn.TransformerEncoderLayer(d_model=embed_dim, nhead=num_heads),
num_layers=depth
)
self.classifier = nn.Linear(embed_dim, num_classes)
self.attention_weights = nn.Linear(embed_dim, 1) # Attention mechanism
def forward(self, x):
# x: (B, N_regions, D)
attn_weights = self.attention_weights(x).softmax(dim=1) # (B, N_regions, 1)
attended = torch.sum(attn_weights * x, dim=1) # Weighted sum across regions
logits = self.classifier(attended)
return logits, attn_weights
class HierarchicalVisionTransformer(nn.Module):
def __init__(self, num_classes=5):
super().__init__()
self.patch_level = PatchLevelTransformer()
self.region_level = RegionLevelTransformer()
self.slide_level = SlideLevelTransformer(num_classes=num_classes)
def forward(self, x):
# x: Whole slide image processed into regions and patches
x = self.patch_level(x)
x = self.region_level(x)
logits, attention_weights = self.slide_level(x)
return logits, attention_weightsExample Usage:
# Dummy input: Batch of 2 slides, each with 16 regions, each region has 16 patches of 224x224 RGB images
input_tensor = torch.randn(2, 16, 16, 3, 224, 224) # Shape: (B, N_regions, N_patches, C, H, W)
model = HierarchicalVisionTransformer(num_classes=5)
logits, attention_weights = model(input_tensor)
print("Logits shape:", logits.shape) # (2, 5)
print("Attention weights shape:", attention_weights.shape) # (2, 16, 1)Loss Function and Training Loop
from torch.optim import Adam
from torch.nn import MSELoss
# Sample targets (ISUP grades: 0 to 4)
targets = torch.tensor([1, 3], dtype=torch.float32) # Shape: (2, )
# One-hot encoding or regression target conversion
regression_targets = torch.nn.functional.one_hot(targets.long(), num_classes=5).float()
regression_targets = torch.cumsum(regression_targets, dim=1)[:, :-1] # Ordinal encoding
model = HierarchicalVisionTransformer(num_classes=5)
optimizer = Adam(model.parameters(), lr=1e-4)
criterion = MSELoss()
for epoch in range(10):
model.train()
optimizer.zero_grad()
logits, _ = model(input_tensor)
loss = criterion(logits, regression_targets)
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}, Loss: {loss.item():.4f}")References
- Grisi et al., 2023 – Hierarchical Vision Transformers for Context-Aware Prostate Cancer Grading in Whole Slide Images
- Strom et al., 2020 – AI for prostate cancer diagnosis
- Campanella et al., 2019 – Weakly supervised learning in pathology
- Faryna et al., 2024 – Generalization of AI grading models ‘in the wild’
- Caron et al., 2021 – Self-supervised learning with DINO
Pingback: 7 Astonishing Ways DIOR-ViT Transforms Cancer Grading (Avoiding Common Pitfalls) - aitrendblend.com
Pingback: 7 Unbelievable Wins & Pitfalls of Context-Aware Knowledge Distillation for Disease Prediction - aitrendblend.com
Pingback: 9 Explosive Strategies & Hidden Pitfalls in Data-Centric Directed Graph Learning - aitrendblend.com
Pingback: 5 Revolutionary Advancements in Medical Image Segmentation: How SDCL Outperforms Existing Methods (With Math Explained) - aitrendblend.com
Pingback: Bidirectional Copy-Paste Revolutionizes Semi-Supervised Medical Image Segmentation (21% Dice Improvement Achieved, but Challenges Remain) - aitrendblend.com
Pingback: 7 Powerful Problems and Solutions: Overcoming and Transforming Long-Tailed Semi-Supervised Learning with FlexDA & ADELLO - aitrendblend.com
Pingback: GenSeg: Revolutionizing Medical Image Segmentation with End-to-End Synthetic Data Generation (2025 Breakthrough) - aitrendblend.com
Pingback: 5 Revolutionary Breakthroughs in AI-Powered Cardiac Ultrasound: Unlocking Self-Supervised Learning (While Overcoming Manual Labeling Challenges) - aitrendblend.com
Pingback: 6 Groundbreaking Innovations in Diabetic Retinopathy Detection: A 2025 Breakthrough - aitrendblend.com
Pingback: 6 Groundbreaking Hybrid Features for Breast Cancer Classification: Power of AI & Machine Learning - aitrendblend.com
Pingback: 5 Revolutionary Insights from biM-CGN: Boosting Recommendation Accuracy and Diversity - aitrendblend.com
Pingback: 7 Powerful Reasons BAST-Mamba Is Revolutionizing Binaural Sound Localization — Despite the Challenges - aitrendblend.com
Pingback: 7 Revolutionary Advancements in Functional Data Clustering with Fdmclust (And What's Holding It Back) - aitrendblend.com
Pingback: Revolutionizing Lower Limb Motor Imagery Classification: A 3D-Attention MSC-T3AM Transformer Model with Knowledge Distillation - aitrendblend.com
Pingback: 7 Revolutionary Ways Event-Based Action Recognition is Changing AI (And Why It’s Not Perfect Yet) - aitrendblend.com
Pingback: 7 Powerful Insights from a Groundbreaking Study on Motion Processing and Neural Adaptation - aitrendblend.com
Pingback: 7 Groundbreaking Innovations in Deep Bi-Directional Predictive Coding (DBPC): The Future of Efficient Neural Networks - aitrendblend.com
Pingback: 7 Revolutionary Ways to Compress BERT Models Without Losing Accuracy (With Math Behind It) - aitrendblend.com
Pingback: 7 Breakthroughs: How Uncertainty-Guided AI is Revolutionizing Malaria Detection in Blood Smears (Life-Saving AI vs. Deadly Parasites!) - aitrendblend.com
Pingback: Decoding Olfactory Response with TACAF: A Breakthrough in EEG and Breathing Signal Fusion - aitrendblend.com
Pingback: UNETR++ vs. Traditional Methods: A 3D Medical Image Segmentation Breakthrough with 71% Efficiency Boost - aitrendblend.com
Pingback: EFAM-Net: The Future of Skin Lesion Classification with Enhanced Feature Fusion (2024 Breakthrough) - aitrendblend.com
Pingback: 10 Groundbreaking Innovations in Treatment-Aware Diffusion Models for Longitudinal MRI and Diffuse Glioma - aitrendblend.com
Pingback: DeepMetaForge: Revolutionizing Skin Lesion Classification with Vision-Transformers and Metadata Fusion (2023 Study) - aitrendblend.com
Pingback: 10X Faster Retinal Vessel Segmentation: How MaskVSC Eliminates Fragmentation for Superior Accuracy - aitrendblend.com
Pingback: 7 Revolutionary Graph-Transformer Breakthrough: Why This AI Model Outperforms (And What It Means for Cancer Diagnosis) - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in Cancer Survival Prediction (And 1 Critical Flaw You Can’t Ignore) - aitrendblend.com
Pingback: 7 Revolutionary Ways ConvexAdam Beats Traditional Methods (And Why Most Fail) - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs and 1 Major Challenge in Nanoscale Biosensing Using AI-Driven Capacitance Spectroscopy - aitrendblend.com
Pingback: Revolutionary Breakthroughs in Time Series Anomaly Detection — The MAAT Model That Outperforms (and 1 Fatal Flaw) - aitrendblend.com
Pingback: 11 Breakthrough Deep Learning Tricks That Eliminate Finger-Vein Recognition Failures for Good - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in Skin Cancer Detection: How a New AI Model Outperforms Experts (And Why Older Methods Fail) - aitrendblend.com
Pingback: 7 Shocking Ways Merging Korean Language Models Boosts LLM Reasoning (And 1 Dangerous Pitfall to Avoid) - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in Diabetes Tech (Why Most Fail & How This AI Model Succeeds) - aitrendblend.com
Pingback: 5 Shocking Secrets of Skin Cancer Detection: How This SSD-KD AI Method Beats the Competition (And Why Others Fail) - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in HDR Video (and the 1 Fatal Flaw Holding It Back) - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in MR Spectroscopic Imaging: How a Powerful New Method Beats Old, Inaccurate Techniques - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in MRI Super-Resolution – The Good, the Bad, and the Future of HFMT - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in Hollow Sphere Simulation: How IGA Outperforms Traditional FEA (And When It Fails) - aitrendblend.com
Pingback: 7 Revolutionary Wins & Costly Mistakes in Structural Optimization: How ASM-Powered Chaos Game Optimization (CGO) Outperforms Old Methods - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in Skin Lesion Segmentation — The Dark Truth About Traditional Methods vs. ESC-UNET’s AI Power - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in Diabetic Retinopathy Detection – How AI Is Saving Sight (And Why Most Mobile Apps Fail) - aitrendblend.com
Pingback: Revolutionary Breakthroughs in Breast Cancer Detection: The +95% Accuracy Model vs. Outdated Methods - aitrendblend.com
Pingback: 9 Revolutionary ETDHDNet Breakthrough: The Ultimate AI Tool That’s Transforming Tuberculosis Detection (And Why Older Methods Are Failing) - aitrendblend.com
Pingback: Shocking Failures of Standard AI Models (And the 1 Solution That Fixes Them All) – AdaPAC Explained - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in Continual Learning: The Rise of Adapt&Align - aitrendblend.com
Pingback: 7 Shocking Truths About Wearable AI in Healthcare: The Good, The Bad, and The Overhyped - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in AI Uncertainty Estimation: The Good, the Bad, and the Future of Trustworthy AI - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in Cancer Immunotherapy: How AI is Transforming ICD Screening - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in Thyroid Cancer AI: How DualSwinUnet++ Outperforms Old Models - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in Cardiac Motion Analysis: How a New AI Model Outperforms Old Methods (And Why It Matters) - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in NPH Diagnosis: the Future of AI-Powered Brain Scans - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in Bacteria Detection: How EmiNet Outperforms Old Methods - aitrendblend.com
Pingback: 3 Revolutionary FCS-MPDTC Breakthroughs That Slash Energy Waste in Linear Motors - aitrendblend.com
Pingback: Revolutionary Ways to Boost Compressor Efficiency by 3.2% - aitrendblend.com
Pingback: Revolutionary Breakthroughs in Skin Cancer Detection: ConvNeXtV2 & Focal Attention - aitrendblend.com
Pingback: 7 Shocking Mistakes in Knowledge Distillation (And the 1 Breakthrough Fix That Changes Everything) - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in AI Disease Grading — The Good, the Bad, and the Future of UMKD - aitrendblend.com
Pingback: 7 Shocking Breakthroughs in Spiking Neural Networks: How HTA-KL Crushes Accuracy & Efficiency - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in Knowledge Distillation: Why Swapped Logit Distillation Outperforms Old Methods - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in Endometriosis Detection: How AI is Transforming Diagnosis - aitrendblend.com
Pingback: 7 Shocking Ways AI Fails at Medical Diagnosis (And the Brilliant Fix That Saves Lives) - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in Gene Network Mapping - aitrendblend.com
Pingback: 7 Breakthrough AI Insights: How Machine Learning Predicts Glioma Grading - aitrendblend.com
Pingback: Revolutionary Breakthroughs in 3D Organ Detection: How Organ-DETR Outperforms Old Methods (+10.6 mAP Gain!) - aitrendblend.com
Pingback: 7 Revolutionary VibNet Breakthrough Detects Invisible Needles in Ultrasound – But Is It Too Good to Be True? - aitrendblend.com
Pingback: 7 Shocking Federated Learning Attacks That Could Destroy Your Network - aitrendblend.com
Pingback: 7 Breakthroughs & 1 Critical Flaw in DSCA: The Ultimate Digital Subtraction Angiography Dataset and Model for Cerebral Artery Segmentation - aitrendblend.com
Pingback: 15× Faster & Smarter: The Revolutionary One-Class Classifier Fusion That Outperforms (And What Slows Others Down) - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in Small Object Detection: The DAHI Framework - aitrendblend.com