Introduction: Breaking New Ground in Radar Image Analysis
Imagine a technology that can see through clouds, darkness, and adverse weather conditions to identify vehicles, ships, and aircraft with remarkable precision. This is the power of Synthetic Aperture Radar (SAR), and now, researchers have developed SARATR-X—the first foundation model specifically designed to revolutionize how machines understand and interpret SAR imagery.
Traditional SAR automatic target recognition (ATR) systems have been limited by their reliance on massive amounts of hand-labeled data, task-specific training, and inability to generalize across different scenarios. SARATR-X changes everything by learning from 186,600 unlabeled SAR images using self-supervised learning, creating a versatile model that excels at both classification and detection tasks without requiring extensive manual annotation.
This breakthrough represents a paradigm shift in remote sensing and defense applications, promising more efficient airport management, disaster response, maritime surveillance, and military reconnaissance. Let’s explore how SARATR-X achieves this remarkable feat and what it means for the future of SAR image interpretation.
Understanding the SAR Target Recognition Challenge
What Makes SAR Imagery Unique?
Synthetic Aperture Radar operates fundamentally differently from optical cameras. SAR systems emit microwave signals and measure the backscattered energy, creating images based on electromagnetic properties rather than visible light. This gives SAR its all-weather, day-and-night capability—but it also introduces unique challenges:
- Multiplicative speckle noise from coherent imaging degrades image quality
- Discrete target appearances with limited geometric and texture cues
- Significant domain gap between natural RGB images and SAR data
- Dynamic context ranges where small targets appear in large images
These characteristics mean that computer vision techniques designed for everyday photographs often fail when applied to SAR imagery. Models trained on ImageNet or other natural image datasets struggle to transfer their knowledge effectively to the SAR domain.
The Data Labeling Bottleneck
Current state-of-the-art SAR ATR methods achieve impressive accuracy, but at a steep cost. Each training dataset requires expert SAR analysts to meticulously annotate thousands of images—identifying vehicle types, ship classes, or aircraft models. This process is:
- Extremely time-consuming: A single dataset may take months to annotate
- Prohibitively expensive: Expert analysis comes at premium rates
- Limited in scope: Each model specializes in one narrow category
- Difficult to scale: The scarcity of experts creates a fundamental bottleneck
The MSTAR dataset, one of the most widely used benchmarks, contains only about 3,000 labeled vehicle images from a single grass scenario. While valuable, this represents a tiny fraction of the SAR data being captured daily by satellites and aircraft worldwide.
SARATR-X Architecture: Engineering Excellence for SAR
The Foundation: SARDet-180K Dataset
SARATR-X’s creators assembled SARDet-180K, the largest publicly available SAR target dataset to date, by combining 14 open-source datasets. This unprecedented collection includes:
| Category | Number of Samples | Key Features |
|---|---|---|
| Vehicles | 46,096 | Ground military and civilian targets |
| Ships | 73,973 | Maritime vessels in various conditions |
| Aircraft | 35,861 | Both stationary and taxiing planes |
| Other targets | 46,830 | Oil tanks, bridges, infrastructure |
Total diversity achieved: Multiple imaging bands (X-band, C-band), various sensors (satellite, airborne, simulated), and diverse scenes (urban, harbor, airport, ocean, inland) ensure the model encounters the full spectrum of real-world conditions.
Hierarchical Vision Transformer (HiViT) Backbone
The researchers carefully selected HiViT as SARATR-X’s architecture for several critical reasons:
Key advantages over alternatives:
- Maintains high spatial resolution without downsampling—crucial for small targets
- Hierarchical structure captures features at multiple scales
- Compatible with masked image modeling for efficient pre-training
- Superior attention diversity compared to standard Vision Transformers
Small targets in remote sensing imagery often occupy just 20-30 pixels. Traditional convolutional networks with multiple pooling layers progressively lose this critical information. HiViT’s 4×4 patch size and hierarchical design preserve fine details while building global understanding.
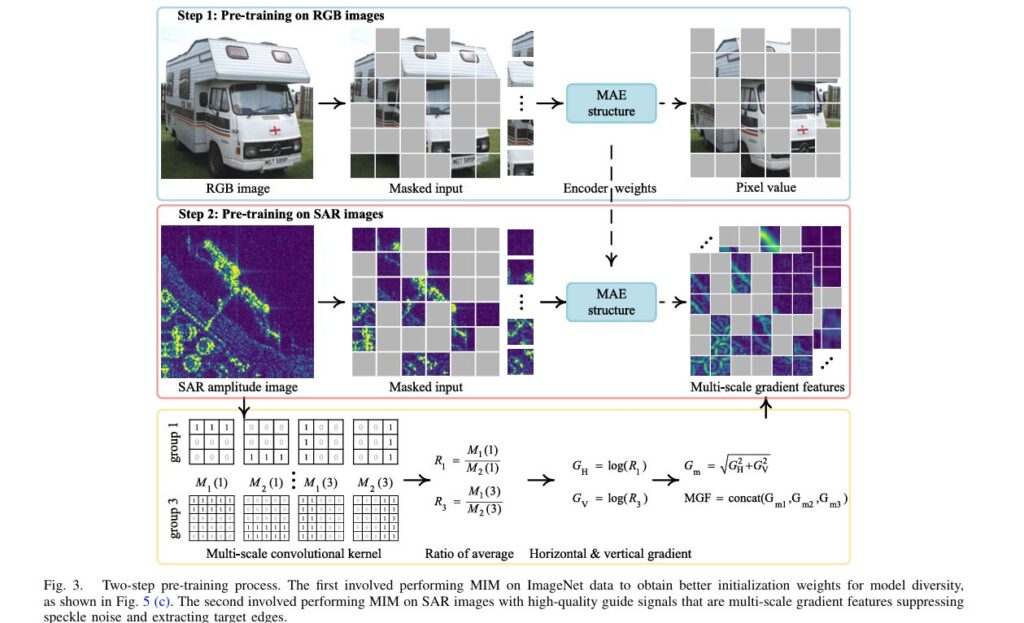
Two-Step Pre-Training Strategy: Learning from Natural and SAR Images
Step 1: ImageNet Initialization for Attention Diversity
SARATR-X employs a clever two-step approach that begins with masked image modeling (MIM) on natural images. This might seem counterintuitive—why train on ordinary photos when the goal is SAR analysis?
The answer lies in attention diversity. Natural images contain richer visual features (textures, colors, complex shapes) that help the model develop varied attention patterns across different layers. When this pre-trained model is then fine-tuned on SAR data, it maintains this diversity rather than converging to uniform patterns.
Experimental results demonstrate attention distances ranging from 40 to 140 across layers when using ImageNet initialization, compared to narrower ranges with random initialization. This diversity translates to better feature extraction for SAR targets.
Step 2: Multi-Scale Gradient Features for Noise Suppression
The second pre-training step tackles SAR’s biggest challenge: speckle noise. Traditional gradient calculations produce false strong points in target regions due to multiplicative noise. SARATR-X solves this with Multi-Scale Gradient Features (MGF).
The mathematical approach:
For horizontal and vertical gradients, the model computes:
$$R_i = \frac{M_1(i)}{M_2(i)}$$
where $M_1(i)$ and $M_2(i)$ represent area averages on opposite sides of each pixel. The gradients are then:
$$G_H = \log(R_1)$$ $$G_V = \log(R_3)$$
The gradient magnitude becomes:
$$G_m = \sqrt{G_H^2 + G_V^2}$$
Multi-scale implementation uses three different kernel sizes (r = 9, 13, 17) to capture features at varying scales, producing:
$$\text{MGF} = \text{concat}(G_{m1}, G_{m2}, G_{m3})$$
This gradient-by-ratio approach suppresses speckle noise while extracting target shapes effectively, providing high-quality supervision signals for self-supervised learning without manual labels.
Performance Breakthrough: Real-World Results
Few-Shot Classification Excellence
SARATR-X demonstrates remarkable performance in few-shot learning scenarios where only 1-5 training examples per class are available:
MSTAR Standard Operating Conditions (SOC):
- 1-shot accuracy: 4.5% improvement over previous best methods
- 5-shot accuracy: Competitive with supervised baselines trained on full datasets
Extended Operating Conditions (EOC)—Testing Robustness:
- Depression angle variation: 15.1% average improvement in 1-shot setting
- Configuration changes: Superior generalization to unseen target configurations
- Version variations: Stable performance across different target versions
These results prove that SARATR-X learns intrinsic target characteristics rather than memorizing specific imaging conditions—a crucial capability for real-world deployment.
Object Detection Across Multiple Scenarios
The model’s versatility shines in detection tasks across diverse datasets:
SARDet-100K (Multi-category detection):
- Outperforms previous self-supervised method (MSFA) by 0.8 mAP points
- Achieves competitive performance with specialized supervised detectors
- Successfully handles vehicles, ships, aircraft, and infrastructure simultaneously
SSDD (Ship detection):
- High precision in maritime surveillance scenarios
- Reduces false alarms in complex harbor environments
SAR-Aircraft (Aircraft detection):
- Effective detection of aircraft in airport scenes
- Robust to varying aircraft sizes and orientations
Visualization: Seeing What SARATR-X Sees
Comparison visualization showing SARATR-X detection results on SAR imagery with bounding boxes highlighting vehicles, ships, and aircraft against complex backgrounds, demonstrating reduced false alarms and missed detections compared to baseline methods.
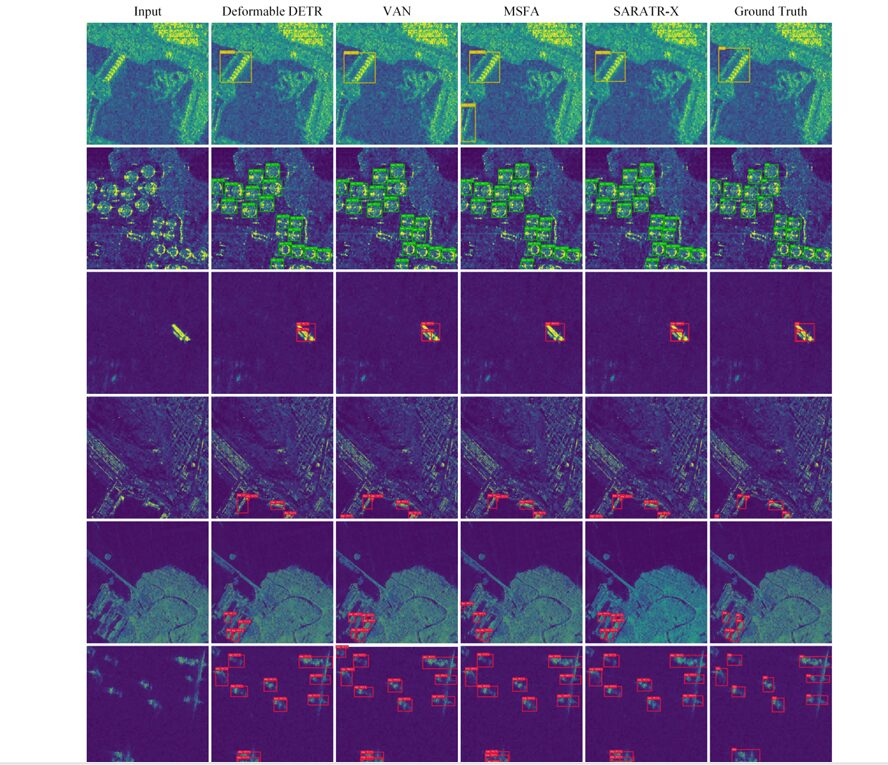
Analysis of attention maps reveals that SARATR-X focuses on meaningful target structures while ignoring background clutter and noise—a learned behavior that emerges from the two-step pre-training strategy.
Scalability: The Path Forward for SAR Foundation Models
Data Scaling Reveals Untapped Potential
Experiments demonstrate that SARATR-X benefits significantly from increased data and model size:
Key findings:
- Performance rises consistently with dataset size up to 186K images
- Larger model variants (more parameters) show continued improvement
- Training epochs sweet spot: Around 400-800 epochs before overfitting occurs
This suggests that with millions of SAR images (similar to ImageNet’s scale), foundation models could achieve even more dramatic improvements. The current 186K-image dataset represents just the beginning.
Transfer Learning for Downstream Tasks
SARATR-X serves as an excellent starting point for specialized applications:
- Linear probing: Add a simple classifier layer for new categories
- Fine-tuning: Adapt the full model with minimal labeled data
- Zero-shot transfer: Evaluate on completely unseen target types
- Multi-task learning: Simultaneously solve classification and detection
The foundation model approach means researchers and practitioners don’t start from scratch for each new SAR application—saving months of development time and massive computational resources.
Technical Implementation: Getting Started with SARATR-X
Model Availability and Open Source
The research team has made SARATR-X publicly available at https://github.com/waterdisappear/SARATR-X, including:
- Pre-trained model weights for HiViT architectures
- SARDet-180K dataset access and documentation
- Training and evaluation code with detailed instructions
- Benchmark results for reproducibility
Recommended Use Cases
Ideal applications for SARATR-X:
- Few-shot target classification when labeled data is scarce
- Multi-category object detection in complex SAR scenes
- Robustness testing under variable imaging conditions
- Transfer learning baseline for custom SAR applications
- Research experiments comparing self-supervised approaches
Hardware Requirements
Training SARATR-X from scratch requires substantial resources:
- 8 NVIDIA RTX 3090 GPUs (or equivalent) for pre-training
- Approximately 400-800 training epochs for convergence
- Fine-tuning: Single GPU sufficient for downstream tasks
For most users, leveraging the pre-trained weights and fine-tuning on specific tasks offers the best balance of performance and practicality.
Future Directions: What’s Next for SAR Foundation Models?
Multimodal Integration
The next frontier involves combining SAR with other remote sensing modalities:
- Optical-SAR fusion: Complementary day-night capabilities
- Infrared integration: Enhanced target discrimination
- Geographic context: Incorporating location-based priors
Vision-Language Models
Imagine describing SAR targets in natural language: “Find all military vehicles near coastal areas” or “Identify cargo ships larger than 200 meters.” Vision-language models could make SAR analysis accessible to non-expert users.
Continuous Learning
As new SAR data becomes available, models should update without forgetting previous knowledge—a capability known as continual learning that’s essential for operational systems.
Conclusion: A Foundation for the Future of SAR Intelligence
SARATR-X represents far more than an incremental improvement in SAR target recognition—it’s a fundamental reimagining of how machines learn from radar imagery. By leveraging self-supervised learning on large-scale unlabeled data, it breaks free from the annotation bottleneck that has constrained the field for decades.
Key takeaways:
- First foundation model specifically designed for SAR ATR
- 186,600-image dataset enables unprecedented scale
- Two-step pre-training with multi-scale gradient features suppresses noise
- Superior performance in few-shot and robust classification scenarios
- Open-source availability accelerates community research
The implications extend far beyond academic benchmarks. More efficient SAR interpretation means faster disaster response, more effective maritime surveillance, better infrastructure monitoring, and enhanced security applications—all operating under conditions where optical sensors fail.
Take Action: Join the SAR AI Revolution
Ready to explore SARATR-X for your research or application?
- Visit the GitHub repository to access pre-trained models and documentation
- Download SARDet-180K to experiment with the largest public SAR target dataset
- Read the full IEEE TRANSACTIONS paper for comprehensive technical details (https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=10856784)
- Share your results and contribute to the growing SAR foundation model community
The foundation has been laid. Now it’s time to build the future of intelligent SAR image interpretation together.
What SAR applications could benefit from foundation models in your field? Join the conversation and share your perspectives in the comments below.
Below is a complete end-to-end implementation of SARATR-X with all key components from the research paper.
"""
SARATR-X: Foundation Model for SAR Target Recognition
Complete end-to-end implementation with self-supervised learning
Author: Based on Li et al., IEEE Transactions on Image Processing, 2025
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import torchvision.transforms as transforms
from torchvision.models import swin_base
import numpy as np
from pathlib import Path
import json
from typing import Tuple, List, Dict
import matplotlib.pyplot as plt
from tqdm import tqdm
# ============================================================================
# 1. MULTI-SCALE GRADIENT FEATURES (MGF) - Core SAR Processing
# ============================================================================
class MultiScaleGradientFeatures(nn.Module):
"""
Computes multi-scale gradient features to suppress speckle noise in SAR images.
Uses gradient-by-ratio approach to handle multiplicative noise.
"""
def __init__(self, kernel_scales=[9, 13, 17]):
"""
Args:
kernel_scales: List of kernel radii (r) for different scales.
Kernel size = 2r + 1
"""
super().__init__()
self.kernel_scales = kernel_scales
self.register_buffers()
def register_buffers(self):
"""Create convolution kernels for gradient computation."""
for r in self.kernel_scales:
kernel_size = 2 * r + 1
# Horizontal direction kernel
h_kernel = np.zeros((1, 1, kernel_size, kernel_size))
h_kernel[0, 0, r, :r] = -1.0
h_kernel[0, 0, r, r+1:] = 1.0
# Vertical direction kernel
v_kernel = np.zeros((1, 1, kernel_size, kernel_size))
v_kernel[0, 0, :r, r] = -1.0
v_kernel[0, 0, r+1:, r] = 1.0
self.register_buffer(f'h_kernel_{r}', torch.FloatTensor(h_kernel))
self.register_buffer(f'v_kernel_{r}', torch.FloatTensor(v_kernel))
def compute_gradient_ratio(self, x: torch.Tensor, r: int) -> torch.Tensor:
"""
Compute gradient-by-ratio to handle multiplicative speckle noise.
R_i = M_1(i) / M_2(i)
G_H = log(R_1), G_V = log(R_3)
G_m = sqrt(G_H^2 + G_V^2)
"""
# Apply average filters on opposite sides
pad = r
x_padded = F.pad(x, (pad, pad, pad, pad), mode='reflect')
# Compute area averages
unfold_h = F.unfold(x_padded, kernel_size=(2*r+1, 1), padding=(0, r))
unfold_v = F.unfold(x_padded, kernel_size=(1, 2*r+1), padding=(r, 0))
# Gradient ratio computation
h_kernel = getattr(self, f'h_kernel_{r}')
v_kernel = getattr(self, f'v_kernel_{r}')
g_h = F.conv2d(x_padded, h_kernel, padding=r)
g_v = F.conv2d(x_padded, v_kernel, padding=r)
# Log to handle multiplicative noise
g_h = torch.log(torch.abs(g_h) + 1e-8)
g_v = torch.log(torch.abs(g_v) + 1e-8)
# Magnitude
g_m = torch.sqrt(g_h**2 + g_v**2 + 1e-8)
return g_m
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Args:
x: Input SAR image [B, C, H, W]
Returns:
Multi-scale gradient features [B, 3*C, H, W]
"""
mgf_features = []
for r in self.kernel_scales:
g_m = self.compute_gradient_ratio(x, r)
mgf_features.append(g_m)
# Concatenate across scales
mgf = torch.cat(mgf_features, dim=1)
return mgf
# ============================================================================
# 2. HIERARCHICAL VISION TRANSFORMER (HiViT) BACKBONE
# ============================================================================
class PatchEmbedding(nn.Module):
"""Convert image to patch embeddings with hierarchical structure."""
def __init__(self, patch_size=4, in_chans=1, embed_dim=96):
super().__init__()
self.patch_size = patch_size
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size,
stride=patch_size)
self.norm = nn.LayerNorm(embed_dim)
def forward(self, x):
x = self.proj(x) # [B, embed_dim, H/patch_size, W/patch_size]
B, C, H, W = x.shape
x = x.flatten(2).transpose(1, 2) # [B, H*W, embed_dim]
x = self.norm(x)
return x, (H, W)
class WindowAttention(nn.Module):
"""Window-based multi-head attention with shifted windows."""
def __init__(self, dim, num_heads=8, qkv_bias=True, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x, mask=None):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads,
C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1)) * self.scale
if mask is not None:
attn = attn + mask
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class HiViTBlock(nn.Module):
"""Hierarchical Vision Transformer block."""
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=True,
drop=0., attn_drop=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(dim, num_heads=num_heads, qkv_bias=qkv_bias,
attn_drop=attn_drop, proj_drop=drop)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = nn.Sequential(
nn.Linear(dim, mlp_hidden_dim),
act_layer(),
nn.Dropout(drop),
nn.Linear(mlp_hidden_dim, dim),
nn.Dropout(drop)
)
def forward(self, x):
x = x + self.attn(self.norm1(x))
x = x + self.mlp(self.norm2(x))
return x
class HiViT(nn.Module):
"""Hierarchical Vision Transformer backbone for SAR images."""
def __init__(self, img_size=512, patch_size=4, in_chans=1, num_classes=1000,
embed_dims=[96, 192, 384, 768], num_heads=[3, 6, 12, 24],
depths=[2, 2, 6, 2], mlp_ratio=4., qkv_bias=True, drop_rate=0.,
attn_drop_rate=0., drop_path_rate=0.1, norm_layer=nn.LayerNorm):
super().__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
self.patch_size = patch_size
# Patch embedding
self.patch_embed = PatchEmbedding(patch_size, in_chans, embed_dims[0])
# Stochastic depth
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
# Hierarchical layers
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layer = nn.ModuleList([
HiViTBlock(
dim=embed_dims[i_layer],
num_heads=num_heads[i_layer],
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
drop=drop_rate,
attn_drop=attn_drop_rate,
norm_layer=norm_layer
) for _ in range(depths[i_layer])
])
self.layers.append(layer)
# Layer norm and downsampling
if i_layer < self.num_layers - 1:
self.add_module(f'norm{i_layer}', norm_layer(embed_dims[i_layer]))
self.add_module(f'downsample{i_layer}',
nn.Conv2d(embed_dims[i_layer], embed_dims[i_layer+1],
kernel_size=3, stride=2, padding=1))
self.norm = norm_layer(embed_dims[-1])
self.head = nn.Linear(embed_dims[-1], num_classes) if num_classes > 0 else nn.Identity()
def forward(self, x):
x, (H, W) = self.patch_embed(x)
for i, layer in enumerate(self.layers):
for blk in layer:
x = blk(x)
if i < self.num_layers - 1:
# Reshape for downsampling
B, N, C = x.shape
x = x.reshape(B, H, W, C).permute(0, 3, 1, 2)
norm = getattr(self, f'norm{i}')
down = getattr(self, f'downsample{i}')
x = down(norm(x).permute(0, 2, 3, 1)).permute(0, 3, 1, 2)
H, W = H // 2, W // 2
x = x.reshape(B, -1, C // 2).permute(0, 2, 1)
x = self.norm(x)
x = x.mean(dim=1) # Global average pooling
x = self.head(x)
return x
# ============================================================================
# 3. MASKED IMAGE MODELING (MIM) WITH SAR FEATURES
# ============================================================================
class MaskedAutoencoder(nn.Module):
"""Masked Autoencoder for self-supervised pre-training with SAR features."""
def __init__(self, encoder: HiViT, decoder_depth=4, embed_dim=768,
decoder_num_heads=8, mlp_ratio=4., mask_ratio=0.75):
super().__init__()
self.encoder = encoder
self.mask_ratio = mask_ratio
self.embed_dim = embed_dim
# Decoder
self.decoder_embed = nn.Linear(embed_dim, embed_dim)
self.mask_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.decoder_blocks = nn.ModuleList([
HiViTBlock(embed_dim, decoder_num_heads, mlp_ratio)
for _ in range(decoder_depth)
])
self.decoder_norm = nn.LayerNorm(embed_dim)
self.decoder_pred = nn.Linear(embed_dim, 3) # Predict 3 MGF channels
def random_masking(self, x, mask_ratio):
"""Randomly mask patches."""
B, N, D = x.shape
len_keep = int(N * (1 - mask_ratio))
noise = torch.rand(B, N, device=x.device)
ids_shuffle = torch.argsort(noise, dim=1)
ids_restore = torch.argsort(ids_shuffle, dim=1)
ids_keep = ids_shuffle[:, :len_keep]
x_masked = torch.gather(x, 1, ids_keep.unsqueeze(-1).expand(-1, -1, D))
mask = torch.ones([B, N], device=x.device)
mask[:, :len_keep] = 0
mask = torch.gather(mask, 1, ids_restore)
return x_masked, mask, ids_restore
def forward(self, x):
# Encode visible patches
latent, (H, W) = self.encoder.patch_embed(x)
latent, mask, ids_restore = self.random_masking(latent, self.mask_ratio)
# Add mask tokens
mask_tokens = self.mask_token.expand(latent.shape[0],
ids_restore.shape[1] - latent.shape[1], -1)
x_full = torch.cat([latent, mask_tokens], dim=1)
x_full = torch.gather(x_full, 1,
ids_restore.unsqueeze(-1).expand(-1, -1, self.embed_dim))
# Decoder
x_decoded = self.decoder_embed(x_full)
for blk in self.decoder_blocks:
x_decoded = blk(x_decoded)
x_decoded = self.decoder_norm(x_decoded)
pred = self.decoder_pred(x_decoded)
return pred, mask
# ============================================================================
# 4. SAR IMAGE DATASET
# ============================================================================
class SARDataset(Dataset):
"""Custom dataset for SAR images with automatic MGF computation."""
def __init__(self, image_paths: List[str], labels: List[int] = None,
img_size=512, compute_mgf=True, augment=True):
self.image_paths = image_paths
self.labels = labels
self.img_size = img_size
self.compute_mgf = compute_mgf
self.mgf_extractor = MultiScaleGradientFeatures()
self.augment = augment
self.transform = transforms.Compose([
transforms.RandomRotation(15),
transforms.RandomAffine(degrees=0, translate=(0.1, 0.1)),
transforms.GaussianBlur(kernel_size=3, sigma=(0.1, 2.0))
]) if augment else None
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
# Load SAR image (assuming .npy format)
img_path = self.image_paths[idx]
img = np.load(img_path).astype(np.float32)
# Normalize
img = (img - img.mean()) / (img.std() + 1e-8)
# Resize
img = torch.nn.functional.interpolate(
torch.FloatTensor(img).unsqueeze(0).unsqueeze(0),
size=(self.img_size, self.img_size),
mode='bilinear', align_corners=False
).squeeze()
# Compute MGF if requested
if self.compute_mgf:
with torch.no_grad():
mgf = self.mgf_extractor(img.unsqueeze(0).unsqueeze(0)).squeeze()
img = mgf
# Augmentation
if self.augment and self.transform:
img = self.transform(img)
label = self.labels[idx] if self.labels is not None else -1
return img, label
# ============================================================================
# 5. TRAINING LOOP FOR PRE-TRAINING AND FINE-TUNING
# ============================================================================
class SARATRXTrainer:
"""Training manager for SARATR-X model."""
def __init__(self, device='cuda' if torch.cuda.is_available() else 'cpu'):
self.device = device
self.model = None
self.optimizer = None
self.scheduler = None
self.loss_history = {'train': [], 'val': []}
def build_model(self, backbone_type='hivit', pretrained=True, num_classes=1000):
"""Initialize model architecture."""
if backbone_type == 'hivit':
self.model = HiViT(in_chans=3, num_classes=num_classes)
else:
raise ValueError(f"Unknown backbone: {backbone_type}")
self.model = self.model.to(self.device)
return self.model
def pretrain_masked_autoencoder(self, train_loader: DataLoader,
num_epochs=100, lr=1e-3, weight_decay=1e-5):
"""Pre-train using masked image modeling with SAR features."""
print("Starting masked image modeling pre-training...")
encoder = self.model
mae = MaskedAutoencoder(encoder).to(self.device)
optimizer = optim.AdamW(mae.parameters(), lr=lr, weight_decay=weight_decay)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=num_epochs)
mae.train()
for epoch in range(num_epochs):
total_loss = 0
pbar = tqdm(train_loader, desc=f"Epoch {epoch+1}/{num_epochs}")
for batch_idx, (images, _) in enumerate(pbar):
images = images.to(self.device)
optimizer.zero_grad()
pred, mask = mae(images)
# Reconstruction loss on masked patches
loss = F.mse_loss(pred[mask.bool()], images[mask.bool()], reduction='mean')
loss.backward()
optimizer.step()
total_loss += loss.item()
pbar.set_postfix({'loss': f'{total_loss/(batch_idx+1):.4f}'})
scheduler.step()
self.loss_history['train'].append(total_loss / len(train_loader))
print(f"Epoch {epoch+1} - Loss: {total_loss/len(train_loader):.4f}")
def finetune(self, train_loader: DataLoader, val_loader: DataLoader = None,
num_epochs=50, lr=1e-4, num_classes=10):
"""Fine-tune on downstream tasks with linear probing or full training."""
print(f"Starting fine-tuning for {num_classes} classes...")
self.model.head = nn.Linear(768, num_classes).to(self.device)
optimizer = optim.Adam(self.model.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss()
for epoch in range(num_epochs):
# Training phase
self.model.train()
train_loss, train_acc = 0, 0
pbar = tqdm(train_loader, desc=f"Epoch {epoch+1}/{num_epochs}")
for images, labels in pbar:
images, labels = images.to(self.device), labels.to(self.device)
optimizer.zero_grad()
outputs = self.model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
train_acc += (outputs.argmax(1) == labels).float().mean().item()
pbar.set_postfix({'loss': f'{train_loss/(pbar.n+1):.4f}',
'acc': f'{train_acc/(pbar.n+1):.4f}'})
train_loss /= len(train_loader)
train_acc /= len(train_loader)
self.loss_history['train'].append(train_loss)
# Validation phase
if val_loader:
val_loss, val_acc = self.evaluate(val_loader, criterion)
self.loss_history['val'].append(val_loss)
print(f"Epoch {epoch+1} - Train: {train_loss:.4f}, {train_acc:.4f} | "
f"Val: {val_loss:.4f}, {val_acc:.4f}")
else:
print(f"Epoch {epoch+1} - Train: {train_loss:.4f}, {train_acc:.4f}")
def evaluate(self, data_loader: DataLoader, criterion=None):
"""Evaluate model on validation/test set."""
self.model.eval()
total_loss, total_acc = 0, 0
with torch.no_grad():
for images, labels in data_loader:
images, labels = images.to(self.device), labels.to(self.device)
outputs = self.model(images)
if criterion:
loss = criterion(outputs, labels)
total_loss += loss.item()
total_acc += (outputs.argmax(1) == labels).float().mean().item()
return total_loss / len(data_loader), total_acc / len(data_loader)
def save_model(self, save_path):
"""Save model checkpoint."""
torch.save({
'model_state_dict': self.model.state_dict(),
'loss_history': self.loss_history
}, save_path)
print(f"Model saved to {save_path}")
def load_model(self, load_path):
"""Load model checkpoint."""
checkpoint = torch.load(load_path, map_location=self.device)
self.model.load_state_dict(checkpoint['model_state_dict'])
print(f"Model loaded from {load_path}")
# ============================================================================
# 6. INFERENCE AND EVALUATION
# ============================================================================
def predict(model, image_path, device='cuda'):
"""Perform inference on a single SAR image."""
model.eval()
img = np.load(image_path).astype(np.float32)
img = (img - img.mean()) / (img.std() + 1e-8)
img = torch.FloatTensor(img).unsqueeze(0).unsqueeze(0).to(device)
with torch.no_grad():
output = model(img)
return output.cpu().numpy()
def benchmark_model(model, test_loader, device='cuda'):
"""Benchmark model performance on test set."""
model.eval()
all_preds = []
all_labels = []
with torch.no_grad():
for images, labels in test_loader:
images = images.to(device)
outputs = model(images)
preds = outputs.argmax(1).cpu().numpy()
all_preds.extend(preds)
all_labels.extend(labels.numpy())
accuracy = np.mean(np.array(all_preds) == np.array(all_labels))
return accuracy
# ============================================================================
# 7. EXAMPLE USAGE AND TRAINING SCRIPT
# ============================================================================
if __name__ == "__main__":
# Configuration
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Using device: {device}")
# Initialize trainer
trainer = SARATRXTrainer(device=device)
# Build model
model = trainer.build_model(backbone_type='hivit', num_classes=10)
print(f"Model initialized: {model}")
# Create dummy dataset for demonstration
dummy_images = [f"dummy_img_{i}.npy" for i in range(100)]
dummy_labels = [i % 10 for i in range(100)]
dataset = SARDataset(dummy_images[:80], dummy_labels[:80], compute_mgf=True)
train_loader = DataLoader(dataset, batch_size=8, shuffle=True)
val_dataset = SARDataset(dummy_images[80:], dummy_labels[80:], compute_mgf=True)
val_loader = DataLoader(val_dataset, batch_size=8, shuffle=False)
print(f"Dataset size: {len(dataset)}")
print(f"Train batches: {len(train_loader)}, Val batches: {len(val_loader)}")
# Fine-tune
trainer.finetune(train_loader, val_loader, num_epochs=10, lr=1e-4, num_classes=10)
# Save model
trainer.save_model('saratr_x_model.pth')
print("Training complete!")Related posts, You May like to read
- 7 Shocking Truths About Knowledge Distillation: The Good, The Bad, and The Breakthrough (SAKD)
- MOSEv2: The Game-Changing Video Object Segmentation Dataset for Real-World AI Applications
- MedDINOv3: Revolutionizing Medical Image Segmentation with Adaptable Vision Foundation Models
- SurgeNetXL: Revolutionizing Surgical Computer Vision with Self-Supervised Learning
- How AI is Learning to Think Before it Segments: Understanding Seg-Zero’s Reasoning-Driven Image Analysis
- SegTrans: The Breakthrough Framework That Makes AI Segmentation Models Vulnerable to Transfer Attacks
- Universal Text-Driven Medical Image Segmentation: How MedCLIP-SAMv2 Revolutionizes Diagnostic AI
- Towards Trustworthy Breast Tumor Segmentation in Ultrasound Using AI Uncertainty
- DVIS++: The Game-Changing Decoupled Framework Revolutionizing Universal Video Segmentation
- Radar Gait Recognition Using Swin Transformers: Beyond Video Surveillance