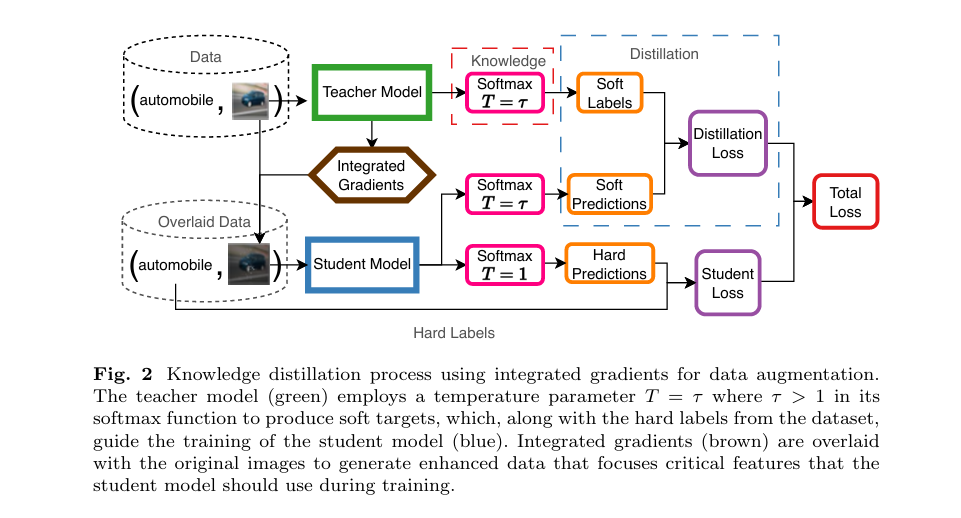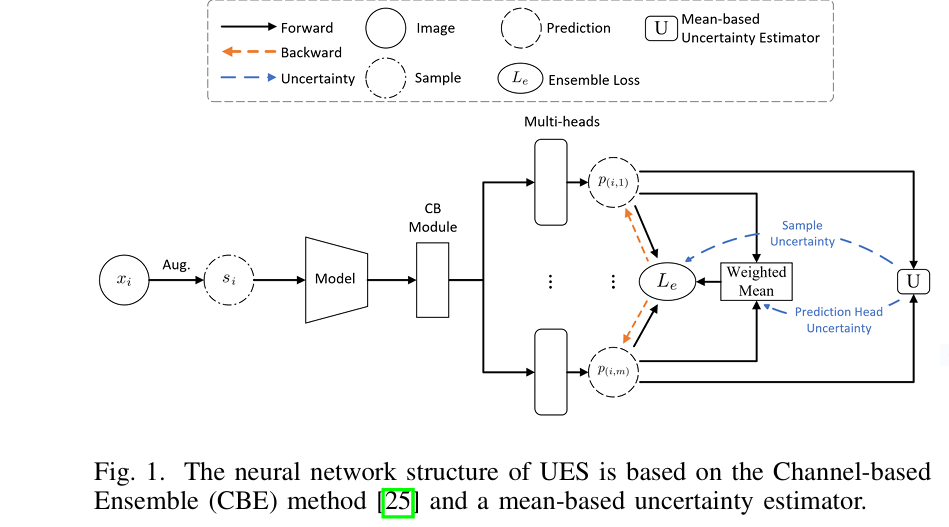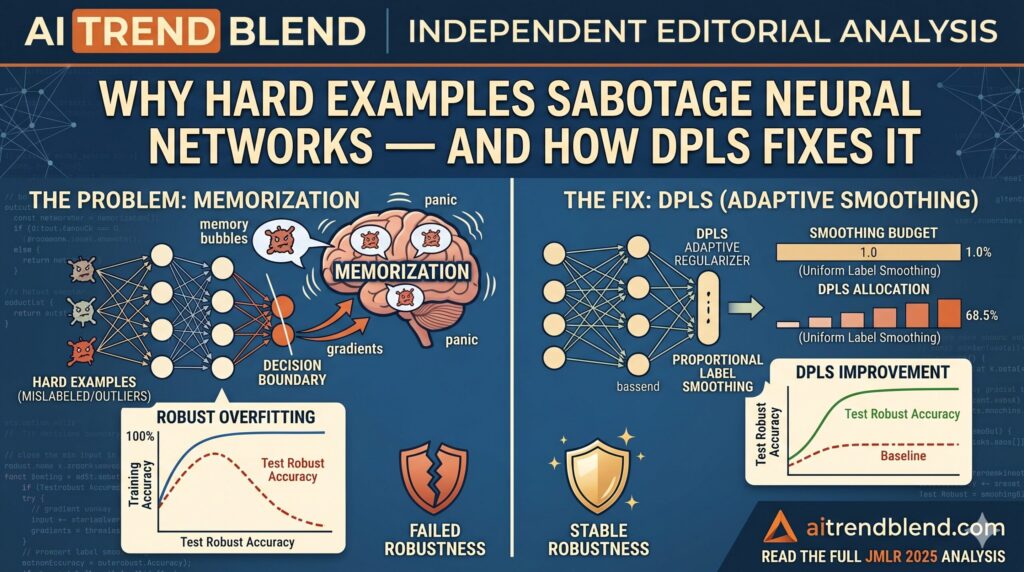
Why Hard Training Examples Hurt Neural Networks — And How DPLS Fixes It
Why Hard Training Examples Hurt Neural Networks — And How DPLS Fixes It | AI Trend Blend AITrendBlend Machine Learning Adversarial AI About Adversarial Robustness · Journal of Machine Learning Research 26 (2025) 1–48 · 16 min read Why Hard Training Examples Are Secretly Sabotaging Your Neural Network’s Robustness A team from Seoul National University […]
Why Hard Training Examples Hurt Neural Networks — And How DPLS Fixes It Read More »