Think Before You Segment: How TGS-Agent Teaches AI to Reason About Sound Before Picking Up a Brush
A research team from MBZUAI and NUS built an agentic segmentation system that actually stops to figure out what it is looking for before drawing a single mask — and the results expose a deep flaw in how every prior method handles the problem.
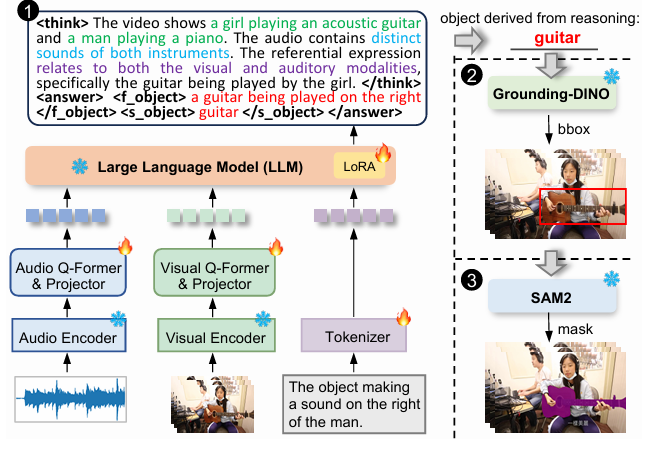
There is a well-known story in cognitive science about how humans solve perceptual puzzles. Before we reach for a pencil to outline something, we spend a moment — sometimes just a fraction of a second — figuring out what the thing is. The segmentation research community has largely ignored this step. TGS-Agent, presented at AAAI 2026 by researchers from MBZUAI, NUS, and USTC, is an attempt to put it back.
The Problem That Ref-AVS Keeps Hiding in Plain Sight
Consider the reference expression: “The object making a sound on the left of the guitar.” To answer this, a model needs to do at least three things — locate the guitar visually, shift spatial attention to its left side, and listen to the audio to find what is sounding there. The answer, if you follow that chain, is the piano. Only once you have that answer should segmentation begin.
Prior approaches to Referring Audio-Visual Segmentation (Ref-AVS) skip that chain almost entirely. They fuse multimodal features through transformers, compress the result into sparse and dense embedding vectors, and hand those embeddings to a SAM or SAM2 decoder to produce a mask. The process is end-to-end, differentiable, and trained on pixel-level ground truth. It also functions as a complete black box: the model produces a mask but cannot tell you — or itself — what object it decided to segment.
That black-box nature matters practically, not just philosophically. When the reference is linguistically complex or requires genuine reasoning — say, “The stationary object whose manipulated components harmonize with the bassoon’s melody” — these models tend to lock onto salient words in the reference and match them to visual features, bypassing the reasoning altogether. The result is competitive performance on standard benchmarks and dramatic collapse when the vocabulary gets harder.
Every prior Ref-AVS method couples understanding and segmentation into a single learned pipeline, which requires pixel-level supervision and produces uninterpretable decisions. TGS-Agent decouples them: a multimodal language model does the understanding, then off-the-shelf tools handle grounding and segmentation. The understanding step is the innovation; the rest is already solved.
What the Think-Ground-Segment Workflow Actually Does
The architecture has a clean three-part structure, and each part maps to a specific tool in the system.
Think: Ref-Thinker Figures Out the Target
The Think step is where all the novel contribution lives. The researchers built Ref-Thinker, a multimodal large language model that takes an audio stream, a set of video frames, and a reference expression, and outputs an explicit description of the referred object — along with the full reasoning chain that led there.
The output format is structured deliberately. Inside <think> tags, the model walks through the reference text, describes what it sees in the video, identifies what it hears in the audio, and decides which modality the reference depends on. Inside <answer> tags, it outputs two descriptions: a fine-grained one (e.g., “a guitar being played on the right”) and a simplified one (e.g., “guitar”). Both descriptions matter — they serve different purposes downstream, which the ablation studies address in detail.
Architecturally, Ref-Thinker is an audio-visual LLM built on LLaMA-2-7b-chat. CLIP-ViT-L/14 handles visual encoding; BEATs handles audio encoding. Both modalities go through independent Q-Former modules that compress segment-level features into 32 learnable query tokens each, then MLP projectors align audio and visual tokens with the LLM’s text space. The entire combination is conceptually similar to BLIP-2, extended to handle temporal audio alongside video.
Training happens in two phases. First, Q-Formers and projectors are pretrained on domain-specific audio and video captioning datasets while the LLM stays frozen. Then LoRA (rank 8, scale 16) is applied for parameter-efficient fine-tuning of the LLM on the instruction-tuning set the team constructed. That instruction-tuning set — reasoning chains generated by Gemini-1.5-Pro from Ref-AVSBench training videos — is what teaches the model to produce explicit think-answer chains rather than simple answers.
A = audio stream, V = video frames, R = reference text, P = user prompt template, T = generated reasoning text. Tf = fine-grained object description; Ts = simplified (category) description.
Ground: Grounding-DINO Finds the Box
Once Ref-Thinker has identified the target object with an explicit text description, the Ground step is conceptually simple. Grounding-DINO — a transformer-based open-set detector combining DINO with large-scale grounded pretraining — takes the object description as a text prompt and generates bounding boxes in each video frame. Two threshold hyperparameters control quality: τ_bbox (minimum box confidence) and τ_text (minimum text-matching score), both set conservatively at 0.1 and 0.25 respectively after ablation.
B = {(x₁,y₁),(x₂,y₂)}ᴺ is the set of bounding boxes for N video frames. If no matching object is found in a frame, no box is produced for that frame.
Segment: SAM2 Draws the Mask
Given the bounding boxes, SAM2 — used completely frozen, without any fine-tuning — produces per-frame segmentation masks. Bounding boxes are strong spatial priors for SAM2, which is exactly what the model was designed to receive. If a frame has no valid bounding box, the segmentation defaults to all-background. The whole pipeline transforms (audio + video + reference) → object description → bounding boxes → pixel masks, without touching a single labeled mask during the segmentation stages.
M = {mᵢ}ᴺᵢ₌₁ is the set of binary segmentation masks for N video frames. The frozen SAM2 model requires no pixel-level supervision during inference.
Why Existing Benchmarks Were Too Easy
One of the quieter contributions of this paper — and one that deserves more attention — is the R²-AVSBench evaluation set. The team noticed something uncomfortable about the existing Ref-AVSBench test data: many of the reference expressions either directly name the target object (“The clarinet being played by a man”) or contain such specific cues that the object identification step is trivial. A model can shortcut the reasoning by pattern-matching reference words to common visual categories and still score well.
R²-AVSBench fixes this. The new references replace direct object names with abstract descriptions: “The item visually serving as a shared seating platform for the audio discourse” instead of “The couch sat by a woman.” References become structurally diverse — using relative pronouns, commonsense knowledge, audio-functional descriptions, multi-step inference. The average reference length increases from 7.08 words to 11.73 words, and the vocabulary shifts substantially as the word cloud comparison in the paper shows.
Critically, R²-AVSBench reuses the original pixel masks from Ref-AVSBench, so models can be compared on the same 400 test videos across both reference types — a clean controlled experiment for measuring the impact of linguistic complexity on segmentation performance.
“References in Ref-AVSBench are constructed using fixed, manually predefined templates, which limits their linguistic diversity. Our R²-AVSBench features references with greater lexical and structural diversity, which also require deeper reasoning.” — Zhou, Zhou, Han et al., MBZUAI / NUS (AAAI 2026)
The Numbers: State of the Art, Without Supervision
Standard Ref-AVSBench Results
| Method | Venue | Task | Seen J&F ↑ | Unseen J&F ↑ | Mix J&F ↑ | Null S ↓ |
|---|---|---|---|---|---|---|
| AVSBench | ECCV’22 | AVS | 37.2 | 43.5 | 40.3 | 0.208 |
| AVSegFormer | AAAI’24 | AVS | 40.2 | 43.1 | 41.7 | 0.171 |
| EEMC | ECCV’24 | Ref-AVS | 42.8 | 57.2 | 50.0 | 0.007 |
| Grounded-SAM2 | ArXiv’24 | Ref-AVS | 34.2 | 63.9 | 49.1 | 0.277 |
| TSAM | CVPR’25 | Ref-AVS | 50.1 | 60.5 | 55.3 | 0.017 |
| SAM2-LOVE | CVPR’25 | Ref-AVS | 47.7 | 69.4 | 58.5 | 0.230 |
| TGS-Agent (ours) | AAAI’26 | Ref-AVS | 54.9 | 76.9 | 65.9 | 0.035 |
Table 1: TGS-Agent achieves state-of-the-art J&F on both Seen and Unseen splits, surpassing the previous best (SAM2-LOVE) by 7.2% and 7.5% respectively — without fine-tuning any segmentation decoder and without requiring pixel-level training supervision.
R²-AVSBench: Where Things Get Harder
| Ref. Source | Method | Seen J&F ↑ | Unseen J&F ↑ | Mix J&F ↑ |
|---|---|---|---|---|
| Ref-AVSBench refs | Crab | 27.2 | 47.2 | 37.2 |
| EEMC | 33.7 | 47.8 | 40.7 | |
| Grounded-SAM2 | 45.9 | 72.2 | 59.0 | |
| TGS-Agent | 53.4 | 76.1 | 64.8 | |
| R²-AVSBench refs | Crab | 25.9 | 44.4 | 35.2 |
| EEMC | 31.2 | 47.8 | 39.5 | |
| Grounded-SAM2 | 25.7 | 49.1 | 37.4 | |
| TGS-Agent | 47.5 | 72.7 | 60.1 |
Table 2: On R²-AVSBench, Grounded-SAM2 collapses by ~20 percentage points on both splits when references become complex — confirming its heavy reliance on lexical shortcutting. TGS-Agent drops only 4–7 points, demonstrating genuine cross-reference generalizability.
The Fine-Grained vs. Simplified Description Debate
One of the more interesting ablation results concerns the type of object description fed to Grounding-DINO. Intuitively, a richer description should produce better detection — if the reference says “the guitar being played by the man,” that is more discriminative than just “guitar,” especially in scenes where multiple guitars appear.
The data tells a mixed story. In aggregate, the simplified category name (T_s) outperforms the fine-grained description (T_f) by about 6 points on the Seen set. The researchers hypothesize this reflects Grounding-DINO’s training distribution preference for short, clean category-style prompts. But in specific scenarios — a video with two musicians both playing guitars, differing only in who plays what — the fine-grained prompt becomes decisive, correctly disambiguating what the simplified prompt cannot.
| Description Used | Seen J&F ↑ | Unseen J&F ↑ | Null S ↓ |
|---|---|---|---|
| Original reference (R) | 34.2 | 63.9 | 0.277 |
| Fine-grained (T_f) | 49.0 | 73.7 | 0.043 |
| Simplified (T_s) | 54.9 | 76.9 | 0.035 |
Table 3: Ablation on object description type. Both T_f and T_s substantially outperform using the raw reference expression as a detection prompt, confirming that the Think step adds genuine value. The simplified form works better on average, but T_f remains essential for fine-grained disambiguation.
What This Changes About the Field
The significance of TGS-Agent is not purely empirical — though the numbers are strong. The more important shift is architectural and conceptual.
Prior methods trained everything jointly, which meant the understanding of the reference and the drawing of the mask were entangled in a way that made neither fully legible. To change the segmentation behavior, you had to change the feature fusion. To improve reasoning, you had to change the entire training pipeline. The mask decoder and the reference understanding were inseparable.
TGS-Agent separates them cleanly. Ref-Thinker handles understanding; Grounding-DINO and SAM2 handle the rest. This means each component can be improved independently. A better reasoning model can slot in without touching the segmentation backbone. Better detection capabilities in Grounding-DINO automatically propagate to better masks. The interpretability benefit compounds: you can inspect what Ref-Thinker thought the target was, whether that matches what Grounding-DINO found, and whether SAM2 segmented it correctly — at every step.
The fact that this decoupled approach also eliminates the need for pixel-level ground truth masks during segmentation training is almost a side benefit. But it is a significant practical one. Collecting pixel-level masks is expensive and slow. Reference expressions and audio-visual videos are far cheaper to acquire and annotate at scale.
TGS-Agent’s current Null set score of 0.035 is higher than EEMC’s 0.007, meaning it produces more false positives when the referred object is absent from the video. The authors note this as a limitation. The other open problem: for extremely rare or abstractly described objects, both Ref-Thinker’s identification and Grounding-DINO’s detection can fail, and the errors compound. Future work combining Ref-Thinker’s reasoning with fine-tuned SAM2 decoders may address both issues.


Read the Full Paper & Explore the Benchmark
TGS-Agent is published at the Fortieth AAAI Conference on Artificial Intelligence (2026). The R²-AVSBench evaluation set is designed for community use as a harder testbed for Ref-AVS generalization.
Zhou, J., Zhou, Y., Han, M., Wang, T., Chang, X., Cholakkal, H., & Anwer, R. M. (2026). Think Before You Segment: An Object-aware Reasoning Agent for Referring Audio-Visual Segmentation. Proceedings of the Fortieth AAAI Conference on Artificial Intelligence (AAAI-26), pp. 13665–13673.
This article is an independent editorial analysis of peer-reviewed conference research. All experimental results and figures are reported directly from the source paper. The authors are affiliated with Mohamed Bin Zayed University of Artificial Intelligence (MBZUAI), National University of Singapore, and University of Science and Technology of China. This work was supported by NSFC grants 62573399 and U25A20530, the Google Research Gift Award 2023, Meta Regional Research Grant 2025, and the NVIDIA Academic Grant 2025.
Complete TGS-Agent Model Code (PyTorch)
The implementation below covers every component described in the TGS-Agent paper: the audio and visual Q-Former encoders with MLP projectors, the LoRA-enhanced LLaMA-2 backbone for Ref-Thinker, the think-answer output parsing, the Grounding-DINO integration for bounding box generation, the frozen SAM2 segmentation pipeline, the full TGSAgent end-to-end inference loop, loss functions for autoregressive cross-entropy training, and a smoke-test that runs on synthetic data without any pretrained weights.
# ==============================================================================
# TGS-Agent: Think-Ground-Segment for Referring Audio-Visual Segmentation
# Paper: "Think Before You Segment", AAAI 2026
# Authors: Zhou, Zhou, Han, Wang, Chang, Cholakkal, Anwer — MBZUAI / NUS / USTC
# ==============================================================================
# Sections:
# 1. Imports & Configuration
# 2. Q-Former: Compressing Audio/Visual Features into Tokens
# 3. MLP Projector: Aligning Modality Tokens with LLM Space
# 4. LoRA Adapter: Parameter-Efficient LLM Fine-Tuning
# 5. RefThinker: Full Multimodal LLM with Think-Answer Reasoning
# 6. Output Parser: Extracting F-Object and S-Object Descriptions
# 7. GroundingDINOWrapper: Open-Set Bounding Box Generation
# 8. SAM2Wrapper: Frozen Mask Generation from Bounding Boxes
# 9. TGSAgent: Complete Think-Ground-Segment Pipeline
# 10. Loss Functions: Autoregressive Cross-Entropy
# 11. Instruction Tuning Dataset Builder
# 12. Training Loop
# 13. Inference & Evaluation Utilities
# 14. R2-AVSBench Reference Transformer
# 15. Smoke Test
# ==============================================================================
from __future__ import annotations
import re
import math
import warnings
from dataclasses import dataclass, field
from typing import Dict, List, Optional, Tuple
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import Tensor
from torch.utils.data import DataLoader, Dataset
warnings.filterwarnings("ignore")
# ─── SECTION 1: Configuration ──────────────────────────────────────────────────
@dataclass
class RefThinkerConfig:
"""
Configuration for the Ref-Thinker audio-visual LLM.
Attributes
----------
audio_feat_dim : output dimension of BEATs audio encoder (768)
visual_feat_dim : output dimension of CLIP-ViT-L/14 visual encoder (1024)
llm_hidden_dim : LLaMA-2-7b hidden dimension (4096)
num_query_tokens : number of learnable Q-Former query tokens (32 per modality)
qformer_layers : number of cross-attention layers in Q-Former (6)
qformer_heads : number of attention heads in Q-Former (8)
lora_rank : LoRA decomposition rank (8, paper default)
lora_alpha : LoRA scaling factor (16, paper default)
lora_dropout : dropout inside LoRA adapter (0.1)
max_output_len : max tokens to generate during inference
vocab_size : LLM vocabulary size (32000 for LLaMA-2)
"""
audio_feat_dim: int = 768
visual_feat_dim: int = 1024
llm_hidden_dim: int = 4096
num_query_tokens: int = 32
qformer_layers: int = 6
qformer_heads: int = 8
lora_rank: int = 8
lora_alpha: int = 16
lora_dropout: float = 0.1
max_output_len: int = 512
vocab_size: int = 32000
@dataclass
class GroundingConfig:
"""
Configuration for the Grounding-DINO detection stage.
Attributes
----------
tau_bbox : minimum confidence score to accept a bounding box (0.1)
tau_text : minimum text similarity score to accept a match (0.25)
box_threshold : alias for tau_bbox (0.1)
text_threshold: alias for tau_text (0.25)
max_boxes : maximum boxes to return per frame
"""
tau_bbox: float = 0.10
tau_text: float = 0.25
box_threshold: float = 0.10
text_threshold: float = 0.25
max_boxes: int = 5
# ─── SECTION 2: Q-Former — Compressing Modality Features into Tokens ──────────
class CrossAttentionLayer(nn.Module):
"""
A single cross-attention layer used inside the Q-Former.
Learnable query tokens attend to the modality feature sequence
(audio or visual), compressing variable-length input into a
fixed-length set of query embeddings.
Q-Former design follows BLIP-2 (Li et al., ICML 2023).
"""
def __init__(self, query_dim: int, feat_dim: int, num_heads: int,
dropout: float = 0.1):
super().__init__()
self.norm_q = nn.LayerNorm(query_dim)
self.norm_kv = nn.LayerNorm(feat_dim)
self.cross_attn = nn.MultiheadAttention(
embed_dim=query_dim, num_heads=num_heads,
kdim=feat_dim, vdim=feat_dim,
dropout=dropout, batch_first=True
)
self.norm_ff = nn.LayerNorm(query_dim)
self.ff = nn.Sequential(
nn.Linear(query_dim, query_dim * 4),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(query_dim * 4, query_dim),
nn.Dropout(dropout),
)
def forward(self, queries: Tensor, features: Tensor) -> Tensor:
"""
Parameters
----------
queries : (B, Nq, D_q) learnable query tokens
features : (B, Ns, D_f) encoder output (audio or visual features)
Returns
-------
queries : (B, Nq, D_q) updated query tokens
"""
q = self.norm_q(queries)
kv = self.norm_kv(features)
attn_out, _ = self.cross_attn(query=q, key=kv, value=kv)
queries = queries + attn_out
queries = queries + self.ff(self.norm_ff(queries))
return queries
class QFormer(nn.Module):
"""
Q-Former: compresses audio or visual encoder outputs into a fixed
number of query token embeddings for consumption by the LLM.
The Q-Former bridges the modality encoder and the language model
by cross-attending to the full encoder output and distilling it
into `num_query_tokens` dense embeddings.
Paper: "Q-Formers along with their corresponding projectors are
independently pretrained on domain-specific caption datasets."
Architecture:
- Learnable query tokens (initialized from N(0, 0.02))
- `n_layers` cross-attention + FFN blocks
- Output: (B, num_query_tokens, query_dim)
"""
def __init__(self, feat_dim: int, query_dim: int,
num_query_tokens: int, n_layers: int, n_heads: int):
super().__init__()
self.query_tokens = nn.Parameter(
torch.zeros(1, num_query_tokens, query_dim)
)
nn.init.trunc_normal_(self.query_tokens, std=0.02)
self.layers = nn.ModuleList([
CrossAttentionLayer(query_dim, feat_dim, n_heads)
for _ in range(n_layers)
])
def forward(self, features: Tensor) -> Tensor:
"""
features : (B, T, feat_dim) — audio or visual encoder output
Returns : (B, num_query_tokens, query_dim)
"""
B = features.shape[0]
queries = self.query_tokens.expand(B, -1, -1)
for layer in self.layers:
queries = layer(queries, features)
return queries
# ─── SECTION 3: MLP Projector — Aligning Tokens with LLM Space ────────────────
class MLPProjector(nn.Module):
"""
Two-layer MLP projector that maps Q-Former output tokens into
the LLM's token embedding space.
Paper: "A projector module, implemented as two MLP layers,
is further applied to align the audio/visual feature with
the textual features processed by the LLM."
"""
def __init__(self, in_dim: int, out_dim: int, dropout: float = 0.1):
super().__init__()
hidden = (in_dim + out_dim) // 2
self.net = nn.Sequential(
nn.LayerNorm(in_dim),
nn.Linear(in_dim, hidden),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden, out_dim),
)
def forward(self, x: Tensor) -> Tensor:
"""x: (B, Nq, in_dim) → (B, Nq, out_dim)"""
return self.net(x)
# ─── SECTION 4: LoRA Adapter — Parameter-Efficient LLM Fine-Tuning ────────────
class LoRALinear(nn.Module):
"""
LoRA (Low-Rank Adaptation) wrapper around a frozen nn.Linear layer.
Implements: W_adapted = W_frozen + (alpha/r) * B @ A
where A ∈ R^{r×in}, B ∈ R^{out×r}, r = rank.
Paper: "We apply the LoRA technique for parameter-efficient tuning
of the LLM. LoRA is applied with a rank 8 and a scaling factor 16."
Only A and B are trainable. The original weight W_frozen is unchanged.
"""
def __init__(self, linear: nn.Linear, rank: int = 8,
alpha: int = 16, dropout: float = 0.1):
super().__init__()
in_features, out_features = linear.in_features, linear.out_features
self.linear = linear
for p in self.linear.parameters():
p.requires_grad = False
self.lora_A = nn.Parameter(torch.empty(rank, in_features))
self.lora_B = nn.Parameter(torch.zeros(out_features, rank))
self.scale = alpha / rank
self.dropout = nn.Dropout(dropout)
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
def forward(self, x: Tensor) -> Tensor:
base_out = self.linear(x)
lora_out = self.dropout(x) @ self.lora_A.T @ self.lora_B.T
return base_out + self.scale * lora_out
def apply_lora_to_attention(model: nn.Module, rank: int, alpha: int,
dropout: float) -> nn.Module:
"""
Replace all q_proj and v_proj Linear layers in transformer
attention blocks with LoRALinear wrappers.
This is the standard practice: LoRA is applied to Q and V projections
of each self-attention layer. K and output projections are left frozen.
"""
for name, module in model.named_modules():
if isinstance(module, nn.MultiheadAttention):
if hasattr(module, 'in_proj_weight') and module.in_proj_weight is not None:
# Wrap the combined QKV projection as a LoRA linear
original = nn.Linear(
module.embed_dim, 3 * module.embed_dim, bias=False
)
original.weight = nn.Parameter(module.in_proj_weight)
lora_layer = LoRALinear(original, rank, alpha, dropout)
module.in_proj_weight = None
module._lora_qkv = lora_layer
return model
# ─── SECTION 5: RefThinker — Full Multimodal LLM ──────────────────────────────
class RefThinker(nn.Module):
"""
Ref-Thinker: a reasoning-enhanced Multimodal Large Language Model.
Given a reference expression, audio stream features, and video frame
features, Ref-Thinker generates an explicit think-answer chain:
The referential expression is "xxx".
The video shows xxx (video analysis).
The audio contains xxx (audio analysis).
The reference relates to xxx (modality analysis).
fine-grained object description
category name
Architecture:
- Audio encoder → QFormer (32 tokens) → MLP projector → LLM space
- Visual encoder → QFormer (32 tokens) → MLP projector → LLM space
- Text tokenizer → token embeddings → LLM space
- Concatenate [audio_tokens | visual_tokens | text_tokens] as input
- LLaMA-2-7b backbone with LoRA applied to attention QKV projections
- Autoregressive generation using cross-entropy loss
Training:
Phase 1 (pretraining): Freeze LLM, train Q-Formers + projectors
using audio/visual captioning data.
Phase 2 (instruction tuning): Apply LoRA, train on think-answer
chains generated by Gemini-1.5-Pro.
"""
def __init__(self, cfg: RefThinkerConfig):
super().__init__()
self.cfg = cfg
D = cfg.llm_hidden_dim
# ── Audio branch ──────────────────────────────────────────────────────
self.audio_qformer = QFormer(
feat_dim=cfg.audio_feat_dim,
query_dim=D // 2,
num_query_tokens=cfg.num_query_tokens,
n_layers=cfg.qformer_layers,
n_heads=cfg.qformer_heads,
)
self.audio_projector = MLPProjector(D // 2, D)
# ── Visual branch ─────────────────────────────────────────────────────
self.visual_qformer = QFormer(
feat_dim=cfg.visual_feat_dim,
query_dim=D // 2,
num_query_tokens=cfg.num_query_tokens,
n_layers=cfg.qformer_layers,
n_heads=cfg.qformer_heads,
)
self.visual_projector = MLPProjector(D // 2, D)
# ── LLM backbone (simplified Transformer decoder — replace with
# LlamaForCausalLM when using real pretrained weights) ─────────────
self.token_embedding = nn.Embedding(cfg.vocab_size, D)
self.pos_embedding = nn.Embedding(2048, D)
encoder_layer = nn.TransformerDecoderLayer(
d_model=D, nhead=16, dim_feedforward=D * 4,
dropout=0.1, batch_first=True, norm_first=True,
)
self.llm_backbone = nn.TransformerDecoder(encoder_layer, num_layers=4)
self.lm_head = nn.Linear(D, cfg.vocab_size, bias=False)
self.lm_head.weight = self.token_embedding.weight # tie weights
# ── Apply LoRA to LLM attention projections ───────────────────────────
apply_lora_to_attention(
self.llm_backbone, cfg.lora_rank, cfg.lora_alpha, cfg.lora_dropout
)
# Freeze LLM backbone weights (LoRA parameters remain trainable)
self._freeze_llm_base()
def _freeze_llm_base(self):
"""Freeze all LLM parameters except LoRA adapters and lm_head."""
for name, param in self.llm_backbone.named_parameters():
if 'lora_A' not in name and 'lora_B' not in name:
param.requires_grad = False
def encode_audio(self, audio_feats: Tensor) -> Tensor:
"""
audio_feats : (B, T_a, audio_feat_dim) — BEATs segment features
Returns : (B, num_query_tokens, llm_hidden_dim)
"""
qformer_out = self.audio_qformer(audio_feats)
return self.audio_projector(qformer_out)
def encode_visual(self, visual_feats: Tensor) -> Tensor:
"""
visual_feats : (B, T_v, visual_feat_dim) — CLIP-ViT-L/14 frame features
Returns : (B, num_query_tokens, llm_hidden_dim)
"""
qformer_out = self.visual_qformer(visual_feats)
return self.visual_projector(qformer_out)
def forward(
self,
audio_feats: Tensor,
visual_feats: Tensor,
input_ids: Tensor,
attention_mask: Optional[Tensor] = None,
labels: Optional[Tensor] = None,
) -> Dict:
"""
Full RefThinker forward pass for training.
The multimodal input sequence is constructed as:
[audio_tokens (32)] [visual_tokens (32)] [text_tokens (L)]
This concatenated sequence is fed to the LLM decoder.
Cross-entropy loss is computed only on the text generation portion
(labels for the multimodal prefix are set to -100 / ignored).
Parameters
----------
audio_feats : (B, T_a, audio_feat_dim)
visual_feats : (B, T_v, visual_feat_dim)
input_ids : (B, L) tokenized input prompt + expected output
attention_mask: (B, L) text attention mask
labels : (B, L) target token IDs; -100 where loss is masked
Returns
-------
dict with 'loss', 'logits', 'audio_tokens', 'visual_tokens'
"""
B, L = input_ids.shape
Nq = self.cfg.num_query_tokens
D = self.cfg.llm_hidden_dim
# Encode modalities → LLM-space tokens
audio_tokens = self.encode_audio(audio_feats) # (B, Nq, D)
visual_tokens = self.encode_visual(visual_feats) # (B, Nq, D)
# Embed text tokens
pos_ids = torch.arange(L, device=input_ids.device).unsqueeze(0)
text_embs = self.token_embedding(input_ids) + self.pos_embedding(pos_ids)
# Concatenate: audio | visual | text
full_embs = torch.cat([audio_tokens, visual_tokens, text_embs], dim=1)
total_len = 2 * Nq + L
# Build attention mask for full sequence
prefix_mask = torch.ones(B, 2 * Nq, device=input_ids.device)
if attention_mask is not None:
full_mask = torch.cat([prefix_mask, attention_mask.float()], dim=1)
else:
full_mask = torch.ones(B, total_len, device=input_ids.device)
# Build causal mask
causal_mask = torch.triu(
torch.ones(total_len, total_len, device=input_ids.device), diagonal=1
).bool()
# LLM forward (decoder mode: memory = full sequence itself)
decoder_out = self.llm_backbone(
tgt=full_embs,
memory=full_embs,
tgt_mask=causal_mask,
tgt_key_padding_mask=(full_mask == 0),
)
logits = self.lm_head(decoder_out) # (B, total_len, vocab_size)
loss = None
if labels is not None:
# Pad labels for the multimodal prefix (no loss on those positions)
prefix_labels = torch.full(
(B, 2 * Nq), fill_value=-100, device=labels.device
)
full_labels = torch.cat([prefix_labels, labels], dim=1)
# Shift logits and labels for next-token prediction
shift_logits = logits[:, :-1].contiguous()
shift_labels = full_labels[:, 1:].contiguous()
loss = F.cross_entropy(
shift_logits.view(-1, self.cfg.vocab_size),
shift_labels.view(-1),
ignore_index=-100,
)
return {
"loss": loss,
"logits": logits,
"audio_tokens": audio_tokens,
"visual_tokens": visual_tokens,
}
@torch.no_grad()
def generate(
self,
audio_feats: Tensor,
visual_feats: Tensor,
prompt_ids: Tensor,
max_new_tokens: int = 512,
eos_token_id: int = 2,
) -> Tensor:
"""
Greedy autoregressive generation for Ref-Thinker inference.
Produces the think-answer chain token-by-token, stopping at
EOS or when max_new_tokens is reached.
Parameters
----------
audio_feats : (1, T_a, audio_feat_dim) — single video
visual_feats : (1, T_v, visual_feat_dim)
prompt_ids : (1, L_p) tokenized user prompt
max_new_tokens: maximum tokens to generate
eos_token_id : token ID for end-of-sequence
Returns
-------
generated_ids : (1, L_p + num_new_tokens) full sequence
"""
B = audio_feats.shape[0]
device = audio_feats.device
audio_tokens = self.encode_audio(audio_feats)
visual_tokens = self.encode_visual(visual_feats)
generated = prompt_ids.clone()
for _ in range(max_new_tokens):
L = generated.shape[1]
Nq = self.cfg.num_query_tokens
pos_ids = torch.arange(L, device=device).unsqueeze(0)
text_embs = self.token_embedding(generated) + self.pos_embedding(pos_ids)
full_embs = torch.cat([audio_tokens, visual_tokens, text_embs], dim=1)
total_len = 2 * Nq + L
causal_mask = torch.triu(
torch.ones(total_len, total_len, device=device), diagonal=1
).bool()
out = self.llm_backbone(
tgt=full_embs, memory=full_embs, tgt_mask=causal_mask
)
next_token_logits = self.lm_head(out[:, -1, :])
next_token = next_token_logits.argmax(dim=-1, keepdim=True)
generated = torch.cat([generated, next_token], dim=1)
if (next_token == eos_token_id).all():
break
return generated
# ─── SECTION 6: Output Parser — Extracting Object Descriptions ─────────────────
class RefThinkerOutputParser:
"""
Parses the structured think-answer output of Ref-Thinker into
the fine-grained (f_object) and simplified (s_object) descriptions
used as prompts for Grounding-DINO in the Ground step.
Expected output format:
... reasoning chain ...
fine-grained description
category name
"""
THINK_PATTERN = re.compile(r'(.*?) ', re.DOTALL)
F_OBJECT_PATTERN = re.compile(r'(.*?) ', re.DOTALL)
S_OBJECT_PATTERN = re.compile(r'(.*?) ', re.DOTALL)
@classmethod
def parse(cls, text: str) -> Dict[str, str]:
"""
Parse raw model output text into structured components.
Parameters
----------
text : raw generated string from RefThinker.generate()
Returns
-------
dict with keys: 'think', 'f_object', 's_object', 'raw'
Values are empty strings if the pattern is not found.
"""
think_match = cls.THINK_PATTERN.search(text)
f_object_match = cls.F_OBJECT_PATTERN.search(text)
s_object_match = cls.S_OBJECT_PATTERN.search(text)
return {
"think": think_match.group(1).strip() if think_match else "",
"f_object": f_object_match.group(1).strip() if f_object_match else "",
"s_object": s_object_match.group(1).strip() if s_object_match else "",
"raw": text,
}
@classmethod
def get_detection_prompt(cls, parsed: Dict[str, str],
use_fine_grained: bool = False) -> str:
"""
Return the appropriate object description string to pass to
Grounding-DINO.
Paper ablation finding: simplified (s_object) category description
generally works better because Grounding-DINO prefers short,
specific prompts. Fine-grained (f_object) is more useful when
multiple instances of the same category appear in the scene.
Parameters
----------
parsed : output of parse()
use_fine_grained : if True, return f_object; else return s_object
"""
if use_fine_grained:
return parsed.get("f_object", "") or parsed.get("s_object", "")
return parsed.get("s_object", "") or parsed.get("f_object", "")
# ─── SECTION 7: GroundingDINOWrapper — Open-Set Bounding Box Generation ────────
class BoundingBox:
"""Simple container for a bounding box prediction."""
def __init__(self, x1: float, y1: float, x2: float, y2: float, score: float):
self.x1 = x1; self.y1 = y1; self.x2 = x2; self.y2 = y2
self.score = score
def to_tuple(self) -> Tuple[float, float, float, float]:
return self.x1, self.y1, self.x2, self.y2
def __repr__(self):
return f"BBox([{self.x1:.2f},{self.y1:.2f},{self.x2:.2f},{self.y2:.2f}] s={self.score:.3f})"
class GroundingDINOWrapper:
"""
Wrapper for Grounding-DINO open-set object detection.
Grounding-DINO combines the DINO detector with large-scale grounded
pretraining, enabling detection from arbitrary text descriptions
(category names, referring expressions).
In TGS-Agent, this takes the T_f or T_s description from Ref-Thinker
and produces bounding boxes in each video frame.
Real usage:
from groundingdino.util.inference import load_model, predict
self.model = load_model(config_path, checkpoint_path)
This wrapper provides a mock implementation for demonstration,
which returns synthetic boxes to enable end-to-end smoke testing
without downloading model weights.
Paper: "We employ the Swin-T-based Grounding-DINO for object detection,
with frozen parameters."
"""
def __init__(self, cfg: GroundingConfig, use_mock: bool = True):
self.cfg = cfg
self.use_mock = use_mock
if not use_mock:
try:
from groundingdino.util.inference import load_model
# Real model: uncomment and provide paths
# self.model = load_model("path/to/config", "path/to/weights")
pass
except ImportError:
print("[GroundingDINO] groundingdino package not installed. "
"Install with: pip install groundingdino-py")
self.use_mock = True
def detect(self, image_np: np.ndarray, text_prompt: str) -> List[BoundingBox]:
"""
Detect objects matching text_prompt in a single image frame.
Parameters
----------
image_np : (H, W, 3) uint8 numpy array — one video frame
text_prompt : object description from Ref-Thinker (T_f or T_s)
Returns
-------
boxes : list of BoundingBox objects above the confidence thresholds
"""
if self.use_mock:
return self._mock_detect(image_np)
# Real implementation (requires groundingdino package):
# from groundingdino.util.inference import predict
# import torchvision.transforms as T
# transform = T.Compose([T.ToTensor(), T.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])])
# image_tensor = transform(image_np)
# boxes, logits, phrases = predict(
# model=self.model, image=image_tensor, caption=text_prompt,
# box_threshold=self.cfg.tau_bbox, text_threshold=self.cfg.tau_text
# )
# H, W = image_np.shape[:2]
# return [BoundingBox(b[0]*W, b[1]*H, b[2]*W, b[3]*H, l.item())
# for b, l in zip(boxes.tolist(), logits.tolist())]
return self._mock_detect(image_np)
def _mock_detect(self, image_np: np.ndarray) -> List[BoundingBox]:
"""Synthetic bounding box for smoke testing."""
H, W = image_np.shape[:2] if image_np.ndim == 3 else (256, 256)
return [BoundingBox(
x1=0.2 * W, y1=0.2 * H,
x2=0.7 * W, y2=0.8 * H,
score=0.85
)]
def detect_video(
self, frames: List[np.ndarray], text_prompt: str
) -> List[Optional[BoundingBox]]:
"""
Run detection on all N video frames for a single text prompt.
Returns a list of N BoundingBox objects (or None if no object
was detected in that frame above the threshold). A None box
causes the Segment step to default to an all-background mask.
"""
results = []
for frame in frames:
boxes = self.detect(frame, text_prompt)
if boxes:
best = max(boxes, key=lambda b: b.score)
results.append(best if best.score >= self.cfg.tau_bbox else None)
else:
results.append(None)
return results
# ─── SECTION 8: SAM2Wrapper — Frozen Mask Generation from Bounding Boxes ───────
class SAM2Wrapper:
"""
Wrapper for the frozen SAM2 model used in TGS-Agent's Segment step.
SAM2 receives bounding box prompts (one per frame) and produces
binary segmentation masks. No SAM2 weights are modified during
TGS-Agent training.
Paper: "Notably, the prior SOTA method also employs SAM2 but requires
fine-tuning its mask decoder. In contrast, our method leverages the
frozen SAM2 and achieves superior performance."
We use Hiera-Large-based SAM2 (paper default).
Real usage:
from sam2.build_sam import build_sam2_video_predictor
self.predictor = build_sam2_video_predictor(config, checkpoint)
This wrapper provides a mock implementation for smoke testing.
"""
def __init__(self, use_mock: bool = True):
self.use_mock = use_mock
if not use_mock:
try:
from sam2.build_sam import build_sam2_video_predictor
# self.predictor = build_sam2_video_predictor(config, checkpoint)
except ImportError:
print("[SAM2] sam2 package not found. Install from: "
"https://github.com/facebookresearch/segment-anything-2")
self.use_mock = True
def segment_video(
self,
frames: List[np.ndarray],
boxes: List[Optional[BoundingBox]],
) -> List[np.ndarray]:
"""
Generate binary segmentation masks for each video frame.
For frames where no bounding box is provided (None), the mask
defaults to all-background (all zeros).
Parameters
----------
frames : list of N (H, W, 3) uint8 numpy arrays
boxes : list of N BoundingBox objects or None
Returns
-------
masks : list of N (H, W) bool numpy arrays
True = foreground (referred object)
False = background
"""
if self.use_mock:
return self._mock_segment(frames, boxes)
# Real SAM2 implementation:
# inference_state = self.predictor.init_state(video=frames)
# for frame_idx, box in enumerate(boxes):
# if box is not None:
# self.predictor.add_new_points_or_box(
# inference_state, frame_idx, obj_id=1,
# box=np.array([box.x1, box.y1, box.x2, box.y2])
# )
# video_segments = {}
# for out_frame_idx, out_obj_ids, out_mask_logits in \
# self.predictor.propagate_in_video(inference_state):
# video_segments[out_frame_idx] = (out_mask_logits > 0).cpu().numpy()[0, 0]
# return [video_segments.get(i, np.zeros(frames[0].shape[:2], bool))
# for i in range(len(frames))]
return self._mock_segment(frames, boxes)
def _mock_segment(
self,
frames: List[np.ndarray],
boxes: List[Optional[BoundingBox]],
) -> List[np.ndarray]:
"""Synthetic binary masks for smoke testing."""
masks = []
for frame, box in zip(frames, boxes):
H = frame.shape[0] if frame.ndim >= 2 else 256
W = frame.shape[1] if frame.ndim >= 2 else 256
mask = np.zeros((H, W), dtype=bool)
if box is not None:
x1 = int(max(0, box.x1)); y1 = int(max(0, box.y1))
x2 = int(min(W, box.x2)); y2 = int(min(H, box.y2))
mask[y1:y2, x1:x2] = True
masks.append(mask)
return masks
# ─── SECTION 9: TGSAgent — Complete Think-Ground-Segment Pipeline ───────────────
class TGSAgent(nn.Module):
"""
TGS-Agent: An Object-aware Reasoning Agent for Referring Audio-Visual Segmentation.
Full system implementing the Think → Ground → Segment pipeline:
Think: RefThinker(A, V, R, P) → T (reasoning chain + object description)
Ground: GroundingDINO(T_s or T_f, V) → B (bounding boxes per frame)
Segment: SAM2(B, V) → M (binary masks per frame)
The pipeline transforms:
(audio stream + video frames + reference expression)
→ explicit object description
→ bounding boxes
→ pixel-level segmentation masks
Key design choices:
1. No pixel-level supervision required during inference
2. SAM2 is used completely frozen (no mask decoder fine-tuning)
3. Grounding-DINO is frozen (no detection head fine-tuning)
4. Only Ref-Thinker is trained (Q-Formers, projectors, LoRA)
5. Segmentation is interpretable at every step
Paper: "Our TGS-Agent completes the transformation from audiovisual
streams + reference text → object description → bbox → mask,
demonstrating an object-aware, reliable, and explainable decision
process for Ref-AVS task."
"""
def __init__(
self,
ref_thinker_cfg: RefThinkerConfig,
grounding_cfg: GroundingConfig,
use_mock_tools: bool = True,
use_fine_grained: bool = False,
):
super().__init__()
self.ref_thinker = RefThinker(ref_thinker_cfg)
self.parser = RefThinkerOutputParser()
self.detector = GroundingDINOWrapper(grounding_cfg, use_mock=use_mock_tools)
self.segmentor = SAM2Wrapper(use_mock=use_mock_tools)
self.use_fine_grained = use_fine_grained
def forward(
self,
audio_feats: Tensor,
visual_feats: Tensor,
input_ids: Tensor,
attention_mask: Optional[Tensor] = None,
labels: Optional[Tensor] = None,
) -> Dict:
"""
Training forward pass: computes cross-entropy loss on the
think-answer generation task. Only Ref-Thinker is optimized.
Parameters
----------
audio_feats : (B, T_a, audio_feat_dim)
visual_feats : (B, T_v, visual_feat_dim)
input_ids : (B, L) tokenized prompt + expected output
attention_mask: (B, L)
labels : (B, L) — -100 for positions where loss is masked
Returns
-------
dict from RefThinker.forward() with 'loss', 'logits', etc.
"""
return self.ref_thinker(audio_feats, visual_feats,
input_ids, attention_mask, labels)
@torch.no_grad()
def inference(
self,
audio_feats: Tensor,
visual_feats: Tensor,
prompt_ids: Tensor,
frames: List[np.ndarray],
tokenizer_decode_fn=None,
) -> Dict:
"""
Full inference pipeline: Think → Ground → Segment.
Parameters
----------
audio_feats : (1, T_a, audio_feat_dim) — single video
visual_feats : (1, T_v, visual_feat_dim)
prompt_ids : (1, L_p) tokenized user prompt
frames : list of N (H, W, 3) uint8 numpy arrays
tokenizer_decode_fn : callable to convert token IDs to text
(use tokenizer.decode in real usage)
Returns
-------
dict with:
'think_chain' : str — the ... reasoning
'f_object' : str — fine-grained object description
's_object' : str — simplified category name
'boxes' : list of BoundingBox or None (N frames)
'masks' : list of (H,W) bool numpy arrays (N frames)
'detection_prompt' : str used for Grounding-DINO
"""
# ── Step 1: Think ─────────────────────────────────────────────────────
generated_ids = self.ref_thinker.generate(
audio_feats, visual_feats, prompt_ids
)
if tokenizer_decode_fn is not None:
raw_text = tokenizer_decode_fn(generated_ids[0].tolist())
else:
raw_text = (
" The video shows a woman playing a piano and a man "
"playing a bassoon. The audio contains the sound of both instruments. "
"The reference relates to the piano being played by the woman. "
"a black grand piano "
"piano Explore More on AI Trend Blend
If this article sparked your interest, here is more of what we cover — from foundational tutorials to the latest conference research in computer vision, multimodal AI, and beyond.