Why Your AI Says It’s Confident When It Shouldn’t Be — And How MaxWEnt Fixes It
Researchers from Michelin and the Centre Borelli at ENS Paris-Saclay have built a smarter way to make neural networks say “I don’t know” — by maximizing the diversity of possible network weights rather than relying on standard regularization that quietly kills genuine uncertainty. The result lands in the top three across thirty-plus competing methods in every benchmark configuration tested.
Every deployed AI model will eventually encounter data it was never trained on. An autonomous car hits an unprecedented weather condition. A medical diagnosis system receives an image from a scanner it has never seen before. A fraud detection model faces a brand-new attack pattern. The critical question is not just whether the model gets it wrong — it’s whether the model knows it might be wrong. Standard Bayesian and ensemble methods, despite their theoretical promise, routinely fail this test. They look appropriately uncertain during training but become overconfident exactly when it matters most — out in the wild, on data that looks nothing like what they were trained on. This paper explains why that happens and builds a principled, practical fix.
The Confidence Problem Nobody Talks About Enough
Think about how a neural network ensemble works. You train five networks independently with different random seeds. When they all agree on a prediction, you call it confident. When they disagree, you call it uncertain. The idea sounds perfectly reasonable — and it works well when you stay close to the training distribution. The problem emerges when you venture beyond it.
When you train each of those five networks using standard practices — weight decay regularization, small random initialization, validation-based hyperparameter tuning — all five end up in roughly the same region of weight space. They might have numerically different values, but they are all “nearby” in a meaningful geometric sense. They produce different predictions inside the training distribution because the optimization paths diverged slightly. But outside the training distribution, all five networks converge to the same overconfident behavior. The ensemble gives you a false sense of security: the agreement between the five networks is not evidence of correctness — it is evidence that all five were trained to look the same.
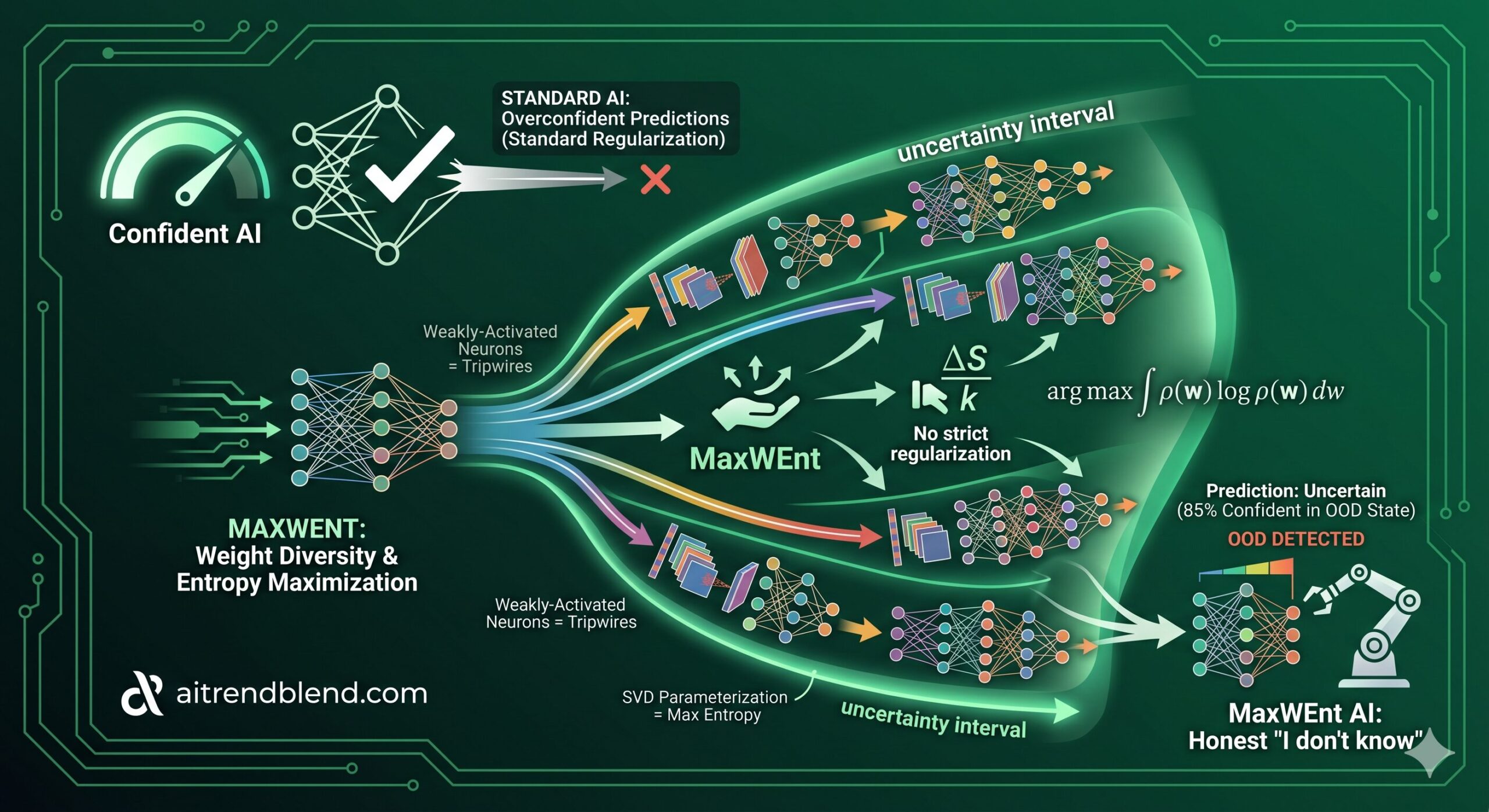
This is the central diagnosis in the paper. The authors call it a lack of weight diversity. Standard regularization methods — particularly weight decay, which penalizes large weights, and small-variance initialization, which starts all networks in similar neighborhoods — act as invisible fences that prevent networks from exploring the full space of models that would explain the training data equally well. The result is that the ensemble samples from a narrow, over-restricted corner of weight space, and anything outside the training distribution looks identical and equally “familiar” to all five networks.
Weight decay keeps networks small. Small-weight initialization keeps them similar. Validation-based tuning rewards in-distribution accuracy, not out-of-distribution honesty. Together, these three standard practices turn a theoretically diverse ensemble into a collection of near-identical models that confidently agree — even when they have no business doing so.
An Old Principle With a New Application
The solution this paper proposes draws on a principle from information theory that dates back to E.T. Jaynes in the 1950s: when you have incomplete information, the best description of your uncertainty is the probability distribution with the maximum entropy that is still consistent with what you know. In everyday terms — do not assume more than your evidence supports.
Applied to neural network weights, this principle becomes surprisingly concrete. Among all weight distributions that produce networks consistent with the training data, pick the one with the highest entropy — the broadest, most spread-out distribution. A narrow, peaked distribution produces overconfident models that agree with each other even in unexplored territory. A broad distribution — subject to the constraint that sampled networks still explain the training data — represents genuine uncertainty about what the right model actually is.
The authors turn this into an optimization objective with two competing terms. The first term minimizes the average training loss across sampled weights, keeping the model accurate on what it has seen. The second term maximizes the entropy of the weight distribution, pushing the distribution to spread as widely as the first term allows. The trade-off between the two is controlled by a single hyperparameter λ. When λ is large, the algorithm prioritizes exploration. When λ is small, it stays close to the pretrained network. In practice, the paper finds λ = 10 (scaled by the number of parameters) works robustly across experiments without dataset-specific tuning.
They call this method MaxWEnt — Maximum Weight Entropy — and show that it can be implemented cleanly on top of any pretrained network using stochastic variational inference with the reparameterization trick. The pretrained weights serve as the fixed mean of the weight distribution; only the scale parameters that control the spread are learned during the MaxWEnt phase.
Why Weakly-Activated Neurons Become OOD Detectors
One of the most elegant theoretical results in the paper is a precise characterization of what the MaxWEnt optimization actually does to individual neurons. In the linear regression case — which gives clean intuition for what happens inside each layer — the paper proves that the optimal scale parameters are exactly inversely proportional to the neuron activation amplitude on the training data.
“Neurons that are weakly activated by the training distribution get the largest weight variance — and therefore act as detectors for out-of-distribution inputs that activate them strongly.” — de Mathelin, Deheeger, Mougeot, Vayatis · JMLR 26 (2025)
This is a beautiful insight. If a neuron rarely fires on training data, its weights have almost no impact on training performance — the entropy maximization can spread the weight distribution very broadly over those weights at almost zero cost to training accuracy. But when an out-of-distribution input comes along and activates one of those dormant neurons strongly, a high-variance, unpredictable signal propagates through the network, producing large output variance — which the user sees as high predicted uncertainty.
In effect, the network has learned to use its least-used neurons as tripwires for the unknown. Every neuron that training data consistently ignores becomes part of the model’s alarm system for inputs it has never encountered. This theoretical connection between weight spread, neuron activation, and OOD sensitivity is supported by direct empirical observation in the paper’s synthetic experiments, where the inverse-proportionality relationship is clearly visible in plots of scale parameters against activation amplitudes layer by layer.
Two Parameterizations — and Why SVD Wins
The paper introduces two concrete implementations of the stochastic weight distribution. Both share the same underlying idea: sample network weights by adding a scaled random perturbation to the pretrained weights. Where they differ is in how that perturbation is structured.
Scaling Parameterization
Each weight gets its own independent scale factor. The perturbation is just the element-wise product of a learned scale vector and a random noise vector. Simple, fast, and effective. The weight entropy has a clean closed form as the sum of log-scale-squared terms. Works well for basic OOD detection and is the right starting point for anyone new to MaxWEnt.
SVD Parameterization
The perturbation is rotated into the basis defined by the singular value decomposition of the neuron activation matrix on training data. This aligns the weight distribution with the directions the training data leaves most unconstrained — achieving strictly higher entropy at the same training risk. Theoretically superior by Hadamard’s inequality, and empirically the best performer across every benchmark in the paper.
The motivation for the SVD variant comes from a simple observation about correlated neurons. If two neurons in the same layer are highly correlated on the training data, treating their weights as independently distributed misses an opportunity: in the combined activation space, one direction is well-constrained by training data and the other is almost free. The SVD parameterization finds those free directions explicitly — by decomposing the activation matrix — and concentrates the weight entropy expansion there. The paper proves formally that SVD achieves the same average training risk as independent scaling but with strictly higher entropy, making it the more efficient parameterization in the maximum entropy sense.
There is a practical cost: the SVD computation requires one extra forward pass through the training data before optimization begins, and each gradient step involves an additional matrix multiplication. The paper estimates this roughly doubles the per-iteration cost compared to the simpler scaling version. For most real-world applications, the improvement in OOD detection — which is substantial, as shown in the benchmarks — is worth it.
What the Benchmarks Actually Show
The paper tests MaxWEnt across four experimental settings of increasing realism and difficulty: synthetic two-dimensional datasets, UCI tabular regression benchmarks, a real-world traffic camera counting task, and the comprehensive OpenOOD benchmark that includes more than thirty competing methods across multiple dataset families.
On the UCI regression benchmarks, the authors split each dataset into training and OOD regions along the first principal component of the input space — an approach that creates both extrapolation scenarios (OOD data lies outside the training range) and interpolation scenarios (OOD data sits between two training regions, which is harder to detect). The numbers are stark. MaxWEnt-SVD with ensembling achieves an average AUROC of 92.7% on extrapolation and 87.3% on interpolation. The next-best non-MaxWEnt method reaches 81.4% on extrapolation and 69.3% on interpolation — gaps of 11 and 18 percentage points respectively.
| Method | Avg AUROC (Extrap.) | Avg AUROC (Interp.) | Rank |
|---|---|---|---|
| Deep Ensemble | 75.9 | 67.6 | 9 |
| Negative Correlation | 79.4 | 68.2 | 5 |
| Repulsive Deep Ensemble | 77.6 | 69.3 | 7 |
| BNN (×5) | 81.4 | 59.2 | 4 |
| MaxWEnt (×5) | 85.9 | 71.4 | 3 |
| MaxWEnt-SVD (×5) | 92.7 | 87.3 | 1 |
The real-world CityCam experiment is even more compelling as a demonstration. Cameras monitoring city traffic were recorded on a day when rain progressively degraded the image quality — raindrops landing on the lens blurred the images until, around 5:30 pm, even a human annotator could not accurately count the vehicles. Deep Ensemble, during this degradation period, actually became more confident as the image quality dropped — the kind of paradoxical overconfidence that would be genuinely dangerous in a deployed system. MaxWEnt, by contrast, showed progressively widening uncertainty intervals that tracked the actual difficulty of the task in real time. On the quantitative metric, every baseline method produces a False Positive Rate at 95% (FPR@95) score of around 97–99% on the camera-shift and weather-shift experiments, meaning they almost never flag degraded inputs as uncertain. MaxWEnt-SVD achieves a FPR@95 of 29.4% (single network) and 15.3% (ensemble of five).
On the OpenOOD benchmark — the most comprehensive comparison, covering open-set recognition and both near-OOD and far-OOD detection across MNIST, CIFAR-10, CIFAR-100, and TinyImageNet — MaxWEnt ranks first in the challenging near-OOD and open-set recognition experiments, and third overall across all thirty-plus competitors, while using no auxiliary OOD data during training.
The Honest Trade-Off — In-Distribution Accuracy Does Suffer
The paper is careful not to oversell the method, and the trade-off it acknowledges is a real one. Maximizing weight entropy — by design — produces larger uncertainty intervals even within the training distribution. This means that standard in-distribution metrics like negative log-likelihood and calibration error are typically worse for MaxWEnt than for standard baselines. Confidence intervals are wider than they need to be for data the model has actually seen, which looks bad on the usual held-out test set metrics.
The practical recommendation that emerges from this finding is a two-mode inference strategy. For OOD detection — deciding whether an input should be trusted at all — use the full, unclipped MaxWEnt distribution. Its high entropy is a feature, not a bug, and produces the strong detection results the benchmarks show. Once a test point has been identified as likely in-distribution, switch to a clipped version of the same distribution, where the sampling noise is bounded by a parameter selected on the validation set. The clipping narrows the distribution back down, recovering in-distribution accuracy without retraining the model.
This dual-inference approach requires two forward passes instead of one, which is a real overhead. But for safety-critical deployments — medical image analysis, autonomous perception, industrial quality monitoring — the ability to reliably flag unfamiliar inputs before acting on them is worth far more than the marginal compute cost. The clipping parameter can be tuned after training on the validation set without any additional gradient steps, making the whole setup modular and practical.
How MaxWEnt Connects to Bayesian Neural Networks
The paper draws a precise connection between MaxWEnt and the Bayesian variational inference framework that underpins standard Bayesian neural networks. When you set up the standard ELBO (Evidence Lower Bound) maximization with a uniform prior over the weight space — which is what the maximum entropy principle recommends in the absence of prior knowledge — the resulting objective is mathematically equivalent to the MaxWEnt optimization. This is not a coincidence: it is the Bayesian expression of the same maximum entropy principle.
The reason standard Bayesian neural networks fail to behave like MaxWEnt comes down to their priors. The most commonly used prior — a zero-mean isotropic Gaussian — is “unintentionally informative,” as the paper puts it, quoting recent Bayesian deep learning literature. It pushes the posterior toward small weights in exactly the same way weight decay does, recreating the over-restriction problem under a Bayesian label. A Gaussian prior with very large variance approaches the uniform prior of maximum entropy, and the paper shows empirically that BNNs with large prior variance and frozen mean behave increasingly like MaxWEnt — a finding confirmed through a careful ablation study in the appendix. The practical lesson is that the prior choice in a Bayesian neural network is not neutral: it directly determines how diverse the resulting weight distribution is, and therefore how well the model detects OOD inputs.
What Comes Next — Open Problems the Paper Identifies
The authors close the paper with an honest assessment of what remains to be done. The SVD parameterization is currently implemented only for fully-connected layers; extending it to convolutional architectures requires computing the SVD of all spatial window activations stacked together, which is computationally heavy at scale but theoretically straightforward. The per-iteration cost of the SVD variant could likely be reduced significantly by using Laplace-like closed-form approximations instead of iterative gradient descent — the paper notes that similarities already exist between the SVD basis and the Kronecker Laplace approximation used in scalable Bayesian deep learning. Finally, because MaxWEnt assumes the network class is rich enough to contain the true model, it may underestimate uncertainty in problems where the architecture is genuinely misspecified — a limitation it shares with all ensemble and variational methods.
More sophisticated stochastic models — normalizing flows over weight space, weight distributions defined over low-dimensional subspaces, or implicit weight models — could push the achievable entropy even higher for the same training risk, potentially closing the gap further between MaxWEnt-SVD and a hypothetical ideal uncertainty quantifier. The maximum entropy framework the paper establishes gives a clear criterion for evaluating any such future method: if it achieves higher entropy at the same training risk, it should be preferred for OOD detection.
Why This Paper Matters — The Bigger Picture
The benchmark numbers are impressive, but the deeper contribution is the reframing it offers. The paper gives practitioners a concrete principle they can reason about and act on: weight diversity is the right target for out-of-distribution uncertainty, and the standard toolkit of weight decay, small initialization, and validation-based hyperparameter tuning systematically destroys it. This is not a subtle effect buried in edge cases — it shows up dramatically in every experiment, from the simplest synthetic dataset to the most competitive classification benchmark.
The practical implications are significant for anyone deploying deep learning models in the real world. Standard uncertainty estimation methods look good on held-out test sets drawn from the same distribution as training data — which is exactly the setting where epistemic uncertainty is least important. Their failure mode is invisible until deployment, when the distribution shifts and the model’s overconfidence becomes a liability. MaxWEnt addresses this failure mode directly, at the cost of slightly wider uncertainty intervals on familiar data — a trade-off that is almost always worth accepting in safety-critical contexts.
For teams already using deep ensembles, the barrier to adopting MaxWEnt is low. The method plugs into any pretrained network, requires only a few additional epochs of training with a single hyperparameter, and produces a stochastic model that can be used with any existing ensemble infrastructure. The SVD variant adds one preprocessing step before training begins. Neither variant requires auxiliary OOD data, access to test data, or architectural changes. For the improvement in OOD detection it delivers, MaxWEnt is one of the most practical advances in uncertainty quantification for deep learning in recent years.
Read the Full Paper and Code
Published open access in the Journal of Machine Learning Research, Volume 26 (2025). Source code available on GitHub under the paper’s official repository.
Antoine de Mathelin, François Deheeger, Mathilde Mougeot, Nicolas Vayatis. Deep Out-of-Distribution Uncertainty Quantification via Weight Entropy Maximization. Journal of Machine Learning Research, 26 (2025) 1–68. https://jmlr.org/papers/v26/23-1359.html
This article is an independent editorial analysis of a peer-reviewed open-access paper. Mathematical statements paraphrase the original results; for complete proofs and precise formulations, refer to the published paper. Submitted 10/23, revised 10/24, published 1/25 under CC-BY 4.0.
Key References
- [1] B. Lakshminarayanan, A. Pritzel, C. Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles. NeurIPS, 2017.
- [2] Y. Ovadia et al. Can you trust your model’s uncertainty? Evaluating predictive uncertainty under dataset shift. NeurIPS, 2019.
- [3] Y. Liu et al. The peril of popular deep learning uncertainty estimation methods. arXiv:2112.05000, 2021.
- [4] E.T. Jaynes. Prior probabilities. IEEE Transactions on Systems Science and Cybernetics, 4(3):227–241, 1968.
- [5] D.P. Kingma, M. Welling. Auto-encoding variational Bayes. ICLR, 2014.
- [6] F. Wenzel et al. How good is the Bayes posterior in deep neural networks really? ICML, 2020.
- [7] J. Yang et al. OpenOOD: Benchmarking generalized out-of-distribution detection. arXiv:2210.07242, 2022.
- [8] A. de Mathelin et al. Deep anti-regularized ensembles provide reliable OOD uncertainty quantification. arXiv:2304.04042, 2023.
- [9] J. Van Amersfoort et al. Uncertainty estimation using a single deep deterministic neural network. ICML, 2020.
- [10] Y. Gal, Z. Ghahramani. Dropout as a Bayesian approximation: representing model uncertainty in deep learning. ICML, 2016.