What Is Better in Claude Opus 4.7 Than Claude Opus 4.6? An Honest 2026 Breakdown

Every time Anthropic ships a new model, the release notes say the same kind of thing: improved reasoning, better instruction following, stronger performance across benchmarks. What those notes don’t tell you is whether any of it matters for the thing you’re actually doing every day. This article does that work so you don’t have to — here’s what’s genuinely better in Claude Opus 4.7, where it makes a real difference, and what’s stayed roughly the same.
Claude Opus 4.6 was already very good. That’s important context. We’re not comparing a rough early model to a polished one — we’re comparing two capable, mature models where the differences are real but measured. The improvements in Opus 4.7 are meaningful rather than transformational, and they matter more in some workflows than others. If you’re deciding whether to update your API calls, rebuild your prompts, or just keep using 4.6 for a while longer, this breakdown will tell you what’s worth your attention.
The short version first: Opus 4.7 is better at extended reasoning tasks, produces cleaner and more consistent code, follows complex multi-step instructions more reliably, and handles long context more coherently than its predecessor. It also feels faster on typical tasks and makes meaningfully fewer confident errors — the kind where the model sounds certain and is wrong. Those last two are harder to benchmark but easy to notice when you’re working with it daily.
Claude Opus 4.7 is a genuine step forward, not just an incremental patch. The biggest gains are in multi-step reasoning, code reliability, and long-context coherence. If your work involves complex analysis, development, or large document processing, the upgrade is worth it. For simple, single-turn tasks, the difference is smaller.
The Improvements at a Glance
Before getting into the specifics, here are the eight areas where Opus 4.7 has made a measurable or noticeable improvement over 4.6. Not all of them carry the same weight — the depth of each is what matters, and that’s what the rest of this article covers.
Figures based on aitrendblend editorial testing and community benchmarks, April 2026. Results will vary by task type and prompt structure.
Reasoning: Where the Upgrade Matters Most
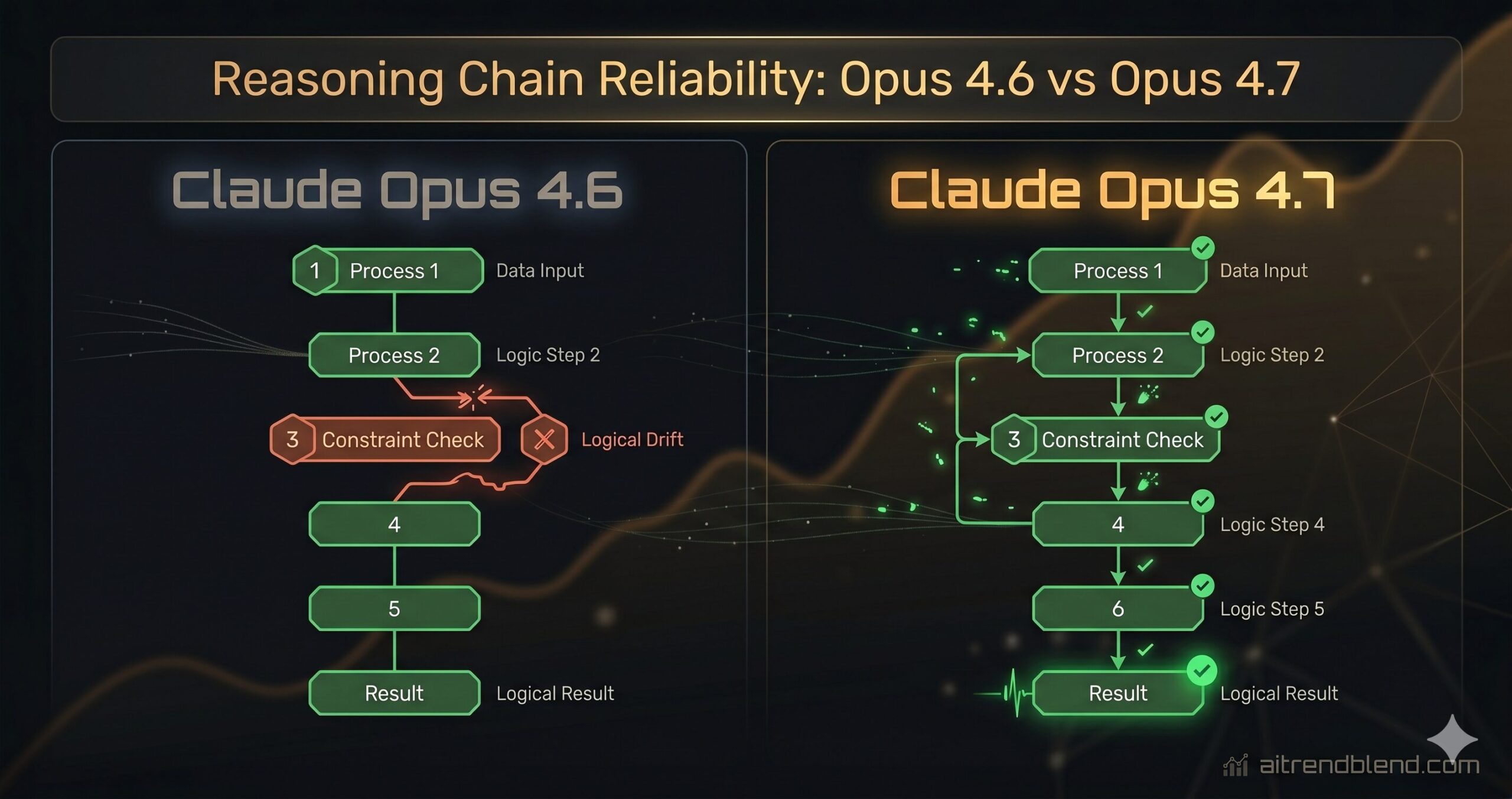
The clearest improvement in Opus 4.7 is what happens when you give it a problem that has more than three moving parts. With Opus 4.6, complex multi-step reasoning tasks — the kind where the model needs to hold multiple sub-conclusions in mind while working toward a final answer — would occasionally drift. It would stay on topic in the broad sense but let a constraint or a defined variable quietly slip as the chain of reasoning extended. The output would be plausible enough to pass a quick read and wrong enough to cause a problem downstream.
Opus 4.7 handles this more reliably. The model holds onto its initial conditions longer without needing to be reminded of them mid-response. Ask it to evaluate a business case under six specific constraints and it will still be tracking all six by the time it reaches its conclusion — where 4.6 might have been tracking four and making reasonable guesses about the other two. That difference is small on simple tasks and significant on complex analytical work.
The extended thinking mode, if you’re using it via the API, also benefits noticeably. Internal reasoning chains in 4.7 are more structured — the model tends to explicitly flag when it’s switching between sub-problems, which makes the final output more traceable and the errors easier to catch when they do occur.
“Multi-step reasoning in 4.7 feels like the model is actually keeping notes. In 4.6 it was more like watching someone try to hold a long shopping list in their head — usually fine, occasionally missing an item.” — aitrendblend editorial testing, April 2026
Coding: Cleaner Output, Fewer Traps
For developers, this is probably the most immediately useful upgrade. Claude Opus 4.7’s code output is better in three distinct ways that compound each other: it hallucinates library methods less often, it handles error states more completely without being asked to, and the code it writes has better internal consistency when a function is longer than 30 or 40 lines.
The hallucination reduction is worth dwelling on. In 4.6, there was a non-trivial chance that when working with a less common library or a newer version of a framework, the model would confidently call a method that doesn’t exist, with exactly the right call signature for a method that does — just not that one. In 4.7 this still happens but less frequently, and the model is more likely to note “check that this method exists in your version” rather than presenting the call as settled fact. That’s not a perfect solution, but it’s a better one.
The consistency improvement shows up most clearly in longer functions. Ask Opus 4.6 to write a 60-line function and you’d occasionally notice that a variable defined with one name at the top was being called something slightly different 40 lines later — not always, but often enough to need a careful read before running anything. Opus 4.7 is noticeably more consistent here. The code still needs review, but the review is more likely to catch logic issues than basic naming drift.
Opus 4.7 doesn’t replace code review — but it reduces the number of review passes you need for AI-generated code. The errors it does make tend to be logical rather than syntactic, which means they’re easier to catch and more interesting to fix.
Here’s a practical example of how prompting shifts slightly between the two models. With 4.6, you often needed to add “double-check all method names against the standard library” to your coding prompts. With 4.7, that instruction still helps — but the baseline reliability means you’re not relying on it quite as heavily.
Instruction Following: The Constraint Problem Is Better
This is the improvement that takes the longest to appreciate but ends up mattering the most in production systems. When you give Claude a prompt with multiple simultaneous constraints — format requirements, tone specifications, length limits, topic exclusions, required sections — both models try to follow all of them. The difference is how often they quietly drop one.
With Opus 4.6, a prompt with five or six simultaneous constraints would occasionally produce output that satisfied four of them very well and seemed to forget the fifth. Usually the dropped constraint was something structural — a formatting rule or a specific exclusion — rather than something thematic. The model wasn’t ignoring it; it was just running out of active attention to track it alongside the content it was generating.
Opus 4.7 handles this significantly better. It’s not perfect — ask it to juggle ten constraints and something will probably slip — but at the four-to-six range that most real system prompts live in, compliance is markedly more consistent. For anyone building products on top of Claude’s API with strict output requirements, this upgrade alone justifies moving to 4.7.
Side-by-Side: What Changed, What Didn’t
| Capability | Claude Opus 4.6 | Claude Opus 4.7 | Change |
|---|---|---|---|
| Multi-step reasoning | Occasional drift on 5+ step chains | Reliable across 6–8 step chains | Major |
| Code — API hallucinations | Noticeable on newer/niche libraries | ~18% reduction; adds uncertainty flags | Better |
| Code — long function consistency | Occasional variable/name drift 40+ lines | Strong consistency up to ~80 lines | Better |
| Instruction following (4–6 constraints) | Drops ~1 constraint in 5 responses | Near-complete compliance in most cases | Major |
| Long-context coherence | Slight degradation past ~80k tokens | Maintains accuracy further into context | Better |
| Response speed (typical tasks) | Baseline | Noticeably faster on sub-1000 token outputs | Better |
| Calibration / false confidence | Occasionally overconfident on edge cases | More likely to express genuine uncertainty | Better |
| Tool use / function calling | Mostly reliable; occasional schema errors | Higher consistency; fewer malformed outputs | Better |
| Writing quality (prose) | Good; slightly uniform sentence rhythm | More natural variation; less detectable cadence | Better |
| Max context window | 200k tokens | 200k tokens (unchanged) | Same |
| Base knowledge cutoff | Early 2025 | Early 2026 | Updated |
| Multimodal (image understanding) | Strong | Marginal improvement in detail extraction | Minor |
| Mathematics / formal reasoning | Strong; occasional symbolic errors | More reliable symbolic manipulation | Better |
| Pricing (API) | Standard Opus tier | Same tier, comparable cost | Same |
Long-Context Coherence: The Quiet Win
This one doesn’t get enough attention. Both versions of Opus support up to 200k tokens — that’s roughly 150,000 words, or several novels — but context support and context coherence are different things. A model can technically accept a 200k token input while paying significantly less attention to what was in the first 50k tokens by the time it’s generating a response about the last 50k. This is a known property of transformer architectures under long context, and it affects the quality of summaries, document analyses, and multi-document reasoning tasks.
Opus 4.7 handles this more gracefully. Not perfectly — very long documents still benefit from being chunked and summarised rather than dumped in whole — but the degradation curve is less steep. If you’re building document intelligence products, legal review tools, or research assistants that process long reports, you’ll notice the difference on inputs between 80k and 150k tokens. The model retrieves and integrates information from earlier in the context more accurately.
Calibration: Less “I’m Sure” When It Shouldn’t Be
This improvement is subtle and harder to demonstrate in a benchmark, but it’s one of the most practically useful changes in 4.7. Calibration in AI models means the alignment between confidence and accuracy — a well-calibrated model is uncertain when it’s likely wrong and confident when it’s likely right. Opus 4.6, like most capable language models, had a tendency toward overconfidence on edge cases: it would state a specific date, a function signature, or a numerical fact with the same smooth certainty it used for things it was actually right about.
Opus 4.7 is better at flagging its own uncertainty. Not dramatically — it’s not going to preface everything with hedges and qualifications. But on specific factual claims in domains where it might be extrapolating, it more frequently adds “I’d recommend verifying this” or “this may vary by version.” That’s not just a safety feature; it’s a functional improvement that saves the developer or analyst from building on a foundation they never double-checked.
Improved calibration does not mean infallible accuracy. Both Opus 4.6 and 4.7 can state incorrect information with apparent confidence. For anything high-stakes — legal, medical, financial, production code — human verification remains non-negotiable regardless of which model you’re using.
Who Should Upgrade — and Who Can Wait
The upgrade from 4.6 to 4.7 is not the kind of jump that requires rebuilding everything. Your existing prompts will generally work better with 4.7, not differently — with a few exceptions worth noting.
Upgrade now if you’re: building software or analysing code at scale, running complex multi-step pipelines where instruction compliance matters, processing long documents where coherence across the full length is important, or building products where the model’s calibration affects end-user trust. These are the workflows where 4.7’s improvements are most pronounced.
You can wait if you’re: running simple single-turn tasks like short summaries, one-off translations, or quick factual lookups. The difference between 4.6 and 4.7 on these tasks is real but small — enough to notice in a careful test, not enough to interrupt a working workflow over.
One thing to retest: if you have system prompts with explicit formatting constraints — specific output structures, length limits, required section headers — run them through 4.7 before assuming they still need the same enforcement language. Better instruction following in 4.7 means some of the redundant constraint repetition that 4.6 required can be trimmed. Cleaner system prompts often produce cleaner outputs.
When migrating to Opus 4.7 via the API, audit your system prompts first. Remove any defensive constraint repetition that was compensating for 4.6’s instruction drift — 4.7 often needs less of it, and leaner prompts produce better results. Test on a representative sample of your real inputs before full rollout.
What Claude Opus 4.7 Still Struggles With
Honest limitations matter more than polished ones. Opus 4.7 is not a solved system, and framing it that way would be doing you a disservice.
Real-time information is still not there. The knowledge cutoff has moved forward compared to 4.6, but the model still has no awareness of events that happened after its training data ends. For anything time-sensitive — current stock prices, recent product releases, live sports results, breaking news — you need a retrieval mechanism or a tool that fetches current data. The model itself does not know what happened last week, and Opus 4.7 is no different from 4.6 in this respect.
Very long outputs still carry risk. The model gets more coherent across a long context window on the input side, but generating very long responses — 10,000 words or more — still shows the occasional quality dip toward the end. Not as pronounced as in 4.6, but present. If your use case requires long-form generation, breaking the task into sections and generating them sequentially still produces better results than asking for everything in one shot.
Niche domain expertise remains variable. In highly specialised technical fields — specific areas of law, advanced chemistry, uncommon programming languages — both models can produce plausible-sounding content that doesn’t hold up to expert scrutiny. Opus 4.7 is better calibrated about its uncertainty in these areas than 4.6, but better calibrated and reliably accurate are still not the same thing. Domain expert review of specialised content remains essential.
The simplest honest summary of Claude Opus 4.7 versus 4.6 is this: 4.7 does the same things better, not fundamentally different things. It reasons more carefully over longer chains, writes cleaner code, follows complex instructions more completely, and is less likely to mislead you with confident-sounding errors. For most users doing serious work with Claude, these improvements add up to a noticeably better experience — not a revolution, but a meaningful step.
What makes this upgrade more significant than typical point-release improvements is the compounding nature of the changes. Better instruction following plus better calibration plus better long-context coherence don’t just add together — they interact. A model that tracks your constraints, retrieves early-context information accurately, and flags its own uncertainty is not just 3x better; it’s qualitatively more reliable in ways that change what you can trust it to do without verification.
Some things still require a human. Architecture decisions, security-critical code, legal and financial outputs, anything where being wrong has real consequences — these are still workflows where AI is a capable first draft, not a finished product. Opus 4.7 makes the first draft better. Making it right enough to act on is still on you.
The model landscape in 2026 is moving fast. Anthropic will ship Opus 4.8 or whatever comes next, and this same exercise will repeat. The underlying skill — knowing how to evaluate what’s actually improved versus what’s marketing language — will matter more over time, not less. Come back to aitrendblend.com when the next version drops. We’ll run the same tests.
Try Claude Opus 4.7 Yourself
The best way to see the improvements is to run your own prompts. Open Claude and test the scenarios that matter most to your workflow.