Building AI Factories: Data, Methods, and Algorithms for Internal AI That Compounds
That answer is uncomfortable for teams that want to skip to the exciting bit — the models, the outputs, the demos. But it accurately describes how organizations that have built durable internal AI capabilities actually operate. The models are, increasingly, a commodity. The data infrastructure, labeling systems, feedback loops, and algorithm selection frameworks that sit beneath them — that is the factory. That is the part that compounds. That is the part your competitors cannot replicate simply by licensing the same model you use.
This article goes deeper than strategy. It covers the practical engineering of each layer: how to identify and value your proprietary data assets, how to build labeling systems that don’t collapse at scale, how to select algorithms for specific internal tasks rather than defaulting to whatever is largest and most popular, and how to wire the feedback loop that turns a one-time model deployment into a system that improves continuously. Ten prompt templates give you immediate tools to start building.
The framing throughout is deliberately operational. Not “what is an AI Factory” but “how do you actually build one” — the decisions, the tradeoffs, and the places where most well-intentioned efforts quietly stall.
Why 80% of AI Factory Work Happens Before the Model Training Starts
Here is where it gets uncomfortable: the first version of an AI Factory that most organizations need to build is not an AI system. It is a data system. Before you can train anything worth deploying, you need data that is collected consistently, cleaned reliably, labeled accurately, versioned properly, and structured in a way that maps to your actual AI tasks. None of that is automated. All of it requires deliberate engineering decisions. And almost none of it is reversible cheaply once you’ve made it wrong and built months of production on top of it.
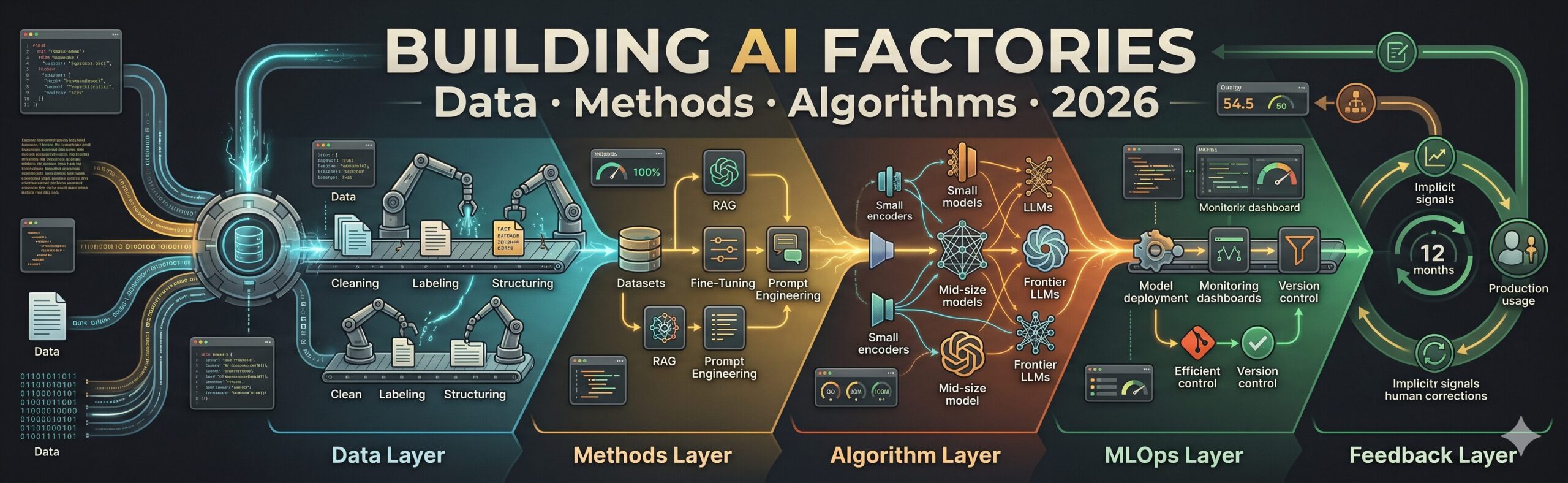
The five layers of a production AI Factory — and roughly how the work distributes across them — look like this:
Teams that skip the data layer and jump to methods or algorithms tend to hit a predictable wall around month three: the model works in demos, fails at edge cases, and there’s no systematic way to improve it because the underlying data infrastructure doesn’t support iteration. The fastest path to a working AI Factory is usually the slowest-looking one — building the data layer properly before touching a model.
The data layer is not preparation for the AI work. It is the AI work. Teams that treat data as a prerequisite to get through quickly consistently produce AI systems that plateau early and can’t be improved systematically. Teams that treat data as a core engineering discipline produce systems that compound over time.
The Data Layer: Finding and Valuing Your Proprietary Assets
The problem most people run into when inventorying their data isn’t that they have too little — it’s that they don’t know how to evaluate what they have against what AI tasks actually need. Not all data is equally valuable for AI development, and the framework for assessing it is different from the one used for business analytics.
Four properties determine how valuable a data asset is for AI Factory development, and they’re not the ones most data teams track by default.
Task relevance. Does this data directly represent the inputs or outputs of an AI task you want to build? A company with ten million customer support tickets has potentially valuable training data — if those tickets are already categorized, resolved, and have resolution outcomes attached. The same tickets without outcomes or resolution codes are significantly less valuable for most supervised learning tasks, even though the volume is identical.
Label quality. How consistent, accurate, and granular are the existing annotations or outcomes attached to the data? Data labeled by a single person with no guidelines is almost always inconsistently labeled. Data labeled by multiple people using a well-written schema, with disagreements adjudicated, is far more valuable regardless of volume. Quality beats quantity for training data more reliably than most teams expect.
Temporal coverage and freshness. Does the data span a sufficient period to represent the variation the AI system will encounter in production? A model trained only on data from the last six months may miss seasonal patterns, product lifecycle stages, or event-driven anomalies. Equally important: how stale is the most recent data, and how quickly does the underlying distribution shift in your business?
Proprietary depth. How specific is this data to your business, your customers, and your operational context? Data that only your company has — internal process records, proprietary transaction patterns, domain-specific annotations made by your own experts — is the only kind that creates a sustainable AI advantage. Any model behavior that can be reproduced by fine-tuning a public model on public data is not a moat.
Historical Transactions
High Value- Labeled with outcomes (approved / rejected / flagged)
- Years of history with seasonal coverage
- Specific to your business rules and thresholds
Support Tickets
High Value- Real user language and problem framing
- Resolution outcomes = implicit labels
- Product-specific taxonomy nobody else has
Internal Documents
Medium Value- Good for RAG knowledge bases
- Inconsistent structure and quality typical
- Rarely labeled for supervised tasks
Expert Annotations
Highest Value- Rare, expensive, non-reproducible
- Encodes domain expertise no public data contains
- Treat as gold standard — protect and version carefully
User Behavior Logs
Medium Value- Implicit feedback signal (clicks, completions, abandons)
- Noisy — requires careful interpretation
- Valuable for ranking and recommendation tasks
Scraped / Public Data
Low Moat- Useful for pre-training or domain adaptation
- Available to all competitors equally
- No proprietary advantage — everyone can use it
“The companies that will win with AI aren’t the ones who get access to the best models first. They’re the ones who spent the last three years quietly building the most complete, highest-quality internal dataset in their domain.”
— aitrendblend.com editorial observation, 2026
Building a Data Pipeline That Feeds the Factory
A data pipeline for an AI Factory is not the same as a data pipeline for analytics. Analytics pipelines optimize for query performance and reporting accuracy. AI data pipelines optimize for training data quality, label consistency, schema stability, and the ability to reproduce any historical training dataset exactly — a requirement that most analytics pipelines don’t need to satisfy.
Raw Sources (CRM, ERP, logs, docs, transactions)
↓
Ingestion + Normalization → Schema enforcement, deduplication, PII handling
↓
Labeling + Annotation → Human review, automated pre-labeling, quality checks
↓
Validation Gate → Completeness checks, distribution analysis, label consistency score
↓
Versioned Dataset Store → Immutable snapshots, lineage tracking, experiment registry
↓
Training Pipeline → Model training, evaluation, deployment
The validation gate is the step most teams skip under schedule pressure and most regret skipping. It is a systematic check — run automatically on every new batch of data — that catches problems like label class imbalance drifting beyond acceptable bounds, sudden drops in labeling completeness, schema changes that break downstream feature generation, and statistical distribution shifts in the input features that suggest data collection problems upstream. None of these problems are obvious without automated checks. All of them silently degrade model quality if they reach the training pipeline undetected.
Data versioning is the other discipline that separates operational AI teams from experimental ones. Every training dataset used to produce a model in production should be saved as an immutable snapshot with a version identifier. When a model in production starts behaving unexpectedly, the ability to answer “what data was this model trained on, exactly?” is the starting point for every useful debugging investigation. Without dataset versioning, that question has no answer, and root cause analysis devolves into guesswork.
Three non-negotiable engineering decisions in your AI data pipeline: automated validation gates on every data batch, immutable versioned dataset snapshots for every training run, and a lineage system that traces any production model back to the exact data that produced it. These feel like overhead until the first production incident — then they become invaluable.
Labeling at Scale: The Work Nobody Talks About Enough
Data labeling is the most labor-intensive, least glamorous, and most consequential activity in building an AI Factory. It is where your domain expertise gets encoded into a form the model can learn from. It is also where most data quality problems originate — not because people label carelessly, but because the labeling guidelines were written ambiguously, the edge cases weren’t defined, and no one measured inter-annotator agreement until months of inconsistent labels had accumulated.
The labeling problems that compound over time share a common root: the label schema was designed for the easy 80% of examples and ignored the hard 20%. Every real-world dataset has edge cases that don’t fit cleanly into the defined categories. If your labeling guidelines don’t explicitly address those cases — with specific examples of how to handle them — every annotator makes their own judgment, and those judgments don’t agree. The result is systematic inconsistency in exactly the data the model needs to learn the most from.
There are three practices that separate high-quality labeling operations from ones that produce noisy training data, and none of them are technically complex.
The Algorithm Layer: Selecting Models for Specific Internal Tasks
Think about what most teams do when they need a model for an internal AI task: they pick the largest, most recent frontier model available and point it at the problem. Sometimes this is right. Often it is expensive overkill that creates unnecessary vendor dependency, high inference costs, and latency problems that a smaller, purpose-fit model would not have caused.
The algorithm selection question is actually several distinct questions, and they deserve separate answers.
| Task Type | Appropriate Algorithm Class | When to Use a Frontier LLM | When NOT to |
|---|---|---|---|
| Classification (10–100 categories) | Fine-tuned small encoder (BERT-class, 110M–340M params) | When categories are ambiguous and require reasoning | Routing, intent detection, tagging — overkill and expensive |
| Named entity recognition | Fine-tuned NER model or small encoder | When entities are novel, ambiguous, or cross-lingual | Standard entity types in well-represented languages |
| Document Q&A from proprietary corpus | RAG with embedding model + frontier LLM for generation | Always — retrieval is required for proprietary doc access | N/A — this task requires retrieval by definition |
| Text generation with style/format rules | Fine-tuned mid-size model (7B–13B params) | When content requires broad world knowledge + style | When output format is strictly templated — fine-tune a smaller model |
| Semantic search / similarity | Domain-adapted embedding model | When the query requires complex reasoning before retrieval | Pure retrieval tasks — embeddings are faster and cheaper |
| Multi-step reasoning / analysis | Frontier LLM (Claude Opus 4.7, GPT-4o) | Complex judgment, synthesis across sources, novel situations | Volume tasks that a smaller fine-tuned model can handle well |
| Data extraction from structured docs | Fine-tuned extraction model or rule-based + LLM fallback | Unstructured documents where extraction rules can’t be written | PDFs with consistent structure — regex + a small model is 10× cheaper |
| Anomaly detection on tabular data | Gradient boosting, isolation forest, statistical baselines | When anomalies require natural language explanation | Pure anomaly detection in numerical data — traditional ML beats LLMs here |
The pattern in this table is consistent: use the smallest, most purpose-fit model that reliably solves the problem. Use frontier LLMs for tasks that genuinely require their reasoning breadth — complex synthesis, novel situations, open-ended analysis. Use fine-tuned smaller models for tasks with well-defined patterns. Use traditional ML for numerical tasks where neural networks offer no advantage. The cost and latency differences between these categories are not marginal — they can be 100× different at production scale.
High World Knowledge Required:
└─ Simple Format → Fine-tuned mid-size (7B–13B) | Complex Reasoning → Frontier LLM
Low World Knowledge Required:
└─ Simple Pattern → Fine-tuned encoder (BERT-class) | Complex Structure → Fine-tuned mid-size
Numerical / Tabular → Traditional ML (XGBoost, Random Forest, statistical models)
Retrieval-dependent → Embedding model + RAG regardless of task complexity
10 Prompts for Building Every Layer of Your AI Factory
These prompt templates are designed for use with Claude Opus 4.7 or GPT-4o. They cover all five factory layers — from data asset mapping through continuous learning pipeline design — and escalate from orientation-level planning prompts to a master-level competitive advantage blueprint.
Prompt 1: Proprietary Data Asset Mapping and Valuation (Beginner)
The first job in building an AI Factory is understanding what raw materials you actually have. Most organizations underestimate some data assets and overestimate others. This prompt produces a structured valuation that prioritizes your data assets by AI utility — not just volume or familiarity.
Why It Works: Separating the AI Readiness Score from the Proprietary Score forces a nuanced evaluation. Data can be high-readiness but low-proprietary (publicly available domain text) or high-proprietary but low-readiness (expert annotations that exist in someone’s head but haven’t been captured). The combination tells you where to invest — high proprietary, improvable readiness.
How to Adapt It: Add “include a data monetization analysis — which of our data assets could potentially be licensed to partners or industry consortia as a secondary revenue stream, and what governance would that require?” for organizations exploring data partnerships.
Prompt 2: AI Data Pipeline Architecture Design (Beginner)
Most teams start building data pipelines reactively — adding steps as problems emerge. This prompt designs the full pipeline architecture upfront, including the validation gates and versioning infrastructure that are always easier to build in than to retrofit.
Why It Works: Including “data splitting strategy at pipeline level” in the transformation layer forces the train/val/test split to happen in the pipeline — not ad hoc at training time. This ensures consistent, reproducible splits across every training run and prevents the subtle leakage that happens when splitting is done manually and inconsistently by different team members.
How to Adapt It: Add “include a streaming data component — design how real-time data (event streams, live transactions) integrates with the batch pipeline so the factory can train on fresh data without a full batch rebuild” for use cases where data freshness is critical.
Prompt 3: Labeling System Design at Scale (Beginner)
Getting labeling right from the start saves weeks of remediation later. This prompt designs a complete labeling operation — guidelines, quality controls, tooling, and the edge case documentation that most teams skip until it’s too late to retrofit.
Why It Works: “Labeler drift” — the phenomenon where a labeler gradually becomes inconsistent with their own past decisions over weeks of labeling — is almost never measured and frequently causes quality problems that look like model failure. The ongoing maintenance section makes this a tracked metric rather than an undetected source of noise.
How to Adapt It: Add “design a disagreement analysis protocol — when labelers disagree, how do we analyze the pattern of disagreements to identify ambiguities in the schema rather than treating all disagreements as random noise?”
Prompt 4: Algorithm Selection Framework for Your Use Case Portfolio (Intermediate)
Most AI Factory projects accumulate multiple AI use cases over time, each with different task profiles, data types, and performance requirements. This prompt generates a principled algorithm selection decision for each use case — preventing the default of reaching for the same large model for every task regardless of fit.
Why It Works: The “resist over-engineering” instruction at the end is doing important work. Every portfolio of AI use cases contains at least one problem that looks complex and is actually solved well by a much simpler approach. Having an AI architect name it explicitly prevents the team from spending weeks building an elaborate solution to a problem that a well-configured rule set with an LLM fallback would have handled in a day.
How to Adapt It: Add “include a build vs. buy vs. API analysis per use case — for each recommended algorithm, should we train our own model, use a pre-trained open-source model, or call a managed API?” to add a make-or-buy dimension to the decision.
Prompt 5: Model Benchmarking Protocol for Internal Tasks (Intermediate)
Choosing a model based on public leaderboards is one of the most common and most misleading selection methods in enterprise AI. Public benchmarks measure generic capabilities — not performance on your specific data, with your specific edge cases, under your specific constraints. This prompt designs an internal benchmarking protocol that measures what actually matters for your use case.
Why It Works: The prompt sensitivity control — testing multiple prompt variants per model — is the insight that most internal benchmarks miss and that explains why “Model A beat Model B” benchmarks often reverse when someone rewrites the prompt. A genuinely better model should outperform consistently across prompt variations, not only with one carefully tuned prompt.
How to Adapt It: Add “include a model card output — document the winning model’s capabilities, limitations, training data provenance, and evaluation results in a standardized format for your model registry” to make the selection decision defensible and auditable.
Prompt 6: AI Factory KPIs and Success Metrics Design (Intermediate)
An AI Factory without clear metrics is an AI Factory nobody can improve systematically. The problem most teams face is conflating model performance metrics (accuracy, F1, BLEU) with business impact metrics (cost saved, time reduced, error rate cut). Both matter, but they answer different questions, and the link between them is rarely automatic.
Why It Works: The “strategic moat indicator” metric in Tier 3 is almost never designed into AI monitoring frameworks and is consistently the most important one for long-term competitiveness. Tracking data asset quality improvement over time gives leadership a concrete indicator of whether the factory is building durable advantage — not just short-term efficiency gains.
How to Adapt It: Add “design a dashboard mockup — describe the three-panel view a non-technical executive would see that summarizes AI Factory health in under 60 seconds, with red/yellow/green status indicators” to translate the metrics into a communication tool for leadership.
Prompt 7: Data Quality Framework — Systematic Quality Assurance (Advanced)
Data quality problems in AI systems are different from data quality problems in analytics. In analytics, bad data produces wrong reports. In AI, bad data produces wrong model behavior — behavior that may persist for months across thousands of predictions before anyone notices the systematic pattern. This prompt designs a proactive data quality framework specific to AI training data.
Why It Works: The “source system reliability tracking” element in Accuracy is non-obvious but critically important. Training data quality problems often originate in upstream systems — a CRM that started storing a field differently, an ERP that changed a code mapping, a sensor that started reading high. Tracking the reliability of data sources upstream, not just validating data quality at the pipeline level, catches problems before they compound into training data issues.
How to Adapt It: Add “design a data quality incident playbook — for each major quality failure type, what is the immediate response, the impact assessment procedure, and the root cause analysis process?” to operationalize the quality framework into runbook documentation.
Prompt 8: Continuous Learning Pipeline — Keeping Models Current (Advanced)
A model deployed and forgotten is a model that degrades. The world changes, your data distribution shifts, user behavior evolves, and a model trained on last year’s patterns gradually becomes less accurate on this year’s reality. The continuous learning pipeline is the infrastructure that keeps your AI Factory’s outputs current without requiring a full rebuild every time something changes.
Why It Works: The cost-benefit retraining trigger in point 3 is almost always omitted from continuous learning designs. Retraining costs compute time and engineering review. At some drift levels, the cost of retraining exceeds the benefit of improved performance. Having an explicit cost-benefit evaluation prevents both over-retraining (burning compute on negligible improvements) and under-retraining (letting significant drift go unaddressed because no threshold was defined).
How to Adapt It: Add “design an A/B testing infrastructure for the continuous learning loop — how do we run the current model and the candidate retrained model side by side in production to measure whether the retrain actually improved outcomes before full deployment?”
Prompt 9: AI Factory Team Structure and Skill Design (Advanced)
Most articles about AI Factories focus on the technology and skip the organizational layer. The technology choices you make should follow from your team’s actual capabilities — and the team structure should evolve as the factory matures. This prompt designs both the initial team and the hiring roadmap tied to your factory build phases.
Why It Works: The sequencing question — which roles must exist before others become productive — is the insight that prevents the most common hiring mistake in AI Factory builds: hiring ML engineers before having a data engineer, then watching them spend 60% of their time doing data work because the infrastructure isn’t there to support modeling. The data engineer comes first. Every time.
How to Adapt It: Add “design an AI literacy program for non-AI team members — what does a product manager, operations lead, or finance controller need to understand about AI to be an effective collaborator with the AI Factory team, and how do we build that literacy efficiently?”
Prompt 10: Master — AI Factory Competitive Advantage Blueprint
This is the capstone prompt — the one that connects your data assets, method choices, algorithm decisions, team structure, and feedback loops into a single coherent strategy for building an AI capability that compounds over time and creates genuine competitive differentiation. It is designed for the moment when a leadership team needs to make a multi-year commitment to an AI Factory build and needs a clear picture of what they’re committing to and why it will be hard for competitors to replicate.
Why It Works: The flywheel design section — mapping every feedback loop with its cycle time — is where the difference between an “AI project portfolio” and an “AI Factory” becomes concrete and measurable. A project portfolio is a collection of deployments. A factory is a system where each deployment makes the next one faster, cheaper, and better. That distinction can only be designed in; it doesn’t emerge accidentally.
How to Adapt It: For board or investor presentations, add “Section 7 — Capital Allocation Model: for each year of the roadmap, break the investment across data infrastructure, model development, MLOps tooling, and team, with the expected output and ROI indicator for each allocation” to produce an investment thesis alongside the technical blueprint.
Where AI Factory Builds Break Down — and Why
The failure patterns in AI Factory projects are remarkably consistent. They rarely fail because of a bad model choice or the wrong cloud provider. They fail because of organizational and architectural decisions made in the first three months that become harder and harder to reverse as the factory grows on top of them.
| Failure Pattern | How It Manifests | The Structural Fix |
|---|---|---|
| Skipping the data layer | Models trained on uncleaned, unlabeled, or inconsistently structured data hit quality ceilings that require expensive data reconstruction — not model improvements — to break through | Mandate a data readiness assessment before any model training begins. No training run starts until the validation gate is green. |
| No versioning discipline | A production model starts behaving unexpectedly. Nobody can identify which training data produced it. Root cause analysis is impossible. Rollback is guesswork. | Dataset versioning and model lineage tracking are non-negotiable from the first training run. If it’s not versioned, it’s not production-ready. |
| Hiring ML engineers before data engineers | ML engineers spend 60% of their time doing data work because there’s no infrastructure to support modeling. Expensive talent is under-utilized. Projects stall. | The data engineer is the first AI Factory hire, not the second. Every subsequent role produces more value when the data infrastructure is already in place. |
| Frontier model defaults for everything | Monthly inference cost becomes unsustainable as volume scales. Team tries to reduce quality to save costs. Customers notice. Confidence in the factory drops. | Match model size to task complexity. Run the algorithm selection matrix for every new use case. Reserve frontier models for tasks that genuinely need them. |
| No feedback loop into training | Models degrade as the world changes. The factory’s output quality falls without anyone systematically improving it. What launched as an advantage becomes a liability. | Design the feedback loop before launch. Production usage should generate training data improvements automatically. If it doesn’t, the factory isn’t self-improving. |
What the Factory Model Still Can’t Automate
None of this comes free. The AI Factory architecture significantly reduces the cost and time required to build and improve AI capabilities — but it does not eliminate the judgment requirements that determine whether those capabilities produce business value.
The decision about which AI problems are worth solving in the first place remains entirely human. A well-functioning AI Factory can build almost anything its team is pointed at. The question of what it should be pointed at — which customer problems to solve, which operational inefficiencies to tackle, which competitive threats to respond to — requires business judgment that the factory itself cannot supply. Organizations that conflate “we can build this” with “we should build this” accumulate AI capabilities that nobody uses, because the factory was optimized for building rather than for solving problems that matter.
Data labeling for genuinely novel domains still requires domain expertise that is scarce and expensive. When a company moves into a new market, launches a new product category, or faces a new type of operational challenge, the labeled data needed to train AI systems for that context doesn’t exist yet. Building it requires finding people who understand the domain deeply enough to label accurately — and that expertise is the actual bottleneck, not the model or the infrastructure. The factory accelerates everything after the first 500 quality labels exist. Getting to 500 quality labels in a new domain is still slow, because there’s no shortcut around domain expertise.
Explainability for high-stakes decisions remains limited across both deep learning and large language model approaches. A factory that produces AI systems making consequential decisions — credit approvals, medical triage, legal risk assessment — faces an explainability ceiling that architecture cannot fully bridge. Interpretable models sacrifice performance. Black-box models sacrifice defensibility. In 2026, that tension is managed rather than resolved, typically through careful task scoping (using AI for lower-stakes sub-decisions within a larger human-supervised workflow) and robust audit trail design.
The Factory Is a Commitment, Not a Project
Every framework in this article — the data pipeline architecture, the labeling system design, the algorithm selection matrix, the feedback loops — is pointing at the same underlying truth: building an AI Factory is an organizational commitment to a way of operating, not a project with a completion date. Projects end. Factories run. The distinction matters because it changes what success looks like: not “we shipped the model” but “the model is better this month than last month, and we can measure why.”
The data strategy is where that commitment becomes most visible, and most difficult to fake. Anyone can run a fine-tuning job or configure a RAG pipeline. Only your organization has your operational history, your expert annotations, your customer interaction patterns accumulated over years of doing business in your specific way. That data is the asset that justifies the factory investment — because it is the part of the factory’s output that your competitors can observe (the capabilities it produces) but cannot replicate (the specific data and feedback loops that produced them).
The human judgment requirement in this architecture is real and shouldn’t be minimized. Deciding what data is worth collecting, what quality standards are worth enforcing, what tasks are worth automating, and what thresholds require human oversight — these are all decisions the factory cannot make for itself. The factory executes on them. People make them. The organizations that build the most capable AI Factories are the ones that understand this boundary clearly and invest on both sides of it: in the engineering infrastructure and in the human judgment that directs it.
Six months from now, the organizations that started building their data layers seriously today will have something nobody can buy off a shelf. Every company has access to the same models. The ones who built the infrastructure to train those models on their own operational history, improve them continuously from production feedback, and apply them systematically to their most valuable business problems — those organizations will have an AI Factory that compounds. The ones who didn’t will have a subscription to a very good AI product. That distinction will matter more with every passing quarter.
Start Building Your AI Factory Today
Use Prompt 10 above with Claude Opus 4.7 to generate your full competitive advantage blueprint — then read our RAG vs. Fine-Tuning guide to lock in the right methods for your first factory use cases.
Disclaimer: aitrendblend.com publishes independent editorial content. Not affiliated with Anthropic, OpenAI, AWS, Google, Microsoft, or any other company referenced. No sponsored recommendations.