RAG vs. Fine-Tuning: A Complete Decision Guide for 2026
Both mistakes are expensive and both are avoidable. The gap between them is not a question of technical skill — the engineers involved were competent. It’s a question of applying the right method to the right problem, and most of the guidance available on this topic either oversimplifies the tradeoffs or buries the decision criteria in jargon that obscures the actual logic.
This is not that kind of article. What follows is a practical, honest decision guide: what RAG and fine-tuning actually do differently (not just how they work mechanically), an eight-question framework for making the choice, an honest comparison across every dimension that matters in production, and ten prompt templates to help you implement whichever approach — or combination — is right for your situation. No oversimplification, no hedging, no “it depends” without specifics.
By the end of this, you’ll know exactly which method your project needs and why — and you’ll know the precise conditions under which your answer would change.
The Fundamental Difference Nobody Explains Clearly Enough
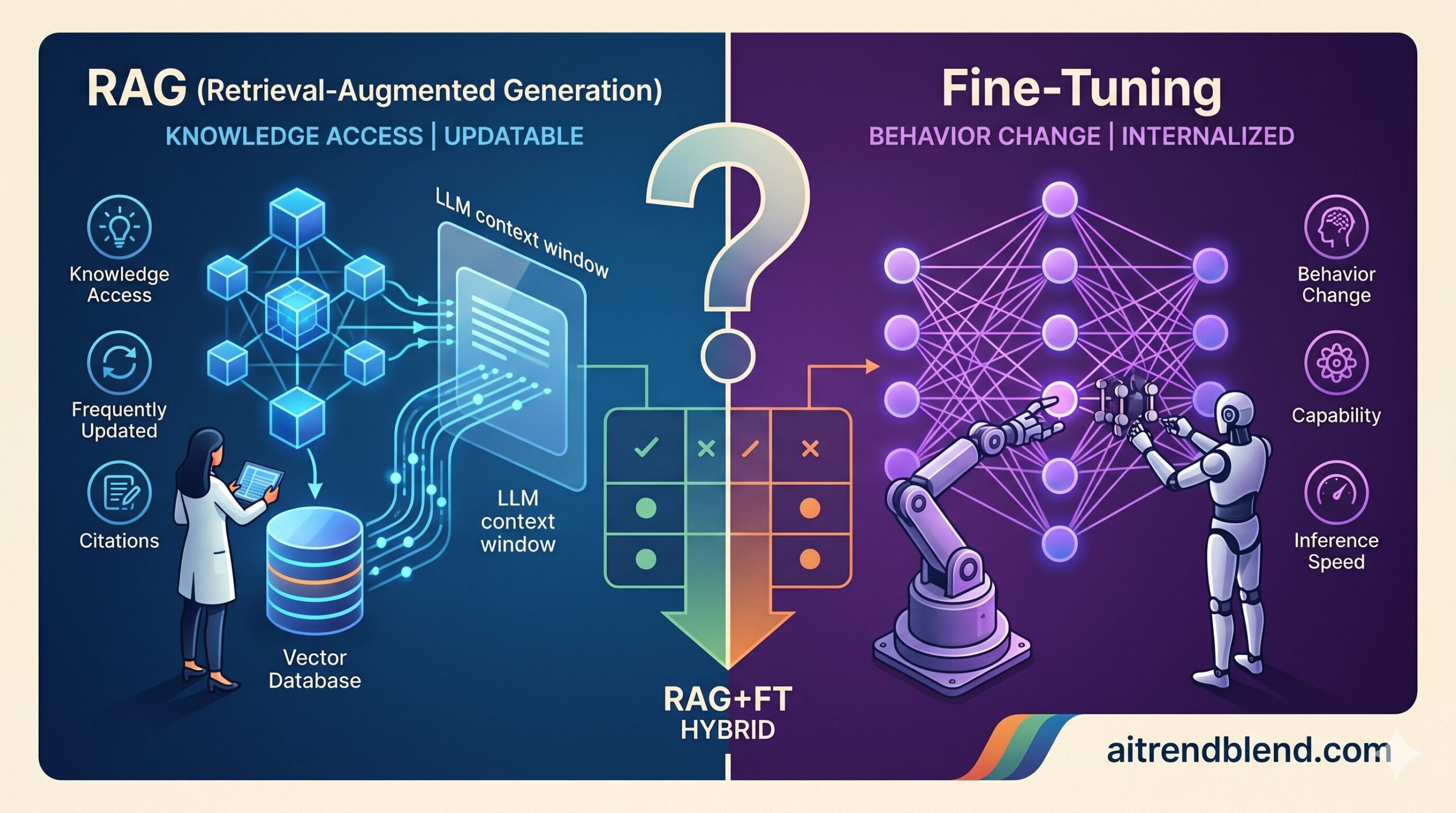
RAG and fine-tuning are solving different problems. That’s the sentence that unlocks the decision, and it’s the one that gets glossed over in most comparisons.
RAG is a knowledge access problem solution. It answers: “how do we give an LLM access to information it doesn’t have in its weights?” The model itself is unchanged. At inference time, a retrieval system finds relevant documents, injects them into the context, and the model reads them just as it would read any text. The model’s reasoning capabilities — its style, its instruction-following, its domain reasoning patterns — stay exactly as they were. What changes is the information it can work with right now.
Fine-tuning is a behavior and capability problem solution. It answers: “how do we change how a model reasons, responds, or specializes?” The training data updates the model’s weights — literally changing what the model knows and how it behaves. A fine-tuned model doesn’t read your domain knowledge at inference time; it has internalized patterns from your domain into its parameters. It reasons differently, not just with more information.
That distinction sounds clean on paper and gets messy in practice, because real problems often have both a knowledge access component and a behavior component. Most of the confusion about when to use each method comes from not being explicit about which problem you’re actually trying to solve.
RAG — Retrieval-Augmented Generation
- Retrieves relevant chunks from external document store at query time
- Injects retrieved content into the LLM context window
- Model reads and reasons over retrieved text
- Knowledge lives outside the model (vector database)
- Update knowledge by updating documents — no retraining
- Can cite sources; transparent about what it retrieved
- Retrieval quality directly determines output quality
Fine-Tuning — Weight Adaptation
- Trains model on labeled examples, updating its weights
- Knowledge and behavior patterns are baked into parameters
- Model responds from internalized patterns — no lookup
- Knowledge lives inside the model (parameters)
- Update behavior by retraining — requires labeled data
- Faster inference — no retrieval overhead
- Training data quality directly determines model quality
If your core problem is “the model doesn’t know X” and X is a body of documents — use RAG. If your core problem is “the model doesn’t behave like an expert in X” or “the model doesn’t output in our required format/style” — fine-tune. When you have both problems, you need both methods.
How RAG Works — and Where It Quietly Fails
The mechanism is worth understanding precisely because the failure modes flow directly from it. In a RAG pipeline, your documents are split into chunks, each chunk is converted into a vector embedding (a numerical representation of its meaning), and those vectors are stored in a vector database. When a query arrives, the query is also embedded, the vector database finds the most semantically similar chunks, those chunks are inserted into the LLM’s context alongside the user’s question, and the model generates an answer based on what it retrieved.
Documents → Chunking → Embedding → Vector Store
↓
Query → Query Embedding → Similarity Search → Top-K Chunks
↓
[System Prompt + Retrieved Chunks + Query] → LLM → Answer
The elegance of this approach is that your knowledge base is entirely separate from your model. Update a product manual, add a new policy document, remove an outdated regulation — the model automatically has access to the current version next time it retrieves. There is no retraining, no downtime, no labeled data required. For knowledge that changes frequently, this is not just convenient — it’s the only viable approach.
The failure modes are less obvious. Chunking quality is where most RAG projects quietly die. If you split documents at the wrong boundaries — too small and you lose context, too large and you dilute relevance — the retrieved chunks won’t contain the information needed to answer the question, even when that information exists somewhere in your document store. A support manual chunked by paragraph might split a problem description from its solution across two different chunks, retrieving one without the other.
Retrieval precision is the second hidden failure point. Dense vector retrieval is excellent at semantic similarity but sometimes terrible at exact match — if a user asks about a specific product code or a precise regulation number, semantic similarity search may return loosely related documents instead of the exact right one. Hybrid retrieval (combining dense vector search with sparse keyword search like BM25) addresses this, but adds architectural complexity most initial RAG implementations skip.
“A RAG system is only as good as its worst retrieval. The most capable LLM in the world cannot give you a correct answer if the chunk it received didn’t contain the relevant information.”
— aitrendblend.com editorial observation, 2026
How Fine-Tuning Works — and What It Actually Changes
Fine-tuning takes a pre-trained model and continues training it on your dataset, using gradient descent to adjust the model’s weights toward the patterns in your examples. The result is a model that has internalized those patterns — not by remembering individual examples, but by shifting its general behavior toward the style, format, and reasoning patterns your training data demonstrated.
Foundation Model + Labeled Training Examples
↓
Training Loop (forward pass → loss → backpropagation → weight update)
↓
Fine-Tuned Model (updated weights)
↓
Query → Fine-Tuned Model → Specialized Answer (no retrieval step)
What fine-tuning changes — and what it doesn’t — matters enormously for the decision. Fine-tuning does change: how a model formats its outputs, what tone and style it uses, how it reasons about domain-specific problems, what vocabulary and terminology it naturally reaches for, and how reliably it follows your specific instructions. These are behavioral shifts that persist at inference time without any prompting overhead.
Fine-tuning does not reliably add factual knowledge about specific documents, events, or entities. This is the misconception that leads teams to fine-tune when they should be using RAG. Training a model on your internal documents does not give it reliable recall of specific facts from those documents the way RAG does. What it gives the model is familiarity with your domain’s patterns, vocabulary, and reasoning style. The difference between “knowing a fact” and “having internalized a reasoning pattern” is the line between RAG and fine-tuning.
The data requirements are also non-trivial. Effective fine-tuning generally requires at least 500 high-quality labeled examples for a narrow task, and closer to 1,000–5,000 for broader behavioral shifts. Collecting and labeling that data is the primary cost and time driver, dwarfing the compute cost of the training run itself. For organizations without existing labeled data, this is often the single biggest practical barrier.
The Decision Framework: 8 Questions That Determine Your Method
This is not a small distinction — how you answer these eight questions determines not just which method you use, but how you configure it and what success looks like. Work through them in order; later questions only matter if the earlier ones don’t already decide the issue.
-
Q1Does the model need access to specific documents, records, or frequently updated information? If yes — your primary problem is knowledge access. The model needs to read specific content at inference time. RAG is the right starting point.→ RAG
-
Q2Does the output format, style, or domain reasoning need to be fundamentally different from the base model’s behavior? If yes — your problem is behavioral. No amount of prompt engineering fully solves deep format or reasoning consistency at scale. Fine-tuning is the right tool.→ Fine-tune
-
Q3How frequently does the underlying knowledge change? If knowledge changes weekly or monthly (product catalog, regulations, prices, news), RAG wins — you can update the document store without retraining. If knowledge is stable (medical coding taxonomy, legal jurisdiction rules, engineering specs that rarely change), fine-tuning pays off.→ Frequency-dependent
-
Q4How much labeled training data do you have — or can realistically collect? Under 200 quality examples: fine-tuning likely won’t produce reliable improvements. 200–1,000: fine-tuning a small model for a narrow task may work. Over 1,000: fine-tuning for broader behavioral shifts becomes viable.→ Data-dependent
-
Q5Do users need to see citations or source references in the output? If yes — RAG. Fine-tuned models cannot reliably cite their sources because their knowledge is implicit in weights. RAG knows exactly which documents were retrieved and can surface them.→ RAG
-
Q6What is your inference volume, and does latency matter? High volume (thousands of queries/day) with strict latency requirements: fine-tuning produces a model that responds without retrieval overhead, faster per call and cheaper at scale. Low to medium volume where a 1–3 second retrieval step is acceptable: RAG is fine.→ Volume-dependent
-
Q7Does your team have ML engineering experience with model training? Fine-tuning requires managing training runs, hyperparameter choices, evaluation loops, and model deployment infrastructure. RAG requires data engineering and retrieval system design — different skills, but generally lower barrier. Honest team skill assessment is essential here.→ Skill-dependent
-
Q8Do you need both — domain behavior AND access to frequently updated documents? If yes — the answer is a hybrid: fine-tune the model to reason like a domain expert, then augment it with RAG to give it access to current documents. This is the architecture that production teams consistently find outperforms either method alone for complex domain applications.→ Both (Hybrid)
The Full Comparison: Every Dimension That Matters in Production
Think about what you’re actually optimizing for across the lifecycle of an AI system — not just the initial build, but the ongoing cost of maintaining, updating, and improving it. The right method for month one is not always the right method for month twelve.
| Dimension | RAG | Fine-Tuning | Hybrid (Both) |
|---|---|---|---|
| Time to first working version | Days to weeks | Weeks to months (data collection is the bottleneck) | Weeks to months |
| Upfront data requirement | Documents only — no labeling needed | 500–5,000+ labeled examples | Documents + labeled examples |
| Knowledge update cost | Low — update document store, no retraining | High — requires new labeled data + retraining | Medium — update docs easily, retrain for behavior changes |
| Inference latency | Slower — retrieval step adds 0.5–3s typically | Faster — no retrieval overhead | Medium — retrieval overhead remains |
| Inference cost at scale | Higher — longer context (retrieved chunks) = more tokens | Lower per query — shorter context, no retrieval | Moderate — fine-tuned model + RAG context |
| Factual accuracy on specific docs | High — model reads actual source text | Lower — model may confabulate specific facts | Highest — domain reasoning + source access |
| Output format / style consistency | Moderate — relies on system prompt | High — baked into model behavior | High — fine-tuning handles this layer |
| Domain reasoning depth | Limited by base model capability | Higher — internalized domain patterns | Highest — domain reasoning + current knowledge |
| Source citation support | Native — can surface retrieved document sources | Not native — model cannot cite weight-based knowledge | Supported via RAG layer |
| Handling queries outside knowledge base | Falls back to base model knowledge (may hallucinate) | Can use general reasoning for gaps | Best coverage — both paths available |
| Infrastructure complexity | Medium — vector DB, embedding pipeline, retrieval logic | Medium — training pipeline, model hosting, versioning | High — both stacks required |
| Failure mode severity | Retrieval misses → wrong or incomplete answers | Training data bias → systematically wrong behavior | Both failure modes possible — more to monitor |
RAG wins on flexibility, update speed, and citation support. Fine-tuning wins on inference performance, behavioral consistency, and domain reasoning depth. The hybrid wins on output quality — but at significantly higher infrastructure and maintenance cost. Match your choice to your constraints, not just your desired outcome.
10 Prompts for Building RAG Pipelines and Fine-Tuned Models
These prompt templates are designed for use with Claude Opus 4.7 or GPT-4o to help you plan, architect, implement, and evaluate both methods. They escalate from basic pipeline design through advanced production optimization and master-level hybrid system architecture.
Prompt 1: RAG Pipeline Quick-Start Specification (Beginner)
The difference between a mediocre RAG pipeline and a good one is usually decided in the first week of design — before a single line of code is written. This prompt generates the full technical specification your engineering team needs to build a production-ready RAG system from scratch.
Why It Works: Asking for specific chunk size values — not just “use appropriate chunking” — forces the output into actionable engineering parameters rather than vague recommendations. A spec that says “256 tokens with 32-token overlap for procedural documents, 512 tokens with 64-token overlap for narrative documents” gives an engineer something to implement. One that says “chunk appropriately” gives them nothing.
How to Adapt It: Add “my documents contain significant tables and structured data — include specific handling strategies for tabular content” to get chunking and retrieval designs appropriate for data-heavy documents, where standard text chunking fails badly.
Prompt 2: Chunking Strategy Design — The Decision Most Teams Get Wrong (Beginner)
Chunking is where most RAG projects quietly fail, and it’s the decision that gets the least attention in most tutorials. The right chunking strategy depends on document structure, query patterns, and what information tends to be adjacent to what. This prompt forces a rigorous chunking design before any ingestion pipeline is built.
Why It Works: The “test my strategy with 3 example queries” instruction at the end forces the AI to walk through the retrieval logic concretely — which reveals whether the chunk sizes and boundaries actually serve the query patterns, or just seem reasonable in the abstract.
How to Adapt It: Add “design a chunk quality validation script — a set of tests I can run against my chunked document store to catch common quality issues before they affect production retrieval” to build quality assurance into the ingestion pipeline.
Prompt 3: Fine-Tuning Dataset Preparation Guide (Beginner)
The training dataset is the single biggest determinant of fine-tuning quality. Most teams underinvest in data quality — rushing to accumulate volume while overlooking diversity, edge cases, and label consistency. This prompt generates a rigorous dataset preparation plan before any labeling work begins.
Why It Works: Asking for concrete example training instances at the end — not just a process description — forces the prompt to produce something immediately usable as a labeling reference for annotators. Teams that start labeling without a concrete example of “this is what a perfect training example looks like” produce inconsistent datasets that train inconsistent models.
How to Adapt It: Add “include an inter-annotator agreement calculation protocol — how will I measure consistency between labelers and what threshold means my dataset is reliable enough to train on?” for tasks with subjective labels.
Prompt 4: RAG vs. Fine-Tuning Decision Audit for Your Specific Project (Intermediate)
The eight-question framework in the section above works best when applied to a specific project. This prompt takes your actual use case through a structured decision audit and produces a justified recommendation with the exact conditions under which that recommendation would change — eliminating the second-guessing that stalls projects for weeks.
Why It Works: The “quick-start in 2 weeks” instruction at the end is the most practically valuable part of this prompt. The fastest path to resolving a RAG-vs-fine-tuning debate is not more analysis — it’s a small, fast experiment that produces real evidence. Framing the output in terms of a two-week proof-of-concept forces the recommendation to be immediately actionable.
How to Adapt It: Add “estimate the total cost (compute + labor) for each approach over 12 months at my usage volume” to incorporate economics into the decision rather than treating it as a purely technical question.
Prompt 5: Hybrid Architecture — Combining RAG and Fine-Tuning (Intermediate)
The hybrid approach is often the right answer for production systems — but “use both” is not an architecture. How you connect them, which layer handles which problem, and how they interact at inference time all require explicit design choices. This prompt generates that design.
Why It Works: The instruction to specify what should NOT be in fine-tuning data is almost universally skipped in hybrid architecture designs. If you train your model on factual details that should be retrieved via RAG, the model begins to confabulate those facts confidently — making its hallucinations harder to detect because they look like authoritative domain knowledge.
How to Adapt It: Add “design the A/B testing framework — how do I compare the hybrid system against each method in isolation to validate that the combination is actually better and by how much?” to quantify the value of the added complexity.
Prompt 6: Embedding Model Selection for Your RAG System (Intermediate)
The embedding model choice is the most consequential technical decision in a RAG pipeline that most teams make too quickly, defaulting to whatever is most popular rather than what fits their specific content and query patterns. This prompt generates an evidence-based selection for your use case.
Why It Works: Asking for the failure scenario per option counteracts the tendency of AI models to produce uniformly positive evaluations with generic warnings. “This model fails when queries are very short and highly technical” is actionable guidance. “May underperform in edge cases” is not.
How to Adapt It: Add “include a benchmark test design — describe 20 representative query-document pairs I should use to evaluate embedding quality on my actual content before committing to a model” to move from theoretical comparison to empirical validation.
Prompt 7: RAG Evaluation Framework — Measuring Quality Rigorously (Advanced)
Most tutorials skip this part entirely: how do you systematically measure whether your RAG pipeline is actually working well, and which component is responsible when it isn’t? Without a rigorous evaluation framework, RAG quality is measured by feel rather than evidence — and improvements are impossible to validate objectively.
Why It Works: Separating retrieval evaluation from generation evaluation is the insight that makes RAG debugging tractable. When a RAG answer is wrong, the cause is almost always one of three things: the right content wasn’t retrieved (retrieval problem), the right content was retrieved but the model ignored it (generation problem), or the right content doesn’t exist in the document store (knowledge gap). You need separate metrics to distinguish these — otherwise every “fix” is a guess.
How to Adapt It: Add “design a failure categorization scheme — a taxonomy of RAG failure modes with the diagnostic test for each, so engineers can systematically identify root causes rather than trial-and-error debugging” to operationalize the evaluation framework into a debugging toolkit.
Prompt 8: Fine-Tuning Hyperparameter and Training Strategy (Advanced)
The training run is where most fine-tuning projects encounter their first serious obstacle — not because the approach is wrong, but because hyperparameter choices were made without a principled strategy. This prompt generates a training plan with justified hyperparameter recommendations for your specific situation.
Why It Works: The “3 most likely failure modes for my specific setup” request at the end is more valuable than generic hyperparameter advice. A 7B parameter model trained with LoRA on 800 classification examples has different failure patterns than a 70B model trained on 10,000 generation examples. Domain-specific failure mode identification is what prevents expensive retraining cycles.
How to Adapt It: Add “design a catastrophic forgetting mitigation strategy — techniques to preserve the base model’s general capabilities while fine-tuning for my specific task” for cases where the fine-tuned model needs to handle both specialized and general queries.
Prompt 9: Production RAG Optimization — Speed, Cost, and Quality at Scale (Advanced)
A RAG pipeline that works well in development often hits performance and cost surprises when query volume scales up. The optimizations that matter in production are different from the ones that matter in a prototype. This prompt designs a production optimization strategy before problems emerge.
Why It Works: Asking for a calculation of expected monthly cost at target query volume — not just optimization techniques in the abstract — forces the output to be grounded in your actual economics. Optimization choices that look equivalent technically often have 5x cost differences at production scale, and those differences should drive the prioritization.
How to Adapt It: Add “design a query routing strategy — for some queries, the answer may not require full RAG. How do I route simple queries to cheaper methods (direct LLM, cache, keyword lookup) and only use full RAG for queries that need it?” to add an intelligent query dispatch layer.
Prompt 10: Master — Complete RAG + Fine-Tuning System Blueprint
This is the full-stack system design prompt — used when you need a complete, architecturally coherent plan for a production system that combines the right adaptation methods with the right infrastructure, evaluation, and maintenance strategy. It integrates every layer of the decision into one comprehensive document for team alignment and engineering handoff.
Why It Works: The instruction to “flag the two assumptions that, if wrong, would change your recommendation” in Section 1 is the most intellectually honest move in this entire prompt series. No recommendation generated from a description of your situation is unconditionally correct. Surfacing the assumptions that underlie it lets you verify them — and gives you the exact conditions to rerun the decision if your situation changes six months from now.
How to Adapt It: For teams presenting to senior leadership, add “Section 8 — Executive Summary: a one-page non-technical version covering the problem, approach, investment required, expected outcome, and go-live timeline in plain language” to make the blueprint usable as a leadership alignment document.
Mistakes That Lead Teams to the Wrong Method — and Keep Them Stuck There
The wrong method choice is not always obvious on day one. These are the patterns that lead teams down the wrong path and, more importantly, the signs that indicate you’ve chosen incorrectly before you’re too deep to change course.
| Mistake | What Goes Wrong | The Correction |
|---|---|---|
| Fine-tuning for knowledge, not behavior | Training model on internal documents hoping it will recall specific facts reliably. It won’t — it will confabulate confidently instead. | Use RAG for factual recall from specific documents. Use fine-tuning only to change how the model reasons or formats output. |
| RAG for tasks that need consistent style | Building a RAG system for a task that requires highly consistent output format, only to find the model’s style varies wildly across queries regardless of what’s retrieved. | Fine-tune for style and format consistency. RAG cannot reliably constrain output style at inference time. |
| Skipping chunking strategy for RAG | Using default text-splitting without thinking about document structure or query patterns. Getting mediocre retrieval and blaming the embedding model. | Design chunking strategy explicitly for your document types and query patterns before building anything. Chunking is the highest-impact RAG decision. |
| Fine-tuning on too little data | Training on 50–200 examples and getting a model that overfits perfectly on training examples and generalizes poorly on anything slightly different. | Don’t start fine-tuning until you have 500+ high-quality examples for a narrow task. Use prompt engineering with few-shot examples for smaller datasets. |
| No evaluation framework before deployment | Deploying RAG or a fine-tuned model and evaluating quality by “how does it feel?” — making it impossible to measure improvements or detect regressions. | Build a golden evaluation dataset before your first deployment. Run it on every version. Track the numbers, not the feeling. |
The first mistake — fine-tuning for knowledge rather than behavior — is worth spending an extra moment on because it’s the most common and the most expensive. The intuition behind it is understandable: “if I train the model on all our internal documents, it will know our stuff.” What actually happens is that the model learns the statistical patterns, terminology, and style of your documents — which is genuinely valuable for domain adaptation — but it does not reliably memorize specific facts, numbers, names, or policies. Ask a model fine-tuned on your HR documents “what is our parental leave policy?” and it may give you a confident, plausible-sounding answer that is wrong about the specific weeks or eligibility criteria. RAG would have retrieved the actual policy text and read it. Fine-tuning just made the model sound more like your company when it fabricates.
What Neither Method Handles Well Yet in 2026
Both approaches have genuine limitations in the current state of the technology — limitations that matter for production system design and are worth naming directly rather than discovering in production.
RAG struggles with multi-hop reasoning over distributed information. If answering a question requires synthesizing information across five different documents — none of which individually contains the answer — standard RAG retrieval typically returns the most semantically similar chunks to the query surface, not the chain of evidence needed to answer it. The model receives fragments, not the thread connecting them. Graph RAG (a newer approach that builds knowledge graphs from documents and traverses relationships during retrieval) addresses this partially, but adds significant indexing complexity and is not yet widely supported in production tooling. For now, multi-hop questions over large document collections remain an area where RAG frequently underperforms human research.
Fine-tuning still struggles with catastrophic forgetting. When you fine-tune a model heavily on a narrow domain, it tends to lose some of its general reasoning capabilities — a phenomenon called catastrophic forgetting. A model fine-tuned intensely on medical coding may degrade at general language tasks, or start applying medical reasoning patterns to questions where they don’t belong. LoRA and PEFT techniques mitigate this significantly, but they don’t eliminate it entirely. For applications where the fine-tuned model also needs to handle general queries alongside specialized ones, the tension between specialization and generality requires careful balance in training data composition.
Both methods share a deeper limitation: neither is a substitute for good knowledge architecture. A RAG system built on poorly organized, inconsistently written, or incompletely maintained documents will produce outputs that reflect those problems regardless of how good the retrieval is. A fine-tuned model trained on inconsistent or biased examples will reproduce those inconsistencies at scale. The quality of the underlying knowledge — whether it lives in a document store or in training data — sets the ceiling on what either method can produce.
The Decision Is Simpler Than the Tooling Makes It Look
Strip away the infrastructure complexity and the jargon, and the decision usually comes down to one question answered honestly: are you trying to change what information the model can access, or are you trying to change how the model behaves? The first answer points to RAG. The second points to fine-tuning. Both answers point to a hybrid — which is the right architecture for demanding production systems, even though it carries the highest implementation cost.
The deeper principle running through both methods is that the quality of your inputs determines the ceiling of your outputs. RAG is only as good as your document store — its completeness, its organization, and how frequently it’s kept current. Fine-tuning is only as good as your training data — its accuracy, its diversity, and how carefully the labeling guidelines were defined. Neither method is a shortcut around the work of having good underlying material. The AI amplifies what you give it, and if what you give it is poorly organized or inconsistently structured, the amplification works on that too.
There is still real judgment involved in this decision that no framework fully captures. The same use case at two companies with different data maturity, different team skills, and different update frequencies might correctly land on different methods. Working through the eight questions honestly against your actual situation — not the idealized version of your situation — is what produces a good decision. The teams that end up rebuilding from scratch six months in are almost always the ones who made the method decision based on what they wanted to be true rather than what was actually true about their data and constraints.
The tooling around both methods is maturing fast. Managed fine-tuning APIs are reducing the engineering overhead of training runs. Vector database options are proliferating and becoming more capable. The RAG-to-hybrid pipeline is becoming more accessible to teams without deep ML expertise. What won’t commoditize is the judgment about which problem you’re actually solving — because that requires understanding your specific business, your data, and what quality actually means in your context. Own that judgment, and the tooling will serve you well.
Start Building — RAG or Fine-Tuning
Use Prompt 4 above with Claude Opus 4.7 to run a decision audit on your specific project. Then explore our AI Factory guide for the infrastructure layer that supports both methods in production.
Disclaimer: aitrendblend.com publishes independent editorial content. Not affiliated with Anthropic, OpenAI, Pinecone, Weaviate, Chroma, or any other AI infrastructure company referenced in this article. No sponsored recommendations.