Building “AI Factories”: How Companies Are Combining Data, Methods, and Algorithms to Build Internal AI Systems Fast
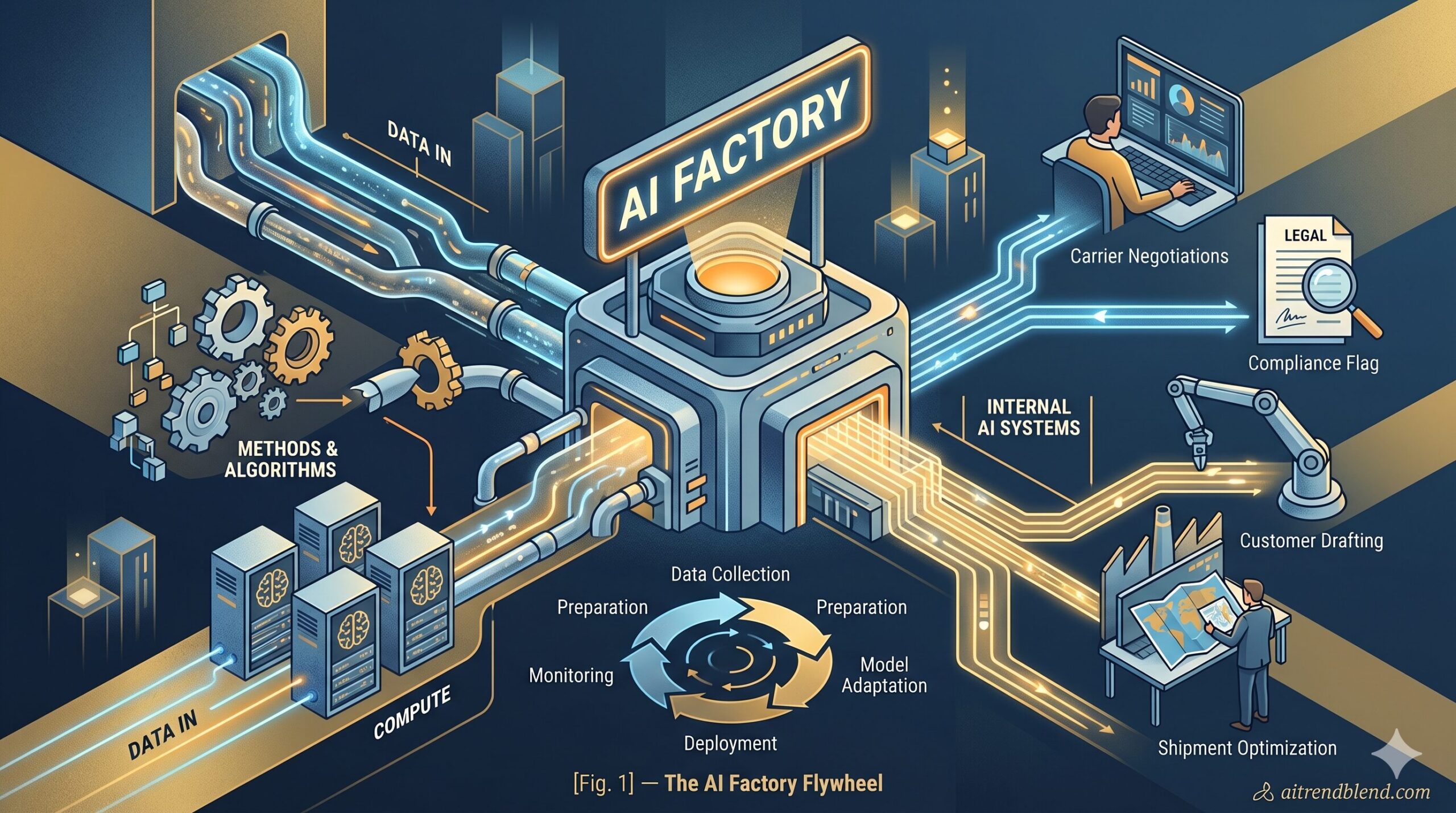
The second company built what people in the industry are starting to call an AI Factory: a repeatable internal system for combining proprietary data, proven methods, and the right algorithms to produce AI capabilities that compound over time. Not a single chatbot. Not a one-off model. A production pipeline that gets better with use, improves as more data flows through it, and creates a competitive moat that’s genuinely hard to replicate.
The term sounds ambitious — and for a long time it was, reserved for companies with hundred-person ML teams and unlimited GPU clusters. That’s changed. The rise of foundation models, open-source tooling, managed fine-tuning APIs, and vector databases has dropped the barrier dramatically. A team of three engineers can now build something in six months that would have required two years and twenty people in 2022. That’s the actual news here.
What you’ll understand by the end of this piece: what an AI Factory actually consists of, how to choose between the three main methods for building internal AI (prompting, RAG, and fine-tuning), what the real obstacles are — not the theoretical ones — and ten practical prompt templates to help you architect, plan, and build your own.
The Term Sounds Like a Buzzword. Here’s What It Actually Means.
Jensen Huang, CEO of NVIDIA, popularized the phrase “AI Factory” in 2024 to describe data centers that take in raw information and produce intelligence as output — the way a factory takes in raw materials and produces goods. The analogy stuck because it captures something real about how the best-performing enterprise AI teams actually operate.
An AI Factory is not a single model. It is a system of interconnected components — data collection, data preparation, model selection, training or adaptation, evaluation, deployment, monitoring, and feedback — that run continuously and improve iteratively. Each stage feeds the next. Feedback from production improves future training data. Better data produces better models. Better models generate more value, which justifies more investment in data. The flywheel is the point.
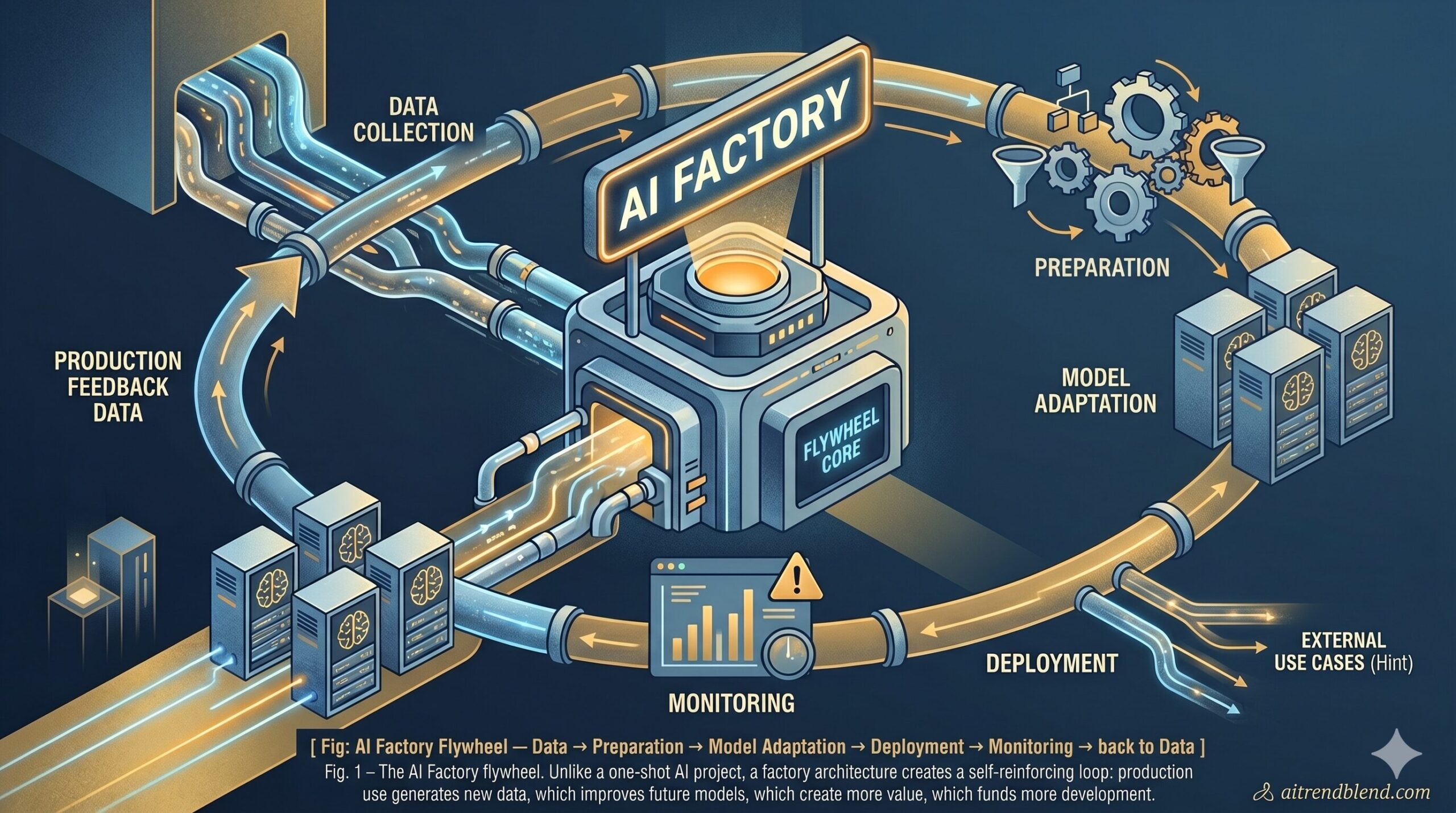
The difference between a company with an AI Factory and one without becomes visible after about six months of operation. Without the factory architecture, AI projects are one-offs. You fine-tune a model, deploy it, and it gradually degrades as your business data evolves. With the factory running, the system grows more capable and more specific to your business with every passing month. That specificity is what actually creates defensibility.
An AI Factory is not a product — it’s a production system. The companies winning with AI in 2026 are not those that deployed the best single model. They’re the ones that built the infrastructure to continuously improve AI capabilities using their own data.
The Three Pillars Every AI Factory Is Built On
Strip away the tooling and cloud provider branding and every functional AI Factory rests on the same three pillars. Getting any one of them wrong sets a ceiling on what the whole system can produce.
Data
The raw material. Proprietary, labeled, curated data is the single most defensible asset you can build. Generic models can be bought; the data that makes them specific to your business cannot.
Methods
How you adapt AI to your needs — prompt engineering, retrieval-augmented generation (RAG), or fine-tuning. Each method has a different cost, speed, and capability ceiling.
Algorithms
The underlying models and architectures you choose — foundation model selection, embedding models, vector search, evaluation metrics. The choice shapes what’s possible and what it costs.
Most companies struggle with data, not algorithms. The algorithms — the foundation models — are now genuinely commoditized at a level that would have seemed impossible three years ago. Claude, GPT-4o, Llama 3, Mistral, Gemini — any of these can serve as the reasoning core of a powerful AI system. The question is almost never “which model is smartest” in the abstract. The real question is always: what data do you have, how do you shape it, and which method of adaptation gets the most out of it fastest?
“The model is the least interesting part of your AI Factory. Your data and your deployment loop are the moat.”
— Observed across successful enterprise AI deployments, aitrendblend.com editorial, 2026
Before You Build: Choosing Your Adaptation Method
The problem most people run into at this stage is trying to decide between prompt engineering, RAG, and fine-tuning without a clear framework for making that choice. All three are legitimate — and all three are the wrong answer for at least one use case each.
Here is the honest version of how to choose:
-
1Start with prompt engineering If the task can be solved by giving a foundation model detailed instructions and examples in the context window, do that first. It’s fast, cheap, and reversible. Most companies underestimate how far prompt engineering alone can take them for internal tools.
-
2Add RAG when knowledge scope is the constraint If the model needs to reason over large bodies of proprietary documents — manuals, contracts, knowledge bases, database records — it cannot fit in a context window. RAG lets you retrieve relevant chunks at query time and inject them. This is the right tool for most enterprise knowledge-retrieval problems.
-
3Fine-tune when style, format, or specialization is the constraint If the model needs to consistently produce outputs in a specific format, speak a specialized vocabulary, or handle a narrow task at very high volume and low latency — fine-tuning is the right move. Fine-tuning encodes patterns into the model weights rather than relying on context, which makes it faster and cheaper per inference at scale.
-
4Combine methods for production systems Real AI Factory deployments almost always use all three in combination. A fine-tuned model optimized for your domain, augmented with RAG to retrieve up-to-date proprietary data, guided by a system prompt that enforces behavior constraints — that layered approach is the production pattern.
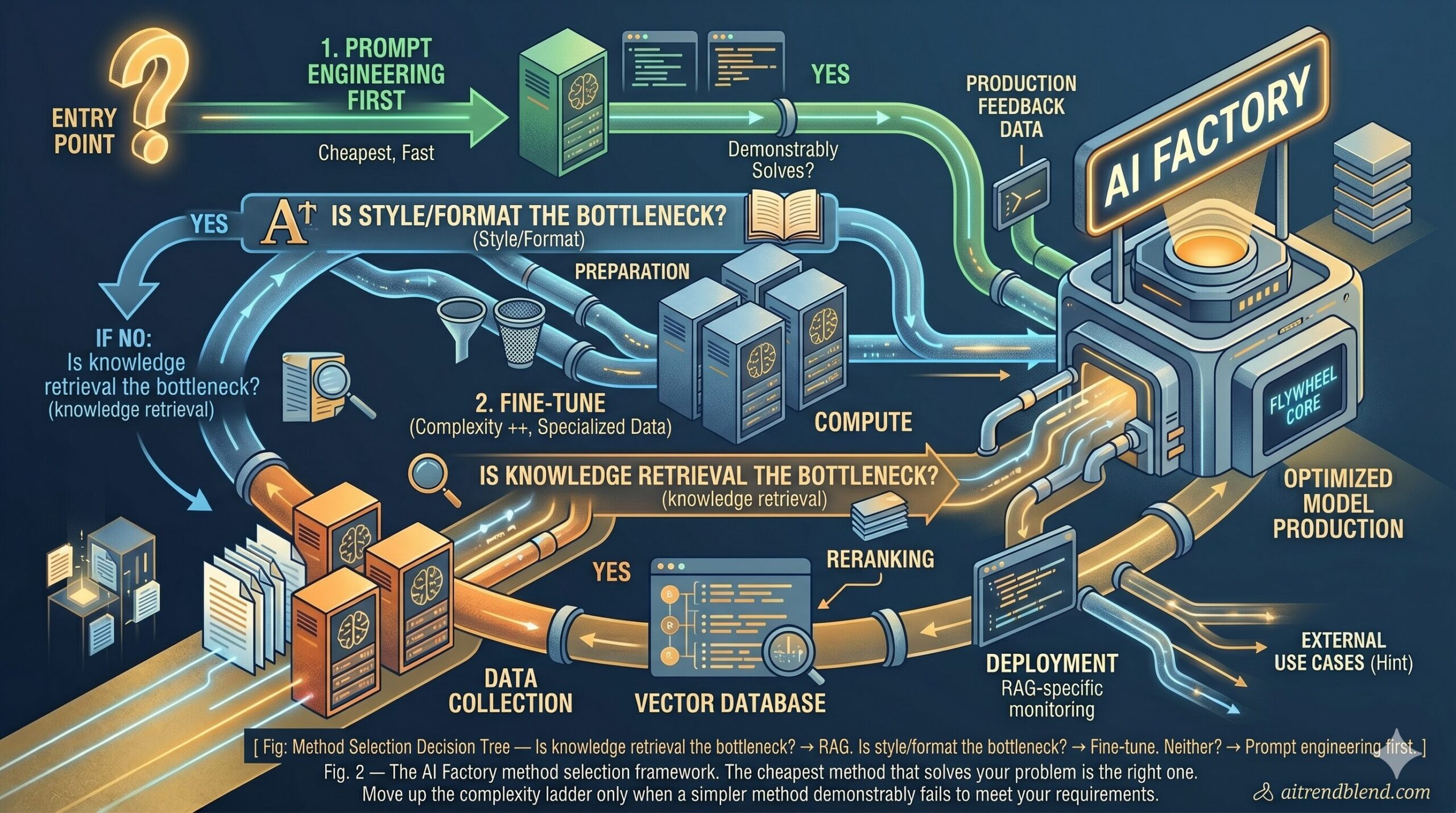
The method hierarchy matters: prompt engineering first, then RAG, then fine-tuning. Each step up adds capability and adds complexity, cost, and maintenance burden. Don’t fine-tune what a good RAG system can handle. Don’t RAG what a well-written system prompt can handle.
10 Prompts for Planning and Building Your AI Factory
The following prompt templates are designed for use with advanced AI systems — Claude Opus 4.7, GPT-4o, or Gemini 1.5 Pro — to help technical leads, AI engineers, and architects plan, specify, and document their internal AI system builds. They escalate from beginner orientation to master-level system orchestration.
Prompt 1: Internal Data Inventory Audit (Beginner)
You cannot design an AI system without knowing what data you have. Most teams underestimate this step, assuming their data is “good enough” before looking closely. This prompt forces a structured audit that surfaces both assets and gaps before a single line of code is written.
Why It Works: The question-first structure forces the AI to gather context before generating output, which eliminates the generic recommendations that come from vague inputs. The AI-readiness score column gives you an immediately actionable prioritization tool.
How to Adapt It: Add “flag any data that cannot be used for AI training due to legal or contractual restrictions” to surface compliance issues before they become blockers.
Prompt 2: Use Case Prioritization Matrix (Beginner)
The second mistake most AI Factory projects make — right after underestimating data complexity — is trying to build too many things at once. You need to ruthlessly prioritize the first use case. This prompt builds the framework for that decision.
Why It Works: Weighting business value against data readiness in the same matrix prevents the most common AI project failure mode: picking the most exciting use case instead of the one you can actually build well with the data you have now.
How to Adapt It: Add a “team skill match” dimension to account for whether your engineering team has relevant experience with the methods required for each use case.
Prompt 3: RAG System Architecture Design (Beginner)
RAG is the first real architecture decision most AI Factory builds face. Getting the components right from the start saves weeks of refactoring. This prompt walks through the design choices systematically.
Why It Works: Asking for “pros/cons of top 3 options” at each component level prevents the output from becoming a single opinionated architecture that ignores your specific constraints. The “flag two likely failure points” instruction ensures the most important risks land in your planning document.
How to Adapt It: Add “assume the team has no existing cloud infrastructure — recommend a fully managed stack” or “assume we’re on AWS — recommend services within that ecosystem” to filter recommendations to your setup.
Prompt 4: Training Data Preparation Specification (Intermediate)
Data preparation is unglamorous and deeply consequential. Garbage in, garbage out is not a cliché — it’s the actual failure mode of the majority of AI projects that fail. This prompt generates a rigorous data preparation specification before a single record is touched.
Why It Works: Asking for edge case examples within the labeling schema is the single most underrated move in data preparation. Without them, annotators make inconsistent judgment calls on the 20% of examples that don’t fit neatly into any category — and that inconsistency becomes noise in your model.
How to Adapt It: Add “include a data card template we can complete to document the dataset for future team members and auditors” to build compliance documentation in from the start.
Prompt 5: Fine-Tuning vs. RAG Decision Framework (Intermediate)
The question comes up in almost every enterprise AI project: should we fine-tune, use RAG, or both? The answer depends on specifics most people haven’t fully thought through. This prompt walks through the decision rigorously.
Why It Works: “Explain specifically what I lose by not choosing the alternative” — that instruction prevents the output from being a one-sided recommendation. Understanding the tradeoff clearly is more valuable than a confident answer that you’ll second-guess six months in.
How to Adapt It: Include a cost model requirement: “estimate the monthly inference cost for each approach at my query volume” to factor economics directly into the recommendation.
Prompt 6: Synthetic Data Generation Plan (Intermediate)
Here is where it gets interesting. One of the most underused tools in the AI Factory builder’s kit is synthetic data — AI-generated examples used to supplement or bootstrap training sets. This prompt designs a synthetic data strategy for situations where real labeled data is scarce or expensive to collect.
Why It Works: The diversity strategy requirement forces the plan to address mode collapse — the tendency for synthetic data generated from LLMs to be more uniform and less varied than real-world data. Without explicit diversity mechanisms, synthetic datasets look great on paper and train mediocre models.
How to Adapt It: Add “include a human review sampling protocol — what percentage of synthetic examples should a human check, and what should they look for” to build quality assurance in from the start.
Prompt 7: MLOps Pipeline Architecture (Advanced)
The model is only half the system. An AI Factory that can’t deploy, monitor, and retrain reliably is not a factory — it’s a science project. MLOps is the operational discipline that makes AI systems production-grade, and this prompt designs the pipeline end to end.
Why It Works: The “two components most teams skip and later regret” instruction surfaces the production-hardened knowledge that comes from operating real ML systems — evaluation gates and rollback procedures — which are almost always deprioritized during initial builds and become the source of production incidents six months later.
How to Adapt It: Add “include a data drift detection strategy — how do we know when the model’s input distribution has shifted enough to require retraining” to complete the monitoring picture.
Prompt 8: Model Evaluation and Red-Teaming Protocol (Advanced)
Most tutorials skip this part entirely: how do you systematically evaluate whether your AI system is actually working well, and how do you surface the failure modes before your users do? Rigorous evaluation separates AI Factory teams from AI experiment teams.
Why It Works: Separating automated evaluation from human evaluation from adversarial red-teaming forces the team to acknowledge that no single evaluation approach catches everything. The regression test suite requirement ensures that future improvements don’t quietly break existing functionality — the most common degradation pattern in iterative AI development.
How to Adapt It: For customer-facing systems, add “include a user feedback collection design — how do we capture and categorize real user dissatisfaction signals from production” to close the feedback loop back into the factory.
Prompt 9: AI Governance and Risk Framework (Advanced)
The question of governance is not optional for companies operating at any meaningful scale. Regulators in the EU, US, and increasingly Asia are tightening requirements around AI systems — and the companies caught without governance frameworks face penalties that dwarf the cost of building them upfront. This prompt produces a tailored framework.
Why It Works: Risk-tiering systems by type — rather than treating all AI as a single category — is the approach regulators actually recommend and what sophisticated compliance teams use. It prevents both over-regulation of low-stakes tools and under-regulation of high-stakes ones.
How to Adapt It: Add “include a vendor AI governance checklist — what questions to ask third-party AI vendors to assess their governance posture” for companies using a mix of internal and external AI systems.
Prompt 10: Master — Full AI Factory Blueprint Generator
This is the prompt that integrates everything — the data strategy, method selection, architecture design, evaluation protocol, MLOps pipeline, and governance requirements into a single comprehensive blueprint document. It is designed for the moment when a technical lead needs to align engineering, product, legal, and executive stakeholders around a shared AI Factory roadmap. Use it with the most capable model available to you.
Why It Works: The “state your assumptions before generating” instruction is the most important line in this prompt. AI models will make assumptions when faced with gaps in your input — and those assumptions will shape the entire blueprint. Making them explicit surfaces the ones that are wrong before they become embedded in a plan your leadership team is acting on.
How to Adapt It: For board-level presentations, add “Section 7: Executive Summary — a two-page non-technical version of this blueprint that communicates the strategic rationale, investment required, and expected return in plain business language.”
The Mistakes That Keep Killing AI Factory Projects
These are not theoretical pitfalls from an AI textbook. They are the patterns observed repeatedly across failed and stalled enterprise AI projects in 2025 and 2026. Each one is avoidable — if you know to look for it.
| Mistake | What It Looks Like | The Correct Approach |
|---|---|---|
| Training from scratch | Deciding to build a domain model from the ground up instead of adapting a foundation model | Fine-tune or RAG on top of an existing foundation model. Almost always cheaper, faster, and better. |
| Skipping evaluation infrastructure | Deploying a model and evaluating quality by “how does it feel in demos” | Build an automated evaluation suite before the first deployment. Run it on every model version. |
| Using one method for everything | Trying to solve every AI use case with just prompting, or just RAG, or just fine-tuning | Match the method to the use case. Most production systems combine all three layers. |
| Ignoring data quality in favor of model quality | Spending weeks tuning model hyperparameters on dirty data | Fix your data first. A simpler model on clean data almost always beats a complex model on dirty data. |
| Building without a feedback loop | Deploying a model and treating it as finished, with no mechanism to capture where it fails | Instrument production from day one. Every failure is training data. Every correction is a signal. |
The fifth mistake — building without a feedback loop — is the one that determines whether you have an AI system or an AI Factory. An AI system is a deployed model. An AI Factory is a deployed model plus the infrastructure to improve it continuously from what it encounters in production. The feedback loop is literally what makes the factory metaphor apt.
What the AI Factory Model Still Struggles With
None of this comes free, and some of it is harder than the enthusiasm around AI Factories suggests. The honest version of the current state includes several genuine limits that teams in 2026 are still running into.
Data labeling at scale remains painful and expensive. Synthetic data helps, and active learning techniques can reduce the volume of labels needed, but for tasks that require genuine domain expertise — legal contract review, medical coding, specialized financial analysis — human labeling is still unavoidably slow and expensive. The bottleneck on most enterprise AI Factory projects is not compute or algorithms; it is the time required to produce enough high-quality labeled examples for the tasks that matter most.
Multi-step reasoning in agentic components still fails unexpectedly. When an AI Factory includes agentic components — systems that take actions, not just produce outputs — the failure modes become more consequential. A retrieval step that returns slightly wrong information compounds into a significantly wrong downstream action. A model that misclassifies one document in a sequential pipeline can propagate that error through three subsequent steps before a human notices. The mitigation is thorough evaluation and conservative human-in-the-loop design for high-stakes pipeline stages. But the compounding error problem is real and not fully solved.
Explainability for regulated industries is still limited. Companies in financial services, healthcare, and insurance often need to explain AI decisions to auditors, regulators, or affected individuals. The interpretability tooling around large language models is improving — attention visualization, chain-of-thought outputs, and influence function research are all advancing — but a fully auditable reasoning trail for a complex LLM decision remains more aspiration than reality in most enterprise deployments. Workarounds include using smaller, more interpretable models for the highest-stakes decisions, and using LLMs only for tasks where rough explanations are acceptable.
The Factory Mindset Is the Actual Shift
What you’ve gained from reading this is a systems view of enterprise AI — one that goes beyond individual models or tools toward the architecture of continuous improvement. The ten prompts above are not the product; they’re an entry point into a way of thinking about AI development as a production discipline rather than a research exercise. The data flywheel, the evaluation pipeline, the feedback loop from production back into training — those are the mechanisms that separate companies with lasting AI advantages from companies with AI experiments that quietly stall.
There’s a deeper pattern here about organizational capability. The companies that will dominate their industries with AI over the next five years are not necessarily those with access to the best models — those are commoditizing fast. They’re the ones that figured out how to collect, label, and structure proprietary data better than their competitors. Data is the one asset in the AI stack that cannot be bought off the shelf, cannot be replicated by a competitor who doesn’t have your business relationships and operating history, and appreciates in value as the algorithms that process it improve. The factory is built around the data, not around the model.
Human judgment remains indispensable at several points in this system. Deciding which use cases are worth building at all requires business judgment that no AI can substitute. Labeling edge cases in training data requires domain expertise. Evaluating whether a deployed model is producing outputs that meet your actual quality bar — not a proxy metric that correlates with quality — requires people who understand your business deeply. The factory automates the mechanical parts of AI development. The parts that require understanding your specific business, your customers, and your standards remain yours.
The trajectory over the next 18 months points toward increasingly automated factory infrastructure — managed fine-tuning, automated evaluation, self-improving pipelines that require less configuration from the teams running them. The build-versus-buy line for MLOps components is moving steadily toward managed services. What won’t change is the fundamental requirement to bring your data, your judgment about what quality means, and your feedback from production. The factory tools will get simpler. The strategic thinking about what to build and why will stay hard — and stay valuable.
Build the infrastructure, feed it well, and it compounds. That’s the bet.
Start Building Your AI Factory Today
Use these prompt templates with Claude Opus 4.7 or GPT-4o to generate your first AI Factory blueprint — then explore our full prompt engineering hub for the next step.
Disclaimer: aitrendblend.com publishes independent editorial content. We are not affiliated with, sponsored by, or commercially partnered with Anthropic, OpenAI, NVIDIA, Google, or any other AI company referenced in this article.