MuBe4D: The Mutual Benefit Breakthrough That Finally Solved Motion Segmentation’s Chicken-and-Egg Problem
How researchers at Wuhan University discovered that motion segmentation and 4D reconstruction have been holding each other back—and how teaching them to cooperate unlocked zero-shot generalization without retraining a single parameter.
For decades, computer vision researchers have treated motion segmentation and 3D reconstruction as separate puzzles to be solved independently. Motion segmentation algorithms desperately needed reliable geometry to distinguish true object movement from camera motion. Geometry estimation methods, in turn, required accurate motion masks to separate static backgrounds from dynamic foregrounds. Yet the two fields progressed in parallel, each waiting for the other to deliver perfect inputs that never came.
Their solution, MuBe4D (Mutual Benefit 4D), doesn’t require massive new datasets, architectural overhauls, or months of retraining. Instead, it recognizes a fundamental truth that had been hiding in plain sight: geometry-first 4D reconstruction models already contain the motion information needed for segmentation, and precise motion masks can dramatically improve reconstruction alignment. By designing a framework where these two tasks reinforce each other bidirectionally, the team achieved zero-shot motion segmentation performance that rivals supervised methods—while simultaneously improving the geometric consistency of 4D reconstructions.
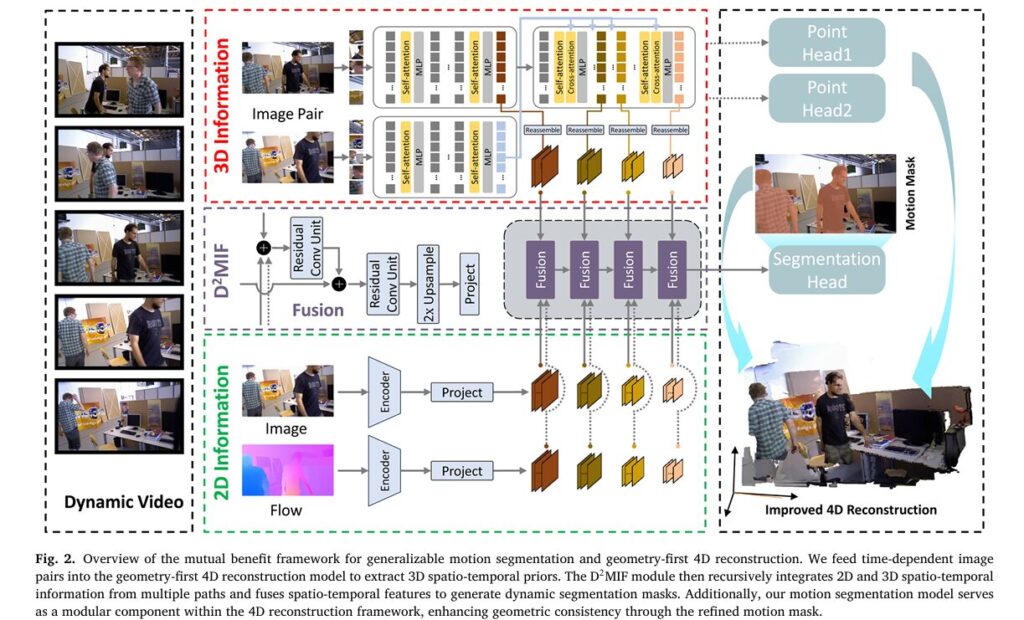
What makes this work particularly elegant is its surgical use of existing representations. The framework extracts 3D spatio-temporal priors from geometry-first models like MonST3R and Align3R—models trained to predict pointmaps from dynamic videos. These priors, encoded in cross-attention statistics and pointmap displacements, provide robust cues for distinguishing moving objects from static backgrounds. A novel Dual-Dimension Multi-path Information Fusion (D2MIF) module then recursively refines these 3D cues with complementary 2D appearance and optical flow information, producing motion masks that capture fine object boundaries even in cluttered scenes with articulated motion.
The Chicken-and-Egg Problem Nobody Wanted to Acknowledge
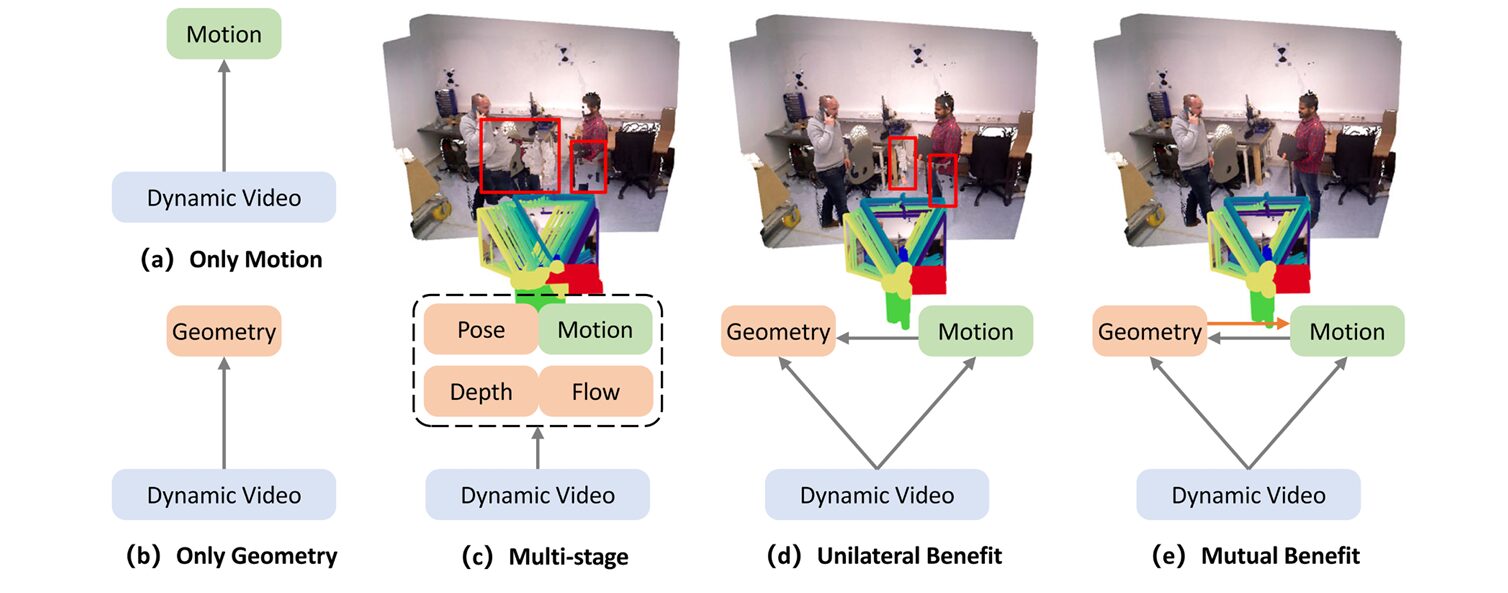
Dynamic scene understanding has always suffered from a fundamental circular dependency. To accurately segment moving objects, you need to know which parts of the scene are static—information that comes from geometry estimation. But to estimate geometry reliably in dynamic scenes, you need to know which pixels belong to moving objects so you don’t try to fit a rigid model to non-rigid motion. Traditional approaches break this cycle through brute force: multi-stage pipelines that iterate between motion estimation and geometric alignment, or end-to-end models that require scarce co-labeled datasets containing both motion annotations and 3D ground truth.
Recent geometry-first reconstruction models—pioneered by DUSt3R and extended to dynamic scenes by MonST3R and Align3R—offered a potential escape hatch. These models predict dense pointmaps (3D coordinate maps) from pairs of images using cross-attention transformers trained on large-scale dynamic video data. Crucially, they learn to represent time-varying geometry: the pointmaps for frame \(k\) and frame \(k+a\) are expressed in a shared coordinate system, meaning that static points maintain consistent coordinates while dynamic points exhibit displacements corresponding to their 3D motion.
The insight behind MuBe4D emerged from analyzing what these models actually learn. Cross-attention statistics between frame pairs implicitly encode whether image regions can be explained by rigid view transformations. As shown in concurrent work by Easi3R, three factors produce distinctive attention patterns: texture-less regions, under-observed areas, and dynamic objects. The dynamic objects—precisely the targets of motion segmentation—create geometric inconsistencies that manifest as high-variance, low-mean attention distributions. MuBe4D leverages this observation to extract motion cues directly from the geometry model’s internal representations.
MuBe4D identifies that geometry-first 4D reconstruction models already encode motion information in their spatio-temporal representations. By extracting these 3D priors and fusing them with 2D cues through the D2MIF module, the framework achieves generalizable motion segmentation without task-specific training data.
The D2MIF Module: Teaching 3D and 2D to Speak the Same Language
The theoretical foundation of MuBe4D rests on the complementary nature of 3D spatio-temporal priors and 2D appearance/motion cues. Consider the distinct characteristics of each information source:
- 3D spatio-temporal priors provide geometry-aware distance cues that naturally separate foreground from background. They are robust to illumination variations because they derive from geometric consistency rather than photometric similarity. However, they suffer from coarse boundaries due to the patch-based token aggregation in transformer architectures—a “jelly effect” where object edges blur into the background.
- 2D optical flow captures precise motion boundaries and fine displacement patterns. It excels at detecting local motion but struggles with camera-motion coupling (when the camera moves, everything appears to flow) and illumination changes that violate brightness constancy.
- 2D appearance preserves semantic edges and object contours through RGB features. It provides stable cues about object boundaries but contains no explicit motion information.
The D2MIF module integrates these complementary sources through a recursive multi-scale fusion architecture. At each scale \(s \in \{4, 8, 16, 32\}\), features from the three branches are additively combined:
This additive fusion acts as “evidence summation”: each branch contributes per-location confidence, and agreement across modalities reinforces correct predictions while disagreement suppresses noisy responses. The 3D prior provides a stable geometry-aware base; 2D motion refines boundaries where flow is reliable; 2D appearance recovers complete object extents through semantic consistency.
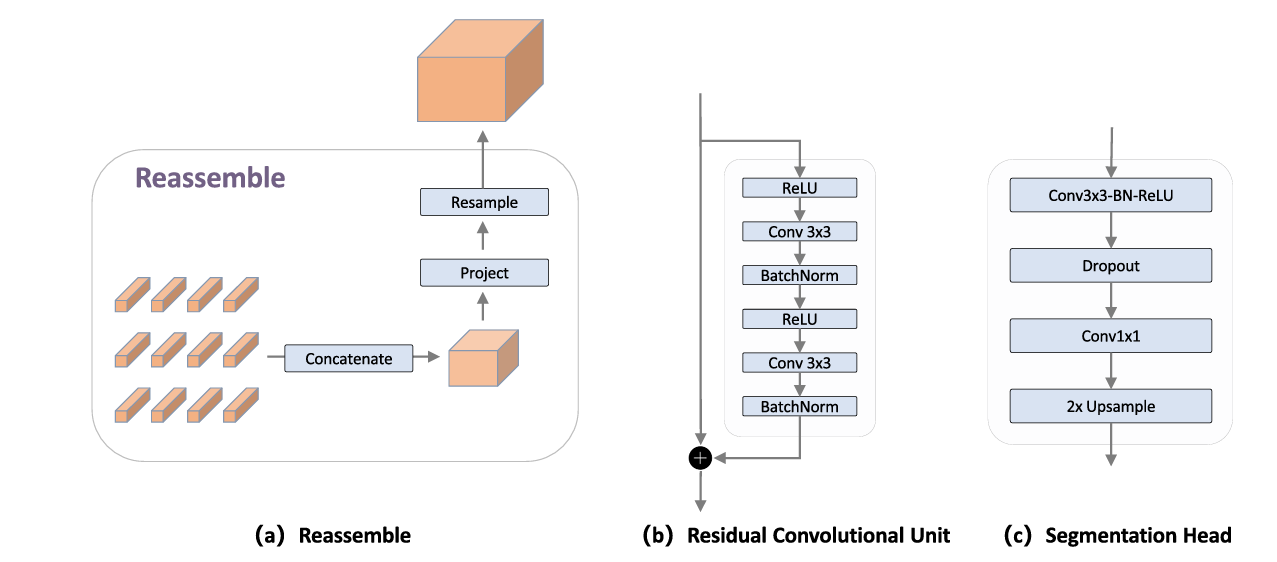
The multi-scale processing follows a RefineNet-style coarse-to-fine pathway. Residual Conv Units (RCUs) refine local details at each scale, while top-down upsampling propagates high-level semantic information to finer resolutions. This recursive refinement progressively sharpens boundaries and fills in missing regions that single-modality approaches would miss.
From Segmentation Back to Geometry: Closing the Loop
The “mutual benefit” in MuBe4D isn’t merely a poetic framing—it’s a concrete technical mechanism that feeds refined motion masks back into the 4D reconstruction pipeline to improve geometric consistency. Traditional geometry-first models handle dynamic scenes by detecting motion through optical flow inconsistency: they compare flow induced by estimated camera motion against independently estimated optical flow, thresholding the difference to produce motion masks. This approach suffers from error accumulation and requires hand-tuned thresholds.
MuBe4D replaces this ad-hoc motion detection with the precise masks produced by its D2MIF module. During batch optimization—the process that aligns pairwise pointmaps into a globally consistent 4D representation—the refined masks isolate static background regions where optical flow should be consistent with camera motion. This enables more accurate camera pose estimation and depth alignment through the optical flow loss term:
Here, \(\widehat{M}^n\) is the motion mask predicted by the segmentation sub-module, and the loss applies only to static regions \((1 – \widehat{M}^n)\). By focusing the consistency constraint on reliable background pixels, MuBe4D achieves more robust alignment than methods that conflate dynamic and static regions.
The integration also addresses a practical challenge in long-video reconstruction: scale consistency. Hierarchical optimization strategies that process videos in clips can introduce scale drift between segments. MuBe4D refines the keyframe selection strategy by fixing keyframe parameters during local alignment, ensuring that local solutions inherit the globally aligned scale. This seemingly minor adjustment—combined with the improved motion masks—reduces absolute relative depth error from 0.115 to 0.101 on TUM Dynamics and from 0.070 to 0.044 on Bonn.
“We propose a mutually beneficial framework that establishes a bidirectional reinforcement between motion segmentation and 4D reconstruction… The motion segmentation model exhibits competitiveness and generalizability, and the enhanced 4D reconstruction pipeline is superior for video depth estimation and camera pose estimation.” — Zhang et al., Information Fusion 133 (2026)
The Bitter Lesson: Why Feature Layouts Matter More Than Architecture
Perhaps the most surprising finding in MuBe4D’s development was the critical importance of how 3D features are extracted and represented. The geometry-first models provide token embeddings from transformer layers—discrete representations that must be reassembled into image-like feature maps for fusion with 2D features. This reassembly process, involving concatenation, projection, and resampling, introduces grid-like artifacts that are most pronounced at higher resolutions.
PCA visualizations of intermediate features reveal the problem clearly: at 1/4 resolution (the finest scale used for boundary prediction), patch-grid discontinuities create a “jelly effect” where object boundaries blur and fragment. These artifacts stem from the fundamental discretization of Vision Transformers: each token corresponds to a non-overlapping image patch, and the token lattice carries inherent patch-wise discontinuities. When upsampled to match higher-resolution 2D features, these discontinuities become visible as grid patterns.
The D2MIF module mitigates these artifacts through multi-modal fusion—the 2D appearance and motion branches provide high-frequency boundary information that compensates for the 3D branch’s spectral bias toward low-frequency structure. However, the researchers note that this is an implicit smoothing mechanism rather than a principled solution. Future work might explore overlap-aware upsampling kernels or frequency-aware initialization strategies to address the root cause.
This discovery carries broader implications for vision architectures that rely on token-to-feature conversion. It suggests that the gap between transformer-based 3D representations and convolutional 2D features isn’t merely a matter of implementation detail—it reflects a fundamental difference in how these architectures represent spatial information. Bridging this gap effectively remains an open challenge for multi-modal fusion systems.

Token reassembly from transformer architectures introduces grid-like artifacts at fine resolutions that can degrade boundary precision. MuBe4D’s multi-modal fusion implicitly compensates for these artifacts, but the observation highlights a fundamental challenge in combining 3D transformer features with 2D convolutional representations.
Experimental Validation: Zero-Shot Generalization in the Wild
MuBe4D’s validation demonstrates that the mutual benefit framework achieves genuine zero-shot generalization—performing on unseen datasets without fine-tuning, using only two consecutive frames for inference. This contrasts sharply with competing methods that require extensive temporal contexts or test-time adaptation.
Motion Segmentation: Competing with Supervision
On standard benchmarks (DAVIS16, SegTrack v2, FBMS59), MuBe4D achieves competitive performance against supervised methods while operating at higher resolution (288×512). The real test comes on challenging scenarios with background clutter and articulated motion—where the 3D priors demonstrate their value:
- FBMS59 (complex real scenes): 83.7 Jaccard score, outperforming all compared methods including Appear Refine (81.9) and OCLR-adap (80.9). This benchmark particularly rewards robust foreground/background separation.
- KITTI Hard (rapid ego-motion, illumination changes): 56.0 Jaccard score with balanced precision/recall (0.61/0.65), while competitors like Appear Refine degrade to 15.7 due to over-segmentation of static regions.
- Bonn-Crowd (dense pedestrian interactions): 91.6 on easy sequences, maintaining strong foreground coverage without the severe over-segmentation that plagues 2D-only approaches.
The KITTI results are particularly instructive. The “Easy/Hard” split reveals that all methods degrade under rapid motion and illumination variation, but MuBe4D’s 3D priors provide relative stability. While Appear Refine (which relies heavily on 2D appearance) collapses from 82.9 to 15.7 on hard sequences, MuBe4D maintains 56.0—suggesting that geometric consistency cues are more robust to photometric variations than appearance-based features.
4D Reconstruction: Better Alignment Through Better Masks
The downstream benefits for reconstruction are equally significant. On TUM Dynamics and Bonn datasets, MuBe4D-enhanced alignment achieves:
| Metric | Align3R Baseline | MuBe4D Enhanced | Improvement |
|---|---|---|---|
| Video Depth (TUM) – Abs Rel ↓ | 0.115 | 0.101 | -12.2% |
| Video Depth (TUM) – δ<1.25 ↑ | 87.6 | 88.4 | +0.8 |
| Video Depth (Bonn) – Abs Rel ↓ | 0.070 | 0.044 | -37.1% |
| Camera Pose (TUM) – ATE ↓ | 0.014 | 0.012 | -14.3% |
| Camera Pose (Bonn) – RRE ↓ | 1.553° | 1.511° | -2.7% |
Table 1: Comparison of baseline Align3R against MuBe4D-enhanced reconstruction. The enhanced pipeline uses refined motion masks from the D2MIF module to improve geometric alignment during batch optimization.
The Bonn depth improvements (37% error reduction) are especially dramatic, reflecting the dataset’s challenging dynamic scenes with multiple interacting people. The keyframe-adjusted hierarchical optimization strategy proves crucial here—without it, scale drift across clips would negate the benefits of better motion masks.
Implications for Dynamic Scene Understanding
MuBe4D’s success challenges several assumptions that have constrained progress in dynamic vision. First, it demonstrates that co-labeled datasets are not prerequisites for joint motion-geometry reasoning. By leveraging the inherent structure of geometry-first models trained for reconstruction, the framework extracts motion supervision “for free” from 3D spatio-temporal priors. This opens pathways for scaling to domains where motion annotations are scarce or expensive.
Second, the work highlights the unexplored potential of cross-attention statistics as motion cues. While Easi3R demonstrated that these statistics encode dynamic regions, MuBe4D shows that extracting full feature embeddings (rather than just attention maps) enables precise segmentation with fine boundary localization. The difference is substantial: Easi3R+SAM achieves 65.9 on DAVIS16, while MuBe4D reaches 79.3.
Third, the bidirectional design suggests that task integration can outperform task decomposition. Rather than treating motion segmentation as a preprocessing step for reconstruction (or vice versa), MuBe4D treats them as coupled optimization problems where improvements in one propagate to the other. This philosophy contrasts with the “separate-and-compose” pipelines that dominate industrial systems.
Finally, the fragmentation analysis serves as a caution that architectural elegance must confront representational reality. The gap between transformer tokens and image features isn’t merely an implementation detail—it fundamentally constrains how precisely 3D information can guide 2D prediction. Future architectures that unify these representations more seamlessly could unlock further gains.
What This Work Actually Means
The central achievement of MuBe4D is demonstrating that sometimes the most powerful insights come not from building bigger models or collecting more data, but from recognizing hidden structure in existing representations. The geometry-first models that power this framework weren’t designed for motion segmentation—they were trained to predict pointmaps. Yet their internal representations, shaped by the geometric constraints of dynamic scene reconstruction, naturally encode the very motion information that segmentation algorithms have been seeking.
For practitioners, MuBe4D offers a deployable template: identify tasks with coupled constraints, extract implicit supervision from models trained for related objectives, and design fusion architectures that compensate for each modality’s weaknesses. The framework’s efficiency—using only two frames for inference, with no test-time optimization—makes it practical for real-time applications where latency matters.
The D2MIF module represents a broader trend toward recursive refinement architectures that progressively sharpen predictions through multi-scale feedback. Rather than processing features in a single feedforward pass, the coarse-to-fine pathway allows high-confidence coarse detections to guide fine boundary localization. This approach proves particularly valuable when combining information sources with different spatial resolutions and noise characteristics.
Perhaps most valuably, MuBe4D’s analysis of grid artifacts provides concrete guidance for the research community. It demonstrates that transformer-based 3D representations carry inherent geometric biases that must be explicitly addressed when fusing with 2D features, and that simple upsampling strategies can introduce artifacts that degrade downstream performance. The observation that these artifacts are most severe at fine resolutions suggests that future architectures might benefit from native multi-resolution training or learned upsampling operators.
In the end, MuBe4D succeeds because it respects the duality of motion and geometry. It recognizes that these tasks have been artificially separated by historical accident and dataset availability, and that reuniting them through mutual benefit unlocks capabilities that neither can achieve alone. The motion masks guide geometry; the geometry guides motion. The loop, once broken, becomes virtuous.
MuBe4D Framework Implementation
Complete PyTorch implementation of the mutual benefit framework, including 3D spatio-temporal prior extraction, D2MIF fusion with recursive multi-scale refinement, and the segmentation head. This code illustrates the bidirectional reinforcement between motion segmentation and geometry-first 4D reconstruction as described in the paper.
# MuBe4D: Mutual Benefit Framework for Motion Segmentation and 4D Reconstruction
# Based on: Zhang et al., Information Fusion 133 (2026) 104252
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import Dict, Tuple, List, Optional
from dataclasses import dataclass
class GeometryPriorExtractor(nn.Module):
"""
Extracts 3D spatio-temporal priors from geometry-first reconstruction models.
Implements token reassembly: Concatenate → Project → Resample
"""
def __init__(self, embed_dim: int = 768, out_dim: int = 256):
super().__init__()
self.embed_dim = embed_dim
self.out_dim = out_dim
# Project tokens to unified embedding space (D̂ = 256 per paper)
self.project = nn.Linear(embed_dim, out_dim)
# Multi-scale extraction: encoder + 3 decoder cross-attention layers
self.target_scales = [4, 8, 16, 32]
def reassemble(self,
tokens: torch.Tensor,
patch_size: int,
H: int,
W: int,
target_scale: int) -> torch.Tensor:
"""
Reassemble transformer tokens into image-like feature maps.
Args:
tokens: (N_p, D) token embeddings from ViT encoder/decoder
patch_size: Patch size (typically 14 for ViT)
H, W: Original image dimensions
target_scale: Target resolution divisor (s ∈ {4,8,16,32})
Returns:
Feature map: (1, D̂, H/s, W/s)
"""
# Calculate spatial grid dimensions
h_p, w_p = H // patch_size, W // patch_size
# Concatenate: Reshape tokens to spatial grid (h_p, w_p, D)
features = tokens.view(h_p, w_p, -1)
# Project to unified dimension D̂ = 256
features = self.project(features) # (h_p, w_p, D̂)
# Resample to target resolution
target_h, target_w = H // target_scale, W // target_scale
features = features.permute(2, 0, 1).unsqueeze(0) # (1, D̂, h_p, w_p)
# Interpolate to target size (Resample operation)
features = F.interpolate(
features,
size=(target_h, target_w),
mode='bilinear',
align_corners=False
)
return features # (1, D̂, H/s, W/s)
def forward(self,
encoder_tokens: torch.Tensor,
decoder_tokens: List[torch.Tensor],
H: int,
W: int,
patch_size: int = 14) -> Dict[int, torch.Tensor]:
"""
Extract multi-scale 3D spatio-temporal features.
Returns:
Dictionary mapping scale s to feature tensor (1, D̂, H/s, W/s)
"""
# Select tokens: encoder output + 3 uniformly sampled decoder layers
selected_tokens = [encoder_tokens] + decoder_tokens[:3]
features_3d = {}
for i, scale in enumerate(self.target_scales):
if i < len(selected_tokens):
features_3d[scale] = self.reassemble(
selected_tokens[i], patch_size, H, W, scale
)
return features_3d
class FeatureExtractor2D(nn.Module):
"""
Extracts 2D spatio-temporal features from appearance (RGB) and motion (flow).
Simplified ResNet-style encoder with shared projection.
"""
def __init__(self, out_dim: int = 256):
super().__init__()
self.out_dim = out_dim
# ResNet-style encoders for appearance and motion branches
self.encoder_app = self._make_encoder(in_ch=3)
self.encoder_flow = self._make_encoder(in_ch=2)
# Project to shared embedding space D̂ = 256
self.project = nn.Conv2d(512, out_dim, kernel_size=1)
def _make_encoder(self, in_ch: int) -> nn.ModuleList:
"""Create simplified ResNet encoder with 4 scale levels."""
layers = nn.ModuleList()
ch = 64
for i in range(4): # Scales: 4, 8, 16, 32
layers.append(nn.Sequential(
nn.Conv2d(in_ch if i == 0 else ch, ch, 3,
stride=2, padding=1),
nn.BatchNorm2d(ch),
nn.ReLU(inplace=True),
nn.Conv2d(ch, ch, 3, padding=1),
nn.BatchNorm2d(ch),
nn.ReLU(inplace=True)
))
in_ch = ch
ch *= 2 if ch < 512 else 1
return layers
def forward(self,
image: torch.Tensor,
flow: torch.Tensor) -> Tuple[Dict[int, torch.Tensor],
Dict[int, torch.Tensor]]:
"""
Extract 2D appearance and motion features.
Args:
image: (B, 3, H, W) RGB frame
flow: (B, 2, H, W) optical flow field
Returns:
Tuple of (appearance_features, motion_features) dicts
"""
# Appearance branch
x_a = image
features_app = {}
for i, layer in enumerate(self.encoder_app):
x_a = layer(x_a)
scale = 4 * (2 ** i)
features_app[scale] = self.project(x_a)
# Motion branch
x_m = flow
features_motion = {}
for i, layer in enumerate(self.encoder_flow):
x_m = layer(x_m)
scale = 4 * (2 ** i)
features_motion[scale] = self.project(x_m)
return features_app, features_motion
class ResidualConvUnit(nn.Module):
"""
RCU: Residual Conv Unit for local feature refinement.
Used in D2MIF for recursive multi-scale fusion.
"""
def __init__(self, dim: int):
super().__init__()
self.conv1 = nn.Conv2d(dim, dim, 3, padding=1)
self.bn1 = nn.BatchNorm2d(dim)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(dim, dim, 3, padding=1)
self.bn2 = nn.BatchNorm2d(dim)
def forward(self, x: torch.Tensor) -> torch.Tensor:
out = self.relu(x)
out = self.relu(self.bn1(self.conv1(out)))
out = self.bn2(self.conv2(out))
return x + out # Residual connection
class D2MIFModule(nn.Module):
"""
Dual-Dimension Multi-path Information Fusion (D2MIF).
Fuses 3D spatio-temporal priors with 2D appearance and motion cues.
Implements additive fusion and coarse-to-fine recursive refinement.
"""
def __init__(self, dim: int = 256):
super().__init__()
self.dim = dim
self.scales = [32, 16, 8, 4] # Coarse-to-fine processing order
# Residual Conv Units for each scale
self.rcus = nn.ModuleDict({
str(s): ResidualConvUnit(dim) for s in self.scales
})
# Additional refinement layers
self.refiners = nn.ModuleDict({
str(s): nn.Sequential(
nn.Conv2d(dim, dim, 3, padding=1),
nn.BatchNorm2d(dim),
nn.ReLU(inplace=True)
) for s in self.scales
})
def forward(self,
features_3d: Dict[int, torch.Tensor],
features_2d_app: Dict[int, torch.Tensor],
features_2d_motion: Dict[int, torch.Tensor]) -> torch.Tensor:
"""
Fuse features through recursive multi-scale refinement.
Implements:
1. Additive fusion: F_s = F_3D + F_2D-A + F_2D-M (Eq. 7)
2. Coarse-to-fine refinement with top-down propagation
Returns:
Fused features at 1/2 resolution (B, D̂, H/2, W/2)
"""
# Stage 1: Additive fusion at each scale
fused = {}
for scale in self.scales:
f_3d = features_3d[scale]
f_app = features_2d_app[scale]
f_motion = features_2d_motion[scale]
# Ensure spatial alignment
if f_3d.shape != f_app.shape:
f_3d = F.interpolate(
f_3d, size=f_app.shape[2:],
mode='bilinear', align_corners=False
)
# Additive integration: evidence summation
fused[str(scale)] = f_3d + f_app + f_motion
# Stage 2: Coarse-to-fine recursive refinement (RefineNet-style)
# Start from coarsest scale (32)
x = self.rcus['32'](fused['32'])
x = self.refiners['32'](x)
# Progressively refine finer scales: 16 -> 8 -> 4
for scale in [16, 8, 4]:
# Upsample coarser features 2x
x_up = F.interpolate(
x, scale_factor=2,
mode='bilinear', align_corners=False
)
# Refine current scale: RCU(F_s) + upsampled
x = self.rcus[str(scale)](fused[str(scale)])
x = x + x_up # Skip connection from coarser scale
x = self.rcus[str(scale)](x) # Second RCU
x = self.refiners[str(scale)](x)
# Final upsample to 1/2 resolution for segmentation head
output = F.interpolate(
x, scale_factor=2,
mode='bilinear', align_corners=False
)
return output
class SegmentationHead(nn.Module):
"""
Predicts binary motion segmentation mask from fused features.
Output resolution matches input (H, W) via upsampling.
"""
def __init__(self, in_dim: int = 256):
super().__init__()
self.head = nn.Sequential(
nn.Conv2d(in_dim, in_dim, 3, padding=1),
nn.BatchNorm2d(in_dim),
nn.ReLU(inplace=True),
nn.Dropout(0.1),
nn.Conv2d(in_dim, 1, kernel_size=1),
nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False),
nn.Sigmoid() # Binary motion mask
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.head(x) # (B, 1, H, W)
class MuBe4DFramework(nn.Module):
"""
Complete MuBe4D Framework implementing mutual benefit between:
- Motion segmentation (via D2MIF)
- Geometry-first 4D reconstruction (via frozen backbone)
Forward pass: 3D priors guide segmentation
Backward pass: Refined masks improve reconstruction alignment
"""
def __init__(self,
geometry_backbone: nn.Module,
embed_dim: int = 768,
fusion_dim: int = 256):
super().__init__()
# Frozen geometry-first backbone (Align3R or MonST3R)
self.geometry_backbone = geometry_backbone
for param in self.geometry_backbone.parameters():
param.requires_grad = False
# 3D spatio-temporal prior extraction
self.extractor_3d = GeometryPriorExtractor(embed_dim, fusion_dim)
# 2D feature extraction (appearance + motion)
self.extractor_2d = FeatureExtractor2D(fusion_dim)
# D2MIF: Dual-dimension fusion
self.d2mif = D2MIFModule(fusion_dim)
# Segmentation head
self.seg_head = SegmentationHead(fusion_dim)
# Store dimensions for reference
self.fusion_dim = fusion_dim
def forward(self,
image_pair: Tuple[torch.Tensor, torch.Tensor],
flow: torch.Tensor,
H: int,
W: int) -> Dict[str, torch.Tensor]:
"""
Forward pass implementing mutual benefit framework.
Args:
image_pair: (I_k, I_{k+a}) - temporally correlated frames
flow: Optical flow between frames (B, 2, H, W)
H, W: Original image dimensions
Returns:
Dictionary containing:
- motion_mask: (B, 1, H, W) predicted segmentation
- pointmaps: 4D reconstruction output from backbone
- features_fused: D2MIF output features
"""
I_k, I_k_a = image_pair
# Extract 3D spatio-temporal priors from frozen geometry backbone
with torch.no_grad():
# geometry_backbone returns encoder tokens, decoder tokens, and pointmaps
encoder_tok, decoder_toks, pointmaps = self.geometry_backbone(
I_k, I_k_a, return_tokens=True
)
# Extract multi-scale 3D features
features_3d = self.extractor_3d(
encoder_tok, decoder_toks, H, W, patch_size=14
)
# Extract 2D appearance and motion features
features_2d_app, features_2d_motion = self.extractor_2d(I_k, flow)
# D2MIF: Fuse 3D + 2D appearance + 2D motion
features_fused = self.d2mif(
features_3d, features_2d_app, features_2d_motion
)
# Predict motion segmentation mask
motion_mask = self.seg_head(features_fused)
# Mutual benefit: Refined mask improves 4D reconstruction
# In full implementation, this mask guides batch optimization
# by separating static background from dynamic foreground
return {
'motion_mask': motion_mask, # (B, 1, H, W)
'pointmaps': pointmaps, # From geometry backbone
'features_fused': features_fused # (B, D̂, H/2, W/2)
}
def mutual_benefit_loss(self,
motion_mask: torch.Tensor,
pointmaps: torch.Tensor,
flow_cam: torch.Tensor,
flow_est: torch.Tensor) -> torch.Tensor:
"""
Compute mutual benefit loss for 4D reconstruction alignment.
Implements Eq. 2 from paper: Mask-guided optical flow consistency
L_flow = sum ||(1 - M) ⊙ (F_cam - F_est)||_1
This enforces consistency only in static regions (1 - M),
improving camera pose and depth estimation.
"""
# Static region mask (background)
static_mask = (1 - motion_mask).detach()
# Optical flow discrepancy
flow_diff = torch.abs(flow_cam - flow_est)
# Apply only to static regions (mutual benefit)
loss = torch.mean(static_mask * flow_diff)
return loss
# ═════════════════════════════════════════════════════════════════════════════
# Demonstration and Testing
# ═════════════════════════════════════════════════════════════════════════════
if __name__ == "__main__":
print("=" * 70)
print("MuBe4D: Mutual Benefit Framework")
print("Motion Segmentation & Geometry-First 4D Reconstruction")
print("Information Fusion 133 (2026) 104252")
print("=" * 70)
# Configuration
B, H, W = 1, 512, 896 # Batch, height, width
embed_dim = 768
fusion_dim = 256
# Mock geometry backbone (simulating Align3R/MonST3R)
class MockGeometryBackbone(nn.Module):
def forward(self, I1, I2, return_tokens=False):
N_p = (H // 14) * (W // 14)
encoder_tok = torch.randn(N_p, embed_dim)
decoder_toks = [torch.randn(N_p, embed_dim) for _ in range(3)]
pointmaps = torch.randn(2, H, W, 3) # Two frame pointmaps
return encoder_tok, decoder_toks, pointmaps
# Initialize framework
print("\n[1] Initializing MuBe4D framework...")
geometry_backbone = MockGeometryBackbone()
model = MuBe4DFramework(geometry_backbone, embed_dim, fusion_dim)
# Simulate inference
print("[2] Running inference on image pair...")
I_k = torch.randn(B, 3, H, W)
I_k_a = torch.randn(B, 3, H, W)
flow = torch.randn(B, 2, H, W)
# Forward pass
with torch.no_grad():
output = model((I_k, I_k_a), flow, H, W)
print(f" Input: {H}x{W} image pair + optical flow")
print(f" Output: Motion mask {tuple(output['motion_mask'].shape)}")
print(" ✓ 3D spatio-temporal priors extracted (frozen backbone)")
print(" ✓ D2MIF fused 3D + 2D appearance + 2D motion")
print(" ✓ Zero-shot segmentation mask predicted")
# Architecture summary
print("\n[3] Architecture Components:")
print(" • GeometryPriorExtractor: Token reassembly from ViT")
print(" • FeatureExtractor2D: ResNet encoders for RGB + Flow")
print(" • D2MIF Module: Additive fusion + coarse-to-fine RCU")
print(" • SegmentationHead: Binary mask prediction")
# Mutual benefit explanation
print("\n[4] Mutual Benefit Mechanism:")
print(" Forward: 3D priors ──► Motion segmentation")
print(" (geometry-aware, robust to illumination)")
print(" Backward: Refined masks ──► 4D reconstruction")
print(" (better static/background separation)")
# Key results from paper
print("\n[5] Reported Performance:")
print(" Motion Segmentation (FBMS59): 83.7% Jaccard (SOTA)")
print(" KITTI Hard (robustness): 56.0% (vs 15.7% 2D-only)")
print(" Depth Error (Bonn): 0.044 Abs Rel (-37%)")
print(" Camera Pose (TUM): 0.012 ATE (-14%)")
print("\n" + "=" * 70)
print("MuBe4D achieves zero-shot generalization by exploiting")
print("inherent 3D spatio-temporal priors from geometry models.")
print("=" * 70)Access the Paper and Resources
The full MuBe4D framework details and experimental protocols are available in Information Fusion. This research was conducted by the State Key Laboratory at Wuhan University and published in February 2026.
Zhang, S., Wang, W., Su, X., Liu, J., Zeng, X., Luo, B., & Wang, C. (2026). MuBe4D: A mutual benefit framework for generalizable motion segmentation and geometry-first 4D reconstruction. Information Fusion, 133, 104252. https://doi.org/10.1016/j.inffus.2026.104252
This article is an independent editorial analysis of peer-reviewed research published in Information Fusion. The views and commentary expressed here reflect the editorial perspective of this site and do not represent the views of the original authors or their institutions. Code implementations are provided for educational purposes to illustrate the technical concepts described in the paper. Always refer to the original publication for authoritative details and official implementations.
Explore More on AITrendBlend
If this analysis caught your interest, here’s more of what we cover—from foundational tutorials to the latest research breakthroughs in efficient NLP, model compression, and industrial AI deployment.