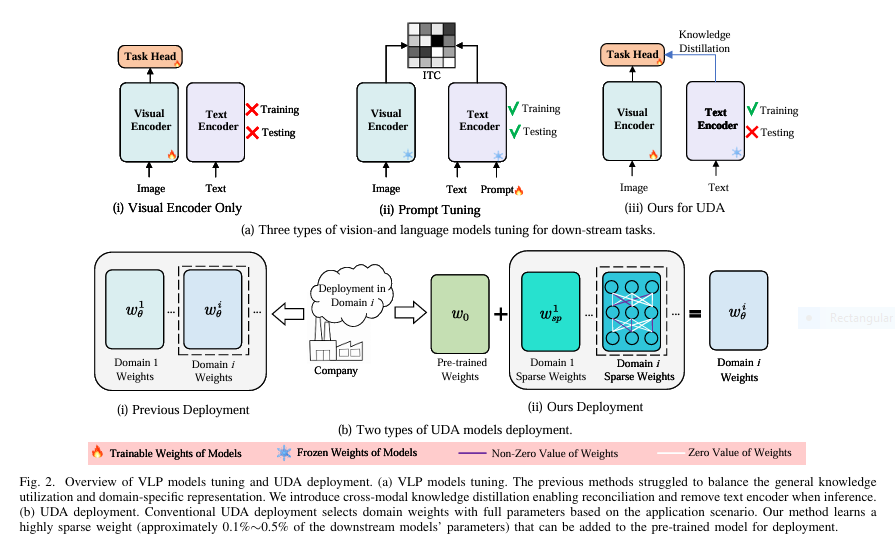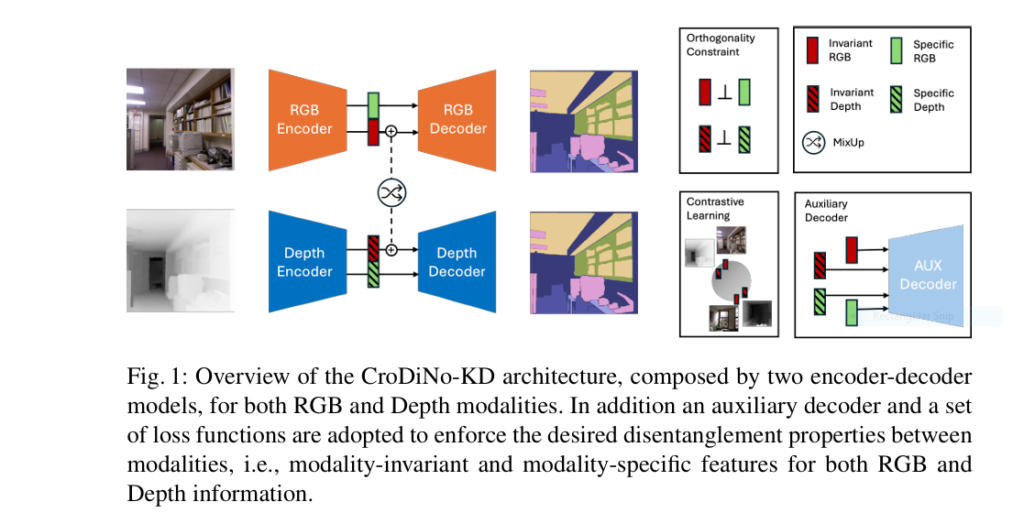
3 Breakthroughs in RGBD Segmentation: How CroDiNo-KD Revolutionizes AI Amid Sensor Failures
The Hidden Crisis in Robotics and Autonomous Vehicles (Keywords: RGBD semantic segmentation, sensor failure, cross-modal learning) Imagine an autonomous vehicle navigating a fog-covered highway. Its depth sensor fails without warning. Instantly, its perception system degrades, risking lives. This nightmare scenario isn’t science fiction—it’s a daily reality for engineers grappling with multi-modal sensor fragility. Traditional RGBD (RGB […]