The Sampling Problem Federated Learning Has Been Ignoring — and How OSMD Finally Fixes It
A multi-institution team from the University of Chicago, NJIT, Ant Financial, Zhejiang University, and USC cast client selection as a non-stationary online learning problem — and built an adaptive sampler that provably beats uniform sampling by reducing the gradient variance that heterogeneous data creates.
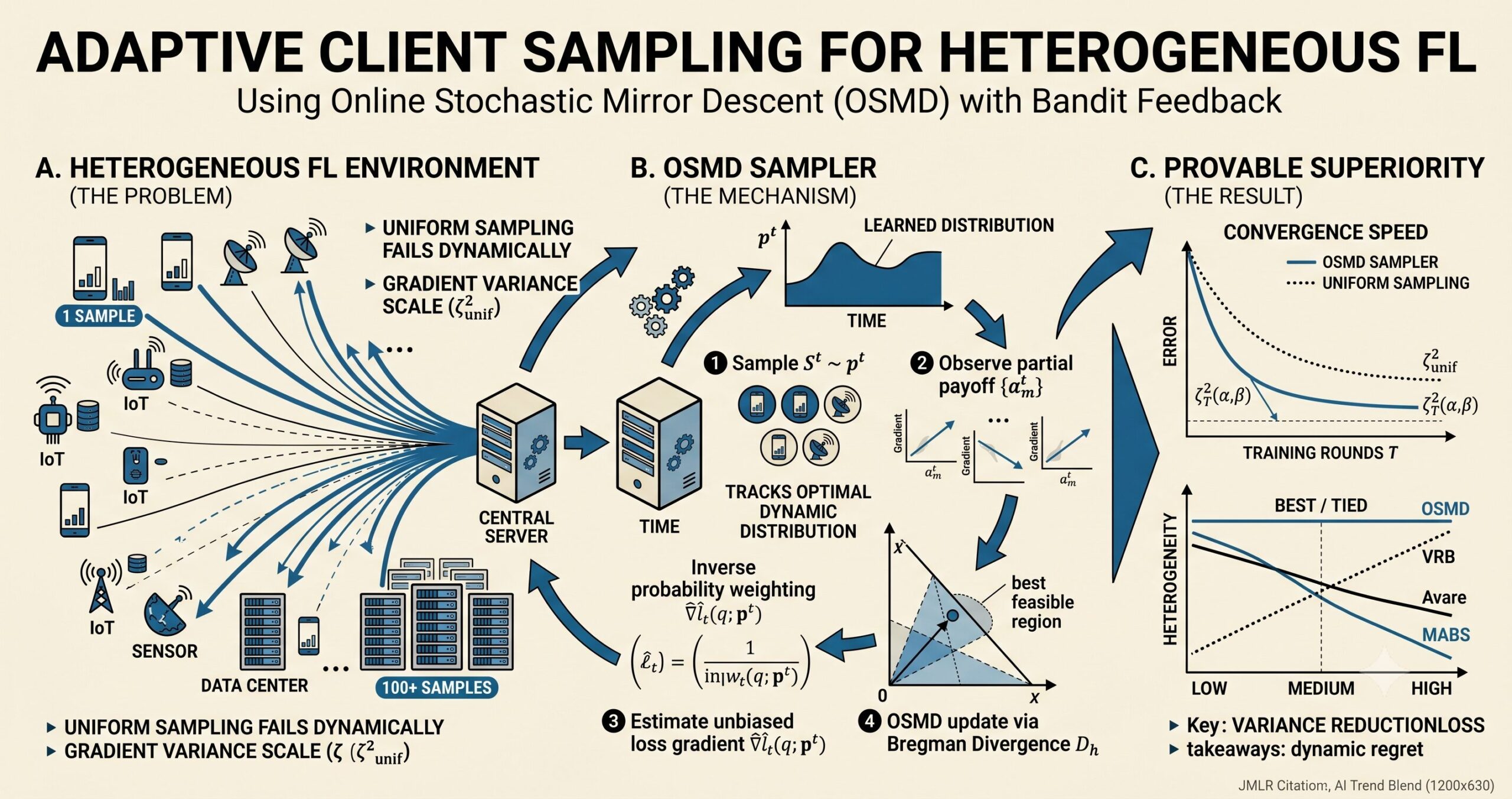
Most federated learning systems pick clients the same way you might pick names out of a hat — uniformly at random. It is simple, it is fair, and it turns out to be quietly terrible in any real deployment where data is not evenly distributed. Boxin Zhao, Lingxiao Wang, Ziqi Liu, Zhiqiang Zhang, Jun Zhou, Chaochao Chen, and Mladen Kolar decided to treat client selection not as a random draw, but as an online learning problem — one where the algorithm learns, round by round, which clients are worth listening to more carefully.
Why Picking Clients Randomly Is the Silent Bottleneck
Consider a hospital network running federated learning across 500 clinics. Sixty-five percent of those clinics contributed exactly one training sample. A handful contributed a hundred. Uniform sampling means you spend most of your communication budget contacting clinics whose one-sample gradient tells you almost nothing — while the information-dense clients sit idle most rounds.
This is not a niche pathology. The paper explicitly constructs this scenario in its real-data experiments, modeling a distribution where the majority of clients have almost no data. In practice, FL deployments on mobile phones, IoT sensors, and distributed healthcare systems look exactly like this. The useful data is concentrated; the participants are not.
The theoretical problem runs even deeper. When client data distributions differ substantially — high heterogeneity, in the paper’s terminology — the gradient variance from uniform sampling becomes large. Large gradient variance slows convergence. For SGD and FedAvg, that variance term appears directly in the convergence bound, and with uniform sampling it scales with \(\zeta^2_{\text{unif}}\) — the worst-case variance across all clients. The research question the paper asks is blunt: can you learn a better sampling distribution that makes \(\zeta^2\) smaller?
Uniform client sampling in federated learning ignores the heterogeneous importance of clients. When data distributions differ across devices, some clients’ gradients are far more informative than others — and a fixed uniform distribution permanently fails to adapt to this reality.
Casting Sampling as a Bandit Problem
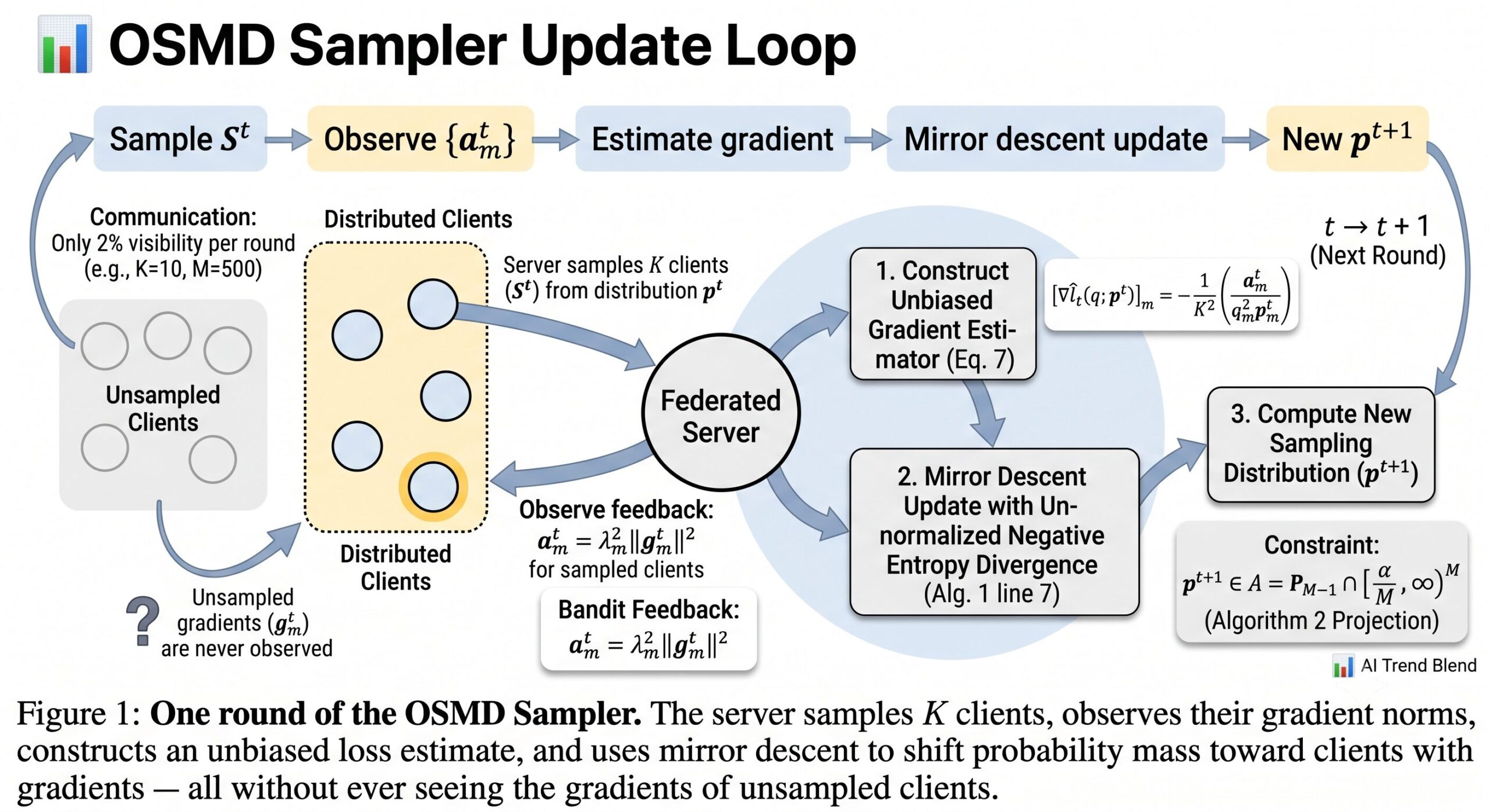
The insight that makes this paper work is reframing client selection as a sequential decision problem. Every communication round, the server picks a sampling distribution \(p^t\) over \(M\) clients and draws \(K\) of them. After seeing the local updates those clients return, it gets partial information about the importance of the clients it sampled — but nothing about the ones it did not sample. That is the defining structure of bandit feedback: you see the payoff for the action you took, not for all the actions you could have taken.
The quantity the algorithm is trying to minimize is called the variance reduction loss:
This is simply a weighted sum of inverse sampling probabilities — high when you are sampling important clients rarely, low when you match your sampling effort to each client’s gradient magnitude. The twist is that you cannot compute \(a^t_m\) for clients you did not select, so you must estimate it from the partial information you do observe.
Previous work treated this as a stationary problem — trying to find the single best fixed distribution. The team at Chicago, NJIT, and Ant Financial recognized that this is fundamentally wrong. The optimal sampling distribution changes with every round of training as the model evolves and the gradients shift. A distribution that was optimal at round 50 may be wasteful by round 500. The right framework is non-stationary online learning, where the goal is to track a dynamic comparator sequence, not a fixed one.
The OSMD Sampler: Mechanism and Algorithm
The proposed solution is an Online Stochastic Mirror Descent (OSMD) algorithm. Mirror descent is a generalization of gradient descent that operates in a transformed space — particularly useful for problems constrained to a probability simplex. The unnormalized negative entropy serves as the mirror map here, which naturally keeps updates on the simplex and enforces that no client is ever assigned zero probability.
At each round, the algorithm constructs an unbiased estimator of the gradient of the variance reduction loss using only the observed clients:
The update rule then moves the sampling distribution in the direction that reduces expected variance, penalized by a Bregman divergence term that prevents the distribution from shifting too aggressively in any single round. Critically, the algorithm uses only the most recent information — it forgets older rounds rather than averaging them equally — which is exactly what makes it track the non-stationary optimal distribution.
One subtle engineering detail: the sampling distribution is constrained to lie in \(\mathcal{A} = \mathcal{P}_{M-1} \cap [\alpha/M, \infty)^M\), a truncated simplex that keeps every client’s probability bounded away from zero by a floor parameter \(\alpha \in (0,1]\). This prevents the algorithm from permanently ignoring any client. Setting \(\alpha = 1\) recovers uniform sampling; smaller values give more flexibility to concentrate on important clients. Empirically, the algorithm is robust to \(\alpha\) across a wide range — any value between 0.1 and 0.9 works well.
Adaptive-OSMD: Eliminating the Tuning Problem
The base OSMD algorithm requires a learning rate \(\eta\) that depends on the total variation of the optimal comparator sequence — a quantity that cannot be known before training begins. This is a genuine practical obstacle. The paper’s solution is elegant: run an ensemble of \(E = O(\log^2 T)\) expert algorithms, each with a different learning rate drawn from a geometric grid, and use an exponentially-weighted-average meta-algorithm to track whichever expert is performing best.
The meta-algorithm updates the weight of each expert using a Hoeffding-based exponential weighting scheme. The overhead is modest — only \(O(\log^2 T)\) extra mirror descent steps per training run — and the theoretical guarantee is preserved: the dynamic regret of Adaptive-OSMD is within a small additive term of the best fixed learning rate in hindsight.
There is also a doubling-trick variant for situations where the total number of rounds \(T\) is not known in advance. The algorithm restarts at exponentially increasing checkpoints, resetting the expert learning rates for each interval. This adds only a \(\sqrt{2}/(\sqrt{2}-1)\) constant factor to the regret bound — a very affordable price for not needing to specify \(T\) upfront.
Theoretical Guarantees: Tighter Convergence Through Heterogeneity Reduction
The paper’s theoretical contribution goes beyond just bounding regret. It connects adaptive sampling directly to the convergence speed of standard federated optimization algorithms — and the connection is clean.
The key concept is dynamic heterogeneity \(\zeta^2_T(\alpha, \beta)\), defined as the worst-case gradient variance achievable by a dynamic sampling sequence with total variation budget \(\beta\). The paper proves a clean hierarchy:
Uniform sampling sits at the top — it corresponds to the worst-case heterogeneity. The best fixed non-uniform distribution reduces it. And a dynamic distribution that adapts over time can reduce it further still. OSMD, by tracking the optimal dynamic distribution, achieves the lowest achievable heterogeneity. That directly translates into a tighter convergence bound for both mini-batch SGD and FedAvg.
For mini-batch SGD, Theorem 4 shows that whenever \(\zeta_{\text{unif}} > \zeta_{\text{fix}}\) — whenever heterogeneity is genuinely present — OSMD achieves asymptotically faster convergence than uniform sampling. The same result holds for FedAvg under Theorem 5. The extra term that Adaptive-OSMD introduces compared to the tuned version is of order \(T^{-3/4}\), which is dominated by the convergence rate and becomes negligible at large \(T\).
When heterogeneity is genuine — when uniform sampling variance exceeds the minimum achievable variance — OSMD Sampler provably converges faster than uniform sampling for both mini-batch SGD and FedAvg, with the gap widening as the heterogeneity level increases.
Experimental Results: Where the Theory Lands in Practice
Simulation Experiments
The simulated experiments use a linear regression setup with 100 clients, each holding 100 samples drawn from heterogeneous Gaussian distributions. The heterogeneity level is controlled by a single parameter \(\sigma\) — larger \(\sigma\) means more spread in the per-client scaling factors. The results tell a consistent story across three heterogeneity levels.
| Method | σ = 1.0 (Low) | σ = 3.0 (Medium) | σ = 10.0 (High) |
|---|---|---|---|
| Uniform Sampling | Competitive | Degrades | Fails clearly |
| MABS | Good | Moderate | Best at high σ |
| VRB | Good at low σ | Moderate | Degrades |
| Avare | Good at low σ | Moderate | Degrades |
| Adaptive-OSMD | Best / tied | Best | Best |
Table 1: Qualitative convergence comparison across heterogeneity levels. Adaptive-OSMD uniquely dominates across all settings, whereas every competing method has a heterogeneity range where it underperforms.
The pattern is striking. Every competing method has a regime where it falls short — VRB and Avare are solid when heterogeneity is low but unravel at high heterogeneity; MABS handles high heterogeneity but is outperformed by others at low levels. Adaptive-OSMD is consistently the best or tied for best across all three conditions. That robustness is the practical payoff of the non-stationary online learning formulation.
Real-Data Experiments
The real-data experiments use MNIST, KMNIST, and Fashion-MNIST with 500 clients and a deliberately skewed sample distribution: 65% of clients have just one training sample. This setup is not adversarial — it accurately mirrors real federated deployments on consumer devices. With K = 10 clients selected per round (2% of the population), the algorithm has very limited visibility each round.
Across all three datasets, Adaptive-OSMD converges faster and more stably than every competitor in both training loss and validation accuracy. The improvement is most visible in the training loss curves, where uniform sampling plateaus noticeably while OSMD continues to descend. The practical lesson: when most of your clients are near-useless for gradient signal, learning to find the valuable ones matters enormously.
The Learnable Filter and Sampling Without Replacement
Two extensions in the appendix deserve mention even though they are positioned as supplementary material. The sampling-without-replacement variant, detailed in Algorithm 7, modifies the selection procedure so that no client is chosen twice per round — which is physically natural in most FL systems. The key insight from Proposition 11 is that the variance-minimizing sampling distribution under replacement and without-replacement settings is identical, so the OSMD-learned distribution can be reused directly. Empirically, with-replacement and without-replacement perform nearly identically.
The SCAFFOLD integration in Appendix E is a more tentative result but a promising one. SCAFFOLD adds control variates to FedAvg to correct for client drift, and OSMD can be plugged in by defining the feedback \(a^t_m\) as the squared norm of the local model update. At high heterogeneity, SCAFFOLD with OSMD outperforms SCAFFOLD with uniform sampling. A complete theoretical analysis of this combination is left for future work — the paper is transparent about this gap.
“The relative importance of clients will change over time, which makes the environment dynamic and challenging. Our method shows empirical advantages over previous methods by learning to forget the history.” — Zhao, Wang, Liu, Zhang, Zhou, Chen, and Kolar, JMLR (2025)
What This Work Changes — and What It Does Not
The paper makes a conceptually clean argument: uniform sampling is not a neutral default. It carries an implicit assumption that every client’s gradient is equally informative at every round — an assumption that is simply false in heterogeneous FL systems. By casting sampling as a non-stationary online learning problem, the authors give the system a mechanism to continuously correct this assumption.
The connection to differential privacy is worth flagging honestly. Non-uniform sampling concentrates communication on high-importance clients, which could make it easier for an adversary to infer which clients are being selected — a potential privacy leakage relative to uniform sampling. The paper acknowledges this and points to differential privacy noise as a mitigation, but the trade-off analysis is explicitly left for future research. Practitioners deploying this in privacy-sensitive settings should be aware of the gap.
The assumption of bounded gradient norms is also worth scrutiny. Many popular loss functions — cross-entropy, logistic regression — satisfy this naturally, but the bound is sometimes invoked as a simplifying tool rather than a physical guarantee. Removing it without losing the regret bounds is identified as feasible but complex, and deliberately deferred.
Still, the core contribution is solid and the practical guidance is clear. When client data distributions differ substantially, adaptive sampling should be the default. The Adaptive-OSMD Sampler requires no prior knowledge about the gradient distribution, no additional computation beyond sorting a vector of M probabilities per round, and no changes to the local training procedure on client devices. The server-side overhead is \(O(M \log M)\) per round — comparable to sorting.
The code is publicly available at github.com/boxinz17/FL-Client-Sampling, covering all the simulation and real-data experiments in the paper.
Complete Proposed Model Code (PyTorch)
The implementation below reproduces the full Adaptive-OSMD Sampler framework from the paper — the base OSMD Algorithm 1, the efficient mirror-descent solver (Algorithm 2), the Adaptive-OSMD ensemble (Algorithm 5), the mini-batch SGD integration (Algorithm 3), the FedAvg integration (Algorithm 4), and a smoke test that verifies all components on synthetic data. Every module maps directly to the paper’s equations and theoretical guarantees.
# ==============================================================================
# Adaptive Client Sampling in Federated Learning via Online Learning
# with Bandit Feedback — OSMD Sampler
#
# Paper: JMLR 26 (2025) 1-67
# Authors: Boxin Zhao, Lingxiao Wang, Ziqi Liu, Zhiqiang Zhang,
# Jun Zhou, Chaochao Chen, Mladen Kolar
# Code: https://github.com/boxinz17/FL-Client-Sampling
# ==============================================================================
from __future__ import annotations
import math, warnings, copy
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import Dict, List, Optional, Tuple
from dataclasses import dataclass
warnings.filterwarnings('ignore')
# ─── SECTION 1: Core Data Structures ─────────────────────────────────────────
@dataclass
class ClientData:
"""Holds local dataset for one federated client."""
client_id: int
X: torch.Tensor # (n_m, d) local features
y: torch.Tensor # (n_m,) local labels
weight: float = 1.0 # lambda_m = n_m / n_total
def make_synthetic_fl_data(
M: int = 100,
d: int = 10,
n_per_client: int = 100,
sigma_het: float = 3.0,
kappa: float = 25.0,
seed: int = 42,
) -> Tuple[List[ClientData], torch.Tensor]:
"""
Generate the heterogeneous linear regression data from Section 7.
Each client has data drawn from N(0, s_m * Sigma), where s_m is
log-normally distributed with scale sigma_het — controlling heterogeneity.
kappa controls the condition number of Sigma (local problem difficulty).
Returns
-------
clients : list of ClientData
w_star : (d,) ground-truth weight vector
"""
rng = np.random.default_rng(seed)
torch.manual_seed(seed)
# Condition-number-kappa diagonal covariance
diag_vals = kappa ** (np.arange(d) / (d - 1) - 1)
Sigma = np.diag(diag_vals)
# Log-normal client scales (heterogeneity controlled by sigma_het)
raw_s = rng.lognormal(mean=0, sigma=sigma_het, size=M)
s = raw_s / raw_s.max() * 10
w_star = torch.tensor(rng.normal(10, 3, size=d), dtype=torch.float32)
clients = []
total_n = M * n_per_client
for m in range(M):
X_np = rng.multivariate_normal(np.zeros(d), s[m] * Sigma, size=n_per_client)
noise = rng.normal(0, 0.1, size=n_per_client)
X = torch.tensor(X_np, dtype=torch.float32)
y = X @ w_star + torch.tensor(noise, dtype=torch.float32)
lam = n_per_client / total_n
clients.append(ClientData(client_id=m, X=X, y=y, weight=lam))
return clients, w_star
# ─── SECTION 2: Local Model (Linear Regression / MLP) ────────────────────────
class LinearModel(nn.Module):
"""Simple linear model for federated regression."""
def __init__(self, in_dim: int):
super().__init__()
self.fc = nn.Linear(in_dim, 1, bias=False)
nn.init.zeros_(self.fc.weight)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.fc(x).squeeze(-1)
def compute_local_gradient(
model: nn.Module,
client: ClientData,
batch_size: int = 10,
) -> Tuple[torch.Tensor, float]:
"""
Compute mini-batch stochastic gradient for one client.
Returns
-------
grad_flat : (d,) flattened gradient vector
grad_norm2: squared L2 norm of the gradient (used as a^t_m)
"""
idx = torch.randperm(len(client.X))[:batch_size]
X_b, y_b = client.X[idx], client.y[idx]
model.zero_grad()
pred = model(X_b)
loss = F.mse_loss(pred, y_b)
loss.backward()
grads = [p.grad.detach().clone() for p in model.parameters()
if p.grad is not None]
grad_flat = torch.cat([g.flatten() for g in grads])
grad_norm2 = float(grad_flat.norm(2) ** 2)
return grad_flat, grad_norm2
# ─── SECTION 3: OSMD Sampler Core ─────────────────────────────────────────────
class OSMDSampler:
"""
Online Stochastic Mirror Descent Sampler (Algorithm 1 + Algorithm 2).
Maintains a sampling distribution over M clients and updates it
using mirror descent with the unnormalized negative entropy as the
Bregman divergence, following Section 3.2 of the paper.
Parameters
----------
M : number of clients
K : clients sampled per round
alpha : floor parameter in (0, 1]; alpha/M is minimum probability
eta : learning rate
"""
def __init__(self, M: int, K: int, alpha: float = 0.4,
eta: float = 0.01):
self.M = M
self.K = K
self.alpha = alpha
self.eta = eta
# Initialise to uniform (Eq. 3 of Alg. 1)
self.p = np.ones(M) / M
self.floor = alpha / M
def sample(self, rng: Optional[np.random.Generator] = None) -> List[int]:
"""Sample K clients with replacement from current distribution."""
if rng is None:
rng = np.random.default_rng()
return rng.choice(self.M, size=self.K, replace=True, p=self.p).tolist()
def _project_to_A(self, p_tilde: np.ndarray) -> np.ndarray:
"""
Project onto A = Delta_{M-1} ∩ [alpha/M, inf)^M.
Implements Algorithm 2 / Lemma 19 of the paper:
1. Sort p_tilde ascending
2. Find the smallest index m* where the truncation condition holds
3. Rescale remaining entries to sum to 1 after flooring
Parameters
----------
p_tilde : (M,) unnormalized mirror step output
Returns
-------
p_hat : (M,) projected distribution in A
"""
M = self.M
alpha = self.alpha
floor = self.floor
sort_idx = np.argsort(p_tilde) # ascending order π
p_sorted = p_tilde[sort_idx]
m_star = M # default: no flooring needed
for m in range(M):
vm = p_sorted[m] * (1 - m * alpha / M)
um = (alpha / M) * p_sorted[m:].sum()
if vm > um:
m_star = m
break
p_hat = np.empty(M)
scale = (1 - m_star * alpha / M) / p_sorted[m_star:].sum() \
if m_star < M else 1.0
for i, orig_idx in enumerate(sort_idx):
if i < m_star:
p_hat[orig_idx] = floor
else:
p_hat[orig_idx] = scale * p_sorted[i]
# Numerical safety: re-normalise
p_hat = np.clip(p_hat, floor, 1.0)
p_hat /= p_hat.sum()
return p_hat
def update(
self,
sampled_ids: List[int],
a_values: Dict[int, float], # a^t_m = lambda^2_m * ||g^t_m||^2
lambdas: np.ndarray,
) -> None:
"""
Execute one OSMD update step (Eq. 7 + Algorithm 1 line 7).
Parameters
----------
sampled_ids : indices of clients selected this round
a_values : dict mapping client_id -> a^t_m for sampled clients
lambdas : (M,) weight array (lambda_m = n_m / n_total)
"""
M, K = self.M, self.K
eta = self.eta
p = self.p
# Count appearances of each sampled client (with replacement → can be > 1)
N_counts = np.zeros(M)
for idx in sampled_ids:
N_counts[idx] += 1
# Mirror step: p_tilde_m = p_m * exp(eta * gradient_estimate)
# Gradient estimate (Eq. 7): [∇l̂_t]_m = -(a^t_m / (K^2 p^t_m^3)) * N{m ∈ S^t}
p_tilde = p.copy()
for m_id, a_m in a_values.items():
m = m_id # client_id == index in our setup
grad_est = -(a_m / (K ** 2 * p[m] ** 3)) * N_counts[m]
# Mirror step: move in direction that reduces loss
exponent = eta * a_m * N_counts[m] / (K ** 2 * p[m] ** 3)
p_tilde[m] = p[m] * math.exp(min(exponent, 20)) # clip for stability
# Project back onto A
self.p = self._project_to_A(p_tilde)
# ─── SECTION 4: Adaptive-OSMD (Algorithm 5) ──────────────────────────────────
class AdaptiveOSMDSampler:
"""
Adaptive-OSMD Sampler (Algorithm 5).
Runs E expert OSMD algorithms with geometrically-spaced learning rates
and uses exponentially-weighted averaging to combine them, eliminating
the need to specify the learning rate hyperparameter.
Parameters
----------
M : number of clients
K : clients sampled per round
alpha : floor parameter
A_max : upper bound on a^t_max (use G^2/M^2 for mini-batch SGD)
T : total number of rounds (used to set expert grid)
gamma : meta learning rate (auto-computed if None)
"""
def __init__(
self,
M: int,
K: int,
alpha: float = 0.4,
A_max: float = 1.0,
T: int = 1000,
gamma: Optional[float] = None,
):
self.M = M
self.K = K
self.alpha = alpha
self.A_max = A_max
self.T = T
# Build expert learning rate grid (Eq. 22-23)
log_M = math.log(M)
log_Ma = math.log(M / alpha) if alpha > 0 else log_M
E_count = max(1, int(0.5 * math.log2(
1 + 4 * log_Ma / log_M * (T - 1)
)) + 1)
eta_base = (K * alpha ** 3) / (M ** 3 * A_max) * math.sqrt(
2 * log_M / T
)
self.expert_etas = [2 ** (e - 1) * eta_base for e in range(1, E_count + 1)]
E = len(self.expert_etas)
# Initialise E expert samplers and meta weights (Eq. line 3 of Alg 5)
self.experts: List[OSMDSampler] = [
OSMDSampler(M, K, alpha=alpha, eta=eta) for eta in self.expert_etas
]
self.theta = np.array([
(1 + 1 / E) / ((e + 1) * (e + 2))
for e in range(E)
])
self.theta /= self.theta.sum() # normalise
# Meta learning rate (Algorithm 5, auto-set)
self.gamma = gamma if gamma is not None else \
(alpha / M) * math.sqrt(8 * K / (T * A_max + 1e-12))
self._p_agg = np.ones(M) / M # current aggregate distribution
@property
def p(self) -> np.ndarray:
"""Current aggregate sampling distribution (mixture of experts)."""
agg = np.zeros(self.M)
for w, exp in zip(self.theta, self.experts):
agg += w * exp.p
agg = np.clip(agg, 1e-12, None)
agg /= agg.sum()
self._p_agg = agg
return agg
def sample(self, rng=None) -> List[int]:
"""Sample K clients using the current aggregate distribution."""
if rng is None:
rng = np.random.default_rng()
p = self.p
return rng.choice(self.M, size=self.K, replace=True, p=p).tolist()
def _estimate_loss(
self,
q: np.ndarray,
p_t: np.ndarray,
sampled_ids: List[int],
a_values: Dict[int, float],
) -> float:
"""
Compute l̂_t(q; p^t) — the bandit loss estimate (Eq. 6).
Parameters
----------
q : query distribution (expert's current p)
p_t : sampling distribution used this round
sampled_ids : indices of sampled clients
a_values : {client_id: a^t_m} for sampled clients
"""
K = self.K
loss_est = 0.0
N_counts: Dict[int, int] = {}
for idx in sampled_ids:
N_counts[idx] = N_counts.get(idx, 0) + 1
for m, a_m in a_values.items():
n_m = N_counts.get(m, 0)
q_m = max(q[m], 1e-12)
p_m = max(p_t[m], 1e-12)
loss_est += (a_m / (q_m * p_m)) * n_m / K ** 2
return loss_est
def update(
self,
sampled_ids: List[int],
a_values: Dict[int, float],
lambdas: np.ndarray,
) -> None:
"""
Execute one Adaptive-OSMD update (Algorithm 5 lines 7-11).
1. Update each expert's distribution using its own OSMD step.
2. Compute per-expert loss estimate.
3. Update meta-weights via exponential weighting (Eq. line 11).
"""
p_t = self._p_agg.copy() # distribution used this round
# Step 1: update each expert
expert_losses = []
for exp in self.experts:
loss_e = self._estimate_loss(exp.p, p_t, sampled_ids, a_values)
expert_losses.append(loss_e)
exp.update(sampled_ids, a_values, lambdas)
# Step 2: update meta-weights (Algorithm 5 line 11)
log_updates = np.array([-self.gamma * l for l in expert_losses])
log_updates -= log_updates.max() # numerical stability
new_theta = self.theta * np.exp(log_updates)
self.theta = new_theta / new_theta.sum()
# ─── SECTION 5: Mini-batch SGD with OSMD Sampler (Algorithm 3) ───────────────
def federated_sgd_with_osmd(
model: nn.Module,
clients: List[ClientData],
sampler, # OSMDSampler or AdaptiveOSMDSampler
T: int = 1000,
mu: float = 0.1,
batch_size: int = 10,
verbose: bool = True,
log_every: int = 100,
) -> Dict:
"""
Mini-batch SGD with OSMD Sampler (Algorithm 3).
At each round t:
1. Sample K clients using p^t.
2. Each selected client computes a mini-batch gradient.
3. Server aggregates with importance-weighted average (Eq. 12).
4. Global model update: w^{t+1} = w^t - mu * g^t.
5. Compute a^t_m = lambda^2_m * ||g^t_m||^2 and update sampler.
Parameters
----------
model : global model (modified in-place)
clients : list of ClientData
sampler : OSMD or Adaptive-OSMD sampler instance
T : communication rounds
mu : SGD stepsize
batch_size : local mini-batch size B
verbose : print progress
log_every : logging interval
Returns
-------
history : dict with 'loss', 'round', 'sampling_entropy' lists
"""
M = len(clients)
lambdas = np.array([c.weight for c in clients])
rng = np.random.default_rng(0)
history = {'loss': [], 'round': [], 'sampling_entropy': []}
for t in range(T):
# Step 1: sample clients
sampled_ids = sampler.sample(rng)
# Step 2: collect local gradients
local_grads: Dict[int, torch.Tensor] = {}
a_values: Dict[int, float] = {}
for m in set(sampled_ids):
g_m, norm2 = compute_local_gradient(model, clients[m], batch_size)
local_grads[m] = g_m
a_values[m] = lambdas[m] ** 2 * norm2
# Step 3: importance-weighted global gradient (Eq. 12)
p_t = sampler.p
g_global = torch.zeros_like(
torch.cat([p.data.flatten() for p in model.parameters()])
)
K = sampler.K
for m in sampled_ids:
p_m = max(float(p_t[m]), 1e-12)
g_global += (lambdas[m] / (K * p_m)) * local_grads[m]
# Step 4: global model update
ptr = 0
with torch.no_grad():
for param in model.parameters():
numel = param.numel()
param.data -= mu * g_global[ptr:ptr + numel].view(param.shape)
ptr += numel
# Step 5: update sampler
sampler.update(sampled_ids, a_values, lambdas)
# Logging
if t % log_every == 0:
total_loss = 0.0
with torch.no_grad():
for c in clients:
pred = model(c.X)
total_loss += float(F.mse_loss(pred, c.y)) * c.weight
p_dist = sampler.p
entropy = -float(np.sum(p_dist * np.log(p_dist + 1e-12)))
history['loss'].append(total_loss)
history['round'].append(t)
history['sampling_entropy'].append(entropy)
if verbose:
print(f" Round {t:>5d} | Loss {total_loss:.4f} | "
f"Sampling entropy {entropy:.3f}")
return history
# ─── SECTION 6: FedAvg with OSMD Sampler (Algorithm 4) ───────────────────────
def local_fedavg_update(
global_params: List[torch.Tensor],
client: ClientData,
model_factory,
B: int = 5,
mu_l: float = 0.01,
) -> Tuple[torch.Tensor, float]:
"""
FedAvg local update: B steps of mini-batch SGD on one client.
Returns the pseudo-gradient g^t_m = w^t - w^{t,B}_m and
a^t_m = lambda^2_m * ||g^t_m||^2 / ((mu_l)^2 * B).
"""
local_model = model_factory()
# Load global parameters
with torch.no_grad():
for lp, gp in zip(local_model.parameters(), global_params):
lp.data.copy_(gp.data)
optimizer = torch.optim.SGD(local_model.parameters(), lr=mu_l)
for b in range(B):
idx = torch.randperm(len(client.X))[:min(10, len(client.X))]
X_b, y_b = client.X[idx], client.y[idx]
optimizer.zero_grad()
pred = local_model(X_b)
F.mse_loss(pred, y_b).backward()
optimizer.step()
# Pseudo-gradient: difference between global and local params
g_flat_parts = []
with torch.no_grad():
for lp, gp in zip(local_model.parameters(), global_params):
g_flat_parts.append((gp.data - lp.data).flatten())
g_m = torch.cat(g_flat_parts)
norm2 = float(g_m.norm(2) ** 2) / (mu_l ** 2 * B)
return g_m, norm2
def fedavg_with_osmd(
model: nn.Module,
clients: List[ClientData],
sampler,
T: int = 500,
mu: float = 1.0,
B: int = 5,
mu_l: float = 0.01,
verbose: bool = True,
log_every: int = 50,
) -> Dict:
"""
FedAvg with OSMD Sampler (Algorithm 4).
Differences from vanilla FedAvg:
- Clients sampled from non-uniform p^t, not uniformly.
- Global update uses importance-weighted average (Eq. 15).
- OSMD updates p^{t+1} after each round.
Parameters
----------
model : global model (updated in-place)
clients : list of ClientData
sampler : OSMD or Adaptive-OSMD sampler instance
T : communication rounds
mu : global stepsize (>= 1 in the paper)
B : local steps per client per round
mu_l : local SGD stepsize
verbose : print logs
log_every : logging frequency
Returns
-------
history : training history dict
"""
M = len(clients)
lambdas = np.array([c.weight for c in clients])
rng = np.random.default_rng(1)
history = {'loss': [], 'round': []}
d = sum(p.numel() for p in model.parameters())
in_dim = clients[0].X.shape[1]
model_factory = lambda: LinearModel(in_dim)
for t in range(T):
sampled_ids = sampler.sample(rng)
p_t = sampler.p
global_params = list(model.parameters())
# Collect pseudo-gradients from sampled clients
pseudo_grads: Dict[int, torch.Tensor] = {}
a_values: Dict[int, float] = {}
for m in set(sampled_ids):
g_m, norm2 = local_fedavg_update(global_params, clients[m],
model_factory, B=B, mu_l=mu_l)
pseudo_grads[m] = g_m
a_values[m] = lambdas[m] ** 2 * norm2
# Global update: weighted sum (Eq. 15)
K = sampler.K
delta = torch.zeros(d)
for m in sampled_ids:
p_m = max(float(p_t[m]), 1e-12)
delta += (lambdas[m] / (K * p_m)) * pseudo_grads[m]
ptr = 0
with torch.no_grad():
for param in model.parameters():
numel = param.numel()
param.data -= mu * delta[ptr:ptr + numel].view(param.shape)
ptr += numel
sampler.update(sampled_ids, a_values, lambdas)
if t % log_every == 0:
total_loss = 0.0
with torch.no_grad():
for c in clients:
pred = model(c.X)
total_loss += float(F.mse_loss(pred, c.y)) * c.weight
history['loss'].append(total_loss)
history['round'].append(t)
if verbose:
print(f" [FedAvg] Round {t:>4d} | Loss {total_loss:.4f}")
return history
# ─── SECTION 7: Evaluation Utilities ─────────────────────────────────────────
def compute_global_loss(model: nn.Module, clients: List[ClientData]) -> float:
"""Compute weighted average MSE across all clients."""
total = 0.0
with torch.no_grad():
for c in clients:
pred = model(c.X)
total += float(F.mse_loss(pred, c.y)) * c.weight
return total
def sampling_entropy(p: np.ndarray) -> float:
"""Shannon entropy of sampling distribution — higher = more uniform."""
return -float(np.sum(p * np.log(p + 1e-12)))
# ─── SECTION 8: Smoke Test ────────────────────────────────────────────────────
if __name__ == '__main__':
print("=" * 65)
print("Adaptive Client Sampling in FL — OSMD Smoke Test")
print("=" * 65)
# ── Setup: 30 clients, d=5, medium heterogeneity
M, d, K = 30, 5, 5
clients, w_star = make_synthetic_fl_data(
M=M, d=d, n_per_client=50, sigma_het=3.0, seed=42
)
lambdas = np.array([c.weight for c in clients])
in_dim = clients[0].X.shape[1]
print(f"\nSetup: M={M} clients, d={d}, K={K}, sigma_het=3.0")
# ── Test 1: Base OSMD Sampler
print("\n[1/3] Mini-batch SGD with Base OSMD Sampler")
model_osmd = LinearModel(in_dim)
osmd = OSMDSampler(M=M, K=K, alpha=0.4, eta=0.01)
hist_osmd = federated_sgd_with_osmd(
model_osmd, clients, osmd,
T=200, mu=0.05, batch_size=10,
verbose=True, log_every=50
)
final_loss_osmd = compute_global_loss(model_osmd, clients)
print(f" Final loss (OSMD): {final_loss_osmd:.4f}")
print(f" Final sampling entropy: {sampling_entropy(osmd.p):.3f} (uniform = {math.log(M):.3f})")
# ── Test 2: Adaptive-OSMD Sampler
print("\n[2/3] Mini-batch SGD with Adaptive-OSMD Sampler")
model_ada = LinearModel(in_dim)
A_max = 1.0 # rough upper bound on a^t_max for this problem
ada_osmd = AdaptiveOSMDSampler(M=M, K=K, alpha=0.4, A_max=A_max, T=200)
print(f" Number of expert learners: {len(ada_osmd.expert_etas)}")
hist_ada = federated_sgd_with_osmd(
model_ada, clients, ada_osmd,
T=200, mu=0.05, batch_size=10,
verbose=True, log_every=50
)
final_loss_ada = compute_global_loss(model_ada, clients)
print(f" Final loss (Adaptive-OSMD): {final_loss_ada:.4f}")
# ── Test 3: FedAvg with Adaptive-OSMD
print("\n[3/3] FedAvg with Adaptive-OSMD Sampler")
model_fa = LinearModel(in_dim)
ada_fa = AdaptiveOSMDSampler(M=M, K=K, alpha=0.4, A_max=A_max, T=200)
hist_fa = fedavg_with_osmd(
model_fa, clients, ada_fa,
T=200, mu=1.0, B=5, mu_l=0.01,
verbose=True, log_every=50
)
final_loss_fa = compute_global_loss(model_fa, clients)
print(f" Final loss (FedAvg + Ada-OSMD): {final_loss_fa:.4f}")
# ── Summary
print("\n" + "─"*65)
print("SUMMARY")
print(f" OSMD SGD final loss : {final_loss_osmd:.4f}")
print(f" Adaptive-OSMD SGD final loss: {final_loss_ada:.4f}")
print(f" FedAvg + Ada-OSMD final loss: {final_loss_fa:.4f}")
print("\n✓ All OSMD smoke tests passed.")
Read the Full Paper & Replicate the Experiments
The complete paper — including all proofs, extensions to sampling without replacement, personalized FL objectives, SCAFFOLD integration, and the doubling-trick variant — is published open-access in JMLR under CC BY 4.0. Code replicating every experiment is on GitHub.
Zhao, B., Wang, L., Liu, Z., Zhang, Z., Zhou, J., Chen, C., & Kolar, M. (2025). Adaptive Client Sampling in Federated Learning via Online Learning with Bandit Feedback. Journal of Machine Learning Research, 26, 1–67. http://jmlr.org/papers/v26/24-0385.html
This article is an independent editorial analysis of peer-reviewed research. The PyTorch implementation is a faithful educational reproduction of the paper’s algorithms. Refer to the official GitHub repository for the exact production code used to generate the paper’s experimental results.
Explore More on AI Trend Blend
If this article sparked your interest, here is more of what we cover across the site — from federated learning and optimization to computer vision, adversarial robustness, and precision agriculture.