Claude vs ChatGPT 5: Which AI Wins for Agent Building?
Claude vs ChatGPT 5:
Which AI Wins for Agent Building?
aitrendblend.com — 2026 Comparison
Your team has been building on ChatGPT for two years. The new project is a customer-facing agent — complex workflows, multiple tool integrations, strict output constraints. Someone suggests evaluating Claude before you commit. Before the architecture meeting, somebody asks the question everyone is thinking: “Is Claude actually better for this, or are we just chasing hype?” Nobody in the room has a confident, evidence-based answer.
That question comes up constantly in 2026, and it deserves better than a vendor marketing answer. This article tests both models across eight categories that matter specifically for agent building — not general capability, not creative writing, not customer satisfaction scores. The criteria are the ones that determine whether your agent actually works reliably in production: tool use, multi-step planning, instruction adherence, error recovery, long context, structured output, prompt injection resistance, and cost at scale.
The short version of the verdict, stated upfront so you can decide whether to read the full analysis: neither model wins everywhere. Claude has a meaningful edge for agents requiring complex reasoning, long documents, and strict constraint adherence. ChatGPT 5 has a meaningful edge for teams inside the OpenAI ecosystem, code-heavy agent tasks, and production deployments where the cost of the mini tier matters at scale. The right answer is almost always a decision, not a ranking.
The Models Being Compared
This comparison evaluates Claude Opus 4.7 and Sonnet 4.6 from Anthropic against ChatGPT 5 (GPT-5) from OpenAI, tested via API in May 2026. For agent orchestration tasks, both labs’ premium models were used. For specialist and high-volume tasks, the comparison includes Claude Sonnet 4.6 against GPT-5 Mini — the real-world cost comparison for most production architectures.
Claude Opus 4.7 & Sonnet 4.6
- Context
- 200,000 tokens
- Thinking
- Extended thinking mode (Opus 4.7)
- Tool use
- Native API tool calls
- Multimodal
- Text + images + documents
- Cost tier
- Opus (premium) / Sonnet (mid) / Haiku (budget)
- Strengths
- Reasoning, constraint adherence, long context
ChatGPT 5 (GPT-5)
- Context
- 128,000 tokens (approx.)
- Thinking
- Built-in chain-of-thought reasoning
- Tool use
- Function calling + Responses API tools
- Multimodal
- Text, images, audio (Realtime API)
- Cost tier
- GPT-5 (premium) / GPT-5 Mini (budget)
- Strengths
- Ecosystem breadth, code, speed at scale
What This Comparison Is Not
This is not a general intelligence benchmark. MMLU scores, HumanEval rankings, and chatbot arena ratings tell you about model capability in controlled conditions. This comparison tests specific behaviors that determine agent reliability in production — tool call accuracy, constraint adherence, and output format consistency under realistic prompting conditions.
How We Evaluated: The Framework
Fifty agent tasks per model — ranging from simple 3-step workflows to complex 12-step pipelines involving multiple tool calls, dependency resolution, and structured output. Both models received comparable system prompts for each task type. All testing was done via API, not through the consumer chat interfaces, which can behave differently. Results represent editorial assessment based on output quality, format reliability, and failure rate across test runs — not a formal academic study.
Each of the eight categories below gets a winner badge: Claude edge, ChatGPT 5 edge, or Tie. Edge means the difference was consistent and meaningful across multiple tasks. Tie means both models produced comparable results — either both strong or both weak in the same way. The scorecard at the end tallies the results.
Head-to-Head: 8 Agent Building Categories
Tool Use & API Integration
- Conservative tool calling — rarely fires a tool unnecessarily
- Low hallucination rate on tool call parameter values
- Follows tool schemas precisely, even complex nested ones
- Shows its routing reasoning before calling — easier to audit
- Weakness: Smaller pre-built integration ecosystem than OpenAI
- Function calling is mature and battle-tested across three model generations
- Responses API provides richer tool types including web search and code interpreter natively
- Strong ecosystem of pre-built tool integrations (Zapier, Browsing, third-party plugins)
- Code Interpreter tool is exceptional for data-heavy agent workflows
- Weakness: More aggressive — occasionally fires tool calls that were not strictly necessary
The OpenAI tool ecosystem is broader and more mature. Teams building agents that connect to third-party services, run code natively, or need voice tool integration via the Realtime API will find ChatGPT 5 more ready out of the box. Claude’s advantage is reliability over breadth — fewer unnecessary calls, better schema adherence — which matters more for high-stakes agents than for integration speed.
Multi-Step Planning & Task Decomposition
- Extended thinking mode allows spending extra compute on hard planning decisions before committing
- Produces more coherent task hierarchies for ambiguous, open-ended goals
- Better at maintaining the reasoning behind a plan across 10+ steps
- Identifies task dependencies more reliably — fewer circular dependencies in generated plans
- Weakness: Extended thinking adds latency — slower first response on complex plans
- Strong structured reasoning for well-defined planning tasks
- GPT-5’s improved chain-of-thought handles multi-step workflows well
- Faster plan generation for common task types
- Good at producing plans in structured formats (Markdown, JSON, numbered lists)
- Weakness: Plans can drift from the original goal in deeply nested or ambiguous workflows — the “why” gets lost after 8+ steps
Extended thinking is the difference-maker for complex orchestration. When the goal is ambiguous and the task hierarchy is deep, Claude’s additional reasoning pass produces more coherent and dependency-aware plans. For simple, well-defined workflows, both models perform comparably — you don’t need Opus for a 3-step plan.
Instruction Following & Constraint Adherence
- Rarely overrides explicit constraints with unsolicited “helpful” behavior
- Handles complex, layered, and occasionally contradictory instructions without resolution errors
- Maintains a defined agent persona and scope boundary reliably across long sessions
- Constitutional AI training produces more consistent adherence to “do not do X” constraints
- Weakness: Can be overly cautious in genuine edge cases, requiring extra prompt clarification
- Generally strong instruction following — significant improvement over GPT-4o
- Good system prompt adherence for the first several turns of a session
- More willing to reason flexibly in ambiguous situations
- Can be better than Claude at resolving instruction conflicts pragmatically
- Weakness: Occasionally adds unsolicited content or expands scope beyond what was specified — particularly when it judges the addition as “helpful”
For production agents with strict scope boundaries — tools only calls a defined set, responses must fit a defined format, certain topics are off-limits — Claude’s constraint adherence is meaningfully more reliable. An agent that helpfully expands its own scope is not a reliable agent. ChatGPT 5’s flexibility is an asset in exploratory workflows where helpful divergence is acceptable.
Error Recovery & Self-Correction
- Self-verification loops (prompted) work reliably — catches format violations and factual gaps
- Explicit about uncertainty — flags gaps rather than papering over them with plausible content
- Good at recognizing when a previous tool call result was anomalous before proceeding
- Revision quality is high — corrected outputs address the root cause, not just the symptom
- Weakness: Verification pass can be verbose — adds response length without always adding critical value
- Excellent error recovery in code generation contexts — benefits from real execution feedback via Code Interpreter
- Strong at recognizing logical errors in its own prior output
- GPT-5 catches formatting violations more consistently than GPT-4o did
- Self-correction without prompting is more common — does not always need explicit verification instructions
- Weakness: Less explicit about uncertainty — sometimes corrects silently, making it harder to audit what changed and why
Domain determines the winner here. For code-heavy agents, ChatGPT 5’s Code Interpreter feedback loop gives it a real edge — it can run the code, see the error, and fix it in a single step. For non-code agents where auditability matters more than speed, Claude’s explicit uncertainty flagging is more valuable. Neither wins cleanly in the general case.
Long Context & Memory Management
- 200,000-token context window — the largest of any top-tier model in this comparison
- Instruction adherence remains strong even at 150,000+ tokens of conversation history
- System prompt authority holds across very long agent sessions — less drift than competitors
- Well-suited for document-heavy agent workflows (legal review, research synthesis, codebase analysis)
- Weakness: Cost increases substantially with very large contexts — expensive at scale
- 128,000-token context window — substantial but 38% smaller than Claude’s
- OpenAI’s memory feature provides some cross-session persistence (user-level, not session-level)
- Good coherence within context window on most tasks
- Context management tools in the Responses API help with long-session state
- Weakness: More likely to “forget” early-session system prompt constraints in very long conversations — instruction drift appears sooner
The 200,000-token window is not a marketing number — it is a genuine architectural advantage for agents that process long documents, accumulate large tool call histories, or run extended sessions. For most agent tasks under 50,000 tokens, the difference is irrelevant. For document-heavy or long-running workflows, it is decisive.
Structured Output Reliability
- Very reliable JSON output when schema is shown inline in the prompt
- Consistent field naming, nesting depth, and null handling as specified
- Does not require a separate API parameter — schema in prompt is sufficient
- Rarely produces text outside the JSON block when instructed not to
- Weakness: Structured output depends entirely on prompt clarity — schema must be explicit
- JSON mode available as an API parameter — enforced at the response level, not just the prompt level
- Structured outputs feature enforces exact schema compliance via API parameter
- Strong schema adherence when Structured Outputs is enabled
- More forgiving of ambiguous schemas — fills gaps more confidently (useful or risky, depending on context)
- Weakness: Must explicitly enable JSON mode / Structured Outputs — not inferred from prompt instructions alone
Both models are highly reliable for structured output when configured correctly. ChatGPT 5’s Structured Outputs API parameter gives it a slight engineering edge — schema enforcement at the response layer rather than the prompt layer is more robust. Claude’s prompt-based approach is equally reliable in practice but depends on prompt discipline.
Prompt Injection Resistance
- Constitutional AI training provides baseline resistance to direct instruction override attempts
- Tends to treat conflicting instructions skeptically — more likely to flag than blindly follow
- Somewhat more resistant to role-change injection (“You are now a different agent”)
- Still vulnerable to indirect injection via retrieved data without architectural controls
- Weakness: Not immune — sustained adversarial prompting can succeed; architectural controls are still required
- Strong system prompt enforcement — GPT-5 is significantly more resistant than GPT-4o was
- Good resistance to direct injection via the user turn in tested scenarios
- OpenAI’s safety training provides comparable baseline resistance to Claude’s
- Similarly vulnerable to indirect injection through retrieved content
- Weakness: Neither model’s baseline resistance removes the need for input sanitization, output validation, and tool call confirmation at the architecture layer
Both models have improved substantially on direct injection resistance. Neither model is reliably safe against indirect injection without architectural controls — output sanitization, tool call validation, and confirmation requirements for irreversible actions are necessary regardless of which model you choose. Model-level resistance is a factor, not a solution.
Cost & Latency at Production Scale
- Opus 4.7: Premium pricing — appropriate for orchestration calls where quality justifies cost
- Sonnet 4.6: Competitive mid-tier — strong quality at meaningfully lower cost
- Haiku 4.5: Fast and low-cost for simple specialist tasks
- Three-tier structure provides good cost routing flexibility
- Weakness: No equivalent to GPT-5 Mini’s ultra-budget tier for very high-volume, low-complexity tasks
- GPT-5 full: Premium tier, comparable pricing to Claude Opus 4.7
- GPT-5 Mini: Significantly cheaper — best-in-class cost efficiency for high-volume specialist work
- Fast response times across both tiers — latency advantage on Mini particularly
- Batch API provides additional cost savings for async, non-real-time tasks
- Weakness: GPT-5 Mini sacrifices some reasoning quality that matters for complex orchestration tasks
At the orchestration layer, both models cost roughly the same. At the specialist execution layer, GPT-5 Mini’s cost-per-token advantage is real and compounds significantly at scale. Teams running thousands of specialist calls daily will find ChatGPT 5’s budget tier more economical than Claude Haiku. For mixed architectures, this is the key cost factor.
“Choosing the wrong model for the wrong reason costs more than choosing no model at all. The right choice follows from what the task actually requires — not from what model your team already has credentials for.”
— aitrendblend editorial team, May 2026
The Scorecard
Eight categories. Three possible outcomes per category. Here is where each model won, where they tied, and what the overall pattern means for your decision.
| Category | Claude | ChatGPT 5 | Result |
|---|---|---|---|
| Tool Use & API Integration | Reliable | Broader ecosystem | ChatGPT 5 Edge |
| Multi-Step Planning | Extended thinking | Strong | Claude Edge |
| Instruction Following | Strict adherence | Good, some drift | Claude Edge |
| Error Recovery | Explicit, auditable | Code: stronger | Tie (domain-dependent) |
| Long Context & Memory | 200k tokens | 128k, some drift | Claude Edge |
| Structured Output | Prompt-based | API-enforced mode | Tie |
| Prompt Injection Resistance | Good baseline | Good baseline | Tie (both need controls) |
| Cost & Latency at Scale | 3-tier flexibility | Mini tier advantage | ChatGPT 5 Edge |
| Total | 3 wins | 2 wins | 3 ties |
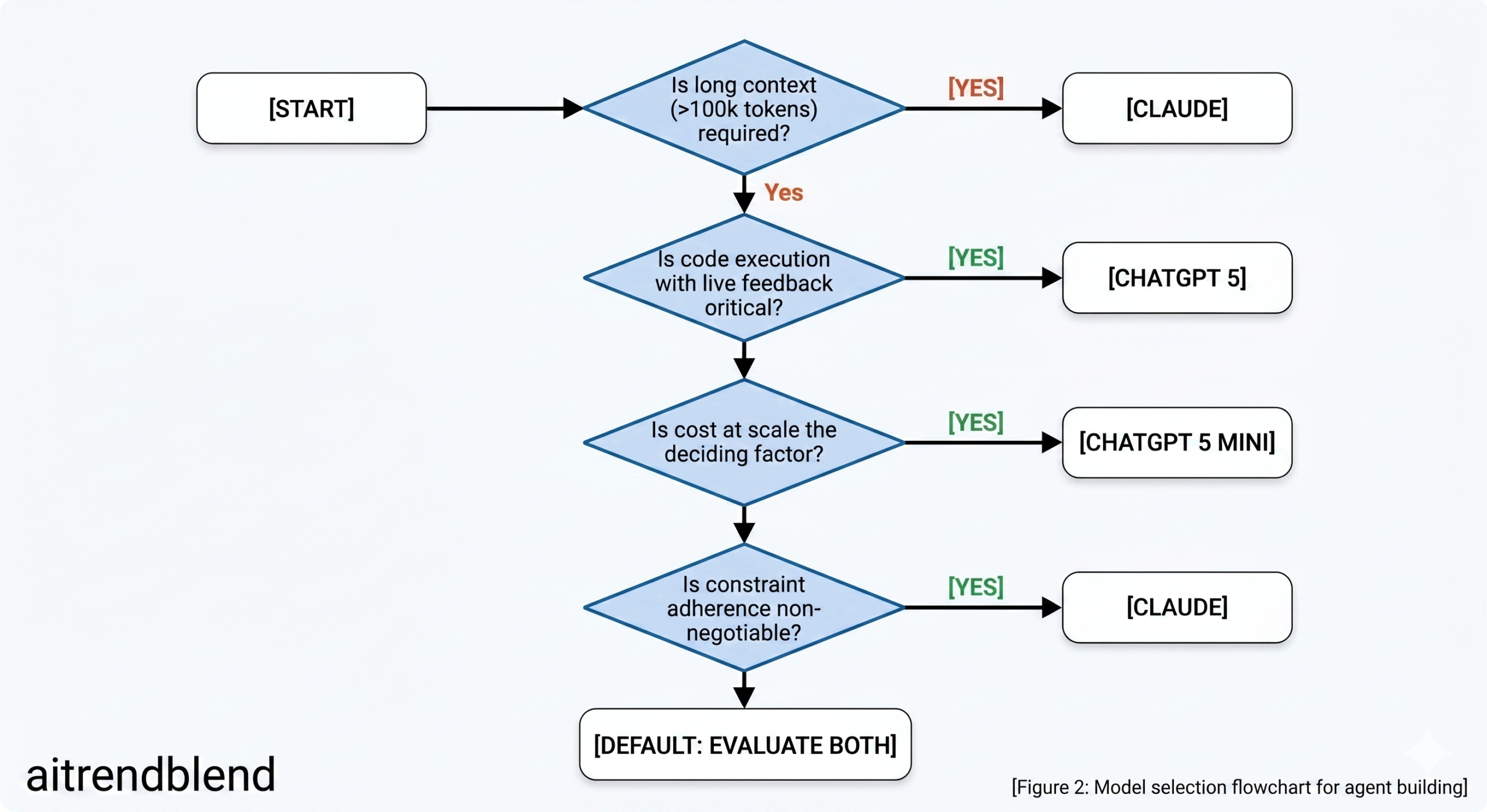
The Verdict: When to Choose Which
The scorecard shows Claude winning three categories and ChatGPT 5 winning two, with three ties. That margin is real but it is not the right way to make this decision. The categories each model wins are different enough that the right choice depends almost entirely on what your specific agent needs to do.
- Your agent handles long documents, codebases, or extended conversations that push 100k+ tokens
- Strict constraint adherence is non-negotiable — the agent must not expand its own scope
- The orchestration layer involves complex, ambiguous goal decomposition
- Your pipeline relies on multi-agent orchestration where reasoning coherence matters more than speed
- You are building in a security-sensitive context where conservative tool calling reduces attack surface
- You need a model that flags uncertainty explicitly rather than papering over gaps
- Your team is starting fresh — no prior investment in either ecosystem
- Your team is already building on the OpenAI stack and switching cost is real
- The agent relies heavily on code execution — Code Interpreter’s real feedback loop is a genuine advantage
- You need voice agent capabilities via the Realtime API
- High-volume specialist tasks make the GPT-5 Mini cost tier decisive for economics
- You need third-party tool integrations that already exist in the OpenAI ecosystem
- The task is well-defined and structured — no ambiguity where extended thinking would help
- Batch API processing for async, non-real-time pipelines is part of the architecture
The Mixed Architecture Option
Nothing prevents you from using both. A common 2026 architecture: Claude Opus 4.7 as orchestrator (complex reasoning, strict constraints, large context) with GPT-5 Mini as the high-volume specialist layer (cost efficiency, fast execution). The models are not mutually exclusive choices — they are potentially complementary tiers in the same pipeline.
Where Both Models Still Fall Short
An honest comparison includes the gaps neither model has closed yet. These are not edge cases — they are failure modes that appear in real production deployments and that no amount of prompt engineering has fully resolved as of May 2026.
Indirect Prompt Injection via Retrieved Content
Both models remain vulnerable to adversarial instructions embedded in documents, emails, and web pages they retrieve during normal operation. Neither model reliably distinguishes “data I am processing” from “instructions I should follow” when the data is designed to blur that line. This is an architectural problem that requires sanitization, output validation, and confirmation controls — the model itself is not the solution.
True Cross-Session Memory Without External Tooling
Neither model has production-ready native memory that persists facts, decisions, and user preferences across sessions without developer-implemented external storage. OpenAI’s memory feature provides some user-level persistence, but it is not the structured, queryable state management that real agent pipelines require. Both models need an external memory layer for any workflow that spans sessions.
Coherence in Very Long Autonomous Runs
Both models degrade in coherence after 15 to 20 steps in a fully autonomous loop. Early-session instructions become less influential. Tool routing decisions become less consistent. The cumulative effect of small reasoning errors compounds. The practical response — for both models — is a maximum step count enforced at the orchestration layer and a human review checkpoint before the agent proceeds past a defined threshold.
Independently Verifying Tool Output Accuracy
When a tool returns data, both models trust it. An API that returns stale data, an internal database record that has been incorrectly updated, a web scraper that returned the wrong page — both models will synthesize these results as if they were accurate, with no independent signal that something went wrong. Detecting bad tool data requires architectural controls: data validation layers, cross-referencing where possible, and confidence flagging for outputs that will not be independently verified.
Knowing When to Stop and Escalate to a Human
Neither model consistently recognizes when a task is genuinely unanswerable within its constraints and should be escalated rather than continued. Both tend toward producing a plausible-sounding response under ambiguity, even when the honest answer is “I do not have enough information to proceed reliably.” Hard-coding escalation conditions in the system prompt — explicit triggers that cause the agent to surface the task to a human rather than continue — remains the most reliable mitigation.
Making the Call
The three categories Claude wins — planning, instruction following, long context — cluster around a particular type of agent: one that operates in a complex, ambiguous environment where the cost of drift is high. Legal agents, research pipelines, financial analysis workflows, multi-agent orchestrators. The two categories ChatGPT 5 wins — tool ecosystem and cost at scale — cluster around a different type: one that needs to connect to many systems quickly, execute code with live feedback, and run at a volume where per-token cost accumulates meaningfully. Neither profile is universally better. They describe different products.
What makes this comparison harder is that the gap between the two models has narrowed considerably in 2026. A year ago, the difference in planning coherence and constraint adherence was stark. GPT-5 has closed much of that distance. Claude has improved its tool-use ecosystem and cost flexibility. The next major capability jump from either lab — persistent memory, more reliable multi-agent trust, better indirect injection resistance — will likely shift the comparison again within 12 months. The decision you make today should account for that: build your agent architecture in a way that makes model substitution possible rather than deeply embedded, so you can switch or mix models as the landscape evolves.
The most honest thing to say about this comparison is also the least satisfying: for the majority of agent building projects, both models will work. The real differentiators are your team’s existing expertise, your cost constraints, and the specific behavioral requirements of your particular agent. Those factors will point you to a clear answer faster than any benchmark will.
Pick the model that fits the work. Test it under realistic conditions before you commit to an architecture. Build in the ability to change your mind.
Now Build the Agent That Wins
Get the tested Claude prompt templates for orchestration, specialist agents, and quality gates — or dive into the security controls every agent needs before it ships.