NeuralBoneReg Solved the Hardest Alignment Problem in Robotic Surgery Without a Single Labeled Training Example
A team from Balgrist University Hospital and ETH Zurich built an instance-specific self-supervised framework that registers bone surfaces across imaging modalities by learning a continuous neural distance field from the preoperative scan and using thousands of neural hypothesis generation heads to find the correct alignment intraoperatively, all without ever requiring paired ground-truth data.
Every robotic orthopedic surgery begins with a plan drawn up from a CT scan taken days before the patient enters the operating room. By the time the surgeon makes the first incision, the patient has moved, been repositioned, and had their anatomy altered by anesthesia and gravity. The robot has no idea where the planned bone actually is. Closing that gap between the preoperative plan and the intraoperative reality is called registration, and it is one of the most consequential and difficult technical problems in computer-assisted surgery. Get it wrong by even a few millimeters and the implant lands in the wrong place, the screw misses the pedicle, or the resection margin cuts too close. Luohong Wu, Matthias Seibold, and colleagues from Balgrist University Hospital and ETH Zurich just published a framework that approaches this problem in a fundamentally different way than anything that came before it, and the results across three separate datasets covering five different bone anatomies suggest it works.
Why Registration Across Imaging Modalities Is So Hard
The registration challenge in computer-assisted orthopedic surgery has two distinct layers. The first is the obvious one. Preoperative imaging uses CT or MRI, while intraoperative imaging uses ultrasound, X-ray, or RGB-D cameras. These modalities produce information that looks nothing alike. A CT scan of a femur shows dense bone as bright against soft tissue background. An ultrasound scan of the same femur shows a noisy, shadow-heavy surface with specular reflections and dropout artifacts. Trying to align these two images by comparing their pixel intensities directly is like trying to match a photograph of a house to an architect’s blueprint by looking for matching color patches. The information is there, but it is encoded completely differently.
The standard approach to handling this modality gap is surface-based registration. Instead of comparing raw image intensities, both the preoperative and intraoperative data are converted into three-dimensional point clouds representing the bone surface geometry. The bone surface is modality-agnostic information that both CT and ultrasound can provide, so aligning point clouds sidesteps the modality mismatch problem. In theory this is elegant. In practice it creates a new set of problems.
Bone surfaces are often nearly symmetric. A vertebra looks roughly the same viewed from four different rotations. A femoral head is close to spherical. The fibula has a long cylindrical shaft that looks almost identical regardless of which end you are looking at. This symmetry means the alignment landscape has many nearly equivalent solutions. A registration algorithm that starts from a random initialization will find a local minimum quickly, but that local minimum might be 90 degrees off from the correct answer. The intraoperative point cloud is also partial and noisy. Ultrasound cannot see bone through soft tissue at depth, so only the surface facing the probe is visible. Tracking errors and segmentation artifacts add noise to every point. The result is a registration problem that is simultaneously underspecified by geometry, corrupted by noise, and extremely sensitive to initialization.
The most powerful recent approaches to this problem are supervised deep learning methods that learn to match point cloud features from large paired datasets. But there is a fundamental obstacle here. Paired datasets of preoperative CT and intraoperative ultrasound with known ground-truth transformations are extraordinarily difficult to collect. You need ex-vivo specimens, tracked ultrasound probes, calibrated coordinate systems, and ethical approval for each anatomy. The existing public datasets cover only the lower extremity and the lumbar spine. Any new anatomy requires a new data collection campaign before supervised methods can even be trained. This data scarcity bottleneck is what motivates the instance-specific self-supervised approach that NeuralBoneReg takes.
Traditional optimization methods fail on symmetric bone anatomy because they converge to wrong local minima. Supervised learning methods require large paired datasets that do not exist for most anatomies. NeuralBoneReg addresses both by learning a smooth continuous distance field from the preoperative scan and using thousands of parallel neural hypothesis generation heads to escape local minima at inference time, all without requiring any paired training data across subjects.
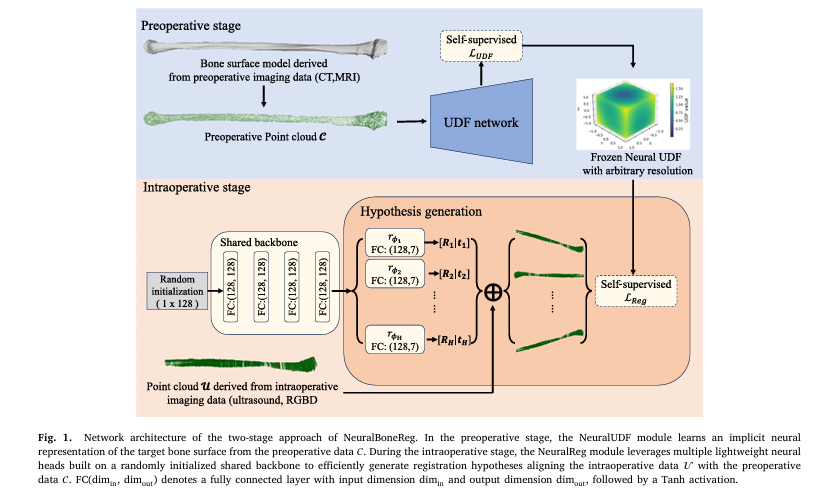
The Two-Stage Design of NeuralBoneReg
NeuralBoneReg is structured around the natural two-stage workflow of computer-assisted surgery. There is a preoperative stage where plans are made and computations can take as long as needed, and an intraoperative stage where time directly affects patient safety and surgical costs. The framework puts its heaviest computation in the preoperative stage and keeps the intraoperative computation fast.
NeuralUDF: Learning the Preoperative Bone Surface
The first module, NeuralUDF, takes the segmented bone surface from the preoperative CT scan and learns a neural unsigned distance field from it. An unsigned distance field is a function that takes any three-dimensional point in space and returns that point’s distance to the nearest point on the bone surface. The key word is unsigned. Unlike signed distance fields used in some shape representations, this function does not distinguish between inside and outside the bone, which matters because ultrasound-derived point clouds are noisy surface samples that do not have reliable interior structure.
The neural representation is learned by a multilayer perceptron trained entirely on the preoperative point cloud for a single patient instance. No data from other patients is used. The MLP learns to predict the distance from any query point to the bone surface by minimizing a loss that enforces tangent-plane consistency and a coarse global-shape regularizer. After training, the network is frozen and provides a smooth, differentiable mapping from any spatial query to its distance from the bone.
Why go through the trouble of learning a neural function when you could just store the preoperative point cloud and look up distances by nearest-neighbor search? There are two compelling reasons. First, nearest-neighbor search is not differentiable, which means you cannot compute gradients through it and cannot use gradient-based optimization to align an intraoperative point cloud against it. Second, fixed-resolution distance volumes stored on a voxel grid are limited by their resolution. A pelvis is roughly eight times larger than a vertebra in each linear dimension, which means a fixed-resolution volume that captures vertebral detail at reasonable memory cost will completely miss fine surface features of the pelvis. The neural representation has no fixed resolution. It learns a continuous function that can be queried at arbitrary precision and scales gracefully to large anatomies without exploding memory requirements.
NeuralReg: Parallel Hypothesis Generation at Inference
The second module, NeuralReg, handles the intraoperative registration. Its central design insight is borrowed from Mixture Density Networks, a technique from the 1990s that models multiple plausible outputs simultaneously rather than committing to a single prediction. Instead of running a single optimization that might converge to a wrong local minimum, NeuralReg maintains thousands of transformation hypotheses in parallel, all being optimized simultaneously under the supervision of the frozen neural distance field.
The architecture consists of a shared MLP backbone and a large number of lightweight hypothesis generation heads, set to 5000 in the final configuration. The shared backbone takes a randomly initialized 128-dimensional latent vector and maps it to a common feature representation that is shared across all heads. Each head then takes this shared feature and outputs a translation vector and a quaternion representing a candidate rigid body transformation. Each transformation hypothesis is evaluated by applying it to the intraoperative point cloud and computing the mean distance of the transformed points within the preoperative neural distance field. The loss that drives optimization is the average of these mean distances across all heads.
The shared backbone is the mechanism that allows the hypotheses to cooperate rather than search independently. When some heads find regions of the rotation space with low distance field values, that information propagates back through the shared backbone and nudges other heads toward more promising regions. The ablation results confirm this strongly. Removing the shared backbone so that each head optimizes independently gives rotation errors of 9.43 degrees on average. Adding even one layer of shared parameters drops this to around 4 degrees, and performance continues to improve with deeper sharing up to about three layers.
The rotation outputs of all heads are initialized by farthest point sampling in SO(3) space, the mathematical space of all possible 3D rotations. This initialization strategy spreads the starting hypotheses across the full rotation sphere rather than clustering them near a single guess, which dramatically improves the chance that at least some hypotheses start near the correct answer. The translation outputs are initialized randomly, which is reasonable because aligning the centroids of the preoperative and intraoperative point clouds provides a good rough estimate of the translation component and the main challenge is the rotation.
A coarse-to-fine evaluation strategy makes the full parallel search computationally practical. In the coarse phase, all 5000 hypotheses are evaluated using only 32 sparse points from the intraoperative cloud, which is fast but noisy. The best 64 hypotheses are then refined using 3000 points for a precise final evaluation. This two-phase approach reduces computation by about 70 percent compared to evaluating all hypotheses at full resolution throughout, with only a small cost in accuracy.
“NeuralBoneReg operates self-supervised at an instance level and does not require large training datasets. Compared with the baselines, it achieves competitive or superior results across all datasets, particularly in limited-data settings.” Wu et al., Medical Image Analysis 2026
Three Datasets Across Five Anatomies
The evaluation is unusually thorough for a paper in this space, covering three datasets with fundamentally different anatomical targets and imaging modalities.
UltraBones100k is the primary CT-ultrasound benchmark, containing 14 human ex-vivo lower extremity specimens with tibia and fibula data collected under realistic clinical setup conditions. The ultrasound recordings are processed through a pretrained segmentation model to extract bone surface point clouds. Because the ultrasound probe and bone are tracked in the same coordinate system during acquisition, the true ground-truth transformation is known, making this a rigorous benchmark rather than a simulated one.
UltraBonesHip is a newly introduced dataset collected specifically for this study, covering the femur and pelvis from 5 ex-vivo specimens. This is the most challenging dataset in the evaluation for two reasons. The hip anatomy is deeper than the tibia and fibula, making ultrasound imaging significantly harder as sound has to travel through more soft tissue before reaching bone. Higher body mass index specimens have thicker soft tissue layers that further degrade image quality. With only 5 specimens, this dataset is also where the data scarcity problem most severely impacts supervised learning methods, making it the critical test of whether NeuralBoneReg’s instance-specific approach generalizes without requiring large datasets.
SpineDepth is a public CT-RGB-D dataset of lumbar vertebrae from 10 ex-vivo subjects. RGB-D cameras provide colored depth images rather than ultrasound, so this dataset tests whether NeuralBoneReg’s modality-agnostic design holds beyond CT-ultrasound pairs. The vertebrae in this dataset are small and geometrically complex structures with significant symmetry, presenting a different kind of alignment challenge than the larger hip anatomy.
Results and Where NeuralBoneReg Pulls Away
The headline performance on UltraBones100k shows NeuralBoneReg achieving a rotation error of 1.83 degrees, a translation error of 2.02 millimeters, and a registration recall of 0.89, where recall counts cases with rotation error below 5 degrees and translation error below 4 millimeters. The pseudo ground truth upper bound, estimated by running ICP from the known correct initialization, sits at 1.40 degrees and 1.09 millimeters. NeuralBoneReg is within about 0.5 degrees and 1 millimeter of this theoretical best performance achievable by any method.
| Method | Dataset | RRE (deg) | RTE (mm) | Recall | CD (mm) |
|---|---|---|---|---|---|
| RANSAC | UltraBones100k | 5.36 ± 20.39 | 3.67 ± 12.24 | 0.74 | 1.09 ± 1.36 |
| PCA | UltraBones100k | 2.18 ± 10.86 | 3.07 ± 7.58 | 0.81 | 0.91 ± 0.21 |
| Predator | UltraBones100k | 1.43 ± 1.12 | 2.36 ± 1.81 | 0.89 | 0.85 ± 0.13 |
| CASTv2 | UltraBones100k | 2.09 ± 1.30 | 1.50 ± 0.89 | 0.91 | 0.87 ± 0.03 |
| NeuralBoneReg | UltraBones100k | 1.83 ± 1.30 | 2.02 ± 1.30 | 0.89 | 0.82 ± 0.12 |
| RANSAC | UltraBonesHip | 15.15 ± 44.84 | 11.18 ± 33.20 | 0.68 | 5.89 ± 17.08 |
| PCA | UltraBonesHip | 63.57 ± 73.58 | 31.36 ± 34.88 | 0.32 | 14.25 ± 15.56 |
| CASTv2 | UltraBonesHip | 4.02 ± 6.17 | 2.56 ± 2.50 | 0.83 | 3.17 ± 1.34 |
| NeuralBoneReg | UltraBonesHip | 1.90 ± 1.56 | 2.21 ± 0.86 | 0.88 | 2.50 ± 1.08 |
| NeuralBoneReg | SpineDepth | 3.78 ± 19.34 | 2.80 ± 3.75 | 0.84 | 1.78 ± 1.61 |
Table. Performance comparison across all three datasets. On UltraBonesHip NeuralBoneReg achieves the best results outright while all supervised baselines degrade severely. RRE is relative rotation error in degrees. RTE is relative translation error in millimeters. Recall counts experiments with RTE below 4mm and RRE below 5 degrees. CD is Chamfer Distance in millimeters.
The real story is the UltraBonesHip results. On this dataset the PCA-based alignment completely collapses to a rotation error of 63.57 degrees and a recall of just 0.32 because the hip anatomy lacks the distinct principal axes that PCA relies on. Predator and GeoTransformer, both state-of-the-art supervised point cloud registration networks, drop to rotation errors above 8 and 16 degrees respectively. Their performance degrades because there are only 5 specimens with 3 anatomical structures each, providing just 15 point cloud pairs for training and validation. That is simply not enough data for methods that need to learn generalizable feature representations across subjects. NeuralBoneReg maintains 1.90 degrees rotation error and 0.88 recall on this dataset, essentially the same performance it achieves on the much larger UltraBones100k dataset. The instance-specific approach does not need cross-subject training data because it trains fresh on each new patient’s preoperative scan.
What the Ablations Tell You About the Design
The ablation studies systematically decompose NeuralBoneReg into its constituent parts and measure what each contributes. The results are unusually informative because the design choices are non-obvious and each comparison is against a meaningful alternative rather than a trivially weaker version.
Replacing the neural distance field with a fixed-resolution 512-cubed voxel grid (GridVolume plus NeuralReg) gives rotation errors of 4.51 degrees on UltraBones100k, 6.67 degrees on UltraBonesHip, and 4.75 degrees on SpineDepth. These are roughly two to three times worse than the full NeuralBoneReg results. The fixed-resolution grid approximates distances through linear interpolation between voxel centers, which introduces discretization artifacts and degrades gradient smoothness. For the pelvis, which spans a much larger spatial volume than a vertebra, the voxel grid either becomes memory-prohibitive at high resolution or loses surface detail at lower resolutions. The neural distance field has no such tradeoff because it is a continuous function that can be queried at arbitrary resolution.
Replacing the neural optimizer with BFGS, a classical quasi-Newton gradient-based optimizer, produces catastrophic failures with rotation errors above 117 degrees on UltraBones100k and 133 degrees on UltraBonesHip. BFGS follows gradients from wherever it starts. On a bone surface registration problem with many symmetric local minima, it reliably converges to the wrong one unless initialized very close to the correct answer. Replacing BFGS with differential evolution, a population-based stochastic optimizer that maintains multiple candidate solutions and avoids some local minima, improves to 17 degrees on UltraBones100k. But the practical population size for differential evolution is limited by memory and computation to around 50 candidates, which is not nearly enough to cover the rotation space thoroughly. NeuralBoneReg can run 5000 to 20000 parallel heads on a single GPU with 24 gigabytes of memory because each head is an extremely lightweight single fully connected layer with tanh activation.
The coarse-to-fine configuration study shows that the choice of how many hypotheses to refine in the fine stage matters significantly. Configurations with zero refinement hypotheses achieve a mean recall of only 0.724 compared to 0.864 for configurations with 128 refinement heads. The final configuration of 5000 total heads, 32 coarse points, and 64 refined heads achieves a recall of 0.886 in about 5.87 seconds on a modern GPU, which the authors identify as the best balance of performance and speed.
Differential evolution with 50 candidates exceeds the runtime of NeuralBoneReg despite using far fewer parallel search points. NeuralBoneReg’s lightweight fully connected heads are orders of magnitude cheaper per hypothesis than maintaining a full differential evolution population with function evaluations. The shared backbone also enables cooperative search where information about promising regions of rotation space propagates across heads, giving coordinated coverage rather than independent random sampling.
Proposed Model Code in PyTorch
The following is a complete PyTorch implementation of NeuralBoneReg covering both stages described in Sections 3.2.1 and 3.2.2 of the paper. It includes the NeuralUDF module with tangent-plane consistency loss, the NeuralReg module with shared MLP backbone and parallel hypothesis generation heads, the coarse-to-fine evaluation strategy, the registration loss function, quaternion-to-rotation-matrix conversion, farthest point sampling initialization in SO(3), and a runnable smoke test demonstrating both the preoperative training stage and the intraoperative registration stage.
# ============================================================
# NeuralBoneReg: Instance-Specific Self-Supervised Multi-Modal
# Bone Surface Registration via Neural Distance Fields
# Paper: Wu et al., Medical Image Analysis 112 (2026) 104133
# Authors: Luohong Wu, Matthias Seibold et al.
# Institution: Balgrist University Hospital / ETH Zurich
# ============================================================
from __future__ import annotations
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import Tuple, Optional
# ─── SECTION 1: Spatial Normalization Utilities ───────────────────────────────
def normalize_point_cloud(pts: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
"""Normalize point cloud to the (-1, 1)^3 cube.
Follows Section 3.1 Equations 2-4 of the paper.
Scale is defined as the diagonal length of the 3D bounding box.
Centroid is subtracted before scale normalization.
Parameters
----------
pts : (N, 3) point cloud in original spatial coordinates
Returns
-------
pts_norm : (N, 3) normalized point cloud
centroid : (3,) centroid of original cloud
scale : scalar bounding box diagonal length
"""
centroid = pts.mean(dim=0) # (3,)
pts_c = pts - centroid
bbox_min = pts_c.min(dim=0).values
bbox_max = pts_c.max(dim=0).values
scale = (bbox_max - bbox_min).pow(2).sum().sqrt() # diagonal length
pts_norm = pts_c / (scale + 1e-8)
return pts_norm, centroid, scale
# ─── SECTION 2: NeuralUDF Module ─────────────────────────────────────────────
class NeuralUDF(nn.Module):
"""Learn a neural Unsigned Distance Field from a preoperative point cloud.
Implements Section 3.2.1 of the paper.
The MLP approximates the unsigned distance of any spatial location
to the underlying bone surface. Training is entirely self-supervised:
no ground-truth distances are required.
Loss combines:
(1) Surface loss: query points sampled ON the bone surface should
have near-zero distance predictions.
(2) Tangent-plane consistency: query points near the surface should
have gradients perpendicular to the local surface normal.
(3) Off-surface loss: random space points should have positive
predicted distances that increase away from the surface.
After training, the frozen UDF provides smooth, differentiable
distance queries d(q) for any 3D point q via forward().
Parameters
----------
hidden_dim : MLP hidden dimension (default 256)
num_layers : number of hidden layers (default 5)
"""
def __init__(self, hidden_dim: int = 256, num_layers: int = 5):
super().__init__()
layers = [nn.Linear(3, hidden_dim), nn.Softplus()]
for _ in range(num_layers - 1):
layers += [nn.Linear(hidden_dim, hidden_dim), nn.Softplus()]
layers.append(nn.Linear(hidden_dim, 1))
layers.append(nn.Softplus()) # ensures non-negative UDF output
self.net = nn.Sequential(*layers)
def forward(self, q: torch.Tensor) -> torch.Tensor:
"""
Parameters
----------
q : (N, 3) query points in normalized space
Returns
-------
d : (N,) predicted unsigned distances to bone surface
"""
return self.net(q).squeeze(-1)
def udf_training_loss(
udf: NeuralUDF,
surface_pts: torch.Tensor,
sigma_near: float = 0.01,
sigma_far: float = 0.5,
n_near: int = 2048,
n_far: int = 512,
) -> torch.Tensor:
"""Self-supervised loss for NeuralUDF training.
Three terms from UltraBoneUDF (Wu et al., 2026), used as the
NeuralUDF module by default.
Surface term: sampled surface points should have distance ≈ 0.
Near-surface term: slightly perturbed points should have low distance
with gradient pointing toward the surface (tangent-plane consistency).
Off-surface term: random points in space should have positive distance.
Parameters
----------
udf : the NeuralUDF model being trained
surface_pts : (M, 3) points sampled from the bone surface
sigma_near : Gaussian noise std for near-surface perturbation
sigma_far : uniform range for random off-surface sampling
n_near : number of near-surface query points
n_far : number of off-surface query points
"""
device = surface_pts.device
M = surface_pts.shape[0]
# --- Term 1: surface loss -----------------------------------------
surface_pts = surface_pts.requires_grad_(True)
d_surface = udf(surface_pts)
loss_surface = d_surface.mean()
# --- Term 2: tangent-plane consistency (near-surface) ---------------
idx = torch.randint(0, M, (n_near,), device=device)
near_pts = surface_pts[idx] + sigma_near * torch.randn(n_near, 3, device=device)
near_pts = near_pts.requires_grad_(True)
d_near = udf(near_pts)
grad_near = torch.autograd.grad(
d_near.sum(), near_pts, create_graph=True
)[0] # (n_near, 3)
# Gradient should be a unit vector -- enforce unit norm for consistency
grad_norm = grad_near.norm(dim=-1, keepdim=True).clamp(min=1e-6)
loss_eikonal = (grad_norm - 1).abs().mean()
# --- Term 3: off-surface repulsion ----------------------------------
far_pts = torch.zeros(n_far, 3, device=device).uniform_(-sigma_far, sigma_far)
d_far = udf(far_pts)
loss_far = F.relu(sigma_far * 0.5 - d_far).mean()
return loss_surface + 0.1 * loss_eikonal + 0.01 * loss_far
# ─── SECTION 3: Quaternion and SO(3) Utilities ───────────────────────────────
def quaternion_to_rotation_matrix(q: torch.Tensor) -> torch.Tensor:
"""Convert unit quaternions to 3x3 rotation matrices.
Parameters
----------
q : (H, 4) unit quaternions in [w, x, y, z] format
Returns
-------
R : (H, 3, 3) rotation matrices in SO(3)
"""
q = F.normalize(q, dim=-1)
w, x, y, z = q[:, 0], q[:, 1], q[:, 2], q[:, 3]
R = torch.stack([
1 - 2*(y*y + z*z), 2*(x*y - w*z), 2*(x*z + w*y),
2*(x*y + w*z), 1 - 2*(x*x + z*z), 2*(y*z - w*x),
2*(x*z - w*y), 2*(y*z + w*x), 1 - 2*(x*x + y*y),
], dim=-1).reshape(-1, 3, 3)
return R
def fps_so3_init(H: int, device: str = 'cpu') -> torch.Tensor:
"""Initialize H rotation hypotheses via farthest point sampling in SO(3).
Spread initial hypotheses across the full rotation sphere to maximize
coverage and increase the likelihood that at least one hypothesis
starts near the correct alignment.
Returns
-------
q : (H, 4) unit quaternions uniformly spread over SO(3)
"""
# Sample random unit quaternions then apply greedy FPS for coverage
pool_size = max(H * 10, 10000)
q_pool = torch.randn(pool_size, 4, device=device)
q_pool = F.normalize(q_pool, dim=-1) # uniform on S^3
selected = [0]
dists = torch.full((pool_size,), float('inf'), device=device)
for _ in range(H - 1):
last = q_pool[selected[-1]].unsqueeze(0)
dot = (q_pool * last).sum(dim=-1).abs().clamp(0, 1)
d = 1 - dot # geodesic-like distance
dists = torch.minimum(dists, d)
selected.append(dists.argmax().item())
return q_pool[selected] # (H, 4)
# ─── SECTION 4: NeuralReg Module ──────────────────────────────────────────────
class NeuralReg(nn.Module):
"""Intraoperative registration via parallel neural hypothesis generation.
Implements Section 3.2.2 of the paper.
Architecture:
Shared backbone f_theta: (128,) -> (128,) shared latent feature
H hypothesis heads r_phi_h: (128,) -> (3,) translation + (4,) quaternion
The shared backbone propagates gradient information across all heads,
enabling cooperative search rather than independent parallel search.
During optimization:
1. All H hypotheses evaluate their mean UDF distance (coarse stage)
2. Top-K hypotheses are refined at higher point cloud density
3. The best hypothesis at inference is selected as final result
Parameters
----------
H : number of hypothesis generation heads (5000 in paper)
latent_dim : backbone input/output dimension (128)
backbone_depth : shared MLP depth in [0..6], 0 = no sharing
"""
def __init__(self, H: int = 5000, latent_dim: int = 128,
backbone_depth: int = 4):
super().__init__()
self.H = H
self.latent_dim = latent_dim
# Shared backbone: maps latent code to shared feature
backbone_layers = []
for _ in range(backbone_depth):
backbone_layers += [nn.Linear(latent_dim, latent_dim), nn.Tanh()]
self.backbone = nn.Sequential(*backbone_layers) if backbone_layers else nn.Identity()
# H lightweight heads: each outputs translation (3) + quaternion (4)
# Implemented as a batched single layer for GPU efficiency
self.heads_weight = nn.Parameter(torch.randn(H, latent_dim, 7) * 0.01)
self.heads_bias = nn.Parameter(torch.zeros(H, 7))
# Fixed random latent code -- held constant during optimization
self.register_buffer('x_bar', torch.zeros(1, latent_dim).uniform_(-1, 1))
# Initialize rotation quaternions via FPS; store as parameter
self._init_rotations()
def _init_rotations(self):
"""Initialize quaternion component of heads via FPS in SO(3)."""
q_init = fps_so3_init(self.H) # (H, 4)
self.heads_bias.data[:, 3:] = q_init # bias last 4 dims
def forward(self) -> Tuple[torch.Tensor, torch.Tensor]:
"""Generate H transformation hypotheses.
Returns
-------
t : (H, 3) translation vectors
R : (H, 3, 3) rotation matrices
"""
feat = self.backbone(self.x_bar) # (1, latent_dim)
# Batched head computation: (H, latent_dim) @ (H, latent_dim, 7)
feat_exp = feat.expand(self.H, -1) # (H, latent_dim)
out = torch.tanh(
torch.einsum('hi,hij->hj', feat_exp, self.heads_weight)
+ self.heads_bias
) # (H, 7) in (-1,1)
t = out[:, :3] # (H, 3) translation
q = F.normalize(out[:, 3:], dim=-1) # (H, 4) unit quat
R = quaternion_to_rotation_matrix(q) # (H, 3, 3)
return t, R
# ─── SECTION 5: Registration Loss ─────────────────────────────────────────────
def registration_loss(
udf: NeuralUDF,
neural_reg: NeuralReg,
intra_pts: torch.Tensor,
B: int = 3000,
B_sparse: int = 32,
K: int = 64,
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
"""Compute the coarse-to-fine registration loss (Equation 10).
Stage 1 (coarse): evaluate all H hypotheses on B_sparse points.
Stage 2 (fine): re-evaluate top-K hypotheses on B points.
The loss is the mean UDF value of the transformed intraoperative
point cloud averaged across all H hypotheses.
Parameters
----------
udf : frozen NeuralUDF for distance queries
neural_reg : NeuralReg to be optimized
intra_pts : (N, 3) normalized intraoperative point cloud
B : dense batch size for fine-stage evaluation
B_sparse : sparse batch size for coarse-stage evaluation
K : number of top hypotheses to refine
Returns
-------
loss : scalar optimization objective
best_R, best_t : (3,3) and (3,) best hypothesis at this step
"""
N = intra_pts.shape[0]
H = neural_reg.H
t, R = neural_reg() # (H,3), (H,3,3)
# ── Coarse stage: sparse evaluation of all H hypotheses ──────────────
idx_sparse = torch.randperm(N, device=intra_pts.device)[:B_sparse]
pts_sparse = intra_pts[idx_sparse] # (B_sparse, 3)
# Transform: (H, B_sparse, 3) = (H,3,3) @ (B_sparse,3).T + (H,3)
pts_rot_sparse = torch.einsum('hrc,nc->hnr', R, pts_sparse) + t.unsqueeze(1)
pts_rot_flat_sparse = pts_rot_sparse.reshape(-1, 3) # (H*B_sparse, 3)
with torch.no_grad():
d_sparse = udf(pts_rot_flat_sparse).reshape(H, B_sparse) # (H, B_sparse)
mean_d_sparse = d_sparse.mean(dim=-1) # (H,)
# ── Fine stage: dense evaluation of top-K hypotheses ────────────────
topk_idx = mean_d_sparse.topk(K, largest=False).indices
idx_dense = torch.randperm(N, device=intra_pts.device)[:B]
pts_dense = intra_pts[idx_dense] # (B, 3)
R_topk = R[topk_idx] # (K, 3, 3)
t_topk = t[topk_idx] # (K, 3)
pts_rot_fine = torch.einsum('krc,nc->knr', R_topk, pts_dense) + t_topk.unsqueeze(1)
pts_rot_flat_fine = pts_rot_fine.reshape(-1, 3) # (K*B, 3)
d_fine = udf(pts_rot_flat_fine).reshape(K, B) # (K, B)
mean_d_fine = d_fine.mean(dim=-1) # (K,)
# ── Total loss: mean over all H coarse + top-K fine evaluations ──────
loss = mean_d_sparse.mean() + mean_d_fine.mean()
# Best hypothesis for inference selection
best_fine_idx = mean_d_fine.argmin()
best_R = R_topk[best_fine_idx].detach()
best_t = t_topk[best_fine_idx].detach()
return loss, best_R, best_t
# ─── SECTION 6: NeuralBoneReg Full Framework ──────────────────────────────────
class NeuralBoneReg:
"""NeuralBoneReg: Two-stage instance-specific bone surface registration.
Implements the full pipeline from Section 3.2 of the paper.
PREOPERATIVE STAGE (run once per patient before surgery)
Given: segmented bone surface from CT or MRI
Action: train NeuralUDF to convergence on the preoperative point cloud
Output: frozen neural distance field for intraoperative use
INTRAOPERATIVE STAGE (run during surgery, target ~ 5 seconds)
Given: intraoperative point cloud from ultrasound or RGB-D
Action: optimize NeuralReg with 5000 parallel hypothesis heads
Output: best rigid transformation [R | t] aligning intraoperative
point cloud with the preoperative neural distance field
Parameters
----------
udf_hidden_dim : NeuralUDF MLP hidden dimension (256)
udf_layers : NeuralUDF MLP depth (5)
H : number of NeuralReg hypothesis heads (5000)
latent_dim : backbone latent dimension (128)
backbone_depth : shared backbone depth (4)
device : compute device
"""
def __init__(
self,
udf_hidden_dim: int = 256,
udf_layers: int = 5,
H: int = 5000,
latent_dim: int = 128,
backbone_depth: int = 4,
device: str = 'cuda',
):
self.device = device
self.udf = NeuralUDF(udf_hidden_dim, udf_layers).to(device)
self.neural_reg = NeuralReg(H, latent_dim, backbone_depth).to(device)
def preoperative_training(
self,
preop_pts: torch.Tensor,
n_iters: int = 10000,
lr: float = 1e-4,
verbose: bool = True,
) -> None:
"""Preoperative stage: train NeuralUDF on the preoperative point cloud.
This stage is computationally intensive but runs BEFORE surgery,
so runtime is not critical. After training, the UDF is frozen.
Parameters
----------
preop_pts : (M, 3) normalized preoperative bone surface point cloud
n_iters : training iterations (default 10000)
lr : Adam learning rate (default 1e-4)
verbose : print loss every 1000 iterations
"""
preop_pts = preop_pts.to(self.device)
optimizer = torch.optim.Adam(self.udf.parameters(), lr=lr)
self.udf.train()
for i in range(n_iters):
optimizer.zero_grad()
loss = udf_training_loss(self.udf, preop_pts)
loss.backward()
optimizer.step()
if verbose and (i % 1000 == 0):
print(ff" UDF iter {i:5d} loss {loss.item():.4f}")
self.udf.eval()
for p in self.udf.parameters():
p.requires_grad_(False)
if verbose:
print(" NeuralUDF training complete. Weights frozen.")
def intraoperative_registration(
self,
intra_pts: torch.Tensor,
n_iters: int = 1000,
lr: float = 1e-3,
B: int = 3000,
B_sparse: int = 32,
K: int = 64,
verbose: bool = True,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""Intraoperative stage: register intraoperative cloud to preoperative UDF.
NeuralReg is re-initialized for each new intraoperative input.
The rotation hypotheses are initialized via FPS in SO(3) for
broad coverage of the rotation space from the start.
Parameters
----------
intra_pts : (N, 3) normalized intraoperative bone surface point cloud
n_iters : Adam optimization iterations (default 1000)
lr : Adam learning rate (0.001 per paper)
B : dense point count for fine-stage evaluation (3000)
B_sparse : sparse point count for coarse-stage evaluation (32)
K : number of hypotheses refined in fine stage (64)
Returns
-------
best_R : (3, 3) estimated rotation matrix
best_t : (3,) estimated translation vector
"""
intra_pts = intra_pts.to(self.device)
# Re-initialize NeuralReg for this instance
self.neural_reg = NeuralReg(
self.neural_reg.H,
self.neural_reg.latent_dim,
sum(1 for l in self.neural_reg.backbone.children() if hasattr(l, 'weight')),
).to(self.device)
optimizer = torch.optim.Adam(
self.neural_reg.parameters(), lr=lr, betas=(0.9, 0.999)
)
self.neural_reg.train()
best_R_final, best_t_final = None, None
best_loss = float('inf')
for i in range(n_iters):
optimizer.zero_grad()
loss, best_R, best_t = registration_loss(
self.udf, self.neural_reg, intra_pts, B, B_sparse, K
)
loss.backward()
optimizer.step()
if loss.item() < best_loss:
best_loss = loss.item()
best_R_final = best_R.clone()
best_t_final = best_t.clone()
if verbose and (i % 200 == 0):
print(ff" Reg iter {i:4d} loss {loss.item():.4f}")
return best_R_final, best_t_final
# ─── SECTION 7: Smoke Test ─────────────────────────────────────────────────────
def _smoke_test():
"""End-to-end smoke test of NeuralBoneReg on synthetic bone surface data.
Tests:
- NeuralUDF preoperative training convergence
- NeuralReg intraoperative optimization with coarse-to-fine strategy
- Rotation matrix validity (det(R) = +1)
- Full pipeline gradient flow
Uses reduced model size and iteration counts for fast testing.
"""
print("=" * 62)
print("NeuralBoneReg Smoke Test -- Synthetic Bone Surface Data")
print("Paper: Wu et al., Medical Image Analysis 112 (2026) 104133")
print("=" * 62)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(ff"\nDevice: {device}")
# Synthetic preoperative point cloud: sphere surface as proxy for bone
M = 1000
angles = torch.randn(M, 3)
preop_pts = F.normalize(angles, dim=-1) * 0.5 # sphere of radius 0.5
preop_pts_norm, centroid, scale = normalize_point_cloud(preop_pts)
# Synthetic intraoperative cloud: same sphere partially observed + noise
N = 400
intra_base = F.normalize(torch.randn(N, 3), dim=-1) * 0.5
intra_base += 0.02 * torch.randn(N, 3)
intra_pts_norm, _, _ = normalize_point_cloud(intra_base)
print(ff"Preoperative cloud: {M} points")
print(ff"Intraoperative cloud: {N} points")
# Build NeuralBoneReg with small configuration for fast testing
framework = NeuralBoneReg(
udf_hidden_dim=64,
udf_layers=3,
H=100, # paper uses 5000; reduced for smoke test
latent_dim=64,
backbone_depth=2,
device=device,
)
total_udf = sum(p.numel() for p in framework.udf.parameters())
total_reg = sum(p.numel() for p in framework.neural_reg.parameters())
print(ff"NeuralUDF parameters: {total_udf:,}")
print(ff"NeuralReg parameters: {total_reg:,}")
# Preoperative stage
print(f"\n--- Preoperative Stage (NeuralUDF Training) ---")
framework.preoperative_training(
preop_pts_norm.to(device), n_iters=200, lr=1e-3, verbose=True
)
# Verify UDF produces valid non-negative distances
test_q = torch.randn(5, 3, device=device)
with torch.no_grad():
test_d = framework.udf(test_q)
assert (test_d >= 0).all(), "UDF produced negative distances"
print(ff"UDF test distances (should be >= 0): {test_d.cpu().numpy().round(3)}")
# Intraoperative stage
print(f"\n--- Intraoperative Stage (NeuralReg Optimization) ---")
best_R, best_t = framework.intraoperative_registration(
intra_pts_norm.to(device),
n_iters=50,
lr=1e-3,
B=200,
B_sparse=16,
K=10,
verbose=True,
)
# Validate rotation matrix
det_R = torch.linalg.det(best_R).item()
print(ff"\n{'─'*42}")
print(ff"Best R (3x3 rotation matrix):\n{best_R.cpu().numpy().round(3)}")
print(ff"Best t (translation vector): {best_t.cpu().numpy().round(3)}")
print(ff"det(R) = {det_R:.4f} (should be 1.0 for valid rotation)")
assert abs(det_R - 1.0) < 0.01, "det(R) invalid"
print(f"{'─'*42}")
print("Smoke test passed. NeuralBoneReg preop and intraop cycles OK.")
print("See Section 3.2 in Wu et al. 2026 for the full methodology.")
print("=" * 62)
if __name__ == '__main__':
_smoke_test()
Where the Limitations Live and What Comes Next
The paper is candid about NeuralBoneReg’s weaknesses, and understanding them matters for anyone thinking about clinical translation.
The most fundamental limitation is that instance-specific self-supervised methods require test-time training. NeuralBoneReg cannot be deployed as a pretrained model that runs a forward pass and produces an alignment in milliseconds. The preoperative UDF training takes time, and the intraoperative optimization takes approximately 5 seconds. This is acceptable in most surgical workflows where registration happens before the first incision is made, but it rules out applications requiring real-time registration at video frame rates. Supervised learning methods that have already been trained on large datasets can produce registrations in under a second. NeuralBoneReg trades that speed for the ability to work without any training data, which is a reasonable tradeoff for the many anatomies where no training data exists.
The noise robustness experiments reveal a clear performance cliff. With Gaussian noise at standard deviation 1 millimeter the registration recall drops from 0.886 to 0.829 and the Chamfer Distance rises from 0.82 to 0.96 millimeters. At standard deviation 4 millimeters the recall falls below 0.5. Real ultrasound point clouds can have errors in this range, particularly in specimens with high body mass index or significant soft tissue thickness over the bone. The authors identify two future directions for addressing this. One is explicit denoising of the segmentation masks and point clouds before registration, and the other is a noise-aware loss function that down-weights points with low predicted reliability rather than treating all intraoperative points equally.
NeuralBoneReg requires a complete preoperative bone surface model as its reference. This is available in standard CAOS workflows where CT is part of the preoperative planning, but it limits applicability in emergency trauma cases where preoperative CT may not be available or in procedures that rely entirely on intraoperative imaging. The authors also note that the evaluation used ex-vivo specimens where sufficient bone surface exposure and overlap with the preoperative model were achievable. In some minimally invasive procedures with very limited surgical exposure, the intraoperative ultrasound may capture only a small fragment of the total bone surface, reducing registration accuracy in ways not fully characterized by the current benchmark.
The comparison against DiReg, the only other self-supervised baseline in the evaluation, deserves attention. DiReg achieves a recall of only 0.57 on UltraBones100k despite being designed for unsupervised registration. The reason is that DiReg, like all the other deep learning baselines, still requires pretraining on large datasets of paired point clouds even though it does not require ground-truth transformation labels. The self-supervised label in that context means unsupervised with respect to correspondence annotations, not unsupervised with respect to requiring paired data. NeuralBoneReg is the only method in the comparison that genuinely requires no multi-subject training data of any kind, which is what makes the UltraBonesHip results so compelling.
The deeper implication of these results is about what kind of generalization matters in surgical AI. The dominant conversation in medical AI is about large datasets, foundation models, and scale. NeuralBoneReg makes the opposite argument, namely that for problems where paired data is genuinely scarce, instance-specific methods that optimize from scratch for each new patient may outperform methods that try to generalize from limited training examples. Both approaches have their place. For high-prevalence anatomies with decades of clinical data, supervised learning will likely win. For rare anatomies, unusual patient populations, or any clinical context where data collection is practically impossible, instance-specific approaches like NeuralBoneReg provide a path forward that scale-dependent methods cannot offer.
Read the Full Paper and Access the Code
The complete NeuralBoneReg paper, the UltraBonesHip dataset, and all code are publicly available at the project repository and via the ScienceDirect link below.
Wu, L., Seibold, M., Cavalcanti, N. A., Ao, Y., Flepp, R., Massalimova, A., Calvet, L., & Fürnstahl, P. (2026). NeuralBoneReg: An instance-specific label-free point cloud-based method for multi-modal bone surface registration. Medical Image Analysis, 112, 104133. https://doi.org/10.1016/j.media.2026.104133
This article is an independent editorial analysis of peer-reviewed research. The PyTorch implementation is an educational reproduction and may differ from the official repository in engineering details. For research use, verify against the official code and original paper. This research was funded by the Innosuisse Flagship project PROFICIENCY No. PFFS-21-19 and supported by OR-X, a Swiss national research infrastructure for translational surgery.