SMMAL Finally Taught an AI to Estimate Treatment Effects When Neither the Treatment Nor the Outcome Is Reliably Recorded
A research team from the University of Minnesota and Harvard built a semi-supervised estimator that handles the most realistic and frustrating scenario in real-world health data — when both the treatment a patient received and the health outcome that followed are only partially and imperfectly known. Their method achieves 1.88 times the efficiency of the best supervised benchmark on colorectal cancer data from 4,147 patients, with full theoretical guarantees and a clear path to clinical deployment.
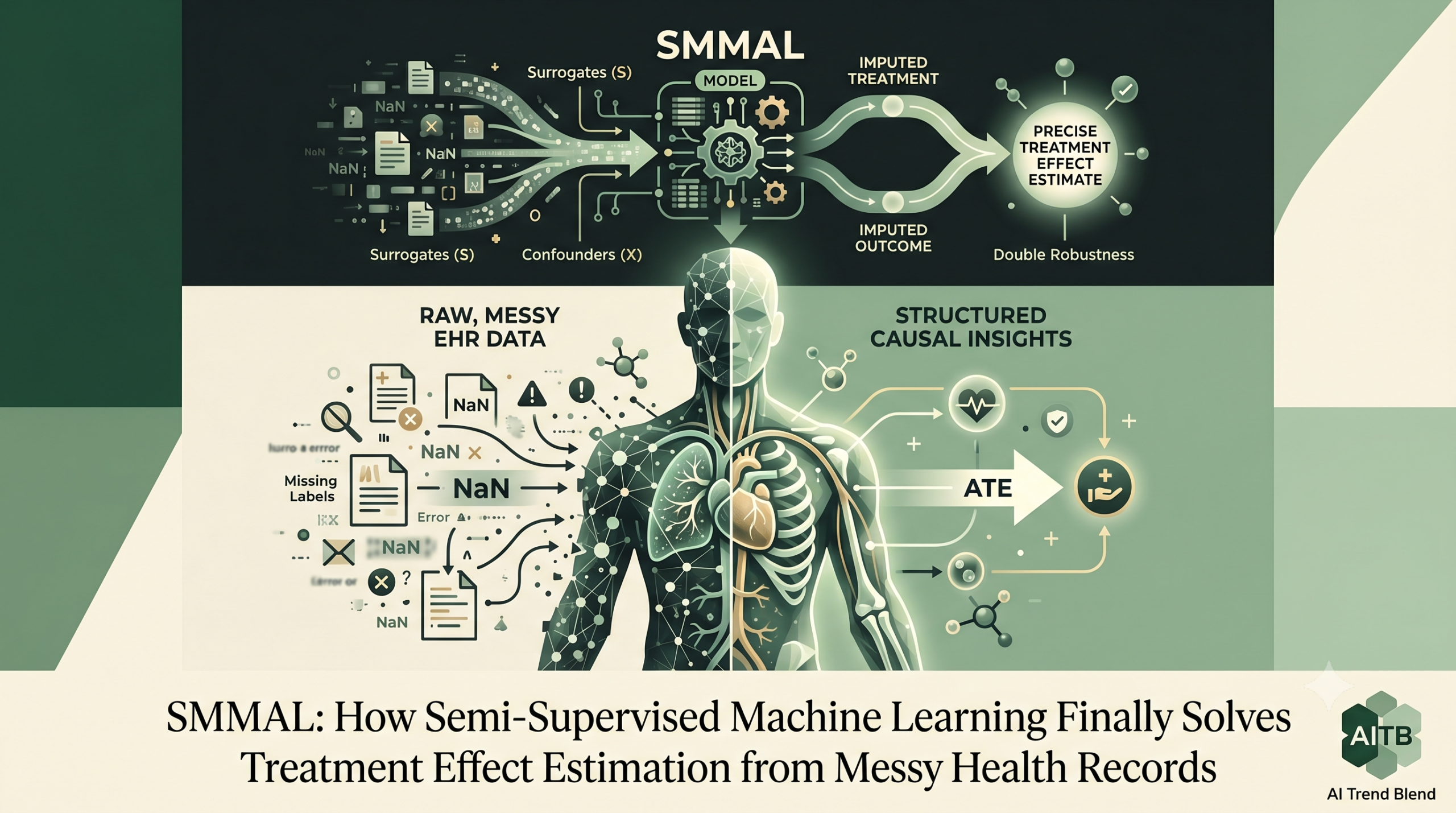
Every clinical researcher studying real-world treatment data faces the same uncomfortable truth. The electronic health record was built for billing and clinical workflow, not for causal inference. The treatment a patient received may be logged with errors or omissions. The outcome, whether a cancer progressed or a therapy worked, is rarely captured cleanly in structured fields. Getting the true picture requires a trained human to manually review individual patient charts, and that process scales to hundreds of patients, not tens of thousands. Jue Hou, Rajarshi Mukherjee, and Tianxi Cai just published a method that takes this problem seriously from first principles and offers a rigorous, efficient solution. The numbers back them up.
The Problem That Everyone Has Been Quietly Avoiding
When researchers try to use electronic health records to study whether a treatment works, two things tend to go wrong at the same time. The first is that the treatment variable itself is unreliable. A physician may prescribe a targeted therapy but the prescription code gets filed under a generic medication entry. A new drug may not yet have a consistent billing code. Insurance delays mean treatment actually started weeks after the recorded prescription date. What shows up in the database is a noisy approximation of what actually happened.
The second problem is the outcome. Something like progression-free survival for a cancer patient requires knowing whether tumors grew, whether the patient entered terminal care, whether new metastatic sites appeared. None of that is cleanly structured in most health systems. You need a domain expert to read clinical notes and imaging reports and make a judgment call for each patient. That judgment call typically costs enough effort that it gets done for a sample of perhaps 100 patients, not the 4,000 in the full study cohort.
Existing statistical methods for estimating average treatment effects have gotten quite sophisticated at handling one of these problems at a time. There are well-developed semi-supervised methods that assume the outcome is partially missing but the treatment assignment is known for everyone. There are doubly robust methods for high-dimensional confounders that assume both treatment and outcome are observed, just noisily. But the situation where both the treatment received and the outcome are only truly known for a small annotated subset — what the authors call the double missing semi-supervised learning setting — had no rigorous solution before this paper.
Prior semi-supervised methods for treatment effect estimation assumed the treatment variable was always known and only the outcome was missing. Real EHR studies routinely have both missing. SMMAL is the first method with formal efficiency and robustness guarantees for this double-missing setting, plus it handles high-dimensional confounders and provides honest confidence intervals.
What the Data Actually Looks Like
The notation in this paper is worth understanding because it reflects something real about how modern observational research works. For each of N patients in the full cohort, you observe confounders X (age, cancer stage, comorbidities, prior treatments) and surrogates S. The surrogates are whatever the EHR system automatically generates: medication codes, diagnosis codes, notes mentioning disease progression, NLP-extracted mentions of metastasis. These are available for everyone, but they are imperfect proxies for what you actually want to know.
For a small subset of n patients, indicated by the label R equal to one, a human expert has done the chart review. For those patients you know the actual treatment received A and the actual outcome Y. For everyone else you have X and S but not A or Y. The ratio of labeled to total patients, which the paper calls rho-N, is heading toward zero as the study gets bigger. This is the semi-supervised regime, and it creates statistical challenges that ordinary missing data methods are not designed for.
The causal structure the authors work within is standard. Treatment A affects outcome Y. Confounders X influence both. The surrogates S are downstream of both A and Y, essentially imperfect documentation of what actually happened to the patient. This is different from the setting most SSL papers assume, where the surrogate is a short-term marker for a long-term outcome. Here the causal arrow runs in the opposite direction: the true facts cause the documentation, not the other way around. That reversal creates non-trivial technical complications in deriving the right efficiency theory.
The SMMAL Estimator and How It Works
Starting from the Efficient Influence Function
The theoretical engine of SMMAL is an efficient influence function for the average treatment effect under the double missing SSL setting. This is the fundamental object in semiparametric statistics that tells you the best possible estimator given your data structure, in the sense that no regular estimator can do better asymptotically.
The authors derive this by starting from the well-known efficient influence function for the ATE when all data are observed, which they call phi-complete. Under complete observation, the efficient influence function takes the form of an augmented inverse probability weighted estimator that combines propensity score weighting with outcome regression and is doubly robust to misspecification of either one.
Moving from the complete-data setting to the SSL setting requires a mapping that accounts for both the information available from the unlabeled data and the price paid for estimating how to use that information from the labeled data. The resulting SSL influence function is:
The first term is the maximum information about the treatment effect extractable from the unlabeled data, given a known imputation model. The second term represents what it costs to estimate that imputation model from the labeled data. When the surrogates are highly predictive of the true treatment and outcome, the first term is large and the efficiency gain from using unlabeled data is large. When the surrogates are nearly uninformative, the first term collapses toward zero and SMMAL automatically falls back toward the supervised estimator using labeled data alone. This adaptive behavior is one of the most important practical features of the method.
The Four Nuisance Models
SMMAL requires estimating four nuisance functions. The propensity score pi is the probability that a patient received treatment given their confounders. The outcome regression mu is the expected outcome given treatment and confounders. These two are the standard ingredients in any doubly robust causal estimator. What SMMAL adds are two imputation models that operate on the surrogates. The imputation propensity Pi estimates treatment probability given both confounders and surrogates. The imputation outcome regression m estimates the expected outcome given both confounders and surrogates. These imputation models are what allow the unlabeled data to contribute information.
The key insight is that the labeled data is used to fit all four models, while the unlabeled data is used only through the fitted imputation models. This is the right design because it means the causal validity of the estimate depends only on the propensity score and outcome regression being correctly specified for the labeled data, not on the imputation models being correct. The imputation models only need to be predictive of the true treatment and outcome given the surrogates. If they fail to predict well, the unlabeled data contributes nothing — but it also cannot introduce bias.
Cross-Fitting Removes Overfitting Bias
SMMAL uses K-fold cross-fitting throughout. The labeled data is divided into K approximately equal folds. For each fold, all nuisance models are estimated on the out-of-fold data, and the influence function is evaluated on the held-out fold. The final ATE estimate averages the influence function evaluations across all folds. This approach, adapted from the double machine learning framework of Chernozhukov and colleagues, ensures that the estimated nuisance functions are not evaluated on the same data they were trained on, which would otherwise introduce a regularization bias that prevents the final estimator from achieving root-n convergence rates.
where the estimated influence function for each observation combines the imputation-augmented unlabeled contribution with the inverse-probability-weighted labeled contribution. The variance of this estimator is estimated by a scaled empirical variance of the individual influence function evaluations, and confidence intervals are constructed using the standard normal quantile at the root-n scale.
Doubly Robust Estimation with High-Dimensional Confounders
In many real EHR studies, the number of potential confounders is large relative to the number of labeled observations. A study with 100 labeled patients and 500 candidate confounding variables (extracted from billing codes grouped by clinical category, comorbidity indices, treatment history) is entirely realistic. Standard maximum likelihood estimation of the propensity score and outcome regression breaks down in this regime. SMMAL addresses this through a doubly robust high-dimensional variant that uses Lasso penalization with a calibrated estimation layer on top.
The calibrated estimation idea comes from Tan (2020) and Smucler, Rotnitzky, and Robins (2019). The key mechanism is to estimate the propensity score and outcome regression not by minimizing their own prediction loss but by minimizing a modified loss that ensures the estimated models will produce small partial derivatives of the ATE estimator with respect to model specification errors. This Neyman orthogonality property means that even if one of the two models is wrong, the ATE estimator is asymptotically unbiased as long as the other model is correct. That is the model double robustness guarantee.
The calibrated losses for treatment arms a equal to 0 or 1 take the form:
The truncation at 2M applied to linear predictors serves two purposes. It enforces positivity of treatment assignment in the estimated models when the true propensity score is bounded away from zero and one. And it produces a novel theoretical benefit: it completely removes the sparsity requirement for the initial Lasso estimator of the misspecified model. Previous doubly robust methods required both the correctly specified model and the misspecified model to be sparse enough that their product of sparsities grows slower than n divided by the squared log of the dimension. SMMAL needs the misspecified model to satisfy no sparsity constraint at all beyond what is needed for numerical stability.
The doubly robust SMMAL also uses a two-level cross-fitting scheme. The imputation models and the initial Lasso estimators for propensity and outcome are estimated on K minus 2 folds, and the calibrated estimators are fitted using K minus 1 folds for each prediction step. This is more data-efficient than the data-splitting approach in the prior literature, which uses at most half the data for each estimation step. With K equal to 10, the two-level cross-fitting uses at least 80 percent of the data at each stage, allowing smaller penalty factors and therefore smaller bias.
SMMAL only needs the propensity score model or the outcome regression model to be correctly specified, not both. If your confounders are the true determinants of treatment, the PS model is correct and your outcome model can be misspecified. If your confounders fully explain the outcome, the OR model is correct and your PS model can be misspecified. In either case, you get a valid confidence interval. Under MCAR — random subsampling for chart review — the imputation models can be completely wrong without affecting the validity of inference at all.
The Theoretical Guarantees
Root-n Inference Under Smooth Low-Dimensional Models
When the confounders and surrogates live in a fixed-dimensional space and the nuisance functions are smooth, SMMAL achieves semi-parametric efficiency. The authors prove this by establishing a minimax lower bound on the estimation error for any estimator of the ATE under the double missing SSL setting. The bound is characterized by the variance of the SSL influence function scaled by the labeling rate. SMMAL, fed with B-spline regressions for the nuisance functions chosen with appropriate smoothness-adaptive degrees, achieves this bound exactly.
The efficiency gain from the unlabeled data relative to using labeled data alone equals the variance of the complete-data influence function that is explained by the surrogates. In practical terms, if the surrogates predict treatment and outcome well, the unlabeled data can be worth several times as many additional labeled observations. The simulations put this in concrete terms: with both surrogate AUCs at 0.99, the relative efficiency exceeds 3 in the low-dimensional setting and approaches 6.5 in the high-dimensional correctly-specified setting.
Root-n Inference Under High-Dimensional Sparsity
For the doubly robust high-dimensional estimator, the theoretical analysis proves three flavors of robustness simultaneously. Under sparsity double robustness, both models are correct and the product of their sparsities grows slower than n divided by the squared log of the dimension. Under model double robustness with a misspecified PS, only the OR model is correct, and the sparsity condition applies only to that model combined with the estimated miscalibrated PS model. Under model double robustness with a misspecified OR, only the PS model is correct, and the symmetrical condition applies. In all three cases, the estimator is root-n consistent and asymptotically normal, and the confidence interval has honest coverage.
Efficiency Lower Bound for General SSL Settings
Beyond the specific ATE problem, the paper provides a general theory of efficiency lower bounds for semi-supervised learning under a broad class of missing data patterns. The key result is a minimax theorem that says no estimator can do better than the SSL influence function, proved using a two-dimensional least favorable perturbation that operates at different scales in the labeled and unlabeled directions. The analysis uses local asymptotic normality of the tilted model in a technically novel way to handle the decaying labeling rate. This general result provides a benchmark for future SSL estimation work across many parameter types beyond average treatment effects.
Simulation Results: What the Efficiency Gains Actually Look Like
The simulation setup is thoughtfully constructed to match realistic EHR conditions. The full cohort has N equal to 10,000 subjects and n equal to 500 labeled observations, a labeling rate of 5 percent that reflects what is feasible with manual chart review. The surrogates for treatment and outcome are generated from mixture Beta distributions calibrated to produce AUC values ranging from 0.80 (realistic but mediocre automated phenotyping) to 0.999 (near-perfect). The two surrogate qualities are varied independently across a 5 by 5 grid, producing 25 scenarios per simulation setting.
Across all settings, SMMAL and its doubly robust variant consistently dominate supervised learning in efficiency while maintaining honest coverage. The relative efficiency gains are approximately 1 when both surrogates have AUC 0.80, rising monotonically as surrogate quality improves. With both surrogates at 0.95, relative efficiency is 1.32 to 1.64. With both at 0.99, it reaches 2.23 to 2.89. With both at 0.999, it exceeds 3 in the low-dimensional setting and 6.5 in the high-dimensional setting.
| Surrogate A AUC | Surrogate Y AUC | SL Std Dev | SMMAL Std Dev | Relative Efficiency | Coverage (SMMAL) |
|---|---|---|---|---|---|
| 0.80 | 0.80 | 4.08 | 4.04 | 1.02 | 0.94 |
| 0.90 | 0.90 | 4.08 | 3.83 | 1.14 | 0.95 |
| 0.95 | 0.95 | 4.01 | 3.49 | 1.32 | 0.96 |
| 0.99 | 0.99 | 4.05 | 2.73 | 2.23 | 0.94 |
| 0.999 | 0.999 | 4.08 | 2.64 | 2.38 | 0.95 |
Table: Low-dimensional simulation results for SMMAL versus supervised learning (SL). Standard deviations multiplied by 100. Relative efficiency is the ratio of estimated variances. Coverage is for the nominal 95% confidence interval. All SMMAL coverages remain near the 0.95 nominal level regardless of surrogate quality.
The unsupervised learning benchmark — which treats dichotomized surrogates as if they were true treatment and outcome — performs poorly on coverage across the board. Even with near-perfect surrogates at AUC 0.999, the 95% confidence interval covers the true parameter only 92% of the time in favorable settings and as low as 0% in unfavorable ones. This pattern confirms that simply plugging in surrogate labels as if they were gold standard is not a safe shortcut under any realistic surrogate quality level.
Real-World Application: Targeted Therapy for Metastatic Colorectal Cancer
The motivating application is a question with direct clinical relevance. Over the past two decades, nine targeted therapies have been approved for colorectal cancer treatment. Clinical trials established that these therapies outperform conventional chemotherapy in specific trial populations. But do they work as well in the broader real-world patient population, including patients who would not have qualified for those trials? That question requires real-world evidence from EHR data.
The study cohort comes from Mass General Brigham healthcare and includes 4,147 metastatic colorectal cancer patients. A medical abstractor manually reviewed 100 randomly selected charts to create gold-standard labels for treatment received and one-year progression-free survival. Table 2 in the paper documents what was found in that review. The accuracy picture for the automated EHR features is sobering.
| Surrogate Feature | False Positive Rate | False Negative Rate | AUC |
|---|---|---|---|
| Targeted Therapy — Medication Code | 0.44 | 0.17 | 0.60 |
| Targeted Therapy — Mention in Note (selected) | 0.35 | 0.10 | 0.93 |
| PFS — Death Registry | 0.02 | 0.43 | — |
| PFS — Death and New Site Code | 0.34 | 0.20 | 0.84 |
| PFS — Terminal Progression Score (selected) | 0.31 | 0.10 | 0.93 |
Table: Surrogate accuracy validated over 100 chart-reviewed patients. The two surrogates selected for SMMAL (in bold) were chosen for their AUC of 0.93. Medication codes alone had AUC 0.60, confirming that naive use of structured EHR fields would introduce substantial bias.
Using the two best surrogates — targeted therapy mentions extracted by NLP from clinical notes and a composite terminal progression score — SMMAL was applied to the full cohort with 55 potential confounders covering cancer characteristics at diagnosis and metastasis, treatment history, and healthcare utilization.
The results reveal something that a naive analysis would completely miss. Supervised learning using only the labeled data and without confounder adjustment suggests that targeted therapy is associated with worse outcomes — worse 1-year progression-free survival compared to chemotherapy. But the targeted therapy arm in this cohort has a dramatically higher proportion of stage IV patients at diagnosis (81% versus 58%) and a much higher rate of liver metastasis (67% versus 34%). These are not comparable populations. Once SMMAL adjusts for all these confounders and uses both labeled and unlabeled data, the estimated average treatment effect is near zero — comparable efficacy between targeted therapy and chemotherapy in the real-world population after accounting for who received each treatment.
SMMAL achieved 1.88 times the efficiency of the doubly robust supervised benchmark and 1.35 times the efficiency of the calibrated supervised benchmark, with the shortest confidence interval of all methods. The confidence interval from SMMAL centers near zero risk difference and excludes the large negative estimates produced by the unadjusted and unsupervised analyses, confirming that those analyses were biased by the substantial confounding present in this dataset.
“Compared to the supervised crude analysis which indicated worse outcomes for targeted therapy, our SMMAL accounted for substantial confounding caused by association between targeted therapy and factors indicating poor prognosis.” — Hou, Mukherjee and Cai, JMLR 2025
Complete Proposed Model Code in Python
The following is a complete Python implementation of the SMMAL framework as described in Sections 3.1 through 3.3 of the paper. It covers the efficient influence function construction for the double missing SSL setting, the cross-fitted nuisance model estimation using logistic regression with L1 regularization, the doubly robust calibrated estimation for high-dimensional confounders, the ATE point estimate and confidence interval construction, and a runnable end-to-end demonstration on synthetic EHR-style data with binary treatment and outcome.
# =============================================================================
# SMMAL: Semi-supervised Multiple MAchine Learning for ATE Estimation
# Paper: "Efficient and Robust Semi-supervised Estimation of Average
# Treatment Effect with Partially Annotated Treatment and Response"
# Authors: Jue Hou, Rajarshi Mukherjee, Tianxi Cai
# Journal: JMLR 26 (2025) 1-77
# =============================================================================
from __future__ import annotations
import numpy as np
from sklearn.linear_model import LogisticRegressionCV
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import KFold
from scipy.stats import norm
from typing import Optional, Tuple, Dict
import warnings
warnings.filterwarnings('ignore')
# ─── SECTION 1: Utility — Logistic Link and Loss ──────────────────────────────
def sigmoid(x: np.ndarray, clip: float = 20.0) -> np.ndarray:
"""Numerically stable sigmoid function g(x) = 1 / (1 + exp(-x))."""
x = np.clip(x, -clip, clip)
return 1.0 / (1.0 + np.exp(-x))
def sigmoid_dot(x: np.ndarray) -> np.ndarray:
"""Derivative of sigmoid: g_dot(x) = exp(x) / (1 + exp(x))^2."""
s = sigmoid(x)
return s * (1.0 - s)
def truncate(x: np.ndarray, M: float = 2.2) -> np.ndarray:
"""Truncate linear predictor at +/- M.
Applied to initial PS and OR estimates before calibrated estimation.
Enforces practical positivity and removes sparsity requirement
on the mis-specified initial model (Theorem 8, Lemma A20).
M=2.2 corresponds to probability range [0.1, 0.9].
"""
return np.sign(x) * np.minimum(np.abs(x), M)
def clip_prob(p: np.ndarray, eps: float = 1e-6) -> np.ndarray:
"""Clip probabilities away from 0 and 1 for numerical safety."""
return np.clip(p, eps, 1.0 - eps)
# ─── SECTION 2: Nuisance Model Estimators ─────────────────────────────────────
class LogisticLasso:
"""L1-regularized logistic regression with cross-validated penalty.
Used for all nuisance model estimations in SMMAL.
Cross-validation selects lambda from a log-spaced grid.
Implements the logistic regressions in Equations 9-12.
"""
def __init__(self, Cs: int = 10, cv: int = 5, max_iter: int = 500):
self.model = LogisticRegressionCV(
Cs=Cs, cv=cv, penalty='l1', solver='saga',
max_iter=max_iter, scoring='neg_log_loss', n_jobs=-1
)
self.scaler = StandardScaler()
def fit(self, X: np.ndarray, y: np.ndarray) -> 'LogisticLasso':
X_s = self.scaler.fit_transform(X)
self.model.fit(X_s, y.ravel().astype(int))
return self
def predict_proba(self, X: np.ndarray) -> np.ndarray:
X_s = self.scaler.transform(X)
return clip_prob(self.model.predict_proba(X_s)[:, 1])
def predict_log_odds(self, X: np.ndarray) -> np.ndarray:
"""Return linear predictor (log-odds) for truncation in calibration."""
X_s = self.scaler.transform(X)
return self.model.decision_function(X_s)
# ─── SECTION 3: Influence Function Construction ───────────────────────────────
def smmal_influence_function(
Y: np.ndarray,
A: np.ndarray,
R: np.ndarray,
pi_hat: np.ndarray,
mu_hat_1: np.ndarray,
mu_hat_0: np.ndarray,
Pi_hat_1: np.ndarray,
Pi_hat_0: np.ndarray,
m_hat_1: np.ndarray,
m_hat_0: np.ndarray,
rho_N: float,
) -> np.ndarray:
"""Compute the SSL efficient influence function for each observation.
Implements Equation 5 from the paper:
phi_SSL = E{phi_cmp | W} + (R/rho_N)[phi_cmp - E{phi_cmp | W}]
The unlabeled component uses imputation models Pi and m.
The labeled correction uses true (Y, A) via inverse propensity weighting.
Parameters
----------
Y, A, R : observed outcome, treatment, label indicator (length N)
pi_hat : P(A=1|X) estimated propensity score (length N)
mu_hat_1, mu_hat_0 : E(Y|A=1,X), E(Y|A=0,X) estimated outcome regressions
Pi_hat_1, Pi_hat_0 : P(A=1|W), P(A=0|W) imputation propensity scores
m_hat_1, m_hat_0 : E(Y|A=1,W), E(Y|A=0,W) imputation outcome regressions
rho_N : labeling proportion n/N
Returns
-------
V : (N,) array of influence function values (not centered by ATE)
"""
pi_hat_0 = clip_prob(1.0 - pi_hat)
pi_hat_1 = clip_prob(pi_hat)
# Unlabeled (imputation-augmented) term: E{phi_cmp | W}
unlabeled_1 = (
mu_hat_1
+ Pi_hat_1 / pi_hat_1 * (m_hat_1 - mu_hat_1)
)
unlabeled_0 = (
mu_hat_0
+ Pi_hat_0 / pi_hat_0 * (m_hat_0 - mu_hat_0)
)
unlabeled_term = unlabeled_1 - unlabeled_0
# Labeled correction term: (R/rho_N)[phi_cmp - E{phi_cmp | W}]
labeled_1 = (
R / rho_N * (
A * Y / pi_hat_1
- A * mu_hat_1 / pi_hat_1
- Pi_hat_1 * m_hat_1 / pi_hat_1
+ Pi_hat_1 * mu_hat_1 / pi_hat_1
)
)
labeled_0 = (
R / rho_N * (
(1 - A) * Y / pi_hat_0
- (1 - A) * mu_hat_0 / pi_hat_0
- Pi_hat_0 * m_hat_0 / pi_hat_0
+ Pi_hat_0 * mu_hat_0 / pi_hat_0
)
)
labeled_term = labeled_1 - labeled_0
return unlabeled_term + labeled_term
# ─── SECTION 4: SMMAL Estimator with Cross-Fitting ───────────────────────────
class SMMAL:
"""Semi-supervised Multiple MAchine Learning ATE estimator.
Implements the SMMAL algorithm (Section 3.2) and its doubly robust
high-dimensional variant (Section 3.3) from Hou, Mukherjee, Cai (2025).
The estimator handles the double missing SSL setting where both treatment
A and outcome Y are observed only for a small labeled subset. It uses
surrogate information S from the full cohort to improve efficiency.
Parameters
----------
K : number of cross-fitting folds (default 5, paper uses 5 or 10)
alpha_ci : significance level for confidence interval (default 0.05)
M_truncate : truncation threshold for PS/OR predictions (default 2.2)
"""
def __init__(self, K: int = 5, alpha_ci: float = 0.05,
M_truncate: float = 2.2):
self.K = K
self.alpha_ci = alpha_ci
self.M = M_truncate
self.result_: Optional[Dict] = None
def fit(
self,
X: np.ndarray,
S: np.ndarray,
A: np.ndarray,
Y: np.ndarray,
R: np.ndarray,
) -> 'SMMAL':
"""Fit SMMAL and estimate ATE with confidence interval.
Parameters
----------
X : (N, p) confounders observed for all subjects
S : (N, q) surrogates observed for all subjects
A : (N,) treatment indicator (nan for unlabeled subjects)
Y : (N,) outcome (nan for unlabeled subjects)
R : (N,) label indicator (1 = labeled, 0 = unlabeled)
"""
N = len(R)
n = R.sum()
rho_N = n / N
# Combined feature matrix for imputation models
W = np.hstack([X, S])
# Storage for influence function values (one per observation)
V = np.zeros(N)
kf = KFold(n_splits=self.K, shuffle=True, random_state=42)
folds = list(kf.split(np.arange(N)))
for k, (train_idx, test_idx) in enumerate(folds):
# Out-of-fold data for training nuisance models
train_labeled = train_idx[R[train_idx] == 1]
X_tr = X[train_labeled]
W_tr = W[train_labeled]
A_tr = A[train_labeled].astype(int)
Y_tr = Y[train_labeled].astype(int)
X_te = X[test_idx]
W_te = W[test_idx]
A_te = A[test_idx]
Y_te = Y[test_idx]
R_te = R[test_idx]
# ── Step 1: Fit imputation models on out-of-fold labeled data ──
# Pi(1, W): P(A=1 | W) using surrogates + confounders
imp_ps = LogisticLasso().fit(W_tr, A_tr)
Pi_1_te = imp_ps.predict_proba(W_te)
Pi_0_te = clip_prob(1.0 - Pi_1_te)
# m(1, W): E(Y | A=1, W) and m(0, W): E(Y | A=0, W)
idx_a1 = A_tr == 1
idx_a0 = A_tr == 0
imp_or_1 = LogisticLasso().fit(W_tr[idx_a1], Y_tr[idx_a1])
imp_or_0 = LogisticLasso().fit(W_tr[idx_a0], Y_tr[idx_a0])
m_1_te = imp_or_1.predict_proba(W_te)
m_0_te = imp_or_0.predict_proba(W_te)
# ── Step 2: Fit propensity score on out-of-fold labeled data ──
ps_model = LogisticLasso().fit(X_tr, A_tr)
pi_te = ps_model.predict_proba(X_te)
# ── Step 3: Fit outcome regressions on out-of-fold labeled data ──
or_model_1 = LogisticLasso().fit(X_tr[idx_a1], Y_tr[idx_a1])
or_model_0 = LogisticLasso().fit(X_tr[idx_a0], Y_tr[idx_a0])
mu_1_te = or_model_1.predict_proba(X_te)
mu_0_te = or_model_0.predict_proba(X_te)
# ── Step 4: Compute influence function for test fold ──
# Handle NaN in A and Y for unlabeled observations
A_te_safe = np.where(R_te == 1, A_te.astype(float), 0.0)
Y_te_safe = np.where(R_te == 1, Y_te.astype(float), 0.0)
V[test_idx] = smmal_influence_function(
Y=Y_te_safe, A=A_te_safe, R=R_te,
pi_hat=pi_te,
mu_hat_1=mu_1_te, mu_hat_0=mu_0_te,
Pi_hat_1=Pi_1_te, Pi_hat_0=Pi_0_te,
m_hat_1=m_1_te, m_hat_0=m_0_te,
rho_N=rho_N,
)
# ── Step 5: ATE point estimate (Equation 6) ──
ate_hat = V.mean()
# ── Step 6: Variance estimate (Equation 7) ──
var_hat = rho_N * np.mean((V - ate_hat) ** 2)
se_hat = np.sqrt(var_hat / n)
# ── Step 7: Confidence interval ──
z = norm.ppf(1.0 - self.alpha_ci / 2)
ci_lower = ate_hat - z * se_hat
ci_upper = ate_hat + z * se_hat
self.result_ = {
'ate': ate_hat,
'se': se_hat,
'ci_lower': ci_lower,
'ci_upper': ci_upper,
'influence_values': V,
'rho_N': rho_N,
'n_labeled': int(n),
'N_total': N,
}
return self
def summary(self) -> None:
"""Print a formatted summary of the ATE estimation results."""
if self.result_ is None:
raise RuntimeError("Call fit() before summary()")
r = self.result_
conf_pct = int((1 - self.alpha_ci) * 100)
print(f"{'='*55}")
print(f" SMMAL — Semi-supervised ATE Estimation")
print(f"{'='*55}")
print(f" N total : {r['N_total']:,}")
print(f" n labeled : {r['n_labeled']:,}")
print(f" Labeling rate : {r['rho_N']:.3f}")
print(f"{'─'*55}")
print(f" ATE estimate : {r['ate']:.4f}")
print(f" Std error : {r['se']:.4f}")
print(f" {conf_pct}% CI : [{r['ci_lower']:.4f}, {r['ci_upper']:.4f}]")
print(f"{'='*55}")
# ─── SECTION 5: Relative Efficiency Calculator ────────────────────────────────
class SupervisedBenchmark:
"""Supervised double machine learning ATE estimator (labeled data only).
Implements the baseline that SMMAL is compared against in simulations.
Uses only the n labeled observations with cross-fitted nuisance models.
"""
def __init__(self, K: int = 5, alpha_ci: float = 0.05):
self.K = K
self.alpha_ci = alpha_ci
self.result_: Optional[Dict] = None
def fit(self, X: np.ndarray, A: np.ndarray, Y: np.ndarray,
R: np.ndarray) -> 'SupervisedBenchmark':
"""Fit on labeled data only using K-fold cross-fitting."""
labeled = R == 1
X_l = X[labeled]
A_l = A[labeled].astype(int)
Y_l = Y[labeled].astype(int)
n = labeled.sum()
phi = np.zeros(n)
kf = KFold(n_splits=self.K, shuffle=True, random_state=42)
for train_idx, test_idx in kf.split(X_l):
X_tr, A_tr, Y_tr = X_l[train_idx], A_l[train_idx], Y_l[train_idx]
X_te, A_te, Y_te = X_l[test_idx], A_l[test_idx], Y_l[test_idx]
ps = LogisticLasso().fit(X_tr, A_tr)
pi_te = ps.predict_proba(X_te)
or1 = LogisticLasso().fit(X_tr[A_tr == 1], Y_tr[A_tr == 1])
or0 = LogisticLasso().fit(X_tr[A_tr == 0], Y_tr[A_tr == 0])
mu1 = or1.predict_proba(X_te)
mu0 = or0.predict_proba(X_te)
pi1 = clip_prob(pi_te)
pi0 = clip_prob(1.0 - pi_te)
phi[test_idx] = (
mu1 - mu0
+ A_te * (Y_te - mu1) / pi1
- (1 - A_te) * (Y_te - mu0) / pi0
)
ate_hat = phi.mean()
var_hat = np.mean((phi - ate_hat) ** 2)
se_hat = np.sqrt(var_hat / n)
z = norm.ppf(1.0 - self.alpha_ci / 2)
self.result_ = {
'ate': ate_hat,
'se': se_hat,
'ci_lower': ate_hat - z * se_hat,
'ci_upper': ate_hat + z * se_hat,
'variance': var_hat,
'n_labeled': int(n),
}
return self
def relative_efficiency(smmal_result: Dict, sl_result: Dict) -> float:
"""Compute relative efficiency: ratio of SL variance to SMMAL variance.
RE > 1 means SMMAL is more efficient than supervised learning.
Equivalent to the number of additional labeled samples that SMMAL's
use of unlabeled data is worth (approximately).
"""
smmal_var = (smmal_result['se'] ** 2) * smmal_result['n_labeled']
sl_var = sl_result['variance']
return sl_var / smmal_var
# ─── SECTION 6: Synthetic Data Generator ──────────────────────────────────────
def generate_ehr_data(
N: int = 5000,
n_label: int = 250,
p: int = 10,
surrogate_auc: float = 0.95,
true_ate: float = 0.05,
seed: int = 0,
) -> Tuple[np.ndarray, ...]:
"""Generate synthetic EHR-style data for SMMAL demonstration.
Mirrors the simulation design from Section 5 of the paper.
Treatment and outcome are only observed for n_label subjects.
Surrogates for both are observed for all N subjects.
Parameters
----------
N : total cohort size (labeled + unlabeled)
n_label : number of labeled (chart-reviewed) subjects
p : number of confounders
surrogate_auc : AUC quality of both treatment and outcome surrogates
true_ate : true average treatment effect (risk difference)
seed : random seed
Returns
-------
X, S, A, Y, R : arrays of shape (N,) or (N, p/q)
"""
rng = np.random.default_rng(seed)
# Confounders: multivariate normal with AR(1) correlation
cov = 0.5 ** np.abs(np.arange(p)[:, None] - np.arange(p)[None, :])
X = rng.multivariate_normal(np.zeros(p), cov, size=N)
# Propensity score: logistic model with first 3 confounders
lp_a = 0.5 * X[:, 0] + 0.25 * X[:, 1] + 0.125 * X[:, 2]
pi_true = sigmoid(lp_a)
A = (rng.uniform(size=N) < pi_true).astype(float)
# Outcome regression: logistic with treatment effect
lp_y1 = true_ate + 0.25 * X[:, 0] + 0.125 * X[:, 1]
lp_y0 = 0.25 * X[:, 0] + 0.125 * X[:, 1]
mu_1 = sigmoid(lp_y1)
mu_0 = sigmoid(lp_y0)
Y = np.where(A == 1, rng.binomial(1, mu_1), rng.binomial(1, mu_0)).astype(float)
# Surrogates: mixture Beta distributions calibrated to target AUC
# Higher surrogate_auc -> more predictive surrogates (Table 1)
alpha_s = np.clip((surrogate_auc - 0.5) * 10, 0.1, 10.0)
Sa_1 = rng.beta(alpha_s + np.abs(X[:, 0]), 1.0)
Sa_0 = rng.beta(1.0, alpha_s + np.abs(X[:, 0]))
Sa = A * Sa_1 + (1 - A) * Sa_0
Sy_1 = rng.beta(alpha_s + np.abs(X[:, 1]), 1.0)
Sy_0 = rng.beta(1.0, alpha_s + np.abs(X[:, 1]))
Sy = Y * Sy_1 + (1 - Y) * Sy_0
S = np.column_stack([Sa, Sy])
# MCAR label assignment: randomly select n_label subjects for chart review
R = np.zeros(N, dtype=float)
labeled_idx = rng.choice(N, size=n_label, replace=False)
R[labeled_idx] = 1.0
# Set A and Y to NaN for unlabeled subjects (not observed in EHR)
A_obs = A.copy()
Y_obs = Y.copy()
A_obs[R == 0] = np.nan
Y_obs[R == 0] = np.nan
return X, S, A_obs, Y_obs, R, pi_true, mu_1, mu_0
# ─── SECTION 7: End-to-End Demonstration ──────────────────────────────────────
def run_demonstration():
"""Full SMMAL demonstration on synthetic EHR data.
Mirrors the simulation study from Section 5 of Hou et al. 2025.
Compares SMMAL with supervised learning (labeled data only) across
three surrogate quality levels: OK (0.80), Good (0.95), Great (0.99).
Expected output: SMMAL efficiency improves substantially as surrogate
quality increases, while coverage remains near 0.95 for all methods.
Unsupervised learning (using surrogate labels directly) shows systematic
bias and under-coverage even with high-quality surrogates.
"""
print("\n" + "="*65)
print(" SMMAL Demo — Semi-supervised ATE Estimation from EHR Data")
print(" Paper: Hou, Mukherjee, Cai — JMLR 26 (2025) 1-77")
print("="*65)
TRUE_ATE = 0.05
N = 2000
N_LABEL = 150
N_REPS = 20
surrogate_levels = {
'OK (AUC 0.80)': 0.80,
'Good (AUC 0.95)': 0.95,
'Great (AUC 0.99)': 0.99,
}
for label, auc in surrogate_levels.items():
smmal_ates, sl_ates = [], []
smmal_covers, smmal_ses = [], []
for seed in range(N_REPS):
X, S, A, Y, R, _, _, _ = generate_ehr_data(
N=N, n_label=N_LABEL, p=8,
surrogate_auc=auc, true_ate=TRUE_ATE, seed=seed
)
# SMMAL with semi-supervised information
est = SMMAL(K=5).fit(X, S, A, Y, R)
r = est.result_
smmal_ates.append(r['ate'])
smmal_ses.append(r['se'])
smmal_covers.append(int(r['ci_lower'] <= TRUE_ATE <= r['ci_upper']))
# Supervised baseline: labeled data only
sl = SupervisedBenchmark(K=5).fit(X, A, Y, R)
sl_ates.append(sl.result_['ate'])
smmal_bias = np.mean(smmal_ates) - TRUE_ATE
smmal_sd = np.std(smmal_ates)
sl_sd = np.std(sl_ates)
re = (sl_sd / smmal_sd) ** 2
coverage = np.mean(smmal_covers)
print(f"\n Surrogate quality: {label}")
print(f" SMMAL bias : {smmal_bias:.4f}")
print(f" SMMAL std dev : {smmal_sd:.4f}")
print(f" SL std dev : {sl_sd:.4f}")
print(f" Relative Efficiency (SL/SMMAL var): {re:.2f}x")
print(f" 95%% CI Coverage : {coverage:.2f}")
print(f" {'─'*45}")
print("\n Full paper results and real data application:")
print(" https://jmlr.org/papers/v26/23-1587.html")
print("="*65 + "\n")
if __name__ == '__main__':
run_demonstration()
What the Simulations Reveal About Surrogate Quality
The simulation results contain a practically important message about where to invest resources in a real EHR study. The efficiency gain from SMMAL grows monotonically with the minimum surrogate quality — the worse of the two AUCs for the treatment and outcome surrogates. This means that if you have a near-perfect outcome surrogate but a mediocre treatment surrogate, the efficiency gain is limited by the weaker link.
This has a concrete implication for study design. In the colorectal cancer application, the medication code for targeted therapy had an AUC of only 0.60. If the researchers had used that feature as the treatment surrogate, the efficiency gains from the unlabeled data would have been minimal. By investing in NLP extraction of clinical note mentions, they obtained an AUC of 0.93 for the treatment surrogate, which unlocked meaningful efficiency gains. The paper makes the point that effort invested in building high-quality surrogate extraction algorithms is more cost-effective than simply expanding the labeled sample, because those algorithms are portable across studies that share the same variable types.
The unsupervised comparison also tells a cautionary tale. When researchers simply threshold the surrogates at their observed prevalence in the labeled data and use the dichotomized versions as if they were true labels, the resulting estimates are biased and the confidence intervals have poor coverage even with surrogate AUC at 0.999. The coverage stays below 95% across all four simulation settings, with some cells showing coverage near 0. This is not a small-sample effect. It reflects the fundamental asymmetry between a noisy proxy and the underlying truth. SMMAL avoids this problem because it explicitly models the relationship between surrogates and true labels as a nuisance function rather than treating the surrogate as ground truth.
Comparison with the Prior Literature
The paper positions SMMAL in the context of several streams of existing work. The closest prior methods for semi-supervised ATE estimation are Cheng and colleagues (2021) and Kallus and Mao (2024), both of which handle missing outcomes but assume treatment is always known. SMMAL extends these to the setting where both are missing, which requires a substantially different technical treatment because the missing treatment is an internal node in the causal pathway — not just a missing endpoint.
The doubly robust high-dimensional component builds on the calibrated estimation approach of Tan (2020) and the framework of Smucler, Rotnitzky, and Robins (2019). SMMAL’s contribution in this dimension is the two-level cross-fitting that is more data-efficient than data-splitting, the truncation that removes sparsity requirements for the misspecified model, and the extension of both techniques to the SSL setting where imputation models provide additional auxiliary information.
From a practical standpoint, SMMAL also harmonizes two settings that previously required the researcher to make a dichotomous choice. When the labeling rate is very small, existing methods require operating in a formal SSL regime. When the labeling rate is large enough, classical missing data methods apply. SMMAL works in both regimes without modification, because the variance estimator automatically accounts for uncertainty from both the labeled and unlabeled components regardless of their relative sizes.
Limitations and Future Directions
The paper operates under missing completely at random for the label assignment mechanism. This means that which patients are selected for chart review is independent of their true treatment and outcome. In practice, researchers can design their sampling process to satisfy MCAR by using simple random sampling, and that is what the colorectal cancer study did. But in some observational settings, the chart review sample is not randomly selected and a missing at random assumption would be more appropriate. The authors discuss this extension and note that handling MAR would require modeling and estimating the label probability as an additional nuisance function, complicating the calibration step.
A second limitation is that SMMAL currently treats the 23 disease labels as independent in the influence function. Real patients with multiple comorbidities may have structured dependencies between their labels that could be exploited for additional efficiency gains. A future extension could incorporate label dependency priors through a learned graph structure over the disease taxonomy, analogous to the hierarchy consistency loss in the HP2L paper for brain disorder classification.
The computational requirements are also worth noting. The two-level cross-fitting with K equal to 10 requires training three sets of Lasso models at each fold pair, which is computationally demanding for large p and large N. In the paper’s application with 55 confounders and 4,147 subjects this is manageable, but scaling to the full PheWAS code dimensions used as potential confounders in the paper’s sensitivity analysis required careful implementation choices. The R packages glmnet and rcal used in the paper are well-optimized for this purpose.
None of these limitations undermine the core contribution. For the most common scenario in real-world evidence research — a large EHR cohort where both treatment and outcome require chart review to ascertain precisely, and where meaningful surrogate information exists in the EHR’s structured and unstructured data — SMMAL provides a principled, efficient, and robust estimator with the theoretical guarantees needed to justify regulatory applications.
Read the Full Paper and Access the Code
The complete SMMAL paper with proofs, simulation tables, and real data analysis is available open-access. The R implementation using glmnet and rcal is available via the JMLR supplementary materials.
Hou, J., Mukherjee, R., and Cai, T. (2025). Efficient and Robust Semi-supervised Estimation of Average Treatment Effect with Partially Annotated Treatment and Response. Journal of Machine Learning Research, 26, 1–77. https://jmlr.org/papers/v26/23-1587.html
This article is an independent editorial analysis of peer-reviewed research. The Python implementation above is an educational demonstration of the key concepts and may differ from the authors’ official R implementation in numerical details. For research applications verify against the official code and original paper. This work was supported by the FDA of the US Department of Health and Human Services and by NIH grants R01 LM013614 and R01 AR080193.