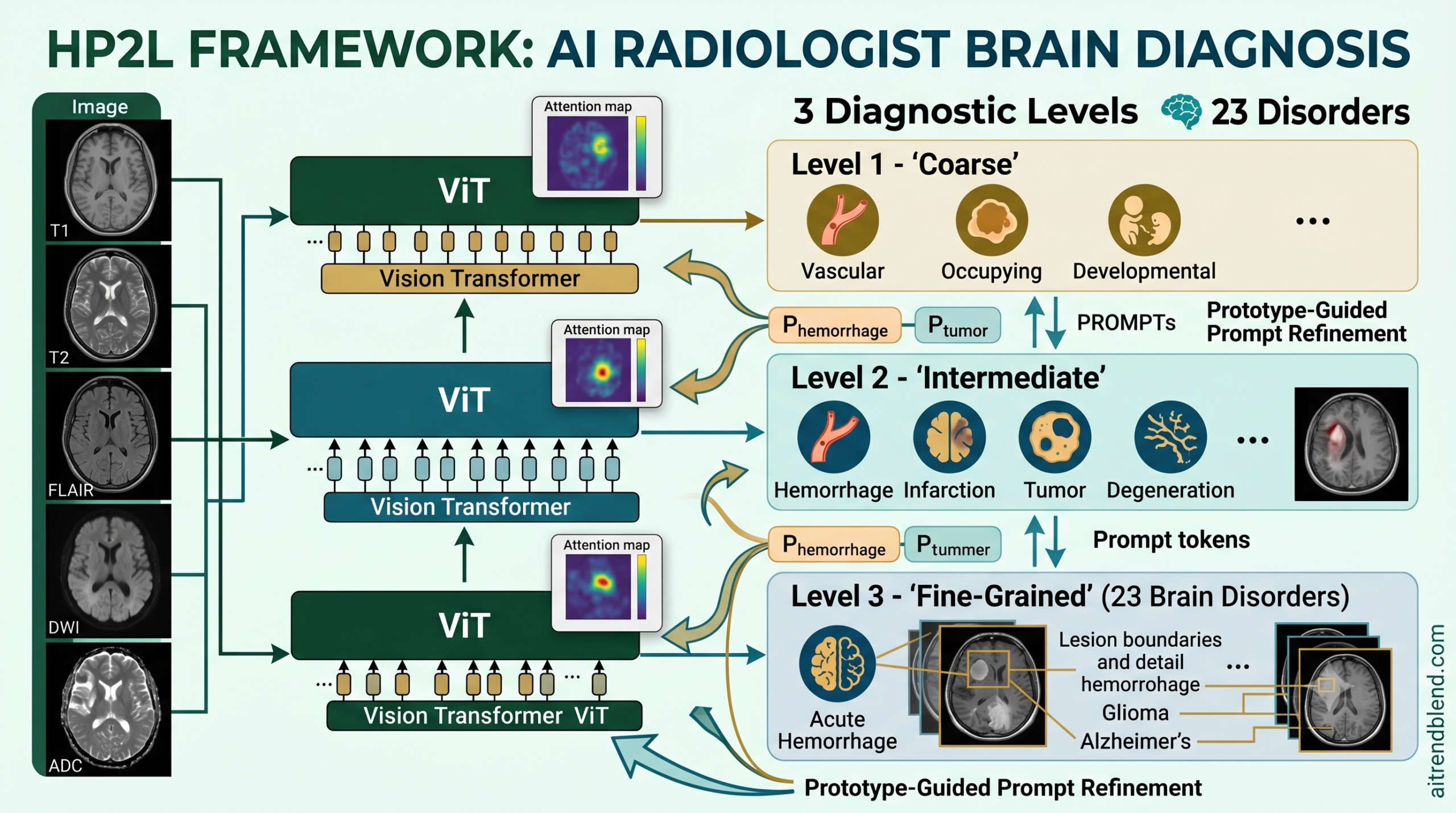
A radiologist looking at a brain scan does not jump straight to naming an exact disease subtype. The process moves in stages. First comes a broad question, is there a vascular problem at all. If the answer is yes, the next question narrows further, is this bleeding or is it a blocked vessel. Only after those earlier questions settle does an expert commit to the precise subtype. That layered reasoning took years of training to build and now runs in a few seconds. The patients behind this kind of scan include anyone who arrives at a hospital with a suspected stroke, a new seizure, unexplained memory loss, or an unusual finding on a routine scan, the everyday caseload of a neurology or emergency imaging service. Getting a deep learning model to follow that same layered path, rather than matching pixels against a flat list of 23 labels, has proven difficult for years. A team from ShanghaiTech University, working with Henan Provincial People’s Hospital and Shanghai United Imaging Intelligence, just published a framework that takes the layered approach seriously, and the numbers back the claim.
Key points
- HP2L is a hierarchical AI framework that classifies 23 brain disorders across three diagnostic levels instead of guessing one label all at once.
- It reached 88.43 percent balanced accuracy at the finest level across 54360 subjects, more than 8 percentage points ahead of the closest rival method.
- A prompt learning module lets evidence gathered at lower levels correct a mistaken guess made at a higher level, instead of locking that guess in permanently.
- An exponential moving average keeps class prototypes stable even for rare conditions such as penetrating deformity, which had only 1074 training cases.
- Two hospitals that contributed no training data were used as external test cohorts, and accuracy held up on both.
This article explains findings from a peer reviewed research paper for general and professional education. It is not medical advice, it does not diagnose any condition, and it is not a substitute for evaluation by a qualified physician or radiologist. Anyone with a personal health concern should speak with a qualified clinician.
The trouble with flat classification in brain imaging
Most medical image AI still runs on what researchers call flat classification. The scan goes in, a probability comes out for every disease class at once, and the highest number wins. This works reasonably well when a dataset has thousands of balanced examples per class and when the classes look visually distinct. Brain disorders satisfy neither condition.
The dataset behind this research spans 23 brain disorders. A common finding such as white matter hyperintensity contributes 22934 of the 54360 total subjects, while a rare one such as penetrating deformity appears in only 1074 cases. That is roughly a 21 fold gap between the biggest and smallest class. A flat classifier trained on that kind of spread learns the common classes well and quietly becomes unreliable on the rare ones. Balanced accuracy exists as a metric precisely to expose that failure, because it weighs every class equally rather than letting the majority classes flatter the overall score. A plain Vision Transformer baseline drops from 85.53 percent balanced accuracy at the broadest level all the way to 70.65 percent at the finest level. A 15 point collapse like that is not a rounding error. It means patients with rarer subtypes are being misread at rates no hospital would accept in practice.
Hierarchical classification is the obvious fix on paper. Sort the task into broad categories first, then refine step after step, mirroring how a clinician actually reasons and focusing the learning signal on the real relationships between disease classes. The catch is that most attempts at building this in practice carry a flaw that papers tend to gloss over. Once a hierarchical model commits to an early decision, everything downstream is locked into that branch. If the model routes a subacute hemorrhage into the infarction branch at the second level, there is no way to recover at the third level. The mistake compounds rather than corrects. Researchers call this error propagation, and it is the entire reason HP2L exists.
Most hierarchical classifiers lock in their top level decision before the lower levels ever see the image. One bad routing choice then cascades all the way down and leaves the final fine grained prediction worse than a flat classifier would have produced on its own. HP2L breaks that pattern by letting a prompt token get refined at every level using evidence pulled from class specific prototypes, which opens the door to correction across levels instead of rigid one direction propagation.
Three ideas that make HP2L work
HP2L stands for hierarchical prompt and prototype learning. Three connected pieces work together to solve the error propagation problem while keeping the benefits of thinking in stages.
A hierarchical ViT backbone built level by level
The backbone stacks three level specific Vision Transformer blocks, one for each diagnostic stage. The first block handles the broadest split, telling vascular problems apart from mass occupying lesions and developmental abnormalities. The second handles a middle layer of distinctions, hemorrhage against infarction, tumor against degeneration. The third handles the full fine grained split across all 23 subtypes.
Each block runs two sub units in sequence. A prompting transformer block processes an extended token sequence made up of image patch tokens, a classification token, and a dedicated prompt token. That prompt token carries the diagnostic context accumulated from earlier levels and shapes the self attention directly, so what the model reads in the image is colored by what it already suspects about the disease category. After that step, a vanilla transformer block refines the patch and classification tokens on their own, with the prompt token removed from the sequence. That gives the visual features room to develop independently before the next level’s classification head reads from the updated classification token.
Prompt learning that corrects itself instead of just passing forward
This is where HP2L diverges most from earlier hierarchical designs. Instead of carrying the prompt token from one level to the next unchanged, HP2L runs it through cross attention against a set of class specific prototype tokens at every level. The attention weights measure how strongly the current prompt should draw on each class’s learned signature. The result is a refined prompt built as a dynamically weighted blend of class prototypes, shaped by what the model currently believes about the scan in front of it.
The refined prompt attends over every class prototype at the current level, weighting each one by how well it matches the query drawn from the updated prompt token.
The practical difference is large. Fixed propagation means a wrong high level prompt poisons every level that follows it. Prototype guided refinement means a wrong high level prompt can be pulled back on course by whatever evidence shows up further down. Suppose the image features at level two point strongly toward hemorrhage even though level one wavered between vascular and mass occupying categories. Cross attention will weight the hemorrhage prototype heavily, and the refined prompt steers level three toward hemorrhage subtypes regardless of what level one guessed first. The hierarchy ends up informed in both directions rather than moving strictly from top to bottom.
Prototype learning steadied by an exponential moving average
None of this works if the prototypes themselves are unstable. For cross attention to mean anything, each prototype has to genuinely represent its class’s imaging signature, not just the last batch of examples, and not an average thrown off by outliers. What HP2L uses instead is an exponential moving average applied after every training batch.
The momentum term alpha is set at 0.99, so each update folds in only 1 percent of the current batch’s class representation. If a class is missing from a batch entirely, its prototype simply holds its previous value.
That high momentum makes prototypes resistant to noisy batches, class imbalance, and the ordinary variability that shows up across scanners and hospital sites. For a class such as penetrating deformity, sitting at only 1074 training examples, this kind of stability is close to a requirement rather than a nice to have. Without it there simply are not enough clean examples per batch to build a trustworthy representation.
Prototype tokens trained with ordinary gradient updates show high variance for rare classes, where a single batch might contain zero examples or one. The moving average gives noise resistant accumulation, folding in information from every training step rather than leaning on the most recent batch alone. The paper’s own ablation shows that removing this stabilization drops balanced accuracy at the finest level from 88.43 percent to 85.90 percent, and that loss concentrates precisely on the rare, clinically important subtypes.
How the training objective keeps levels honest with each other
HP2L trains end to end with a loss made of two parts. The first is an ordinary sigmoid based binary cross entropy applied independently at each level. The second is a consistency penalty that fires only when a child class shows a lower predicted probability than its parent, and only in cases where that child label is actually true.
The penalty only fires in one direction. It never punishes a fine grained prediction for being more confident than its coarse parent, because that is exactly the behavior you want when specific evidence is strong.
The reasoning behind that asymmetry deserves a moment of attention. When a fine grained label is truly present in a scan, its predicted probability should be at least as high as its parent’s. The penalty never discourages fine grained confidence from exceeding coarse confidence, since that reflects exactly the behavior you want when specific evidence is strong. This is not an incidental design choice. It encodes the clinical logic that certainty should grow as more specific evidence accumulates, never shrink.
The data behind the numbers
The scale and range of the validation work is unusually rigorous for a paper in this space, and it deserves attention on its own.
The primary training cohort comes from Henan Provincial People’s Hospital, covering 47227 subjects whose diagnostic labels were pulled from radiology reports through a natural language processing pipeline. The team manually checked a random 10 percent slice of that output before trusting the pipeline at full scale. The remaining subjects come from three public research cohorts, ADNI with 1432 subjects, OASIS with 823 subjects, and NACC with 3989 subjects, contributing mostly Alzheimer’s disease and mild cognitive impairment labels.
The real stress test of generalization comes from two external cohorts that never appeared during training in any form. One is from Fuwai Central China Cardiovascular Disease Hospital, 329 cases focused on cerebral small vessel disease. The other is from the First Hospital of Xi’an, 560 tumor cases. Different institutions, different scanners, and different disease distributions, with the model given no access to any of it before evaluation.
All five MRI sequences, T1, T2, FLAIR, DWI, and ADC, are concatenated as channels. Missing modalities, common in messy multi center data, are handled with zero filling for the absent channel rather than dropping the case. The model processes 3D volumes at 1.5mm isotropic spacing, mapped to a 32 token sequence through a 3D CNN encoder before entering the transformer hierarchy.
Where HP2L pulls ahead of everything else
HP2L reaches 88.43 percent balanced accuracy at the fine grained third level. The strongest hierarchical rival, TransHP, reaches 83.14 percent, and HPDT lands at 80.01 percent. An 8.42 point gap over the best prior method, on a task spanning 23 classes with severe imbalance, is not a marginal edge. It is the difference between a system that handles the common diseases adequately and one that handles the full range of presentations a radiologist actually sees on a given shift.
| Method | Level 1 BAcc | Level 1 AUC | Level 3 BAcc | Level 3 AUC | BAcc Drop |
|---|---|---|---|---|---|
| ViT | 85.53% | 85.22% | 70.65% | 71.87% | 14.88% |
| PromptViT | 87.19% | 85.77% | 73.11% | 73.21% | 14.08% |
| TransHP | 89.22% | 91.37% | 83.14% | 82.37% | 4.08% |
| HPDT | 87.23% | 87.01% | 80.01% | 80.12% | 7.22% |
| HP2L (Ours) | 90.45% | 90.03% | 88.43% | 87.58% | 2.02% |
The drop from level one to level three is where the design advantage shows up most clearly. HP2L loses just 2.02 percent moving from the broadest split to the finest one, against 14.88 percent for a plain ViT. For every non hierarchical method here, adding structure without correction makes the lower levels worse, because errors accumulate downward. For HP2L the hierarchy is a net gain at every level, because the prompt refinement step contains the damage from any single wrong early guess rather than letting it spread.
The rare diseases where the gain matters most
Fine grained AUC comparisons across individual subtypes show where the improvement actually lands. Penetrating deformity, with just 1074 training cases, climbs from 72.25 percent AUC under TransHP to 80.94 percent under HP2L. Mild cognitive impairment climbs from 76.47 percent to 83.46 percent. All three hemorrhage subtypes show consistent gains as well.
The external cohorts tell the same story from a different angle. On the cerebral small vessel disease cohort, cerebral microbleeds improve from 66.10 percent AUC under the plain ViT baseline to 83.88 percent under HP2L. On the tumor cohort, metastatic tumor classification improves from 70.28 percent to 86.64 percent. Those gains show up on data from hospitals the model never trained on, using equipment it never saw during development.
HP2L can revise a suboptimal higher level preference and reach the correct final label, while other methods stay on an incorrect path through the whole hierarchy. Liu et al., Medical Image Analysis, 2026
What the attention maps show about how the model reasons
The attention dynamics across levels are one of the more genuinely interesting parts of this paper, and they are worth reading closely rather than skimming past as a figure caption. At each level the prompt token attends over image patches, and the resulting attention maps shift in a way that tracks real clinical reasoning as the hierarchy deepens.
For hemorrhage cases, the level one attention spreads broadly across the lateral ventricles. By level three it has narrowed onto the boundary of the specific lesion, which is roughly the same feature a radiologist uses to judge acute versus chronic bleeding from signal intensity at the hematoma margin. For infarction cases attention concentrates progressively toward the infarction center, matching how subtype discrimination in practice depends on the lesion core rather than the surrounding edema. For tumors, early attention covers both the mass and the surrounding edema, while the final level isolates the tumor center, mirroring the clinical need to separate primary tumor morphology from secondary reactive tissue.
The prototype evolution across training is just as telling. At epoch 10 every prototype token clusters together with no meaningful separation. By epoch 50 the coarse level prototypes begin pulling apart. By epoch 100 the full structure of the taxonomy has emerged in the embedding space, fine grained subtypes clustering around their parent prototype and the three broad groups sitting well apart from each other. The model arrived at roughly the same organizational structure clinicians already use, and it got there without that structure being hard coded beyond the hierarchy consistency loss.
What the ablation study reveals about each design choice
The ablation numbers are worth reading in full because they show which parts of the design actually earn their place and by how much.
On prompt configuration, removing prompting entirely drops level three balanced accuracy from 88.43 percent to 71.28 percent. Static one hot prompts barely move the needle, reaching only 72.26 percent. Learnable prompts without prototype guidance reach 80.47 percent. Only when learnable prompts are updated through prototype cross attention does performance climb to the full 88.43 percent, meaning the refinement mechanism accounts for roughly 8 of the 17 percentage points gained over the no prompt baseline.
On prototype configuration, dropping prototypes entirely lands at 73.75 percent. Fixed one hot prototype tokens reach 79.91 percent. Learnable prototypes without the moving average reach 85.90 percent. The full HP2L design with the moving average reaches 88.43 percent, a 2.53 point gain concentrated on the rare fine grained classes where a single batch’s variance runs highest.
On hierarchy depth, skipping hierarchy altogether produces 74.23 percent balanced accuracy. A two level hierarchy reaches 82.38 percent. Three levels reach 88.43 percent. Each additional level adds roughly 6 percentage points, a scaling pattern that supports the core decision to build the framework in stages rather than flattening it back down for simplicity.
Clinical translation gap
A benchmark number and a clinical deployment are two different things, and it is worth being specific about the distance between them here rather than gliding past it. HP2L was trained on four NVIDIA L40 GPUs, each with 40GB of memory, running a full 3D volumetric pipeline across five MRI sequences and a three level transformer backbone. That is a substantial computational footprint, well beyond what a smaller community hospital or an outpatient imaging center typically has on hand, and it matters for anyone thinking about how this would actually run day to day rather than in a research cluster.
The paper reports a single forward pass producing all three diagnostic levels at once, with no manual post processing step required, which is a genuine convenience for a deployment pipeline. But a research paper reporting balanced accuracy on retrospective cohorts is not the same claim as a regulatory clearance for clinical decision support, and this paper makes no such claim. Retrospective validation on two external hospitals is a meaningfully strong signal of generalization, stronger than most papers in this space bother to include, yet it is still not prospective validation on new patients being scanned in real time, with real clinical workflows, real staffing pressure, and real consequences attached to a wrong call. Zero filling for missing MRI sequences is a reasonable engineering choice, but a hospital that routinely skips certain sequences for cost or scheduling reasons would need to know how much that zero filling degrades accuracy on their specific case mix before trusting the tool, and that specific breakdown is not something this paper measures directly.
None of this is a knock against the research. It is a reminder that the distance between a strong benchmark and a usable clinical tool is measured in years of prospective study, regulatory review, and integration work, not in a single Medical Image Analysis publication, however well designed.
Honest limitations
The paper’s own interpretability study points to where HP2L still struggles, and those failure modes are worth taking seriously rather than treating as a footnote. Tiny lesions that fall below the resolution the spatial attention mechanism can resolve remain difficult to catch. Closely related subtypes with overlapping imaging signatures continue to cause confusion between each other. Comorbid presentations, where a secondary finding sits alongside a primary one, are an ongoing weak point. HP2L handles comorbidity better than the competing methods tested here and can correctly flag both a lacunar infarction and a metastatic tumor in the same subject, but the problem is not solved outright, and under detected secondary findings remain a real risk in a clinical setting.
There is also a structural gap worth naming plainly. The paper evaluates a single expert defined hierarchy, built with input from experienced neuroradiologists, which is a meaningful strength on its own. But other valid hierarchies exist, organized around disease staging over time, underlying cause, or treatment pathway rather than the taxonomy used here. Whether HP2L holds up equally well under a different hierarchical organization is only partly tested in this paper, and a broader sensitivity analysis across alternative taxonomies would strengthen the claim considerably.
The paper also flags inter disease dependency as future work rather than something already solved, and that is an honest omission worth repeating here. Real neuroradiology recognizes that vascular burden raises the odds of later degenerative findings, that certain genetic profiles co express multiple tumor types, and that white matter hyperintensity and lacunar infarction often appear together as markers of the same underlying small vessel disease. A system that scores each disorder independently is leaving structural information on the table, and building a learned dependency structure over the taxonomy is a reasonable next step the authors themselves point toward.
Complete PyTorch implementation of HP2L
The implementation below covers the full three level hierarchical ViT backbone with its prompting transformer block and vanilla transformer block sub units, the cross attention prompt learning module, the exponential moving average prototype learning module, the level wise classification heads, the combined training loss with the hierarchy consistency penalty, and a runnable smoke test on synthetic 3D brain MRI data.
# ===========================================================================
# HP2L Hierarchical Prompt and Prototype Learning for Brain Disorder Diagnosis
# Paper "A hierarchical prompt and prototype learning framework for brain
# disorder classification"
# Authors Yuxiao Liu et al. ShanghaiTech / Henan Provincial People's Hospital
# Journal Medical Image Analysis 112 (2026) 104063
# ===========================================================================
from __future__ import annotations
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import List, Dict, Optional, Tuple
# SECTION 1 Multi-Head Self-Attention and Feed-Forward Utilities
class MultiHeadSelfAttention(nn.Module):
"""Standard multi-head self-attention used in both PTB and VTB."""
def __init__(self, D: int, H: int):
super().__init__()
self.H = H
self.d_h = D // H
self.scale = math.sqrt(self.d_h)
self.W_Q = nn.Linear(D, D, bias=False)
self.W_K = nn.Linear(D, D, bias=False)
self.W_V = nn.Linear(D, D, bias=False)
self.W_O = nn.Linear(D, D, bias=False)
self.dropout = nn.Dropout(0.1)
def forward(self, x: torch.Tensor) -> torch.Tensor:
B, N, D = x.shape
Q = self.W_Q(x).view(B, N, self.H, self.d_h).transpose(1, 2)
K = self.W_K(x).view(B, N, self.H, self.d_h).transpose(1, 2)
V = self.W_V(x).view(B, N, self.H, self.d_h).transpose(1, 2)
attn = self.dropout(torch.softmax(Q @ K.transpose(-2, -1) / self.scale, dim=-1))
out = (attn @ V).transpose(1, 2).contiguous().view(B, N, D)
return self.W_O(out)
class FeedForwardNetwork(nn.Module):
"""Position-wise FFN with GELU activation."""
def __init__(self, D: int, ffn_dim: int = None):
super().__init__()
ffn_dim = ffn_dim or D * 4
self.net = nn.Sequential(
nn.Linear(D, ffn_dim), nn.GELU(), nn.Dropout(0.1),
nn.Linear(ffn_dim, D), nn.Dropout(0.1),
)
def forward(self, x): return self.net(x)
# SECTION 2 Prompting Transformer Block (PTB)
class PromptingTransformerBlock(nn.Module):
"""Processes [CLS, prompt, patches] together, then splits tokens back out."""
def __init__(self, D: int, H: int):
super().__init__()
self.ln1 = nn.LayerNorm(D)
self.attn = MultiHeadSelfAttention(D, H)
self.ln2 = nn.LayerNorm(D)
self.ffn = FeedForwardNetwork(D)
def forward(self, x_cls: torch.Tensor, x_pro: torch.Tensor,
X: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
Z = torch.cat([x_cls, x_pro, X], dim=1)
Z = Z + self.attn(self.ln1(Z))
Z = Z + self.ffn(self.ln2(Z))
x_cls_p = Z[:, 0:1, :]
x_pro_p = Z[:, 1:2, :]
X_p = Z[:, 2:, :]
return x_cls_p, x_pro_p, X_p
# SECTION 3 Vanilla Transformer Block (VTB)
class VanillaTransformerBlock(nn.Module):
"""Refines CLS and patch tokens without the prompt token present."""
def __init__(self, D: int, H: int):
super().__init__()
self.ln1 = nn.LayerNorm(D)
self.attn = MultiHeadSelfAttention(D, H)
self.ln2 = nn.LayerNorm(D)
self.ffn = FeedForwardNetwork(D)
def forward(self, x_cls: torch.Tensor, X: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
Z = torch.cat([x_cls, X], dim=1)
Z = Z + self.attn(self.ln1(Z))
Z = Z + self.ffn(self.ln2(Z))
return Z[:, 0:1, :], Z[:, 1:, :]
# SECTION 4 Prompt Learning Module
class PromptLearningModule(nn.Module):
"""Refines the prompt token through cross-attention over class prototypes."""
def __init__(self, D: int, d: int = None):
super().__init__()
d = d or D
self.W_Q = nn.Linear(D, d, bias=False)
self.W_K = nn.Linear(D, d, bias=False)
self.W_V = nn.Linear(D, d, bias=False)
self.out_proj = nn.Linear(d, D, bias=False)
self.scale = math.sqrt(d)
self.ln = nn.LayerNorm(D)
def forward(self, x_pro_prime: torch.Tensor, prototypes: torch.Tensor) -> torch.Tensor:
B = x_pro_prime.shape[0]
P = prototypes.unsqueeze(0).expand(B, -1, -1)
Q = self.W_Q(x_pro_prime)
K = self.W_K(P)
V = self.W_V(P)
alpha = torch.softmax(Q @ K.transpose(-2, -1) / self.scale, dim=-1)
attended = alpha @ V
x_pro_next = x_pro_prime + self.out_proj(attended)
return self.ln(x_pro_next)
# SECTION 5 Prototype Learning with EMA Update
class PrototypeLearning(nn.Module):
"""Maintains per-class prototype tokens at each diagnostic level using EMA."""
def __init__(self, C: int, D: int, alpha: float = 0.99):
super().__init__()
self.C = C
self.alpha = alpha
self.register_buffer('prototypes', torch.randn(C, D))
def get_prototypes(self) -> torch.Tensor:
return self.prototypes
@torch.no_grad()
def update(self, x_cls_batch: torch.Tensor, labels: torch.Tensor) -> None:
for c in range(self.C):
mask = labels[:, c].bool()
if mask.sum() > 0:
x_bar_c = x_cls_batch[mask].mean(dim=0)
self.prototypes[c] = (
self.alpha * self.prototypes[c] + (1 - self.alpha) * x_bar_c
)
# SECTION 6 Level-Specific ViT Block
class HierarchicalViTBlock(nn.Module):
"""One complete diagnostic level combining PTB, Prompt Learning, and VTB."""
def __init__(self, D: int, H: int, C_l: int):
super().__init__()
self.ptb = PromptingTransformerBlock(D, H)
self.prompt_learn = PromptLearningModule(D)
self.vtb = VanillaTransformerBlock(D, H)
self.prototype_learn = PrototypeLearning(C_l, D)
self.cls_head = nn.Linear(D, C_l)
self.C_l = C_l
def forward(self, x_cls, x_pro, X, labels=None) -> Dict:
x_cls_p, x_pro_p, X_p = self.ptb(x_cls, x_pro, X)
prototypes = self.prototype_learn.get_prototypes()
x_pro_next = self.prompt_learn(x_pro_p, prototypes)
x_cls_next, X_next = self.vtb(x_cls_p, X_p)
logits = self.cls_head(x_cls_next.squeeze(1))
if labels is not None and self.training:
self.prototype_learn.update(x_cls_next.squeeze(1).detach(), labels)
return {'x_cls': x_cls_next, 'x_pro': x_pro_next, 'X': X_next, 'logits': logits}
# SECTION 7 3D CNN Image Feature Encoder
class BrainMRIEncoder(nn.Module):
"""Maps (B, 5, H, W, D) multi-modal MRI to (B, N, D) tokens."""
def __init__(self, in_channels: int = 5, D: int = 768):
super().__init__()
self.cnn = nn.Sequential(
nn.Conv3d(in_channels, 32, kernel_size=3, stride=2, padding=1),
nn.GroupNorm(8, 32), nn.GELU(),
nn.Conv3d(32, 64, kernel_size=3, stride=2, padding=1),
nn.GroupNorm(16, 64), nn.GELU(),
nn.Conv3d(64, 128, kernel_size=3, stride=2, padding=1),
nn.GroupNorm(16, 128), nn.GELU(),
nn.Conv3d(128, 32, kernel_size=3, stride=2, padding=1),
nn.GroupNorm(8, 32), nn.GELU(),
)
self.token_proj = nn.Linear(32, D)
self.D = D
def forward(self, x: torch.Tensor) -> torch.Tensor:
feat = self.cnn(x)
B, C, H, W, Dp = feat.shape
tokens = feat.permute(0, 2, 3, 4, 1).reshape(B, H * W * Dp, C)
return self.token_proj(tokens)
# SECTION 8 HP2L Full Framework
class HP2L(nn.Module):
"""Three level hierarchical prompt and prototype learning framework.
Level 1 C1 = 4 vascular, occupying, developmental, normal
Level 2 C2 = 6 hemorrhage, infarction, WMH, tumor, degeneration, deformity
Level 3 C3 = 16 fine grained disease subtypes plus normal
"""
def __init__(self, class_hierarchy: List[int] = [4, 6, 16],
D: int = 768, H: int = 12, in_channels: int = 5):
super().__init__()
self.L = len(class_hierarchy)
self.D = D
self.encoder = BrainMRIEncoder(in_channels, D)
self.x_cls_init = nn.Parameter(torch.randn(1, 1, D))
self.x_pro_init = nn.Parameter(torch.randn(1, 1, D))
self.levels = nn.ModuleList([HierarchicalViTBlock(D, H, C_l) for C_l in class_hierarchy])
self.label_smoothing = 0.1
def forward(self, images: torch.Tensor,
labels_per_level: Optional[List[torch.Tensor]] = None) -> Dict:
B = images.shape[0]
X = self.encoder(images)
x_cls = self.x_cls_init.expand(B, -1, -1).clone()
x_pro = self.x_pro_init.expand(B, -1, -1).clone()
logits_per_level, cls_per_level = [], []
for l, level_block in enumerate(self.levels):
labels_l = labels_per_level[l] if labels_per_level else None
out = level_block(x_cls, x_pro, X, labels=labels_l)
x_cls, x_pro, X = out['x_cls'], out['x_pro'], out['X']
logits_per_level.append(out['logits'])
cls_per_level.append(x_cls)
return {'logits_per_level': logits_per_level, 'cls_per_level': cls_per_level}
# SECTION 9 Loss Functions
def level_classification_loss(logits: torch.Tensor, labels: torch.Tensor,
smoothing: float = 0.1) -> torch.Tensor:
"""Level-wise sigmoid binary cross entropy with label smoothing."""
labels_smooth = labels.float() * (1 - smoothing) + 0.5 * smoothing
return F.binary_cross_entropy_with_logits(logits, labels_smooth)
def hierarchy_consistency_loss(logits_per_level, labels_per_level, parent_map) -> torch.Tensor:
"""Asymmetric penalty that only fires when a true child trails its parent."""
consist_loss = torch.tensor(0.0, device=logits_per_level[0].device)
for l in range(len(logits_per_level) - 1):
probs_coarse = torch.sigmoid(logits_per_level[l])
probs_fine = torch.sigmoid(logits_per_level[l + 1])
labels_fine = labels_per_level[l + 1].float()
for child_idx, parent_idx in parent_map[l].items():
if child_idx >= probs_fine.shape[1] or parent_idx >= probs_coarse.shape[1]:
continue
p_child = probs_fine[:, child_idx]
p_parent = probs_coarse[:, parent_idx]
y_child = labels_fine[:, child_idx]
penalty = y_child * torch.clamp(p_parent - p_child, min=0)
consist_loss = consist_loss + penalty.mean()
return consist_loss
def hp2l_total_loss(logits_per_level, labels_per_level, parent_map,
lambda_levels=[1.0, 1.0, 1.0], lambda_consist=0.5,
label_smoothing=0.1) -> Dict:
"""Full training objective, level-wise BCE plus the consistency penalty."""
cls_losses = [
level_classification_loss(logits_per_level[l], labels_per_level[l], label_smoothing)
for l in range(len(logits_per_level))
]
total_cls = sum(lambda_levels[l] * cls_losses[l] for l in range(len(cls_losses)))
consist = hierarchy_consistency_loss(logits_per_level, labels_per_level, parent_map)
total = total_cls + lambda_consist * consist
return {'total': total, 'cls_losses': cls_losses, 'consist': consist}
# SECTION 10 Smoke Test on Synthetic 3D Brain MRI Data
def _smoke_test():
print("=" * 65)
print("HP2L Smoke Test Synthetic 3D Brain MRI Data")
print("Paper Liu et al. Medical Image Analysis 112 (2026) 104063")
print("=" * 65)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
B = 4
H_vol, W_vol, D_vol = 64, 64, 32
D_model = 256
num_heads = 8
class_hierarchy = [4, 6, 16]
images = torch.randn(B, 5, H_vol, W_vol, D_vol, device=device)
labels = [torch.randint(0, 2, (B, C), device=device).float() for C in class_hierarchy]
parent_map = [
{0: 0, 1: 0, 2: 0, 3: 1, 4: 1, 5: 2},
{i: i // 3 for i in range(16)},
]
model = HP2L(class_hierarchy=class_hierarchy, D=D_model, H=num_heads, in_channels=5).to(device)
model.train()
total_params = sum(p.numel() for p in model.parameters())
print(f"\nDevice {device}")
print(f"Total parameters {total_params:,}")
print(f"Input shape {list(images.shape)}")
print(f"Class hierarchy {class_hierarchy}")
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4, weight_decay=1e-2)
out = model(images, labels_per_level=labels)
loss_dict = hp2l_total_loss(out['logits_per_level'], labels, parent_map)
optimizer.zero_grad()
loss_dict['total'].backward()
optimizer.step()
print(f"\n{'-'*45}")
print(f"Total loss {loss_dict['total'].item():.4f}")
print(f"Level 1 cls loss {loss_dict['cls_losses'][0].item():.4f}")
print(f"Level 2 cls loss {loss_dict['cls_losses'][1].item():.4f}")
print(f"Level 3 cls loss {loss_dict['cls_losses'][2].item():.4f}")
print(f"Consistency loss {loss_dict['consist'].item():.4f}")
print(f"Logit shapes {[list(l.shape) for l in out['logits_per_level']]}")
print(f"{'-'*45}")
model.eval()
with torch.no_grad():
out_inf = model(images)
probs = [torch.sigmoid(l) for l in out_inf['logits_per_level']]
print(f"\nInference level 3 mean probability {probs[2].mean().item():.3f}")
print("Smoke test passed. HP2L forward and backward cycles OK.")
print("=" * 65)
if __name__ == '__main__':
_smoke_test()
What this research opens up and where it goes next
The core achievement here is narrower than it might first sound, and that narrowness is exactly what makes it convincing. HP2L does not claim to have solved brain disorder diagnosis. It demonstrates that a specific, well understood failure mode in hierarchical classification, error propagation, can be measurably reduced by letting evidence flow both up and down a diagnostic hierarchy instead of only downward. The 8.42 point gain over the strongest prior method, on 54360 subjects spanning 23 disorders with heavy class imbalance, is large enough that it is unlikely to be noise, and the external cohort results suggest the gain survives contact with hospitals the model never trained on.
The conceptual shift underneath the numbers matters as much as the numbers themselves. Flat classification treats a diagnosis as one flat guess. Rigid hierarchical classification treats it as a sequence of guesses where an early mistake becomes permanent. HP2L treats it as a conversation between levels, where the model is allowed to reconsider an early impression once better evidence shows up. That framing is closer to how an actual radiologist works through an ambiguous scan, revising an initial impression as more detail becomes visible, rather than committing to a first guess and defending it regardless of what comes next.
The approach is not obviously specific to brain imaging. Any domain with a natural taxonomy and severe class imbalance, chest imaging with its overlapping infectious and structural findings, dermatology with fine grained lesion subtypes, pathology slides with nested tumor grading systems, could plausibly benefit from the same prompt and prototype structure. Nothing about the cross attention refinement step or the exponential moving average is anatomically specific to the brain. That transferability is speculative rather than demonstrated in this paper, and it would need its own validation work before anyone should build on it for a different organ system.
The honest limitations carry real weight and should not be read as a formality. Tiny lesions below the attention mechanism’s effective resolution, overlapping subtypes with similar imaging signatures, and under detected comorbid findings are all still open problems, not solved ones. A single expert defined hierarchy was tested rather than several competing taxonomies. Inter disease dependency, the fact that some conditions genuinely predict others, is explicitly left for future work rather than addressed here. And the computational cost, four 40GB GPUs for training, is a real barrier to smaller institutions replicating or extending this work without external support.
The larger argument this paper is making is about what kind of structure is worth building into medical AI in the first place. Flat classifiers are convenient because they require no decisions about how disease categories relate to each other. HP2L requires exactly those decisions, and argues they are worth making. A model organized around clinically meaningful relationships between diagnoses turns out to be more accurate on rare classes, more interpretable through its attention maps, and apparently more robust across institutions than one that treats diagnosis as an unstructured label assignment problem. That is a strong claim, and it is backed here by a genuinely large and diverse evaluation rather than a single benchmark table, which is what makes it worth taking seriously.
Frequently asked questions
What is HP2L in plain terms
HP2L is a hierarchical prompt and prototype learning framework built by researchers at ShanghaiTech University to classify brain disorders from MRI scans across three diagnostic levels, going from a broad category down to a specific subtype, in a single forward pass through the model.
How many brain disorders can HP2L classify
HP2L classifies 23 brain disorders organized into three levels, a broad level with 4 categories, a middle level with 6 categories, and a fine grained level with 16 categories covering the full set of subtypes plus a normal class.
How accurate is HP2L compared with other methods
HP2L reaches 88.43 percent balanced accuracy at the fine grained level, more than 8 percentage points ahead of the strongest prior hierarchical method tested in the paper, and its accuracy drops only 2.02 percent moving from the broadest level to the finest one, far less than any competing method.
Does HP2L replace a radiologist
No. HP2L is a research framework evaluated on retrospective data. It has not undergone prospective clinical validation or regulatory review, and the published results describe a benchmark study rather than a deployed diagnostic tool. Any real diagnosis should come from a qualified physician or radiologist.
What is prototype learning and why does it help with rare diseases
Prototype learning keeps a running representation of what each disease class looks like in the model’s learned feature space, updated after every batch using an exponential moving average. That moving average keeps the representation stable even when a rare class such as penetrating deformity appears in only a handful of training examples per batch.
Where can I read the full paper
The full paper is published in Medical Image Analysis and is linked directly below, along with the authors’ code and data release where available.
The paper itself, with the full ablation tables and per disorder AUC breakdowns, is available through its DOI at doi.org/10.1016/j.media.2026.104063, and it is worth reading directly rather than relying only on a summary, especially for anyone considering this approach for a different imaging domain.
Read the full paper and access the official code
The complete HP2L paper, supplementary analyses, and the official code and data release are available through the links below.
Liu Y., Sun K., Wu Y., Lin X., Bai Y., Yang L., Zhou W., Yuan H., Wu X., He Y., Wu Q., Che Z., Zhan Y., Zhou S., Wu D., Shi F., Wang M., and Shen D. (2026). A hierarchical prompt and prototype learning framework for brain disorder classification. Medical Image Analysis, 112, 104063. doi.org/10.1016/j.media.2026.104063
This analysis is based on the published paper and an independent evaluation of its claims. The PyTorch implementation above is an educational reproduction built from the paper’s described equations and may differ from the authors’ own repository in engineering detail. Verify against the official code and the original paper before using this for research. The underlying work was supported by the National Natural Science Foundation of China and the China Ministry of Science and Technology, as stated in the paper’s acknowledgments.
This piece also belongs in the site’s Medical AI hub alongside other coverage in the same pillar, and it sits under the broader Machine Learning category.