Key points
- Multimodal intent recognition combines text, audio, and video to infer what a person actually means, and most existing methods fuse all three with fixed weights regardless of how reliable each one is on a given sample.
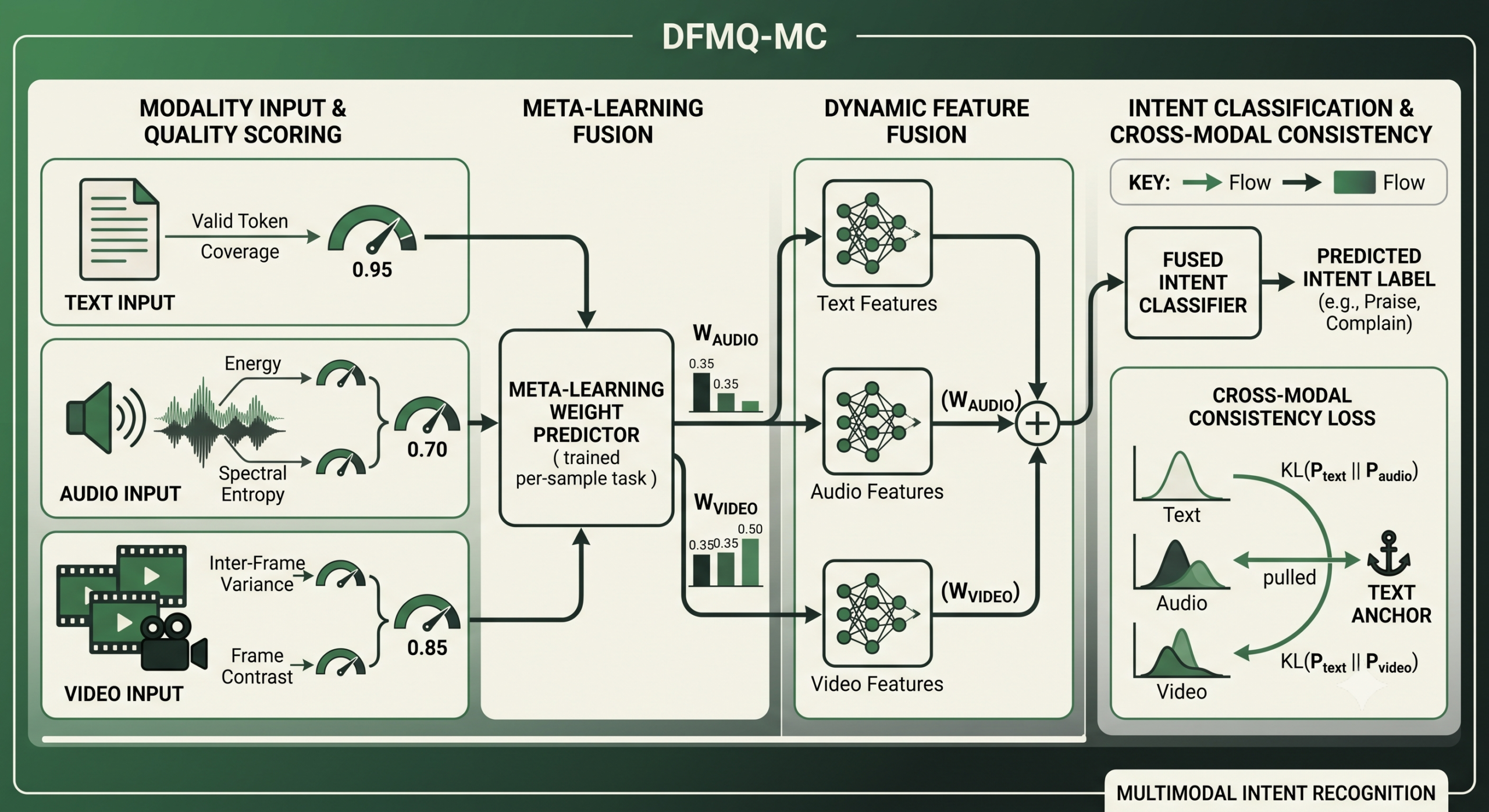
- DFMQ-MC scores the quality of each modality directly from measurable signal properties, valid token coverage for text, energy and spectral entropy for audio, and inter frame variance plus contrast for video.
- A meta learning weight predictor trained with a first order variant of model agnostic meta learning turns those quality scores into fusion weights, adapting per sample rather than relying on one fixed weighting scheme for the whole dataset.
- A cross modal consistency loss uses the text prediction as a semantic anchor and pulls the audio and video prediction distributions toward it with KL divergence, without ever hard replacing their features.
- On two public benchmarks, MIntRec and MELD-DA, the model edges out eight established baselines and a fine tuned large multimodal model, while using a small fraction of the parameters and GPU memory those larger models require.
Why intent recognition needs more than just the words
Multimodal intent recognition tries to figure out what someone is actually trying to accomplish in a conversation, whether they are complaining, joking, apologizing, or asking for help, by reading text, audio, and video together rather than text alone. The appeal is obvious. A sentence can carry sarcasm through tone of voice or hesitation through facial expression that the words by themselves would never reveal. Systems built this way get used in customer service platforms and human computer interaction research precisely because real conversations are full of these gaps between what is said and how it is said.
The field has produced a genuinely useful line of methods to model these cross modal interactions. MulT models directional attention between modalities, MAG-BERT injects non-verbal signals into a BERT-based text representation through an adaptive gate, MISA separates out representations that are shared across modalities from ones that are specific to each, and MMIM adds a mutual information objective to keep modalities aligned. More recent, task-specific systems push further still. TCL-MAP converts audio and video features into prompt-like vectors so a language model style encoder can reason over them together with contrastive learning. SDIF-DA aligns modalities progressively from shallow to deep representations. MIntOOD adds robustness against out of distribution samples through a two stage fusion pipeline.
Despite that progress, the paper argues two problems have gone mostly unaddressed. First, almost every one of these methods treats every modality as equally trustworthy on every sample, when in practice audio picks up background noise, video frames blur, and text can be clipped or incomplete, and none of that gets accounted for in how strongly each modality’s signal gets weighted during fusion. Second, even methods that do try some form of dynamic weighting rarely impose any explicit constraint that keeps the final predictions from each modality pointing in a semantically compatible direction, so a model can end up trusting a noisy, misleading modality simply because nothing in the training objective tells it not to.
Scoring each modality before you trust it
DFMQ-MC’s first move is to stop assuming every modality is reliable and instead measure it. The paper builds a separate, interpretable quality metric for each of the three modalities, each one grounded in a concrete, measurable signal property rather than a learned black box score.
Text quality as content completeness
Because text tends to be the clearest and least ambiguous modality, its quality metric is kept correspondingly simple, a measure of how much of the input sequence is actual content rather than padding.
A sample with a short, clipped utterance scores lower here, and a fully formed sentence scores close to one, giving the model a direct signal for how much semantic content it actually has to work with from the text channel.
Audio quality from energy and spectral entropy
Audio quality is judged along two different axes that the paper treats as complementary. Signal energy captures how clear and strong the audio actually is, computed as the mean of the L2 norm of the audio features and passed through a sigmoid centered on the batch average energy. Spectral entropy captures how much information the frequency content actually carries, working from the intuition that pure noise tends to spread energy flatly across the whole spectrum, producing high entropy, while a clean, structured voice signal concentrates energy in fewer, more distinctive frequency bands.
Video quality from motion and contrast
Video quality draws on two properties as well, temporal variance and spatial contrast. If a face barely changes across a sequence of frames, that often signals a blurred, motion smeared clip rather than genuine stillness, since real facial movement during speech produces measurable frame to frame variation. Contrast measured as the standard deviation of pixel values within each frame catches the opposite failure, an overexposed or underexposed frame that has lost the detail a model would need to read an expression at all.
All three scores get normalized to a common zero to one range and packed into a small quality feature vector per sample, one value each for text, audio, and video, which becomes the direct input to the weighting mechanism described next.
Turning quality scores into fusion weights with meta learning
Having a quality score for each modality only helps if the model actually changes its behavior in response to it. DFMQ-MC’s answer is a compact weight predictor, essentially two linear layers with a ReLU in between, trained using a first order variant of model agnostic meta learning, commonly abbreviated MAML.
What makes this an interesting application of meta learning rather than a standard classifier is what counts as a task. Ordinary meta learning setups train across genuinely different tasks, learning to classify new categories of images the model has never seen, for instance. Here, each individual training sample is treated as its own tiny subtask, with its own particular combination of text completeness, audio clarity, and video sharpness. The weight predictor is meta trained across many of these micro subtasks, each split into a small support set for fast inner loop adaptation and a query set for the outer loop update that actually shapes the shared initialization. The practical payoff is a weight predictor that has effectively learned how to react to any new combination of modality quality values it encounters at test time, without needing to memorize a lookup table of specific quality combinations from training.
The paper opts for first order MAML specifically to keep the computational cost manageable, reducing the complexity of the meta gradient computation from quadratic to linear in the parameter dimension. At inference time the whole meta learning machinery disappears, the trained predictor just runs forward once like an ordinary small network, so none of this adds meaningful latency once training is done.
Text does not receive a dynamically predicted weight the way audio and video do. Instead, the weighted combination of audio and video features is added to the text representation through a residual connection, which keeps text functioning as the stable backbone of the fusion process while audio and video contribute variable, quality-gated amounts on top of it.
Keeping predictions from three modalities pointing the same direction
Weighting modalities correctly at the feature level does not automatically stop them from disagreeing at the prediction level. Text describing a compliment can still get paired with a flat, low energy voice or a blurry, expressionless face, and without some explicit constraint a model has no particular reason to reconcile those signals into one coherent judgment. DFMQ-MC addresses this with a second mechanism operating directly on the loss function rather than on the features themselves.
Each of the three modalities produces its own unimodal prediction distribution through a separate branch, with text converted to a distribution via log softmax and audio and video via ordinary softmax. Text is treated as the semantic anchor, the modality whose prediction is taken as closest to ground truth because of its structured, low ambiguity nature, and Kullback Leibler divergence measures how far the audio and video prediction distributions have drifted from it.
Because KL divergence is asymmetric, this setup specifically pulls audio and video toward text rather than averaging all three toward some blended middle ground, which matters because text is the modality the paper trusts most as a semantic reference point. Importantly, this is a soft regularization term added into the total training loss alongside the ordinary classification loss, not a hard replacement of the audio or video features with text derived ones. The independent audio and video branches remain in place throughout training, so whatever corrective, non-verbal signal they carry is preserved as a complementary contribution to the final prediction rather than erased in favor of text.
The full training objective
Four separate loss terms get combined into one weighted total, a classification loss that supervises the fused prediction against the true intent label, a contrastive loss that pulls same class samples closer together in feature space and pushes different classes apart, the meta learning loss that trains the weight predictor itself, and the modal consistency loss described above.
Two hyperparameters, one for the meta learning term and one for the modal consistency term, control how strongly each of those two more specialized objectives influences training relative to the core classification and contrastive signals.
How it performs against the field
The team tested on two datasets with quite different characteristics. MIntRec draws its raw footage from the television series Superstore, comprising 2224 samples across 20 fine grained intent categories such as complain, praise, apologize, and joke. MELD-DA is a derived subset of the MELD dataset pulled from Friends, with 1433 complete dialogues and 13,708 individual utterances covering 12 broader dialogue act categories such as question, agreement, and backchannel.
Beating established baselines and a fine tuned large model
| Method | MIntRec Acc | MIntRec F1 | MELD-DA Acc | MELD-DA F1 |
|---|---|---|---|---|
| MISA | 71.59 | 68.74 | 60.16 | 51.25 |
| MAG-BERT | 72.12 | 67.95 | 61.08 | 50.38 |
| MulT | 71.37 | 68.89 | 59.61 | 51.02 |
| TCL-MAP | 73.08 | 69.65 | 60.67 | 50.49 |
| SDIF-DA | 70.52 | 67.33 | 61.77 | 50.82 |
| MIntOOD | 71.78 | 68.14 | 61.19 | 49.91 |
| MMIM | 71.91 | 69.10 | 60.51 | 50.23 |
| A-MESS | 72.25 | 68.51 | 59.96 | 52.36 |
| Qwen3-VL, fine tuned | 73.71 | 70.72 | 61.28 | 50.78 |
| DFMQ-MC | 74.38 | 71.66 | 62.06 | 53.16 |
On MIntRec, DFMQ-MC’s 74.38 accuracy beats the strongest prior specialized baseline, TCL-MAP at 73.08, and also edges past a fully fine tuned Qwen3-VL at 73.71, a large vision language model with billions of parameters that had to be specifically adapted to this task. The paper attributes the gain over TCL-MAP specifically to the dynamic weighting mechanism responding to per sample modality quality rather than applying one fixed fusion strategy across the whole dataset. On the more class-imbalanced MELD-DA dataset, the F1 gain is the more telling number, DFMQ-MC’s 53.16 clears the previous best, A-MESS at 52.36, and the paper connects this specifically to the modal consistency constraint reducing the model’s tendency to misclassify minority intent categories, a plausible mechanism since a text anchored consistency signal should help stabilize predictions precisely on the harder, less frequent classes where audio and video signals are noisiest.
Two general purpose multimodal large language models were also tested in a pure zero shot setting without any fine tuning, MiniCPM-o 2.6 and Qwen3-VL, both at roughly 8 billion parameters. Both scored well below every specialized baseline, MiniCPM-o 2.6 reaching only 53.48 accuracy on MIntRec and Qwen3-VL reaching 61.12, which is a useful reminder that raw scale in a general purpose multimodal model does not automatically translate into strong performance on a specialized, fine grained classification task like this one without task specific training.
What the ablations actually isolate
| Variant | MIntRec Acc | Change vs full | MIntRec F1 | Change vs full |
|---|---|---|---|---|
| Equal weight fusion, no dynamic weighting | 70.79 | −3.59 | 65.70 | −5.96 |
| No modality quality module at all | 72.49 | −1.89 | 68.34 | −3.32 |
| No modal consistency loss | 73.71 | −0.67 | 68.65 | −3.01 |
| Full DFMQ-MC | 74.38 | – | 71.66 | – |
The largest single drop, nearly six points of F1, comes from replacing the dynamic weighting with plain equal weighting across modalities, which is a fairly strong confirmation that the core premise of the paper, that modality reliability genuinely varies sample to sample and matters for fusion quality, is doing real work rather than just adding architectural complexity for a marginal gain. Removing the modal consistency loss specifically produces a comparatively modest accuracy drop but a much larger F1 drop, three points, which lines up with the earlier explanation that its main benefit shows up on harder, less frequent classes rather than uniformly across all categories.
Checking whether the text anchor suppresses other modalities
An anchoring design like this raises a fair concern, that leaning on text so heavily might quietly erase whatever useful signal audio and video actually carry, especially on the hardest cases where text and non-verbal cues genuinely conflict. The paper tests this directly on a set of intent categories chosen specifically because they tend to involve semantic mismatch between what is said and how it is delivered, criticize, flaunt, taunt, and joke.
| Method | Criticise | Flaunt | Taunt | Joke |
|---|---|---|---|---|
| MISA | 0.4906 | 0.4800 | 0.2215 | 0.3874 |
| MMIM | 0.4583 | 0.5000 | 0.1111 | 0.5387 |
| SDIF-DA | 0.3810 | 0.5556 | 0.2838 | 0.4706 |
| TCL-MAP | 0.5283 | 0.5130 | 0.1720 | 0.2900 |
| A-MESS | 0.5232 | 0.3158 | 0.2667 | 0.5556 |
| DFMQ-MC | 0.5306 | 0.5714 | 0.2727 | 0.5455 |
DFMQ-MC leads on criticize and flaunt and stays competitive rather than falling behind on taunt and joke, where SDIF-DA and A-MESS respectively post the single best score. That is a genuinely honest result to report, the text anchored consistency constraint clearly does not collapse performance on exactly the samples where text and non-verbal cues would be expected to disagree most, but it also does not dominate every one of these hard categories outright, and the paper is straightforward about presenting it that way rather than cherry picking only the categories where it wins.
Efficiency, the practical argument for a smaller model
| Method | Parameters, millions | GPU memory, MB | Training time per epoch, seconds | Samples per second |
|---|---|---|---|---|
| MiniCPM-o 2.6, inference only | 8622.08 | 20724.46 | 550.05 | 0.81 |
| Qwen3-VL, fine tuned | 8788.95 | 18776.02 | 839.64 | 1.589 |
| Qwen3-VL, inference only | 8980.48 | 16730.16 | 2411.32 | 0.18 |
| DFMQ-MC | 263.85 | 7917.29 | 212.52 | 29.10 |
This is arguably the most practically relevant table in the paper. DFMQ-MC uses roughly 264 million parameters against the 8 to 9 billion parameters the large multimodal models require, fits comfortably on a single consumer grade RTX 4090 with about 7.7 gigabytes of memory, and processes samples at more than 29 per second, translating to roughly 7.5 milliseconds of latency per sample on the full test set. For anyone deploying an intent recognition system that needs to respond in real time, that gap in resource requirements is arguably as important as the accuracy numbers, since it is the difference between running on a single workstation GPU and needing data center grade hardware just to serve inference.
Holding up under noise
| Noise level added to audio and video | MIntRec Acc | Drop from clean |
|---|---|---|
| None, clean input | 74.38 | – |
| Mild, 0.3 | 73.48 | −0.90 |
| Moderate, 0.5 | 72.81 | −1.57 |
| Severe, 0.7 | 70.56 | −3.82 |
Injecting synthetic Gaussian noise directly into audio and video at increasing intensities produces a gradual, contained degradation rather than a cliff, with accuracy dropping under four points even at the most severe noise level tested. The paper reasonably attributes this stability to the quality aware weighting mechanism doing exactly what it was designed to do, automatically assigning lower fusion weight to a modality once its measured quality drops, rather than continuing to trust a modality that has become unreliable.
Honest limitations
The paper devotes a dedicated section to limitations rather than folding them quietly into a single sentence, and three specific gaps stand out. The model has not been validated on open domain visual tasks such as pure visual understanding, image to text generation, or complex visual reasoning, so its demonstrated generalization is currently confined to conversational intent classification rather than broader multimodal understanding. The robustness testing relies entirely on synthetic Gaussian noise added to audio and video, which the authors themselves note is a simplified stand in for the kinds of degradation that actually show up in the field, motion blur, occlusion, and genuine environmental noise, none of which were tested here. And despite the model’s comparatively lightweight design relative to large multimodal models, the authors flag that its deployment efficiency on genuinely resource constrained edge or mobile hardware still needs further optimization rather than being solved by this design alone.
A few additional points are worth naming plainly. The hard sample analysis on criticize, flaunt, taunt, and joke shows real, specific cases where competing methods still post the single best score, which is useful context against any framing that DFMQ-MC simply wins everywhere. And the comparison against fine tuned Qwen3-VL, while favorable overall, does show that model slightly ahead of DFMQ-MC on a few individual metrics on MIntRec even though DFMQ-MC leads on the headline accuracy and F1 numbers, another instance where the paper’s own tables show a more nuanced picture than a single summary sentence would suggest.
Takeaway for practitioners
If your multimodal pipeline already struggles specifically when one input channel is degraded, a background noisy call, a poorly lit video feed, building in an explicit, measurable per-sample quality score for each modality before fusion is a comparatively simple change with a large demonstrated payoff here, nearly six points of F1 in the ablation against naive equal weighting.
Takeaway on the theory
Treating each individual training sample as its own meta learning subtask, rather than reserving meta learning for cross task or cross domain transfer, is a genuinely underused framing that could apply to any setting where the reliability of an input signal varies unpredictably from one example to the next, well beyond multimodal intent recognition specifically.
Where this could go next
The specific system here targets conversational intent classification, but the two core mechanisms are more broadly transferable ideas. Quantifying input reliability directly from measurable, interpretable signal properties rather than learning an opaque quality score, and then feeding that measurement into a lightweight, meta learned predictor that adapts per sample, is an approach that could plausibly extend to any multimodal task where different input channels degrade independently and unpredictably, sensor fusion in robotics or autonomous systems being one obvious candidate the paper itself does not test.
The text anchored consistency constraint is a narrower idea specific to settings where one modality genuinely does carry more reliable, lower ambiguity semantic content than the others, which is a reasonable assumption for text against audio and video in a conversational setting, but would need real rethinking in domains where no single modality holds that kind of privileged status.
The honest limitations the authors name, no testing on genuinely realistic degradation types like occlusion or motion blur, and no validation outside conversational intent classification, are the natural next experiments for anyone looking to build on this work rather than simply cite it. Until that testing happens, the strongest claim this paper actually supports is narrower than a headline reading of the abstract might suggest, that quality aware dynamic fusion and text anchored consistency constraints measurably beat fixed weight fusion specifically on conversational multimodal intent recognition, tested against synthetic rather than naturally occurring degradation.
Read the full paper for the complete meta training procedure, all six ablation and robustness tables, and the confusion matrices for both datasets.
A minimal PyTorch implementation
Below is a compact, runnable sketch of the core ideas, the three modality quality scoring functions, a small meta learned weight predictor, and the text anchored KL consistency loss. It favors clarity over matching the paper’s exact backbone encoders, and it includes a smoke test on random dummy data.
Conclusion
The real contribution here is a shift in what gets treated as a design decision versus what gets treated as a measurable, sample specific property. Most prior multimodal intent systems bake fusion weighting in as a fixed architectural choice, made once at design time and applied uniformly to every input the model ever sees. DFMQ-MC instead treats modality reliability as something to measure per sample, using signal properties that are simple enough to compute directly and interpret plainly, valid token coverage, audio energy and entropy, frame to frame variance and contrast, and then hands that measurement to a lightweight meta learned predictor that adapts its weighting behavior sample by sample rather than dataset by dataset.
The second piece, anchoring cross modal consistency on text through an asymmetric KL divergence rather than symmetric feature averaging, is a smaller but genuinely useful idea in its own right. It gives the model a principled way to lean on the modality it has the most reason to trust without silencing the other two, which the hard sample analysis on categories like criticize and flaunt suggests is a real distinction rather than just a theoretical one.
None of this comes without real caveats, and the paper names them directly rather than tucking them away. Robustness testing here used synthetic Gaussian noise rather than the messier degradation that shows up in genuinely field collected audio and video, the model has not been tested outside conversational intent classification, and a fine tuned large multimodal model still edges it out on a handful of individual metrics even though DFMQ-MC leads on the primary accuracy and F1 numbers. What the results do support convincingly is the narrower and still valuable claim that quality aware dynamic fusion beats fixed weight fusion, and that a lightweight, purpose built model can match or beat a fine tuned billion parameter multimodal model on this specific task while needing a small fraction of the compute and memory to do it.
Whether the idea of per sample meta learned reliability weighting generalizes past this specific combination of text, audio, and video will depend on how it holds up in domains where degradation is messier and less controllable than an injected noise parameter, sensor fusion in robotics being an obvious next test the authors themselves have not run. The underlying idea, that reliability is a property of the specific input in front of you rather than a fixed property of the modality itself, is general enough that it is worth watching for in other multimodal settings well beyond intent recognition.
Frequently asked questions
What is multimodal intent recognition
It is the task of identifying what someone is trying to communicate, such as complaining, praising, or asking for help, by jointly analyzing text, audio, and video from an interaction rather than relying on the words alone, since tone of voice and facial expression can carry meaning the text by itself would miss.
How does DFMQ-MC measure the quality of each modality
It uses a separate, interpretable metric for each modality computed directly from measurable signal properties, the proportion of valid, non-padding tokens for text, a combination of signal energy and spectral entropy for audio, and a combination of inter-frame variance and intra-frame contrast for video.
Why does the model use meta learning to predict fusion weights
Each individual training sample is treated as its own small subtask with a unique combination of modality quality values, and a first order variant of model agnostic meta learning trains a shared, adaptable initialization across many of these per sample subtasks, so the weight predictor generalizes to new quality combinations at test time rather than memorizing patterns from specific training samples.
Why is text used as the anchor for cross modal consistency instead of averaging all three modalities
Text tends to carry more structured and less ambiguous semantic content than audio or video, so an asymmetric KL divergence term pulls the audio and video prediction distributions toward the text distribution specifically, rather than blending all three toward some shared middle ground, while still keeping the independent audio and video branches intact.
Does DFMQ-MC beat every baseline on every metric
No. It leads on the primary accuracy and F1 metrics on both benchmarks tested, but a fine tuned Qwen3-VL model edges it out on a few individual metrics on the MIntRec dataset, and on a set of semantically ambiguous intent categories such as taunt and joke, other baseline methods post the single best score on individual categories even though DFMQ-MC remains competitive overall.
How much computational cost does this model need compared to large multimodal models
DFMQ-MC uses about 264 million parameters and roughly 7.7 gigabytes of GPU memory, compared to the 8 to 9 billion parameters and 16 to 21 gigabytes of memory the compared large multimodal models required, and it runs at more than 29 samples per second versus under 2 samples per second for the large models tested.
Gou, Z., Jia, M., Xue, X., and Wang, Y. DFMQ-MC, dynamic fusion based on modality quality and cross-modal semantic consistency for multimodal intent recognition. Knowledge-Based Systems, volume 349, 2026, article 116472, DOI 10.1016/j.knosys.2026.116472. This analysis is based on the published paper and an independent evaluation of its claims.