Key points
- Deterministic flow matching models, the fast alternative to iterative diffusion sampling, mathematically converge toward an averaged, over smoothed prediction rather than a single sharp reconstruction.
- Existing mixture of experts restorers route entire images to experts, and on real composite inputs the four experts in a leading baseline activate almost equally, a measured selectivity ratio of only 1.2 times.
- F2D-Net factorizes the restoration flow into a shared backbone plus four lightweight experts, assembled separately at every pixel rather than once per image, pushing that same selectivity ratio to roughly 10 times.
- A new multiplicative noise schedule scales its own magnitude to the remaining error, staying large early and provably contracting to exactly zero at the clean target, which a closed form solution turns into single step inference.
- On the CDD-11 composite degradation benchmark F2D-Net posts the best SSIM, LPIPS, and FID at every complexity tier while trailing the strongest PSNR baseline by roughly a third of a decibel, a genuine tradeoff the paper documents rather than hides.
Why one photo can have four problems at once
All in one image restoration is the idea of training a single network that can fix rain, haze, low light, snow, blur, or noise without needing a separate specialist model for each. It works well when a test image genuinely has just one of those problems. Real photographs are rarely that considerate. A dashcam frame shot at night in a snowstorm carries low light, snow streaks, and often haze all layered on top of each other in the same pixels. A benchmark called CDD-11 was built specifically to test this harder, more realistic scenario, combining low light, haze, rain, and snow into eleven configurations, four single degradations, five pairwise combinations, and two triple combinations, and the benchmark’s own results showed existing all in one methods losing significant accuracy as the number of overlapping degradations climbed from one to three.
The authors did not just note that models get worse on harder inputs, which would not be surprising on its own. They went looking for the actual mechanism behind the failure, and found two distinct causes operating independently.
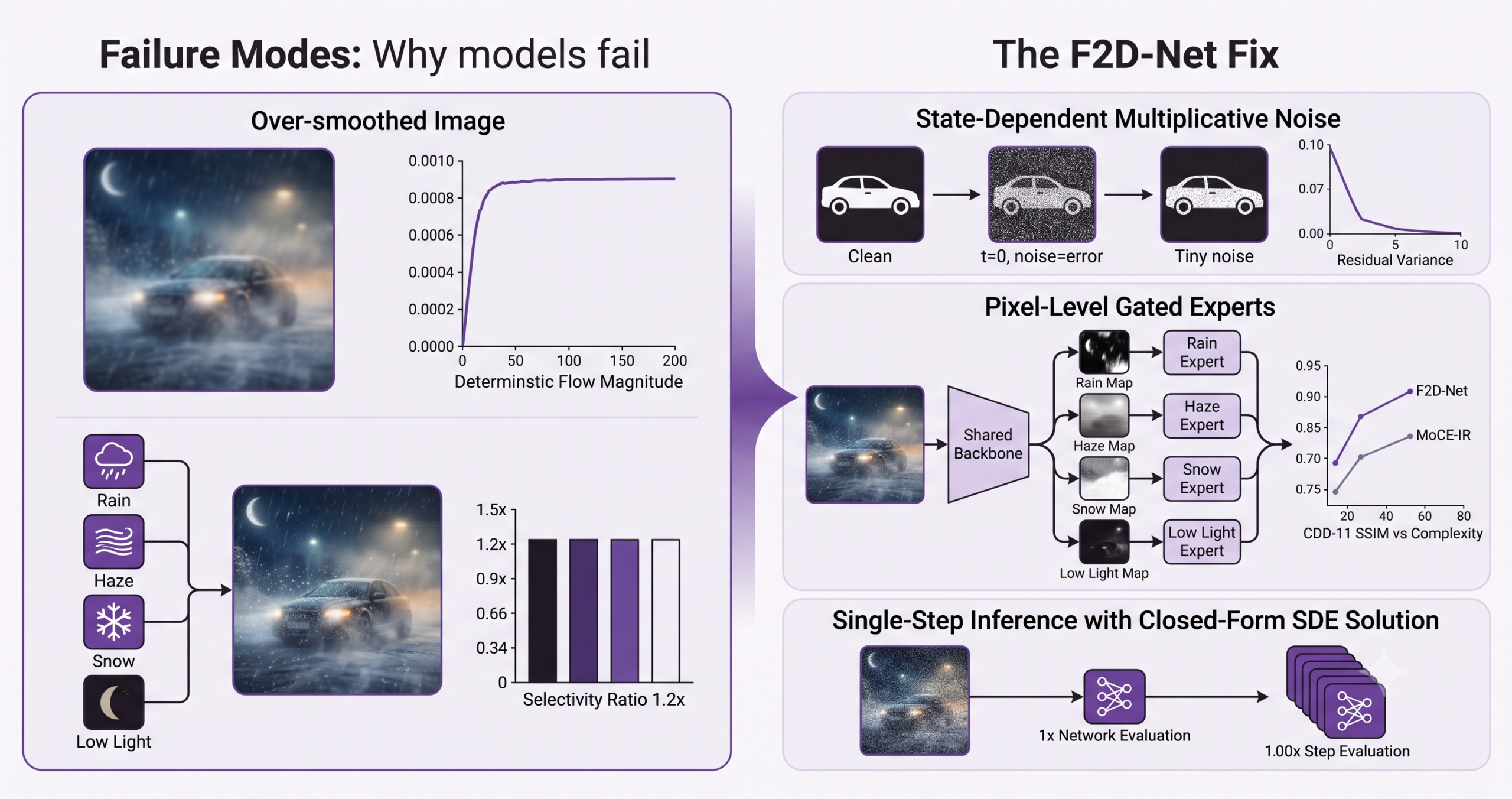
Failure mode one, deterministic transport averages away the answer
Modern fast restoration models increasingly rely on flow matching, a technique that learns a velocity field pointing from a degraded image toward a clean one and then follows that field with a simple, deterministic differential equation rather than the slow, iterative sampling diffusion models need. The problem is that restoration is often ambiguous. Given a hazy patch of sky, there may be several equally plausible clean reconstructions, and a deterministic velocity field trained to minimize average error learns to point toward the average of those plausible answers rather than committing to any one of them. The paper verifies this directly by training a standard flow matching model on CDD-11 and tracking the magnitude of its learned velocity as the transport process approaches completion. If the model had actually converged on the correct answer, that magnitude should shrink to zero. Instead it plateaus at a stubbornly non-negligible value, direct evidence that the model is still hedging between multiple feasible reconstructions rather than committing to one, which shows up visually as over smoothed, low detail output.
Failure mode two, routing an entire image to one expert throws away spatial information
The second failure mode comes from how existing mixture of experts restorers make routing decisions. A representative recent method called MoCE-IR assigns activation weights to a fixed set of specialist experts, but it does so once per image rather than once per pixel. The authors measured what that produces on a genuinely composite input, a photograph combining low light, haze, and rain. All four experts, including the snow expert that has no business being active on an image with no snow in it, received close to equal activation weight. The measured selectivity ratio, essentially how much more the most relevant expert fires compared to the least relevant one, came out to just 1.2 times, barely distinguishable from uniform. Image level routing simply cannot express the fact that the rain in the image lives in one region of the frame and the haze lives diffusely across the whole scene, because it is only allowed to make one decision for the entire picture.
The fix, noise that knows when to stop and experts that get a vote per pixel
F2D-Net, short for factorized stochastic transport, addresses both failure modes with two separate mechanisms bolted onto the same underlying transport process.
From additive noise to noise that shrinks with the residual
Classical mean reverting stochastic differential equations, the kind used in some diffusion restoration variants, drive a state toward a target mean while adding a constant amount of noise at every step. The paper shows mathematically why that does not work for restoration. With constant additive noise, the process converges to a distribution centered on the clean target but with a nonzero steady state variance, meaning the model can never actually land exactly on the clean image, only somewhere in a cloud around it.
The fix is conceptually simple even though the analysis behind it is careful. Instead of adding a constant amount of noise, scale the noise by how far the current state still is from the clean target. Far from the target, the noise stays large, which is exactly when the model needs room to explore multiple plausible reconstructions. Close to the target, the noise shrinks automatically, without needing any hand tuned schedule, because it is multiplied by a residual that is itself approaching zero.
This small change has a large mathematical payoff. The resulting stochastic differential equation has a closed form solution, meaning the state at any later time can be computed directly from the state at an earlier time without numerically integrating step by step, because each pixel channel’s residual behaves like a geometric Brownian motion with a known log normal distribution.
The paper proves two useful consequences of this structure. First, the log magnitude of the residual at any time follows a known normal distribution, which is what makes the closed form solution possible in the first place. Second, and more practically important, under a schedule condition the paper specifies, the expected magnitude of the residual contracts exponentially toward zero, and so does its variance, which is the formal guarantee that this noise design actually delivers exact recovery at the end of the process rather than converging to a fuzzy cloud around the answer the way constant additive noise does.
Why the loss function needed a rethink too
Having a closed form log normal transition is only useful if the training objective plays nicely with it. The most direct approach borrowed from diffusion model training would minimize a KL divergence in log space, since the target transition is a log normal distribution. The paper works through this option and finds it numerically ill behaved. Because the true residual is contracting toward zero over the course of training, exactly the design goal of the whole scheme, a log space loss ends up putting nearly unbounded weight on residuals that have already gotten very small, since the log of a tiny number changes enormously for even a tiny absolute error near it. Elements that have essentially already converged keep dominating the gradient, starving the elements that still genuinely need correcting. The paper’s answer is to train instead with a plain mean squared error directly on the residual in the original pixel space, which naturally keeps the gradient budget on the parts of the image that still need work rather than the parts that are already fixed.
Splitting the flow into a shared backbone and four specialists
The second half of the fix addresses the routing problem directly by changing where routing decisions get made. Instead of a single per-image weight for each expert, F2D-Net produces a full resolution spatial intensity map for every one of the four atomic degradation types, low light, haze, rain, and snow, alongside a set of global weights that indicate roughly how strongly each degradation is present overall. A lightweight CNN parser, containing well under half a million parameters, reads the degraded input once and produces both outputs in a single forward pass. Because the parser uses a sigmoid rather than a softmax over the global weights, an image with both rain and haze can activate both experts simultaneously rather than being forced to split its attention as if the two degradations were mutually exclusive categories.
The shared backbone handles degradation agnostic restoration, essentially generic denoising and detail recovery that every task benefits from, while each of the four lightweight expert branches only has to learn the residual correction specific to its own degradation type. A visualized example in the paper on a low light, haze, and snow composite shows the spatial maps behaving exactly as intended, low light and haze producing broad, scene spanning activation while snow activates only in the sparse locations where individual snow particles actually sit, and the absent rain degradation correctly suppressed to a near zero global weight.
Timing matters too, not just location
A second, smaller gating mechanism handles when each expert should act rather than just where. Early in the restoration process aggressive correction makes sense, while late in the process conservative refinement avoids introducing new artifacts on an image that is already mostly clean. F2D-Net learns a softmax weighted allocation across the active experts conditioned jointly on the transport time and the degradation profile, so a heavily snowed and hazed scene might see its snow expert peak early and its haze expert peak midway through the reconstruction trajectory, an ordering the paper reports emerging naturally from the training objective without being explicitly imposed.
Why factorizing the flow, not just the network, matters
A subtle but important design choice is that the mixture of experts structure operates on the restoration velocity field itself rather than being one more architectural block bolted onto a generic network. This means the factorization inherits a theoretical justification from a known property of flow matching called vector additivity, where the optimal velocity field for a mixture distribution decomposes into a weighted sum of the optimal velocities for each component. Real composite degradations interact nonlinearly rather than adding up perfectly, so the paper treats this as a useful inductive bias rather than a literal law, and includes a formal bound on how much approximation error that simplification introduces, split into a term the shared backbone must absorb and a term each expert must absorb.
How well it actually performs
The team tested three broad settings, a standard three task all in one benchmark, an extended five task version, and the harder CDD-11 composite benchmark, then followed up with two real world generalization tests.
Three task and five task all in one restoration
| Task | Metric | Best other baseline | F2D-Net |
|---|---|---|---|
| Dehaze, SOTS | PSNR | MoCE-IR, 31.34 | 31.40 |
| Derain, Rain100L | PSNR | MoCE-IR, 38.57 | 37.62 |
| Denoise, sigma 15 | PSNR | MoCE-IR, 34.11 | 34.48 |
| Denoise, sigma 25 | PSNR | MoCE-IR, 31.45 | 31.74 |
| Denoise, sigma 50 | PSNR | MoCE-IR, 28.18 | 28.35 |
F2D-Net wins four of the five three task metrics but loses deraining to MoCE-IR by 0.95 dB. The paper offers a genuinely plausible explanation rather than papering over the loss, Rain100L consists of globally uniform rain streaks spread evenly across the whole frame, which is precisely the scenario where a model built around strong global priors has an advantage and spatial gating has comparatively little heterogeneity to exploit. On the five task extension, F2D-Net reaches an average PSNR of 30.69 dB across dehazing, deraining, denoising, deblurring, and low light enhancement, ranking first overall, with its largest single task advantage over MoCE-IR showing up on low light enhancement at a 0.32 dB gain.
The composite degradation benchmark, where the real test is
| Complexity tier | Metric | MoCE-IR | F2D-Net |
|---|---|---|---|
| Single (4 types) | SSIM | 0.941 | 0.945 |
| Pairwise (5 types) | SSIM | 0.869 | 0.884 |
| Triple (2 types) | SSIM | 0.790 | 0.798 |
| Average | SSIM | 0.881 | 0.890 |
| Average | PSNR | 29.05 | 28.72 |
| Average | LPIPS | 0.108 | 0.096 |
| Average | FID | 38.8 | 27.2 |
The pattern that emerges is consistent and the paper is explicit about naming it as a genuine tradeoff rather than a clean sweep. F2D-Net’s SSIM lead over MoCE-IR actually grows as the number of overlapping degradations increases, from a 0.004 gap on single degradations to a 0.008 gap on the hardest triple degradation tier, which is exactly the direction you would want if pixel-wise expert factorization is paying off precisely where it should. At the same time, F2D-Net trails MoCE-IR on raw PSNR by roughly a third of a decibel on average. The explanation offered is structural rather than incidental, the multiplicative noise process is explicitly designed to produce diverse, structurally faithful reconstructions rather than the single smoothest possible average, and PSNR as a metric specifically rewards that kind of averaging while penalizing the small pixel level deviations a more structurally accurate but less blurred image will contain. The perceptual and distributional metrics tell a clearer story in F2D-Net’s favor, with an FID improvement of 11.6 points over MoCE-IR, a genuinely large distributional quality gap.
Speed, and beating diffusion style restorers without their sampling cost
F2D-Net’s closed form transition means restoration collapses to a single network evaluation rather than the tens or hundreds of sampling steps diffusion and bridge based restoration methods typically need.
| Method | Type | Steps | PSNR | LPIPS |
|---|---|---|---|---|
| UniDB | Bridge | 100 | 22.78 | 0.137 |
| DiffIR | Diffusion | 50 | 27.28 | 0.122 |
| IR-SDE | Mean reverting SDE | 100 | 27.62 | 0.116 |
| GOUB | Bridge | 100 | 27.88 | 0.110 |
| DA-RCOT | Optimal transport | 20 | 28.05 | 0.108 |
| PMRF | Rectified flow | 25 | 28.18 | 0.104 |
| ResFlow | Normalizing flow | 4 | 28.34 | 0.101 |
| BaryIR | Optimal transport | 10 | 28.38 | 0.104 |
| F2D-Net | Stochastic transport | 1 | 28.72 | 0.096 |
F2D-Net beats every one of these methods on both PSNR and LPIPS while using a single network call where the others need between four and one hundred. On a single RTX 4090, the paper reports a 61.1 times speed advantage over IR-SDE once that step count difference is accounted for, and at 512 by 512 resolution F2D-Net posts lower latency and lower peak memory than every other stochastic or transport-based restorer tested, including the single-step discriminative baseline MoCE-IR itself. At 1024 by 1024, IR-SDE and PMRF both run out of GPU memory entirely under standard precision, while F2D-Net completes inference at the lowest memory footprint of any method that finishes the test at all.
Does it generalize past the synthetic benchmark
Synthetic composite benchmarks like CDD-11 are built by artificially layering degradations onto clean images, which raises the fair question of whether a model tuned for that recipe actually helps on real degraded photographs. The paper runs two separate checks. On RTTS, a set of real hazy scenes with no ground truth available, the team used a depth estimation sharpness proxy and found F2D-Net produced the sharpest recovered depth boundaries of the methods compared, including on a nighttime scene where a leading baseline, PromptIR, actually made the depth estimate worse than the hazy input it started from. On WeatherBench, a paired dataset of genuinely captured rain, snow, and haze rather than synthetic composites, F2D-Net was retrained on the official split and reached the best average PSNR and SSIM among the compared methods, with its largest single task gain appearing on deraining, where it beat the next best method, AdaIR, by more than two decibels. AdaIR did keep a narrow perceptual edge on average LPIPS, another instance of the paper reporting a real, specific tradeoff rather than claiming a universal win.
What the ablation studies actually isolate
| Configuration added | PSNR | Gain |
|---|---|---|
| Deterministic flow matching baseline | 27.84 | – |
| + Stochastic transport | 28.32 | +0.48 |
| + Factorized flow field | 28.52 | +0.20 |
| + Time conditioned gating | 28.72 | +0.20 |
The single largest gain in the entire ablation ladder, 0.48 dB, comes from adding the multiplicative noise stochastic transport on top of a plain deterministic flow matching baseline, which is a strong internal confirmation that the first failure mode the paper identifies really was costing real accuracy. The factorized flow field and the time conditioned gating each contribute a further 0.20 dB on top of that. A separate ablation on the noise strength parameter found a middle value gave the best tradeoff, with zero noise producing blurry output as expected, a very small noise value under exploring the space of plausible reconstructions, and too much noise introducing visible artifacts.
A capacity control experiment addresses an obvious objection, that any accuracy gain might just come from adding more parameters rather than the factorization itself being useful. The team widened a single, non-factorized backbone to match F2D-Net’s full 23.77 million parameter budget and found it reached only 28.05 dB, closing less than a quarter of the gap between the plain additive baseline and the full model. Most of the remaining improvement, the paper argues, comes from the inductive bias of factorization itself rather than raw capacity.
Honest limitations
The paper is unusually direct about where the method still breaks, dedicating a specific limitations discussion to two documented failure cases rather than only listing successes. The first is gating ambiguity, where rain streaks on reflective surfaces share spectral characteristics with specular highlights, causing the pixel-wise gate to misroute experts at boundaries between water and vegetation whenever degradation sources overlap in frequency content. The second is over contraction on sparse residuals, where thin structures such as power lines get collapsed by the multiplicative noise process before single-step inference gets a chance to recover them, a direct consequence of trading iterative refinement for one-step speed. The authors suggest soft expert routing and adaptive step inference as natural remedies for both issues and leave them as future work rather than claiming to have solved them here.
A few additional caveats are worth naming. Training a full model takes approximately seven days on two NVIDIA A100 GPUs, a nontrivial cost for anyone looking to reproduce or extend the work. The PSNR tradeoff on CDD-11 is real and averages about a third of a decibel below the strongest baseline, even though every perceptual and structural metric favors F2D-Net, so which model is actually better depends partly on which metric a given downstream application cares about most. And while the WeatherBench and RTTS tests are a genuine and welcome effort at real world validation, the authors themselves note that paired real world benchmarks at the specific triple degradation complexity CDD-11 tests do not yet exist, so the hardest composite scenarios remain validated only on synthetic data for now.
Takeaway for practitioners
If your restoration pipeline already struggles specifically on images with more than one degradation type layered together, and speed matters as much as accuracy, F2D-Net’s single-step inference and lower memory footprint compared even to a strong discriminative baseline like MoCE-IR make it a genuinely practical option to evaluate, not just a research curiosity.
Takeaway on the theory
The core mathematical trick, scaling diffusion noise by the residual itself so it provably contracts to exactly zero rather than leaving a persistent variance, is a clean and reusable idea that extends beyond image restoration to any generative or transport based task where exact recovery of a specific target matters more than sampling diversity at convergence.
Where this could go next
The specific contribution here is a restoration network, but the two underlying ideas are more broadly applicable. Treating expert routing as a per-pixel spatial decision rather than a per-image global one is not inherently specific to image restoration, and could plausibly transfer to any dense prediction task built on a mixture of experts architecture, wherever different regions of an input genuinely call for different specialized processing. The state dependent multiplicative noise design is even more general, since the underlying mathematical problem it solves, additive noise diffusion processes leaving a nonzero steady state variance that prevents exact recovery, shows up in any generative modeling context where the goal is not just plausible samples but a specific, correct target.
The honesty of the paper’s own limitations section is worth taking seriously rather than glossing over. Gating ambiguity at water-vegetation boundaries and over contraction on thin sparse structures are not minor edge cases, they are the kind of failure that shows up in exactly the real world scenes, wet reflective roads and overhead power lines, that a genuinely deployed weather restoration system would need to handle reliably. Soft routing and adaptive step counts are reasonable directions to try, but neither has been tested yet in this paper, so whether they actually close those gaps remains an open question for follow up work.
What is already reasonably well established is that the two failure modes identified here, deterministic averaging and coarse image level routing, are genuine, measurable phenomena rather than post hoc justifications for an architecture the authors wanted to build anyway. The flow magnitude that refuses to decay to zero and the 1.2 times selectivity ratio are both things you can go measure yourself on an existing baseline, which is a more falsifiable kind of motivation than most papers offer, and it is part of why the fixes proposed here land as targeted rather than incidental.
Read the full paper for the complete proofs behind Propositions 1 and Corollaries 1 and 2, the full set of ablation tables, and the project page with additional qualitative comparisons.
A minimal PyTorch implementation
Below is a compact, runnable sketch of the core ideas, the closed form log-normal transition for the multiplicative noise SDE, a factorized flow field with a shared backbone and gated experts, and the original-space stochastic flow matching loss. It favors clarity over matching the paper’s exact U-Net backbone, and it includes a smoke test on random dummy data.
Conclusion
The real contribution of this paper is not the network architecture on its own, it is the pair of specific, measurable diagnoses that motivated it. A flow magnitude that refuses to decay to zero and a 1.2 times expert selectivity ratio are concrete, checkable facts about why existing all in one restoration models fail on composite inputs, not vague intuitions dressed up after the fact. Once those two failure modes are named precisely, the fixes follow with a kind of inevitability, noise that shrinks exactly to zero rather than leaving a residual cloud, and routing decisions made at every pixel rather than once per image.
The mathematical core, scaling diffusion noise multiplicatively by the residual so that a closed form log-normal solution falls out and single step inference becomes possible without sacrificing the provable contraction to zero variance, is the kind of idea that is easy to undersell because the resulting equations look almost too simple. The proofs behind Corollaries 1 and 2 are what actually earn the right to call this an exact recovery process rather than an approximate one, and that rigor is what lets the paper move from a diffusion style stochastic process to genuinely fast, single call inference without giving up the theoretical guarantee that motivated using stochasticity in the first place.
None of this comes for free, and the paper does not pretend otherwise. A roughly third of a decibel PSNR deficit against the strongest baseline, gating confusion at water and vegetation boundaries, and a tendency to over-contract thin structures like power lines are all named directly rather than buried in an appendix. Seven days of training on two A100 GPUs is a real cost too. None of these caveats undercut the central result, which is that pixel-wise expert factorization gets meaningfully better as degradations pile up, exactly where a real world composite restoration system would need it most, and that a single network evaluation can now match or beat restoration methods that previously needed dozens to hundreds of sampling steps to reach comparable quality.
Whether the idea of residual-scaled multiplicative noise finds a home beyond image restoration will depend on how well the same contraction guarantee holds up in other domains where exact target recovery matters, from super resolution to broader inverse problems in imaging. The theoretical argument behind it does not depend on anything specific to rain, haze, or snow, which is reason enough to expect this will not be the last place the trick shows up.
Frequently asked questions
What is composite degradation in image restoration
It refers to a single image that contains more than one type of quality problem at the same time, such as rain, haze, low light, and snow all overlapping spatially in the same frame, rather than the simpler case most restoration models are trained and tested on, where an image has only one degradation type.
Why does deterministic flow matching produce blurry restorations
When a degraded image could plausibly be restored in more than one valid way, a deterministic flow matching model trained to minimize average error learns to predict something close to the average of those plausible outcomes rather than committing to any single sharp reconstruction, which shows up as an over smoothed result.
What is a selectivity ratio in a mixture of experts model
It measures how much more strongly the most relevant expert activates compared to the least relevant one for a given input. A ratio near 1 means every expert is firing about equally, which suggests the routing mechanism is not actually specializing. The paper measured a ratio of only 1.2 times for a leading image level routing baseline on composite inputs.
How does F2D-Net achieve single step inference
Its noise process has a closed form mathematical solution, meaning the state at any later point in the restoration trajectory can be computed directly from an earlier state without numerically simulating every intermediate step, which lets the model collapse the entire restoration process to one network evaluation.
Does F2D-Net beat every baseline on every metric
No, and the paper is explicit about this. It trails the strongest baseline, MoCE-IR, on raw PSNR by about a third of a decibel on the CDD-11 benchmark, and it also loses to MoCE-IR specifically on the deraining task in the three task setting. It leads on SSIM, LPIPS, DISTS, and FID across every degradation complexity tier it was tested on.
What are the known failure cases of this method
The paper documents two specific failure modes, gating confusion where rain streaks on reflective surfaces get misrouted at boundaries between water and vegetation because they share spectral characteristics with specular highlights, and over contraction on sparse thin structures such as power lines, where single step inference can collapse the noise before the structure is fully recovered.
Su, X., Chao, J., Shen, H., Chen, A., Gao, Y., and Yuan, J. Factorized stochastic transport for composite degradation image restoration. Knowledge-Based Systems, volume 349, 2026, article 116411, DOI 10.1016/j.knosys.2026.116411. This analysis is based on the published paper and an independent evaluation of its claims.