Key points
- KD-FixMatch splits FixMatch’s single weight sharing network into two networks trained one after another, an outer network first, then an inner network that learns from the outer network’s best pseudo labels.
- The outer network’s pseudo labels are filtered twice before the inner network ever sees them, once by a confidence threshold and once by checking that a clustering of the image’s learned features agrees with the predicted class.
- A merging rule the authors call Heuristic 1 lets the inner network’s own confident predictions override the outer network’s pseudo labels once the inner network becomes confident enough to trust itself.
- Swapping in a symmetric cross entropy loss for the inner network’s unlabeled loss term gives a further small accuracy gain, with no hyperparameter search over the loss’s two weighting terms.
- Across CIFAR10, SVHN, CIFAR100, and FOOD101, KD-FixMatch beats plain FixMatch in every labeled data setting tested, though it takes more than double the training time to get there.
The core problem with teaching yourself from your own notes
FixMatch is built around a deceptively simple idea. Take one unlabeled image, make two versions of it, one with a light augmentation such as a small crop or flip, and one with a heavy augmentation such as strong color distortion or cutout. Feed the lightly augmented version into the network and treat its softmax output as a pseudo label, but only if the network is at least 95 percent confident in its own top guess. Then feed the heavily augmented version into the very same network and train it to match that pseudo label. Since both the “teacher” reading the easy version and the “student” reading the hard version are the same weights, the whole thing runs as one siamese neural network, a pair of identical branches that share every parameter.
That shared weight design is elegant, and it is also exactly where the trouble starts. At the beginning of training, the network has not learned anything useful yet, so whatever handful of unlabeled examples happen to cross that 95 percent confidence bar are essentially confident accidents. Training the same network to reproduce its own confident accidents does not average out the noise the way a genuinely independent second opinion would. It reinforces it. The paper’s authors frame this plainly. FixMatch trains its teacher and student simultaneously, and heavy label noise from an immature teacher in the early stage can hurt the final model’s ability to generalize.
Where this sits among earlier fixes for label noise
Semi supervised learning has approached this same underlying problem, an imperfect teacher supervising a student, from two different directions. The paper the authors build on most directly, KD-FixMatch, Knowledge Distillation Siamese Neural Networks by Chien-Chih Wang, Shaoyuan Xu, Jinmiao Fu, Yang Liu, and Bryan Wang, sorts prior work into sequential and simultaneous camps.
Sequential methods train one model fully, then use it to teach the next. Classic self training, going back to Yarowsky’s 1995 work on word sense disambiguation, follows this pattern, as does Noisy Student, which trains a large teacher, generates pseudo labels for a huge unlabeled pool, then trains a student that is equal to or larger than the teacher while injecting extra noise through dropout, stochastic depth, and heavy augmentation. Once that student outperforms its teacher, Noisy Student swaps roles, reinitializes a new student, and repeats the whole cycle several times. It works well, but it is expensive. Each of those repeated cycles needs its own full training run, and the process cannot start generating trustworthy pseudo labels until the current teacher has already converged.
Simultaneous methods avoid that waiting period entirely. FixMatch, Mean Teacher, and Meta Pseudo Labels all update teacher and student together in a single training loop, which is faster and simpler to run, but it is precisely this simultaneity that lets early stage noise leak straight into the model. KD-FixMatch’s central move is refusing to pick a side. It borrows the sequential structure at a coarse level, training exactly one outer network and then exactly one inner network, never looping back to retrain either one, while each of those two networks internally still trains its own teacher and student simultaneously using ordinary FixMatch. The result gets a better starting point than plain FixMatch without paying Noisy Student’s cost of retraining from scratch multiple times.
How KD-FixMatch actually works
FixMatch’s own optimization target is worth pinning down first, since KD-FixMatch reuses it twice. Given a network with parameters theta, a regularization strength C, and a set of training examples, the network minimizes a standard regularized loss.
FixMatch’s base optimization objective
$$\min_{\theta} f(\theta), \quad f(\theta) = \frac{1}{2C}\,\theta^T\theta + \frac{1}{\ell}\sum_{i=1}^{\ell}\xi(\theta; x^i, y^i)$$For a labeled example, the per example loss term is just standard cross entropy between the true label and the network’s prediction on the weakly augmented image.
The loss term when example i is labeled
$$\xi(\theta; x^i, y^i) = \xi_l\big(y^i, f_\theta(x_w^i)\big)$$For an unlabeled example, the loss instead compares the network’s prediction on the strongly augmented image against a pseudo label taken from the network’s own prediction on the weakly augmented image, weighted by a scaling term lambda.
The loss term when example i is unlabeled
$$\xi(\theta; x^i, y^i) = \lambda_u\, \xi_u\big(\hat{y}^i, f_\theta(x_s^i)\big)$$Crucially, that unlabeled loss term is only ever applied when the pseudo label is confident enough to trust, which is what keeps a completely untrained network from being punished for confidently disagreeing with its own random early guesses on every single unlabeled example.
The confidence gate that decides whether an unlabeled example gets used at all
$$\mathbb{1}\big(\max(\hat{y}^i) \ge \tau\big)\, \xi_u\big(\mathrm{OHL}(\hat{y}^i), f_\theta(x_s^i)\big)$$KD-FixMatch runs that entire recipe twice, in two clearly separated stages.
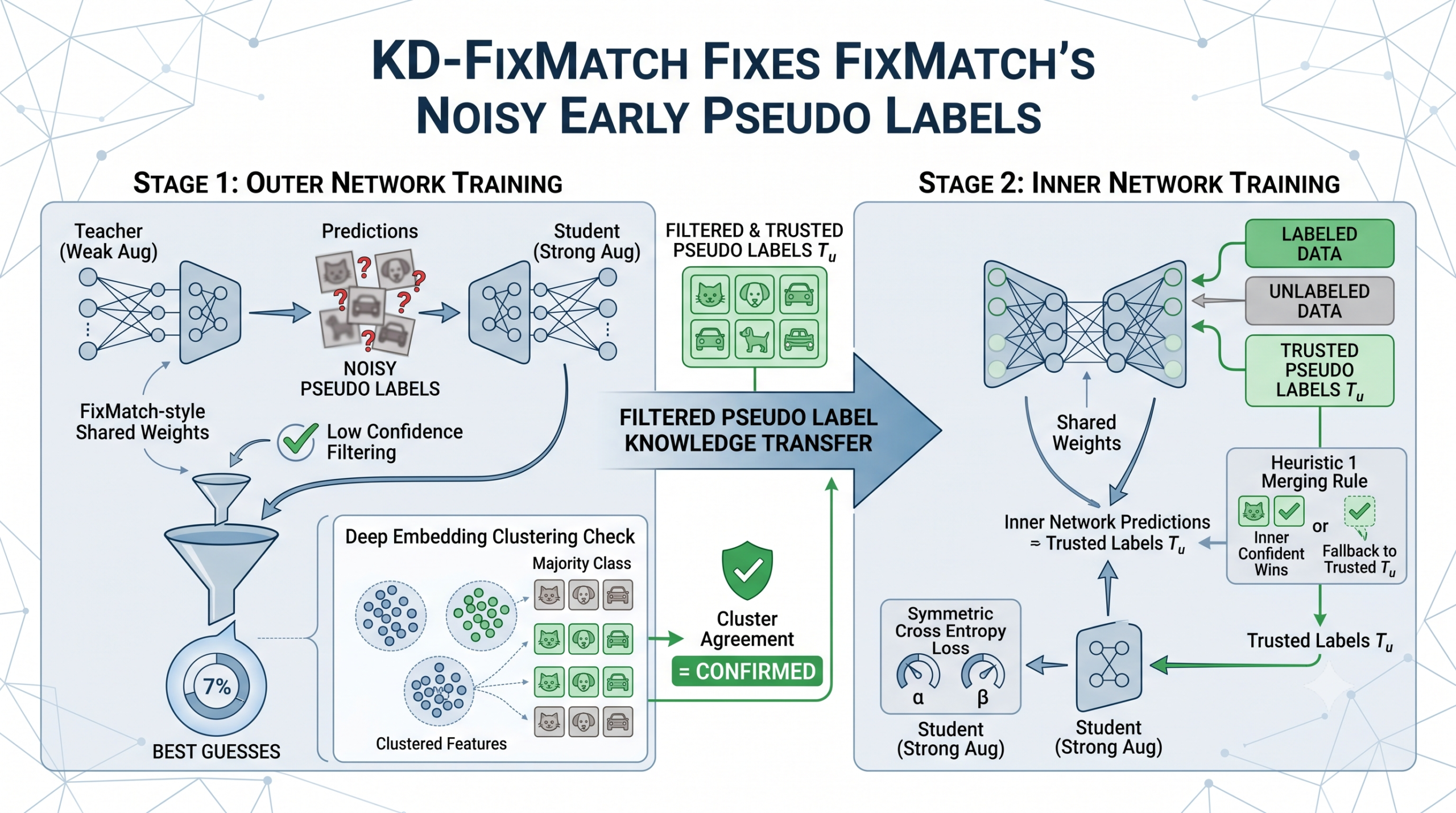
Stage one, an outer network trained the ordinary way
The outer network is nothing exotic. It is trained with plain FixMatch on the labeled and unlabeled data, using the same three equations above. Its only job is to become a reasonably competent, one time teacher for the next stage. It is never shipped as the final model.
Stage two, trusted pseudo label selection
Once the outer network has converged, it generates pseudo labels for every unlabeled image. Rather than trusting all of them, the authors apply a looser confidence threshold, 0.80 rather than the 0.95 used during training, then take an extra step that goes beyond simple thresholding. They pull the learned embedding, the representation from the layer just before the final classifier, for every example that cleared the confidence bar, and run a deep embedding clustering pass over those embeddings. Only the examples where the unsupervised cluster assignment agrees with the network’s own predicted class survive into a trusted subset the paper calls T sub u.
The logic is worth sitting with for a moment. A softmax confidence score and a clustering structure in the embedding space are two largely independent signals. A network can be falsely confident about a wrong answer, but it is much less likely that a wrong answer also happens to land in a tight, well separated cluster of similarly classified examples purely by chance. Requiring both signals to agree is a cheap way to get something like a second opinion without spending a single additional human label.
Stage three, an inner network that inherits a head start
A fresh inner network is then trained, again with ordinary FixMatch on the labeled and unlabeled data, but with one addition. It also receives supervision from the trusted subset T sub u produced in stage two. Since the inner network generates its own pseudo labels as it trains, conflicts naturally arise between what the outer network trusted earlier and what the inner network now believes. The authors resolve this with a rule they call Heuristic 1.
if max( f_inner(x_w^i) ) ≥ τ_inner
then ŷ^i ← f_inner(x_w^i), the inner network trusts its own current judgment
else if i is in the trusted subset T_u
then ŷ^i ← y^i_outer, fall back to the outer network’s earlier trusted label
else
that example gets no supervision this step
The reasoning behind the ordering matters. Once the inner network is confident enough on its own, it is assumed to already have better generalization than the outer network did at a comparable point, since it started from a cleaner supervisory signal in the first place, so its live judgment takes priority. The outer network’s trusted labels exist purely as scaffolding for examples the inner network has not grown confident about yet, not as a permanent authority.
An optional upgrade, robust loss functions
The paper adds one more lever. Plain cross entropy treats every pseudo label as equally trustworthy, which is not quite true even after the two rounds of filtering above. Symmetric loss functions, a family that includes mean absolute error, symmetric cross entropy, and normalized cross entropy, have a theoretical property that makes them provably more tolerant of residual label noise, the sum of the loss across every possible one hot target for a given input equals a constant value no matter what the network predicts.
The symmetry condition that makes a loss function noise tolerant
$$\sum_{k=1}^{K} \xi\big(f(x), e_k\big) = M, \quad \forall\, x \in X,\ \forall\, f$$Due to space limits, the authors test only symmetric cross entropy, which combines ordinary cross entropy with a reverse cross entropy term.
Symmetric cross entropy, used as the inner network’s unlabeled loss
$$\mathrm{SCE} = \alpha \cdot \mathrm{CE} + \beta \cdot \mathrm{RCE}, \quad \mathrm{RCE}(p, q) = H(p, q)$$Swapping this in for the inner network’s unlabeled loss term is the only difference between the KD-FixMatch-CE and KD-FixMatch-SCE variants tested in the experiments below.
Put together, the six steps of the full method run as follows.
- Initialize an outer network and train it on the labeled and unlabeled data with ordinary FixMatch.
- Use the well trained outer network to generate pseudo labels for every unlabeled example.
- Select a trusted subset of those pseudo labels using the confidence threshold and deep embedding clustering agreement check.
- Choose either plain cross entropy or a robust loss such as symmetric cross entropy for the inner network’s unlabeled loss term.
- Initialize a fresh inner network and train it on the labeled data, the unlabeled data, and the trusted pseudo labeled subset, merging conflicts with Heuristic 1.
- Return the well trained inner network as the final model.
What the experiments actually show
All experiments use EfficientNet-B0 pretrained on ImageNet as the backbone, with two identical weight sharing copies forming what the paper calls SNN-EB0. Five methods are compared. A plain Baseline trained only on labeled data, ordinary FixMatch, KD-FixMatch-CE, and two symmetric cross entropy variants, KD-FixMatch-SCE-1.0-0.01 and KD-FixMatch-SCE-1.0-0.1, named for their alpha and beta weighting terms.
| Data set | Classes | Train images | Validation images | Test images |
|---|---|---|---|---|
| CIFAR10 | 10 | 40,000 | 10,000 | 10,000 |
| SVHN | 10 | 58,606 | 14,651 | 26,032 |
| CIFAR100 | 100 | 40,000 | 10,000 | 10,000 |
| FOOD101 | 101 | 60,600 | 15,150 | 25,250 |
Worth flagging up front, the unlabeled data in every one of these experiments comes from the same official training split as the labeled data, simply with the labels ignored, rather than a separate and possibly messier unlabeled pool. That choice makes for a clean, controlled comparison, and it is also a real difference from how a production system would source its unlabeled data, a point worth keeping in mind while reading the results.
| Data set, labeled count | Baseline | FixMatch | KD-FixMatch-CE | KD-FixMatch-SCE |
|---|---|---|---|---|
| CIFAR10, 400 labels | 33.47% | 84.96% | 87.40% | 87.55% |
| CIFAR10, 4,000 labels | 93.37% | 95.69% | 96.18% | 96.34% |
| SVHN, 400 labels | 19.66% | 70.20% | 76.01% | 76.50% |
| CIFAR100, 1,000 labels | 35.02% | 57.72% | 61.26% | 60.68% |
| FOOD101, 20,000 labels | 75.62% | 77.38% | 79.33% | 79.46% |
Three patterns hold across all four data sets and every labeled data setting the authors tried, twelve separate experimental cells in total. FixMatch always beats the Baseline, which is expected since it gets to use the extra unlabeled data that Baseline never sees. KD-FixMatch always beats FixMatch, in every single one of those twelve cells, which is the more interesting result given how easy it would have been for the extra machinery to help in some settings and not others. And the size of that improvement shrinks as labeled data grows. On CIFAR10, KD-FixMatch-CE improves on FixMatch by 2.44 points at 400 labels but only 0.49 points at 4,000 labels. Once FixMatch already has enough labels to reach a strong starting point on its own, a better outer network head start has less room to help.
The Baseline’s own numbers are a small story in themselves. At the lowest labeled counts, its standard deviation across five random seeds balloons to 23.56 percent on SVHN and 30.12 percent on CIFAR100, meaning a plain supervised model trained on that little labeled data is barely stable from one run to the next. FixMatch and KD-FixMatch both settle into a much tighter spread even before their accuracy advantage is considered, which is its own kind of evidence that the unlabeled data is doing real work.
The comparison between KD-FixMatch-CE and the two SCE variants is the subtlest result. Symmetric cross entropy wins in most cells, sometimes by less than half a point, but not in every single one. On CIFAR100 at 1,000 labels, KD-FixMatch-CE actually edges out both SCE variants, at 61.26 percent versus 60.68 and 60.62 percent. The authors are candid that they did not run a grid search over alpha and beta at all, so the fact that a fixed, untuned setting still helps in most cases is the headline, not a claim that SCE always wins.
Key takeaway
The improvement from KD-FixMatch is largest exactly where labeled data is scarcest, which is also where a practitioner is most likely to be reaching for semi supervised learning in the first place. That is a fortunate alignment between where the method helps most and where it is most needed.Why the two stage design earns its complexity
The deep embedding clustering step deserves more attention than a single subsection in the original paper gives it. Confidence thresholding alone, the trick FixMatch already uses, catches one specific failure mode, a network that has not learned enough to say anything useful yet. It does not catch a different failure mode, a network that has learned something, just the wrong pattern, and is now confidently wrong about it. Checking whether the embedding space independently agrees with that confident prediction is a general purpose trick for catching the second failure mode, and it is not tied to FixMatch or even to image classification specifically. Any pipeline that filters pseudo labels by confidence alone is implicitly assuming that confidence and correctness always move together, an assumption that clustering agreement helps verify rather than assume.
Heuristic 1’s handoff logic is worth generalizing too. Rather than picking a single fixed point in training to swap from trusting the outer network to trusting the inner network, it lets the inner network earn that trust example by example, the moment its own confidence clears the bar. That is a soft, adaptive alternative to the kind of fixed distillation schedule many multi stage training pipelines use, and it is a pattern that could plausibly transfer to other settings where one model’s output seeds the training of a second, better positioned model.
Honest limitations of this study
The authors are upfront about several constraints, and a few more are worth adding from a careful read of the setup.
- Training cost is real and explicitly acknowledged. The authors state plainly that KD-FixMatch’s time complexity is more than double that of FixMatch, since it trains two full networks in sequence plus the clustering step in between. Anyone with abundant labeled data, where the accuracy gain is smallest, should weigh that cost carefully.
- Only one robust loss function, symmetric cross entropy, was actually tested. Mean absolute error and normalized cross entropy are mentioned as alternatives from the noisy label literature but were left untested due to space limits, so it is not yet clear whether SCE is the best available choice or simply the one that fit in the paper.
- Every experiment uses a single backbone, EfficientNet-B0. Whether the same pattern of gains holds for much larger or much smaller architectures is not established here.
- The unlabeled data in every experiment is drawn from the same distribution and the same original training split as the labeled data, just with labels hidden. Real deployments often pull unlabeled data from messier, more varied sources, and it is not yet clear how much of KD-FixMatch’s advantage survives that shift.
- The two key thresholds controlling trust, 0.80 for initial selection and 0.95 for the inner network’s own confidence, are set once and used everywhere, without a reported ablation showing how sensitive the results are to those specific values.
Reference implementation, KD-FixMatch core mechanics in PyTorch
The snippet below is a compact, runnable stand in for the paper’s outer network, trusted pseudo label selection, Heuristic 1, and symmetric cross entropy. It uses a small linear backbone and random data so it runs anywhere without a real dataset or checkpoint, and it has been executed end to end to confirm it produces no errors.
# -----------------------------------------------------------------------
# Educational reference implementation inspired by KD-FixMatch, described
# in Wang et al., "KD-FixMatch, Knowledge Distillation Siamese Neural
# Networks" (arXiv 2309.05826). It illustrates, on dummy data, the three
# ideas that make up the paper's Algorithm 1.
# 1. An outer SNN trained the ordinary FixMatch way, a shared backbone
# that reads a weakly augmented view as the teacher and a strongly
# augmented view as the student, supervised only above a confidence
# threshold.
# 2. Trusted pseudo label selection, which keeps only the outer SNN's
# confident predictions whose embedding cluster agrees with the
# predicted class.
# 3. An inner SNN trained the same FixMatch way, plus the trusted
# subset, with conflicting pseudo labels merged by Heuristic 1 and
# an optional symmetric cross entropy loss for extra noise
# tolerance.
#
# Toy backbone, toy data, no real images or checkpoints required.
# -----------------------------------------------------------------------
import torch
import torch.nn as nn
import torch.nn.functional as F
# -------------------------------------------------------------------
# 1. A tiny shared backbone standing in for EfficientNet-B0. Both the
# "teacher" (weak view) and "student" (strong view) forward passes
# in the paper's SNN reuse this exact same network, so one module
# plays both roles.
# -------------------------------------------------------------------
class TinyBackbone(nn.Module):
def __init__(self, in_dim=32, embed_dim=16, num_classes=5):
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(in_dim, 64),
nn.ReLU(),
nn.Linear(64, embed_dim),
nn.ReLU(),
)
self.classifier = nn.Linear(embed_dim, num_classes)
def forward(self, x, return_embedding=False):
embedding = self.encoder(x)
logits = self.classifier(embedding)
if return_embedding:
return logits, embedding
return logits
# -------------------------------------------------------------------
# 2. Toy stand ins for weak and strong augmentation. Real KD-FixMatch
# uses the augmentations from the FixMatch and RandAugment papers.
# Weak augmentation adds a little noise, strong augmentation adds
# a lot, which is enough to exercise the loss functions below.
# -------------------------------------------------------------------
def weak_augment(x):
return x + 0.05 * torch.randn_like(x)
def strong_augment(x):
return x + 0.35 * torch.randn_like(x)
# -------------------------------------------------------------------
# 3. FixMatch's core loss, Equations 2 and 3 in the paper. The backbone
# reads the weakly augmented view to make a pseudo label, then the
# strongly augmented view is only supervised when that pseudo label
# clears the confidence threshold tau.
# -------------------------------------------------------------------
def default_ce(logits, targets):
return F.cross_entropy(logits, targets, reduction="none")
def fixmatch_unlabeled_loss(backbone, x_unlabeled, tau=0.95, unlabeled_loss_fn=None):
unlabeled_loss_fn = unlabeled_loss_fn or default_ce
with torch.no_grad():
weak_logits = backbone(weak_augment(x_unlabeled))
weak_probs = F.softmax(weak_logits, dim=-1)
confidence, pseudo_labels = weak_probs.max(dim=-1)
mask = (confidence >= tau).float()
strong_logits = backbone(strong_augment(x_unlabeled))
per_example_loss = unlabeled_loss_fn(strong_logits, pseudo_labels)
if mask.sum() == 0:
return per_example_loss.sum() * 0.0
return (mask * per_example_loss).sum() / mask.sum()
def labeled_loss(backbone, x_labeled, y_labeled):
logits = backbone(weak_augment(x_labeled))
return F.cross_entropy(logits, y_labeled)
# -------------------------------------------------------------------
# 4. Symmetric cross entropy, the robust loss option from Section 3.3.
# SCE = alpha * CE + beta * reverse CE, used in place of plain CE
# for the inner network's unlabeled loss term.
# -------------------------------------------------------------------
def symmetric_cross_entropy(logits, targets, alpha=1.0, beta=0.1, num_classes=5, eps=1e-4):
probs = F.softmax(logits, dim=-1).clamp(min=eps, max=1.0)
one_hot = F.one_hot(targets, num_classes=num_classes).float().clamp(min=eps, max=1.0)
ce = F.cross_entropy(logits, targets, reduction="none")
rce = -(probs * torch.log(one_hot)).sum(dim=-1)
return alpha * ce + beta * rce
# -------------------------------------------------------------------
# 5. Trusted pseudo label selection, Section 3.1. Keep only the outer
# SNN's confident predictions whose embedding neighborhood agrees
# with the predicted class, using a minimal from scratch k means as
# a stand in for the paper's deep embedding clustering.
# -------------------------------------------------------------------
def simple_kmeans(embeddings, num_clusters, iters=10):
num_clusters = min(num_clusters, embeddings.size(0))
idx = torch.randperm(embeddings.size(0))[:num_clusters]
centers = embeddings[idx].clone()
assignments = torch.zeros(embeddings.size(0), dtype=torch.long)
for _ in range(iters):
distances = torch.cdist(embeddings, centers)
assignments = distances.argmin(dim=-1)
for c in range(centers.size(0)):
members = embeddings[assignments == c]
if members.size(0) > 0:
centers[c] = members.mean(dim=0)
return assignments
def select_trusted_pseudo_labels(outer_backbone, x_unlabeled, tau_select=0.80, num_classes=5):
with torch.no_grad():
logits, embeddings = outer_backbone(x_unlabeled, return_embedding=True)
probs = F.softmax(logits, dim=-1)
confidence, predicted = probs.max(dim=-1)
confident_mask = confidence >= tau_select
trusted_mask = torch.zeros_like(confident_mask)
if confident_mask.any():
cluster_ids = simple_kmeans(embeddings[confident_mask], num_classes)
confident_predicted = predicted[confident_mask]
# A cluster "agrees" with a predicted class when that class is the
# majority label inside the cluster, mirroring the paper's
# consistency check between clustering and predicted class.
agree = torch.zeros(int(confident_mask.sum().item()), dtype=torch.bool)
for c in cluster_ids.unique():
members = (cluster_ids == c)
majority_class = confident_predicted[members].mode().values
agree[members] = confident_predicted[members] == majority_class
trusted_mask[confident_mask.nonzero(as_tuple=True)[0]] = agree
return trusted_mask, predicted
# -------------------------------------------------------------------
# 6. Heuristic 1, merging conflicting pseudo labels. When the inner
# SNN is confident on its own, trust the inner SNN. Otherwise fall
# back to the outer SNN's trusted pseudo label, and if neither is
# available, do not supervise that example at all.
# -------------------------------------------------------------------
def merge_conflict_pseudo_labels(inner_probs, tau_inner, trusted_mask, outer_predicted):
confidence, inner_predicted = inner_probs.max(dim=-1)
inner_confident = confidence >= tau_inner
final_labels = torch.zeros_like(inner_predicted)
supervise_mask = torch.zeros_like(inner_confident)
final_labels[inner_confident] = inner_predicted[inner_confident]
supervise_mask[inner_confident] = True
fallback = (~inner_confident) & trusted_mask
final_labels[fallback] = outer_predicted[fallback]
supervise_mask[fallback] = True
return final_labels, supervise_mask
# -------------------------------------------------------------------
# 7. Algorithm 1 end to end, sequential outer then inner SNN training,
# matching the paper's six numbered steps.
# -------------------------------------------------------------------
def run_kd_fixmatch(x_labeled, y_labeled, x_unlabeled, num_classes=5,
outer_steps=30, inner_steps=30, use_sce=True):
outer = TinyBackbone(in_dim=x_labeled.size(-1), num_classes=num_classes)
optimizer = torch.optim.Adam(outer.parameters(), lr=1e-2)
for _ in range(outer_steps):
optimizer.zero_grad()
loss = labeled_loss(outer, x_labeled, y_labeled) \
+ fixmatch_unlabeled_loss(outer, x_unlabeled, tau=0.95)
loss.backward()
optimizer.step()
trusted_mask, outer_predicted = select_trusted_pseudo_labels(
outer, x_unlabeled, tau_select=0.80, num_classes=num_classes
)
inner = TinyBackbone(in_dim=x_labeled.size(-1), num_classes=num_classes)
optimizer = torch.optim.Adam(inner.parameters(), lr=1e-2)
unlabeled_loss_fn = (
(lambda logits, targets: symmetric_cross_entropy(logits, targets, num_classes=num_classes))
if use_sce else default_ce
)
for _ in range(inner_steps):
optimizer.zero_grad()
loss = labeled_loss(inner, x_labeled, y_labeled) \
+ fixmatch_unlabeled_loss(inner, x_unlabeled, tau=0.95, unlabeled_loss_fn=unlabeled_loss_fn)
with torch.no_grad():
inner_probs = F.softmax(inner(weak_augment(x_unlabeled)), dim=-1)
merged_labels, supervise_mask = merge_conflict_pseudo_labels(
inner_probs, tau_inner=0.95, trusted_mask=trusted_mask, outer_predicted=outer_predicted
)
if supervise_mask.any():
trusted_logits = inner(strong_augment(x_unlabeled[supervise_mask]))
trust_loss = unlabeled_loss_fn(trusted_logits, merged_labels[supervise_mask])
loss = loss + trust_loss.mean()
loss.backward()
optimizer.step()
return outer, inner
# -------------------------------------------------------------------
# 8. Smoke test on dummy data so the whole pipeline can be checked in
# a couple of seconds, without any real dataset or checkpoint.
# -------------------------------------------------------------------
def run_smoke_test():
torch.manual_seed(0)
num_classes = 5
x_labeled = torch.randn(20, 32)
y_labeled = torch.randint(0, num_classes, (20,))
x_unlabeled = torch.randn(60, 32)
outer, inner = run_kd_fixmatch(x_labeled, y_labeled, x_unlabeled, num_classes=num_classes,
outer_steps=8, inner_steps=8, use_sce=True)
with torch.no_grad():
outer_acc = (outer(x_labeled).argmax(dim=-1) == y_labeled).float().mean().item()
inner_acc = (inner(x_labeled).argmax(dim=-1) == y_labeled).float().mean().item()
print(f"outer SNN labeled set accuracy {outer_acc * 100:.1f} percent")
print(f"inner SNN labeled set accuracy {inner_acc * 100:.1f} percent")
print("smoke test finished without errors")
if __name__ == "__main__":
run_smoke_test()
Conclusion
KD-FixMatch’s core insight is narrow and well aimed. FixMatch’s weakness is not the confidence threshold, the augmentation strategy, or the loss function, it is the fact that a single network is asked to be both a trustworthy teacher and an eager student from the very first training step, before it has earned the right to be trusted at all. Splitting that single role into two networks trained one after another, with a genuinely independent filter sitting between them, addresses the actual failure mode rather than tuning around it.
The two stage design is also a useful reminder that sequential and simultaneous training are not rival philosophies that force a choice. KD-FixMatch applies sequential structure at the coarse level, exactly one outer network handing off to exactly one inner network, while keeping the fast, simultaneous FixMatch loop inside each of those two stages. That combination captures a meaningful share of Noisy Student’s better starting point property without inheriting its cost of repeating an entire training cycle several times over.
The deep embedding clustering step is the part most likely to generalize beyond this specific paper. Any pipeline that filters pseudo labels using confidence alone is implicitly trusting that confidence and correctness move together, and this paper shows a cheap, label free way to check that assumption using structure the network has already learned. That idea does not depend on FixMatch, siamese networks, or even image classification specifically.
The honest limitations matter just as much as the results. A training cost of more than double plain FixMatch is not a small tax, particularly once labeled data becomes abundant and the accuracy gain shrinks to under half a point. A single backbone, a single robust loss function, and unlabeled data drawn from the same clean distribution as the labeled set all narrow how far these specific numbers can be expected to travel to messier, real deployment settings.
Even with those caveats, the result that KD-FixMatch beat FixMatch in all twelve tested combinations of data set and labeled data volume is not a small claim, and the paper’s own framing of where the benefit concentrates, exactly the low label regime where semi supervised learning gets used in the first place, gives practitioners a clear, honest signal for when the extra training cost is likely to be worth paying.
Read the original research
KD-FixMatch comes from Chien-Chih Wang and colleagues at Amazon, posted to arXiv in September 2023.
Frequently asked questions
Why does FixMatch struggle in the early stage of training
FixMatch’s teacher and student are the exact same weights inside one siamese network. Early in training those weights have not learned much, so any pseudo label that happens to cross the confidence threshold is often a confident accident, and training the network to reproduce its own accidents reinforces the noise instead of correcting it.
What does the outer network actually contribute that the inner network could not do alone
The outer network is trained first and only has one job, generating a set of pseudo labels that get filtered twice, once by confidence and once by checking that an unsupervised clustering of the learned features agrees with the predicted class. The inner network then starts from that cleaner signal instead of starting from nothing.
How does Heuristic 1 decide which pseudo label to trust
It checks the inner network’s own current confidence first. If the inner network is confident enough on its own, its live prediction wins. If not, but the example is in the outer network’s trusted subset, the outer network’s earlier label is used instead. If neither condition holds, that example simply is not used for supervision on that step.
Does symmetric cross entropy always beat plain cross entropy in this paper
No. It wins in most of the tested settings but not all of them, and the authors did not run a hyperparameter search over its two weighting terms. The main claim is that an untuned symmetric cross entropy setting still helps in most cases, not that it is guaranteed to win every time.
Is KD-FixMatch worth the extra training time it needs
That depends on how much labeled data is available. The accuracy gain over plain FixMatch is largest when labeled data is scarce and shrinks toward less than half a point once labeled data is abundant, while the training cost stays more than double FixMatch’s regardless. It is most worth the cost in exactly the low label settings semi supervised learning is usually chosen for.
Does this method require a specific network architecture
The paper tests everything with EfficientNet-B0 as the shared backbone for both the outer and inner siamese networks. The general approach, sequential training plus filtered pseudo labels, does not appear to depend on that specific architecture, but the paper itself only reports results using it.
This analysis is based on the published paper and an independent evaluation of its claims.
Pingback: 5 Breakthroughs in Dual-Forward DFPT-KD: Crush the Capacity Gap & Boost Tiny AI Models - aitrendblend.com