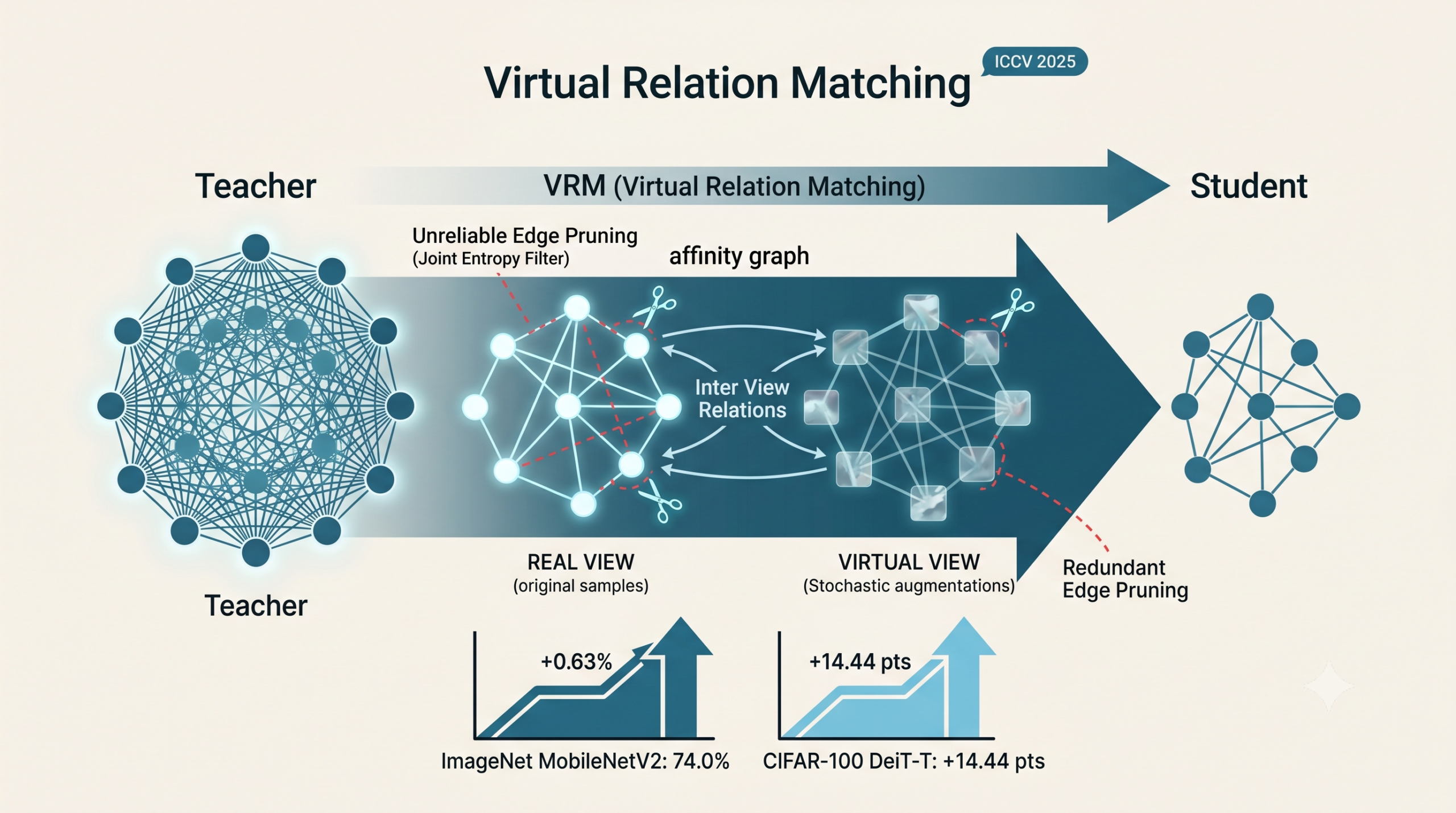
For about five years, relation based knowledge distillation has been the polite loser of the field. Instance matching methods kept winning benchmarks, while the relation based literature went quiet. A paper from Shanghai Jiao Tong University and the University of Sydney now argues that the loss was not inevitable. It was a consequence of two specific failures that nobody had named, and once you name them, the fix is both clean and surprisingly effective. The student trained with their method hits 74.0 percent on ImageNet with a MobileNetV2 architecture, the first time any distillation method has crossed that line, and lifts a DeiT-T transformer on CIFAR-100 by 14.44 percentage points.
Key Points
- Two flavors of knowledge distillation have been competing. Instance matching forces the student to copy each teacher prediction. Relation matching forces it to copy how teacher predictions relate to each other across a batch.
- Relation matching has been losing. The authors run pilot studies and find two specific reasons. Relation matching is more prone to overfitting because it is a weaker constraint than instance matching. A single noisy prediction also propagates spurious gradients across an entire batch.
- The fix is to enrich the relations and prune the bad ones. VRM generates a second virtual view of every image through stochastic augmentation, builds affinity graphs that connect real and virtual predictions, and then drops edges that are either redundant or unreliable.
- Unlike Gram matrix relations from prior work, VRM preserves class wise structure along a secondary dimension, so inter sample and inter class knowledge get transferred together rather than collapsed into a scalar.
- VRM beats every instance matching baseline on CIFAR-100 and ImageNet, scales to MS-COCO object detection, and works across convolutional and vision transformer architectures.
- The pruning is dynamic. Unreliable edges are detected on the fly using joint entropy of student predictions, so the set of pruned edges changes every iteration.
Why relation matching quietly fell behind
Knowledge distillation has split into two camps almost from the start. Hinton’s 2015 paper set up the instance matching template. For each image, the student is asked to produce a distribution close to the teacher’s distribution, measured by KL divergence on the logits. Park and colleagues later proposed relation matching in 2019. Instead of comparing per sample distributions, the student is asked to reproduce the structure of relationships among predictions across a whole batch.
The pitch for relation matching is appealing. Pairwise distances and angles between teacher predictions encode information that does not exist in any single prediction. Two cats that look similar to the teacher should look similar to the student even if the absolute confidences differ. The relational signal is also less coupled to specific architectures, which makes it a natural fit for distilling across heterogeneous teacher and student pairs.
For a few years the two camps traded blows. Then around 2022 the instance matching side pulled ahead. Variants of the divergence function, decoupled target and non target logits, feature map matching with smart projection layers. The relation based literature did not produce a comparable wave of progress. By 2024, top instance matching methods like FCFD and CRLD were ahead of even the strongest relation based method, DIST, by a clear margin on standard benchmarks.
What was going wrong was not obvious from the papers themselves. The relation based methods reported reasonable numbers and presented sound arguments. They just lost the race. Zhang and his coauthors went looking for a specific diagnosis.
Two cruxes from a pilot study
The pilot study has the shape of good empirical research. Train a ResNet32x4 teacher and an 8×4 student on CIFAR-100. Distill with several relation based methods and with vanilla KD. Watch what happens.
The first surprise is in the training curve. Relation based methods reach significantly higher training accuracy than instance matching. They fit the teacher signal more aggressively. On the validation set, that aggression does not pay off. The relation based students lead only marginally or fall slightly behind. Classic signs of overfitting. The authors give this a logical interpretation. Instance matching is a strictly stronger constraint than relation matching. If two student logit vectors match two teacher logit vectors exactly, the relations between them are also matched automatically. The converse is not true. You can match relations while individual predictions drift, which gives the student more degrees of freedom to fit teaching signals without generalizing.
The second surprise is in the gradient. The authors set up a controlled experiment. Take a batch of 64 random prediction vectors. Replace one of them with a noisy version. Compute the loss under instance matching and under relation matching. Look at how the gradient for each sample changes when the noise is injected.
Under instance matching, only the spurious sample sees a meaningful gradient change. The other 63 are unaffected. Under relation matching, every sample in the batch sees a substantial gradient change. The noisy sample’s bad signal has propagated through the relation graph because every other sample is connected to it. Samples that are semantically similar to the noisy one get hit hardest, since the relation matching loss reads more strongly between them. The authors visualize this on ImageNet with a real spurious case where a dog photo with a watery background gets contaminated by a wrongly predicted computer mouse, and the gradient diffusion is exactly as the synthetic experiment predicted.
From these two findings the remedy almost writes itself. To fight overfitting, give the student richer learning signals and more regularization. For relation matching, that means richer relations. To fight spurious gradient diffusion, identify and suppress the bad edges in the relation graph. The authors then build a method that does both.
The virtual view trick
Here is where it gets interesting. The authors generate a second view of every input image using RandAugment, the same stochastic augmentation policy popular in self supervised learning. So every batch now contains real images and virtual images, paired up. The teacher and the student each process both views, producing twice as many predictions per batch.
With predictions doubled, the affinity graph triples in expressiveness. There are still inter sample relations among the real views, like in any relation matching method. There are now also inter sample relations among the virtual views. And there is a new category, inter view relations between real and virtual versions of the same image, which is the genuinely new contribution. The student now has to match how a real cat relates to a virtually augmented cat, how a real cat relates to a virtually augmented dog, and so on across the whole batch.
The most regularizing relations are the asymmetric ones. Forcing the student to match how the teacher connects a real sample to a transformed copy of itself turns out to be a harder and more useful objective than matching the easier intra view relations. A way to read Zhang and colleagues
The affinity graph itself is constructed differently from prior work. Most relation based methods, including the strong DIST baseline, encode the relation between two predictions as a Gram matrix entry, basically an inner product. The authors point out that this collapses a vector relationship into a scalar, throwing away the class wise structure of the difference. Their construction keeps the structure. For two prediction vectors \( z_i \) and \( z_j \) over C classes, the edge between them is the normalized difference vector itself, living in \( \mathbb{R}^C \). Stacking all edges gives a tensor of shape B by B by C, where the first two axes index samples and the third preserves class information.
The inter class graph mirrors this construction but swaps the roles of sample and class dimensions. Each vertex is now a class wise logit vector across the batch, of dimension B, and edges between classes are normalized differences in \( \mathbb{R}^B \). The full edge tensor is C by C by B. This dual formulation captures inter sample structure with class wise auxiliary knowledge in one tensor, and inter class structure with sample wise auxiliary knowledge in the other.
The ablation in Table 7 of the paper makes the case for this format. Swapping the VRM relation encoding out for traditional Gram matrices, on the same backbone with no other changes, drops accuracy by more than a full point. Swapping in third order angular relations from RKD does worse still. Preserving the secondary dimension is doing real work.
Pruning the graph that just doubled
Doubling the predictions quadruples the edges in the affinity graph. The inter sample tensor balloons from B by B by C to 2B by 2B by C. Without intervention, training time and memory blow up. The pruning step is partly a performance fix and partly a regularization mechanism in its own right.
The authors prune in two stages. The first stage handles redundant edges. The edge tensor is symmetric along its diagonal, so half of it carries no new information. The intra view edges between two real samples or two virtual samples turn out to be the easy ones, the ones the student fits without trouble, so the authors drop them too. What remains is purely inter view edges between real and virtual samples, which are both novel and harder to match. The same logic applies to the inter class graph, where the augmented tensor gets decomposed back into a single B by C structure that captures only real to virtual affinities.
The second stage handles unreliable edges. This is where the spurious gradient problem gets attacked directly. For each edge in the pruned graph, the authors compute the joint entropy of the two endpoint student predictions. Higher joint entropy means the two predictions are more divergent or more uncertain. Edges whose joint entropy lands above a chosen percentile within the batch are dropped before the loss is computed. The threshold m is a hyperparameter, but the set of dropped edges shifts every iteration as student predictions evolve, which means the pruning is genuinely dynamic.
One detail worth flagging. Earlier work like REM used the maximum predicted probability as the reliability score, which biases toward easy samples that the student already gets right. The authors argue this is exactly wrong for distillation, where you want the student to learn from informative disagreements. Joint entropy measures discrepancy between predictions, which is closer to what you actually want to filter on. The Figure 8 analysis in the paper shows that unreliable edge pruning increases average pairwise gradient cosine similarity within a batch over training, which is a clean way of saying that gradient conflicts go down and the student converges faster.
The numbers, and what they show
The evaluation grid is large. Six teacher and student pairs on CIFAR-100 with same family architectures, six more with mixed families, two on ImageNet, two on MS-COCO for object detection, and four on CIFAR-100 with vision transformer students learning from a ResNet teacher. The results are remarkably consistent.
| Setting | Teacher | Student | Best Prior | VRM | Gain |
|---|---|---|---|---|---|
| CIFAR-100 same family | ResNet32x4 | ResNet8x4 | 77.60 (CRLD) | 78.76 | +1.16 |
| CIFAR-100 same family | WRN-40-2 | WRN-16-2 | 76.45 (CRLD) | 77.47 | +1.02 |
| CIFAR-100 mixed | ResNet50 | MobileNetV2 | 71.36 (CRLD) | 72.30 | +0.94 |
| CIFAR-100 mixed | VGG-13 | MobileNetV2 | 70.65 (FCFD) | 71.66 | +1.01 |
| ImageNet | ResNet50 | MobileNetV2 | 73.53 (CRLD) | 74.16 | +0.63 |
| ImageNet | ResNet34 | ResNet18 | 72.37 (CRLD) | 72.67 | +0.30 |
| CIFAR-100 ViT student | ResNet56 | DeiT-T | 78.58 (AutoKD) | 79.52 | +0.94 |
| MS-COCO detection AP | ResNet50 | MobileNetV2 | 32.34 (DKD) | 32.67 | +0.33 |
The most quoted number in the paper, the 14.44 percent improvement for DeiT-T, comes from comparing against the bare student baseline of 65.08 percent rather than against the strongest prior method. Read as a gain over AutoKD with its neural architecture search, the improvement is just under a point, which is still meaningful but less dramatic. The honest headline is that VRM lifts the ceiling on a hard cross architecture distillation case where prior methods had plateaued.
What is harder to dismiss is the ImageNet ResNet50 to MobileNetV2 result. Crossing 74 percent on this benchmark has been a stubborn problem. FCFD got to 73.37 with feature alignment tricks. CRLD got to 73.53 by enforcing cross view consistency. VRM gets to 74.16 by changing only the relational loss, with no extra trainable parameters and no projector heads. The gap to the teacher narrows by close to a full point compared to the previous best, which is the kind of margin that matters in production deployment.
On MS-COCO the result is more nuanced. VRM is the strongest logit or relation based method and competitive with strong feature based detectors like FCFD and ReviewKD. It does not lead the feature based pack outright, which the authors attribute to the fact that object detection rewards fine grained spatial features that feature distillation can target directly. This is one of the more honest sections in the paper. Object detection is hard for any logit based method, and VRM does not claim to overturn that.
Where VRM does not change the rules
The framework is light on parameters but not on hyperparameters. There are three to set. The weight alpha on the inter sample loss, the weight beta on the inter class loss, and the augmentation strength n controlling how aggressive RandAugment gets when producing virtual views. Table 8 in the paper gives sensible ranges. Alpha around 128 and beta around 32 work for most settings. The augmentation strength n equal to 2 wins on CIFAR-100 with weak weak being slightly worse. On ImageNet the choice matters less because the natural variance in large images already produces large teacher to student prediction discrepancy, so heavier augmentation does not add as much.
The method is sensitive to batch size, in a good way. Figure 6 shows that DIST, the strongest prior relation method, degrades sharply as batch size grows beyond 128. VRM holds its performance up to batch size 512. This matters when training large student models where batches are constrained by GPU memory budgets that no longer leave room for the older relation methods.
The method does not work as well on features as on logits. The authors run an ablation where the affinity graph is built from penultimate layer feature vectors instead of the logits. Performance drops by about two points. The argument they make is that logits compress the categorical signal more tightly, and since VRM does not have any direct instance matching objective to anchor the features, the relational signal alone is too weak to organize an embedding space. This is a real limitation if you wanted to use VRM as a feature distillation framework, although it remains stronger than other relation methods even in that setting.
The longer training experiment in Table 15 is encouraging. VRM gains about 0.21 points from a 360 epoch schedule over the standard 240 epochs, while KD, RKD, and DIST stay flat or get slightly worse. The intuition is that richer relations give the student more to keep learning from, so it benefits from more iterations rather than plateauing into overfit territory.
What this changes for practitioners
If you train students through distillation and your task is classification, the case for trying VRM is straightforward. The method needs no architectural changes, no auxiliary networks, no multi stage training. You replace the distillation loss with the inter sample and inter class virtual relation terms and add a RandAugment pipeline for the virtual view. The expected lift on classification benchmarks is in the half a point to two point range, more on heterogeneous teacher and student pairs.
If you work on vision transformer distillation specifically, the case is stronger. The DeiT-T and PiT-T results in Table 4 are some of the best published numbers for distilling a convolutional teacher into a transformer student. The structural mismatch between the two architectures is exactly what relation based methods were always supposed to handle well, and VRM finally delivers on that promise.
If your task is object detection, the case is more mixed. VRM beats every logit based method and matches strong feature based detectors, but it does not lead the feature side outright. For detection, the recommendation is to use VRM if you want a simple, fast distillation pipeline that does not need feature alignment infrastructure, and to use a feature based method like FCFD if you can afford the extra complexity for that last point of AP.
The pruning component is where there is room to experiment. The unreliable edge percentile is set conservatively in the paper. If you have noisier teacher predictions, say a teacher trained with label smoothing or distilled itself, more aggressive pruning may help. Joint entropy is one reasonable measure of edge reliability but it is not the only one. The paper opens up the question without claiming to have settled it.
Reproducing VRM in PyTorch
The construction of the affinity tensors looks intimidating in equations but is actually compact in code. The authors include a 12 line pseudocode in the supplementary material. Here is a complete reference implementation that follows the paper, including the joint entropy based unreliable edge pruning and the redundant edge masking.
The implementation is intentionally close to the paper’s pseudocode rather than highly optimized. A production pipeline would batch the augmentation, fuse the inter sample and inter class edge computations, and cache the teacher predictions. The structure here makes the math visible, which matters when adapting the loss to non standard architectures or feature spaces. The official reference code from the authors is hosted in the supplementary material of the paper.
Conclusion
The framing argument of this paper is the most useful contribution. Relation based knowledge distillation had been losing for reasons nobody had cleanly named. The pilot studies in Section 4 of the paper do the diagnostic work that the literature had skipped, and the diagnosis turns out to be precise enough to act on. Overfitting because relation matching is a weaker constraint. Spurious gradient diffusion because every sample is connected to every other in the relation graph. Once you state the problems this way, the remedies follow almost mechanically. Richer relations through virtual views, and pruning of the unreliable edges.
The technical execution is solid. The virtual view construction reuses RandAugment, which is a well understood augmentation policy from the self supervised learning world. The affinity graph format that preserves class structure along a secondary dimension is a small change from the Gram matrix conventions of prior work, but the ablation shows it carries more than a point of accuracy on its own. The joint entropy criterion for unreliable edge pruning is the kind of detail that often gets glossed over but is doing real work, as the gradient cosine similarity analysis demonstrates.
The transferability deserves a second look. The same loss function that beats CRLD on ImageNet classification also beats AutoKD on CIFAR-100 ViT distillation and beats DKD on MS-COCO object detection. That breadth, on three different downstream tasks with very different statistical structures, is unusual for a method that did not have to be tuned per task. It suggests the diagnosis was capturing something more fundamental than a benchmark gaming trick.
The honest gaps are worth flagging. Object detection still favors feature based distillation, where spatial structure matters more than relational structure. Feature space VRM works less well than logit space VRM, which means the method does not yet generalize to scenarios where you cannot access the final classifier. The three hyperparameters are well behaved in the paper’s experiments but still require some tuning when the teacher and student gap looks unusual. None of these are blockers, but they mark where future work has room to move.
The reason this paper matters is that it puts relation based distillation back in contention. For three or four years the conventional wisdom has been that instance matching was just better, that relations were a clever idea that did not pay off in practice. VRM does not just close the gap, it overtakes the strongest instance matching baselines across the standard benchmarks. The implication is that the prior generation of relation methods were under realizing the potential of the approach, not that the approach itself was wrong. That is the kind of correction that is worth more than a single benchmark point. It opens a door that had been treated as closed.
Frequently Asked Questions
What is the difference between instance matching and relation matching in knowledge distillation?
Instance matching forces the student to copy each individual teacher prediction. The loss is computed per sample and summed across the batch. Relation matching instead asks the student to copy how teacher predictions relate to each other across a batch, such as which samples the teacher considers similar. Instance matching is the stronger constraint mathematically, while relation matching is supposed to be more robust to architectural differences between teacher and student.
Why has relation matching been losing to instance matching in recent benchmarks?
The VRM paper traces it to two specific problems. First, relation matching is a weaker constraint than instance matching, which makes the student more prone to overfitting the training set without generalizing. Second, in the relation graph every sample is connected to every other sample, so a noisy prediction propagates spurious gradients across the entire batch. Earlier relation based methods had no mechanism to defend against either issue.
What is a virtual view in VRM?
A virtual view is a stochastically augmented copy of an input image, produced by applying RandAugment transformations. For every real image in a batch, VRM creates one virtual view. The teacher and student each process both versions, doubling the available predictions. This lets VRM construct three new kinds of relations beyond what prior methods used. Relations among real samples, relations among virtual samples, and the genuinely new inter view relations connecting real and virtual versions of each image.
How does VRM decide which edges to prune?
VRM prunes in two stages. The redundant edge pruning removes the symmetric half of the affinity graph and drops intra view edges, since these turn out to be easier and less informative than inter view edges. The unreliable edge pruning uses joint entropy of student predictions to identify edges between uncertain or conflicting predictions. Edges with joint entropy above a percentile threshold are dropped before the loss is computed. The percentile is fixed, but the actual set of dropped edges changes every iteration as the student improves.
How does VRM compare to the alpha beta divergence approach for knowledge distillation?
They attack different parts of the distillation pipeline. The alpha beta divergence framework, ABKD, changes the divergence function used to compare individual teacher and student predictions, which is an instance matching improvement. VRM keeps the divergence simple but changes the entire structure of what gets compared, building affinity graphs over batches instead of matching per sample distributions. The two are largely orthogonal and could in principle be combined.
Does VRM work for object detection?
Yes, with caveats. On MS-COCO, VRM beats every logit and relation based detection distillation method, and it matches strong feature based methods like FCFD and ReviewKD within about a point of AP. It does not lead the feature based pack outright, because object detection rewards fine grained spatial features that feature distillation can target directly. The honest recommendation is to use VRM if you want a simple pipeline without feature alignment infrastructure, and to use a feature based method if you can afford the complexity for that last bit of detection performance.
Read the full VRM paper
The paper has the complete pilot studies, ablations, t-SNE embeddings, loss landscape visualizations, and the cross architecture results on vision transformers.
Read the arXiv paper Download PDFCitation. Zhang, W., Xie, F., Cai, W., and Ma, C. (2025). VRM, Knowledge Distillation via Virtual Relation Matching. arXiv preprint arXiv:2502.20760v3. Available at https://arxiv.org/abs/2502.20760.
This analysis is based on the published paper and an independent evaluation of its claims.