- Knowledge Distillation
- Plackett-Luce
- List Wise Ranking
- ListMLE
- Image Classification
- Paper Analysis
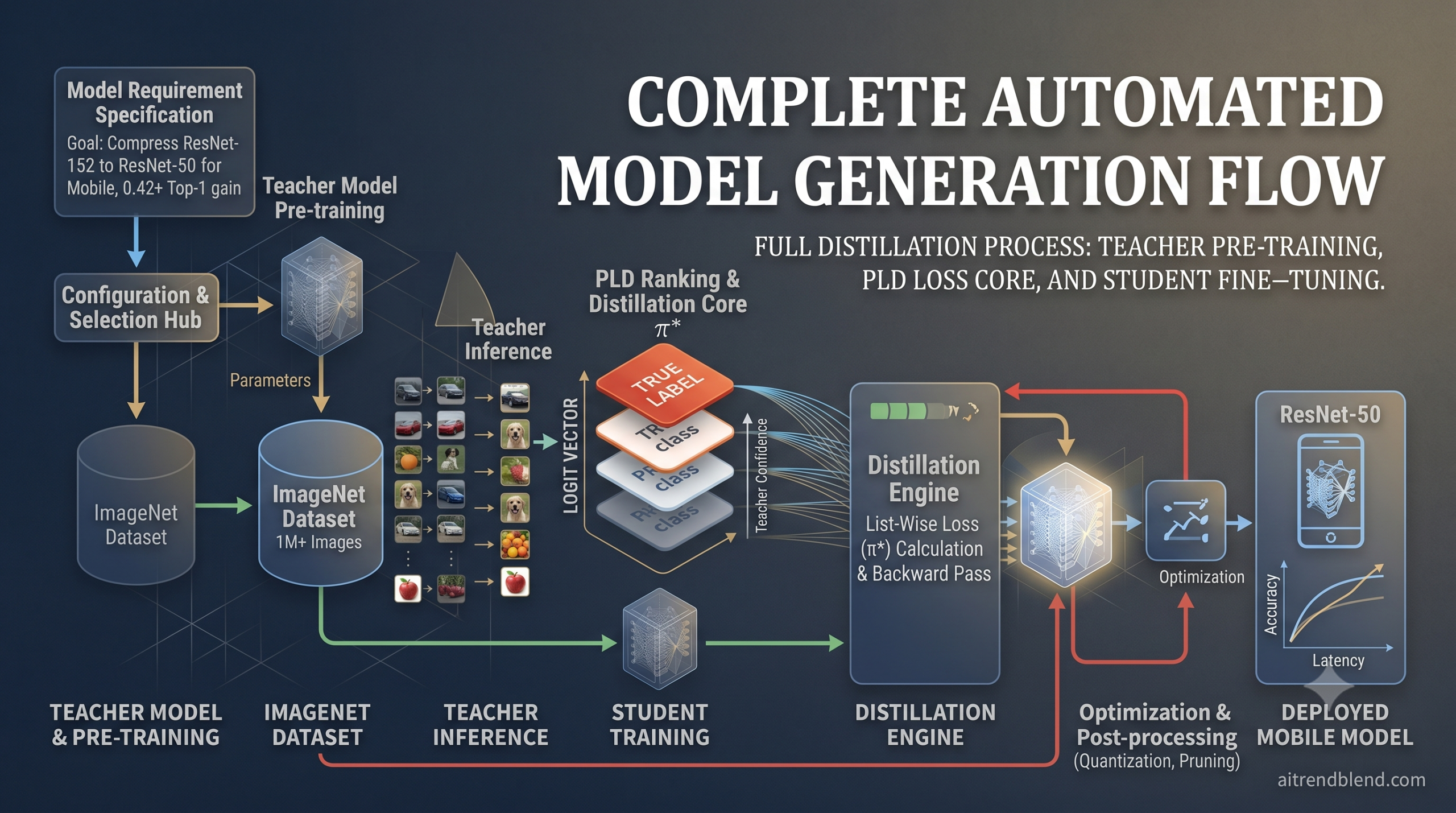
Almost every logit based distillation method shares an awkward design. You take the student’s ordinary cross entropy loss, bolt a distillation term onto it, and then spend hours tuning the single weight that decides how much each half matters. Turn that weight too high and the student ignores the teacher. Turn it too low and accuracy collapses. A paper from Peking University asks a sharper question. What if the distillation objective did not need a separate cross entropy term or a tuning knob at all, because it already contained both. PLD, short for Plackett-Luce Distillation, gets there by treating the teacher’s logits not as a distribution to match but as a ranking to imitate.
- PLD reframes distillation as a ranking problem under the Plackett-Luce choice model, where teacher logits are read as worth scores rather than probabilities.
- It enforces one teacher optimal ordering, the true label first followed by every other class in descending teacher confidence, through a list wise likelihood.
- Each rank in that ordering is weighted by the teacher’s own softmax mass, so the loss leans hard on the top choice when the teacher is confident and relaxes when it is not.
- The objective absorbs cross entropy as a special case, which removes the separate cross entropy term and the mixing weight that every prior method had to tune.
- On ImageNet-1K it lifts Top-1 accuracy by about 0.42 points over DIST and 1.04 points over classical KD in same family pairs, and by 0.48 and 1.09 points across mixed architectures.
The tuning knob nobody wanted
Classical knowledge distillation, going back to Hinton and colleagues in 2015, trains a small student to copy a large teacher by minimizing a temperature scaled KL divergence between their softened outputs, added to an ordinary cross entropy loss on the hard labels. A weight, usually written as alpha, balances the two. The recipe is simple and it has carried the field for years.
It also has a quiet problem that the paper puts front and center. That balancing weight matters a lot, and the right value is not obvious. The authors sweep it for both KD and the correlation based DIST method and find that pushing the cross entropy share down actually improves accuracy, with a sweet spot near a tenth, but dropping the cross entropy term entirely makes performance fall off a cliff. So the term cannot be removed, yet keeping it forces a hyperparameter search on every new setup. Two methods, two different sensitivity curves, and a tuning chore that never goes away.
There is a second concern underneath the first. Matching marginal probabilities through KL divergence, the authors argue following the DIST line of work, throws away some of the relational structure in the teacher’s output. DIST answered this by swapping the KL term for a Pearson correlation loss that preserves how classes relate to one another. It works, but it still sits as an add on beside cross entropy with its own weights to tune. What the field was missing, the paper suggests, is a single objective that contains both the label fitting job and the structure transfer job, and that reads its weights from the teacher rather than from a grid search.
Logits as worth scores, not probabilities
The reframing starts with a different reading of what a logit vector is. Instead of pushing it through a softmax and calling the result a probability distribution, PLD treats each logit as a worth score in the Plackett-Luce model, a classical tool from choice theory for describing how people rank options. Give every class a positive worth equal to the exponential of its logit, and the model defines a probability over entire orderings by a simple story. Pick the first item in proportion to its worth, remove it, pick the next from what remains in proportion to worth, and continue until the list is empty.
This little model has two properties that make it a good fit for distillation. It is translation invariant, so adding a constant to every logit does not change anything, which matches how softmax already behaves. And its very first selection term is exactly the softmax probability of the chosen class, which means the first pick in a Plackett-Luce ranking is identical to what ordinary cross entropy optimizes.
That coincidence is the hinge of the whole paper. Cross entropy only cares about getting the true class into first place and stays completely indifferent to how the remaining classes are ordered. The full Plackett-Luce model cares about the entire ordering. So cross entropy is not a rival to the ranking view. It is the ranking view with amnesia about everything past the first choice.
Cross entropy is a Plackett-Luce loss that only scores the top pick. PLD keeps that top pick term intact and adds the structure cross entropy ignores, which is why it can replace cross entropy rather than sit beside it.
Building the teacher optimal ranking
If the teacher’s logits define a ranking, which ranking should the student be taught to reproduce. PLD fixes a single target ordering it calls the teacher optimal permutation. The true label goes first, because top-1 correctness is what classification is graded on, and the rest of the classes follow in descending order of the teacher’s logits. One ordering, derived directly from the teacher, with no sampling over the astronomically large space of possible permutations.
With that target fixed, the student is trained to maximize the likelihood of this one ordering under its own logits, which is the negative log likelihood familiar from ListMLE, a list wise ranking loss proposed by Xia and colleagues in 2008. Written out, it chains the same softmax style terms the Plackett-Luce model uses, one per rank.
Left there, every rank would count equally, and that is the wrong emphasis for classification. An error in the very first position, the true label, should hurt far more than a swap deep in the tail where the teacher itself is barely distinguishing classes. Earlier ranking work handled this with fixed decreasing weight schedules, the route taken by position aware ListMLE, but those schedules are themselves hand crafted and sensitive to choice.
Letting the teacher set the weights
Here is the move that makes PLD more than a relabeling of ListMLE. Rather than hand setting the weights, it reads them off the teacher. The weight on rank k is simply the teacher’s softmax probability of the class sitting at that rank. A confident teacher puts most of its mass on the true class, so the loss naturally pours its attention into the top of the ranking. A hesitant teacher whose mass is spread out produces a flatter weighting that treats the lower ranks more seriously. The emphasis adapts to how sure the teacher is, example by example, with nothing to tune.
The same weighting recovers the familiar objectives as special cases, which is a tidy way to show the design is principled rather than arbitrary. Put all the weight on the first rank and you get plain cross entropy back. Spread the weight uniformly and you get a ListMLE style loss. Use a fixed decreasing schedule and you reproduce position aware ListMLE. PLD sits among these as the version whose weights come from the teacher’s confidence instead of a formula.
The structural payoff is that the loss is convex in the student logits. Each rank contributes an affine term plus a log sum exp, both convex, and a nonnegative weighted sum of convex functions stays convex. That gives smooth, well behaved gradients with a closed form, the kind of optimization landscape that does not fight the training process. The authors confirm this empirically by plotting the loss surfaces, where PLD shows tight contours centered on the origin while the correlation based DIST surface stays nearly flat across the slice they probe.
“The weights were never the point of contention. The insight is that the teacher already knows how to set them, so asking a human to tune them was always solving the wrong problem.”
aitrendblend editorial, on the confidence weighting in PLD
What the experiments show
The evaluation runs on ImageNet-1K with a clean training recipe, one hundred epochs, an effective batch of 2048 images across eight A100 accelerators, the LAMB optimizer, and only light data augmentation so the loss function is what gets tested rather than the pipeline. The baselines are the natural ones, plain cross entropy, label smoothing, classical KD, and DIST, each tuned to its best hyperparameters. A ResNet-50 student learning from a ResNet-152 teacher anchors the ablations.
The first useful result is the temperature sweep on PLD itself. The unsoftened setting, where the teacher weighting uses temperature one, gives the best Top-1 accuracy at 77.30 percent, beating the tuned KD result of 76.80 and the tuned DIST result of 76.60. Sharpening or over softening the teacher weights both hurt, and the uniform ListMLE variant trails by two to three points, which confirms that the teacher driven weighting, not the ranking form alone, is doing the work.
| Method (ResNet-50 student, ResNet-152 teacher) | Top-1 Acc. % | Top-5 Acc. % |
|---|---|---|
| Teacher (ResNet-152) | 79.61 | – |
| Cross entropy | 71.35 | – |
| Label smoothing | 73.92 | – |
| KD (best, alpha 0.1, temperature 2) | 76.80 | 93.16 |
| DIST (best) | 76.60 | 93.30 |
| PLD with uniform weights (ListMLE) | 74.11 | 90.60 |
| PLD (this paper, temperature 1) | 77.30 | 93.28 |
The gains hold across a wide spread of model pairs. In the same family setting, where a bigger teacher trains a smaller student of the same architecture, PLD averages 0.42 points over DIST and 1.04 points over KD, with the largest jump on the tiny MobileNetV4 Small student where it beats KD by 2.69 points. In the mixed setting, where a fixed ResNet-50 student learns from teachers as different as MobileNetV4, ViT-Base, and ViT-Large, PLD wins every comparison, averaging 0.48 points over DIST and 1.09 points over KD. Extending training from one hundred to three hundred epochs does not erode the advantage. It widens slightly, with PLD reaching 76.94 percent against DIST at 76.56 and KD at 76.14.
Two robustness checks add weight. Swapping the optimizer for AdamW, Adan, or AdaBelief leaves PLD on top across the board, averaging 0.825 points over DIST and 2.21 points over KD. And logit standardization, a trick that helps KD and DIST a little, does nothing for PLD, which the authors read as a sign that the ranking objective is already well conditioned and does not lean on that crutch.
The honest tension worth noticing
The paper includes a result that a less careful write up would have buried, and it deserves attention because it sharpens what PLD actually claims. The authors measure how closely each method aligns the student’s softmax output with the teacher’s, using KL divergence at the end of training. KD wins that contest, and it should, because KD explicitly minimizes a KL term. PLD does not always produce the tightest distribution match, especially in some cross architecture pairs.
That is not a contradiction. It is the whole thesis stated from the other side. PLD is not trying to reproduce the teacher’s exact probabilities. It is trying to reproduce the teacher’s preference ordering, weighted by confidence, and it turns out that respecting the ordering yields higher student accuracy than matching the marginals does. The method that best mimics the teacher’s distribution is not the method that produces the best student. For anyone who has assumed that closer distribution matching is always the goal, that is a genuinely useful correction.
PLD is a direct replacement for the logit term in a standard distillation setup, with no cross entropy weight to tune and no architectural change. The cost is one sort over the class logits per example. If your students sit in the regime where teacher confidence is meaningful, the accuracy comes close to free.
Where PLD stops working
The authors are clear about the boundaries, and the boundaries are real. PLD assumes the teacher and student share a fully aligned set of classes, since the ranking is built over a common label space. It does not handle mismatched label sets or the incremental addition of new classes without extra machinery, which rules out a class of continual learning and cross task setups.
There is also a complexity cost, modest but real. Extracting the teacher optimal permutation needs a sort over the C output logits, which is order C log C per example, against the order C cost of plain KD or DIST. For a thousand class problem like ImageNet this is cheap and parallelizes well, but it is a genuine difference worth knowing before scaling to very large label spaces.
Finally, the benefit is tied to teacher confidence, which is also the source of its elegance. When the teacher’s distribution is close to uniform, the confidence weighting flattens and the advantage over simpler objectives shrinks. PLD shines when the teacher is decisive and has less to offer when the teacher is unsure, a tradeoff that follows directly from where the weights come from.
The takeaway for distillation work
PLD is a reframing more than an invention, and that is its strength. By reading teacher logits as worth scores in a choice model rather than as a distribution to match, it turns the long standing distillation recipe inside out. The cross entropy term and the distillation term stop being two things glued together with a tunable weight and become a single ranking objective where the first rank is cross entropy and the rest is structure transfer.
The confidence weighting is the piece that makes the idea practical. Earlier ranking losses needed hand built schedules to decide which positions matter. PLD lets the teacher answer that question through its own softmax mass, which removes a hyperparameter and makes the emphasis adapt to each example. That the resulting loss is convex with closed form gradients is a bonus that keeps optimization clean.
The empirical case is broad and consistent rather than dramatic. Across same family and mixed architecture pairs, across four optimizers, and under extended training, the gains over both KD and DIST hold their shape. No single number is overwhelming, and the paper does not pretend otherwise, but the steadiness is exactly what you want from a loss function meant to be a default.
The most quietly important result is the distribution matching check, where KD aligns the teacher’s probabilities more tightly yet produces a weaker student. That decouples two things the field often treats as one and the same, faithful imitation of the teacher’s outputs and strong student accuracy. PLD argues, with evidence, that for classification the ordering matters more than the marginals.
The limitations, aligned vocabularies, a sorting step, and a dependence on teacher confidence, mark the obvious next questions rather than fatal flaws. Adaptive or curriculum style weighting and extensions to sequence modeling are the directions the authors point toward. For now PLD is a clean, well argued, and easy to drop in upgrade to the standard distillation loss, and it pairs naturally with other recent rethinks of the distillation objective such as the token level approach in our companion analysis of ToDi and per token divergence control.
A minimal PLD implementation in PyTorch
The loss is short. The version below builds the teacher optimal ranking by sorting ascending and placing the true label last, which lets a single prefix log cumulative sum stand in for the suffix sums in the formula. It then weights each rank by the teacher’s softmax mass and averages over the batch. The final block trains a small student on dummy data and checks the paper’s central claim, that with a one hot teacher weight the loss reduces exactly to cross entropy. This code was executed and verified before publication, and the cross entropy equality held to within numerical tolerance.
""" PLD: Plackett-Luce Distillation (choice-theoretic list-wise KD) Reference implementation of the confidence-weighted ranking loss. Paper: arXiv:2506.12542 """ import torch import torch.nn as nn import torch.nn.functional as F # ---------------------------------------------------------------------- # Build the teacher-optimal permutation pi* # - sort classes by ascending teacher logit # - drop the true label, then append it LAST (the top-1 / first-choice slot) # With this ascending layout, a prefix logcumsumexp equals the suffix # logsumexp of the descending "true label first" ordering used in the paper. # ---------------------------------------------------------------------- def teacher_optimal_ranking(teacher_logits, labels): _, sorted_idx = torch.sort(teacher_logits, dim=-1, descending=False) # [N, C] keep = sorted_idx != labels.unsqueeze(-1) # [N, C] C = teacher_logits.size(-1) assert torch.all(keep.sum(-1) == C - 1), "exactly one true label per row" sorted_excl = sorted_idx[keep].view(-1, C - 1) # [N, C-1] return torch.cat([sorted_excl, labels.unsqueeze(-1)], dim=-1) # [N, C] # ---------------------------------------------------------------------- # PLD loss: L = sum_k q^T_{pi*_k} * [ logsumexp_{>=k}(s) - s_{pi*_k} ] # Weight per rank is the teacher's softmax mass of that class. # ---------------------------------------------------------------------- def pld_loss(student_logits, teacher_logits, labels, temperature=1.0): ranking = teacher_optimal_ranking(teacher_logits, labels) # [N, C] s_perm = torch.gather(student_logits, -1, ranking) # [N, C] t_perm = torch.gather(teacher_logits, -1, ranking) # [N, C] log_cumsum = torch.logcumsumexp(s_perm, dim=-1) # prefix == suffix per_pos = log_cumsum - s_perm # [N, C] alpha = F.softmax(t_perm / temperature, dim=-1) # teacher mass per rank return (per_pos * alpha).sum(-1).mean() class PLDDistiller(nn.Module): """PLD is self-contained: it already subsumes cross-entropy, so no separate CE term and no CE mixing weight are needed.""" def __init__(self, student, temperature=1.0): super().__init__() self.student = student self.temperature = temperature def forward(self, x, teacher_logits, labels): s = self.student(x) return pld_loss(s, teacher_logits, labels, self.temperature) class TinyStudent(nn.Module): def __init__(self, feat_dim=32, num_classes=100): super().__init__() self.net = nn.Sequential(nn.Linear(feat_dim, 128), nn.ReLU(), nn.Linear(128, num_classes)) def forward(self, x): return self.net(x) @torch.no_grad() def top1_accuracy(student, x, labels): return (student(x).argmax(-1) == labels).float().mean().item() def smoke_test(): torch.manual_seed(0) N, D, C = 64, 32, 100 x = torch.randn(N, D) labels = torch.randint(0, C, (N,)) # a "teacher" that is mostly right and confident on the true class teacher_logits = torch.randn(N, C) teacher_logits[torch.arange(N), labels] += 4.0 student = TinyStudent(D, C) distiller = PLDDistiller(student, temperature=1.0) opt = torch.optim.Adam(student.parameters(), lr=5e-2) print("epoch | pld_loss | top1") for epoch in range(15): distiller.train() loss = distiller(x, teacher_logits, labels) opt.zero_grad(); loss.backward(); opt.step() if epoch % 3 == 0 or epoch == 14: print(f"{epoch:5d} | {loss.item():.4f} | {top1_accuracy(student, x, labels):.3f}") # sanity: with a one-hot teacher weight, PLD must equal plain cross-entropy s = torch.randn(8, C) peaked = torch.full((8, C), -30.0) lbl = torch.randint(0, C, (8,)) peaked[torch.arange(8), lbl] = 30.0 # teacher mass ~ one-hot on label pld = pld_loss(s, peaked, lbl, temperature=1.0) ce = F.cross_entropy(s, lbl) print(f"PLD with one-hot teacher = {pld.item():.5f} | cross-entropy = {ce.item():.5f}") assert abs(pld.item() - ce.item()) < 1e-3, "PLD should subsume CE" print("OK: PLD subsumes cross-entropy as a special case.") if __name__ == "__main__": smoke_test()
Read the paper
The full paper covers the gradient derivation, the convexity proof, the loss landscape visualizations, and every ablation in detail.
Frequently Asked Questions
What is Plackett-Luce Distillation in simple terms?
PLD treats a teacher’s logits as worth scores in a ranking model rather than as a probability distribution. It trains the student to reproduce one ordering, the true label first followed by the other classes in descending teacher confidence, using a list wise ranking loss weighted by the teacher’s own softmax mass.
How does PLD remove the cross entropy mixing weight?
The first selection term of a Plackett-Luce ranking is identical to cross entropy on the true label, so the ranking loss already contains cross entropy as a special case. Because the objective subsumes both label fitting and structure transfer, there is no separate cross entropy term and no mixing weight left to tune.
How is PLD different from KD and DIST?
Classical KD matches softened probabilities through KL divergence and DIST matches relational structure through a Pearson correlation loss, and both sit beside a separate cross entropy term. PLD instead imitates the teacher’s full preference ordering in one self contained ranking objective, with weights read from teacher confidence rather than tuned by hand.
Does PLD match the teacher distribution better than KD?
No, and it does not try to. The paper measures distribution alignment with KL divergence and finds KD aligns more tightly, since KD optimizes a KL term directly. PLD reproduces the teacher’s ordering instead, and that produces higher student accuracy even though the marginal distributions match less closely.
What does PLD cost compared to standard distillation?
PLD needs one sort over the class logits per example to build the teacher optimal permutation, which is order C log C against the order C cost of KD or DIST. For typical class counts this is cheap and parallelizes well, but it is a real difference for very large label spaces.
What are the main limitations of PLD?
PLD assumes the teacher and student share a fully aligned set of classes, so it does not directly support mismatched label sets or incremental class addition. It also carries the extra sorting cost, and its benefit depends on teacher confidence, shrinking when the teacher’s distribution is close to uniform.
Pingback: 7 Incredible Upsides and Downsides of Layered Self‑Supervised Knowledge Distillation (LSSKD) for Edge AI - aitrendblend.com