Key points
- The paper identifies why a strong pretrained teacher can actually hurt a small student, a well documented issue called the capacity gap problem.
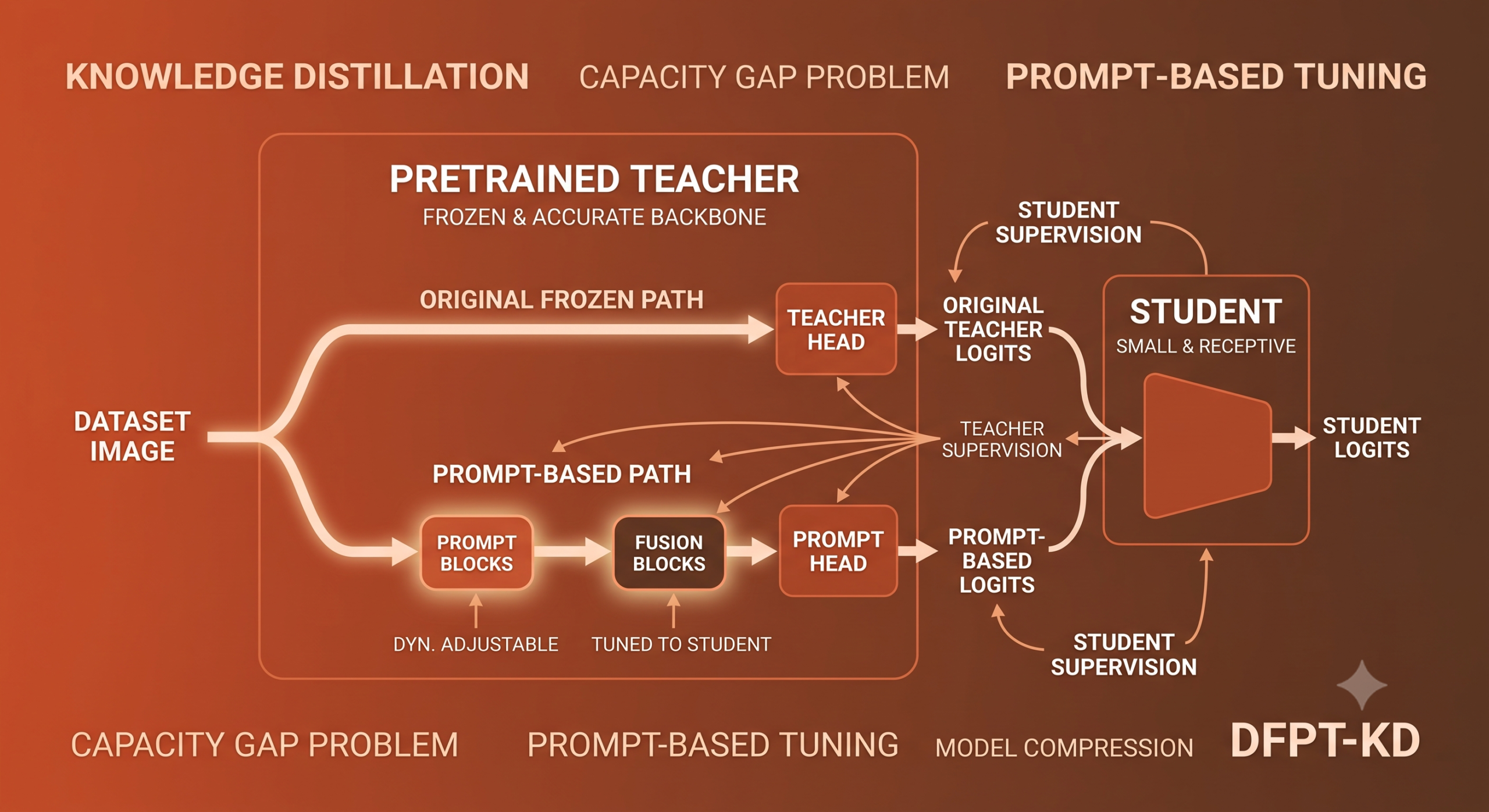
- Dual Forward Path Teacher Knowledge Distillation, shortened to DFPT-KD, adds a second forward path inside the frozen teacher rather than shrinking the teacher or adding teacher assistants.
- The new path is trained with prompt blocks and fusion blocks under supervision from both the original teacher output and the student, so it learns to speak the student’s language.
- A stronger variant, DFPT-KDt, unfreezes the whole prompt path and pushes results further, in some pairs above the original teacher’s own accuracy.
- Tested on CIFAR-100, ImageNet, and CUB-200 across VGG, ResNet, Wide ResNet, and the ShuffleNet and MobileNet families, with consistent gains over vanilla KD and several adaptive KD baselines.
Why a smart teacher can be a bad teacher
The idea of knowledge distillation goes back to Hinton, Vinyals, and Dean, who proposed training a small student network to mimic the softened output probabilities of a large teacher rather than only the hard labels. It works remarkably well in a lot of cases. Yet researchers kept noticing an odd pattern. Push the teacher to be more and more accurate, and at some point the student stops improving, sometimes it even gets worse. Cho and Hariharan showed that a fully trained teacher is not always the best choice for distillation. Mirzadeh and colleagues gave this effect a name, the capacity gap problem, and confirmed it experimentally across model families.
The authors of this paper walk through the actual mechanics of why that happens, and it is a cleaner explanation than the usual hand wave about mismatched sizes. During pretraining, a teacher’s confidence in the correct class keeps climbing while its confidence in every other class keeps shrinking, because that is literally what minimizing negative log likelihood does. A small student, with far less representational room to work with, cannot spread its own confidence that thin. So when the student tries to match a teacher whose probability mass is almost entirely concentrated on one class, the two distributions are simply incompatible, not because the teacher is wrong, but because the shape of its answer does not fit inside the student’s capacity.
The math behind the mismatch
The paper rederives the vanilla KD loss in a form borrowed from decoupled knowledge distillation. For a classification task with C classes, the softened prediction from logits z at temperature τ is given by the usual softmax.
Split that prediction into two pieces, the probability mass on the target class and the probability mass spread across every non target class, and the KL divergence loss used in vanilla KD factors cleanly into two terms.
The first term measures how far apart the teacher and student are on the binary question of target versus non target. The second term measures how far apart their distributions are among the non target classes. During training, the pretrained teacher’s confidence on the target class, that \(p_t^{T}\) term, keeps rising while the student’s confidence stays modest for most of training. That imbalance inflates both loss terms and gives the student a moving, oversized target to chase.
What earlier fixes tried, and where they fell short
Two broad families of solutions have been proposed before this paper. Multi stage approaches introduce one or more teacher assistants, medium sized networks that sit between the big teacher and the small student, so the distillation task is broken into smaller hops. TAKD popularized this idea, DGKD extended it with denser supervision across multiple assistants, and ResKD used a residual network to bridge the gap directly. One stage approaches instead try to borrow the teacher’s own training trajectory. ESKD stops training the teacher early so it never gets overconfident, RCO mimics a sequence of checkpoints from the teacher’s training run, and Pro-KD and EKD build smoother, evolving teaching signals along the way.
Both families share a structural weakness. To make the teacher’s knowledge easier for the student to absorb, they have to lower the teacher’s own performance, whether that means an intermediate assistant with a smaller capacity or a teacher that never finished training. That trims away the very accuracy that made the teacher worth learning from in the first place. And because the adjustment is baked in ahead of time, it cannot adapt as the student’s own representation ability changes over the course of training. Early in training the student is a rough learner and late in training it is a much more capable one, but a fixed size teacher assistant treats both phases the same way.
Where this paper differs
Instead of degrading the teacher to make it easier to learn from, DFPT-KD keeps the original teacher fully intact and adds a second path that dynamically adjusts on top of it. The accurate signal never disappears, it just gets a companion signal that is tuned to be reachable.
The dual forward path teacher, piece by piece
The core move borrows an idea from prompt based learning in NLP and vision, where methods like CoOp, CoCoOp, and VPT insert learnable tokens into a frozen pretrained model rather than fine tuning the whole thing. The authors adapt that philosophy to distillation. Rather than adjusting the teacher’s weights wholesale, they insert lightweight prompt blocks at each stage boundary of the teacher’s backbone, and those blocks learn a set of knowledge prompts that are specific to the student they are paired with.
Prompt blocks
Each prompt block is a small convolutional stack designed to be cheap. It starts with a 1 by 1 down sampling convolution that shrinks the channel count by a ratio r1, follows with a multi scale partial convolution using three kernel sizes at once so it captures both fine detail and broader structure, adds a 1 by 1 point wise convolution so information can flow across all channels again, and finishes with a 1 by 1 up sampling convolution that restores the original channel count. Only a fraction of the channels get touched by the partial convolution, controlled by a ratio r2, which keeps the parameter count small. Table VII in the paper reports that the prompt and fusion blocks for a WRN-40-2 teacher cost only 0.03 million parameters and 5.87 million FLOPs, dramatically less than the 1.09 million parameters a comparable teacher assistant network would need.
Fusion blocks
After a prompt block generates its knowledge prompt for a given stage, a fusion block combines that prompt with the teacher’s original intermediate feature using a 1 by 1 convolution, producing a blended representation that feeds into the next stage of the backbone. This is what actually creates the second forward path. The teacher’s original weights process the raw input as usual, and in parallel a lightly modified version of the same features, now infused with a learned prompt, threads through the network stage by stage until it reaches its own classification head.
Bidirectional supervision
This is the part that keeps the new path honest. The prompt based path is trained with two pulls at once. Supervision from the teacher’s original, frozen output nudges the path to stay accurate and keep climbing toward the teacher’s own performance. Supervision from the student’s predictions nudges the same path to stay reachable, so its knowledge does not drift back into the overconfident territory that caused the capacity gap in the first place. In an ablation shown in Figure 3 of the paper, training accuracy for the prompt path only improved when both supervision signals were active together. Teacher only supervision pushed the path upward but let it drift out of the student’s reach, while student only supervision kept it reachable but let accuracy plateau too early. The combination follows what the authors call an easy to hard schedule, since the prompt path starts out close to the student and gradually grows more demanding as training continues, in step with the student’s own improving representation ability.
Here \(p^{P}\) is the prompt path’s prediction, \(p^{T}\) is the frozen teacher’s own prediction, and \(p^{S}\) is the student’s prediction. Note the gradient here touches the prompt blocks, the fusion blocks, and a freshly initialized classification head, while the pretrained backbone stays frozen. That gives the basic version, DFPT-KD.
The stronger variant, DFPT-KDt, takes the same objective but also lets gradients flow into the teacher backbone itself, with a small learning rate, so the whole prompt path can fine tune together rather than working through a fixed set of features.
The student, meanwhile, is trained to match both the teacher’s original path and the new prompt based path at once, which is what gives it access to accurate knowledge and compatible knowledge in the same training step rather than choosing between them.
A theory backed reason to expect this works
The paper leans on VC dimension generalization bounds to argue the point formally rather than just empirically. Because the prompt path is built on top of the original path with lightweight modules and receives reverse supervision from the student, its learning rate related term ends up smaller than the teacher’s, which under their derivation implies the student should achieve lower error learning from the prompt path than from the original one. It is a tidy piece of theory to back up what the experiments already show.
What the numbers actually say
The team tested on CIFAR-100 with matched, same family teacher student pairs and with mismatched, cross family pairs, then repeated the exercise on the much larger ImageNet and on the fine grained CUB-200 bird dataset. They compared against ten feature based distillation methods, nine logit based methods including DKD and the newer LSKD, and four adaptive methods that specifically target the capacity gap, RCO, TAKD, DGKD, and AAKD.
Same family results on CIFAR-100
| Teacher | Student | Teacher Acc | Student Acc | KD | DFPT-KD | DFPT-KDt |
|---|---|---|---|---|---|---|
| ResNet32x4 | ResNet8x4 | 79.42 | 72.50 | 73.33 | 77.48 | 78.63 |
| ResNet110 | ResNet32 | 74.31 | 71.14 | 73.08 | 73.92 | 74.65 |
| ResNet56 | ResNet20 | 72.34 | 69.06 | 70.66 | 71.32 | 72.46 |
| WRN-40-2 | WRN-40-1 | 75.61 | 71.98 | 73.54 | 75.47 | 76.38 |
| WRN-40-2 | WRN-16-2 | 75.61 | 73.26 | 74.92 | 76.68 | 77.23 |
| VGG13 | VGG8 | 74.64 | 70.36 | 72.98 | 75.23 | 75.74 |
The pattern holds across every pair. DFPT-KD beats vanilla KD every time, and DFPT-KDt beats DFPT-KD every time, consistent with what the theory section predicted. The gain over plain KD ranges from about 0.66 to 4.15 points for DFPT-KD and 1.57 to 5.30 points for DFPT-KDt in these matched architecture pairs.
Cross family pairs, where the gap is widest
| Teacher | Student | Teacher Acc | Student Acc | KD | DFPT-KD | DFPT-KDt |
|---|---|---|---|---|---|---|
| ResNet32x4 | ShuffleNetV1 | 79.42 | 70.50 | 74.07 | 77.72 | 79.05 |
| WRN-40-2 | ShuffleNetV1 | 75.61 | 70.50 | 74.83 | 77.53 | 78.29 |
| VGG13 | MobileNetV2 | 74.64 | 64.60 | 67.37 | 70.26 | 70.82 |
| ResNet50 | MobileNetV2 | 79.34 | 64.60 | 67.35 | 70.89 | 71.73 |
| ResNet32x4 | ShuffleNetV2 | 79.42 | 71.82 | 74.45 | 78.74 | 79.85 |
This is the setting where the capacity gap problem tends to bite hardest, since the teacher and student come from entirely different architecture families with very different inductive biases. The WRN-40-2 to ShuffleNetV1 pair is the headline result. DFPT-KDt pushes the student to 78.29 percent top one accuracy, which is 2.68 points higher than the 75.61 percent the teacher itself achieves. A student that outperforms its own teacher is not something vanilla distillation is built to deliver.
Confirming the gap actually closes
Table V in the paper tracks the accuracy gap between teacher and student directly, averaged across the eleven pairs it tests. With no distillation at all the average gap is 6.37 points. Vanilla KD trims that to 3.98 points. DFPT-KD brings it down to 1.41 points. DFPT-KDt brings the average gap to just 0.50 points, and in several individual pairs the gap turns negative, meaning the student edges ahead of the teacher entirely. That is a fairly direct confirmation that the method is doing what it claims to do rather than just improving raw accuracy through some unrelated mechanism.
ImageNet and CUB-200
On the harder, larger ImageNet benchmark, the ResNet34 to ResNet18 pair sees DFPT-KDt gain 1.77 points of top one accuracy and 0.90 points of top five accuracy over vanilla KD. The ResNet50 to MobileNetV2 pair, a more architecturally mismatched combination, sees larger gains of 2.96 points top one and 1.33 points top five. On CUB-200, a fine grained bird classification task where different species can look nearly identical, DFPT-KD and DFPT-KDt outperform KD by 3.55 to 10.41 points and 4.41 to 11.48 points respectively, the largest margins reported anywhere in the paper. The authors argue fine grained tasks are exactly where a compatible, easy to hard knowledge signal matters most, because the discriminative signal needed to separate near identical classes is subtle and easy for a small student to miss if it is handed all at once.
Against dedicated capacity gap methods
| Pair | TA Acc | RCO | TAKD | DGKD | AAKD | DFPT-KD | DFPT-KDt |
|---|---|---|---|---|---|---|---|
| ResNet32x4 to ResNet8x4 | 76.17 | 74.63 | 74.91 | 75.01 | 75.01 | 77.48 | 78.63 |
| WRN-40-2 to WRN-40-1 | 74.92 | 74.15 | 73.99 | 74.33 | 74.21 | 75.47 | 76.38 |
| ResNet32x4 to ShuffleNetV1 | 76.17 | 75.31 | 74.93 | 76.13 | 75.20 | 77.72 | 79.05 |
Even against methods purpose built for this exact problem, DFPT-KD and DFPT-KDt come out ahead in every reported pair, and Table VII shows the prompt and fusion blocks cost a fraction of the parameters that a full teacher assistant network requires. That efficiency argument matters as much as the accuracy numbers for anyone actually deploying this in a compute constrained pipeline.
The ablations that explain why it works
A few of the paper’s smaller experiments do more to build confidence in the method than the headline tables do. Letting the student learn exclusively from the prompt path beats letting it learn exclusively from the original path, and learning from both together beats either alone, which lines up with the authors’ claim that accurate and compatible knowledge are both necessary and neither is sufficient on its own. Inserting prompt blocks at every stage boundary beats stuffing them all into one single position, because a single injection point saturates quickly and stops adjusting anything useful after that. Multi scale partial convolution beats an ordinary single scale convolution of any one kernel size, and increasing the capacity of the prompt blocks past a modest point brings no further benefit, which is a nice practical finding since it means the method does not need to be scaled up to work. The fusion block matters too. Removing it and simply adding the prompt to the raw feature, rather than blending them with a learned convolution, causes the prompt path’s accuracy curve to saturate much earlier in training.
Honest limitations
The paper is thorough on the empirical side, but a few caveats are worth naming plainly. All of the reported numbers come from the paper’s own experimental runs, averaged over three to five trials depending on the dataset, and there is no independent replication cited yet since this is a fairly recent preprint. The method introduces two new hyperparameters, the down sampling rate r1 and the partial convolution ratio r2, and while the ablation in Table VIII shows the results are fairly stable across a range of settings, tuning them for a new architecture pair is still an extra step compared to plain KD, which has none. The approach also assumes the teacher and student networks can be cleanly divided into a shared number of stages, which holds for the CNN families tested here but is not guaranteed to transfer cleanly to architectures with very different stage structures, such as some transformer backbones, without further adaptation. Finally, training cost is higher than vanilla KD because the prompt path adds its own forward and backward pass on top of the teacher and student, even though the added parameter count is small.
Takeaway for practitioners
If you are already running standard KD and hitting a wall with a large teacher small student pair, this is a method you can bolt onto an existing pretrained teacher without retraining it from scratch, since the backbone stays frozen in the base DFPT-KD variant. The fine tuned DFPT-KDt variant asks a little more of your compute budget in exchange for the strongest results.
Takeaway on the theory
The VC dimension argument in Section III is a genuinely useful contribution beyond the benchmark numbers, because it gives a principled reason to expect prompt based paths to outperform the original path for distillation purposes, rather than treating the empirical gains as a lucky architecture choice.
Where this could go next
The immediate achievement here is narrow and specific, closing the accuracy gap between a pretrained teacher and a much smaller student without sacrificing the teacher’s own performance along the way. The conceptual shift underneath it is broader than that single result. Treating a frozen pretrained model as a source of multiple, task adapted forward paths rather than a single fixed function is an idea that shows up across prompt tuning research in language and vision, and this paper is one of the first attempts to bring that idea specifically into distillation rather than transfer learning or fine tuning. It is easy to imagine the same trick applied outside image classification, in object detection or semantic segmentation, where feature level distillation already matters a great deal and where a compatible, dynamically adjusted knowledge signal could plausibly help even more than it does here.
There are open questions the authors leave for future work rather than answering themselves. Whether the prompt path idea composes cleanly with feature level distillation methods like ReviewKD or CAT-KD, which operate on intermediate representations rather than final logits, is untested. Whether it holds up on transformer based teachers and students, where the notion of a clean stage boundary is less obvious, is also untested. And whether the gains persist when the teacher itself is enormous, at the scale of the vision foundation models now common in production systems, rather than the mid sized CNNs used in these experiments, is an open question the paper does not attempt to answer.
None of that undercuts what is here. The result that a distilled student can outperform its own pretrained teacher, on a real benchmark with a full accounting of the numbers, is a meaningful data point in a field that has spent a decade assuming the teacher sets a hard ceiling on how good the student can get. This paper is evidence that ceiling was never as fixed as it looked, it was a side effect of always handing the student a single, overconfident forward path and nothing else.
For anyone building compressed models for edge devices, the practical upside is straightforward even if the theory is not the main draw. You get to keep your best available teacher, you do not need to hunt for or train an intermediate assistant network, and the extra parameter cost during training is small enough that it barely shows up in a training budget line item. Whether it becomes a standard tool or a stepping stone toward something more general will depend on how well it holds up outside the CNN and CIFAR style benchmarks this first paper covers.
Limitations the authors report directly
Beyond the general caveats above, the paper is candid that the prompt path optimization back propagates gradients through the entire frozen teacher backbone even in the base DFPT-KD variant, which the authors argue helps convergence but which also means the memory footprint during training is closer to that of the full teacher than a lightweight adapter approach might suggest. They also note, in the ablation on prompt block capacity, that simply adding more prompt blocks per stage does not help, which is reassuring for anyone worried about needing to scale the method up, but it also means there is a ceiling on how much the prompt path alone can compensate for a truly enormous capacity gap between teacher and student.
Read the full paper for the complete derivation, all eleven teacher student pairs, and the additional ablations on kernel size and inserting position.
A minimal PyTorch implementation
Below is a compact, runnable implementation of the core ideas, a prompt block, a fusion block, a dual forward path teacher wrapper, and the DFPT-KD training step. It is written for clarity rather than matching the paper’s exact backbone code, and it includes a smoke test on random dummy data so you can confirm it runs before wiring it into a real training pipeline.
Conclusion
The core achievement of this paper is a clean fix for a problem the field has been circling for years, that a strong pretrained teacher can quietly work against the student it is supposed to help. Instead of shrinking the teacher or bolting on a chain of intermediate assistants, DFPT-KD keeps the teacher exactly as strong as it always was and gives it a second, more approachable voice built out of small prompt and fusion blocks. The student then gets both voices at once, the confident original and the compatible companion, and the results across CIFAR-100, ImageNet, and CUB-200 back up the claim with real margins rather than marginal noise.
The conceptual shift worth remembering is broader than the specific architecture choices. A frozen pretrained network does not have to be a single fixed function handed down to whoever wants to learn from it. It can be treated as a source of multiple forward paths, each shaped for a different downstream learner, without ever touching the original weights unless you choose to. That is the same intuition driving prompt tuning research across language and vision, applied here to a problem, distillation, where it had not been tried before in quite this form.
Whether the idea generalizes past convolutional networks and past image classification is still open. Transformer backbones, object detection heads, and segmentation decoders all have different notions of what a stage boundary even means, and none of that has been tested yet in this framework. The authors are candid about that gap and frame it as future work rather than pretending the current results already cover it.
Set against that open question, the more concrete limitations, extra hyperparameters, added training cost, and the requirement for a clean stage structure, all look manageable rather than disqualifying. None of them require a fundamentally different approach to fix, they mostly require more engineering effort applied to the same core idea.
The single most memorable result, a compressed ShuffleNetV1 student edging past its own WRN-40-2 teacher, is a small thing to hang a big claim on, but it is exactly the kind of result that tends to reshape how a subfield thinks about its own assumptions. Distillation research has spent a decade treating the teacher’s accuracy as a hard ceiling on the student. This paper is a reasonably convincing argument that the ceiling was an artifact of how the knowledge was being handed over, not a law of the process itself.
Frequently asked questions
What is the capacity gap problem in knowledge distillation
It refers to the finding that a very strong, fully trained teacher network often fails to transfer its knowledge effectively to a much smaller student network, sometimes producing worse results than a less accurate teacher would. The paper traces this to the teacher’s overconfident, sharply peaked output distribution, which a small student cannot match given its limited representational capacity.
How is DFPT-KD different from using a teacher assistant network
A teacher assistant is a separate, medium sized network trained from scratch to sit between the teacher and student. DFPT-KD instead adds lightweight prompt blocks and fusion blocks directly inside the existing pretrained teacher, keeping the teacher’s original weights frozen and intact rather than training a whole new intermediate model.
What is the difference between DFPT-KD and DFPT-KDt
DFPT-KD only trains the new prompt blocks, fusion blocks, and a fresh classification head, leaving the pretrained teacher backbone frozen. DFPT-KDt also lightly fine tunes the teacher backbone itself with a small learning rate as part of the prompt based path, which the paper shows produces stronger results across every tested pair.
Can a student trained with this method actually beat its own teacher
In some of the paper’s reported pairs, yes. The clearest example is a WRN-40-2 teacher at 75.61 percent top one accuracy on CIFAR-100 being outperformed by a ShuffleNetV1 student trained with DFPT-KDt, which reaches 78.29 percent, a gain of 2.68 points over the teacher itself.
Does this method require retraining the teacher from scratch
No. The base DFPT-KD variant keeps the pretrained teacher backbone completely frozen and only trains the small added prompt and fusion blocks, which the paper reports cost as little as 0.03 million extra parameters for a WRN-40-2 teacher. DFPT-KDt does fine tune the backbone but starts from the existing pretrained weights rather than training from zero.
Has this method been tested outside image classification
Not in this paper. The experiments cover CIFAR-100, ImageNet, and CUB-200, all image classification benchmarks, using CNN backbones including VGG, ResNet, Wide ResNet, ShuffleNetV1, ShuffleNetV2, and MobileNetV2. The authors mention extending the approach to other tasks as future work rather than reporting results for it here.
Li, T., Liu, L., Hu, Y., Chen, H., and Chen, S. Dual Forward Path Teacher Knowledge Distillation, Bridging The Capacity Gap Between Teacher and Student. arXiv, identifier 2506.18244. This analysis is based on the published paper and an independent evaluation of its claims.
Pingback: 97% Smaller, 93% as Accurate: Revolutionizing Retinal Disease Detection on Edge Devices - aitrendblend.com