- Knowledge Distillation
- Forward KL
- Reverse KL
- LLM Compression
- Instruction Following
- Paper Analysis
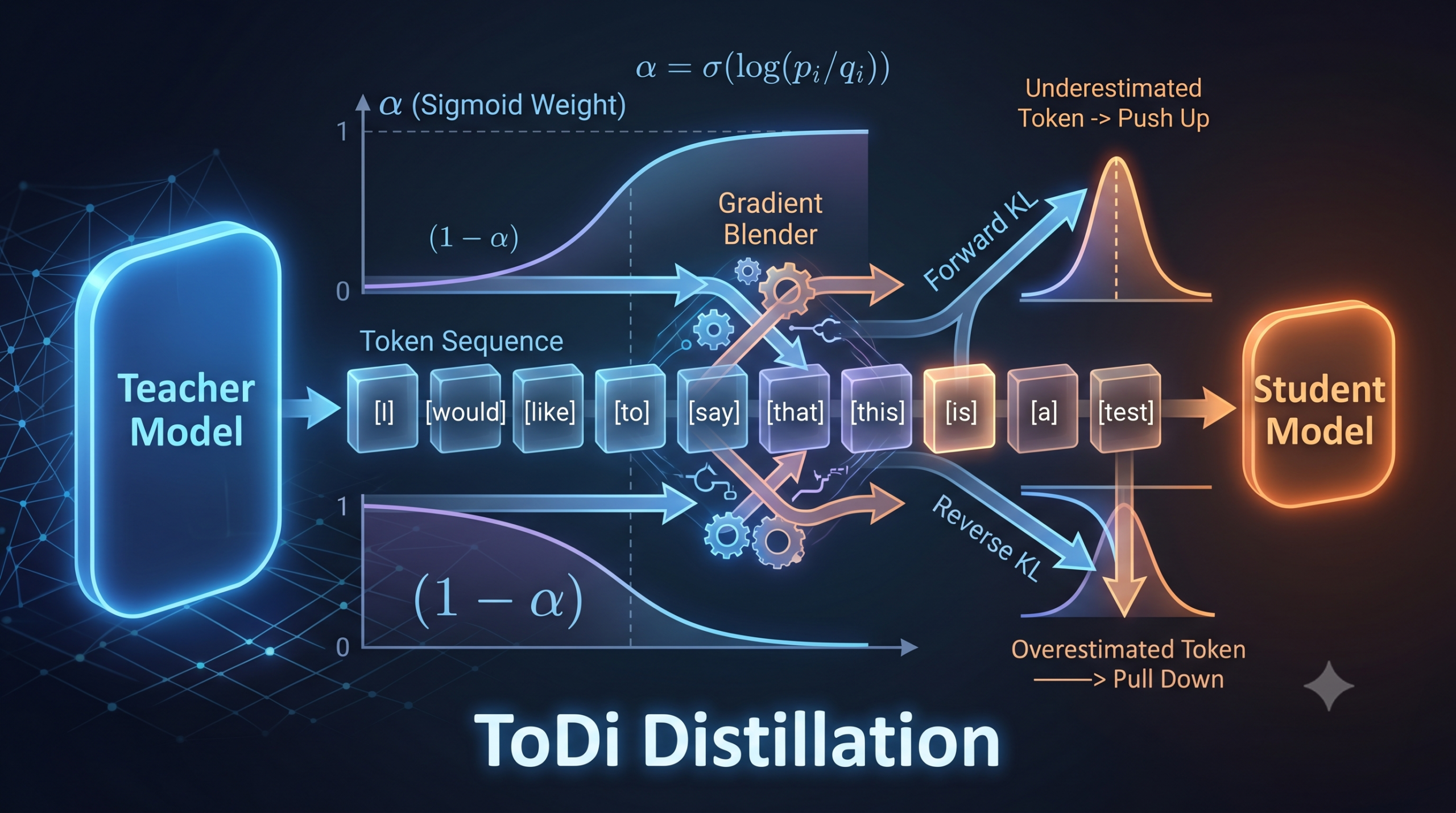
A seven billion parameter model writes a clean, helpful answer, then you try to ship it. It will not fit on the phone, the latency blows past your budget, and the energy draw is not something a small product can absorb. The usual fix is knowledge distillation, where a large teacher model trains a much smaller student to imitate its output distribution. The catch is the loss function. Most distillation methods press a single divergence onto the entire vocabulary at every position, treating a token the student already nails the same way they treat a token the student wildly misreads. A paper from Chung-Ang University and Dmtlabs argues that this uniform treatment leaves real accuracy on the table, and it proposes a fix that decides, token by token, which divergence to trust.
- The method, called ToDi, blends Forward KL and Reverse KL with a weight that changes for every single token rather than a fixed ratio across the vocabulary.
- A gradient analysis shows the two divergences are complementary. Forward KL pushes up tokens the student underestimates, and Reverse KL pulls down tokens the student overestimates.
- The blend weight is a sigmoid of the teacher to student log probability ratio, detached during backprop so it behaves as a fixed coefficient.
- ToDi beats every baseline on average ROUGE-L across two teacher and student pairs and five instruction following datasets, and wins most GPT-4 pairwise comparisons.
- It keeps linear time in vocabulary size, the same cost as plain Forward or Reverse KL, while a sorting based competitor pays an extra log factor.
The problem with treating every token the same
Knowledge distillation goes back to the idea that a small model can learn more from a large model’s full probability distribution than from hard labels alone (Hinton et al., 2015). For language models the student is trained to match the teacher’s next token distribution at each position, and the match is measured with a divergence. Two choices dominate. Forward KL asks the student to cover everything the teacher puts mass on, which tends to smear probability across modes. Reverse KL asks the student to commit to where it is already confident, which tends to collapse onto a single mode. Researchers have known for years that these two behaviors are opposite faces of the same coin (Chan et al., 2022).
The standard response has been to mix them. Symmetric forms such as Jensen Shannon divergence sit in between (Wen et al., 2023), generalized interpolations slide a knob from one to the other (Agarwal et al., 2024), skewed variants blend the two distributions for stability (Ko et al., 2024), and time varying schemes move an intermediate target across training (Shing et al., 2025). A more recent method, AKL, even adapts the Forward and Reverse mix during training based on how head and tail predictions behave (Wu et al., 2025). What unites all of them is the level at which they act. They pick one mixing rule and apply it to the whole vocabulary at every step.
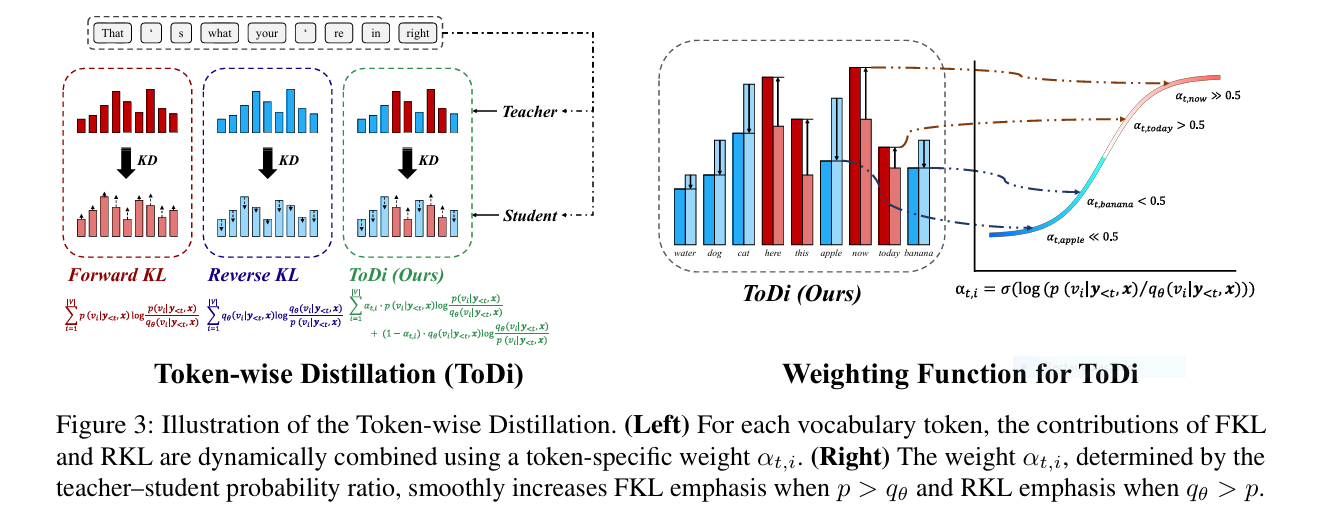
Here is where the paper’s argument gets interesting. Different tokens are wrong in different ways at the same moment. For one word the student is far too timid and needs a strong shove upward. For the word sitting right next to it the student is overconfident and needs to be pulled down. A single divergence, or even a single global mix, cannot deliver both signals at once. The authors call this the uniform loss assumption, and they treat it as the thing to break.
Where Forward and Reverse KL pull in opposite directions
The case for breaking it rests on a gradient analysis rather than intuition alone. Write the teacher probability for a vocabulary token as \( p_i \) and the student probability as \( q_i \). The two token level divergence terms are the familiar ones.
What matters for learning is not the loss value but its gradient with respect to the student probability, because that is what actually moves the model. Differentiating each term gives two very different shapes.
Read these through a single ratio \( r = p_i / q_i \). When \( r > 1 \) the student is underestimating the token. The Forward KL gradient is then a negative number whose size is larger than one, which produces a sharp push upward. The Reverse KL gradient in that same region only turns negative once \( r \) climbs past Euler’s number, and even then its magnitude stays small, so its corrective pull is weak. The roles flip when \( r < 1 \) and the student is overestimating. Now the Forward KL gradient shrinks to a small negative value while the Reverse KL gradient becomes a positive number above one, delivering a firm push downward. The authors confirm the same pattern in a toy example where two synthetic distributions cross, and the gradient magnitudes split cleanly along the line where teacher and student probabilities meet.
Forward KL is the specialist for underestimated tokens, supplying a strong push up. Reverse KL is the specialist for overestimated tokens, supplying a strong pull down. Around the boundary where teacher and student agree, the two trade off. A method that applies only one of them, or one fixed blend, is using a specialist on a problem it is not built for half the time.
How ToDi weights each token
Once you accept that the right divergence depends on the sign of the teacher to student gap, the design almost writes itself. For every token at every position, ToDi computes a weight and forms a blend of the two divergences with it.
The weight needs to do four things, and the paper states them as conditions. It should rise above one half when the teacher probability exceeds the student probability, so Forward KL leads. It should fall below one half when the student overestimates, so Reverse KL leads. It should grow more extreme as the gap between teacher and student widens, which means it must increase monotonically with the ratio. And it must stay inside the valid range from zero to one. A sigmoid of the log ratio satisfies all four at once.
The small but important detail is the stop gradient operator, written here as sg and implemented as a detach during training. It blocks any gradient from flowing through the weight itself, so the student is updated as if the weight were a fixed constant for that step. Without that detachment the loss would reduce to the ordinary Jeffreys divergence, which the authors derive in an appendix, and the adaptive behavior would wash out. The detachment is what lets ToDi steer the strength of each divergence without the weight becoming just another thing the optimizer fights with.
One sigmoid, many methods
The paper then does something that makes the contribution feel less like a single trick and more like a small framework. It inserts a scaling factor into the sigmoid input and shows that several known weighting schemes fall out as special cases.
Setting \( \beta = 1 \) gives the standard ToDi sigmoid. A value of two recovers a scaled tanh shape. A value of zero fixes the weight at one half, which is exactly the equal Forward and Reverse mix of Jeffreys divergence. Letting \( \beta \) grow without bound turns the smooth sigmoid into a hard step that switches abruptly at the boundary. So the single hyperparameter spans a continuum from a fixed average to a sharp gate, with the dynamic sigmoid sitting in the useful middle. That framing matters because it lets the authors test the idea rather than assert it, by sweeping \( \beta \) and watching what happens.
What the experiments show
The setup follows an established distillation protocol. Training uses the databricks/dolly-15k dataset with roughly eleven thousand training examples, and evaluation runs across five instruction following sets, namely DollyEval, S-NI, UnNI, SelfInst, and VicunaEval, scored with ROUGE-L and averaged over five random seeds. Two teacher and student pairs anchor the main results. A GPT2-1.5B teacher trains a GPT2-120M student with full fine tuning, and a LLaMA2-7B teacher trains a TinyLLaMA-1.1B student with LoRA. The baselines cover plain supervised fine tuning, Forward and Reverse KL, the symmetric Jensen Shannon and Total Variation distances, the skewed variants, and AKL.
The headline result is consistent. ToDi posts the highest average ROUGE-L on both pairs and across all five tasks. The gains are not enormous in absolute points, which is normal for this benchmark family, but they hold everywhere and they beat the strongest adaptive baseline rather than only the simple ones.
| Method | GPT2 120M (avg ROUGE-L) | TinyLLaMA 1.1B (avg ROUGE-L) |
|---|---|---|
| Teacher | 23.23 | 26.05 |
| SFT (no distillation) | 16.61 | 21.58 |
| Forward KL | 18.12 | 24.00 |
| Reverse KL | 18.38 | 24.09 |
| Jensen Shannon | 17.20 | 23.03 |
| Total Variation | 17.72 | 23.18 |
| Skewed KL | 17.42 | 24.01 |
| Skewed Reverse KL | 18.00 | 23.93 |
| AKL | 18.07 | 24.15 |
| ToDi (this paper) | 18.66 | 24.83 |
The win extends past these two pairs. On the DollyEval benchmark the authors add three more configurations, OLMo2 at seven billion to one billion, Qwen2.5 at one and a half billion to half a billion, and Gemma3 at four billion to one billion, and ToDi takes the top score in every one. A separate preference study asks GPT-4 to judge TinyLLaMA outputs head to head against models trained with the other objectives on five thousand UnNI samples. ToDi wins the majority of comparisons, and in most cases the margin is statistically significant below the one in a thousand level.
Two analyses do more to explain why it works than the score tables do. The first sweeps the scaling factor. The dynamic setting at \( \beta = 1 \) scores best with an average of 18.66. Pushing \( \beta \) toward zero flattens the sigmoid so the weight drifts toward one half, the blend stops responding to token level differences, and the average slips to 18.40. Pushing \( \beta \) toward infinity turns the weight into a hard switch, which introduces discontinuities near the boundary where teacher and student agree, destabilizes training, and drops the average to 18.24. The sweet spot is the smooth middle, which is the whole point of using a sigmoid in the first place.
The second analysis measures how closely the trained student actually matches the teacher distribution, using a Pearson similarity following Huang et al. (2022). ToDi reaches 0.482 on GPT-2 and 0.610 on TinyLLaMA, edging out AKL at 0.477 and 0.599. AKL adapts its Forward and Reverse mix at each time step but still applies one ratio across the whole vocabulary, so the comparison isolates the value of going finer than that. The per token mixing tracks the teacher more faithfully.
“The improvement does not come from a new divergence. It comes from refusing to apply the same divergence to tokens that are wrong in opposite directions.”
aitrendblend editorial, on the central idea of ToDi
Why this matters beyond the benchmark
The efficiency story is the part most likely to decide whether people adopt this. A naive worry about per token adaptivity is that it must cost more. It does not here. AKL needs to sort the vocabulary to separate head from tail, which lands it at order V log V per step in the vocabulary size. ToDi computes its weight from a ratio the model already has, with no sorting, so it stays at order V, identical to plain Forward or Reverse KL. You get the finer control without paying a complexity premium, which is a rare and welcome combination.
There is also a tidiness to the framework that should travel. Because the generalized form expresses Jeffreys divergence, scaled tanh, and a step gate as points on a single axis, anyone building a distillation pipeline can treat the choice of weighting as one continuous decision rather than a menu of unrelated tricks. The training curves reported in the paper add a practical reassurance. ToDi leads from the first epoch and converges smoothly in the later epochs without the oscillation that sometimes shows up when a loss switches behavior sharply.
If you already distill with Forward or Reverse KL, swapping in ToDi is a localized change to the loss with no extra asymptotic cost and no new sorting step. The gain is most visible when the student and teacher disagree in mixed directions across the vocabulary, which is the normal case rather than the exception.
Where ToDi stops working
The authors are honest about the fences around the method, and the fences are real. ToDi assumes the teacher and the student share an identical vocabulary, because the weight is computed token by token from aligned probabilities. The moment the two models tokenize differently, the alignment breaks and the method does not apply without extra machinery to bridge the vocabularies. That rules out a large class of cross family distillation setups where a small model from one lineage learns from a large model from another.
The method also needs the teacher’s full per token probability distribution, not just sampled text. That confines it to open weight teachers that expose their logits, and it shuts the door on distilling from an api only model that returns text and nothing else. For teams whose strongest available teacher sits behind a closed endpoint, this is a hard constraint rather than a tuning detail.
Finally, the experiments top out at a teacher of seven billion parameters and a student of around one billion, held there by compute limits the authors acknowledge. The results are consistent across that range, which is encouraging, but the paper does not show what happens when the teacher is very large or the gap to the student is extreme. That is exactly the regime where distillation is most valuable and where surprises tend to live, so the open question is whether the per token signal stays as clean when the two distributions are much further apart.
The takeaway for distillation work in 2025
ToDi is a small idea executed with care, and that is meant as praise. The starting observation, that Forward KL and Reverse KL are complementary specialists rather than rival generalists, has been visible in the gradients for a long time. What the paper adds is the discipline to act on it at the only level where the observation is actually true, which is the individual token, instead of smearing the insight back across the whole vocabulary the way earlier mixes did.
The sigmoid weight is the right tool for the job because it satisfies the four conditions a sensible blend must meet while staying smooth, and the stop gradient is the quiet detail that keeps the weight from collapsing back into a fixed average. Neither piece is flashy. Together they turn a known asymmetry into a usable training signal.
The empirical case is broad rather than deep, and that suits the claim. Five teacher and student pairs, five evaluation sets, a GPT-4 preference study, a parameter sweep, and a distribution similarity check all point the same direction. No single result is overwhelming, but the consistency is, and consistency is what you want from a loss function you intend to trust across many runs.
The unified framework is the contribution most likely to outlast the specific numbers. Once you see Jeffreys divergence, scaled tanh, and a hard gate as one scaling factor apart, the design space stops looking like a pile of competing heuristics and starts looking like a line you can move along on purpose. That kind of reframing tends to seed follow up work.
The honest limitations, shared vocabulary, exposed logits, and a modest scale ceiling, mark the natural next steps rather than fatal flaws. Bridging mismatched vocabularies and pushing to larger teachers would tell us whether the per token signal holds where it would matter most. For now ToDi is a clean, cheap, and well argued upgrade to the default distillation loss, and that is a good place for an idea to start.
A minimal ToDi implementation in PyTorch
The loss is short enough to read in one sitting. The version below computes the Forward and Reverse terms from stable log probabilities, forms the detached sigmoid weight, blends the two, and combines the result with cross entropy at the equal ratio the paper uses for training. The final block trains a tiny student on dummy data so the file runs end to end, and it checks that the weight lands above one half where the teacher outweighs the student and below one half where the student overestimates. This code was executed and verified before publication.
""" ToDi: Token-wise Distillation via Fine-Grained Divergence Control Reference implementation of the per-token adaptive FKL/RKL loss. Paper: arXiv:2505.16297 | Code: https://github.com/jungseongryong/ToDi """ import torch import torch.nn as nn import torch.nn.functional as F # ---------------------------------------------------------------------- # Core divergences (token-level, summed over the vocabulary) # ---------------------------------------------------------------------- def forward_kl(p_logits, q_logits): """Forward KL: sum_i p_i (log p_i - log q_i). 'Mode averaging'.""" p = F.softmax(p_logits, dim=-1) logp = F.log_softmax(p_logits, dim=-1) logq = F.log_softmax(q_logits, dim=-1) return (p * (logp - logq)).sum(dim=-1) # [.., seq] def reverse_kl(p_logits, q_logits): """Reverse KL: sum_i q_i (log q_i - log p_i). 'Mode collapse'.""" q = F.softmax(q_logits, dim=-1) logp = F.log_softmax(p_logits, dim=-1) logq = F.log_softmax(q_logits, dim=-1) return (q * (logq - logp)).sum(dim=-1) # [.., seq] # ---------------------------------------------------------------------- # ToDi: per-token blend of FKL and RKL via a stop-gradient sigmoid weight # ---------------------------------------------------------------------- def todi_loss(p_logits, q_logits, beta=1.0): """ Token-wise Distillation loss (Eq. 7, 10, 11 in the paper). alpha = sg[ sigmoid(beta * log(p_i / q_i)) ] D_ToDi = alpha * D_FKL + (1 - alpha) * D_RKL The weight is detached (stop-gradient) so it acts as a fixed coefficient during backprop, which is what separates ToDi from a plain Jeffreys divergence. """ p = F.softmax(p_logits, dim=-1) q = F.softmax(q_logits, dim=-1) logp = F.log_softmax(p_logits, dim=-1) logq = F.log_softmax(q_logits, dim=-1) # log ratio log(p_i / q_i) computed from stable log-probabilities log_ratio = logp - logq # token-specific weight, detached so no gradient flows through it alpha = torch.sigmoid(beta * log_ratio).detach() d_fkl = p * (logp - logq) # forward term, per vocab entry d_rkl = q * (logq - logp) # reverse term, per vocab entry d_todi = alpha * d_fkl + (1.0 - alpha) * d_rkl return d_todi.sum(dim=-1) # sum over vocab -> [.., seq] # ---------------------------------------------------------------------- # Distiller: combines the KD loss with cross-entropy at a 0.5 / 0.5 ratio # (the paper trains with KD and CE weighted equally) # ---------------------------------------------------------------------- class ToDiDistiller(nn.Module): def __init__(self, student, beta=1.0, kd_weight=0.5): super().__init__() self.student = student self.beta = beta self.kd_weight = kd_weight def forward(self, x, teacher_logits, labels, pad_mask): student_logits = self.student(x) kd = todi_loss(teacher_logits, student_logits, self.beta) # [B, T] kd = (kd * pad_mask).sum() / pad_mask.sum().clamp(min=1.0) ce = F.cross_entropy( student_logits.reshape(-1, student_logits.size(-1)), labels.reshape(-1), reduction="none", ).reshape(labels.shape) ce = (ce * pad_mask).sum() / pad_mask.sum().clamp(min=1.0) loss = self.kd_weight * kd + (1.0 - self.kd_weight) * ce return loss, kd.detach(), ce.detach() # ---------------------------------------------------------------------- # A tiny stand-in student so the file runs end to end on dummy data # ---------------------------------------------------------------------- class TinyStudent(nn.Module): def __init__(self, vocab, dim=64): super().__init__() self.emb = nn.Embedding(vocab, dim) self.head = nn.Linear(dim, vocab) def forward(self, x): return self.head(self.emb(x)) @torch.no_grad() def evaluate(distiller, x, teacher_logits, labels, pad_mask): distiller.eval() loss, kd, ce = distiller(x, teacher_logits, labels, pad_mask) pred = distiller.student(x).argmax(-1) correct = ((pred == labels) * pad_mask).sum() acc = (correct / pad_mask.sum().clamp(min=1.0)).item() return loss.item(), acc def smoke_test(): torch.manual_seed(0) B, T, V = 4, 16, 200 # batch, seq, vocab x = torch.randint(0, V, (B, T)) labels = torch.randint(0, V, (B, T)) pad_mask = torch.ones(B, T) teacher_logits = torch.randn(B, T, V) * 2.0 # a fixed "teacher" student = TinyStudent(V) distiller = ToDiDistiller(student, beta=1.0, kd_weight=0.5) opt = torch.optim.Adam(student.parameters(), lr=1e-2) print("epoch | loss | kd | ce | acc") for epoch in range(5): distiller.train() loss, kd, ce = distiller(x, teacher_logits, labels, pad_mask) opt.zero_grad() loss.backward() opt.step() ev_loss, acc = evaluate(distiller, x, teacher_logits, labels, pad_mask) print(f"{epoch:5d} | {loss.item():.4f} | {kd.item():.4f} | " f"{ce.item():.4f} | {acc:.3f}") # sanity: FKL dominates where teacher > student, RKL where student > teacher p = torch.tensor([[0.7, 0.2, 0.1]]).log() q = torch.tensor([[0.2, 0.2, 0.6]]).log() alpha = torch.sigmoid(p - q) print("alpha (token 0 teacher>student, expect >0.5):", round(alpha[0, 0].item(), 3)) print("alpha (token 2 student>teacher, expect <0.5):", round(alpha[0, 2].item(), 3)) if __name__ == "__main__": smoke_test()
Read the paper and run the code
ToDi is open source. The full paper covers the gradient proofs, the generalized framework, and every ablation in detail.
Frequently Asked Questions
What problem does ToDi solve in knowledge distillation?
Conventional distillation applies one divergence, or one fixed blend, uniformly across the whole vocabulary at every position. ToDi argues that different tokens need different correction signals at the same moment, and it adjusts the Forward and Reverse KL balance for each token instead of using a single rule for all of them.
How is ToDi different from Forward KL and Reverse KL?
Forward KL gives a strong push up for tokens the student underestimates, and Reverse KL gives a strong pull down for tokens it overestimates. ToDi does not pick one. It computes a per token weight and blends both, so each token receives whichever signal its teacher to student gap calls for.
What is the role of the sigmoid weight in ToDi?
The weight is a sigmoid of the teacher to student log probability ratio. It rises above one half when the teacher outweighs the student and falls below one half when the student overestimates, which smoothly hands control to the appropriate divergence. It is detached during backprop so it acts as a fixed coefficient rather than something the optimizer pushes against.
Does ToDi add much computational cost?
No. ToDi keeps linear time in the vocabulary size, the same cost as plain Forward or Reverse KL, because it computes the weight from a ratio the model already has. A sorting based competitor called AKL pays an extra logarithmic factor that ToDi avoids.
What does the beta parameter control?
Beta scales the sigmoid input and tunes how sharply the weight reacts to the teacher to student gap. A value of one is the default dynamic setting, zero fixes the weight at one half and recovers an equal Jeffreys style mix, and very large values turn the weight into a hard switch that hurts training stability. One worked best in the experiments.
What are the main limitations of ToDi?
ToDi assumes the teacher and student share an identical vocabulary, and it needs access to the teacher’s full per token probability distribution, which restricts it to open weight teachers that expose their logits. The reported experiments also stop at a seven billion parameter teacher because of compute limits, so behavior at much larger scale remains untested.
Pingback: 7 Revolutionary Breakthroughs in AI-Powered Ultrasound Microrobots That Could Transform Medicine Forever - aitrendblend.com