Key points
- RigFace pairs 3D Morphable Model controls with Stable Diffusion to edit facial expression, head pose, and lighting in portrait images while keeping the subject’s identity intact.
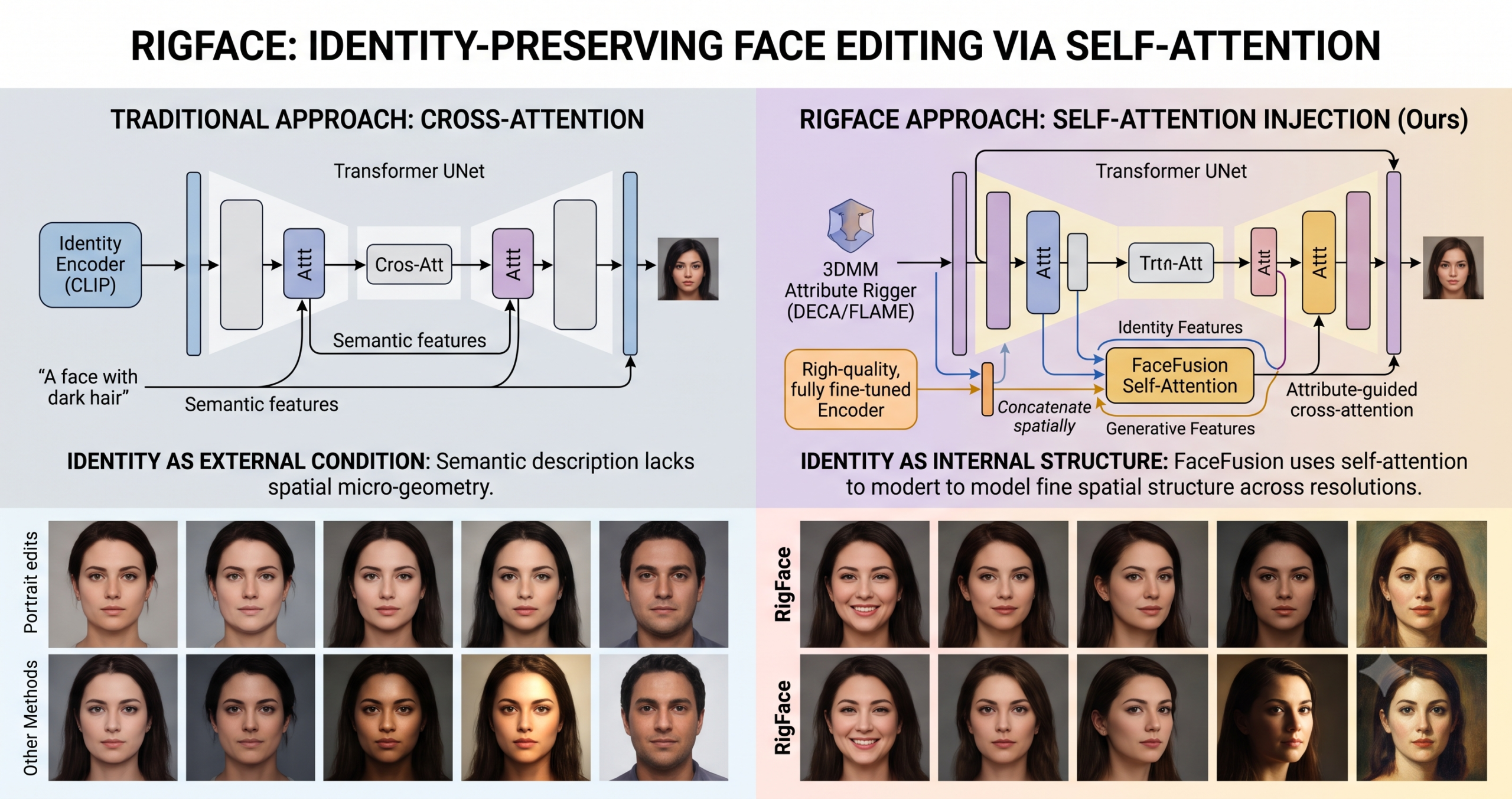
- The FaceFusion module injects identity features into the self attention of every transformer block in the denoising UNet, rather than the cross attention used by most adapter-based methods.
- A Spatial Attribute Provider supplies three separate signals for three jobs: expression coefficients for expression changes, Lambertian rendered images for pose and lighting changes, and a composited background for spatial consistency.
- On real face benchmarks the model leads on SSIM (0.850), LPIPS (0.063), and identity L2 distance (0.356) against ten published baselines, though its FID of 60.27 is beaten by AniPortrait at 49.55, with that gap due in part to AniPortrait’s evaluation on a narrower set of conditions.
- The model generalizes to out-of-domain portrait styles including oil paintings, cyberpunk art, cartoon characters, and comics without any domain-specific fine-tuning, which is the most practically interesting finding in the paper.
- Inference takes approximately 5 seconds per image, which is slower than most of the ten baselines. That trade-off reflects the dual-encoder architecture and is the clearest cost of the approach.
The problem with routing identity through cross attention
To understand why self attention matters here, it helps to think about what the two mechanisms do inside a transformer block inside a diffusion UNet. Cross attention was designed to let the generated image tokens attend to an external conditioning signal. In the original Stable Diffusion model, that signal is a text embedding from CLIP, and cross attention is how the model follows a text prompt. It is a mechanism for responding to external instructions.
Self attention, by contrast, lets every spatial position in the feature map attend to every other spatial position in the same map. It builds internal spatial relationships. When the model generates a face, self attention captures how the nose relates to the eyes, how the jaw sits under the cheekbones, how the forehead connects to the hairline. These are the structural relationships that make a face recognizable as that particular person across different expressions and lighting conditions.
Most methods that adapt Stable Diffusion for face editing inject identity through cross attention, treating the source face like an additional text prompt. IP-Adapter, FaceAdapter, and AniPortrait all take variations of this approach. The identity encoder extracts features from a source face, and those features condition the generation through cross attention. The problem is that cross attention was built to inject external signals that modulate the content being generated, not to wire a specific spatial structure into how the image reasons about itself. High-level CLIP embeddings are good at telling the model to generate a face with dark hair and strong cheekbones, but poor at preserving the subtle micro-geometry that makes one specific dark-haired face distinct from another.
This argument connects to an observation the paper makes about earlier methods. Adapter-based approaches and ControlNet primarily modify cross attention, and the paper argues this constrains how well the model can adapt to tasks that diverge substantially from text-to-image generation. Face editing is one of those tasks. The goal is no longer to generate a face matching a description but to reconstruct a specific face in a new configuration, and that is a structural task more than a semantic one.
What 3D Morphable Models provide, and what they cannot
The attribute control side of RigFace rests on 3D Morphable Models. The paper works with two of the most widely used ones. FLAME, which uses a linear blend skinning approach with roughly 5,000 vertices, handles pose and overall head shape through interpretable parameter changes. BFM, which uses roughly 35,000 vertices, captures finer facial deformations and provides a denser representation of expression.
The appeal of 3DMMs is that their parameter spaces are genuinely disentangled in a way that image encoders almost never are. A change to the expression parameters in BFM changes the face geometry without touching the lighting or pose parameters. A change to the SH lighting coefficients changes illumination without touching the geometry. That clean separation is what makes 3DMMs so attractive as control interfaces.
The catch is that taking parameters out of a 3DMM and rendering a face directly from them produces something that looks nothing like a photograph. The geometry is a simplified mesh, the reflectance model assumes a simple Lambertian surface, and nothing in the model accounts for hair, skin texture, glasses, earrings, or the dozens of other details that make a real portrait look real. This gap, which the paper illustrates directly in Figure 4 by comparing Deep3DRecon rendered faces to photographs, is the reason 3DMM-only approaches have always needed a generative model to finish the job.
RigFace uses DECA, which builds on FLAME and adds Lambertian reflectance and spherical harmonics lighting, to produce rendered images for pose and lighting conditions. It uses Deep3DRecon, which builds on the denser BFM template, to extract expression coefficients. The choice of which system handles which attribute reflects a finding the ablation study later validates, though the design decision came first from thinking about what each representation is actually able to describe.
The Spatial Attribute Provider, different signals for different jobs
The module that produces all control signals is called the Spatial Attribute Provider. It uses three distinct approaches for expression, lighting and pose, and background because those attributes respond to fundamentally different kinds of signal.
Expression through coefficients
Deep3DRecon extracts expression coefficients from the target image. These coefficients describe facial deformations in the BFM parameter space and are passed through a linear layer to match the time embedding dimensionality of the denoising UNet, then added directly to that embedding. Sending expression as a compact numerical vector works because expression is inherently a high-level semantic concept. Knowing that the face is smiling, or that the brow muscles are pulling together into a frown, is the right level of abstraction for expression transfer. The model learns to map those abstract parameter values to appropriate surface deformations during training.
Pose and lighting through rendered images
For pose and lighting, the paper takes a different route. Rather than passing the raw SH coefficients or rotation angles extracted by DECA, it renders those parameters into a Lambertian image of the face and uses that image as the conditioning signal. The rendered image is pixel aligned with the target face, giving the model a spatial, low-level map of where the light is coming from and how the head is oriented in space.
The ablation study in Section 4.3.2 validates this choice directly. When pose and lighting coefficients are used instead of rendered images, even when the coefficients are separated from expression and handled through different linear layers, pose editing fails. The model cannot reliably change head orientation when given only an abstract rotation vector. When the rendering is used, pose editing works. The paper’s hypothesis is that spatial cues are what the model needs for these attributes, an image that shows where the head goes is easier to learn from than a set of angles that describe where it goes.
Background through compositing
The background predictor uses a face parsing model to extract head regions from both source and target images, then composes them into a single image before passing it as a condition. This makes the generation task simpler. Instead of asking the model to invent a new background consistent with the new head position, it shows the model what the background should look like and asks it to inpaint the face into that context. During inference, when editing expression or lighting without changing pose, the source mask alone is used. When pose changes move the head significantly, the union of source and target masks is used to account for the spatial shift.
FaceFusion, injecting identity layer by layer
The Identity Encoder has the same architecture as the denoising UNet and is initialized from the same pretrained Stable Diffusion weights. Both encoders are fully fine-tuned during training. Given a source portrait, a frozen VAE encoder compresses it to a latent representation. The Identity Encoder processes that latent and produces feature maps at every resolution of the UNet hierarchy.
Inside each transformer block, FaceFusion takes the Identity Encoder feature map at that resolution and concatenates it with the denoising UNet feature map along the sequence dimension, effectively doubling the number of positions the self attention layer sees. The self attention then runs over this extended sequence and the output is split. Only the positions corresponding to the denoising features are kept and passed forward to the cross attention layer. The identity positions are discarded after the self attention step has allowed them to influence the structural reasoning about the generated image.
Where \(\mathbf{z}_t\) is the noised latent at timestep \(t\), \(\mathbf{g} = \mathcal{E}(\mathbf{I}_{sor})\) is the VAE-compressed source identity image, \(\mathbf{y} = \mathcal{E}(\mathbf{C})\) is the compressed conditional images, and \({\psi}\) are the expression coefficients. The three networks \(\phi_{id}\), \(\phi_{dn}\), and \(\phi_{col}\) are the Identity Encoder, the Denoising UNet, and the lightweight Attribute Rigger respectively.
The Attribute Rigger deserves a brief note because the paper is specific about how lightweight it is. It is a single convolutional layer with 8 channels, 4 by 4 kernels, and 2 by 2 strides. The VAE encoder compresses the conditional images into latent features, and the Attribute Rigger blends those into the denoising UNet. The heavy lifting is done by the fine-tuned UNet, not by an elaborate adapter.
Data and training setup
The model trains on the Aff-Wild video dataset, which provides in-the-wild videos of people across a wide range of emotional states and head positions. Each video is broken into frame sequences, and from each sequence two temporally distant frames are sampled as a source-target pair, ensuring that the training examples show real variation in expression, pose, and lighting rather than adjacent frames that look nearly identical. The total training set comes to roughly 30,000 image pairs. Faces are cropped to preserve partial backgrounds and resized to 512 by 512 to match the resolution of Stable Diffusion 1.5.
Training runs for 100,000 steps on two AMD MI250x GPUs with a constant learning rate of 1e-5 and a batch size of 4 per GPU, taking approximately 12 hours. Inference is performed on a single GPU and takes about 5 seconds per image.
Evaluation uses 20 identities from held-out Aff-Wild videos and 20 more from CelebV-HQ and AFEW, for 40 identities in total. Each identity receives three types of edit across three test cases per type, producing 360 generated images. Ten baselines across four categories are compared: two 3D rendering methods, two GAN-based methods, two relighting methods, and four diffusion-based methods.
What the numbers say
The quantitative results in Table 1 of the paper show RigFace leading or matching the best competitor across most metrics. The identity L2 distance is 0.356, the lowest in the comparison, meaning the generated faces are closest to the source identity as measured by a face recognition model. SSIM reaches 0.850, better than AniPortrait’s 0.802 which was the previous best. LPIPS drops to 0.063 from AniPortrait’s 0.090.
| Method | ID L2 ↓ | SSIM ↑ | LPIPS ↓ | FID ↓ | APD ↓ | AED ↓ | ALD ↓ |
|---|---|---|---|---|---|---|---|
| Arc2Face | 0.637 | 0.644 | 0.545 | 100.02 | 0.059 | 0.082 | N/A |
| GIF | 0.624 | 0.650 | 0.527 | 86.41 | 0.033 | 0.066 | 0.050 |
| HyperReenact | 0.584 | 0.689 | 0.308 | 72.77 | 0.046 | 0.074 | N/A |
| DiffusionRig | 0.455 | 0.724 | 0.133 | 90.52 | 0.028 | 0.071 | 0.057 |
| FaceAdapter | 0.421 | 0.785 | 0.125 | 88.32 | 0.030 | 0.063 | 0.082 |
| AniPortrait | 0.361 | 0.802 | 0.090 | 49.55 | 0.035 | 0.066 | N/A |
| RigFace (ours) | 0.356 | 0.850 | 0.063 | 60.27 | 0.026 | 0.061 | 0.053 |
One number in that table deserves an honest annotation. The FID for RigFace is 60.27, while AniPortrait achieves 49.55. FID measures distributional similarity between generated images and real images at a dataset level, and AniPortrait’s advantage here reflects in part that it does not support lighting editing, meaning its FID is computed over a narrower set of conditions where it presumably performs well. RigFace supports all three editing types and is compared across all of them. Whether the FID gap reflects a genuine quality difference in the images AniPortrait generates, or is largely an artifact of evaluation scope, the paper does not analyze in depth, and a careful reader should hold both interpretations open.
“Our method achieves superior performance in both identity preservation and photorealism compared to existing face editing models.” Mengting Wei et al., University of Oulu and ELLIS Institute Finland, Pattern Recognition 2026
The user study adds a different kind of evidence. Amazon Mechanical Turk participants were shown pairs of images, one generated by RigFace and one real, and asked which looked more realistic for the given edit type. For expression edits, 59.3% chose the generated image over the real one. For lighting edits, 55.8% chose the generated image. For pose edits, 42.1% chose the generated image, with real images preferred by 57.9% of respondents. The pose result is the honest one. Changing head pose requires the model to inpaint background areas around the new head position, and that inpainting is the most visible challenge in the qualitative results as well.
Generalization to artistic portraits
The most practically interesting result in the paper has nothing to do with the main benchmark. The authors collected 500 images from Pinterest and Unsplash covering oil paintings, cyberpunk art, cartoon illustrations, and comics, none of which resemble the in-the-wild photographs in the Aff-Wild training set, and ran the same editing pipeline on them without any additional fine-tuning.
RigFace transfers expression, lighting, and pose to these out-of-domain portraits more reliably than the ten baselines. Most of the competing methods were trained only on real face photographs, and they tend to either fail to produce plausible output on artistic portraits or collapse toward a photographic style that overwrites the original visual character.
The reason this works as well as it does probably traces back to the identity injection mechanism. CLIP, which many methods use to extract identity features, was trained on an enormous corpus of natural images paired with text, and its representations reflect that training distribution. When given a face from an oil painting, CLIP embeds it somewhere in a high-level semantic space that captures broad attributes but loses the fine spatial detail that makes one painted face distinct from another. The UNet based Identity Encoder initialized from Stable Diffusion weights operates differently. Stable Diffusion itself was trained on a broad distribution that includes artistic images, and the generative features it learns span a wider range of visual styles. The identity features extracted by a network initialized from those weights are more likely to retain style-specific details that survive the editing process.
The paper also tests whether fine-tuning on a small set of stylized images improves results further. It does, with FID dropping from 89.41 to 73.72 in the out-of-domain evaluation, but the improvement is modest enough that the authors conclude the base model already generalizes well without domain-specific training. That kind of genuine zero-shot behavior across artistic styles is not something most face editing papers can claim.
What the ablation studies reveal
The ablation on condition design is one of the cleaner experiments in the paper. Using expression coefficients with rendered images for pose and lighting outperforms using all coefficients, using all rendered images, or using any other combination. More specifically, the no-disentanglement baseline that concatenates all coefficients into a single vector performs worst, with FID rising to 104.11 compared to the full model’s 60.27, and the average pose distance exploding to 0.061 from 0.026. The model simply cannot separate which coefficient is asking for what change when they arrive as a single entangled vector.
The coefficient-separated baseline, which uses separate linear layers for each coefficient type but still relies on abstract numbers for pose and lighting, recovers some performance but still fails at lighting editing specifically, with the average lighting distance rising to 0.125 versus 0.053 for the full model. Rendering the lighting condition into an actual image before passing it to the model is responsible for most of the lighting editing improvement.
The ablation on identity encoder design compares CLIP, a simple convolutional encoder, and the full UNet-based Identity Encoder with FaceFusion. CLIP scores an identity L2 of 0.457, worse than even some GAN baselines. The convolutional encoder brings that down to 0.361 but at the cost of worse pose editing, with the average pose distance rising to 0.044 from 0.026. The full approach combining the UNet-based encoder with the self-attention injection pathway achieves both the best identity preservation and the most accurate attribute control, suggesting the two cannot be fully separated when identity features are handled in a unified way without the progressive self-attention injection keeping identity and attribute editing pathways distinct.
Computational cost, the honest version
RigFace sits at roughly 1.8 billion parameters, which puts it in the same territory as other diffusion-based face editing methods. Arc2Face is smaller at 891.8 million parameters but still comparably fast at 3.08 seconds per image. FaceAdapter is larger at 1.9 billion parameters and runs in about 2.84 seconds. AniPortrait is the heaviest at 2.7 billion parameters but runs in about 1.3 seconds per frame because it generates video and amortizes some costs over multiple frames. RigFace at 5 seconds per image is the slowest in the diffusion category. Peak GPU memory at 8,448 megabytes is comparable to Arc2Face and below AniPortrait’s 9,180 megabytes.
The paper describes the 5-second inference time as acceptable given the quality gains, and that is a judgment call that depends entirely on the deployment context. For studio production work or avatar creation where quality matters and generation is not real time, 5 seconds is a reasonable trade. For any application that needs interactive or near-interactive generation speed, the current approach is not suitable. The dual-encoder architecture, with both the Identity Encoder and the Denoising UNet fully fine-tuned and running at inference time, is the structural reason for the cost. No parameter-efficient shortcut is being taken, and the quality gains come partly from that thoroughness.
Honest limitations
- Large pose changes are the weakest editing condition. When the head turns significantly, the model needs to inpaint large background areas around the new head position, and the quality of that inpainting degrades under extreme rotations. The paper’s own extreme conditions evaluation shows facial deformation in the most challenging pose examples.
- DECA can partially encode skin tone as illumination in its albedo and lighting estimation. When RigFace transfers a target lighting condition, some lighting results show unintended skin color shifts, particularly when the target and source subjects have different skin tones. The paper notes this is a limitation of current 3DMM-based decomposition approaches broadly, not unique to RigFace, and that the open problem of accurately separating facial albedo from illumination in the wild remains unsolved.
- Training and evaluation rely entirely on video frames from Aff-Wild, CelebV-HQ, and AFEW. The model’s behavior on demographics underrepresented in those datasets, or on faces with significant occlusions, accessories, or unusual lighting conditions, is not fully characterized.
- The current architecture is designed for still image generation. Extending to video requires ensuring temporal consistency across frames, which the current method does not address.
- Inference takes approximately 5 seconds per image on a single GPU, which is slower than most baselines and rules out real-time or interactive use cases.
A reference PyTorch implementation
The code below is an independent educational reconstruction of the FaceFusion self-attention injection mechanism and the overall RigFace structure, written from the method description in the paper. It is not the authors’ released code. The training loop uses synthetic dummy tensors rather than real image pairs and a real VAE, so it runs as a smoke test without dataset dependencies. You can find the published paper here.
# rigface_reference.py
# Independent educational reimplementation of the RigFace architecture.
# Source paper: Wei, Varanka, Li, Jiang, Khor, Zhao.
# Pattern Recognition 180 (2026) 114322. DOI 10.1016/j.patcog.2026.114322
# Not the authors' released code. Written from the method description only.
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
# ──────────────────────────────────────────────────────────────────────────────
# FaceFusion: self-attention identity injection
# ──────────────────────────────────────────────────────────────────────────────
class FaceFusionAttention(nn.Module):
"""Core FaceFusion self-attention block.
Given identity features (x_id) and denoising features (x_dn), both
flattened to (batch, seq_len, channels):
1. Concatenate x_id and x_dn along the sequence dimension.
2. Run self-attention over the combined sequence.
3. Return only the x_dn half of the output.
This mirrors the description in Section 3.4 of the paper:
'x_id is first concatenated with x_dn along the w dimension. Then the
self-attention layer takes in it and only half feature of the output
along the w dimension is kept and sent into the cross-attention layer.'
"""
def __init__(self, channels, num_heads=8):
super().__init__()
assert channels % num_heads == 0, "channels must be divisible by num_heads"
self.norm = nn.LayerNorm(channels)
# Standard multi-head self-attention
self.attn = nn.MultiheadAttention(channels, num_heads, batch_first=True)
self.out_proj = nn.Linear(channels, channels)
def forward(self, x_id, x_dn):
# x_id, x_dn: (batch, seq_len, channels)
seq_len = x_dn.shape[1]
# Concatenate identity features first, then denoising features
x_cat = torch.cat([x_id, x_dn], dim=1) # (batch, 2*seq_len, channels)
x_norm = self.norm(x_cat)
attn_out, _ = self.attn(x_norm, x_norm, x_norm)
attn_out = self.out_proj(attn_out) + x_cat # residual connection
# Keep only the x_dn positions (second half)
return attn_out[:, seq_len:, :] # (batch, seq_len, channels)
class TransformerBlockWithFaceFusion(nn.Module):
"""A simplified transformer block that incorporates FaceFusion self-attention
followed by a standard cross-attention layer and a feed-forward layer.
In the full RigFace model, this replaces the standard transformer blocks
in both the Identity Encoder and the Denoising UNet."""
def __init__(self, channels, cross_dim, num_heads=8, ff_mult=4):
super().__init__()
self.face_fusion = FaceFusionAttention(channels, num_heads)
# Cross-attention: query from self, key/value from external condition
self.cross_norm = nn.LayerNorm(channels)
self.cross_attn = nn.MultiheadAttention(channels, num_heads,
kdim=cross_dim, vdim=cross_dim,
batch_first=True)
self.ff_norm = nn.LayerNorm(channels)
self.ff = nn.Sequential(
nn.Linear(channels, channels * ff_mult),
nn.GELU(),
nn.Linear(channels * ff_mult, channels),
)
def forward(self, x_dn, x_id, context):
# x_dn, x_id: (batch, seq_len, channels)
# context: (batch, ctx_len, cross_dim) from text or other conditions
x_dn = self.face_fusion(x_id, x_dn) # inject identity via self-attention
q = self.cross_norm(x_dn)
cross_out, _ = self.cross_attn(q, context, context)
x_dn = x_dn + cross_out
x_dn = x_dn + self.ff(self.ff_norm(x_dn))
return x_dn
# ──────────────────────────────────────────────────────────────────────────────
# Attribute Rigger: lightweight conditioning encoder
# ──────────────────────────────────────────────────────────────────────────────
class AttributeRigger(nn.Module):
"""The paper describes the Attribute Rigger as 'a convolution layer with
8 channels, 4x4 kernels and 2x2 strides'. It encodes the VAE-compressed
conditional images (rendering + background) into latent features and
integrates them into the Denoising UNet."""
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv = nn.Conv2d(in_channels, 8, kernel_size=4, stride=2, padding=1)
self.proj = nn.Conv2d(8, out_channels, kernel_size=1)
def forward(self, y):
# y: VAE-encoded conditional images (batch, in_channels, h, w)
return self.proj(F.relu(self.conv(y)))
# ──────────────────────────────────────────────────────────────────────────────
# Expression conditioning via time embedding injection
# ──────────────────────────────────────────────────────────────────────────────
class ExpressionEmbedder(nn.Module):
"""Maps BFM expression coefficients to the same dimension as the UNet
time embedding, then adds them so expression acts as an additional
continuous conditioning signal at every timestep."""
def __init__(self, expr_dim, time_dim):
super().__init__()
self.linear = nn.Linear(expr_dim, time_dim)
def forward(self, psi, time_emb):
# psi: (batch, expr_dim) expression coefficients from Deep3DRecon
# time_emb: (batch, time_dim) existing time embedding
return time_emb + self.linear(psi)
# ──────────────────────────────────────────────────────────────────────────────
# Minimal UNet-style encoder/decoder with FaceFusion blocks
# ──────────────────────────────────────────────────────────────────────────────
class SinusoidalPositionEmbedding(nn.Module):
def __init__(self, dim):
super().__init__()
self.dim = dim
def forward(self, t):
device = t.device
half = self.dim // 2
freqs = torch.exp(
-math.log(10000) * torch.arange(half, device=device) / (half - 1)
)
args = t[:, None].float() * freqs[None]
embedding = torch.cat([torch.sin(args), torch.cos(args)], dim=-1)
return embedding
class ResBlock(nn.Module):
def __init__(self, channels, time_dim):
super().__init__()
self.norm1 = nn.GroupNorm(8, channels)
self.conv1 = nn.Conv2d(channels, channels, 3, padding=1)
self.time_proj = nn.Linear(time_dim, channels)
self.norm2 = nn.GroupNorm(8, channels)
self.conv2 = nn.Conv2d(channels, channels, 3, padding=1)
def forward(self, x, t_emb):
h = self.conv1(F.silu(self.norm1(x)))
h = h + self.time_proj(F.silu(t_emb))[:, :, None, None]
h = self.conv2(F.silu(self.norm2(h)))
return x + h
class SimplifiedRigFace(nn.Module):
"""Simplified RigFace model demonstrating the key architectural ideas.
Compared to the full model (which inherits from SD 1.5 with full UNet
fine-tuning), this version uses lightweight conv blocks and a single
FaceFusion layer to make the code runnable without SD weights.
The identity injection mechanism is architecturally faithful to the paper.
"""
def __init__(
self,
base_ch=32,
time_dim=128,
context_dim=64,
expr_dim=64,
num_heads=4,
):
super().__init__()
self.time_embed = nn.Sequential(
SinusoidalPositionEmbedding(time_dim),
nn.Linear(time_dim, time_dim),
nn.SiLU(),
nn.Linear(time_dim, time_dim),
)
self.expr_embed = ExpressionEmbedder(expr_dim, time_dim)
# Identity Encoder (shares architecture with Denoising UNet)
self.id_stem = nn.Conv2d(4, base_ch, 3, padding=1) # 4-ch VAE latent
self.id_down1 = ResBlock(base_ch, time_dim)
self.id_down2 = ResBlock(base_ch * 2, time_dim)
self.id_down_conv = nn.Conv2d(base_ch, base_ch * 2, 2, stride=2)
# Denoising UNet
self.dn_stem = nn.Conv2d(4, base_ch, 3, padding=1)
self.dn_down1 = ResBlock(base_ch, time_dim)
self.dn_down_conv = nn.Conv2d(base_ch, base_ch * 2, 2, stride=2)
self.dn_down2 = ResBlock(base_ch * 2, time_dim)
# FaceFusion block at the bottleneck (second resolution level)
self.face_fusion_block = TransformerBlockWithFaceFusion(
channels=base_ch * 2,
cross_dim=context_dim,
num_heads=num_heads,
)
# Decoder
self.up_conv = nn.ConvTranspose2d(base_ch * 2, base_ch, 2, stride=2)
self.up1 = ResBlock(base_ch * 2, time_dim) # skip from dn_down1
self.head = nn.Conv2d(base_ch * 2, 4, 1) # predict noise in latent space
# Attribute Rigger for conditional images (renderings + background)
self.attr_rigger = AttributeRigger(in_channels=4, out_channels=base_ch)
def _encode_identity(self, z_id, t_emb):
# Simplified identity encoder matching UNet structure
h = self.id_stem(z_id)
h1 = self.id_down1(h, t_emb)
h = self.id_down_conv(h1)
h2 = self.id_down2(h, t_emb)
return h2
def forward(self, z_t, t, z_id, psi, y_cond, context):
# z_t : (batch, 4, h, w) noised target latent
# t : (batch,) diffusion timesteps
# z_id : (batch, 4, h, w) VAE-encoded source identity latent
# psi : (batch, expr_dim) expression coefficients from Deep3DRecon
# y_cond : (batch, 4, h, w) VAE-encoded conditional images
# context: (batch, ctx_len, context_dim) text or null embedding
t_emb = self.time_embed(t) # (batch, time_dim)
t_emb = self.expr_embed(psi, t_emb) # inject expression coefficients
# Identity Encoder forward pass (frozen VAE already ran to produce z_id)
x_id_feat = self._encode_identity(z_id, t_emb) # (batch, 2*ch, h/2, w/2)
# Attribute Rigger: add rendering/background signal to first denoising layer
attr_feat = self.attr_rigger(y_cond) # (batch, base_ch, h/2, w/2)
# Denoising UNet encoder
dn = self.dn_stem(z_t) + F.interpolate(attr_feat, size=z_t.shape[-2:])
dn_skip = self.dn_down1(dn, t_emb) # (batch, base_ch, h, w) — skip connection
dn = self.dn_down_conv(dn_skip)
dn = self.dn_down2(dn, t_emb) # (batch, 2*base_ch, h/2, w/2)
# FaceFusion: flatten spatial dims, inject identity, reshape back
b, c, hh, ww = dn.shape
dn_seq = dn.flatten(2).transpose(1, 2) # (batch, hh*ww, c)
id_seq = x_id_feat.flatten(2).transpose(1, 2) # (batch, hh*ww, c)
dn_seq = self.face_fusion_block(dn_seq, id_seq, context)
dn = dn_seq.transpose(1, 2).reshape(b, c, hh, ww)
# Decoder with skip connection
dn = self.up_conv(dn)
dn = torch.cat([dn, dn_skip], dim=1) # concatenate skip from encoder
dn = self.up1(dn, t_emb)
noise_pred = self.head(dn)
return noise_pred
# ──────────────────────────────────────────────────────────────────────────────
# Training loss: standard diffusion MSE on predicted vs. actual noise
# ──────────────────────────────────────────────────────────────────────────────
def diffusion_loss(noise_pred, noise_target):
"""Equation 2 in the paper. Simple MSE in the latent noise space."""
return F.mse_loss(noise_pred, noise_target)
def add_noise(z0, t, noise, num_timesteps=1000):
"""Simplified linear noise schedule for the smoke test."""
alpha = 1.0 - t.float() / num_timesteps # crude approximation
alpha = alpha[:, None, None, None]
return (alpha ** 0.5) * z0 + ((1.0 - alpha) ** 0.5) * noise
# ──────────────────────────────────────────────────────────────────────────────
# Smoke test: confirms shapes are correct end-to-end
# ──────────────────────────────────────────────────────────────────────────────
def smoke_test():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = SimplifiedRigFace(
base_ch=16,
time_dim=64,
context_dim=32,
expr_dim=32,
num_heads=4,
).to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-5)
batch, h, w = 2, 16, 16 # small spatial size for a smoke test
ctx_len, ctx_dim = 8, 32
z0 = torch.randn(batch, 4, h, w, device=device) # clean latent
z_id = torch.randn(batch, 4, h, w, device=device) # identity latent
y_cond = torch.randn(batch, 4, h, w, device=device) # conditional images
psi = torch.randn(batch, 32, device=device) # expression coefficients
context = torch.randn(batch, ctx_len, ctx_dim, device=device)
t = torch.randint(1, 1000, (batch,), device=device)
noise = torch.randn_like(z0)
z_t = add_noise(z0, t, noise)
optimizer.zero_grad()
noise_pred = model(z_t, t, z_id, psi, y_cond, context)
assert noise_pred.shape == z0.shape, \
f"shape mismatch: expected {z0.shape}, got {noise_pred.shape}"
loss = diffusion_loss(noise_pred, noise)
loss.backward()
optimizer.step()
print(f"smoke test passed, output shape {noise_pred.shape}")
print(f"training loss {loss.item():.4f}")
print(f"all gradients computed without error")
if __name__ == "__main__":
smoke_test()
Conclusion
The central claim of RigFace is that where you inject identity in a diffusion model matters more than how elaborate the injection mechanism is. Most adapter-based approaches to face editing have routed identity through cross attention, which is available and flexible but was designed for text-to-image alignment rather than structural identity preservation. RigFace routes it through self attention instead, which is where the model builds internal spatial relationships, and the experimental results suggest that the architectural position of the injection is doing a substantial portion of the work.
The Spatial Attribute Provider makes an equally important point about representation. Expression, lighting, and pose are all described differently in 3DMM parameter spaces, and the right signal format for each attribute is not the same. Expression coefficients, which describe how face muscles deform the geometry, transfer well as abstract parameter vectors. Lighting and pose, which describe spatial configurations in the scene, work better when rendered into an image before being given to the model. The ablation study shows that mixing these representations in either direction hurts performance, which is a transferable design principle for anyone building multi-attribute conditioning systems on top of diffusion models.
The out-of-domain generalization is the most practically distinctive finding and the one that differs most clearly from what existing face editing papers usually show. The ability to edit oil paintings, digital art, and cartoon faces without seeing any of those styles during training reflects something about using a generative model’s own internal features as the identity representation rather than an external semantic encoder like CLIP. Whether this would extend to even more unusual visual styles, to 3D representations, or to video is genuinely untested, and the paper is honest that these are open directions rather than demonstrated capabilities.
The real costs of the approach are inference speed and the assumption of a clean source image. Five seconds per image is workable for studio applications and unusable for interactive ones. The reliance on a well-exposed, well-composed source portrait as the identity image means the method is not robust to low-quality inputs, and the skin tone entanglement in DECA’s lighting decomposition will produce occasional color artifacts that neither RigFace nor the user has full control over. None of these are fatal to the approach, but they are the places where a production deployment would need additional engineering attention.
What stays with a reader after working through the method and the results is a concrete lesson about the anatomy of diffusion models. Cross attention and self attention are not interchangeable injection points. Self attention, because it models the internal structure of what is being generated, is the right place to inject structural identity information. Cross attention, because it responds to external conditioning signals, is the right place for attribute guidance like text or rendered conditions. RigFace succeeds in part because it takes that distinction seriously rather than treating both mechanisms as equivalent channels for shoving features into the model.
Frequently asked questions
What is RigFace and what can it edit
RigFace is a face editing model that combines 3D Morphable Model parameter control with a fine-tuned Stable Diffusion model. Given a portrait image, it can change the facial expression, head pose, or lighting while keeping the subject’s identity intact. It was tested on both real face photographs and artistic portrait styles.
Why does RigFace use self attention for identity instead of cross attention
Self attention models the internal spatial relationships within a generated image, which is where facial structure and identity live. Cross attention was designed to connect the generated image to an external conditioning signal like a text prompt. Injecting identity into self attention means the model reasons about the target face’s structure in terms of the source face’s structure, rather than treating the source face as an external instruction to follow.
Why does RigFace use rendered images for lighting and pose but coefficients for expression
Rendered images provide a spatial, pixel-aligned map of how the head is oriented and where the light is coming from. Expression coefficients describe how muscles deform the face geometry in a compact parameter space that the model learns to interpret. The ablation study in the paper shows that using abstract angle or SH coefficient vectors for lighting and pose fails, while rendered images succeed, but expression works better as coefficients than as a rendered face.
Can RigFace edit oil paintings and cartoon faces without retraining
Yes. The paper evaluated the model on 500 images from Pinterest and Unsplash covering oil paintings, cyberpunk art, cartoon illustrations, and comics, all out of the training distribution. The model edits expression, lighting, and pose on these artistic portraits without any additional fine-tuning. Fine-tuning on a small in-domain set improves results further, but the base generalization is already strong.
How long does RigFace take to generate an image
About 5 seconds per image on a single GPU. That is slower than most of the ten baselines in the paper’s comparison. The dual-encoder architecture, with both an Identity Encoder and a Denoising UNet fully fine-tuned and running at inference time, is the structural reason for the cost. No parameter-efficient shortcut is taken, which is also part of why the quality is competitive.
What are the main failure cases for RigFace
Large head pose changes are the weakest condition because they require significant background inpainting, and the inpainting quality degrades under extreme rotations. A second known issue is that DECA’s lighting estimation can partially encode skin tone as illumination, which produces unintended skin color shifts in some lighting editing results when the source and target subjects differ in skin tone.
Read the full method, ablation studies, and generalization experiments for yourself.