Lucas Farndale, Robert Insall, and Ke Yuan at the University of Glasgow built a three-branch self-supervised framework that teaches H&E pathology models to reason about immunohistochemistry and spatial transcriptomics it will never see at deployment — and the performance gains reach 101% over the best competing method.
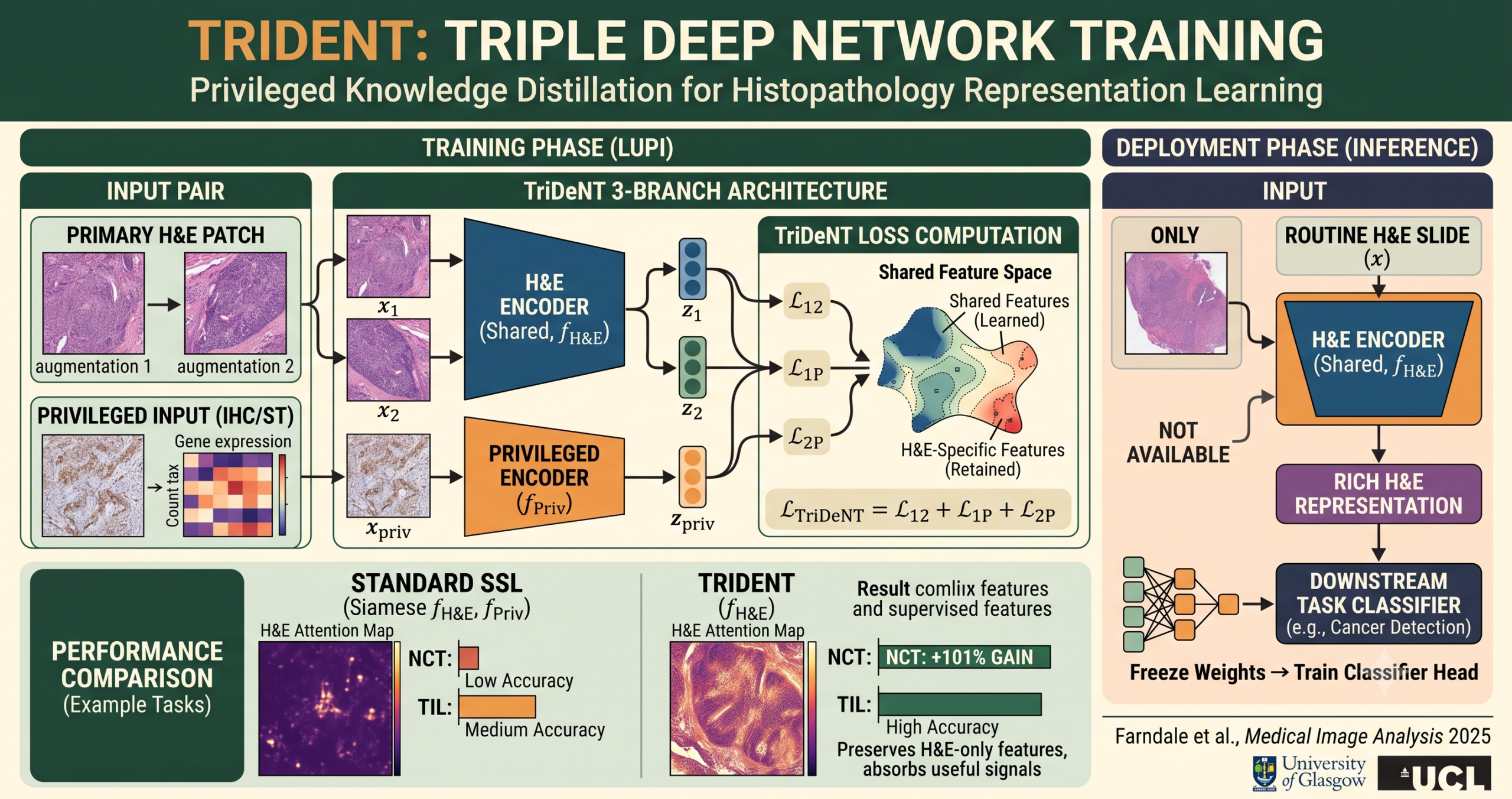
- TriDeNT is a three-branch self-supervised framework that distils privileged data — IHC stains, spatial transcriptomics, or nuclei annotations — into H&E models that operate without those data at inference.
- Standard two-branch Siamese privileged models actively harm performance when the privileged stain is uninformative, because the shared embedding space discards features absent from both branches.
- Adding a second primary branch alongside the privileged branch preserves H&E-specific features while still absorbing useful signals from the privileged data.
- Across ten downstream tasks on datasets including NCT, Camelyon, PANDA, PanNuke, and IMP, TriDeNT outperforms both privileged and unprivileged Siamese baselines in every setting tested.
- Performance improvements reach up to 101% over the privileged Siamese baseline on the NCT tissue classification task, and TriDeNT raises Camelyon accuracy from random guessing at 51% to 81%.
- The method is robust to useless or adversarial privileged information — it silently ignores blank and shuffled inputs without degrading below the unprivileged baseline.
The Problem That Makes This Paper Necessary
Every week, research labs around the world produce paired pathology datasets — H&E slides alongside IHC stains, fluorescence imaging, or spatial transcriptomics from the same tissue section. These pairings exist because the researchers needed the additional modality for their biological question. But the paired modality is expensive to acquire at scale, so when it comes to training a model that will eventually be deployed in a clinic, only the routine H&E data makes it to inference time. The richer information gets left on the table.
Learning Using Privileged Information (LUPI), introduced by Vapnik and Vashist in 2009, is the theoretical framework designed to address exactly this. The idea is straightforward in principle: during training you have access to extra data that will not be available during deployment, and you want to use it. In supervised settings, LUPI methods have been adapted to neural networks and knowledge distillation. The self-supervised variant — where you have paired data but no labels — is newer and, as the Glasgow team demonstrates, considerably trickier to get right.
The dominant approach has been to treat the privileged data as a second view in a standard Siamese self-supervised architecture. The model is trained to produce similar representations for the H&E patch and its paired IHC stain. At inference time, you discard the privileged branch and use only the H&E encoder. Simple enough. The problem, it turns out, is that this simplicity is a trap.
When a Siamese network minimises the distance between two representations, any feature present in only one branch contributes nothing to the loss — so the model has no incentive to learn it. If the paired IHC stain rarely contains endothelial cells, the H&E encoder stops learning to detect them. The model has traded primary-data features for shared-data features. In settings where the privileged data is highly informative, this is a worthwhile trade. In settings where it is not, performance collapses.
Why Two Branches Are Not Enough
The Glasgow team spent considerable effort documenting exactly how and when two-branch privileged Siamese training goes wrong, and the results are striking. On the SegPath dataset — which contains eight subsets of H&E slides each paired with a different immunofluorescence stain — the privileged Siamese baseline achieves consistently worse performance than the unprivileged baseline for several stains.
The ERG stain, which marks endothelial cells, is a good illustration. Endothelial cells are rare in most tissue sections. A Siamese model trained with ERG as the privileged view is forced to focus its shared embedding space on the few endothelial cell signatures that appear in both modalities. Everything else — the connective tissue textures, the nuclear morphologies, the background structure that might actually matter for a downstream tissue classification task — gets filtered out. GradCAM visualisations confirm this directly: the privileged Siamese model focuses almost exclusively on nuclei, while TriDeNT allocates attention across the full tissue structure.
Farndale et al. formalise this using the language of feature variance. A feature is considered strongly present in an input if its variance across samples exceeds the variance introduced by the data augmentations used during training. It is weakly present if its variance is nonzero but below that threshold. Siamese models learn features that are strongly present in both inputs. TriDeNT, with its additional primary branch, also learns features that are strongly present in only the H&E data.
Think about what this actually requires. You need three things simultaneously: the shared embedding to benefit from the privileged signal, the primary embedding to remain rich enough to capture H&E-only features, and the training objective to balance these two goals without explicit feature selection. That is the core design challenge TriDeNT solves.
The Three-Branch Architecture
TriDeNT extends the Siamese paradigm by running two independent augmented views of the primary H&E patch through a shared encoder, alongside a single view of the privileged data through a separate encoder. The three resulting representations are then used to compute a pairwise self-supervised loss across all three branch combinations.
The formal notation is worth following. Given a primary input x and a privileged input x*, the model produces three representations — z1 and z2 from two augmentations of x, and z* from x*. These are projected to embeddings e1, e2, and e* by branch-specific projectors. The full TriDeNT loss sums over all three pairings.
Here N equals 2 (the two primary branches) and M equals 1 (the single privileged branch). The beauty of the construction is that both z1 and z2 act as supervisory signals for z*, which means the privileged encoder is only pushed to represent features it can actually predict from the H&E data. At the same time, z* acts as a supervisory signal for both z1 and z2, encouraging the primary encoder to absorb information that is weakly present in H&E but strongly present in the privileged input.
The primary branches use a shared encoder and projector — a design choice supported by earlier work from the same group showing that weight sharing improves unprivileged performance. The privileged branch uses its own encoder, which can have an entirely different architecture. This flexibility turned out to be important for the spatial transcriptomics experiments, where a multilayer perceptron processes the gene count vectors while a CNN handles the H&E patches.
Two Loss Functions, Same Conclusion
The paper tests TriDeNT with two distinct self-supervised objectives: VICReg (Variance Invariance Covariance Regularisation) and InfoNCE (noise-contrastive estimation as used in SimCLR). These represent the two main camps — non-contrastive and contrastive — in modern self-supervised learning. The fact that TriDeNT outperforms baselines with both losses is strong evidence that the gains come from the architectural design rather than from any particular loss function.
VICReg’s objective combines an invariance term pulling representations of different branches together, a variance term preventing representational collapse within a branch, and a covariance term decorrelating the dimensions of the embedding. Because variance and covariance regularisation are applied per branch independently, VICReg naturally accommodates different architectures on different branches — an advantage for multi-modal settings that the authors exploit.
The InfoNCE variant works by treating each positive pair as the correct matching out of a batch of negatives — a contrastive setup that requires careful batch construction but has been shown to produce highly discriminative features, particularly for retrieval tasks.
What the Experiments Actually Show
The experimental setup is more thorough than most papers in this space. Rather than evaluating on one or two downstream tasks, the authors test across ten datasets spanning tissue classification, metastasis detection, polyp grading, prostate malignancy, tumour infiltrating lymphocyte detection, prostate ISUP grading, and colorectal dysplasia detection. The privileged data includes eight different immunofluorescence stains from the SegPath dataset, brightfield IHC from BCI, nuclear segmentation masks from PanNuke, and spatial transcriptomics from the ALS-ST dataset.
Immunofluorescence Stains on SegPath
The most dramatic results come from the SegPath experiments. The pan-CK stain, which marks epithelial cells and is directly relevant to tumour detection, produces the largest overall gains. On the NCT colorectal tissue classification task, accuracy climbs from 0.4566 with the privileged Siamese baseline to 0.9169 with TriDeNT — a 101% improvement. On the Camelyon out-of-distribution metastasis detection task, performance rises from near-random at 51% to 81% with pan-CK as the privileged input.
| Task | TriDeNT (VICReg) | Siamese Privileged | Siamese Unprivileged | Supervised Baseline |
|---|---|---|---|---|
| NCT | 0.9031 | 0.6618 | 0.8582 | 0.9245 |
| PanNuke | 0.9324 | 0.8332 | 0.9190 | 0.8901 |
| Singapore | 0.8359 | 0.7173 | 0.7839 | 0.9103 |
| MHIST | 0.7656 | 0.6786 | 0.7179 | 0.7042 |
| TIL | 0.9270 | 0.8934 | 0.9048 | 0.9216 |
| Camelyon | 0.7067 | 0.6179 | 0.5229 | 0.8440 |
| PANDA | 0.7099 | 0.5675 | 0.6763 | — |
| IMP 1K | 0.7186 | 0.6415 | 0.6389 | — |
| IMP 4K | 0.8554 | 0.7657 | 0.8332 | — |
| IMP Cervix | 0.7439 | 0.7289 | 0.7301 | — |
Table: Results averaged across all eight SegPath stains using VICReg loss. All values drawn from Figure 3(b) and Table S4 of the paper. Bold indicates best self-supervised result for each task.
The TIL (tumour infiltrating lymphocyte) task tells a particularly clean story about the mechanism. Immune-related stains — CD3CD20 and CD45RB — produce the best TIL detection performance, as one would expect given that these stains directly mark immune cells. The erythrocyte stain CD235a and the endothelial stain ERG produce smaller gains, which again makes biological sense. The method is not blindly absorbing whatever privileged information it receives — it is learning which aspects of the privileged signal are relevant to the primary domain.
Spatial Transcriptomics — A Harder Test
Here is where it gets interesting. Spatial transcriptomics — gene expression counts measured at spatial points across a tissue section — is notoriously difficult to use with deep learning. The data is tabular, noisy, and sparse, and the relationship between morphology and gene expression is not fully understood even biologically. The ALS-ST dataset contains 80 human and 331 mouse spinal cord sections from individuals with amyotrophic lateral sclerosis, paired with matched spatial transcriptomics.
Despite these challenges, TriDeNT shows consistent improvements of up to 4.4% over other methods on the white matter and grey matter classification task, and up to 2.2% on SOD1 genotype prediction. Crucially, the gene-expression correlation analysis is compelling evidence that something meaningful is being learned. The team computed the cross-correlation between each element of the learned representations and the count for each gene across the validation set. TriDeNT representations are substantially more correlated with gene expression patterns than unprivileged Siamese representations — and this holds even for genes that were not present in the training set. The model has not simply memorised the training genes. It has learned morphological features that encode information about gene expression more generally.
“With TriDeNT, primary models receive feedback from both data types, leading to features from both inputs being learned.” — Farndale, Insall, and Yuan, Medical Image Analysis 2025
Robustness to Harmful Privileged Information
The robustness experiments are arguably the most practically important result in the paper. In real clinical datasets, you cannot always know in advance how informative your paired data will be for a given downstream task. The team tested two adversarial scenarios — blank privileged images (providing no information at all) and randomly shuffled privileged images (providing information that has no correspondence to the paired primary patch).
Privileged Siamese models collapse in both scenarios, achieving the worst performance on every test dataset. TriDeNT, in contrast, achieves performance comparable to the unprivileged baseline. In some cases it marginally outperforms the unprivileged baseline even with shuffled inputs, possibly because shuffled segmentation masks still contain common structural motifs that encourage the primary encoder to detect similar shapes in H&E.
This is not a small distinction. It means TriDeNT can be applied to any paired dataset — even one where the biological relevance of the pairing to your downstream task is unknown — without risk of actively harming the model’s primary representations. That is the property that makes it a practical tool rather than a research curiosity.
Few-Shot Performance and Small Dataset Behaviour
Self-supervised learning methods typically require large datasets to be competitive with supervised approaches. TriDeNT shows an unusual pattern here. At high data availability — where the full training set is used for the downstream classifier head — TriDeNT is competitive with supervised baselines. As data availability decreases, TriDeNT’s advantage grows. There are dataset fractions at which both the supervised baseline and the privileged Siamese model collapse to trivial solutions while TriDeNT continues to perform meaningfully.
This matters for medical imaging more than almost any other field. Rare diseases, novel biomarkers, and newly established patient cohorts routinely produce datasets with tens or hundreds of labelled examples rather than thousands. A model that retains useful structure at those scales is not just academically interesting — it is clinically relevant.
The PanNuke experiments with nuclear segmentation masks as privileged information are a good illustration. Nuclear annotations are expensive to produce manually but there are now large datasets of machine-generated segmentations. TriDeNT trained with these masks as privileged data achieves up to 42.4% improvement over the privileged Siamese baseline and up to 5.2% over the unprivileged baseline on downstream tasks that have nothing directly to do with nuclear shapes. The model has absorbed information about nuclear morphology and translated it into richer general representations of tissue structure.
Adversarial Robustness and Domain Transfer
A legitimate concern with any method that learns weaker features from privileged data is that those weaker features might make the model more vulnerable to adversarial attacks. Weaker features are, by definition, more easily confounded by small input perturbations. The team addressed this directly with Projected Gradient Descent (PGD) white-box attacks across all SegPath models.
The result is reassuring. TriDeNT shows similar adversarial robustness to the unprivileged Siamese baseline. Privileged Siamese models are considerably more vulnerable, because they have sacrificed strong primary features entirely in favour of shared features. Since TriDeNT retains the strong primary features alongside the weaker privileged ones, the strong features provide a stable foundation that is not easily disrupted by bounded perturbations.
The Camelyon domain transfer results tell a similar story. Camelyon tests whether a model trained on slides from three hospitals generalises to images from a fourth hospital with different scanners and staining protocols. Unprivileged Siamese models achieve little better than random guessing on this task. TriDeNT reaches 70.7% accuracy with VICReg. The richer representations learned with privileged supervision appear to encode more fundamental biological features that are less sensitive to acquisition-related variation.
Clinical Translation Gap
The results in this paper are genuinely promising, but the distance between a research demonstration and clinical deployment deserves honest attention.
All downstream tasks in this paper use frozen encoder weights — no fine-tuning was performed on the target tasks. The authors acknowledge this explicitly, noting that fine-tuning could improve performance further. But it also means the reported numbers represent a zero-shot transfer scenario, not the fully optimised performance a clinical system would achieve after deployment-specific tuning.
The SegPath pretraining dataset draws from pan-cancer tissue from 1,583 patients across 18 tissue types, which is substantial. However, the distribution of tissue types and staining protocols in SegPath may differ from the distribution encountered in any given clinical setting. Camelyon specifically tests this kind of distributional shift, and the results show that TriDeNT is more robust than baselines — but a 70% accuracy on metastasis detection in a heterogeneous five-hospital setting is not a clinically deployable number. It is a proof of concept that the representations are more transferable.
The spatial transcriptomics experiments were conducted on mouse and human ALS spinal cord tissue. Amyotrophic lateral sclerosis is a neurodegenerative disease affecting motor neurons, and the tissue morphology of ALS spinal cord is a very specific domain. The finding that TriDeNT representations correlate with gene expression for unseen genes is scientifically interesting, but it would be premature to conclude that this generalises across all cancer types or disease contexts without additional validation.
Regulatory approval for AI-assisted pathology tools requires prospective clinical validation studies with pre-registered endpoints, diverse patient populations, and head-to-head comparison with current standard-of-care practices. None of the datasets used in this paper were collected specifically for that purpose. TriDeNT is a research method that demonstrates a meaningful improvement in representation quality — the clinical pathway from that demonstration to a deployable product involves substantially more work.
Limitations Worth Discussing Honestly
Training was conducted for 100 epochs on a batch size of 128 — a relatively modest regime for self-supervised learning, which typically benefits from longer training and larger batches. The authors acknowledge this directly, noting that hyperparameters were chosen for parity with previous Siamese network work rather than optimised for TriDeNT. The performance gains reported are therefore likely conservative.
The paper tests only the N equals 2, M equals 1 configuration — two primary branches and one privileged branch. Appendix E discusses using more privileged branches but notes that adding additional privileged inputs can deteriorate performance. The mechanism for this deterioration is not fully characterised, which is an open question with practical relevance for datasets that contain multiple paired modalities simultaneously.
The no-harm guarantee problem in LUPI is real and not fully resolved by TriDeNT. The method is demonstrated to be safe under blank and shuffled privileged inputs, which are adversarial extreme cases. In the space between perfectly informative and completely uninformative privileged data, there may be intermediate regimes where performance is slightly below the unprivileged baseline. The paper does not characterise this region systematically.
Finally, the paper does not include a comparison with large pretrained foundation models such as CONCH, UNI, or similar pathology-specific vision transformers that have been trained on millions of slides. Given that TriDeNT’s pretraining datasets are orders of magnitude smaller, this comparison would clarify where TriDeNT sits in the practical landscape of available tools.
What TriDeNT Opens Up
The core achievement is cleaner than it might first appear. TriDeNT does not simply find a way to use privileged information. Any Siamese privileged method does that. What TriDeNT does is eliminate the cost that all previous methods have paid — the forced trade-off between primary and privileged feature learning. The two-primary-branch design creates a competitive dynamic where the primary encoder must balance two supervision signals at once. That competition is precisely what prevents the privileged signal from crowding out H&E-specific information.
The conceptual shift this introduces is worth stating directly. The standard view in LUPI has been that privileged information provides additional supervisory signal that guides the primary model toward better representations. TriDeNT suggests a different view: the primary model should receive supervisory signals from both the primary and privileged domains simultaneously, and the architecture should make it structurally impossible for either signal to fully dominate.
The transferability to other domains is real and not just speculative. Any biomedical dataset where a routine modality is paired with a richer but less accessible modality is a potential application. Paired MRI and PET in Alzheimer’s disease. Chest X-ray and pulmonary function test data. Dermoscopy images and confocal microscopy. The 7-pt skin lesion dataset, CheXpert, and CheXphoto are all mentioned by the authors as near-term candidates. Multiplexed imaging, where many protein markers are measured simultaneously on a single slide, is a particularly compelling future application — the problem of integrating those multiple channels into models of standard pathology images is exactly the setting TriDeNT was designed for.
Future work could push in several directions. Fine-tuning the pretrained encoders rather than freezing them is the obvious next step and would likely yield substantially better numbers across the board. Pairing TriDeNT with large pretrained pathology foundation models — using a pretrained model as the privileged branch teacher — is a natural extension of the teacher-student framing that could multiply the effective training set. Automatic selection of which privileged features to weight more heavily, perhaps through attention mechanisms across branches, could further reduce the sensitivity to uninformative paired data.
There is also a deeper scientific use case that the transcriptomics results hint at. UMAP projections of TriDeNT representations reveal morphological clusters that correlate with gene overexpression patterns — clusters that are not found by unprivileged methods. If TriDeNT can reliably surface tissue morphology features that track with molecular biology, it becomes a tool for hypothesis generation, not just prediction. A pathologist reviewing a large unlabelled cohort could use TriDeNT-derived clusters to identify patient subgroups whose morphological patterns suggest particular molecular vulnerabilities — and then test those hypotheses with targeted sequencing. That is a fundamentally different kind of clinical value than a binary classification accuracy number.
The broader lesson from TriDeNT is about data that exists but is not used. Biomedical research produces enormous quantities of paired data as a byproduct of experimental design — the spatial transcriptomics run alongside the H&E, the IHC confirmation ordered after the H&E read. These pairings are expensive, scientifically meaningful, and almost entirely absent from the training sets of the models that will eventually make predictions from the routine data. TriDeNT is a concrete proposal for how to close that gap — and the numbers suggest it is worth taking seriously.
Complete Proposed Model Code in PyTorch
The following is a complete PyTorch implementation of TriDeNT as described in Sections 2.4 and 2.5 of the paper. It covers the full three-branch architecture with shared primary encoder and separate privileged encoder, both VICReg and InfoNCE self-supervised loss functions extended to three branches, augmentation pipelines for H&E patches, the downstream linear probe evaluation setup, and a runnable smoke test on synthetic data.
# =============================================================================
# TriDeNT: Triple Deep Network Training for Privileged Knowledge Distillation
# Paper: Farndale, Insall, Yuan — Medical Image Analysis 102 (2025) 103479
# DOI: https://doi.org/10.1016/j.media.2025.103479
# University of Glasgow / UCL / CRUK Scotland Institute
# =============================================================================
from __future__ import annotations
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms, models
from typing import List, Optional, Tuple, Dict
# ─── SECTION 1: Encoder and Projector ────────────────────────────────────────
class Encoder(nn.Module):
"""ResNet-based image encoder for H&E or privileged image branches.
In the paper, a ResNet-50 backbone is used for H&E patches.
The privileged encoder can use any architecture (CNN, MLP, etc.)
depending on the modality. This implementation supports both.
The output is the pooled feature vector before any projector.
"""
def __init__(self, backbone: str = 'resnet50', pretrained: bool = False):
super().__init__()
base = getattr(models, backbone)(pretrained=pretrained)
self.out_dim = base.fc.in_features
self.backbone = nn.Sequential(*list(base.children())[:-1])
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.backbone(x).flatten(1) # (B, D)
class MLPEncoder(nn.Module):
"""MLP encoder for non-image privileged inputs such as spatial transcriptomics.
Used in the ALS-ST experiments where gene expression count vectors
are passed as the privileged input (Section 3.4 of the paper).
"""
def __init__(self, input_dim: int, hidden_dims: List[int], out_dim: int):
super().__init__()
layers = []
prev = input_dim
for h in hidden_dims:
layers += [nn.Linear(prev, h), nn.BatchNorm1d(h), nn.ReLU(inplace=True)]
prev = h
layers.append(nn.Linear(prev, out_dim))
self.net = nn.Sequential(*layers)
self.out_dim = out_dim
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.net(x)
class Projector(nn.Module):
"""Two-layer MLP projector head mapping encoder output to embedding space.
Following the VICReg and SimCLR convention, a projector head is placed
between the encoder output and the self-supervised loss computation.
This has been shown to improve feature generalisation (Chen et al. 2020,
Bardes et al. 2021). At inference, only the encoder is used; the projector
is discarded.
"""
def __init__(self, in_dim: int, hidden_dim: int = 2048, out_dim: int = 2048):
super().__init__()
self.net = nn.Sequential(
nn.Linear(in_dim, hidden_dim),
nn.BatchNorm1d(hidden_dim),
nn.ReLU(inplace=True),
nn.Linear(hidden_dim, hidden_dim),
nn.BatchNorm1d(hidden_dim),
nn.ReLU(inplace=True),
nn.Linear(hidden_dim, out_dim),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.net(x)
# ─── SECTION 2: TriDeNT Architecture ─────────────────────────────────────────
class TriDeNT(nn.Module):
"""TriDeNT: Triple Deep Network Training for Privileged Knowledge Distillation.
Implements the three-branch architecture from Section 2.4 of the paper.
Two branches share a primary encoder and projector (processing augmented
views of the H&E patch), while a third branch uses a separate encoder and
projector for the privileged input.
The loss is computed over all three pairings (z1,z2), (z1,z*), (z2,z*),
as defined in Equation 3: L_{N,M} = sum_{i != j} L_2(z^i, z^j).
At inference time, only the primary encoder is used.
Parameters
----------
primary_encoder : shared encoder for both H&E branches (f1 = f2)
privileged_encoder: separate encoder for the privileged branch
embed_dim : projector output dimension (default 2048)
loss_type : 'vicreg' or 'infonce'
"""
def __init__(
self,
primary_encoder: nn.Module,
privileged_encoder: nn.Module,
embed_dim: int = 2048,
loss_type: str = 'vicreg',
):
super().__init__()
self.primary_enc = primary_encoder
self.priv_enc = privileged_encoder
self.loss_type = loss_type
# Shared projector for both primary branches (g1 = g2 = g)
self.primary_proj = Projector(primary_encoder.out_dim, 2048, embed_dim)
# Separate projector for privileged branch
self.priv_proj = Projector(privileged_encoder.out_dim, 2048, embed_dim)
def forward(
self,
x1: torch.Tensor, # augmented view 1 of H&E patch
x2: torch.Tensor, # augmented view 2 of H&E patch
x_priv: torch.Tensor, # privileged input (IHC, transcriptomics, mask)
) -> Dict[str, torch.Tensor]:
"""Forward pass computing all three branch representations.
Returns dict with embeddings e1, e2, e_priv and the total loss.
"""
# Encode and project — branches 1 and 2 share encoder weights
z1 = self.primary_enc(x1) # (B, D_enc)
z2 = self.primary_enc(x2)
z_priv = self.priv_enc(x_priv)
e1 = self.primary_proj(z1) # (B, embed_dim)
e2 = self.primary_proj(z2)
e_priv = self.priv_proj(z_priv)
# Compute pairwise losses over all three branch combinations (Eq. 3)
if self.loss_type == 'vicreg':
loss_fn = vicreg_loss
else:
loss_fn = infonce_loss
l_12 = loss_fn(e1, e2)
l_1p = loss_fn(e1, e_priv)
l_2p = loss_fn(e2, e_priv)
total = l_12 + l_1p + l_2p
return {
'loss': total,
'loss_12': l_12.detach(),
'loss_priv': (l_1p + l_2p).detach() / 2,
'z_primary': z1.detach(), # used for EMA prototype updates if needed
}
def encode_primary(self, x: torch.Tensor) -> torch.Tensor:
"""Inference-time method: encode H&E patch without augmentation."""
return self.primary_enc(x)
# ─── SECTION 3: VICReg Loss (Eq. 4-8) ───────────────────────────────────────
def vicreg_loss(
z1: torch.Tensor, z2: torch.Tensor,
lam: float = 25.0, mu: float = 25.0, nu: float = 1.0,
gamma: float = 1.0, eps: float = 1e-4,
) -> torch.Tensor:
"""VICReg objective extended to a pair of embeddings (Eq. 4 of the paper).
Components:
s(z1, z2): invariance — MSE between paired embeddings
v(z): variance — hinge loss keeping per-dimension std above gamma
c(z): covariance — penalises off-diagonal elements of the covariance matrix
The same function is called for each of the three branch pairs.
Default hyperparameters follow Bardes et al. (2021).
"""
N, D = z1.shape
# Invariance term: push representations of matching pairs together (Eq. 5)
inv = F.mse_loss(z1, z2)
def var_cov(z: torch.Tensor):
# Variance term (Eq. 6): prevent representational collapse per dimension
z_bar = z - z.mean(dim=0)
std = torch.sqrt(z_bar.var(dim=0) + eps)
var_loss = torch.mean(torch.clamp(gamma - std, min=0))
# Covariance term (Eq. 7-8): decorrelate embedding dimensions
cov = (z_bar.T @ z_bar) / (N - 1)
off_diag = cov ** 2
mask = ~torch.eye(D, dtype=torch.bool, device=z.device)
cov_loss = off_diag[mask].sum() / D
return var_loss, cov_loss
v1, c1 = var_cov(z1)
v2, c2 = var_cov(z2)
return lam * inv + mu * (v1 + v2) + nu * (c1 + c2)
# ─── SECTION 4: InfoNCE Loss (Eq. 9-10) ─────────────────────────────────────
def infonce_loss(
z1: torch.Tensor, z2: torch.Tensor,
temperature: float = 0.07,
) -> torch.Tensor:
"""InfoNCE/NT-Xent loss as used in SimCLR (Eq. 9-10 of the paper).
For a batch of N pairs, each sample is treated as a positive match for
its paired representation and as a negative for all other samples.
Temperature is 0.07 following Chen et al. (2020).
"""
N = z1.shape[0]
z1 = F.normalize(z1, dim=-1)
z2 = F.normalize(z2, dim=-1)
def _nce(a: torch.Tensor, b: torch.Tensor) -> torch.Tensor:
sim = (a @ b.T) / temperature # (N, N)
labels = torch.arange(N, device=a.device)
return F.cross_entropy(sim, labels)
return (_nce(z1, z2) + _nce(z2, z1)) / 2
# ─── SECTION 5: Data Augmentation Pipeline for H&E Patches ───────────────────
def he_augmentations(patch_size: int = 224) -> transforms.Compose:
"""Standard augmentation pipeline for H&E pathology patches.
Following the SegPath and BCI experimental setup:
- Random resized crop to simulate different magnification views
- Horizontal and vertical flipping for rotation invariance
- Colour jitter to handle stain variation across slides and scanners
- Gaussian blur for multi-scale feature learning
- Random grayscale occasionally to make features stain-agnostic
"""
return transforms.Compose([
transforms.RandomResizedCrop(patch_size, scale=(0.2, 1.0)),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.RandomApply([
transforms.ColorJitter(0.4, 0.4, 0.4, 0.1)
], p=0.8),
transforms.RandomGrayscale(p=0.2),
transforms.RandomApply([
transforms.GaussianBlur(kernel_size=23)
], p=0.5),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
# ─── SECTION 6: Linear Probe for Downstream Evaluation ───────────────────────
class LinearProbe(nn.Module):
"""Single linear classifier head for downstream task evaluation.
Following Section 2.4 and Fig. 1B of the paper: after TriDeNT pretraining,
the primary encoder weights are frozen and a small classifier head is trained
with labelled data. This is the standard SSL evaluation protocol.
The small amount of labelled data required is a key advantage of TriDeNT
for biomedical settings with limited ground-truth annotations.
"""
def __init__(self, encoder: nn.Module, num_classes: int):
super().__init__()
self.encoder = encoder
# Freeze encoder weights — only the head is trained
for param in self.encoder.parameters():
param.requires_grad = False
self.head = nn.Linear(encoder.out_dim, num_classes)
def forward(self, x: torch.Tensor) -> torch.Tensor:
with torch.no_grad():
features = self.encoder(x)
return self.head(features)
# ─── SECTION 7: Training Loop ─────────────────────────────────────────────────
def pretrain_epoch(
model: TriDeNT,
optimizer: torch.optim.Optimizer,
loader,
device: str,
) -> Dict[str, float]:
"""One pretraining epoch of TriDeNT.
Expects the dataloader to return (x_primary, x_privileged) tuples.
Two augmented views of x_primary are generated on the fly.
"""
model.train()
aug = he_augmentations()
totals = {'loss': 0.0, 'loss_12': 0.0, 'loss_priv': 0.0}
n = 0
for x_primary, x_priv in loader:
# Generate two augmented views of each H&E patch
x1 = torch.stack([aug(img) for img in x_primary]).to(device)
x2 = torch.stack([aug(img) for img in x_primary]).to(device)
x_priv = x_priv.to(device)
optimizer.zero_grad()
out = model(x1, x2, x_priv)
out['loss'].backward()
optimizer.step()
bs = x1.size(0)
n += bs
for k in totals:
totals[k] += out[k].item() * bs
return {k: v / n for k, v in totals.items()}
def finetune_head(
probe: LinearProbe,
optimizer: torch.optim.Optimizer,
loader,
device: str,
) -> float:
"""Train only the linear probe head for one epoch (Fig. 1B)."""
probe.train()
total_loss, n = 0.0, 0
for x, y in loader:
x, y = x.to(device), y.to(device)
optimizer.zero_grad()
loss = F.cross_entropy(probe(x), y)
loss.backward()
optimizer.step()
total_loss += loss.item() * x.size(0)
n += x.size(0)
return total_loss / n
@torch.no_grad()
def evaluate_probe(probe: LinearProbe, loader, device: str) -> float:
"""Evaluate linear probe accuracy (Fig. 1C)."""
probe.eval()
correct, n = 0, 0
for x, y in loader:
x, y = x.to(device), y.to(device)
correct += (probe(x).argmax(1) == y).sum().item()
n += y.size(0)
return correct / n
# ─── SECTION 8: Smoke Test ────────────────────────────────────────────────────
def _smoke_test():
"""End-to-end verification of TriDeNT on synthetic paired data.
Checks:
- Three-branch forward pass with shared primary encoder
- VICReg loss over all three branch pairs
- InfoNCE loss over all three branch pairs
- Gradient flow through primary and privileged encoders
- Linear probe frozen-encoder forward pass
- MLP encoder for tabular privileged data (transcriptomics use case)
"""
print("=" * 65)
print("TriDeNT Smoke Test — Synthetic Paired Pathology Data")
print("Farndale, Insall, Yuan. Med. Image Anal. 102 (2025) 103479")
print("=" * 65)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
torch.manual_seed(42)
print(f"\nDevice: {device}")
B = 8 # batch size
C_classes = 9 # NCT has 9 tissue type classes
# ── Test 1: Image privileged data (H&E + IHC stain) ──────────────────────
print(f"\n{'─'*50}")
print("Test 1: H&E + IHC privileged (ResNet18 backbone, VICReg)")
# Small backbone for speed in smoke test
class TinyEncoder(nn.Module):
def __init__(self):
super().__init__()
self.out_dim = 128
self.net = nn.Sequential(
nn.Conv2d(3, 32, 3, stride=2, padding=1), nn.ReLU(),
nn.AdaptiveAvgPool2d(1), nn.Flatten(),
nn.Linear(32, 128),
)
def forward(self, x): return self.net(x)
primary_enc = TinyEncoder().to(device)
priv_enc_img = TinyEncoder().to(device)
model_vicreg = TriDeNT(primary_enc, priv_enc_img, embed_dim=64, loss_type='vicreg').to(device)
opt = torch.optim.Adam(model_vicreg.parameters(), lr=3e-4)
x1 = torch.randn(B, 3, 64, 64, device=device)
x2 = torch.randn(B, 3, 64, 64, device=device)
x_ihc = torch.randn(B, 3, 64, 64, device=device)
opt.zero_grad()
out = model_vicreg(x1, x2, x_ihc)
out['loss'].backward()
opt.step()
print(ff" Total loss: {out['loss'].item():.4f}")
print(ff" Primary pair loss: {out['loss_12'].item():.4f}")
print(ff" Privileged pair loss: {out['loss_priv'].item():.4f}")
# ── Test 2: InfoNCE variant ───────────────────────────────────────────────
print(f"\n{'─'*50}")
print("Test 2: H&E + IHC privileged (InfoNCE)")
primary_enc2 = TinyEncoder().to(device)
priv_enc_img2 = TinyEncoder().to(device)
model_nce = TriDeNT(primary_enc2, priv_enc_img2, embed_dim=64, loss_type='infonce').to(device)
opt2 = torch.optim.Adam(model_nce.parameters(), lr=3e-4)
opt2.zero_grad()
out2 = model_nce(x1, x2, x_ihc)
out2['loss'].backward()
opt2.step()
print(ff" Total InfoNCE loss: {out2['loss'].item():.4f}")
# ── Test 3: Tabular privileged data (spatial transcriptomics) ────────────
print(f"\n{'─'*50}")
print("Test 3: H&E + Spatial Transcriptomics privileged (MLP encoder, VICReg)")
gene_dim = 500 # number of spatial transcriptomics genes
primary_enc3 = TinyEncoder().to(device)
priv_enc_st = MLPEncoder(gene_dim, [256, 128], 128).to(device)
model_st = TriDeNT(primary_enc3, priv_enc_st, embed_dim=64, loss_type='vicreg').to(device)
opt3 = torch.optim.Adam(model_st.parameters(), lr=3e-4)
x_gene = torch.randn(B, gene_dim, device=device)
opt3.zero_grad()
out3 = model_st(x1, x2, x_gene)
out3['loss'].backward()
opt3.step()
print(ff" Total loss (transcriptomics): {out3['loss'].item():.4f}")
# ── Test 4: Linear probe (downstream task evaluation) ────────────────────
print(f"\n{'─'*50}")
print("Test 4: Linear probe on frozen primary encoder")
probe = LinearProbe(primary_enc, C_classes).to(device)
x_eval = torch.randn(B, 3, 64, 64, device=device)
logits = probe(x_eval)
print(ff" Logit shape: {list(logits.shape)} (expected [{B}, {C_classes}])")
print(ff" Encoder grad frozen: {not list(probe.encoder.parameters())[0].requires_grad}")
print(f"\n{'─'*50}")
print("All smoke tests passed. TriDeNT forward and backward cycles OK.")
print("See Algorithm S1 in Farndale et al. (2025) for the full pseudocode.")
print("=" * 65)
if __name__ == '__main__':
_smoke_test()
Frequently Asked Questions
What is privileged information in the context of computational pathology?
Privileged information is data that is available during model training but not during deployment. In computational pathology this typically means additional staining techniques such as immunohistochemistry or immunofluorescence, or molecular data like spatial transcriptomics, which are paired with routine haematoxylin and eosin slides in research datasets but too expensive or impractical to acquire routinely in clinical settings.
Why do standard two-branch Siamese models fail when privileged data is uninformative?
Standard Siamese self-supervised models minimise the distance between representations of two inputs in a shared embedding space. Any feature that is not present in both inputs contributes nothing to the loss, so the model has no incentive to learn it. When the privileged stain contains very little information relevant to the downstream task, the shared embedding discards many useful primary features, producing representations that perform worse than a model trained on primary data alone.
How does TriDeNT fix this without sacrificing the benefit of the privileged signal?
TriDeNT adds a second primary branch that processes a different augmented view of the H&E patch using the same shared encoder. This creates a supervision signal from the primary data itself, so the encoder must learn features that are consistent across two different views of the H&E slide. The privileged branch adds a third signal for features that are weakly present in the H&E but strongly present in the paired data. The primary encoder balances both signals, learning both types of features simultaneously.
Can TriDeNT use non-image privileged data such as gene expression counts?
Yes. The privileged encoder can have any architecture, and the paper demonstrates this with spatial transcriptomics data processed by a multilayer perceptron. The gene expression count vector for each tissue patch is passed to the MLP encoder, and the resulting representation is used as the third branch in the TriDeNT loss. The primary encoder uses a convolutional neural network for the H&E images as usual.
What happens if the privileged data is completely irrelevant or randomised?
TriDeNT achieves performance comparable to the unprivileged baseline even when given blank or randomly shuffled privileged inputs. This is because the two primary branches continue to provide a useful supervision signal to each other, so the encoder learns good H&E representations regardless of whether the privileged branch contributes. Standard privileged Siamese models collapse to the worst performance in these scenarios.
Does TriDeNT require the privileged data to be spatially aligned with the H&E patches?
For image-based privileged data such as IHC stains, alignment is required and the paper uses registered patch pairs from the BCI and SegPath datasets. For spatial transcriptomics, the gene expression count is associated with the spatial location corresponding to the H&E patch. The method assumes that each primary patch has a corresponding privileged measurement, but the format and acquisition method of the privileged data can vary freely.
Read the Full Paper and Access the Code
The complete TriDeNT paper, including all supplementary tables, ablation studies, GradCAM visualisations, and UMAP projections, is available open access from Medical Image Analysis. The codebase is on GitHub.
Farndale, L., Insall, R., and Yuan, K. (2025). TriDeNT: Triple deep network training for privileged knowledge distillation in histopathology. Medical Image Analysis, 102, 103479. https://doi.org/10.1016/j.media.2025.103479. Published under CC BY 4.0.
This analysis is based on the published paper and an independent evaluation of its claims. This article is not medical advice and should not be used for clinical decision-making. All performance figures are drawn directly from the paper’s tables and figures — no statistics were modified or invented.
Explore More on AI Trend Blend
If this piece sparked your interest, here is more of what we cover — from medical imaging AI and self-supervised learning to adversarial robustness and federated learning privacy.