Picture a radiology department that wants an AI tool to outline kidneys on ultrasound scans. The best open segmentation model weighs hundreds of megabytes and was trained on everyday photos of cats, cars and coffee mugs. The department has eighty labelled scans. That gap, between what the giant model knows and what the clinic actually needs, is the problem a team from Shanghai Jiao Tong, Sun Yat-sen and HKUST set out to close.
Key points
- Task-specific knowledge distillation fine-tunes a vision foundation model on the target medical task first, then teaches a small student, rather than transferring generic features.
- LoRA adapts the Segment Anything teacher with very few trainable parameters, which keeps fine-tuning cheap and resists overfitting on tiny label sets.
- A Swin-transformer diffusion model generates synthetic scans to fill the transfer set when labelled data is scarce.
- A 33 MB ViT-Tiny student reached Dice scores close to, and on one dataset above, a teacher roughly ten times its size.
- The biggest gain landed on the hardest task, retinal vessel segmentation, at a 74.82 percent relative improvement over the baseline.
Their paper, posted to arXiv in March 2025, asks a question that sounds almost too practical for a research venue. How do you take the broad visual knowledge locked inside a Vision Foundation Model and pour it into a small, fast network that a hospital can actually run, when you barely have any labelled data to work with. The answer they land on reshuffles three familiar ideas into something that works surprisingly well together.
Most of us in the field have watched foundation models eat benchmark after benchmark. Segment Anything, DINOv2 and their cousins generalise beautifully because they were trained on oceans of data. Medical imaging rarely gets to enjoy that abundance. Annotating a single scan means paying a specialist to trace anatomy pixel by pixel, and the structures hide in noise, low contrast and biological variation. So the usual recipe of fine-tune the giant and deploy it falls apart twice over, once on cost and once on the domain gap between natural and medical images.
The question that actually matters
Knowledge distillation has a tidy origin story. Geoffrey Hinton and colleagues showed back in 2015 that a small student network could learn to mimic a large teacher and inherit much of its skill at a fraction of the size. The idea spread fast. Medical imaging researchers have used it to compress segmentation models for years.
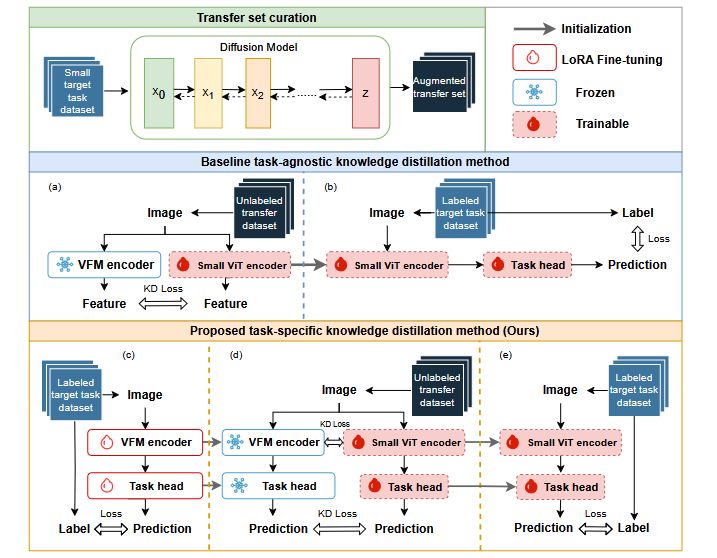
Here is the catch that the Shanghai group zeroes in on. Almost all of that prior work distills knowledge in a task-agnostic way. The teacher hands over generic feature representations, the kind that help with everything and specialise in nothing. For a task like tracing the faint border of a kidney medulla or following a retinal vessel one pixel wide, generic is not good enough. The student inherits a vague sense of the visual world when what it needs is a sharp sense of this exact anatomy.
So they flip the order. Instead of distilling a generic teacher and hoping the student figures out the medical part later, they first make the teacher an expert in the medical task, then distill. The teacher learns to segment kidneys before it ever tries to teach. That single reordering is the heart of the method, and the experiments suggest it carries most of the weight.
The core idea in one line
Specialise the teacher first, then teach. A foundation model fine-tuned on the target task transfers far more useful knowledge than the same model used straight off the shelf.
Building a teacher worth learning from
The teacher in this study is the Segment Anything Model, specifically its ViT-B backbone. Fine-tuning all of that on a few dozen scans would be both wasteful and a fast route to overfitting. This is where Low-Rank Adaptation earns its place. Rather than nudging every weight in the network, LoRA freezes the original model and injects two small matrices into each attention layer. Only those small matrices learn.
The trick rests on a simple observation about how much a model really needs to change to handle a new task. The update to a frozen weight matrix can be written as the product of two thin matrices, so the number of trainable parameters drops dramatically while the pretrained knowledge stays intact.
The rank \(r\) controls how much capacity the adaptation gets. The authors apply LoRA only to the query and value projections inside each transformer block, train with the AdamW optimiser at a learning rate of 0.005, and supervise with a blend of cross-entropy and Dice loss weighted at 0.2 and 0.8. That weighting leans hard on Dice, which makes sense for segmentation where overlap quality matters more than per pixel classification.
One of the quieter findings in the paper is that the right LoRA rank changes with the task. Simple structures want a small rank and intricate ones want more. Autooral ulcer segmentation peaked at rank 2, kidney ultrasound at rank 4, the abdominal CHAOS dataset at rank 16. The team picked the smallest rank that stayed competitive, which keeps the teacher cheap to adapt and, as a bonus, restrains how much it can overfit to a handful of labels.
Two channels of knowledge, not one
Once the teacher knows the task, the distillation begins. The student is a ViT-Tiny with a Feature Pyramid Network head, a model small enough to deploy on modest hardware. What sets this approach apart from ordinary feature distillation is that knowledge flows along two channels at once.
The first channel aligns the encoders. The student is pushed to produce hidden representations that match the teacher’s, so it learns to see the image the way an expert does. The loss is a plain mean squared error over the feature maps.
The second channel aligns the decoders. The teacher’s predicted segmentation logits become a target for the student’s own output, which transfers the task-specific part of the knowledge, the part that says where the boundary really sits.
That second encoder-to-decoder pairing is doing something subtle. Task-agnostic distillation usually matches only features and leaves the prediction layer to fend for itself. By matching predictions too, the student gets a direct view of the decisions the expert teacher makes, not just the features it computes. The ablation study backs this up. Dropping the hidden-state loss and relying on prediction matching alone gave weaker boundaries, and the best configuration kept both losses with the spatial term turned up.
Where the training data comes from when you have almost none
Distillation needs a transfer set, a pool of images the teacher and student can talk over. In a data-starved setting that pool is exactly what is missing. The team’s answer is to grow one with a Swin-transformer-based diffusion model.
Starting from a small labelled set expanded with rotations, scaling and affine transforms, they train the diffusion model to generate fresh synthetic scans. The forward process slowly buries an image in Gaussian noise and the reverse process learns to climb back out, producing new images that look like the real thing.
How good is the synthetic data. Measured against the originals, the generated images held a peak signal-to-noise ratio around 27 to 28 decibels with low reconstruction error across every dataset, from ultrasound to retinal fundus to dermoscopy. The consistency is the interesting part. The diffusion model did not favour one modality, which means the same data-generation step can serve very different segmentation tasks without retuning.
The math behind why a specialised teacher helps
The authors do not just show that their method works, they argue why it should. The reasoning leans on two well worn tools, PAC learning theory and information theory, and the conclusion is intuitive once you sit with it.
When a teacher has already been fine-tuned for the task, the student is searching a smaller, more relevant space of possible solutions. A smaller hypothesis space carries a lower VC dimension, and the generalisation bound tightens as that complexity drops.
The information-theoretic half makes a parallel point. A generic teacher produces fuzzier outputs, which means its predictions carry less information about the true label. A task-specific teacher sharpens those outputs, so the mutual information between teacher and label rises and the student gets a clearer signal to learn from.
None of this is a hard proof that the method beats every alternative on every dataset. It is a clean explanation for the pattern they observe, and it lines up with the experiments rather than standing apart from them.
What the experiments actually show
The team ran their method against five datasets that span very different challenges. KidneyUS for noisy ultrasound, Autooral for ulcers in the mouth, CHAOS for multi-organ abdominal MRI, PH2 for skin lesions and DRIVE for the hair-thin vessels of the retina. They compared task-specific distillation against training from scratch, ImageNet pretraining with masked autoencoders, self-supervised MoCo v3, self-supervised MAE on the transfer set, and ordinary task-agnostic distillation.
The standout number comes from the hardest task. On DRIVE retinal vessel segmentation, where a from-scratch small model barely functions, task-specific distillation delivered a 74.82 percent relative improvement in Dice score over the baseline. Vessels are exactly the kind of fine structure where generic features collapse and expert guidance pays off.
| Dataset | Task | Best mean Dice (TS-KD) | Relative gain |
|---|---|---|---|
| DRIVE | Retinal vessels | 0.5741 | +74.82% |
| KidneyUS | Kidney ultrasound | 0.6139 | +13.59% |
| CHAOS | Abdominal organs (MRI) | 0.8663 | +6.76% |
| PH2 | Skin lesions | 0.9455 | +3.05% |
| Autooral | Oral ulcers | 0.5754 | +28.72% |
Two things stand out beyond the headline. First, the advantage grows as labelled data shrinks, which is the whole point in medical imaging. With only eighty labelled kidney scans, task-specific distillation beat task-agnostic distillation by a wide margin. Second, the method scales gracefully with the size of the synthetic transfer set, climbing steadily as the pool grew from one thousand to three thousand images while rival methods flattened out earlier.
There is an honest wrinkle worth flagging. On PH2 skin lesions, ordinary task-agnostic distillation actually hurt performance slightly compared to training from scratch, dipping by about 1.7 percent, while the task-specific version still gained. That contrast is a neat little argument for the paper’s thesis all by itself.
A 33 megabyte model that mostly keeps up
The deployment story is where this gets exciting for anyone who has tried to put a model on real clinical hardware. The ViT-Tiny student weighs about 33 megabytes against the teacher’s 357. On CHAOS the tiny student actually edged past its LoRA-tuned teacher, scoring 0.6912 to 0.6799, and on PH2 the two were nearly identical. A model a tenth of the size, holding its own.
The compression does have limits, and the authors do not hide them. On Autooral and DRIVE, where structures are most intricate, the small student trailed the larger teacher by a real margin. The teacher’s extra capacity buys accuracy that the student cannot fully replicate. That tradeoff is the kind of thing a deployment team needs to weigh rather than wish away.
What this unlocks in practice
A hospital can take an open foundation model it could never deploy, specialise it on a small private dataset, and compress that expertise into a model that runs on ordinary hardware. The expensive part happens once, offline, and the cheap part ships to the clinic.
“Specialise the teacher before it ever opens its mouth, and the small student inherits judgement rather than vocabulary.”
aitrendblend editorial reading of Liang et al., 2025
Where it gets complicated
Synthetic data is a double-edged tool. The diffusion images looked statistically close to the originals, but a generative model can quietly bake in the same biases it learned, and those biases may not survive contact with messy real clinics, with new scanners and unfamiliar patient populations. The authors say as much and call for validation on broader real-world cohorts.
Compute is another honest cost. Task-specific distillation took longer to pre-train than the lighter self-supervised baselines because of the extra teaching step, roughly sixteen hours on the kidney and skin tasks. It still came in far cheaper than the twenty-three hour ImageNet pretraining route, so the picture is favourable rather than free.
And the method, as tested, handles one segmentation task per teacher. Real clinical work is rarely so tidy. Extending this to multi-class and multi-task settings, where one model must juggle several structures at once, is the obvious and genuinely hard next step.
Complete Proposed Model Code (PyTorch)
The implementation below captures the moving parts of the framework in a single runnable file. It defines a LoRA wrapper for attention projections, a compact teacher and a ViT-Tiny student, the dual-level distillation losses, the combined cross-entropy and Dice objective for fine-tuning, a distillation training loop and a Dice evaluator. The teacher here stands in for SAM so the script runs end to end on dummy data. Swap in a real SAM backbone for production work. Run the smoke test to confirm everything wires together.
# ─── Task-Specific Knowledge Distillation for Medical Segmentation ───
# Minimal, runnable reference implementation. Teacher stands in for SAM.
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
# ─── 1. LoRA adapter for a linear projection ───
class LoRALinear(nn.Module):
"""Wraps a frozen Linear layer and adds a trainable low-rank update.
The base weight stays frozen. Only A and B learn, giving the
W = W0 + A @ B update from the paper with rank r much smaller than d.
"""
def __init__(self, base: nn.Linear, rank: int = 4, alpha: float = 1.0):
super().__init__()
self.base = base
for p in self.base.parameters():
p.requires_grad = False
d_out, d_in = base.weight.shape
self.rank = rank
self.scale = alpha / rank
self.A = nn.Parameter(torch.zeros(rank, d_in))
self.B = nn.Parameter(torch.zeros(d_out, rank))
nn.init.normal_(self.A, std=0.02) # B stays zero so training starts from W0
def forward(self, x):
return self.base(x) + self.scale * (x @ self.A.t() @ self.B.t())
# ─── 2. A tiny transformer encoder block (teacher and student share it) ───
class Block(nn.Module):
"""Standard pre-norm transformer block with multi-head self attention."""
def __init__(self, dim: int, heads: int = 4, mlp_ratio: float = 4.0):
super().__init__()
self.norm1 = nn.LayerNorm(dim)
self.q = nn.Linear(dim, dim)
self.k = nn.Linear(dim, dim)
self.v = nn.Linear(dim, dim)
self.proj = nn.Linear(dim, dim)
self.heads = heads
self.norm2 = nn.LayerNorm(dim)
hidden = int(dim * mlp_ratio)
self.mlp = nn.Sequential(nn.Linear(dim, hidden), nn.GELU(), nn.Linear(hidden, dim))
def attn(self, x):
B, N, C = x.shape
h = self.heads
q = self.q(x).reshape(B, N, h, C // h).transpose(1, 2)
k = self.k(x).reshape(B, N, h, C // h).transpose(1, 2)
v = self.v(x).reshape(B, N, h, C // h).transpose(1, 2)
att = (q @ k.transpose(-2, -1)) / math.sqrt(C // h)
att = att.softmax(dim=-1)
out = (att @ v).transpose(1, 2).reshape(B, N, C)
return self.proj(out)
def forward(self, x):
x = x + self.attn(self.norm1(x))
x = x + self.mlp(self.norm2(x))
return x
# ─── 3. Encoder plus a lightweight segmentation head ───
class SegViT(nn.Module):
"""Patch embed, transformer encoder, and an upsampling seg head.
Returns both the final feature map and the segmentation logits so the
distillation loop can align hidden states and predictions together.
"""
def __init__(self, dim=192, depth=4, heads=4, patch=16, img=128, num_classes=2):
super().__init__()
self.grid = img // patch
self.patch_embed = nn.Conv2d(3, dim, kernel_size=patch, stride=patch)
self.pos = nn.Parameter(torch.zeros(1, self.grid * self.grid, dim))
nn.init.normal_(self.pos, std=0.02)
self.blocks = nn.ModuleList([Block(dim, heads) for _ in range(depth)])
self.dim = dim
self.head = nn.Sequential(
nn.Conv2d(dim, dim // 2, 3, padding=1), nn.GELU(),
nn.Conv2d(dim // 2, num_classes, 1),
)
self.img = img
def forward(self, x):
B = x.shape[0]
t = self.patch_embed(x).flatten(2).transpose(1, 2) + self.pos
for blk in self.blocks:
t = blk(t)
feat = t.transpose(1, 2).reshape(B, self.dim, self.grid, self.grid)
logits = self.head(feat)
logits = F.interpolate(logits, size=(self.img, self.img), mode="bilinear", align_corners=False)
return feat, logits
# ─── 4. Inject LoRA into every q and v projection of a model ───
def add_lora(model: nn.Module, rank: int = 4):
"""Replace q and v linear layers in each Block with LoRA wrappers."""
for blk in model.blocks:
blk.q = LoRALinear(blk.q, rank=rank)
blk.v = LoRALinear(blk.v, rank=rank)
return model
# ─── 5. Loss functions ───
def dice_loss(logits, target, eps=1e-6):
"""Soft Dice loss over the foreground probability."""
prob = logits.softmax(dim=1)[:, 1]
t = (target == 1).float()
inter = (prob * t).sum(dim=(1, 2))
union = prob.sum(dim=(1, 2)) + t.sum(dim=(1, 2))
return (1 - (2 * inter + eps) / (union + eps)).mean()
def supervised_loss(logits, target, l1=0.2, l2=0.8):
"""Combined cross-entropy and Dice, matching the paper's 0.2 / 0.8 split."""
return l1 * F.cross_entropy(logits, target) + l2 * dice_loss(logits, target)
def distill_loss(s_feat, s_logits, t_feat, t_logits, w_enc=1.0, w_dec=0.2):
"""Dual-level distillation. Encoder MSE on features, decoder MSE on logits."""
enc = F.mse_loss(s_feat, t_feat)
dec = F.mse_loss(s_logits, t_logits)
return w_enc * enc + w_dec * dec, enc.item(), dec.item()
# ─── 6. Distillation training loop ───
def distill(teacher, student, transfer_loader, epochs=1, lr=1.5e-4, device="cpu"):
"""Teacher is frozen and in eval mode. Only the student updates."""
teacher.eval()
for p in teacher.parameters():
p.requires_grad = False
opt = torch.optim.Adam(student.parameters(), lr=lr, weight_decay=0.05)
student.train()
for ep in range(epochs):
for images in transfer_loader:
images = images.to(device)
with torch.no_grad():
t_feat, t_logits = teacher(images)
s_feat, s_logits = student(images)
loss, enc, dec = distill_loss(s_feat, s_logits, t_feat, t_logits)
opt.zero_grad()
loss.backward()
opt.step()
print(f"[distill] epoch {ep} enc {enc:.4f} dec {dec:.4f}")
return student
# ─── 7. Dice evaluation ───
def dice_score(model, loader, device="cpu"):
"""Mean foreground Dice over a labelled loader."""
model.eval()
scores = []
with torch.no_grad():
for images, masks in loader:
images, masks = images.to(device), masks.to(device)
_, logits = model(images)
pred = logits.argmax(dim=1)
inter = ((pred == 1) & (masks == 1)).sum().float()
denom = (pred == 1).sum().float() + (masks == 1).sum().float()
scores.append((2 * inter / (denom + 1e-6)).item())
return sum(scores) / max(len(scores), 1)
# ─── 8. Smoke test on dummy data ───
def _smoke_test():
"""Wires teacher, LoRA, student and the loops together on random tensors."""
device = "cuda" if torch.cuda.is_available() else "cpu"
img = 128
teacher = SegViT(dim=256, depth=6, img=img).to(device) # stands in for SAM
teacher = add_lora(teacher, rank=4).to(device) # LoRA fine-tune target
student = SegViT(dim=96, depth=3, img=img).to(device) # ViT-Tiny style student
transfer = [torch.randn(2, 3, img, img) for _ in range(3)] # synthetic set
labelled = [(torch.randn(2, 3, img, img),
torch.randint(0, 2, (2, img, img))) for _ in range(2)]
distill(teacher, student, transfer, epochs=1, device=device)
score = dice_score(student, labelled, device=device)
print(f"[smoke] student dice on dummy data: {score:.4f}")
print("[smoke] all components ran end to end.")
if __name__ == "__main__":
_smoke_test()
What this means going forward
The achievement here is quieter than a new state-of-the-art leaderboard entry, and arguably more useful. By fine-tuning a foundation model on a task before distilling it, the team turned the foundation model from an expensive curiosity into a practical teacher, and they did it with a recipe any reasonably equipped lab can follow. The 33 megabyte student that keeps pace with a teacher ten times its size is the kind of result that changes what is deployable rather than what is possible.
There is a conceptual shift tucked inside the engineering. For years the instinct in transfer learning was to grab the most general representation available and adapt it downstream. This work argues the opposite for narrow, high-stakes tasks. Specialise early, then compress. Generality is a starting point, not the prize. That reframing travels well beyond kidneys and retinas.
It travels, in fact, to almost any field where a giant pretrained model meets a small specialised dataset. Industrial inspection, satellite imagery, microscopy and document analysis all share the same shape of problem, a powerful generalist and a scarcity of labels. The three-part pattern of specialise with LoRA, generate data with diffusion, then distill along two channels is not married to medicine.
The honest limitations keep the enthusiasm grounded. Synthetic data can mislead, the small student still buckles on the most intricate structures, and a one-task-per-teacher setup will not survive contact with a busy clinical pipeline that needs many structures at once. These are not fatal flaws. They are the next papers.
If there is a single lesson to carry out of this study, it is that knowledge transfers best when it is shaped for the destination before it leaves the source. A teacher who has actually done the job teaches a better lesson than one who merely knows a great deal. That is true of neural networks, and it has always been true of people.
Read the Source and the Datasets
The full paper covers every ablation, all five datasets, the LoRA rank sweeps and the diffusion data evaluation in detail. Each dataset used in the study is publicly available for your own experiments.
Liang, P., Huang, H., Pu, B., Chen, J., Hua, X., Zhang, J., Ma, W., Chen, Z., Li, Y., and Chang, Q. (2025). Task-Specific Knowledge Distillation from the Vision Foundation Model for Enhanced Medical Image Segmentation. arXiv preprint arXiv:2503.06976.
This article is an independent editorial analysis of publicly available research. The interpretation is our own and does not represent the original authors. Figures referenced describe the source paper. The code shown is a simplified educational reference rather than the authors’ official implementation.
Frequently asked questions
What is task-specific knowledge distillation in medical image segmentation
It is a training approach where a large vision foundation model is first fine-tuned on the exact medical segmentation task, and only then used as a teacher to train a small student model. Because the teacher already understands the target anatomy, the knowledge it passes down is far more useful than the generic features transferred by ordinary distillation.
How is it different from task-agnostic knowledge distillation
Task-agnostic distillation hands over general purpose features from an unmodified teacher and hopes the student learns the medical part later. Task-specific distillation reverses that order by specialising the teacher first, which narrows what the student has to learn and produces sharper boundaries on fine structures like vessels.
Why use LoRA to fine-tune the Segment Anything Model
Full fine-tuning of a foundation model on a few dozen scans is wasteful and overfits quickly. LoRA freezes the original weights and trains only two small low-rank matrices per attention layer, so adaptation stays cheap and the model keeps its broad pretrained knowledge.
How do diffusion models help when labelled data is scarce
A diffusion model trained on a small augmented set generates new synthetic scans that look statistically close to the originals. These synthetic images enlarge the transfer set used during distillation, which gives the student more material to learn from without needing more expensive annotations.
Can a small ViT-Tiny model really match a large foundation model
On several tasks, yes. The 33 MB student matched its much larger teacher on skin lesions and even edged ahead on abdominal organs. On the most intricate tasks, retinal vessels and oral ulcers, the larger model still held a clear advantage, so the tradeoff depends on how fine the target structures are.
Which datasets and results back up the method
The study evaluated five public datasets, KidneyUS, Autooral, CHAOS, PH2 and DRIVE, covering ultrasound, oral cavity, abdominal MRI, dermoscopy and retinal fundus images. Task-specific distillation led on all five, with relative Dice gains ranging from about 3 percent on skin lesions up to 74.82 percent on retinal vessels.