How to Build Multi-Agent Systems with Claude Opus 4.7 & Gemini Flash 3.5
How to Build Multi-Agent Systems
with Claude Opus 4.7 & Gemini Flash 3.5
aitrendblend.com — 2026 Technical Guide
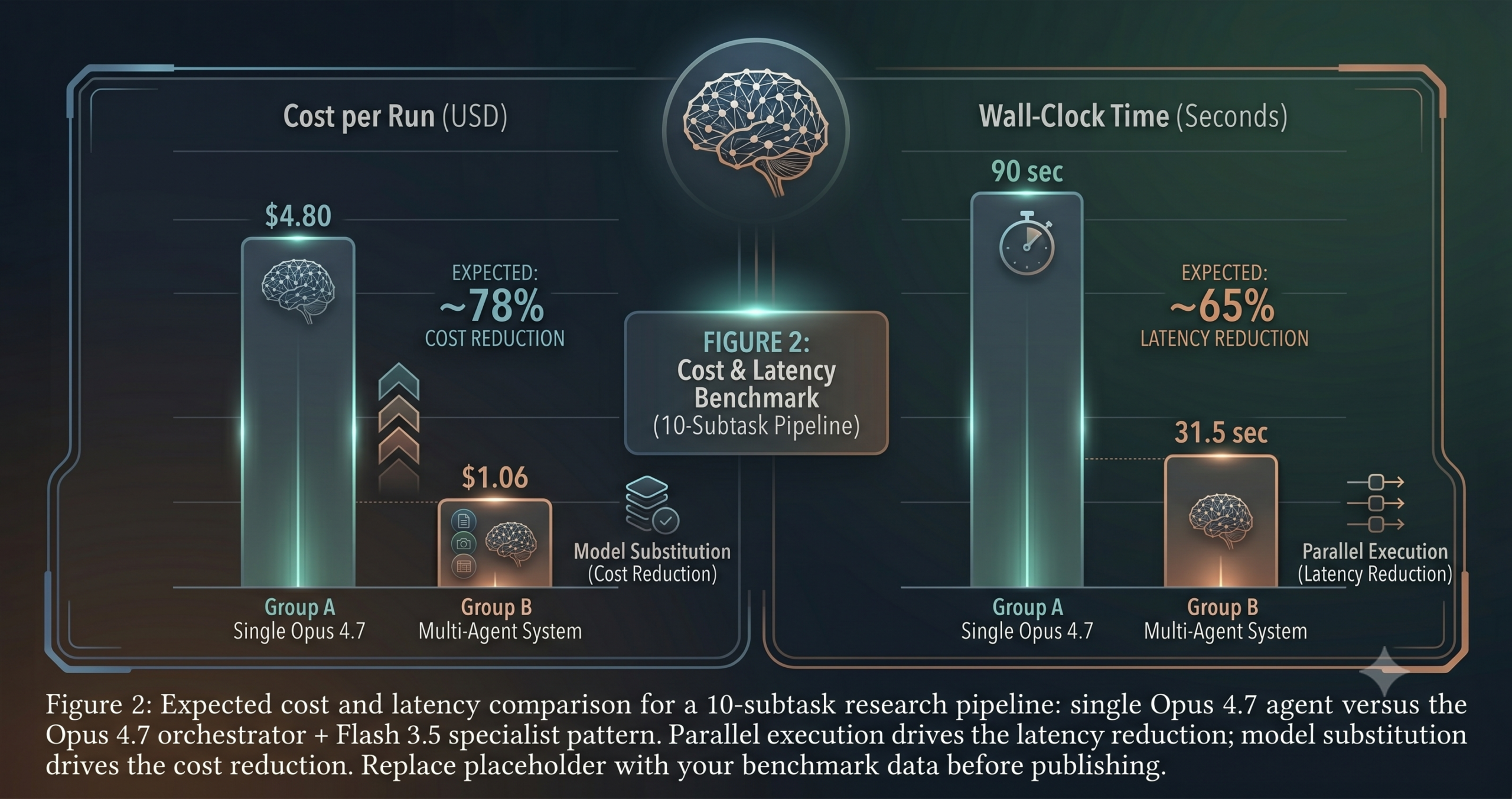
You are building a research pipeline that needs to search the web, process a dozen PDFs, extract structured data from tables, and produce a cited written report. You set it up as a single Claude Opus 4.7 agent. The quality is excellent. The cost is $4.80 per run and each run takes 90 seconds. You need to run it 500 times a month. The economics stop working before the product ships.
Multi-agent systems solve a specific version of this problem. Instead of one powerful model doing everything, you split the work: a smart orchestrator handles planning and synthesis while a fleet of faster, cheaper specialist agents handles high-volume execution. Done right, this cuts cost-per-run dramatically, reduces latency through parallelism, and lets each model do the work it is genuinely optimized for — not the work that happens to fit within a single context window.
This guide walks through building that system using Claude Opus 4.7 as the orchestrator and Gemini Flash 3.5 as the specialist agents. These are not arbitrary choices. The pairing is deliberate, and the reasons behind it directly shape how the architecture is structured. By the end you will have a working blueprint: five prompt templates, five implementation steps with real Python code, a routing pattern that handles parallel execution, and an honest picture of where this architecture earns its complexity and where it does not.
Why Claude Opus 4.7 and Gemini Flash 3.5 Make a Strong Pair
The pairing is about complementary strengths, not brand loyalty. Opus 4.7 is the right orchestrator for complex multi-step planning tasks because it produces the most coherent multi-step reasoning of any currently available model — and because its 200,000-token context window can hold an entire pipeline’s worth of intermediate results without losing the thread. Extended thinking mode lets it spend additional compute on genuinely hard planning decisions before committing to a routing strategy.
Gemini Flash 3.5 is the right specialist model for a different set of reasons. It returns results in under two seconds on most tasks. Its per-token cost is a fraction of Opus 4.7’s, which means calling it ten times per pipeline run is still cheaper than calling Opus once for the same tasks. It has native Google Search grounding — real-time web retrieval, not retrieval from training data. Its native multimodal handling of images, audio, video, and documents means the same model that processes text can also process a scanned invoice or a chart without a separate vision API call.
The cost math is the clearest argument. A typical pipeline that calls Opus twice (to plan and synthesize) and Flash ten times (to research, extract, and analyze) costs roughly 80% less than running Opus for all twelve steps — with equivalent or better output quality, because each model is doing the work it is actually optimized for. That is not a small margin. At production scale, it is the difference between a viable product and one that cannot grow.
Claude Opus 4.7
- Best-in-class complex reasoning
- 200k token context window
- Extended thinking mode for hard decisions
- Reliable instruction-following at scale
- Consistent structured output (JSON)
- Use for: planning, routing, synthesis, QA
Gemini Flash 3.5
- Sub-2-second response on most tasks
- Lowest cost-per-token in its class
- Native Google Search grounding
- True multimodal: text, image, audio, video
- 1M token context for document-heavy tasks
- Use for: research, extraction, analysis, summarization
The Cost Principle
Route every task to the cheapest model that can do it well. Opus 4.7 should only be called when the task requires complex multi-step reasoning, synthesis of conflicting information, or high-stakes quality judgment. Everything else goes to Flash 3.5.
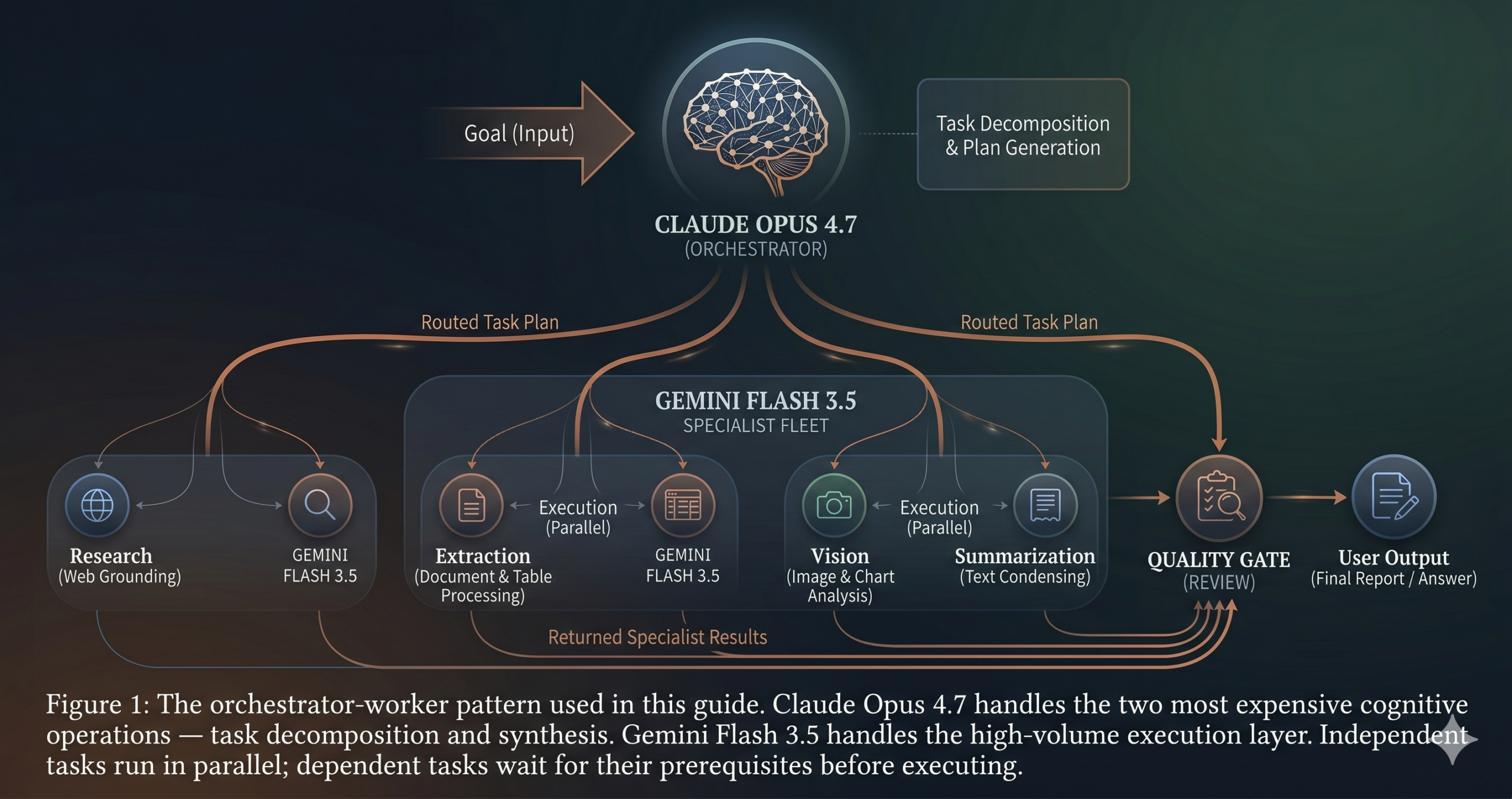
Understanding the Multi-Agent Architecture
The pattern used throughout this guide is the orchestrator-worker model. A single orchestrator agent — running on Opus 4.7 — receives the top-level goal, breaks it into subtasks, routes each subtask to the appropriate specialist worker, collects the results, and synthesizes a final output. Workers run on Flash 3.5 and have no awareness of each other. They receive a specific input, execute a specific task, and return a structured output. That is the entire scope of a worker’s responsibility.
This pattern is not the only way to build multi-agent systems. Peer-to-peer networks, where agents communicate directly with each other, and hierarchical trees, where sub-orchestrators manage groups of workers, are both viable for certain problems. The orchestrator-worker model is the right starting point because it is the most debuggable. Every decision — what tasks to create, how to route them, how to synthesize results — traces back to a single orchestrator whose reasoning you can inspect in logs. When something goes wrong, you know exactly where to look.
State management is the piece most architectural guides skip. Every agent run needs a shared state object — a dictionary or database record — that tracks what has been planned, what has been completed, and what each specialist returned. Without shared state, two specialists may work on the same subtask in parallel, or the orchestrator may synthesize a result that contradicts information already collected in a previous step. The state object is the source of truth for the entire pipeline.
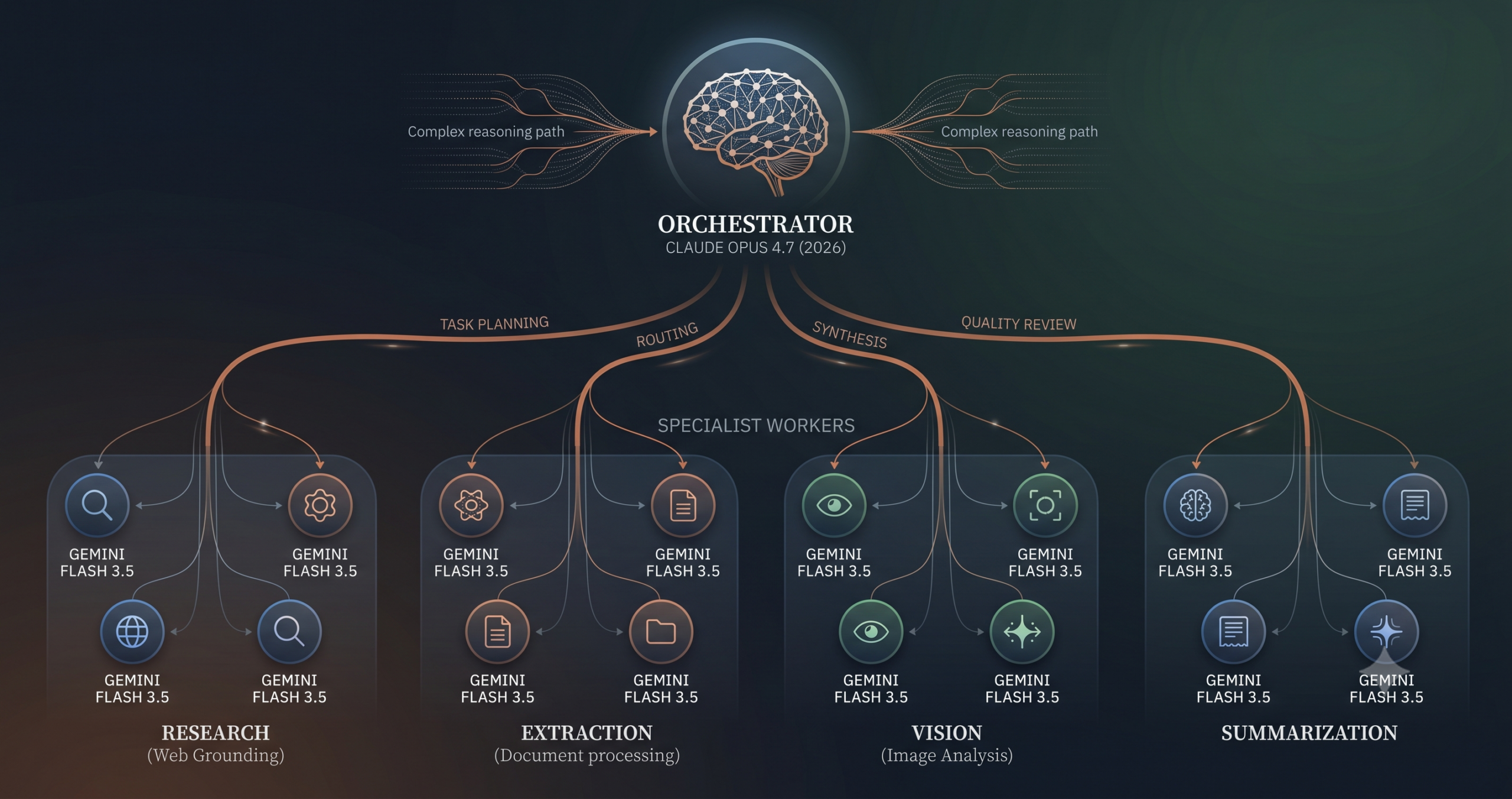
The 4 Essential Roles in the System
Before writing a line of code, every role in the system needs a clear definition. The most common architecture mistake is role bleed — an orchestrator that starts doing execution work, or specialists that start making routing decisions. Each role should have a single, well-defined responsibility that it does not exceed.
Orchestrator
Claude Opus 4.7Receives the top-level goal. Decomposes it into discrete subtasks. Determines which specialist handles each subtask and in what order. After specialists complete their work, synthesizes all results into a coherent final output. The orchestrator should never execute a subtask itself — only plan and synthesize.
Specialist Agents
Gemini Flash 3.5Narrow-scope executors. Each one has a single job: search the web, extract structured data, analyze an image, summarize a document set. Specialists receive a focused input and return a structured JSON output. They do not communicate with other specialists and have no awareness of the broader task context.
State Manager
Python dict / DatabaseNot a model — a data structure. Holds the shared state for an entire pipeline run: the task plan, completed task IDs, specialist outputs, and any flags or errors. Every agent reads from and writes to state. It is the single source of truth that prevents duplicated work and ensures the orchestrator always has an accurate picture of progress.
Quality Gate
Claude Sonnet 4.6 or Opus 4.7Reviews the synthesized output before it reaches the user. Checks for format compliance, factual gaps, internal contradictions, and missing citations. Use Sonnet 4.6 for most pipelines — it is fast and cost-efficient for review tasks. Escalate to Opus 4.7 only for high-stakes outputs where review quality must match generation quality.
Building the System: 5 Implementation Steps
The steps below move from environment setup through a complete, runnable pipeline. Each step includes the key code and the decision logic behind it. Adapt the specific model parameters and API calls to match the current SDK versions in Anthropic’s and Google’s documentation — model names and client interfaces evolve faster than articles do.
Install SDKs and Initialize Both Clients
Both the Anthropic and Google Generative AI SDKs need to be installed and configured before anything else. Keep API keys in environment variables — never hardcoded. The ThreadPoolExecutor import is needed for the parallel execution pattern in Step 4.
# pip install anthropic google-generativeai import anthropic import google.generativeai as genai import json, os from concurrent.futures import ThreadPoolExecutor, as_completed from dataclasses import dataclass, field from typing import Any # Initialize Claude client (Anthropic) claude = anthropic.Anthropic( api_key=os.environ["ANTHROPIC_API_KEY"] ) # Initialize Gemini client (Google) genai.configure(api_key=os.environ["GOOGLE_API_KEY"]) # Shared pipeline state — one instance per pipeline run @dataclass class PipelineState: goal: str task_plan: list = field(default_factory=list) results: dict = field(default_factory=dict) errors: dict = field(default_factory=dict) completed: set = field(default_factory=set)
Build the Orchestrator with Claude Opus 4.7
The orchestrator does two things: it produces a task plan from the top-level goal, and it synthesizes specialist results into a final output. Both use Opus 4.7. The task plan must be valid JSON — the pipeline depends on it to route tasks correctly. Wrap the JSON parse in a try/except and retry once before failing; Opus 4.7 very rarely produces malformed JSON but it does happen under unusual inputs.
def plan_tasks(state: PipelineState) -> list[dict]: """Opus 4.7 decomposes the goal into a structured task list.""" response = claude.messages.create( model="claude-opus-4-7", max_tokens=4096, system=ORCHESTRATOR_SYSTEM_PROMPT, messages=[{ "role": "user", "content": ( f"Goal: {state.goal}\n\n" "Return a JSON array of subtasks. Each subtask must have:\n" " id (string), type (string), params (object),\n" " depends_on (array of ids, empty if independent)\n" "Return ONLY the JSON array — no explanation." ) }] ) tasks = json.loads(response.content[0].text) state.task_plan = tasks return tasks def synthesize(state: PipelineState, instructions: str) -> str: """Opus 4.7 combines all specialist results into a final output.""" response = claude.messages.create( model="claude-opus-4-7", max_tokens=8192, messages=[{ "role": "user", "content": SYNTHESIS_PROMPT.format( instructions=instructions, results=json.dumps(state.results, indent=2) ) }] ) return response.content[0].text
Configure Gemini Flash 3.5 Specialist Agents
Each specialist is a function that wraps a Gemini Flash 3.5 call with a narrow system prompt. The research specialist enables Google Search grounding — this is the key feature that makes Flash genuinely useful for real-time research rather than just fast inference on training data. Keep specialist system prompts short and focused: one job, one output schema, no ambiguity.
# Research specialist — web grounding enabled _research_model = genai.GenerativeModel( model_name="gemini-3.5-flash", # verify name in Google AI docs system_instruction=RESEARCH_SPECIALIST_PROMPT, tools=["google_search"] # real-time web grounding ) def research_specialist(query: str, num_sources: int = 5) -> dict: response = _research_model.generate_content( f"Research: {query}\nReturn {num_sources} authoritative sources." ) return json.loads(_clean_json(response.text)) # Extraction specialist — structured data from documents _extract_model = genai.GenerativeModel( model_name="gemini-3.5-flash", system_instruction=EXTRACTION_SPECIALIST_PROMPT ) def extraction_specialist(document: str, schema: dict) -> dict: response = _extract_model.generate_content( f"Extract data matching this schema:\n{json.dumps(schema)}" f"\n\nDocument:\n{document}" ) return json.loads(_clean_json(response.text)) # Vision specialist — image / chart analysis (multimodal) def vision_specialist(image_bytes: bytes, question: str) -> dict: model = genai.GenerativeModel("gemini-3.5-flash") image_part = {"mime_type": "image/png", "data": image_bytes} response = model.generate_content([image_part, question]) return {"analysis": response.text} # Route task type to the correct specialist function SPECIALISTS = { "research": research_specialist, "extraction": extraction_specialist, "vision": vision_specialist, }
Route Tasks and Execute in Parallel
Independent tasks — those with no depends_on entries — run in parallel using a thread pool. Dependent tasks run sequentially after their prerequisites complete. This is where most of the latency savings come from: ten research subtasks that previously ran one after another now run simultaneously, cutting wall-clock time by 80% or more depending on how many independent tasks the orchestrator produced.
def execute_tasks(tasks: list[dict], state: PipelineState) -> None: """Route and execute all tasks; update state with results.""" independent = [t for t in tasks if not t.get("depends_on")] dependent = [t for t in tasks if t.get("depends_on")] # Run independent tasks in parallel with ThreadPoolExecutor(max_workers=min(len(independent), 8)) as pool: future_map = { pool.submit( SPECIALISTS[t["type"]], **t["params"] ): t for t in independent if t["type"] in SPECIALISTS } for future in as_completed(future_map): task = future_map[future] try: state.results[task["id"]] = future.result() state.completed.add(task["id"]) except Exception as e: state.errors[task["id"]] = str(e) # Run dependent tasks after their prerequisites for task in dependent: if all(dep in state.completed for dep in task["depends_on"]): dep_context = { d: state.results[d] for d in task["depends_on"] } try: state.results[task["id"]] = SPECIALISTS[task["type"]]( **task["params"], dependencies=dep_context ) state.completed.add(task["id"]) except Exception as e: state.errors[task["id"]] = str(e)
Run the Full Pipeline End to End
The run_pipeline function ties every component together. Notice that the quality gate runs after synthesis — it adds one model call but catches format violations and factual gaps that Opus occasionally misses when synthesizing large volumes of specialist output. The function returns both the final output and the full state object, which is your audit trail for debugging.
def quality_gate(output: str, criteria: str) -> dict: """Sonnet 4.6 validates the synthesized output before delivery.""" response = claude.messages.create( model="claude-sonnet-4-6", max_tokens=1024, messages=[{ "role": "user", "content": QUALITY_GATE_PROMPT.format( output=output, criteria=criteria ) }] ) return json.loads(_clean_json(response.content[0].text)) # Returns: {"passed": bool, "issues": [...], "revised_output": "..."} def run_pipeline(goal: str, quality_criteria: str = "") -> dict: """ Full pipeline: Plan → Execute → Synthesize → Quality Gate. Returns the final output and full state for audit. """ state = PipelineState(goal=goal) # Step 1 — Opus 4.7 plans the task list tasks = plan_tasks(state) print(f"Planned {len(tasks)} subtasks") # Step 2 — Flash 3.5 specialists execute in parallel execute_tasks(tasks, state) print(f"Completed {len(state.completed)}/{len(tasks)} tasks") # Step 3 — Opus 4.7 synthesizes all results synthesis = synthesize(state, instructions=quality_criteria) # Step 4 — Sonnet 4.6 quality gate qg = quality_gate(synthesis, quality_criteria) final_output = qg.get("revised_output", synthesis) \ if not qg["passed"] else synthesis return {"output": final_output, "state": state, "qg_report": qg}
The 5 Prompt Templates That Power the System
The code above is the skeleton. These prompts are the muscle — they determine what each model actually does when called. Each prompt is written specifically for its model and its role. The Opus prompts prioritize structured output and clear reasoning. The Flash prompts are narrow, fast, and explicit about the schema they must return.
Prompt 1: The Orchestrator System Prompt (Claude Opus 4.7)
This goes in ORCHESTRATOR_SYSTEM_PROMPT. It defines Opus’s planning role, the task schema it must produce, and the routing rules it uses to assign task types. Keep this tight — the user turn carries the actual goal.
You are an orchestration agent. Your job is to decompose a complex goal into a precise list of subtasks, each assigned to the correct specialist. AVAILABLE SPECIALISTS - "research" → web search + source synthesis (Gemini Flash 3.5 + Google Search) - "extraction" → structured data extraction from documents - "vision" → image, chart, or PDF visual analysis - "summarize" → condense a large body of text into key points TASK PLANNING RULES 1. Decompose aggressively — prefer many small, focused tasks over few large ones 2. Mark tasks as independent (depends_on: []) when they can run in parallel 3. Only create a dependency when Task B genuinely requires Task A's output 4. Each task must have a single, unambiguous objective 5. Every task "params" object must contain all inputs the specialist needs OUTPUT FORMAT Return ONLY a valid JSON array. No explanation, no markdown, no preamble. Each task object: { "id": "task_01", "type": "research | extraction | vision | summarize", "description": "one sentence describing what this task produces", "params": { ...all inputs the specialist function needs }, "depends_on": [] } # Do not attempt to execute tasks. Planning only. # Do not invent specialist types. Use only the four listed above.
Prompt 2: The Research Specialist (Gemini Flash 3.5)
This goes in RESEARCH_SPECIALIST_PROMPT. Its job is web research with real source grounding. The JSON output schema is non-negotiable — the orchestrator’s synthesis step depends on receiving data in this exact structure.
You are a research specialist with access to Google Search. For each research request: 1. Search for the most relevant, recent, and authoritative sources 2. Discard sources older than [DATE_CUTOFF] or from unverified publishers 3. Extract the core claim or data point from each source Return ONLY a valid JSON object in this exact format: { "query": "the search query used", "sources": [ { "title": "source title", "url": "full URL", "date": "YYYY-MM-DD", "key_point": "the single most relevant finding from this source" } ], "synthesis": "2-3 sentence summary of what all sources agree on", "conflicts": "any major disagreements between sources, or null if none" } # Return no text outside the JSON block. # If Google Search returns no usable results, return {"query": "...", "sources": [], "synthesis": "No results found", "conflicts": null}
Prompt 3: The Data Extraction Specialist (Gemini Flash 3.5)
This prompt goes in EXTRACTION_SPECIALIST_PROMPT. Extraction tasks need explicit handling for missing fields — without it, Flash sometimes invents plausible values to fill gaps in the schema.
You are a data extraction specialist. Your job is to extract structured data
from documents, tables, forms, and unstructured text.
RULES:
- Extract only what is explicitly stated in the document
- If a field is not present, return null — never invent or infer a value
- If a field is ambiguous, return the raw text and flag it
- Numbers must be returned as numbers, not strings
- Dates must be returned in ISO 8601 format (YYYY-MM-DD)
You will receive:
- A target JSON schema (the structure you must populate)
- A document to extract from
Return ONLY a JSON object with two keys:
{
"extracted": { ...the populated schema, with null for missing fields },
"flags": [ ...list of field names that were ambiguous or uncertain ],
"confidence": "high | medium | low"
}
# Confidence is LOW if more than 20% of required fields are null.
# Confidence is MEDIUM if 5-20% are null.
# Confidence is HIGH if fewer than 5% are null.
Prompt 4: The Synthesis Prompt (Claude Opus 4.7)
This is the user-turn template used in the synthesize() function. Opus receives all specialist outputs as a single JSON block and combines them into the final deliverable. The format instructions in [OUTPUT_FORMAT] should match whatever the pipeline is designed to produce.
You are synthesizing the results of a multi-agent research pipeline. The specialist agents have completed their tasks. Your job is to combine their outputs into a single, coherent, high-quality deliverable. SYNTHESIS INSTRUCTIONS {instructions} SPECIALIST RESULTS {results} SYNTHESIS RULES - Treat all specialist outputs as raw data inputs — do not reproduce them verbatim - Where sources conflict, acknowledge the conflict and explain the most likely resolution - Any claim that traces to a research specialist result must be cited inline - If a specialist returned a low-confidence extraction, flag the relevant section - The final output should read as if written by a single author, not assembled from parts # Do not reference "the research specialist" or "the extraction agent" in the output. # The reader should not be able to tell this was a multi-agent pipeline.
Prompt 5: The Quality Gate (Claude Sonnet 4.6)
This runs after synthesis and before delivery. Sonnet 4.6 is fast and cost-efficient for this review role. If the output fails, the gate returns a revised version — the pipeline uses that instead of the original synthesis.
Review the following output against the quality criteria below. Return your assessment as a JSON object. QUALITY CRITERIA {criteria} OUTPUT TO REVIEW {output} REVIEW CHECKLIST □ Does the output meet the stated quality criteria? □ Are there any factual claims without a supporting source? □ Are there internal contradictions between sections? □ Is the format correct and complete? □ Are any low-confidence extractions unacknowledged? Return ONLY this JSON: { "passed": true | false, "issues": ["list of specific issues found, empty array if none"], "revised_output": "the corrected output if passed is false, or null if passed is true" } # If passed is true, set revised_output to null. # If passed is false, revised_output must be the full corrected text.
Prompt Discipline
Every specialist prompt must specify an exact output schema and the rule for handling missing or uncertain data. Prompts that say “return structured data” without showing the schema will produce inconsistent output formats that break the synthesis step at the worst possible moment.
“The best multi-agent system is the simplest one that actually solves your problem — not the most architecturally impressive one you can imagine.”
— aitrendblend editorial team, May 2026
Common Failure Modes — and How to Prevent Them
These five failure modes appear consistently across teams building their first multi-agent pipelines. None of them require exotic inputs to trigger. They emerge from normal use, at normal scale, and they are all preventable with architecture decisions made before the first line of code is written.
Blind Trust in Specialist Outputs
The orchestrator passes specialist output directly into the synthesis prompt without checking whether the output is valid, complete, or in the expected format. A Flash 3.5 call that times out returns an error string. A call that hits a rate limit returns a partial response. When those get passed to Opus as if they were valid data, the synthesis produces confidently-worded output built on garbage. Fix: Validate every specialist output against its expected JSON schema before adding it to the state. Log any validation failure and decide whether to retry, skip, or abort.
Context Window Explosion
The orchestrator accumulates every specialist output in its synthesis context. Ten research results, each 800 tokens, plus five extraction outputs, plus the original task plan — and suddenly Opus is processing 40,000 tokens of intermediate data before it writes a word of the final output. Cost spikes. Latency climbs. At the extreme end, you hit the context limit and the call fails entirely. Fix: Summarize large specialist outputs before passing them to the synthesis prompt. Each research result should contribute its synthesis field, not its full sources array. The synthesis prompt does not need raw data — it needs distilled findings.
Circular Delegation
The orchestrator, uncertain about a result, sends a task back to a specialist for refinement. The specialist, uncertain about the input, returns a clarifying question embedded in its output. The orchestrator interprets this as another specialist task and creates a new routing entry. The pipeline enters a feedback loop. Step counts climb. The quality gate never fires because nothing ever reaches synthesis. Fix: Specialists must never return clarifying questions. They return data or they return a structured error. The orchestrator must never send the same task to the same specialist twice. Add a retry_count field to state and enforce a hard maximum of one retry per task.
Missing State Management
Two independent research tasks have overlapping scope. Both run in parallel. Both fetch the same sources, produce nearly identical outputs, and consume double the tokens. Or: a dependent task fires before its prerequisite completes because the dependency check reads from a stale in-memory dict that another thread has not yet updated. Fix: Use a thread-safe state object — Python’s threading.Lock for in-process pipelines, or a proper database for distributed ones. Every state write acquires the lock. Every dependency check reads from the locked state, not from a local copy.
No Fallback When Flash Is Unavailable
Gemini Flash 3.5 returns a 503. The specialist function raises an exception. The router catches the exception, logs it, and marks the task as errored. The orchestrator tries to synthesize with a results dict that has three tasks completed and seven tasks errored. The synthesis produces a partial, incoherent output that the quality gate fails — but there is nothing to revise it against. Fix: For critical tasks, build a fallback to Claude Sonnet 4.6. Sonnet is more expensive than Flash but reliably available. Mark tasks as "critical": true in the task plan, and the router should retry critical task failures with Sonnet before marking them as errored.
What This Architecture Can and Cannot Do
Multi-agent systems built on this pattern earn their complexity for a specific category of tasks. Using this architecture for problems that do not fit the pattern adds cost and operational burden without adding value. The capability boundary below is worth reviewing honestly before you commit to the build.
- Parallel research tasks requiring live web data
- High-volume document processing pipelines
- Multimodal workflows mixing text, images, and documents
- Tasks where latency can be hidden by async execution
- Pipelines where cost per run matters at production scale
- Complex planning tasks with many independent subtasks
- Workflows needing a quality gate before user delivery
- Real-time responses under 3 seconds (orchestration adds latency)
- Tasks where specialists need to see each other’s live reasoning
- Workflows requiring true shared mutable state across parallel agents
- Conversational pipelines where context evolves turn by turn
- Tasks simple enough for a single well-prompted model call
- Any pipeline where operational complexity outweighs the savings
Model Comparison at a Glance
| Dimension | Claude Opus 4.7 | Gemini Flash 3.5 |
|---|---|---|
| Primary role | Orchestration, planning, synthesis, quality review | Specialist execution — research, extraction, vision |
| Context window | 200,000 tokens | 1,000,000 tokens |
| Response speed | Slower — optimized for quality, not latency | Sub-2 seconds on most tasks |
| Web access | Via tool use (web_search tool) | Native Google Search grounding |
| Multimodal | Images and documents via API | Text, image, audio, video, documents natively |
| Cost efficiency | Premium — use sparingly | Lowest cost in class — use liberally |
| Calls per pipeline | 2 (plan + synthesize) | As many as subtasks require |
Shipping the Pipeline
The architecture in this guide is a starting point, not a ceiling. The orchestrator-worker pattern with Opus 4.7 and Flash 3.5 handles a genuinely wide range of real production use cases — research pipelines, document processing workflows, multimodal analysis jobs — at a cost structure that makes them economically viable at scale. What it requires from you is clarity about what each role does and discipline about not letting those roles blur under pressure to ship faster.
The broader principle here applies beyond this specific model pairing. Multi-agent systems work when the task genuinely requires parallelism, specialization, or scale that a single model call cannot deliver. They add complexity that a single well-prompted model would not require. Every extra model call is a failure point, a cost, and a latency contribution. The decision to build a multi-agent system should follow from the task’s requirements — not from the appeal of the architecture.
Human oversight at the synthesis and quality-gate stages is not a concession to the system’s limitations. It is how you calibrate the pipeline over time. The quality gate report tells you which specialist outputs consistently produce synthesis failures. That signal tells you where to tighten the specialist prompts, where to add validation, and where a human checkpoint is genuinely necessary versus where automation is safe. Treat the quality gate as a learning loop, not just a filter.
Gemini Flash 3.5 and Claude Opus 4.7 will not be the optimal pairing forever. Model capabilities are advancing fast enough that the cost and quality calculations in this guide will shift meaningfully within 12 to 18 months. The architecture pattern — orchestrator handles reasoning, specialists handle execution, shared state holds the pipeline together — will outlast any specific model choice. Build the system around the pattern, substitute the models as the landscape evolves, and the investment in this architecture compounds rather than depreciates.
Build Your First Multi-Agent Pipeline
Grab the Claude agent prompt guide for the orchestrator and synthesis templates — all tested and ready to paste into your system prompt.
claude-opus-4-7, gemini-3.5-flash), API interface signatures, and pricing are subject to change — always verify against the current official documentation before production deployment. aitrendblend.com is not affiliated with Anthropic or Google. No commercial arrangement influenced this content. All code is provided for illustrative purposes; test thoroughly in your own environment before production use.