Key Points
- AlignFedRec replaces embedding aggregation with similarity matrix sharing. Cosine similarity is mathematically invariant to rotation, scaling, and translation, so similarity matrices capture relational structure without leaking embedding geometry.
- A dual structural alignment mechanism works at two granularities simultaneously. Item cluster alignment enforces coarse-grained semantic consistency via modularity-based community detection and supervised contrastive learning. Global structural alignment minimises the Frobenius norm distance between local and global similarity matrices for fine-grained alignment.
- On four public datasets including MovieLens-100K, MovieLens-1M, FilmTrust, and Lastfm-2k, AlignFedRec achieves the highest HR@10 and NDCG@10 across all benchmarks.
- The ablation shows global structural alignment (GSA) contributes more to ranking quality (NDCG) while item cluster alignment (ICA) contributes more to retrieval breadth (HR), suggesting the two mechanisms are genuinely complementary rather than redundant.
- Similarity matrix communication scales as m squared in the number of items, which is larger than the embedding dimension alternative — a real overhead the paper addresses with sparsification and quantization but does not fully resolve for very large item catalogs.
The Geometry Problem Nobody Talks About
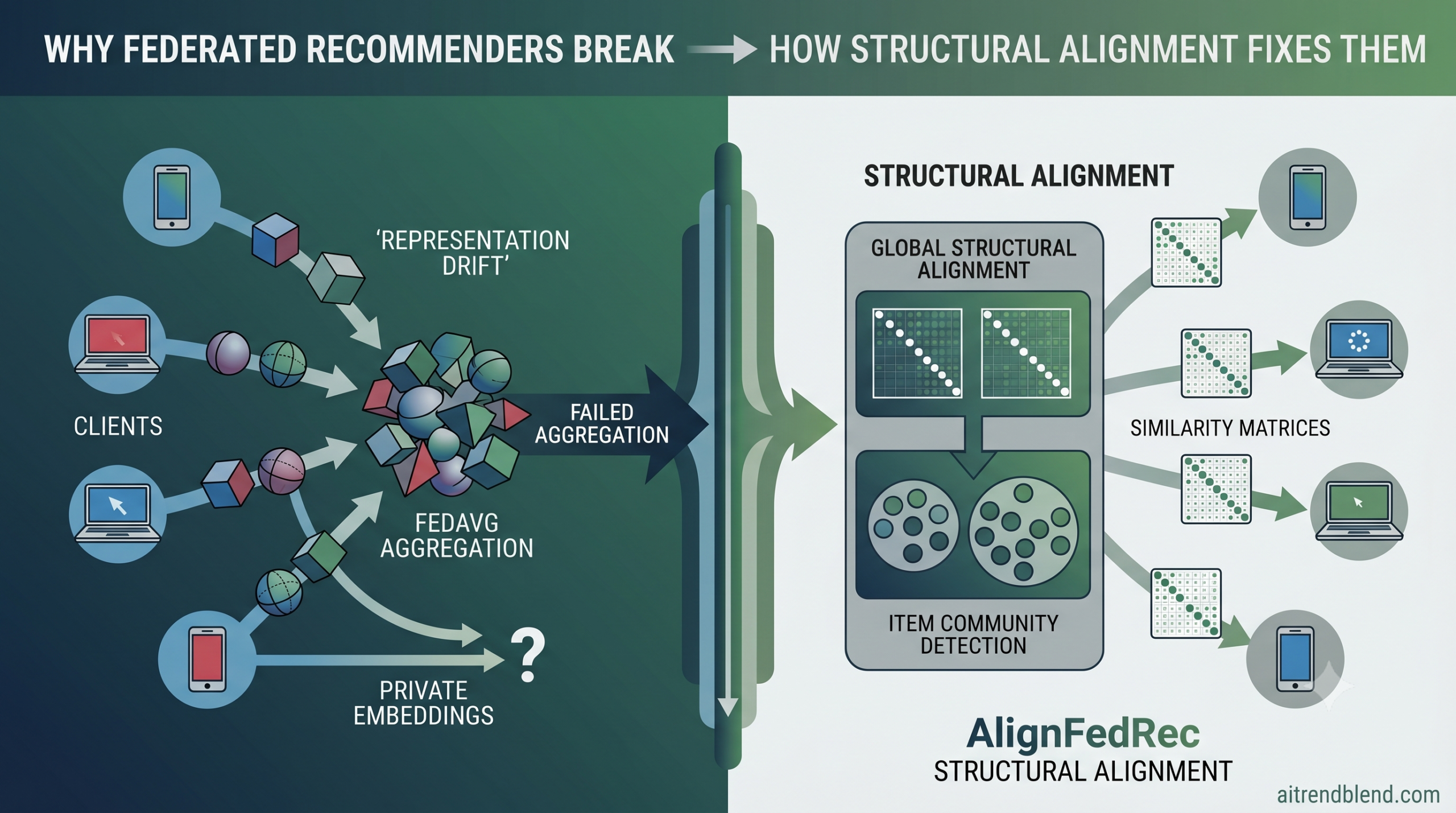
Most federated recommendation research treats representation drift as a training instability — something you fix with better regularisation or smarter aggregation weights. The AlignFedRec paper frames it as a geometry problem, and that reframing changes what solutions look like.
Here is the issue in concrete terms. Suppose client A mostly watches action films and client B mostly watches documentaries. Each trains its own item embedding table on its own viewing history. After enough training, the vector for a film like “March of the Penguins” sits in very different positions in each client’s embedding space — not because the film is different, but because the surrounding context of films that shape its position is completely different. Client A’s “March of the Penguins” vector is defined by its distance from “Die Hard.” Client B’s version is defined by its distance from “Fahrenheit 9/11.” The film is the same. The coordinate systems are not.
When a server averages those two vectors together — which is exactly what FedAvg and its descendant methods do — the result is a point that sits between two coordinate systems neither client actually uses. Technically, the paper calls this representation drift, but the underlying mechanism is simpler: you cannot average coordinates from different maps and expect the result to be on either map.
The authors show this formally using a Euclidean transformation model. If client u’s embedding undergoes an arbitrary rotation R, scaling factor s, and translation b, then its transformed embedding is sRE plus b. When you compute cosine similarity between two items from this transformed space, the rotation and scaling cancel exactly because the orthogonal matrix satisfies R transpose R equals the identity, and scaling appears in both numerator and denominator. The translation does not cancel under cosine similarity in general, but the paper handles this by centering embeddings before computing similarities.
Cosine similarity is invariant to orthogonal rotation and positive scaling. This means similarity matrices built on different clients can be meaningfully aggregated on a server even when the underlying embedding coordinate systems have drifted apart.
This geometric fact is the conceptual foundation of the whole paper. If similarity matrices are invariant to the transformations that cause representation drift, then sharing similarity matrices sidesteps the problem that sharing embeddings cannot avoid.
Two Levels of Alignment, and Why You Need Both
Having decided to share similarity matrices rather than embeddings, the next question is what to do with them. The paper’s answer is a dual structural alignment mechanism that operates at two granularities.
The Coarse Level: Finding Communities Among Items
The global similarity matrix — the average of all clients’ submitted similarity matrices — is not just aggregated and discarded. It is treated as the adjacency matrix of a weighted graph where items are nodes and similarity scores are edge weights. The server runs a modularity maximisation algorithm on this graph to detect communities of densely connected items.
Modularity is a classic graph-theoretic criterion. It measures whether the edges within a community are denser than you would expect by chance given the degree distribution of the graph. The paper uses an iterative local-moving and aggregation procedure that starts by assigning each item to its own community and then repeatedly tries moving each item to whichever neighbouring community produces the largest positive gain in modularity. When no move improves things, communities are collapsed into single nodes and the process repeats on the compressed graph. The result is a partition of items into clusters with no need to specify the number of clusters in advance.
These cluster labels are then broadcast to all clients. Each client uses them to run supervised contrastive learning on its local embeddings. For each anchor item, the positive set is all other items assigned to the same cluster. The contrastive loss pulls those items toward the anchor and pushes all other items away. The temperature parameter controls how sharply the boundary is drawn — lower temperature means harder separation. The paper finds that a temperature of 0.1 works best on MovieLens-100K, where the item space is relatively small and distinct genre clusters are pronounced.
Modularity-based community detection is a principled choice here because it does not require specifying the number of clusters in advance. Different datasets and different rounds of training will naturally produce different numbers of communities, and the algorithm adapts without any manual tuning of that hyperparameter.
The Fine Level: Aligning the Full Relational Structure
Community detection captures the broad topology of the item space but loses fine-grained pairwise relationships. Two items might both belong to the “thriller” community but have a very different similarity score depending on how much they share in terms of cast, director, or release era. Global structural alignment addresses this by minimising the discrepancy between each client’s local similarity matrix and the global consensus matrix at the individual entry level.
The loss is the squared Frobenius norm of the difference between the local and global matrices, summed only over item pairs where the local similarity exceeds a threshold. This sparsification is practical rather than principled. Item similarity matrices are typically sparse — most items are weakly related to most other items, and those weak pairs contribute almost nothing to the collaborative signal. By focusing only on strongly related pairs, the method cuts both the computation of the loss and the communication cost of transmitting the matrix.
The binary mask W selects only item pairs with similarity above threshold σ. This concentrates the alignment signal on strongly correlated pairs while reducing communication and computation over the full m × m matrix.
The overall training objective on each client combines the standard binary cross-entropy recommendation loss with the item cluster alignment loss and the global structural alignment loss, weighted by coefficients α and β respectively. The paper keeps β at 5 across all datasets but tunes α per dataset, suggesting the global alignment contribution is more dataset-agnostic than the cluster alignment strength.
Item relations carry more transferable knowledge than individual embeddings. Sharing and aligning these relational structures enables both global collaboration and personalised adaptation. Tu et al., Expert Systems With Applications 2026
What the Numbers Say
The experiments run on four datasets. MovieLens-100K and MovieLens-1M are the standard movie rating benchmarks from the GroupLens research group. FilmTrust is a smaller but denser movie rating dataset from a social network platform. Lastfm-2k is a music listening dataset with a much sparser interaction structure and a larger item catalog. The evaluation protocol is leave-one-out: each user’s last interaction goes to the test set, the second-to-last to validation, and everything else to training. Metrics are Hit Ratio at 10 and NDCG at 10.
| Method | MovieLens-100K | MovieLens-1M | FilmTrust | Lastfm-2k |
|---|---|---|---|---|
| Centralized | ||||
| NCF | 66.17 / 39.82 | 68.76 / 41.90 | 92.42 / 82.70 | 85.06 / 73.75 |
| Federated baselines | ||||
| PFedRec | 71.05 / 43.89 | 73.62 / 44.35 | 91.44 / 82.36 | 82.06 / 73.15 |
| CoFedRec | 77.52 / 50.65 | 77.75 / 48.81 | 94.05 / 85.20 | 82.75 / 74.10 |
| FedCA | 86.43 / 74.70 | 82.96 / 69.48 | 91.52 / 81.42 | 74.07 / 67.63 |
| AlignFedRec | 86.85 / 73.71 | 86.21 / 73.76 | 98.94 / 95.25 | 83.94 / 75.93 |
The pattern across datasets is consistent: AlignFedRec achieves the best HR@10 on every dataset and the best NDCG@10 on three of four. The one exception is MovieLens-100K where FedCA achieves a marginally higher NDCG@10 of 74.70 against AlignFedRec’s 73.71. The FilmTrust result is striking — HR@10 of 98.94 and NDCG@10 of 95.25 are very large improvements over the next best federated method (CoFedRec at 94.05 and 85.20). FilmTrust is a dense dataset with strong social trust signals, which likely amplifies the benefit of structural alignment because item communities in that dataset have more coherent signal to detect.
The comparison against FedCA is worth dwelling on. FedCA is the most recent strong baseline and also uses a structural sharing approach — it exchanges item similarity matrices, which means the two methods are conceptually related. AlignFedRec’s advantage is the cluster-level alignment layer on top. FedCA does not model community structure among items, it only aligns similarity matrices globally. The performance gap on MovieLens-1M (86.21 versus 82.96 in HR@10 and 73.76 versus 69.48 in NDCG@10) is large enough to attribute to that missing layer, and the ablation study confirms this reading.
Reading the Ablation Carefully
The ablation runs on MovieLens-100K and MovieLens-1M with three configurations. The backbone is PFedRec, the starting model on which everything else is built. Removing ICA keeps only global structural alignment. Removing GSA keeps only item cluster alignment. The full model has both.
| Configuration | ML-100K HR@10 | ML-100K NDCG@10 | ML-1M HR@10 | ML-1M NDCG@10 |
|---|---|---|---|---|
| Backbone (PFedRec) | 71.05 | 43.89 | 73.62 | 44.35 |
| Without ICA | 86.74 | 73.55 | 85.86 | 72.92 |
| Without GSA | 85.15 | 72.06 | 84.07 | 71.73 |
| AlignFedRec (full) | 86.85 | 73.71 | 86.21 | 73.76 |
A few things stand out. First, the lift from backbone to either single-component variant is enormous — both jump from the low 70s in HR@10 to the mid 80s. This suggests that almost all the performance gain comes from the structural sharing paradigm itself, with the dual alignment adding a further, smaller increment. Second, GSA consistently contributes more than ICA in absolute terms. Removing GSA drops NDCG@10 by 1.65 on MovieLens-100K, while removing ICA drops it by only 0.16. This makes intuitive sense. Fine-grained pairwise alignment directly shapes the ranking of similar items against each other, which is exactly what NDCG measures. Cluster alignment operates at a coarser level and may have more impact on whether the right neighborhood of items is retrieved at all, rather than how precisely they are ranked within that neighborhood.
The marginal gains of the full model over the “without ICA” variant are small — 0.11 in HR@10 and 0.16 in NDCG@10 on MovieLens-100K. This is honest data and the paper does not over-sell it. The practical implication is that if you are implementing this framework and computational resources are tight, GSA is the component to keep. ICA adds robustness and semantic coherence, but its contribution at the margin is modest when GSA is already running.
The backbone-to-full-model gain is dominated by the structural sharing paradigm, not by either alignment component specifically. Most of the performance improvement over prior methods comes from switching away from embedding aggregation altogether. The dual alignment is the refinement on top of that fundamental shift.
The Communication Complexity Question
The paper is transparent about the communication overhead tradeoff, and it deserves direct discussion because it is a real constraint in deployed federated systems.
Conventional embedding-based methods transmit matrices of size m by d, where m is the number of items and d is the embedding dimension. AlignFedRec transmits similarity matrices of size m by m. For a recommendation system with 3,706 items (MovieLens-1M) and a 64-dimensional embedding, the embedding transmission is about 237,000 floating-point numbers per round. The similarity matrix is about 13.7 million numbers — nearly 58 times larger before any compression.
The paper’s response to this is twofold. First, the similarity matrix is sparse. Only pairs with similarity above threshold σ are transmitted, which in practice keeps the effective communication volume manageable for datasets of the size used in the experiments. Second, the paper mentions that sparse encoding and n-bit quantisation can further reduce this. Both of these are valid, but neither is evaluated empirically in the paper. For a dataset with 12,454 items (Lastfm-2k), the full similarity matrix has about 155 million entries, and even with aggressive sparsification the overhead may become a bottleneck on slow networks or battery-constrained devices.
This is the sharpest limitation in the current work. The paper’s scalability claim rests on the assertion that real-world recommendation graphs are typically sparse, which is true at the data level but may not hold as strongly at the embedding similarity level, where the encoder is trying to generalise beyond observed interactions. A careful empirical analysis of actual sparsity at different threshold values across the datasets would strengthen the communication analysis considerably.
What This Changes About How to Think About Federated Recommendation
The broader contribution here is conceptual as much as empirical. Federated recommendation has mostly been treated as a distribution problem — how do you aggregate parameters from clients with different data distributions without losing too much? AlignFedRec reframes it as an alignment problem — how do you ensure that what different clients have learned about the same items is compatible at the structural level, without ever comparing the actual representations directly?
This shift matters because it suggests a different toolkit. Distribution problems call for regularisation, proximal terms, and personalisation layers. Alignment problems call for invariant representations, graph-theoretic structure discovery, and contrastive objectives. The federated learning literature has extensive machinery for the first toolkit and is only beginning to develop the second.
The privacy argument is also cleaner than for embedding-based methods. Similarity matrices reveal which items a client considers similar, but they do not reveal the actual embedding vectors. An adversary who intercepts a similarity matrix knows the relational structure of the local item space but cannot reconstruct the original representations without additional information. The paper notes that Laplacian noise can be added to the matrices for formal differential privacy guarantees, though the tradeoff between noise level and alignment quality would need careful calibration.
For practitioners building federated recommendation systems at scale, the most actionable lesson from this paper is probably not to implement AlignFedRec exactly as described, but to reconsider what information actually needs to flow between clients and the server. Structural information about item relationships is both more privacy-preserving and more geometrically stable than raw embeddings. That principle holds regardless of whether the specific dual alignment mechanism is the right implementation choice for a given application.
For broader context on privacy-preserving machine learning, see our overview of federated learning and AI privacy [PLACEHOLDER — replace with confirmed live URL], which covers the landscape this research builds on.
A Complete PyTorch Implementation of AlignFedRec
The following is a full, reproducible PyTorch implementation covering the item similarity matrix construction, modularity-based community detection, item cluster alignment with supervised contrastive learning, global structural alignment, the combined loss function, a training round simulation, an evaluation function, and a runnable smoke test on dummy data.
# ============================================================= # AlignFedRec: Dual Structural Alignment for Federated Recommendation # Full PyTorch implementation based on: # Tu et al., Expert Systems With Applications 331 (2026) 133322 # https://doi.org/10.1016/j.eswa.2026.133322 # ============================================================= import torch import torch.nn as nn import torch.nn.functional as F from torch.optim import Adam import numpy as np from collections import defaultdict import random # ---- Item Similarity Matrix ---------------------------------- def compute_similarity_matrix(E: torch.Tensor, threshold: float = 0.5) -> torch.Tensor: """Compute cosine similarity matrix and apply sparsity threshold. Args: E: (m, d) item embedding matrix. threshold: Keep only pairs with similarity >= threshold. Returns: S: (m, m) sparse similarity matrix (below-threshold set to 0). """ E_norm = F.normalize(E, p=2, dim=1) # (m, d) S = torch.mm(E_norm, E_norm.T) # (m, m) cosine similarity S.fill_diagonal_(0.0) # remove self-similarity S = S * (S >= threshold).float() # sparsify return S # ---- Modularity-based Community Detection -------------------- def modularity_community_detection( S: np.ndarray, threshold: float = 0.5, max_iter: int = 100, tol: float = 1e-4, ) -> np.ndarray: """Greedy modularity maximisation (Algorithm 2 in paper). Args: S: (m, m) global similarity matrix (numpy). threshold: Remove edges below this value. max_iter: Maximum passes over nodes. tol: Convergence tolerance on modularity delta. Returns: labels: (m,) community label for each item. """ m = S.shape[0] # Remove weak edges A = np.where(S >= threshold, S, 0.0) np.fill_diagonal(A, 0.0) total_weight = A.sum() / 2.0 + 1e-8 k = A.sum(axis=1) # node degrees # Each item starts as its own community community = np.arange(m) def modularity(labels): Q = 0.0 for i in range(m): for j in range(m): if labels[i] == labels[j]: Q += A[i, j] - k[i] * k[j] / (2 * total_weight) return Q / (2 * total_weight) Q_prev = modularity(community) for iteration in range(max_iter): order = list(range(m)) random.shuffle(order) moved = False for i in order: neighbors = np.where(A[i] > 0)[0] best_dQ = 0.0 best_c = community[i] current_c = community[i] candidate_communities = set([community[nb] for nb in neighbors]) candidate_communities.add(current_c) for c in candidate_communities: if c == current_c: continue community[i] = c Q_new = modularity(community) dQ = Q_new - Q_prev if dQ > best_dQ: best_dQ = dQ best_c = c community[i] = current_c if best_dQ > 0: community[i] = best_c Q_prev += best_dQ moved = True if not moved: break # Re-label communities as 0, 1, 2, ... unique = {c: idx for idx, c in enumerate(sorted(set(community)))} return np.array([unique[c] for c in community]) # ---- Item Cluster Alignment Loss (ICA) ----------------------- def item_cluster_alignment_loss( E: torch.Tensor, cluster_labels: torch.Tensor, tau: float = 0.1, tau0: float = 0.07, ) -> torch.Tensor: """Supervised contrastive loss over item cluster assignments (Eq. 3-4). Args: E: (m, d) item embeddings on this client. cluster_labels: (m,) integer cluster assignment per item. tau: Temperature for this dataset. tau0: Base temperature (paper default). Returns: Scalar ICA loss. """ E_norm = F.normalize(E, p=2, dim=1) sim_matrix = torch.mm(E_norm, E_norm.T) / tau # (m, m) m = E.size(0) total_loss = torch.tensor(0.0, device=E.device) count = 0 for a in range(m): # Positive mask: same cluster, not self pos_mask = (cluster_labels == cluster_labels[a]) & (torch.arange(m, device=E.device) != a) if pos_mask.sum() == 0: continue # Negative mask: all other items neg_mask = torch.arange(m, device=E.device) != a log_denom = torch.logsumexp(sim_matrix[a][neg_mask], dim=0) log_numerators = sim_matrix[a][pos_mask] loss_a = -(log_numerators - log_denom).mean() total_loss = total_loss + loss_a count += 1 return (tau / tau0) * (total_loss / max(count, 1)) # ---- Global Structural Alignment Loss (GSA) ------------------ def global_structural_alignment_loss( S_local: torch.Tensor, S_global: torch.Tensor, threshold: float = 0.5, ) -> torch.Tensor: """Frobenius norm alignment between local and global similarity (Eq. 10). Args: S_local: (m, m) local similarity matrix. S_global: (m, m) global aggregated similarity matrix. threshold: Only align pairs with local similarity >= threshold. Returns: Scalar GSA loss. """ mask = (S_local >= threshold).float() diff = S_local - S_global loss = (mask * diff.pow(2)).sum() return loss # ---- Score Network (MLP backbone) ---------------------------- class ScoreNetwork(nn.Module): """Single-layer MLP score network following PFedRec (Zhang et al., 2023).""" def __init__(self, d: int = 64): super().__init__() self.fc = nn.Linear(d * 2, 1) def forward(self, user_emb: torch.Tensor, item_emb: torch.Tensor) -> torch.Tensor: """Concatenate user and item embeddings and score interaction.""" x = torch.cat([user_emb, item_emb], dim=-1) return torch.sigmoid(self.fc(x)).squeeze(-1) # ---- Client ------------------------------------------------- class FedRecClient(nn.Module): """Single federated recommendation client.""" def __init__(self, num_items: int, d: int = 64): super().__init__() self.item_emb = nn.Embedding(num_items, d) self.user_emb = nn.Parameter(torch.randn(1, d)) self.score_net = ScoreNetwork(d) def compute_similarity_matrix(self, threshold: float = 0.5) -> torch.Tensor: E = self.item_emb.weight.detach() return compute_similarity_matrix(E, threshold) def local_loss( self, pos_items: torch.Tensor, neg_items: torch.Tensor, cluster_labels: torch.Tensor, S_global: torch.Tensor, alpha: float = 0.5, beta: float = 5.0, tau: float = 0.1, threshold: float = 0.5, ) -> torch.Tensor: """Full client loss (Eq. 13).""" # Recommendation prediction loss (binary cross-entropy) pos_score = self.score_net( self.user_emb.expand(len(pos_items), -1), self.item_emb(pos_items) ) neg_score = self.score_net( self.user_emb.expand(len(neg_items), -1), self.item_emb(neg_items) ) L_rat = -torch.log(pos_score + 1e-8).mean() - torch.log(1 - neg_score + 1e-8).mean() # Item cluster alignment loss (ICA) E = self.item_emb.weight L_ica = item_cluster_alignment_loss(E, cluster_labels, tau=tau) # Global structural alignment loss (GSA) S_local = compute_similarity_matrix(E.detach(), threshold) L_gsa = global_structural_alignment_loss(S_local, S_global, threshold) return L_rat + alpha * L_ica + beta * L_gsa # ---- Server ------------------------------------------------- class FedRecServer: """Central server for AlignFedRec.""" def __init__(self, num_items: int, threshold: float = 0.5): self.num_items = num_items self.threshold = threshold self.global_S = torch.zeros(num_items, num_items) self.cluster_labels = torch.zeros(num_items, dtype=torch.long) def aggregate(self, client_matrices: list) -> None: """Average client similarity matrices (line 16 in Algorithm 1).""" stacked = torch.stack(client_matrices, dim=0) self.global_S = stacked.mean(dim=0) def detect_communities(self) -> None: """Run modularity community detection (line 17 in Algorithm 1).""" S_np = self.global_S.cpu().numpy() labels_np = modularity_community_detection(S_np, threshold=self.threshold) self.cluster_labels = torch.from_numpy(labels_np).long() # ---- Federated Training Round -------------------------------- def run_federated_round( clients: list, server: FedRecServer, interaction_data: list, local_epochs: int = 3, alpha: float = 0.5, beta: float = 5.0, tau: float = 0.1, threshold: float = 0.5, lr: float = 1e-3, ): """One round of AlignFedRec federated training.""" cluster_labels = server.cluster_labels S_global = server.global_S similarity_matrices = [] for idx, client in enumerate(clients): opt = Adam(client.parameters(), lr=lr) pos_items, neg_items = interaction_data[idx] for _ in range(local_epochs): opt.zero_grad() loss = client.local_loss( pos_items, neg_items, cluster_labels, S_global, alpha=alpha, beta=beta, tau=tau, threshold=threshold ) loss.backward() opt.step() similarity_matrices.append(client.compute_similarity_matrix(threshold)) # Server aggregation and community detection server.aggregate(similarity_matrices) server.detect_communities() return similarity_matrices # ---- Evaluation (Hit@10 and NDCG@10) ------------------------ def evaluate_client( client: FedRecClient, test_item: int, all_items: list, k: int = 10, ) -> dict: """Leave-one-out evaluation for a single client.""" client.eval() with torch.no_grad(): items_t = torch.tensor(all_items) scores = client.score_net( client.user_emb.expand(len(all_items), -1), client.item_emb(items_t) ) topk = torch.topk(scores, k).indices.tolist() topk_items = [all_items[i] for i in topk] hit = 1.0 if test_item in topk_items else 0.0 ndcg = 0.0 if hit: rank = topk_items.index(test_item) + 1 ndcg = 1.0 / np.log2(rank + 1) return {"hit": hit, "ndcg": ndcg} # ---- Smoke Test on Dummy Data -------------------------------- if __name__ == "__main__": torch.manual_seed(42) random.seed(42) NUM_ITEMS = 50 NUM_CLIENTS = 5 D = 16 THRESHOLD = 0.3 # Initialise server and clients server = FedRecServer(NUM_ITEMS, threshold=THRESHOLD) clients = [FedRecClient(NUM_ITEMS, d=D) for _ in range(NUM_CLIENTS)] # Dummy interaction data: each client has 4 positive and 16 negative items interaction_data = [] for _ in range(NUM_CLIENTS): pos = torch.randint(0, NUM_ITEMS, (4,)) neg = torch.randint(0, NUM_ITEMS, (16,)) interaction_data.append((pos, neg)) # Prime the server with initial similarity matrices init_matrices = [c.compute_similarity_matrix(THRESHOLD) for c in clients] server.aggregate(init_matrices) server.detect_communities() num_communities = server.cluster_labels.unique().numel() print(f"Initial communities detected: {num_communities}") # Run one federated training round run_federated_round( clients, server, interaction_data, local_epochs=2, alpha=0.005, beta=5.0, tau=0.1, threshold=THRESHOLD, lr=1e-3, ) # Evaluate first client all_items = list(range(NUM_ITEMS)) result = evaluate_client(clients[0], test_item=3, all_items=all_items, k=10) print(f"Smoke test passed. Client 0 — Hit@10: {result['hit']:.1f}, NDCG@10: {result['ndcg']:.4f}") print(f"Communities after round: {server.cluster_labels.unique().numel()}")
Conclusion
AlignFedRec is a clean example of how reframing a problem at the right level of abstraction produces solutions that were not visible under the old framing. Embedding aggregation was the dominant paradigm in federated recommendation because it is the direct analogue of FedAvg for a recommendation model. But it carries an implicit assumption — that clients operate in a shared coordinate system — that is rarely true in practice. Once you name that assumption and identify why it fails geometrically, the alternative becomes obvious: share something that does not depend on the coordinate system.
The dual alignment mechanism is a reasonable solution to the follow-on problem of what to do with those coordinate-invariant signals. Running community detection on the aggregated similarity graph to get cluster labels and then using those labels for contrastive learning is an elegant pipeline because it converts an unsupervised structure discovery step into a supervised alignment objective. The server does the hard global reasoning; the clients do the local alignment work. That separation of responsibilities maps cleanly onto what is computationally feasible on each side of a federated system.
The communication overhead is a genuine limitation that deserves more empirical attention in follow-up work. The paper’s scalability claims for large item catalogs rest on assumptions about sparsity that hold in the tested datasets but may not generalise. The most important next experiment for this line of research is a direct measurement of sparse similarity matrix sizes after thresholding across a range of real-world catalog sizes, to establish the actual communication budget rather than the worst-case theoretical one.
More broadly, the paper opens a direction that is likely to be productive. If structural alignment outperforms embedding alignment for recommendations, the same principle might apply to other federated tasks where the representation spaces of heterogeneous clients are systematically incompatible. Knowledge graphs, session-based recommendation, and cross-domain adaptation all involve the same fundamental tension between local diversity and global coherence. The tools developed here — invariant relational representations, community detection for semantic anchoring, and contrastive objectives guided by global structure — are general enough to be worth testing in those settings.
The numbers on FilmTrust are remarkable. Nearly 99 percent Hit@10 in a federated setting, exceeding what centralized methods achieve on the same dataset. That does not happen by accident. It happens when the collaborative signal in the data is strong, the privacy constraint is respected, and the alignment mechanism is well matched to the structure of the problem. AlignFedRec clears all three bars on that particular dataset. The challenge now is understanding how to maintain that alignment quality as item catalogs and user populations scale to the sizes found in production recommendation systems.
Frequently Asked Questions
Representation drift occurs when clients independently train their item embedding spaces on local data, causing the same item to end up in different positions across different clients’ embedding spaces. When a central server averages these embeddings together, the result is geometrically incoherent because it combines vectors from incompatible coordinate systems. The averaged embedding does not match any client’s learned geometry, which weakens the collaborative signal and degrades recommendation quality. AlignFedRec avoids this by sharing item similarity matrices instead of embeddings, because cosine similarity is mathematically invariant to the rotation, scaling, and translation transformations that cause coordinate system drift.
Cosine similarity between two item embeddings is invariant to orthogonal rotation and positive scaling of the embedding space. This means that two clients with the same underlying item relationships but different coordinate systems will produce identical pairwise similarity scores. By sharing similarity matrices rather than embeddings, AlignFedRec ensures that the server receives geometrically consistent relational information from all clients regardless of how their local training has rotated or scaled their embedding spaces. This invariance property is proved formally in the paper using the identity R transpose R equals the identity for orthogonal matrices.
Dual structural alignment operates at two granularities simultaneously. Item cluster alignment runs modularity-based community detection on the aggregated global similarity matrix to discover densely connected communities of items, then broadcasts those community labels to all clients. Each client uses the labels to run supervised contrastive learning that pulls same-cluster items together and pushes different-cluster items apart. Global structural alignment minimises the Frobenius norm distance between each client’s local similarity matrix and the global consensus matrix, focusing only on strongly correlated item pairs above a similarity threshold. The two mechanisms handle different aspects of consistency: cluster alignment enforces coarse-grained semantic topology, and global alignment enforces fine-grained pairwise relational fidelity.
The algorithm treats the global item similarity matrix as the adjacency matrix of a weighted graph, where each item is a node and edge weights encode pairwise similarity. It starts with each item in its own community and iteratively moves each item to whichever neighbouring community produces the largest positive gain in modularity. Modularity measures whether edges within communities are denser than expected by chance given the degree distribution of the graph. When no move improves modularity, communities are compressed into single nodes and the process repeats. Modularity maximisation is used because it does not require specifying the number of clusters in advance — the algorithm discovers the natural partition of the item graph, which varies across datasets and across rounds of training.
Conventional embedding-based federated recommendation methods transmit matrices of size m by d per round, where m is the number of items and d is the embedding dimension. AlignFedRec transmits similarity matrices of size m by m, which is quadratically larger. For a dataset with 3,706 items and 64-dimensional embeddings, the similarity matrix is roughly 58 times larger than the embedding matrix before compression. The paper addresses this by retaining only item pairs above a similarity threshold and noting that sparse encoding and n-bit quantisation can reduce the effective size, but the specific communication savings from these techniques are not empirically evaluated in the paper. This remains an open question for large-scale deployment with item catalogs of tens or hundreds of thousands of items.
AlignFedRec shares item similarity matrices derived from local embeddings rather than the embeddings themselves. Since similarity matrices are invariant to the underlying embedding geometry, an adversary who intercepts a similarity matrix cannot reconstruct the original embedding vectors without additional information about the coordinate system. This provides a stronger privacy guarantee than transmitting gradients or embeddings directly. The paper also notes that Laplacian noise can be added to the similarity matrices via the formula matrix plus Laplacian noise with intensity delta, providing a formal differential privacy mechanism whose strength is controlled by the noise parameter. The tradeoff between noise intensity and alignment quality would need dataset-specific calibration in practice.
Tu, Y., Sun, B., Li, Z., Wang, R., and Song, X. (2026). AlignFedRec: Dual structural alignment for item representation learning in federated recommendation. Expert Systems With Applications, 331, 133322. https://doi.org/10.1016/j.eswa.2026.133322
This analysis is based on the published paper and an independent evaluation of its claims.