A doctor assessing a patient for depression does not expect the patient’s face to fall neatly into one of six predefined expression categories. Real emotional states are layered, ambiguous, and often do not match the vocabulary the training data was built from. Yet almost every multimodal emotion AI in use today would silently force that patient’s expression into its nearest known category rather than flagging the uncertainty. That failure mode is what Yuanyuan Liu, Shuyang Liu, and colleagues at China University of Geosciences, Yunnan University, and La Trobe University set out to address.
Key Points
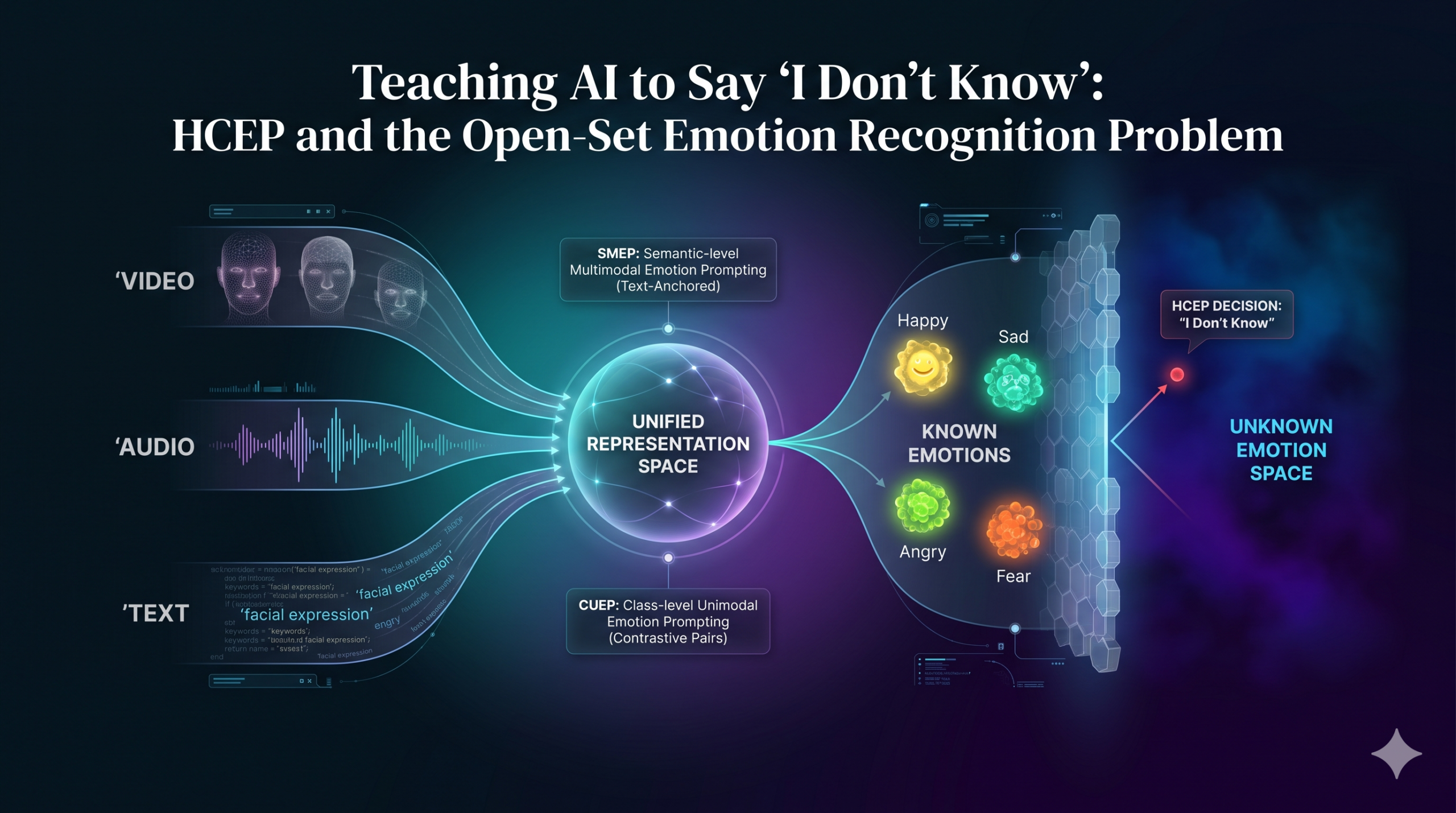
- HCEP is the first framework specifically designed for open-set multimodal emotion recognition, meaning it classifies known emotions across video, audio, and text while actively detecting when an emotion falls outside its training vocabulary rather than forcing a wrong classification.
- A hierarchical two-level prompting strategy adapts frozen pretrained models (CLIP for vision and text, wav2vec 2.0 for audio) rather than retraining them, making the approach computationally practical and modality-agnostic in its foundation.
- The semantic-level module aligns emotion features across modalities using text as a semantic anchor, while the class-level module introduces contrastive positive and negative prompt pairs per known emotion category to sharpen the boundary between what is known and what is not.
- Across five benchmark settings including cross-dataset evaluation, HCEP achieves average relative improvements of 16.79% in AUROC and 28.49% in OSCR over its multimodal baseline, with both metrics measured in a threshold-independent way that avoids test set leakage.
- The gap between known and unknown emotion probability distributions in HCEP’s output is visually distinct in a way that prior methods including ARPL and HESP cannot match, which matters for real deployment where a confidence threshold must be set using only training data.
- Significant limitations remain for clinical contexts: the framework assumes temporally aligned, high-quality inputs, has only been tested on academic datasets, and currently treats all unknown emotions as a single undifferentiated category rather than distinguishing among types of novel emotional states.
The Closed-Set Assumption and Why It Fails in Sensitive Settings
Every emotion recognition model you have ever seen reviewed in a paper was trained on a fixed list of emotion categories. Happy, sad, angry, fearful, surprised, disgusted. Sometimes the list extends to contempt, anxiety, helplessness, or compound states. But the list always closes. At test time, the model receives a video clip of a person expressing something, and it returns its best match from that closed set.
This works adequately in controlled research environments where the test distribution is designed to match the training distribution. It fails in the real world for a simple reason: human emotional experience is not closed. Someone might be experiencing a culturally specific affective state that your training dataset never contained. They might be deliberately masking their primary emotion while leaking a secondary one. They might be in a transitional state between two familiar emotions. Micro-expressions, compound affect, ambiguous presentations, and emotional states specific to clinical contexts like anosognosia or flat affect in schizophrenia will never appear in a labeled training set in adequate numbers.
The consequences of forcing an unknown emotional state into the nearest known category vary by application. In a casual recommendation system, a mismatch is a minor annoyance. In a depression screening tool, a misclassified emotional state could mean a patient is assessed as “sad” when the system should have flagged the response as falling outside the model’s competence and deferred to a clinician. Forcing a classification the model is not equipped to make is worse than admitting uncertainty.
Open-set recognition is the framework designed to prevent this. A model operating in an open-set regime does not just classify; it also maintains an explicit mechanism for detecting when a test sample falls outside the distribution of known categories. The challenge is that this is much harder when the inputs are multimodal, because a face, a voice, and a transcript do not always agree on what emotion is being expressed.
What Makes the Multimodal Open-Set Problem Harder
Unimodal open-set recognition has a relatively established literature. You train a model on known classes, you design a scoring mechanism that assigns lower confidence to out-of-distribution inputs, and you set a threshold below which samples are flagged as unknown. The score might come from the maximum softmax probability, a reconstruction error, a distance metric in feature space, or a learned auxiliary model. The field has converged on several reliable approaches.
Multimodal emotion recognition adds a structural complication that does not exist in the single-modality case. Emotions are expressed heterogeneously across modalities. A person whose face is expressive may speak in a flat tone. Someone verbally describing sadness may show micro-expressions of contempt. This cross-modal inconsistency is not noise to be suppressed; it is meaningful information about the complexity of the emotional state. But it also means that the feature space you are trying to separate into known and unknown regions is inherently higher-dimensional and more scattered.
The paper by Liu and colleagues identifies two failure modes in existing approaches applied to this problem. First, simply combining pretrained models for each modality and feeding their outputs into an open-set classifier produces what they call semantically heterogeneous emotion representations. The visual features and audio features occupy different representational spaces, and their concatenation does not produce a coherent joint space where the boundary between known and unknown emotions is cleanly learnable.
Second, the class boundaries between fine-grained emotions are blurry even within the known categories. The distance between “anxious” and “fearful” in any embedding space is small. If you cannot separate these two known categories reliably, you have no hope of detecting a novel unknown category that sits near their boundary.
“Forcing novel emotional states into rigid categories can obscure diagnostic cues and increase the risk of misinterpretation.”Liu et al., Information Fusion 2026
HCEP’s Three-Module Architecture
The HCEP framework, published in Information Fusion in 2026, addresses both problems through a hierarchical two-level prompting strategy built on top of frozen pretrained models. The key word is frozen. HCEP does not retrain CLIP or wav2vec 2.0. It learns small prompt vectors that steer these models toward emotion-relevant features without touching their weights. This is both computationally efficient and conceptually cleaner: the foundation models provide general representational capacity, and the learned prompts provide emotion-specific focus.
Semantic-level Multimodal Emotion-aligning Prompting. Anchors all three modalities to a shared emotion semantic space using text as the primary guide.
Class-level Unimodal Emotion-opposing Prompting. Generates contrastive positive and negative prompts per known emotion category to sharpen decision boundaries.
Dual-stream Prompt-driven Open-set Learning. Jointly optimizes known emotion recognition and unknown emotion detection using a distance-based contrastive score.
SMEP: Using Text as a Semantic Anchor
The core insight behind SMEP comes from cognitive science. Among the three modalities in play, text is the most direct and least ambiguous carrier of emotional meaning. A transcript that says “the girl looks down, lets out a long sigh” is less susceptible to noise and individual variation than the corresponding audio waveform or the 224-by-224 pixel visual input. SMEP uses this property by initializing learnable textual prompts with an emotion-related anchor phrase and then projecting those prompts into the visual and audio modality spaces through two small learned projection layers.
The result is a triplet of emotion-unified prompts, one for each modality, that all trace back to the same text-grounded emotional semantics. These prompts are prepended to the respective modality inputs and fed through the frozen encoders. The frozen CLIP visual encoder and the frozen wav2vec 2.0 audio encoder now receive inputs that are explicitly guided toward the same emotion-relevant subspace. The three resulting feature vectors are concatenated into a unified multimodal representation.
The paper tests three alternatives to this text-anchored design: anchoring via visual prompts, anchoring via audio prompts, and no cross-modal guidance at all. Text anchoring consistently outperforms the alternatives, and removing the cross-modal alignment entirely drops AUROC by about 1% and OSCR by over 1%. These are not large numbers in absolute terms, but the pattern confirms that cross-modal alignment at the semantic level contributes independently of the class-level and dual-stream components.
CUEP: Positive and Negative Prompts Per Category
SMEP handles the alignment problem. CUEP handles the boundary problem. For each of the K known emotion categories, CUEP maintains two sets of prompts: a positive set that reinforces the discriminative patterns belonging to that category, and a negative set that captures what that category is not.
The design difference between positive and negative prompts is instructive. For the text modality, positive prompts follow the fixed natural language template “This video is [CLASS-k]” and negative prompts follow “This video is not [CLASS-k]”. The explicit negation in the text is a clean semantic signal. For visual and audio modalities, both positive and negative prompts are learnable continuous tensors initialized with random noise. This asymmetry reflects the different roles of the three modalities. Text can carry explicit semantic polarity through natural language. Visual and audio representations cannot, so their polarity must be learned rather than specified.
The ablation results on prompt design are worth reading carefully. Using only randomly initialized negative features (the ARPL baseline approach) gives an AUROC of 70.07% and OSCR of 57.88% on the 10-emotion MAFW benchmark. Adding the prompted negative features raises AUROC to 76.67% and OSCR to 61.74%. Adding prompted positive features on top gives the final result of 77.72% AUROC and 62.87% OSCR. Each step makes a meaningful contribution, and the ordering matters. Without the semantic structure from the text templates, fully learnable prompts without emotion labels perform worst of all three text formulation variants tested.
DPOL: Turning the Distance Gap Into a Decision
DPOL takes the unified semantic features from SMEP and the contrastive class-level features from CUEP and combines them into a dual-stream learning objective. The known-class stream uses cosine similarity between the multimodal feature and the positive textual features for K known categories to compute a standard supervised classification loss. The unknown-class stream uses a composite distance metric (the difference between Euclidean distance and dot product, following the ARPL formulation) to compute two quantities for each sample: how close it is to the positive features of all known classes, and how close it is to the negative features of all known classes.
The contrastive distance score \(D_{neg,i} – D_{pos,i}\) is the key quantity. During training, this term encourages the model to push each known-class sample closer to its corresponding positive features and further from its negative features. At inference, the softmax of this score becomes the confidence signal. A high value means the sample matches a known emotion pattern more closely than it matches the negation of any known pattern. A low value means the opposite, which is the signature of an unknown emotion.
This design makes the known/unknown separation a direct consequence of how the model structures its feature space during training, rather than a postprocessing step applied to an already-trained classifier. The probability distributions in the paper’s visualization show this clearly: for HCEP, known emotion samples cluster in the high-confidence range and unknown samples cluster in the low-confidence range with very little overlap, while the baseline and ARPL show large overlap regions where the two distributions are nearly indistinguishable.
Most threshold-based open-set methods learn a closed-set classifier and then apply a threshold to its maximum softmax output at inference time. This works moderately well but the threshold choice is heavily dependent on the training distribution, and the known/unknown gap tends to narrow as openness increases. HCEP’s contrastive distance training directly shapes the embedding space so that the gap is structural rather than incidental.
Five Benchmarks, and What the Numbers Mean
The paper evaluates HCEP across five experimental settings on three datasets: MAFW (10,045 video-audio clips with 11 basic and 32 compound emotion categories), CMU-MOSEI (23,453 annotated sentences across six emotion categories), and OV-MERD (236 emotion vocabulary categories). The five settings test different types of challenge: varying ratios of known to unknown classes within a single dataset, fine-grained compound emotion detection, large-scale open-world emotion detection with 236 unknown categories, and cross-dataset evaluation where both distribution shift and unknown categories are present simultaneously.
| Method | Type | MAFW Mean AUROC | MAFW Mean OSCR | CMU-MOSEI AUROC | CMU-MOSEI OSCR | Cross-Dataset AUROC | Cross-Dataset OSCR |
|---|---|---|---|---|---|---|---|
| ARPL | Unimodal | 57.14 | 25.28 | 52.80 | 30.92 | 66.35 | 26.76 |
| HESP | Unimodal | 69.34 | 46.85 | 57.46 | 36.20 | 72.67 | 37.97 |
| CPN* | Multimodal | 68.34 | 56.14 | 54.61 | 35.01 | 56.49 | 30.88 |
| LPL* | Multimodal | 58.37 | 47.45 | 50.75 | 24.28 | 51.65 | 31.82 |
| Baseline | Multimodal | 65.32 | 50.19 | 54.27 | 32.93 | 63.61 | 38.07 |
| HCEP (Ours) | Multimodal | 77.72 | 62.87 | 63.13 | 42.39 | 77.54 | 51.81 |
Mean AUROC and OSCR across openness settings. Source: Liu et al., Information Fusion 2026, Tables 2-4. CPN* and LPL* are multimodal extensions of CPN and LPL using the same pretrained backbone as HCEP for fair comparison.
The numbers deserve a careful read rather than a quick scan. AUROC and OSCR measure different things. AUROC reflects how well the model separates known from unknown samples when you sweep over all possible thresholds. OSCR measures joint correctness: a sample is only counted as correct in OSCR if it is both accepted as known and classified into the right category. OSCR is the harder and more practically relevant metric for clinical applications, because correct detection of an unknown emotion requires both that the sample is not misclassified into a wrong known category and that it is not rejected when it is actually known.
On MAFW, HCEP’s mean OSCR of 62.87% against the multimodal baseline’s 50.19% is a 25% relative gain. On the cross-dataset setting, HCEP reaches 51.81% OSCR against the multimodal baseline’s 38.07%. The cross-dataset result is arguably the most informative for deployment because it tests the model against both novel emotion categories and distribution shift simultaneously. The 13.74-point OSCR gain over the baseline in that setting confirms that HCEP’s design improvements hold up when the test distribution differs from training not just in class vocabulary but in recording conditions, demographics, and dataset biases.
One important observation the paper surfaces: multimodal extension does not automatically beat unimodal methods. Several of the multimodal baselines (CPN*, LPL*) trail behind the unimodal HESP on AUROC. Being multimodal is not sufficient; the cross-modal interaction mechanism has to actually work. HCEP’s results are the first demonstration in this paper’s experimental setting that a well-designed multimodal approach can substantially and consistently outperform both unimodal and naive multimodal competitors across every benchmark tested.
Clinical Translation Gap
HCEP represents a meaningful research advance in open-set emotion AI. The distance between these results and a deployable clinical tool is significant and should not be understated. The benchmarks used are academic datasets collected in controlled or semi-controlled settings, not clinical populations. The three most important gaps before any such system could responsibly inform clinical decisions are described below.
The paper’s own conclusion section is candid about what HCEP does not yet handle. First, it assumes temporally aligned, high-quality multimodal inputs. In real clinical settings, audio quality varies, video may be interrupted, and text transcripts may contain errors. The paper tests what happens with temporal disorder and misalignment and acknowledges that performance degrades substantially, but does not provide a solution.
Second, all unknown emotion categories are collapsed into a single “unknown” label. This is a significant limitation for clinical use. A clinician does not just need to know that a patient’s emotional state falls outside the trained vocabulary; they need some structured characterization of what the unknown state resembles. A flat affect, a masked secondary emotion, and a culturally specific expression should ideally generate different outputs, not the same “unknown” flag. The paper identifies structured modeling of unknown subtypes as a future direction.
Third, the dataset sizes for some test conditions are small. The OV-MERD benchmark covers 236 emotion categories, which is conceptually valuable for testing large-scale open-world detection, but the paper does not report per-class sample counts for this dataset in a way that allows evaluation of statistical reliability for rare categories.
There is also a broader question about whether an AI system that detects “unknown emotions” should ever make autonomous decisions in healthcare settings, regardless of its technical performance. The appropriate role for a system like HCEP in a clinical context would be as a decision-support tool that flags unusual presentations for human clinician review, not as an autonomous classifier. The research makes no claim to the contrary, and practitioners considering similar systems should hold to this principle regardless of the AUROC numbers.
Prompt Engineering Lessons From HCEP
The design choices in HCEP carry lessons that extend beyond emotion recognition to prompt learning in general. Several of them are worth making explicit.
Text anchoring outperforms visual or audio anchoring for cross-modal semantic alignment. This is not unique to emotions; it reflects the general finding that language provides a more structured and consistent representational space than raw visual or audio features. If you are designing a multimodal prompt learning system and you need to establish a common semantic reference across modalities, starting from text is the empirically supported choice.
Explicit negation in prompts adds information that positive-only prompts cannot provide. The “This video is not [CLASS-k]” template does something that a learnable continuous vector cannot: it specifies a semantic direction using the pretrained model’s existing knowledge of linguistic negation. The CUEP ablation makes clear that this explicit structure outperforms fully learnable alternatives by a small but consistent margin.
Hybrid feature settings outperform both textual-only and multimodal-only settings in the DPOL distance computation. The reason is that textual features are stable and semantically clean but lack multimodal nuance, while multimodal features are richer but noisier during training. Using textual features for the recognition stream and multimodal features for the discovery stream separates these roles cleanly, and the paper shows this design choice matters more than the architectural details of either stream individually.
HCEP demonstrates that contrastive prompt pairs, positive and negative, structured around semantic templates outperform learned-only prompt vectors in boundary-sensitive tasks. The pattern likely generalizes to any classification problem where the boundary between known and unknown matters as much as the classification accuracy within known classes.
Complete PyTorch Implementation of the HCEP Core
The implementation below reproduces the SMEP cross-modal prompt projection, the CUEP positive and negative prompt generation, and the DPOL dual-stream loss computation in runnable PyTorch code. It includes the full training loop, both loss terms, threshold-independent inference, and a smoke test on synthetic tri-modal data.
# HCEP: Hierarchical Cross-modal Emotion-interactive Prompting # Liu et al., Information Fusion 2026 # Educational reproduction — core modules and training loop import torch import torch.nn as nn import torch.nn.functional as F from typing import Tuple # --------------------------------------------------------- # Placeholder frozen encoders (replace with real CLIP + wav2vec 2.0) # --------------------------------------------------------- class FrozenEncoder(nn.Module): """Simulates a frozen pretrained encoder (CLIP text/visual, wav2vec 2.0).""" def __init__(self, out_dim: int): super().__init__() self.proj = nn.Linear(128, out_dim) for p in self.parameters(): p.requires_grad = False # frozen def forward(self, x: torch.Tensor) -> torch.Tensor: return self.proj(x) # --------------------------------------------------------- # SMEP: Semantic-level Multimodal Emotion-aligning Prompting # --------------------------------------------------------- class SMEP(nn.Module): """ Learns text-grounded emotion prompts and projects them into visual and audio modality spaces via two small projection layers. All three modality encoders remain frozen. """ def __init__(self, text_dim: int, visual_dim: int, audio_dim: int, m: int = 2): super().__init__() self.m = m # Learnable text prompt vectors (m x text_dim) self.text_prompts = nn.Parameter(torch.randn(m, text_dim) * 0.02) # Cross-modal projection layers (text -> visual, text -> audio) self.N_v = nn.Sequential(nn.Linear(text_dim, visual_dim), nn.LayerNorm(visual_dim)) self.N_a = nn.Sequential(nn.Linear(text_dim, audio_dim), nn.LayerNorm(audio_dim)) def forward( self, text_enc: FrozenEncoder, visual_enc: FrozenEncoder, audio_enc: FrozenEncoder, T: torch.Tensor, V: torch.Tensor, A: torch.Tensor, ) -> torch.Tensor: B = T.shape[0] # Project text prompts into visual/audio spaces delta_v = self.N_v(self.text_prompts) # (m, visual_dim) delta_a = self.N_a(self.text_prompts) # (m, audio_dim) # Prepend prompts to inputs by adding their mean as a prompt prefix signal # (A full implementation would use sequence-level concatenation inside the encoder) T_prompted = T + self.text_prompts.mean(0).unsqueeze(0).expand(B, -1) V_prompted = V + delta_v.mean(0).unsqueeze(0).expand(B, -1) A_prompted = A + delta_a.mean(0).unsqueeze(0).expand(B, -1) F_T = text_enc(T_prompted) F_V = visual_enc(V_prompted) F_A = audio_enc(A_prompted) # Concatenated multimodal feature F_M = torch.cat([F_T, F_V, F_A], dim=-1) return F_M, F_T, F_V, F_A # --------------------------------------------------------- # CUEP: Class-level Unimodal Emotion-opposing Prompting # --------------------------------------------------------- class CUEP(nn.Module): """ Maintains K positive and K negative prompt sets per modality. Text prompts follow fixed natural language templates (semantic polarity). Visual and audio prompts are learnable continuous vectors. """ def __init__(self, K: int, visual_dim: int, audio_dim: int, text_dim: int): super().__init__() self.K = K # Learnable visual and audio positive/negative prompts (K x dim) self.pos_v = nn.Parameter(torch.randn(K, visual_dim) * 0.02) self.neg_v = nn.Parameter(torch.randn(K, visual_dim) * 0.02) self.pos_a = nn.Parameter(torch.randn(K, audio_dim) * 0.02) self.neg_a = nn.Parameter(torch.randn(K, audio_dim) * 0.02) # Text prompts encoded from fixed templates "This video is [k]" / "not [k]" # In practice: tokenize + CLIP text encoder. Here: learnable with label supervision. self.pos_t = nn.Parameter(torch.randn(K, text_dim) * 0.02) self.neg_t = nn.Parameter(torch.randn(K, text_dim) * 0.02) # Fusion projections to shared feature space (dim = text+visual+audio combined) feat_dim = text_dim + visual_dim + audio_dim self.pos_proj = nn.Linear(feat_dim, feat_dim) self.neg_proj = nn.Linear(feat_dim, feat_dim) def encode_prompts( self, text_enc: FrozenEncoder, visual_enc: FrozenEncoder, audio_enc: FrozenEncoder, ) -> Tuple[torch.Tensor, torch.Tensor]: # Encode each class prompt through its modality encoder F_pos_t = text_enc(self.pos_t) # (K, enc_dim) F_pos_v = visual_enc(self.pos_v) F_pos_a = audio_enc(self.pos_a) F_pos_M = self.pos_proj(torch.cat([F_pos_t, F_pos_v, F_pos_a], dim=-1)) # (K, C) F_neg_t = text_enc(self.neg_t) F_neg_v = visual_enc(self.neg_v) F_neg_a = audio_enc(self.neg_a) F_neg_M = self.neg_proj(torch.cat([F_neg_t, F_neg_v, F_neg_a], dim=-1)) # (K, C) return F_pos_M, F_neg_M, F_pos_t # --------------------------------------------------------- # DPOL: Dual-stream Prompt-driven Open-set Learning # --------------------------------------------------------- def composite_distance(x: torch.Tensor, protos: torch.Tensor) -> torch.Tensor: """ ARPL-style composite distance: Euclidean minus dot product. x: (B, C) protos: (K, C) Returns: (B, K) """ euc = torch.cdist(x, protos) # (B, K) dot = torch.matmul(x, protos.T) # (B, K) return euc - dot def dpol_losses( F_M: torch.Tensor, F_pos_M: torch.Tensor, F_neg_M: torch.Tensor, F_pos_T: torch.Tensor, labels: torch.Tensor, ) -> Tuple[torch.Tensor, torch.Tensor]: """ Known-class emotion recognition stream: cosine similarity to positive text features. Unknown-class discovery stream: contrastive distance score (D_neg - D_pos). """ # Stream 1: recognition via cosine similarity to positive textual features cos_sim = F.normalize(F_M, dim=-1) @ F.normalize(F_pos_T, dim=-1).T # (B, K) L_emo = F.cross_entropy(cos_sim, labels) # Stream 2: open-set discovery via contrastive distance score D_pos = composite_distance(F_M, F_pos_M) # (B, K) D_neg = composite_distance(F_M, F_neg_M) # (B, K) contrast_score = D_neg - D_pos # higher = closer to positive L_osr = F.cross_entropy(contrast_score, labels) return L_emo, L_osr # --------------------------------------------------------- # Full HCEP model # --------------------------------------------------------- class HCEP(nn.Module): """ Hierarchical Cross-modal Emotion-interactive Prompting (HCEP). Adapts frozen pretrained multimodal encoders for open-set emotion recognition. """ def __init__( self, K: int, text_enc_dim: int = 64, visual_enc_dim: int = 64, audio_enc_dim: int = 64, m: int = 2, ): super().__init__() self.text_enc = FrozenEncoder(text_enc_dim) self.visual_enc = FrozenEncoder(visual_enc_dim) self.audio_enc = FrozenEncoder(audio_enc_dim) self.smep = SMEP(text_enc_dim, visual_enc_dim, audio_enc_dim, m=m) self.cuep = CUEP(K, visual_enc_dim, audio_enc_dim, text_enc_dim) def forward( self, T: torch.Tensor, V: torch.Tensor, A: torch.Tensor, labels: torch.Tensor ) -> Tuple[torch.Tensor, torch.Tensor]: # SMEP: unified multimodal feature F_M, F_T, F_V, F_A = self.smep( self.text_enc, self.visual_enc, self.audio_enc, T, V, A ) # CUEP: positive/negative class prototypes F_pos_M, F_neg_M, F_pos_T = self.cuep.encode_prompts( self.text_enc, self.visual_enc, self.audio_enc ) # DPOL: dual-stream losses L_emo, L_osr = dpol_losses(F_M, F_pos_M, F_neg_M, F_pos_T, labels) total_loss = L_emo + L_osr return total_loss, F_M def predict( self, T: torch.Tensor, V: torch.Tensor, A: torch.Tensor ) -> Tuple[torch.Tensor, torch.Tensor]: """Returns confidence scores and predicted labels at inference.""" F_M, _, _, _ = self.smep( self.text_enc, self.visual_enc, self.audio_enc, T, V, A ) F_pos_M, F_neg_M, _ = self.cuep.encode_prompts( self.text_enc, self.visual_enc, self.audio_enc ) D_pos = composite_distance(F_M, F_pos_M) D_neg = composite_distance(F_M, F_neg_M) scores = torch.softmax(D_neg - D_pos, dim=-1) confidence = scores.max(dim=-1).values pred_label = scores.argmax(dim=-1) return confidence, pred_label # --------------------------------------------------------- # Training loop # --------------------------------------------------------- def train_epoch(model, optimizer, T, V, A, labels): model.train() optimizer.zero_grad() loss, _ = model(T, V, A, labels) loss.backward() optimizer.step() return loss.item() # --------------------------------------------------------- # Smoke test on synthetic tri-modal data # --------------------------------------------------------- if __name__ == "__main__": torch.manual_seed(42) K_classes = 6; B = 16 model = HCEP(K=K_classes, text_enc_dim=64, visual_enc_dim=64, audio_enc_dim=64) optimizer = torch.optim.SGD( [p for p in model.parameters() if p.requires_grad], lr=5e-4, momentum=0.9 ) # Synthetic inputs matching paper modality dimensions (flattened) T_batch = torch.randn(B, 128) V_batch = torch.randn(B, 128) A_batch = torch.randn(B, 128) labels = torch.randint(0, K_classes, (B,)) for epoch in range(3): loss_val = train_epoch(model, optimizer, T_batch, V_batch, A_batch, labels) print(f"Epoch {epoch+1} loss: {loss_val:.4f}") # Inference smoke test with threshold-based open-set decision model.eval() with torch.no_grad(): conf, pred = model.predict(T_batch, V_batch, A_batch) THRESHOLD = 0.63 decisions = ["known" if c >= THRESHOLD else "unknown" for c in conf] print(f"Confidence range: {conf.min():.3f} to {conf.max():.3f}") print(f"Decisions: {decisions[:8]}") print("Smoke test passed.")
Conclusion
The problem HCEP addresses is more fundamental than it might appear from the benchmark numbers. Most AI-powered emotion recognition research has been built on an assumption so deeply embedded it rarely gets stated: that the emotions you will encounter at deployment are the emotions you trained on. This assumption is false in virtually every application that matters, from mental health screening to human-computer interaction research to behavioral analysis in educational settings. HCEP is the first multimodal framework to take this assumption off the table and replace it with a principled mechanism for detecting its violation.
The conceptual contribution is the hierarchical separation of two alignment problems that most prior work conflates. Aligning emotion representations across modalities (the SMEP problem) and sharpening the boundaries between emotion classes (the CUEP problem) are not the same task, they require different mechanisms, and solving them jointly through a unified dual-stream objective produces better results than solving either alone. That separation is a transferable design principle for any multimodal classification problem where the known/unknown boundary matters.
The sensitivity of the approach to prompt design is worth noting. Explicit textual negation outperforms fully learnable prompts for boundary-sensitive tasks. This may be a useful heuristic for practitioners working on prompt-tuned foundation models in other domains where you need to model what something is not, as much as what it is.
For domains with clinical implications, the honest summary is that HCEP represents a valuable step toward AI systems that know what they do not know. The current form of the system does not go far enough for clinical deployment: it lacks robustness to input noise and temporal misalignment, treats all unknown emotions identically, and has not been validated on clinical populations. These are exactly the research directions the authors themselves identify for future work, and they are the right directions. A system that detects emotional ambiguity and defers to human judgment is more useful in healthcare than a system that confabulates a confident classification.
The hardest part of open-set recognition is not the detection algorithm. It is convincing a field that optimizes for closed-set accuracy on known categories that the metric they are optimizing is the wrong one for real-world deployment. HCEP makes that argument concretely, with numbers, and that may be its most important contribution.
Frequently Asked Questions
Standard emotion recognition is a closed-set task: the model classifies test inputs into one of the emotion categories it was trained on. Open-set recognition adds the capability to detect when a test sample does not belong to any known category, flagging it as unknown rather than forcing a wrong classification. This matters whenever the model will be deployed in environments where novel emotional states are likely, such as clinical settings, cross-cultural applications, or any scenario involving compound or transitional emotions not represented in training data.
AUROC (Area Under the Receiver Operating Characteristic Curve) measures how well the model separates known from unknown samples across all possible confidence thresholds. A higher AUROC means the model’s confidence scores are better at distinguishing the two groups. OSCR (Open-Set Classification Rate) is stricter because it requires a sample to be both correctly accepted as known and correctly classified into the right category to count as a success. A model with high AUROC but low OSCR is good at detecting unknowns but unreliable at classifying the known emotions it accepts.
Text carries more direct and structured emotional semantics than visual or audio signals. A transcript provides explicit semantic content about what is being expressed, while visual and audio signals are more susceptible to individual variation, noise, and implicit expression. The paper tests three alternatives and text-anchored alignment consistently outperforms both visual-anchored and audio-anchored designs. This reflects a broader finding in multimodal AI that language provides the most stable reference point for aligning heterogeneous feature spaces.
HCEP is a research prototype and has not been validated for clinical use. The paper mentions depression detection and mental health monitoring as motivating applications, not as validated uses. The model has only been tested on academic benchmark datasets, assumes high-quality temporally aligned inputs that are unlikely in real clinical settings, and treats all unknown emotional states as a single undifferentiated category. Any application in a clinical context would require extensive validation on clinical populations, regulatory review, and should be designed as decision-support for qualified clinicians rather than an autonomous assessment tool.
For each known emotion category, CUEP maintains two sets of prompts. Positive prompts capture what the emotion looks, sounds, and reads like. Negative prompts capture what that category explicitly is not. For the text modality, positive prompts follow the template “This video is [emotion label]” and negative prompts follow “This video is not [emotion label]”, providing explicit semantic polarity through natural language. For visual and audio modalities, both positive and negative prompts are learnable continuous vectors, since raw visual and audio inputs cannot express semantic polarity directly. At inference, a sample that sits much closer to the positive features than to the negative features of some known class receives high confidence for that class.
Three main limitations are important. First, the framework assumes temporally aligned and high-quality multimodal inputs; performance degrades substantially with misaligned or noisy data. Second, all unknown emotions are collapsed into a single category, which limits usefulness in applications that need to distinguish between types of novel emotional states. Third, the benchmarks use academic datasets, not clinical or real-world deployment data, so performance estimates from the paper may not transfer to practical applications without further validation. The authors identify all three as directions for future work.
Read the full paper and explore the experimental details directly.
Read the Information Fusion Paper Explore More Prompt EngineeringThis analysis is based on the published paper and an independent evaluation of its claims.