HP2L Taught an AI to Think Like a Radiologist — Step by Step, Disease by Disease
A team from ShanghaiTech University, Henan Provincial People’s Hospital, and Shanghai United Imaging Intelligence built a hierarchical framework that classifies 23 brain disorders across three diagnostic levels, cuts the performance gap between coarse and fine-grained predictions to just 2%, and outperforms every comparable method by more than 8 percentage points on 54,360 subjects.
A radiologist does not look at a brain MRI and immediately shout “chronic hemorrhage.” She starts somewhere broader: is there a vascular abnormality at all? If yes, is it hemorrhagic or ischemic? Only after those calls does she narrow down to the specific subtype. That layered, divide-and-conquer reasoning is decades of training compressed into seconds. Teaching a deep learning model to replicate it — rather than just pattern-matching to a flat list of 23 labels — turns out to be genuinely hard. Yuxiao Liu, Kaicong Sun, and colleagues from ShanghaiTech just published a framework that takes this challenge seriously, and the numbers suggest they got it right.
What Flat Classification Gets Wrong
The dominant paradigm in medical image AI is still what researchers politely call “flat” classification: feed the scan in, produce a probability over every disease class simultaneously, pick the winner. It works surprisingly well when your dataset has thousands of examples per class and the classes are visually distinct. Brain disorders are neither of these things.
Consider the scale of the problem. The dataset used in this paper spans 23 brain disorders — from common conditions like white matter hyperintensity (WMH), which contributes 22,934 of the 54,360 subjects, to rare ones like penetrating deformity, which shows up in just 1,074 cases. That is a 21-fold ratio. When a flat classifier trains on this distribution, it learns to be very good at the common classes and quietly useless at the rare ones. The balanced accuracy metric exists precisely to expose this failure mode, and it exposes it badly: a standard ViT baseline drops from 85.53% balanced accuracy at the coarse level all the way down to 70.65% at the fine-grained level. That 14.88-point collapse is not a rounding error. Patients with rare subtypes are being misclassified at rates that would be unacceptable in clinical deployment.
The theoretical fix has been known for years. Hierarchical classification — organizing the task into coarse levels first, then progressively refining — mimics exactly how clinicians reason and naturally concentrates learning signal on the structural relationships between disease classes. But the practical implementation has a fatal flaw that most papers quietly ignore.
Once a hierarchical classifier commits to a higher-level decision, every subsequent prediction is locked into a subtree of that decision. If the model wrongly routes a sub-acute hemorrhage into the infarction branch at level two, there is no mechanism to correct that error at level three. The mistake propagates, amplifies, and the final prediction is doubly wrong. This is the error propagation problem, and it is the central motivation for everything in HP2L.
Existing hierarchical classifiers fix their top-level decisions before processing lower levels. One bad routing choice cascades through the hierarchy, making the final fine-grained prediction worse — not better — than a flat classifier. HP2L breaks this pattern by allowing prompt tokens to be dynamically refined at each level using evidence from class-specific prototypes, enabling cross-level correction rather than rigid top-down propagation.
The Three Innovations Behind HP2L
The HP2L framework — Hierarchical Prompt and Prototype Learning — introduces three interlinked components that together address the error propagation problem while maintaining the benefits of hierarchical structure.
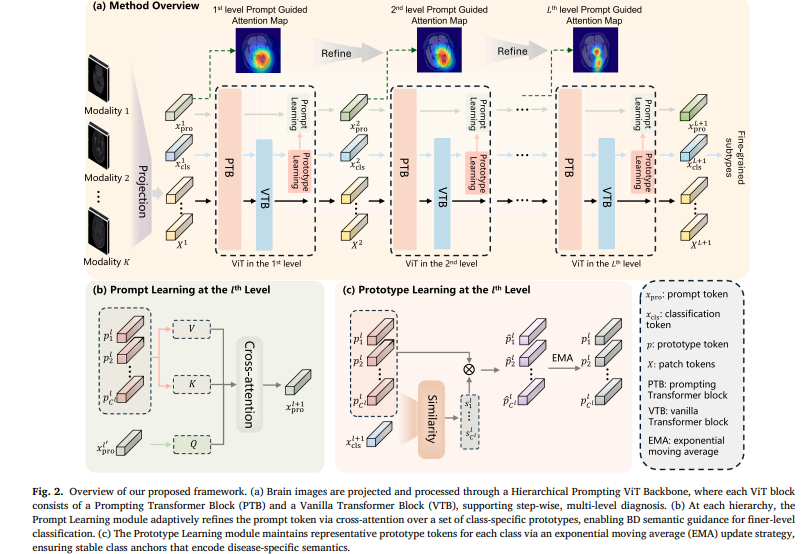
Hierarchical Prompting ViT Backbone
The backbone stacks three level-specific ViT blocks, one per diagnostic level. Each block processes the same input image but operates in a different context: the first block is tuned for coarse discrimination (vascular vs occupying vs developmental lesions), the second for intermediate distinction (hemorrhage vs infarction, tumor vs degeneration), and the third for fine-grained classification of all 23 subtypes.
Each block contains two sequential sub-units. The Prompting Transformer Block (PTB) operates on an extended token sequence that includes the image patch tokens, a classification token, and a dedicated prompt token. The prompt token carries the accumulated diagnostic context from higher levels and conditions the self-attention mechanism — the model’s visual reading is literally shaped by what it already suspects about the disease category. After the PTB, the Vanilla Transformer Block (VTB) refines the patch and classification tokens without the prompt token, giving the image features room to develop independently before the next level’s classification head reads from the updated CLS token.
The full token sequence fed into each PTB is:
The attention-based feature update in the PTB follows standard ViT mechanics, but the presence of the prompt token in the key-value space means the [CLS] token is always attended over diagnostic context as well as raw image content. This is not a trivial change — it means the fine-grained features extracted at level three are conditioned on both the image and the accumulated diagnostic guidance from levels one and two.
Prompt Learning: Refinement Instead of Propagation
Here is where the paper’s design departs most sharply from prior work. Rather than passing the prompt token from one level to the next unchanged, HP2L runs it through a cross-attention update against the class-specific prototype tokens at each level. The updated prompt token for the next level is computed as:
The query \(Q\) comes from the updated prompt token at the current level. The keys \(K\) and values \(V\) come from the learnable prototype tokens — one per disease class at each level. The attention weights \(\alpha_i\) measure how much the current prompt should incorporate each class’s semantic signature. The resulting \(x^{l+1}_{\text{pro}}\) is a dynamically weighted blend of class prototypes, shaped by what the model currently believes about the input.
This is not a small distinction. Fixed propagation means a wrong high-level prompt poisons every subsequent level. Prototype-guided refinement means a wrong high-level prompt can be corrected by the emerging lower-level evidence. If the image features at level two strongly suggest hemorrhage even though level one wavered between vascular and occupying, the cross-attention will weight the hemorrhage prototype highly and the updated prompt will steer level three toward hemorrhage subtypes. The hierarchy becomes bidirectionally informed rather than strictly top-down.
Prototype Learning with EMA Stabilization
The prototypes themselves need to be more than randomly initialized vectors. For the cross-attention mechanism to work well, each prototype must genuinely represent its class’s imaging semantics — not just the last batch’s examples, not an average corrupted by outliers, but a stable, accumulated summary of what each disease class looks like in the model’s learned feature space.
The prototype update rule is an exponential moving average applied after every training batch:
The momentum coefficient \(\alpha = 0.99\) is deliberately high. That means each update only incorporates 1% of the current batch’s class representation — a design choice that makes prototypes robust to noisy batches, class imbalance, and the inherent variability of medical imaging data across scanners and sites. When a particular class is absent from a batch entirely, its prototype simply holds its previous value unchanged. For rare classes like penetrating deformity with only 1,074 training examples, this stability is critical.
The prototypes are initialized from a zero-mean Gaussian and accumulate semantic meaning progressively during training. By the time the model is fully trained, each prototype represents a compact, denoised summary of its disease class across all training batches — a semantic anchor that the prompt token can attend to for reliable guidance.
Without EMA stabilization, prototype tokens trained with standard gradient descent show high variance for rare classes, where individual batches may contain zero or one example. EMA provides noise-robust accumulation: each prototype integrates information from every training step, not just recent ones. The ablation shows that removing EMA from the prototype update drops balanced accuracy at the finest level from 88.43% to 85.90% — a 2.5-point hit concentrated precisely on the rare, clinically important disease subtypes.
Training Objective: Consistency Across Levels
HP2L is trained end-to-end with a loss function that has two components. The first is a standard sigmoid-based binary cross-entropy applied independently at each hierarchical level:
The second component is a hierarchy-consistency penalty that penalizes cases where a child class has lower predicted probability than its parent, when the child is a true positive:
The intuition here is worth spelling out carefully. When a fine-grained class is truly present, its probability should be at least as high as its parent’s probability. The consistency loss only fires in one direction — it never penalizes fine-grained confidence that exceeds coarse-level confidence, because that is exactly the behavior you want when fine-grained evidence is strong. The penalty is asymmetric by design.
The full training objective combines all level-wise losses and the consistency term:
The Data: 54,360 Subjects Across Six Cohorts
The scale and heterogeneity of the validation deserves its own discussion, because it is unusually serious for a medical AI paper.
The primary training cohort comes from Henan Provincial People’s Hospital — 47,227 subjects with diagnostic labels extracted from radiology reports using an NLP entity-matching pipeline. The team manually quality-checked a random 10% subset before trusting the pipeline at scale, which is the kind of methodological care that does not always make it into the methods section but matters enormously for label reliability. The remaining subjects come from three public research cohorts: ADNI (1,432 subjects), OASIS (823), and NACC (3,989), contributing mainly Alzheimer’s disease and MCI labels.
The real test of generalizability comes from two fully independent external cohorts that were never seen during training. Cohort A is from Fuwai Central China Cardiovascular Disease Hospital (329 cases focusing on cerebral small vessel disease). Cohort B is from the First Hospital of Xi’an (560 tumor cases). Different institutions, different scanners, different disease focuses — and the model had no access to any of them during training or validation.
All five MRI sequences (T1, T2, FLAIR, DWI, ADC) are concatenated as channels. Missing modalities — which are common in heterogeneous multi-center data — are handled by zero-filling the missing channel. The model processes 3D volumes at 193×229×193 voxels with 1.5mm isotropic spacing, mapped to a 32-token sequence via a 3D CNN encoder before entering the transformer hierarchy.
Results: Where HP2L Pulls Away
The headline numbers are strong. HP2L achieves 88.43% balanced accuracy at the fine-grained third level, compared to 83.14% for TransHP (the best-performing hierarchical baseline) and 80.01% for HPDT. That 8.42-point gap over the best prior method is not marginal. On a task with 23 classes and severe class imbalance, closing that gap matters clinically.
| Method | Level 1 BAcc | Level 1 AUC | Level 3 BAcc | Level 3 AUC | BAcc Drop |
|---|---|---|---|---|---|
| ViT | 85.53% | 85.22% | 70.65% | 71.87% | 14.88% |
| PromptViT | 87.19% | 85.77% | 73.11% | 73.21% | 14.08% |
| TransHP | 89.22% | 91.37% | 83.14% | 82.37% | 4.08% |
| HPDT | 87.23% | 87.01% | 80.01% | 80.12% | 7.22% |
| HP2L (Ours) | 90.45% | 90.03% | 88.43% | 87.58% | 2.02% |
Table: Performance comparison across hierarchical levels. HP2L’s 2.02% drop from level 1 to level 3 is dramatically smaller than all competing methods, confirming that prompt refinement effectively contains error propagation. All improvements statistically significant at p < 0.05 via paired bootstrap.
The performance gap metric — the drop from level 1 to level 3 — is where HP2L’s design advantage is most visible. A 2.02% drop compared to 14.88% for vanilla ViT. That four-versus-fifteen-point comparison is not just a number; it reflects whether the hierarchical structure helps or hurts. For all non-hierarchical methods, adding hierarchy makes things worse at lower levels because errors propagate. For HP2L, the hierarchy is a genuine benefit at every level because the prompt refinement mechanism contains the damage from any single wrong prediction.
Long-Tail Classes: Where the Gains Are Clinically Meaningful
Fine-grained AUC comparisons across individual disease subtypes reveal where the improvement lands. Penetrating deformity — just 1,074 training cases — improves from 72.25% AUC (TransHP) to 80.94% (HP2L). MCI improves from 76.47% to 83.46%. The three hemorrhage subtypes all show consistent gains. These are the classes where clinical misdiagnosis is most costly and where current AI systems most reliably fail.
The external cohort results reinforce this story. On Cohort A (cerebral small vessel disease), cerebral microbleeds — genuinely subtle small lesions — improve from 66.10% AUC for the ViT baseline to 83.88% for HP2L. On Cohort B (tumors), metastatic tumor classification improves from 70.28% to 86.64%. These are not test-set overfitting artifacts. These improvements appear on data from entirely different hospitals with different equipment.
“HP2L can revise a suboptimal higher-level preference and reach the correct final label — whereas other methods remain on an incorrect trajectory throughout the hierarchy.” — Liu et al., Medical Image Analysis 2026
Interpretability: What the Model Actually Sees
The attention dynamics across hierarchical levels are one of the most clinically compelling aspects of the paper. At each level, the prompt token attends over image patches — and the resulting attention maps shift in a medically coherent way as the hierarchy deepens.
For hemorrhage cases, level-one attention spreads broadly over the lateral ventricles. By level three, it has narrowed to the boundary of the specific lesion — the exact feature radiologists use to distinguish acute from chronic hemorrhage based on signal intensity at the hematoma margins. For infarction, attention progressively concentrates on the infarction center, matching clinical practice where subtype discrimination depends on the lesion core rather than surrounding edema. For tumors, early attention covers both the mass and surrounding edema, while final-level attention isolates the tumor center itself — reflecting the clinical importance of distinguishing primary tumor morphology from secondary reactive tissue changes.
The prompt-to-prototype attention heatmaps are also worth examining. The 1st-level heatmap shows vascular cases strongly attending to the Vascular prototype and occupying lesions attending to the Occupying prototype. The 3rd-level heatmap shows more distributed attention, with non-zero weights spilling into adjacent disease prototypes. This is not a bug — it reflects genuine imaging similarity between related conditions. Meningioma and metastatic tumor share radiological features that even experienced radiologists find challenging to distinguish. The model is capturing that ambiguity rather than hiding it.
The prototype evolution during training is equally revealing. At epoch 10, all prototype tokens cluster together with no meaningful separation. By epoch 50, the coarse-level prototypes begin to separate. By epoch 100, the full hierarchical structure of the taxonomy has emerged in the embedding space — fine-grained subtypes cluster around their parent prototypes, and the three coarse groups are well separated. The model has learned the same organizational structure that clinicians use, without that structure being explicitly enforced beyond the hierarchical loss function.
Ablation Studies: What Each Component Actually Contributes
The ablation results deserve careful reading because they reveal which design choices matter and by how much.
On prompt configuration: removing all prompting drops level-3 balanced accuracy from 88.43% to 71.28%. Adding static one-hot prompts barely helps (72.26%). Learnable prompts without prototype guidance reach 80.47%. Only when learnable prompts are updated via prototype cross-attention does performance jump to 88.43%. The prototype refinement mechanism is not a minor addition — it is responsible for roughly 8 of the 17 percentage points gained over the no-prompt baseline.
On prototype configuration: removing prototypes entirely drops level-3 BAcc to 73.75%. Fixed one-hot prototype tokens (simple class identifiers) reach 79.91%. Learnable prototypes without EMA reach 85.90%. HP2L with EMA achieves 88.43%. The stabilization provided by exponential moving average contributes a 2.53-point gain concentrated precisely on the rare, fine-grained classes where individual batch variance is highest.
On hierarchy depth: flat (no hierarchy) yields 74.23% BAcc. Two-level hierarchy reaches 82.38%. Three-level reaches 88.43%. Each additional level of hierarchy contributes a roughly 6-point gain — a remarkably consistent scaling behavior that validates the core architectural design choice.
Complete Proposed Model Code (PyTorch)
The following is a complete PyTorch implementation of HP2L as described in Sections 3.1 through 3.4 of the paper. It covers the full three-level hierarchical ViT backbone with PTB and VTB sub-blocks, the cross-attention Prompt Learning module, the EMA-based Prototype Learning module, the level-wise classification heads, the combined training loss with hierarchy consistency penalty, and a runnable smoke test on synthetic 3D brain MRI data.
# =============================================================================
# HP2L: Hierarchical Prompt and Prototype Learning for Brain Disorder Diagnosis
# Paper: "A hierarchical prompt and prototype learning framework for brain
# disorder classification"
# Authors: Yuxiao Liu et al., ShanghaiTech / Henan Provincial People's Hospital
# Journal: Medical Image Analysis 112 (2026) 104063
# =============================================================================
from __future__ import annotations
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import List, Dict, Optional, Tuple
# ─── SECTION 1: Utility — Multi-Head Self-Attention and Feed-Forward ──────────
class MultiHeadSelfAttention(nn.Module):
"""Standard multi-head self-attention as used in both PTB and VTB.
For PTB, the input sequence includes the prompt token.
For VTB, the prompt token is excluded — only patch and CLS tokens.
All mathematical operations follow Equations 4-8 in the paper.
"""
def __init__(self, D: int, H: int):
super().__init__()
self.H = H
self.d_h = D // H
self.scale = math.sqrt(self.d_h)
self.W_Q = nn.Linear(D, D, bias=False)
self.W_K = nn.Linear(D, D, bias=False)
self.W_V = nn.Linear(D, D, bias=False)
self.W_O = nn.Linear(D, D, bias=False)
self.dropout = nn.Dropout(0.1)
def forward(self, x: torch.Tensor) -> torch.Tensor:
B, N, D = x.shape
Q = self.W_Q(x).view(B, N, self.H, self.d_h).transpose(1, 2)
K = self.W_K(x).view(B, N, self.H, self.d_h).transpose(1, 2)
V = self.W_V(x).view(B, N, self.H, self.d_h).transpose(1, 2)
attn = self.dropout(torch.softmax(Q @ K.transpose(-2, -1) / self.scale, dim=-1))
out = (attn @ V).transpose(1, 2).contiguous().view(B, N, D)
return self.W_O(out)
class FeedForwardNetwork(nn.Module):
"""Position-wise FFN with GELU activation, as in standard ViT blocks."""
def __init__(self, D: int, ffn_dim: int = None):
super().__init__()
ffn_dim = ffn_dim or D * 4
self.net = nn.Sequential(
nn.Linear(D, ffn_dim),
nn.GELU(),
nn.Dropout(0.1),
nn.Linear(ffn_dim, D),
nn.Dropout(0.1),
)
def forward(self, x): return self.net(x)
# ─── SECTION 2: PTB — Prompting Transformer Block ────────────────────────────
class PromptingTransformerBlock(nn.Module):
"""PTB: processes the full token sequence including the prompt token.
Implements the operation described in Equations 1-9:
Z^l = [x_cls, x_pro, x_1, ..., x_N]
After PTB, the updated prompt token x_pro' is extracted and forwarded
to the Prompt Learning module; [CLS] and patch tokens go to VTB.
"""
def __init__(self, D: int, H: int):
super().__init__()
self.ln1 = nn.LayerNorm(D)
self.attn = MultiHeadSelfAttention(D, H)
self.ln2 = nn.LayerNorm(D)
self.ffn = FeedForwardNetwork(D)
def forward(self, x_cls: torch.Tensor, x_pro: torch.Tensor,
X: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
"""
Parameters
----------
x_cls : (B, 1, D) classification token
x_pro : (B, 1, D) prompt token
X : (B, N, D) patch tokens
Returns updated (x_cls', x_pro', X')
"""
B, N, D = X.shape
# Concatenate full sequence including prompt token
Z = torch.cat([x_cls, x_pro, X], dim=1) # (B, N+2, D)
Z = Z + self.attn(self.ln1(Z))
Z = Z + self.ffn(self.ln2(Z))
x_cls_p = Z[:, 0:1, :] # updated CLS
x_pro_p = Z[:, 1:2, :] # updated prompt
X_p = Z[:, 2:, :] # updated patch tokens
return x_cls_p, x_pro_p, X_p
# ─── SECTION 3: VTB — Vanilla Transformer Block ───────────────────────────────
class VanillaTransformerBlock(nn.Module):
"""VTB: refines CLS and patch tokens without the prompt token.
Implements Equation 10: [x_cls^{l+1}, X^{l+1}] = B_van([x_cls', X']).
By intentionally excluding the prompt token from this stage, the VTB
allows image features to develop independently of diagnostic priors,
creating a clean separation of concerns between prompting and refinement.
"""
def __init__(self, D: int, H: int):
super().__init__()
self.ln1 = nn.LayerNorm(D)
self.attn = MultiHeadSelfAttention(D, H)
self.ln2 = nn.LayerNorm(D)
self.ffn = FeedForwardNetwork(D)
def forward(self, x_cls: torch.Tensor,
X: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
"""Operates on CLS + patch tokens only (no prompt token)."""
Z = torch.cat([x_cls, X], dim=1) # (B, N+1, D)
Z = Z + self.attn(self.ln1(Z))
Z = Z + self.ffn(self.ln2(Z))
return Z[:, 0:1, :], Z[:, 1:, :] # updated CLS, X
# ─── SECTION 4: Prompt Learning Module ───────────────────────────────────────
class PromptLearningModule(nn.Module):
"""Refines the prompt token via cross-attention over class prototypes.
Implements Equations 11-15:
Q = x_pro' W_Q (query from updated prompt token)
K = P^l W_K (keys from class prototype tokens)
V = P^l W_V (values from class prototype tokens)
alpha_i = Softmax_i(QK^T / sqrt(d))
x_pro^{l+1} = sum_i alpha_i V_i
This mechanism allows the prompt for the next level to be a
dynamically weighted blend of class-specific semantic anchors,
enabling evidence-driven correction rather than fixed propagation.
"""
def __init__(self, D: int, d: int = None):
super().__init__()
d = d or D
self.W_Q = nn.Linear(D, d, bias=False)
self.W_K = nn.Linear(D, d, bias=False)
self.W_V = nn.Linear(D, d, bias=False)
self.out_proj = nn.Linear(d, D, bias=False)
self.scale = math.sqrt(d)
self.ln = nn.LayerNorm(D)
def forward(self, x_pro_prime: torch.Tensor,
prototypes: torch.Tensor) -> torch.Tensor:
"""
Parameters
----------
x_pro_prime : (B, 1, D) updated prompt token from PTB
prototypes : (C_l, D) class prototype tokens for current level
Returns
-------
x_pro_next : (B, 1, D) refined prompt token for next level
"""
B = x_pro_prime.shape[0]
C = prototypes.shape[0]
# Expand prototypes to batch dimension
P = prototypes.unsqueeze(0).expand(B, -1, -1) # (B, C, D)
Q = self.W_Q(x_pro_prime) # (B, 1, d)
K = self.W_K(P) # (B, C, d)
V = self.W_V(P) # (B, C, d)
# Attention weights alpha: how much to attend to each class prototype
alpha = torch.softmax(Q @ K.transpose(-2, -1) / self.scale, dim=-1)
attended = alpha @ V # (B, 1, d)
x_pro_next = x_pro_prime + self.out_proj(attended) # residual update
return self.ln(x_pro_next)
# ─── SECTION 5: Prototype Learning with EMA Update ───────────────────────────
class PrototypeLearning(nn.Module):
"""Maintains per-class prototype tokens at each diagnostic level.
Prototypes are updated after each mini-batch using exponential moving
average (EMA) as described in Equations 16-17:
x_bar_c = mean of CLS tokens for class c in current batch
p_c^t = alpha * p_c^{t-1} + (1 - alpha) * x_bar_c
When class c is absent from the batch, its prototype retains its
previous value unchanged. This provides stability for rare classes
that may appear in only a fraction of training batches.
Parameters
----------
C : number of disease classes at this level
D : token dimension (768)
alpha : EMA momentum coefficient (default 0.99 per paper)
"""
def __init__(self, C: int, D: int, alpha: float = 0.99):
super().__init__()
self.C = C
self.alpha = alpha
# Prototype tokens initialized from N(0,1) as in Section 3.3
self.register_buffer('prototypes', torch.randn(C, D))
def get_prototypes(self) -> torch.Tensor:
"""Return current prototype embeddings: (C, D)."""
return self.prototypes
@torch.no_grad()
def update(self, x_cls_batch: torch.Tensor,
labels: torch.Tensor) -> None:
"""EMA prototype update for one training batch.
Parameters
----------
x_cls_batch : (B, D) CLS tokens for the current batch
labels : (B, C) multi-label ground-truth at this level
(binary matrix — a subject can have multiple labels)
"""
for c in range(self.C):
# Find samples with ground-truth label c present
mask = labels[:, c].bool()
if mask.sum() > 0:
x_bar_c = x_cls_batch[mask].mean(dim=0) # mean CLS for class c
self.prototypes[c] = (
self.alpha * self.prototypes[c]
+ (1 - self.alpha) * x_bar_c
)
# If class absent: prototype unchanged (no-op)
# ─── SECTION 6: Level-Specific ViT Block ──────────────────────────────────────
class HierarchicalViTBlock(nn.Module):
"""One level of the HP2L backbone: PTB + Prompt Learning + VTB.
The complete inference loop at level l:
1. PTB: process [CLS, prompt, patches] together → updated tokens
2. Prompt Learning: refine prompt via cross-attention over prototypes
3. VTB: refine CLS and patch tokens without prompt token
4. Classification head: predict y_hat^l from updated CLS token
5. Prototype update (during training): EMA update of prototype tokens
"""
def __init__(self, D: int, H: int, C_l: int):
super().__init__()
self.ptb = PromptingTransformerBlock(D, H)
self.prompt_learn = PromptLearningModule(D)
self.vtb = VanillaTransformerBlock(D, H)
self.prototype_learn = PrototypeLearning(C_l, D)
# Classification head: project CLS token to C_l logits
self.cls_head = nn.Linear(D, C_l)
self.C_l = C_l
def forward(
self,
x_cls: torch.Tensor,
x_pro: torch.Tensor,
X: torch.Tensor,
labels: Optional[torch.Tensor] = None,
) -> Dict:
"""
Parameters
----------
x_cls : (B, 1, D) CLS token from previous level
x_pro : (B, 1, D) prompt token from previous level
X : (B, N, D) patch tokens
labels : (B, C_l) ground-truth labels for EMA update (training only)
Returns dict with next-level tokens, logits, and updated CLS.
"""
# (1) Prompting Transformer Block
x_cls_p, x_pro_p, X_p = self.ptb(x_cls, x_pro, X)
# (2) Prompt Learning: refine prompt via prototype cross-attention
prototypes = self.prototype_learn.get_prototypes()
x_pro_next = self.prompt_learn(x_pro_p, prototypes)
# (3) Vanilla Transformer Block: refine CLS and patches
x_cls_next, X_next = self.vtb(x_cls_p, X_p)
# (4) Classification head: predict logits from updated CLS
logits = self.cls_head(x_cls_next.squeeze(1)) # (B, C_l)
# (5) Prototype EMA update (training only)
if labels is not None and self.training:
self.prototype_learn.update(x_cls_next.squeeze(1).detach(), labels)
return {
'x_cls': x_cls_next,
'x_pro': x_pro_next,
'X': X_next,
'logits': logits,
}
# ─── SECTION 7: Image Feature Encoder (3D CNN → token sequence) ──────────────
class BrainMRIEncoder(nn.Module):
"""3D CNN encoder: maps (B, 5, H, W, D) → (B, 32, token_dim).
Performs four spatial downsampling stages as in Section 4.2,
producing a dense feature grid of size 32 x 12 x 14 x 12.
The 32 spatial tokens are linearly projected to D=768.
Input: 5 MRI sequences (T1, T2, FLAIR, DWI, ADC) concatenated as channels.
Missing modalities are zero-filled before concatenation.
"""
def __init__(self, in_channels: int = 5, D: int = 768):
super().__init__()
self.cnn = nn.Sequential(
nn.Conv3d(in_channels, 32, kernel_size=3, stride=2, padding=1),
nn.GroupNorm(8, 32), nn.GELU(),
nn.Conv3d(32, 64, kernel_size=3, stride=2, padding=1),
nn.GroupNorm(16, 64), nn.GELU(),
nn.Conv3d(64, 128, kernel_size=3, stride=2, padding=1),
nn.GroupNorm(16, 128), nn.GELU(),
nn.Conv3d(128, 32, kernel_size=3, stride=2, padding=1),
nn.GroupNorm(8, 32), nn.GELU(),
)
# After 4 downsampling stages: spatial dims -> /16 each axis
# Project 32 feature channels to token dimension D
self.token_proj = nn.Linear(32, D)
self.D = D
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Parameters
----------
x : (B, 5, H, W, D_depth) multi-modal 3D brain MRI
Returns
-------
tokens : (B, N, D) flattened spatial tokens with N = HxWxD / 16^3
"""
feat = self.cnn(x) # (B, 32, H', W', D')
B, C, H, W, Dp = feat.shape
tokens = feat.permute(0, 2, 3, 4, 1).reshape(B, H * W * Dp, C)
return self.token_proj(tokens) # (B, N, D)
# ─── SECTION 8: HP2L Full Framework ──────────────────────────────────────────
class HP2L(nn.Module):
"""HP2L: Hierarchical Prompt and Prototype Learning for BD Diagnosis.
Implements the full three-level hierarchical classification framework
described in Sections 3.1-3.4 and Algorithm 1 of the paper.
Three diagnostic levels:
Level 1: C1 = 4 (vascular, occupying, developmental, normal)
Level 2: C2 = 6 (hemorrhage, infarction, WMH, tumor, degeneration,
deformity)
Level 3: C3 = 16 (23 BDs; 15 disease subtypes + normal)
At inference: single forward pass produces predictions for all levels.
No additional post-processing required for clinical deployment.
"""
def __init__(self,
class_hierarchy: List[int] = [4, 6, 16],
D: int = 768,
H: int = 12,
in_channels: int = 5):
super().__init__()
self.L = len(class_hierarchy)
self.D = D
# 3D CNN feature encoder
self.encoder = BrainMRIEncoder(in_channels, D)
# Learnable initial CLS and prompt tokens
self.x_cls_init = nn.Parameter(torch.randn(1, 1, D))
self.x_pro_init = nn.Parameter(torch.randn(1, 1, D))
# One HierarchicalViTBlock per diagnostic level
self.levels = nn.ModuleList([
HierarchicalViTBlock(D, H, C_l)
for C_l in class_hierarchy
])
# Label smoothing factor as per Section 4.2
self.label_smoothing = 0.1
def forward(self, images: torch.Tensor,
labels_per_level: Optional[List[torch.Tensor]] = None
) -> Dict:
"""
Parameters
----------
images : (B, 5, H, W, D_depth) multi-modal 3D brain MRI
labels_per_level: list of L label tensors, each (B, C_l), for
prototype EMA update during training (optional)
Returns
-------
dict with:
'logits_per_level' : list of (B, C_l) tensors
'cls_per_level' : list of (B, 1, D) CLS tokens for attention viz
"""
B = images.shape[0]
# Extract patch token sequence from 3D CNN encoder
X = self.encoder(images) # (B, N, D)
# Initialize CLS and prompt tokens, expand to batch size
x_cls = self.x_cls_init.expand(B, -1, -1).clone() # (B, 1, D)
x_pro = self.x_pro_init.expand(B, -1, -1).clone() # (B, 1, D)
logits_per_level = []
cls_per_level = []
for l, level_block in enumerate(self.levels):
labels_l = labels_per_level[l] if labels_per_level else None
out = level_block(x_cls, x_pro, X, labels=labels_l)
# Pass updated tokens to next level
x_cls = out['x_cls']
x_pro = out['x_pro']
X = out['X']
logits_per_level.append(out['logits'])
cls_per_level.append(x_cls)
return {
'logits_per_level': logits_per_level,
'cls_per_level': cls_per_level,
}
# ─── SECTION 9: Loss Functions ────────────────────────────────────────────────
def level_classification_loss(logits: torch.Tensor,
labels: torch.Tensor,
smoothing: float = 0.1) -> torch.Tensor:
"""Level-wise sigmoid binary cross-entropy with label smoothing (Eq. 18).
Uses BCEWithLogits applied element-wise over all class labels.
Label smoothing prevents overconfidence on noisy multi-center labels.
"""
labels_smooth = labels.float() * (1 - smoothing) + 0.5 * smoothing
return F.binary_cross_entropy_with_logits(logits, labels_smooth)
def hierarchy_consistency_loss(
logits_per_level: List[torch.Tensor],
labels_per_level: List[torch.Tensor],
parent_map: List[Dict[int, int]],
) -> torch.Tensor:
"""Hierarchy-consistency penalty across adjacent diagnostic levels (Eq. 19).
For each true child label c, penalize max(0, p_parent - p_child).
This asymmetric penalty never suppresses fine-grained confidence
that exceeds coarse confidence — it only fires when fine-grained
evidence lags behind coarse evidence for a true positive class.
Parameters
----------
logits_per_level : list of (B, C_l) logit tensors
labels_per_level : list of (B, C_l) ground-truth label tensors
parent_map : list of dicts mapping child class index -> parent
class index at the preceding level
"""
consist_loss = torch.tensor(0.0, device=logits_per_level[0].device)
B = logits_per_level[0].shape[0]
for l in range(len(logits_per_level) - 1):
probs_coarse = torch.sigmoid(logits_per_level[l]) # (B, C_l)
probs_fine = torch.sigmoid(logits_per_level[l + 1]) # (B, C_{l+1})
labels_fine = labels_per_level[l + 1].float()
for child_idx, parent_idx in parent_map[l].items():
if child_idx >= probs_fine.shape[1] or parent_idx >= probs_coarse.shape[1]:
continue
p_child = probs_fine[:, child_idx]
p_parent = probs_coarse[:, parent_idx]
y_child = labels_fine[:, child_idx]
penalty = y_child * torch.clamp(p_parent - p_child, min=0)
consist_loss = consist_loss + penalty.mean()
return consist_loss
def hp2l_total_loss(
logits_per_level: List[torch.Tensor],
labels_per_level: List[torch.Tensor],
parent_map: List[Dict[int, int]],
lambda_levels: List[float] = [1.0, 1.0, 1.0],
lambda_consist: float = 0.5,
label_smoothing: float = 0.1,
) -> Dict[str, torch.Tensor]:
"""Full training objective (Eq. 20): level-wise BCE + consistency penalty.
Returns dict with 'total', 'cls_losses', and 'consist' for logging.
"""
cls_losses = [
level_classification_loss(logits_per_level[l], labels_per_level[l],
label_smoothing)
for l in range(len(logits_per_level))
]
total_cls = sum(lambda_levels[l] * cls_losses[l] for l in range(len(cls_losses)))
consist = hierarchy_consistency_loss(logits_per_level, labels_per_level, parent_map)
total = total_cls + lambda_consist * consist
return {'total': total, 'cls_losses': cls_losses, 'consist': consist}
# ─── SECTION 10: Smoke Test — Synthetic Brain MRI Data ───────────────────────
def _smoke_test():
"""End-to-end smoke test of HP2L on synthetic 3D brain MRI data.
Verifies:
- Forward pass through full 3-level hierarchical backbone
- EMA prototype updates during training
- Loss computation with hierarchy-consistency penalty
- Gradient flow through all components
"""
print("=" * 65)
print("HP2L Smoke Test — Synthetic 3D Brain MRI Data")
print("Paper: Liu et al., Medical Image Analysis 112 (2026) 104063")
print("=" * 65)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(ff"\nDevice: {device}")
# Small model config for fast smoke test
B = 4 # batch size
H_vol, W_vol, D_vol = 64, 64, 32 # reduced spatial dimensions
D_model = 256 # token dimension (768 in paper)
num_heads = 8
class_hierarchy = [4, 6, 16] # 3-level BD hierarchy from paper
# Synthetic multi-modal 3D brain MRI: (B, 5 modalities, H, W, D)
images = torch.randn(B, 5, H_vol, W_vol, D_vol, device=device)
# Synthetic multi-label ground-truth for each diagnostic level
labels = [
torch.randint(0, 2, (B, C), device=device).float()
for C in class_hierarchy
]
# Simple parent-child mapping for consistency loss
# Level 0->1: coarse class -> intermediate (example mapping)
parent_map = [
{0: 0, 1: 0, 2: 0, 3: 1, 4: 1, 5: 2}, # level 1->2
{i: i // 3 for i in range(16)}, # level 2->3
]
# Instantiate HP2L with small model config
model = HP2L(
class_hierarchy=class_hierarchy,
D=D_model,
H=num_heads,
in_channels=5,
).to(device)
model.train()
total_params = sum(p.numel() for p in model.parameters())
print(ff"Total parameters: {total_params:,}")
print(ff"Input shape: {list(images.shape)}")
print(ff"Class hierarchy: {class_hierarchy}")
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4, weight_decay=1e-2)
# Forward pass
out = model(images, labels_per_level=labels)
logits_per_level = out['logits_per_level']
# Compute full training objective
loss_dict = hp2l_total_loss(
logits_per_level, labels, parent_map,
lambda_levels=[1.0, 1.0, 1.0],
lambda_consist=0.5,
label_smoothing=0.1,
)
optimizer.zero_grad()
loss_dict['total'].backward()
optimizer.step()
print(ff"\n{'─'*45}")
print(ff"Total loss: {loss_dict['total'].item():.4f}")
print(ff"Level-1 cls loss: {loss_dict['cls_losses'][0].item():.4f}")
print(ff"Level-2 cls loss: {loss_dict['cls_losses'][1].item():.4f}")
print(ff"Level-3 cls loss: {loss_dict['cls_losses'][2].item():.4f}")
print(ff"Consistency loss: {loss_dict['consist'].item():.4f}")
print(ff"Logit shapes: {[list(l.shape) for l in logits_per_level]}")
print(f"{'─'*45}")
# Verify inference mode (no labels, no prototype update)
model.eval()
with torch.no_grad():
out_inf = model(images)
probs = [torch.sigmoid(l) for l in out_inf['logits_per_level']]
print(ff"\nInference level-3 mean probability: {probs[2].mean().item():.3f}")
print("Smoke test passed. HP2L forward and backward cycles OK.")
print("See Algorithm 1 in Liu et al. 2026 for the full inference workflow.")
print("=" * 65)
if __name__ == '__main__':
_smoke_test()
What This Opens Up — and Where the Gaps Remain
The external cohort results suggest something clinically important about HP2L’s generalizability. When a model trained on Henan Provincial People’s Hospital data is tested on two different institutions with different scanners, different patient populations, and different disease focuses, the performance does not collapse. That is not guaranteed by any property of the architecture — it has to be earned through the combination of multi-center training data, robust prototype representations that are not scanner-specific, and a hierarchical structure that reflects genuine pathological taxonomy rather than dataset-specific patterns.
The failure modes are worth understanding too. The interpretability study flags cases where HP2L still struggles: tiny lesions that fall below the resolution threshold of the spatial attention mechanism, closely related subtypes with overlapping imaging signatures, and comorbid presentations where secondary findings go undetected. The last category is particularly interesting. HP2L handles comorbidity better than competing methods — case (f) in the paper shows it correctly identifying both lacunar infarction and metastatic tumor in the same subject. But the problem is not fully solved. Under-detected secondary findings remain a clinical risk.
There is also an honest methodological gap: the paper evaluates a single, expert-defined hierarchy. The taxonomy was constructed in collaboration with experienced neuroradiologists, which is good. But alternative valid hierarchies exist — temporal stage-based groupings, etiology-based groupings, treatment-pathway-based groupings — and whether HP2L is robust to different hierarchical organizations is only partially tested. The supplementary material includes one alternative, but a more systematic sensitivity analysis across hierarchy definitions would strengthen the conclusions.
The inter-disease dependency problem is explicitly acknowledged as future work. Real neuroradiology recognizes that vascular burden increases the probability of subsequent degenerative findings, that certain genetic profiles co-express multiple tumor types, that WMH and lacunar infarction frequently co-occur as markers of small vessel disease. A diagnostic system that treats each disorder independently is missing structural information that could substantially improve calibration in the multi-label setting. Building label-dependency priors into the framework — possibly through a learned graph structure over the disease taxonomy — is an obvious extension that would make the system more faithful to actual clinical epidemiology.
From a deployment perspective, the computational requirements deserve attention. Training was performed on four NVIDIA L40 GPUs with 40GB of memory. The 3D volumetric inputs, five modalities, and full hierarchical backbone combine into a model that is not trivially portable to resource-constrained clinical environments. The paper notes that inference produces all three levels in a single forward pass with no post-processing — that is a genuine deployment advantage — but the memory footprint during training would require careful management in a federated or distributed learning setup.
None of these gaps diminish the core contribution. The error propagation problem in hierarchical classification is real, its consequences for rare disease subtypes are clinically significant, and the HP2L mechanism of prototype-guided prompt refinement addresses it directly. The 8.42-point improvement over the best prior method on 54,360 subjects is not a marginal gain — it is the difference between a system that adequately handles common diseases and one that handles the full spectrum of presentations that a radiologist encounters.
The deeper point is about what kind of structure we build into medical AI. Flat classifiers are convenient. They require no knowledge of disease taxonomy, no collaboration with domain experts, no decisions about how to organize the label space. HP2L requires all of those things. The argument from this paper is that the difficulty is worth it — that a model structured around clinically meaningful relationships between diseases will be more accurate, more interpretable, and more robust to distribution shift than one that treats the diagnostic problem as an unstructured label assignment task. That argument is supported by 54,360 data points, two independent external cohorts, and attention maps that a cardiologist could explain to a medical student. That is a strong evidentiary foundation.
Read the Full Paper and Access the Code
The complete HP2L paper, supplementary analyses, and the official code and data release are available via the links below. Six-cohort experiments, ablation details, and per-disorder AUC breakdowns are available open-access.
Liu, Y., Sun, K., Wu, Y., Lin, X., Bai, Y., Yang, L., Zhou, W., Yuan, H., Wu, X., He, Y., Wu, Q., Che, Z., Zhan, Y., Zhou, S., Wu, D., Shi, F., Wang, M., & Shen, D. (2026). A hierarchical prompt and prototype learning framework for brain disorder classification. Medical Image Analysis, 112, 104063. https://doi.org/10.1016/j.media.2026.104063
This article is an independent editorial analysis of peer-reviewed research. The PyTorch implementation is an educational reproduction and may differ from the official repository in engineering details. For research use, verify against the official code and original paper. This work is supported by the National Natural Science Foundation of China and the China Ministry of Science and Technology.
Explore More on AI Trend Blend
If this analysis sparked your interest, here is more of what we cover across the site — from medical imaging AI and hierarchical deep learning to adversarial robustness and optimization theory.