A photograph of Earth wrapped in a thick blanket of cloud. A caption reading “taken by the Hubble Telescope.” The image and the text match perfectly, semantically speaking. And yet the claim is false, because the Hubble telescope photographs deep-sky objects, not Earth. Detection systems built around image-text alignment would give this a clean pass. That is the problem a team from Shanghai University and Shanghai Jiao Tong University set out to fix.
Key Points
- Existing multimodal fake-news detectors over-rely on image-text semantic alignment, which fails when misinformation creators deliberately pair misleading claims with plausible images.
- The KECL framework decomposes image and text representations into shared and private components, letting the model reason about each modality separately before fusing them.
- For images, the method injects manipulation-aware knowledge from a pretrained forgery encoder and adapts it to the misinformation domain via a transfer consistency objective.
- For text, it extracts scene-graph triplets using GPT-4o, links them to ConceptNet, and measures the deviation between original and knowledge-augmented embeddings to surface commonsense violations.
- A weak alignment strategy replaces strict reconstruction objectives, accepting that real-world image-text pairs are rarely perfectly aligned and using that asymmetry as a detection signal.
- On three standard benchmarks (Weibo, Twitter, GossipCop) and the NewsCLIPpings out-of-context dataset, the framework outperforms more than ten recent baselines.
The Alignment Problem No One Wants to Talk About
There is an assumption embedded in most multimodal misinformation detection research that feels intuitively correct but does not hold up under scrutiny. The assumption is that fake news should show detectable mismatches between the image and the text, and that real news should cohere. Detection systems train on this expectation. They build co-attention layers, contrastive objectives, and cross-modal alignment scores, all aimed at catching the moment where the visual story and the verbal story diverge.
The problem runs deeper than it first appears. Images and text are fundamentally different modalities. Even in a perfectly legitimate news article, the image rarely matches the text with the kind of semantic precision that a feature-level alignment score would call “consistent.” A photo of a press conference might illustrate a story about an economic policy, but the visual features of that photo share almost nothing with the word vectors in the article. A detection system looking for tight alignment would be confused. A misinformation creator looking to game such a system simply needs to pick an image that feels vaguely related. That is not difficult.
The Hubble example above is instructive precisely because it is so simple. The researchers at Shanghai University who published their work in Information Fusion in 2026 use it alongside two other cases to frame their entire framework. You can read the full paper at the Information Fusion DOI. One case shows a nighttime car-crash photo paired with text about a garbage incineration plant (misalignment). Another shows a photo of Mount Fuji that has been digitally manipulated (image forgery). The third is the Hubble case (semantically coherent but factually wrong). Three failure modes. Three different signals needed to catch them. The existing literature mostly handles one or two at best.
How KECL Rethinks the Problem from the Ground Up
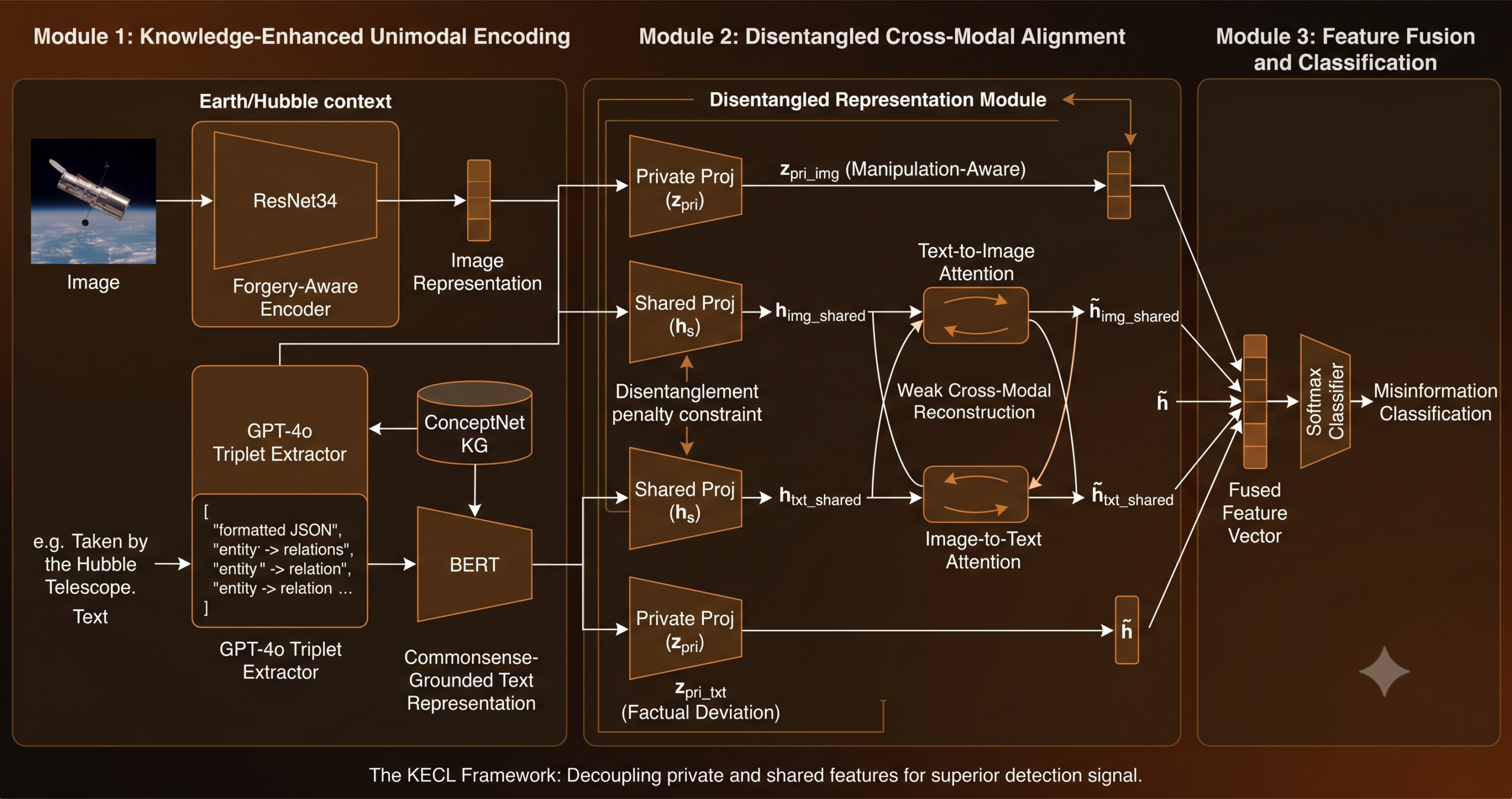
The framework is called Knowledge-Enhanced Consistency Learning with Disentangled Multimodal Representation, shortened to KECL. The name is a bit of a mouthful, but each word earns its place. Knowledge-enhanced because both image and text representations are enriched with external knowledge before any cross-modal reasoning happens. Consistency learning because the goal is not alignment per se, but consistency with what we know is true. Disentangled because the framework explicitly separates what is modality-specific from what is shared across modalities.
The architecture has three modules running in sequence. First, knowledge-enhanced unimodal encoding pulls out manipulation-aware features from images and commonsense-grounded features from text. Second, a disentangled representation module separates private features (specific to each modality) from shared features (available for cross-modal reasoning). Third, a fusion module concatenates everything and feeds it to a classifier. The framing is elegant because each module addresses a distinct failure mode from the three examples above.
The Image Side: Teaching the Encoder About Forgery
For images, the researchers start from a simple observation. Visual forgeries leave traces. Copy-move operations, splicing, recomposition — these all produce artifacts that a network trained on labeled forgery data can learn to detect. The challenge is that misinformation datasets do not label whether each image is manipulated. The ground truth labels only say whether the whole post is misinformation or not.
Their solution is pretraining. They take ResNet34 and train it on CASIAv2, a forgery detection benchmark containing 12,614 images (7,491 authentic, 5,123 manipulated). The pretraining loss is a standard binary cross-entropy on the forgery labels. After this phase, the encoder has learned what manipulation looks like at a feature level. The loss written in the paper is:
The harder part is bridging the domain gap. CASIAv2 and Weibo or Twitter look very different statistically. To adapt without needing per-image manipulation labels, the team generates synthetic forged copies of real-news images using a copy-move operator, then minimizes the difference between how the encoder treats authentic versus manipulated images across both domains. The intuition is that if the distribution of authentic images in CASIAv2 relates to the distribution of forged images in CASIAv2 in a certain way, then training the encoder to mirror that relationship on the misinformation dataset should transfer the forgery-detection capacity. The transfer consistency loss is a variant of Maximum Mean Discrepancy that operates on mean feature distances rather than full distribution moments.
This gives you an image representation that carries manipulation-awareness independently of anything the text says. That is the image-private feature, obtained by passing the backbone representation through a dedicated projection head.
The Text Side: When Common Sense Catches Lies
Here is where it gets interesting. Most text-side features in fake-news detection come from a BERT encoder applied to the claim directly. BERT is excellent at capturing surface semantics. What it struggles with is catching the claim “this was photographed by the Hubble telescope” as wrong, because nothing in the sentence surface structure signals falsity. The error is factual, not linguistic.
The KECL team routes around this by building a textual scene graph. They prompt GPT-4o with a template asking for all entity-relation-entity triplets from the input text, formatted as a JSON list. For the Hubble example, this might produce something like (Hubble telescope, takes, photo of Earth) or (image, captured-by, Hubble telescope). These triplets are structural representations of what the text is claiming.
Then each triplet is linked to ConceptNet, a multilingual commonsense knowledge graph, via entity linking. For each textual triplet (head, relation, tail), the system retrieves supporting KG triplets sharing either the head entity and relation, or the head and tail entities. Both the textual triplet and the nearest retrieved KG triplet are encoded with BERT. The key feature is the discrepancy vector between the two embeddings:
If the text claims something that aligns with commonsense knowledge, the discrepancy should be small. If it claims something the knowledge graph considers unlikely or impossible, the discrepancy should be large. These triplet-level discrepancy vectors are aggregated into a single factual deviation feature via attention, where the original text representation acts as the query and the individual triplet embeddings act as keys. The result is concatenated with the original BERT encoding to form the text-private feature.
For multilingual datasets such as Weibo (which contains Chinese text), GPT-4o normalizes triplets into English before ConceptNet linking, since ConceptNet operates primarily in English canonical form. The paper reports that fewer than 2% of extraction attempts fail due to network issues, resolved with a single retry.
“Textual cues — particularly commonsense inconsistencies that often signal fabricated claims — are insufficiently leveraged.”Liu et al., Information Fusion 136, 2026
Disentanglement: Separating What Is Shared from What Is Not
Having private features for each modality is not enough on its own. You also need a way to reason about what the two modalities share. The disentangled representation module addresses this by introducing separate projection heads for each modality that produce shared features alongside the private ones.
The backbone embeddings from ResNet and BERT are projected into two separate subspaces per modality. The private projection produces the manipulation-aware and factual-deviation features described above. A parallel shared projection produces modality-invariant representations intended to capture the semantic common ground between the image and the text. To actually enforce this separation, the model minimizes the cosine similarity between private and shared features for each modality:
This pushes the shared representation to encode only what cannot be explained by the private (modality-specific) features. In practice, this means the shared image feature should not carry forgery signals (that belongs to the private image feature), and the shared text feature should not carry factual-deviation signals (that belongs to the private text feature). Clean separation means the subsequent cross-modal alignment operates on genuinely comparable representations.
Weak Alignment: A Smarter Way to Handle Imperfect Pairs
Cross-modal attention then aligns the shared representations bidirectionally. In the text-to-image direction, the shared text feature acts as a query attending over image patch embeddings from the ResNet backbone. In the image-to-text direction, the shared image feature queries the token embeddings from BERT. Each direction produces an aligned feature that grounded in the other modality.
The clever part is what happens with the reconstruction objective. A naive approach would minimize the distance between the aligned feature and the original shared feature for every sample. But that would penalize genuine semantic distance between modalities in cases where the image and text are covering related but not identical ground — which happens in legitimate news all the time.
Instead, the paper introduces a weak alignment constraint. The premise is that real news should exhibit lower cross-modal reconstruction error than fake news, because real news is more likely to have been produced with coherent intent between image and text choice. The loss is a hinge-style formulation:
where the means are computed over reconstruction errors within each class and the margin is set at 0.5. This formulation only pushes back when real-news samples have higher reconstruction errors than fake-news samples. When the model already maintains the expected ordering, the loss is zero.
The researchers provide empirical support for the weak alignment assumption from an interesting angle. On the Twitter dataset, their forgery-aware image encoder identifies 66.4% of fake samples as containing manipulated images, while 90.0% of real samples are identified as authentic. The statistical gap justifies the margin-based formulation rather than a stricter ranking objective.
What the Numbers Actually Show
The comparison experiments span three datasets: Weibo (9,528 total samples, roughly balanced), Twitter (13,924 total, imbalanced toward fake), and GossipCop (12,840 total, heavily imbalanced with about 4 to 1 ratio of real to fake). The baselines include both older methods from 2018 to 2021 and very recent ones published in 2024 and 2025. The table below shows results on Twitter and GossipCop, which tend to be the harder of the three for most methods.
| Method | Twitter Acc | Twitter F1 | GossipCop Acc | GossipCop Macro F1 |
|---|---|---|---|---|
| EANN (2018) | 0.648 | 0.638 | 0.864 | 0.761 |
| SAFE (2020) | 0.766 | 0.764 | 0.877 | 0.794 |
| CAFE (2022) | 0.806 | 0.806 | 0.867 | 0.754 |
| FND-CLIP (2023) | — | — | 0.880 | 0.783 |
| MIMoE-FND (2025) | 0.910 | 0.909 | 0.895 | 0.811 |
| MHR (2025) | 0.932 | 0.932 | 0.884 | 0.782 |
| KECL (Ours) | 0.940 | 0.940 | 0.907 | 0.832 |
On Weibo, the framework reaches 0.931 accuracy and 0.931 macro F1, ahead of the previous best (MHR at 0.918). On Twitter the improvement over MHR is about 0.8 percentage points in accuracy. On GossipCop, where the class imbalance makes macro F1 the more informative metric, the jump from MIMoE-FND (0.811) to KECL (0.832) is more meaningful than the raw accuracy gap suggests.
The NewsCLIPpings benchmark is worth separate attention because it specifically tests out-of-context misinformation. The comparisons there include InstructBLIP with Vicuna, SNIFFER, and a fine-tuned Qwen2-VL-7B. These are all large vision-language models, which makes the comparison unfair in a sense — the KECL framework uses ResNet34 and BERT rather than a multi-billion parameter VLM. That KECL reaches 0.912 overall accuracy against SNIFFER’s 0.884 and Qwen2-VL’s 0.789 suggests the architectural choices are doing real work, not just being outpowered by scale.
The Ablation Study Tells a Coherent Story
Three ablation variants appear in the paper. Removing the disentangled representation module, removing the forgery-pretrained image encoder, or removing the knowledge-enhanced textual scene graph each produces a measurable drop across all three datasets. No single module carries all the performance. The drops are roughly proportional to how much each module contributes to the failure mode the dataset tests most.
There is also an ablation that replaces GPT-4o with the open-source LLaMA-8B model for scene graph extraction, using the same prompt template. The performance drop from this substitution is marginal (for example, 0.931 down to 0.925 on Weibo F1). The paper interprets this correctly: the gain comes from the knowledge-deviation modeling mechanism, not from GPT-4o’s proprietary knowledge. The mechanism works as long as the triplet extractor produces roughly correct structural representations. This matters for reproducibility and cost.
Hyperparameter sensitivity analysis shows the model is stable across a wide range of the three loss-balancing coefficients. The best configuration weights the transfer consistency loss at about 0.6, the disentanglement loss at 0.8, and the reconstruction loss at 0.4 on the Weibo dataset. The grid search covers the range 0.2 to 1.0 and performance stays relatively flat outside a narrow bad region around very low values for all three.
The t-SNE Picture and Why It Matters
The paper includes a t-SNE visualization comparing the embedding distribution of text features with and without the scene graph and knowledge graph enrichment on the Weibo dataset. Without enrichment, fake and real samples form overlapping clusters. With enrichment, they separate into more distinct compact regions. This is the kind of figure that is easy to dismiss as illustrative, but here it is doing more than decoration. It shows that the factual deviation signal is genuinely adding discriminative information that a raw BERT encoding misses. The separation is not dramatic, but it is consistent.
What This Framework Cannot Do (and What Comes Next)
Honest Limitations
The copy-move operator used to generate synthetic forged images represents only one type of visual manipulation. Real-world misinformation increasingly involves image reuse out of context, cropping and recomposition, or AI-generated images. The forgery encoder pretrained on CASIAv2 may not transfer well to these newer forgery types, particularly AI-generated content, which leaves no traditional forensic artifacts.
The ConceptNet linking step inherits the limitations of that knowledge graph. ConceptNet has stronger coverage for some domains and entity types than others. Highly specialized or recent factual claims may not have corresponding entries. Entity linking errors can compound if the triplet extractor produces non-canonical entity forms.
The weak alignment assumption (real news has lower cross-modal reconstruction error than fake news) is empirically supported on the Twitter dataset but not formally verified on the others. The margin value of 0.5 is set without dataset-specific tuning and may not be optimal across different news domains.
The framework is evaluated on supervised detection with a 70/10/20 train/validation/test split. Performance in zero-shot or low-resource settings is not reported. The authors note the MMFakeBench benchmark (which has no training data and is designed for zero-shot evaluation) is left as future work.
GPT-4o is called at inference time (or LLaMA-8B as the cheaper alternative), which adds latency compared to end-to-end systems. At 2% failure rate, retry logic is needed in production settings.
The authors identify two natural extensions. One is expanding the image-side forgery handling beyond copy-move to cover the full spectrum of modern manipulation, including diffusion-generated fakes. The other is investigating more principled disentanglement techniques, since the current approach (cosine similarity penalty) is a practical approximation rather than a theoretically grounded independence constraint.
The disentanglement framework itself is transferable beyond fake news. Any task where you have two heterogeneous modalities providing complementary evidence about the same underlying phenomenon faces the same tension between what is shared and what is private. Medical imaging paired with clinical notes, satellite imagery paired with ground-level reports, audio recordings paired with transcripts — all of these could benefit from the same private/shared decomposition and weak alignment strategy.
The Broader Implications: Rethinking What Alignment Means
The most interesting conceptual contribution here is not any single technical component. It is the argument that alignment-based detection has an inherent ceiling because misinformation creators can game it. If your detector asks “does the image match the text semantically?”, a sophisticated actor simply needs to pick a semantically plausible image. The Hubble example is not a contrived edge case. It is the obvious strategy once alignment detection becomes the standard.
Moving to a framework that reasons about what each modality claims independently, and asks whether those claims are consistent with external knowledge, shifts the target. Now the question is not “do the image and text agree with each other?” but “does what the text claims agree with what is known to be true?” and “does the image show signs of having been altered?” These are harder questions to game simultaneously.
The weakness is that both questions depend on the quality of external resources. ConceptNet is not a complete model of world knowledge. Forgery detection trained on one type of manipulation does not generalize to all others. But the principle — that each modality should be cross-checked against knowledge external to the post itself, not just against each other — is sound and likely to become more prominent as AI-generated content makes visual authenticity an even weaker signal.
There is also a practical engineering lesson in the weak alignment strategy. When you have training pairs that are not guaranteed to be coherent (because real news is noisier than clean research datasets), imposing a strict reconstruction objective is wrong. A hinge-style objective that enforces a relative ordering rather than an absolute criterion adapts to that noise. This pattern appears in metric learning and ranking literature but is less common in multimodal fusion. It is worth considering in any task where ground-truth alignment annotations are absent.
Finally, the ablation replacing GPT-4o with LLaMA-8B deserves attention beyond this specific paper. It demonstrates something the field tends to underreport: that the mechanism matters more than the model powering any given component. A well-designed knowledge-deviation signal computed from good-enough triplets outperforms a raw BERT encoding regardless of how expensive the triplet extractor is. That lesson generalizes.
Reference PyTorch Implementation
The following is a complete, reproducible implementation of the KECL architecture. It includes the image encoder with forgery pretraining logic, the text encoder with scene graph-knowledge graph deviation modeling, the disentanglement and cross-modal attention modules, the feature fusion classifier, all four loss functions, a training loop, an evaluation function, and a smoke test on dummy data.
# KECL: Knowledge-Enhanced Consistency Learning with Disentangled Multimodal Representation # Reference implementation in PyTorch — matches the architecture in Liu et al. (2026) # pip install torch torchvision transformers import torch import torch.nn as nn import torch.nn.functional as F from torchvision import models from transformers import BertModel, BertTokenizer from typing import List, Tuple, Optional import numpy as np # ── 1. Image Encoder with Forgery-Aware Projection ──────────────────────────── class ForgeryAwareImageEncoder(nn.Module): """ResNet34 backbone pretrained for manipulation detection, with two projection heads: one private (manipulation-aware) and one shared (modality-invariant).""" def __init__(self, feature_dim: int = 512, proj_dim: int = 256): super().__init__() backbone = models.resnet34(pretrained=True) self.backbone = nn.Sequential(*list(backbone.children())[:-1]) # drop FC self.feature_dim = feature_dim # Forgery classifier head (used only during pretraining on CASIAv2) self.forgery_classifier = nn.Linear(feature_dim, 2) # Private projection head: captures manipulation cues self.private_proj = nn.Linear(feature_dim, proj_dim) # Shared projection head: captures modality-invariant semantics self.shared_proj = nn.Linear(feature_dim, proj_dim) def forward(self, images: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]: """Returns: backbone_feat, private_feat, shared_feat.""" h = self.backbone(images).squeeze(-1).squeeze(-1) # (B, 512) z_private = self.private_proj(h) # (B, proj_dim) h_shared = self.shared_proj(h) # (B, proj_dim) return h, z_private, h_shared def forgery_logits(self, images: torch.Tensor) -> torch.Tensor: h = self.backbone(images).squeeze(-1).squeeze(-1) return self.forgery_classifier(h) def get_patch_features(self, images: torch.Tensor) -> torch.Tensor: """Return spatial feature map for cross-modal attention (B, HW, C).""" x = images for layer in list(self.backbone.children())[:-1]: x = layer(x) # x shape: (B, C, H, W) B, C, H, W = x.shape return x.view(B, C, H * W).permute(0, 2, 1) # (B, HW, C) # ── 2. Text Encoder with Knowledge Deviation Feature ───────────────────────── class KnowledgeAwareTextEncoder(nn.Module): """BERT-based text encoder that incorporates scene-graph/knowledge-graph deviation.""" def __init__(self, bert_model: str = "bert-base-uncased", proj_dim: int = 256): super().__init__() self.bert = BertModel.from_pretrained(bert_model) self.hidden_dim = self.bert.config.hidden_size # 768 # Attention for aggregating triplet discrepancies self.attn_Q = nn.Linear(self.hidden_dim, proj_dim) self.attn_K = nn.Linear(self.hidden_dim, proj_dim) self.attn_V = nn.Linear(self.hidden_dim, proj_dim) self.scale = proj_dim ** -0.5 # Private projection: original BERT + factual deviation self.private_proj = nn.Linear(self.hidden_dim + proj_dim, proj_dim) # Shared projection: modality-invariant semantics self.shared_proj = nn.Linear(self.hidden_dim, proj_dim) def encode_text(self, input_ids: torch.Tensor, attention_mask: torch.Tensor) -> torch.Tensor: outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask) return outputs.last_hidden_state[:, 0, :] # CLS token (B, 768) def forward( self, input_ids: torch.Tensor, attention_mask: torch.Tensor, triplet_text_embs: Optional[torch.Tensor] = None, # (B, N_T, 768) triplet_kg_embs: Optional[torch.Tensor] = None, # (B, N_T, 768) ) -> Tuple[torch.Tensor, torch.Tensor]: """Returns: private_feat (B, proj_dim), shared_feat (B, proj_dim).""" h_text = self.encode_text(input_ids, attention_mask) # (B, 768) h_shared = self.shared_proj(h_text) if triplet_text_embs is not None and triplet_kg_embs is not None: # Compute discrepancy vectors: (B, N_T, 768) discrepancy = triplet_text_embs - triplet_kg_embs # element-wise difference # Attention: query from global text, keys from triplet embeddings Q = self.attn_Q(h_text).unsqueeze(1) # (B, 1, proj_dim) K = self.attn_K(triplet_text_embs) # (B, N_T, proj_dim) V = self.attn_V(discrepancy) # (B, N_T, proj_dim) attn_scores = torch.bmm(Q, K.transpose(1, 2)) * self.scale # (B, 1, N_T) attn_weights = F.softmax(attn_scores, dim=-1) s_agg = torch.bmm(attn_weights, V).squeeze(1) # (B, proj_dim) z_private_input = torch.cat([h_text, s_agg], dim=-1) # (B, 768+proj_dim) else: # No triplets available: use zero deviation s_agg = torch.zeros(h_text.size(0), self.attn_V.out_features, device=h_text.device) z_private_input = torch.cat([h_text, s_agg], dim=-1) z_private = self.private_proj(z_private_input) return z_private, h_shared # ── 3. Cross-Modal Attention Alignment ──────────────────────────────────────── class CrossModalAttention(nn.Module): """Bidirectional cross-modal attention for shared feature alignment.""" def __init__(self, img_dim: int, txt_dim: int, out_dim: int = 256): super().__init__() # Text-to-image alignment self.t2i_Q = nn.Linear(txt_dim, out_dim) self.t2i_K = nn.Linear(img_dim, out_dim) self.t2i_V = nn.Linear(img_dim, out_dim) # Image-to-text alignment self.i2t_Q = nn.Linear(img_dim, out_dim) self.i2t_K = nn.Linear(txt_dim, out_dim) self.i2t_V = nn.Linear(txt_dim, out_dim) self.scale = out_dim ** -0.5 def forward( self, h_img_shared: torch.Tensor, # (B, img_dim) — image shared global feature h_txt_shared: torch.Tensor, # (B, txt_dim) — text shared global feature img_patches: torch.Tensor, # (B, M, img_dim) — spatial patch features txt_tokens: torch.Tensor, # (B, N, txt_dim) — token embeddings ) -> Tuple[torch.Tensor, torch.Tensor]: """Returns: aligned_text_feat (B, out_dim), aligned_img_feat (B, out_dim).""" # Text-to-image: text query attends over image patches Q_t = self.t2i_Q(h_txt_shared).unsqueeze(1) # (B, 1, D) K_i = self.t2i_K(img_patches) # (B, M, D) V_i = self.t2i_V(img_patches) # (B, M, D) a = F.softmax(torch.bmm(Q_t, K_i.transpose(1, 2)) * self.scale, dim=-1) h_tilde_text = torch.bmm(a, V_i).squeeze(1) # (B, D) # Image-to-text: image query attends over text tokens Q_i = self.i2t_Q(h_img_shared).unsqueeze(1) # (B, 1, D) K_t = self.i2t_K(txt_tokens) # (B, N, D) V_t = self.i2t_V(txt_tokens) # (B, N, D) b = F.softmax(torch.bmm(Q_i, K_t.transpose(1, 2)) * self.scale, dim=-1) h_tilde_img = torch.bmm(b, V_t).squeeze(1) # (B, D) return h_tilde_text, h_tilde_img # ── 4. Full KECL Model ──────────────────────────────────────────────────────── class KECL(nn.Module): """ Knowledge-Enhanced Consistency Learning with Disentangled Multimodal Representation. Liu et al., Information Fusion 136 (2026) 104501. """ def __init__( self, proj_dim: int = 256, num_classes: int = 2, bert_model: str = "bert-base-uncased", ): super().__init__() self.img_encoder = ForgeryAwareImageEncoder(feature_dim=512, proj_dim=proj_dim) self.txt_encoder = KnowledgeAwareTextEncoder(bert_model=bert_model, proj_dim=proj_dim) self.cross_attn = CrossModalAttention(img_dim=512, txt_dim=proj_dim, out_dim=proj_dim) # Fuse: private_img + private_txt + shared_img + shared_txt fuse_dim = proj_dim * 4 self.classifier = nn.Sequential( nn.Linear(fuse_dim, 256), nn.ReLU(), nn.Dropout(0.3), nn.Linear(256, num_classes), ) def forward( self, images: torch.Tensor, input_ids: torch.Tensor, attention_mask: torch.Tensor, txt_tokens: torch.Tensor, # (B, N, 768) token-level BERT outputs triplet_text_embs: Optional[torch.Tensor] = None, triplet_kg_embs: Optional[torch.Tensor] = None, ) -> Tuple[torch.Tensor, dict]: """Returns: logits (B, num_classes), intermediates dict.""" # Image encoding h_img, z_pri_img, h_img_shared = self.img_encoder(images) img_patches = self.img_encoder.get_patch_features(images) # (B, HW, 512) # Text encoding z_pri_txt, h_txt_shared = self.txt_encoder( input_ids, attention_mask, triplet_text_embs, triplet_kg_embs ) # Cross-modal attention alignment h_tilde_text, h_tilde_img = self.cross_attn( h_img_shared, h_txt_shared, img_patches, txt_tokens ) # Feature fusion h_fuse = torch.cat([h_img_shared, z_pri_img, h_txt_shared, z_pri_txt], dim=-1) logits = self.classifier(h_fuse) intermediates = { "h_img_shared": h_img_shared, "h_txt_shared": h_txt_shared, "z_pri_img": z_pri_img, "z_pri_txt": z_pri_txt, "h_tilde_text": h_tilde_text, "h_tilde_img": h_tilde_img, } return logits, intermediates # ── 5. Loss Functions ───────────────────────────────────────────────────────── def forgery_loss(logits: torch.Tensor, labels: torch.Tensor) -> torch.Tensor: """Binary cross-entropy for pretraining on CASIAv2 or similar forgery datasets.""" return F.cross_entropy(logits, labels) def transfer_consistency_loss( encoder, real_mis: torch.Tensor, # real images from misinformation dataset fake_mis: torch.Tensor, # fake images from misinformation dataset real_syn_mean: torch.Tensor, # precomputed mean feature of real CASIAv2 images fake_syn_mean: torch.Tensor, # precomputed mean feature of forged CASIAv2 images ) -> torch.Tensor: """MMD-inspired transfer consistency loss (Eq. 6 in the paper).""" _, z_real_mis, _ = encoder(real_mis) _, z_fake_mis, _ = encoder(fake_mis) d_real = F.cosine_similarity(z_real_mis, real_syn_mean.unsqueeze(0).expand_as(z_real_mis)) d_fake = F.cosine_similarity(z_fake_mis, fake_syn_mean.unsqueeze(0).expand_as(z_fake_mis)) loss = torch.abs(d_real.mean() - d_fake.mean()) return loss def disentanglement_loss( h_img_shared: torch.Tensor, z_pri_img: torch.Tensor, h_txt_shared: torch.Tensor, z_pri_txt: torch.Tensor, ) -> torch.Tensor: """Penalize cosine similarity between shared and private features (Eq. 21).""" cos_img = F.cosine_similarity(h_img_shared, z_pri_img, dim=-1).abs() cos_txt = F.cosine_similarity(h_txt_shared, z_pri_txt, dim=-1).abs() return cos_img.mean() + cos_txt.mean() def weak_reconstruction_loss( h_tilde_text: torch.Tensor, h_txt_shared: torch.Tensor, h_tilde_img: torch.Tensor, h_img_shared: torch.Tensor, labels: torch.Tensor, margin: float = 0.5, ) -> torch.Tensor: """Hinge-style weak alignment loss (Eq. 28). Encourages real samples to have lower reconstruction error than fake ones.""" err = ( (h_tilde_text - h_txt_shared).pow(2).sum(dim=-1) + (h_tilde_img - h_img_shared).pow(2).sum(dim=-1) ) # (B,) real_mask = (labels == 0) fake_mask = (labels == 1) mu_real = err[real_mask].mean() if real_mask.any() else torch.tensor(0.0, device=labels.device) mu_fake = err[fake_mask].mean() if fake_mask.any() else torch.tensor(0.0, device=labels.device) return F.relu(mu_real - mu_fake + margin) def total_loss( logits, labels, intermediates, alpha: float = 0.6, beta: float = 0.8, gamma: float = 0.4, l_trans: torch.Tensor = None, margin: float = 0.5, ) -> torch.Tensor: """Overall objective: CE + alpha*L_trans + beta*L_dis + gamma*L_rec (Eq. 32).""" l_ce = F.cross_entropy(logits, labels) l_dis = disentanglement_loss( intermediates["h_img_shared"], intermediates["z_pri_img"], intermediates["h_txt_shared"], intermediates["z_pri_txt"], ) l_rec = weak_reconstruction_loss( intermediates["h_tilde_text"], intermediates["h_txt_shared"], intermediates["h_tilde_img"], intermediates["h_img_shared"], labels, margin, ) l_t = l_trans if l_trans is not None else torch.tensor(0.0) return l_ce + alpha * l_t + beta * l_dis + gamma * l_rec # ── 6. Training Loop ────────────────────────────────────────────────────────── def train_one_epoch(model, dataloader, optimizer, device, alpha=0.6, beta=0.8, gamma=0.4): model.train() total_loss_val = 0.0 for batch in dataloader: images = batch["images"].to(device) input_ids = batch["input_ids"].to(device) attention_mask = batch["attention_mask"].to(device) txt_tokens = batch["txt_tokens"].to(device) # (B, N, 768) labels = batch["labels"].to(device) triplet_text_embs = batch.get("triplet_text_embs") triplet_kg_embs = batch.get("triplet_kg_embs") if triplet_text_embs is not None: triplet_text_embs = triplet_text_embs.to(device) triplet_kg_embs = triplet_kg_embs.to(device) optimizer.zero_grad() logits, intermediates = model( images, input_ids, attention_mask, txt_tokens, triplet_text_embs, triplet_kg_embs ) loss = total_loss(logits, labels, intermediates, alpha=alpha, beta=beta, gamma=gamma) loss.backward() optimizer.step() total_loss_val += loss.item() return total_loss_val / len(dataloader) # ── 7. Evaluation ───────────────────────────────────────────────────────────── def evaluate(model, dataloader, device): model.eval() all_preds, all_labels = [], [] with torch.no_grad(): for batch in dataloader: images = batch["images"].to(device) input_ids = batch["input_ids"].to(device) attention_mask = batch["attention_mask"].to(device) txt_tokens = batch["txt_tokens"].to(device) labels = batch["labels"] logits, _ = model(images, input_ids, attention_mask, txt_tokens) preds = logits.argmax(dim=-1).cpu() all_preds.extend(preds.tolist()) all_labels.extend(labels.tolist()) acc = sum(p == l for p, l in zip(all_preds, all_labels)) / len(all_labels) return {"accuracy": acc, "predictions": all_preds, "labels": all_labels} # ── 8. Smoke Test on Dummy Data ─────────────────────────────────────────────── if __name__ == "__main__": import warnings warnings.filterwarnings("ignore") device = torch.device("cuda" if torch.cuda.is_available() else "cpu") print(f"Running smoke test on {device}") B, N, M = 4, 32, 49 # batch, text tokens, image patches (7x7) proj_dim = 256 model = KECL(proj_dim=proj_dim).to(device) dummy_images = torch.randn(B, 3, 224, 224).to(device) dummy_input_ids = torch.randint(0, 30522, (B, 128)).to(device) dummy_attention_mask = torch.ones(B, 128, dtype=torch.long).to(device) dummy_txt_tokens = torch.randn(B, N, proj_dim).to(device) dummy_triplet_text = torch.randn(B, 5, 768).to(device) dummy_triplet_kg = torch.randn(B, 5, 768).to(device) dummy_labels = torch.randint(0, 2, (B,)).to(device) logits, intermediates = model( dummy_images, dummy_input_ids, dummy_attention_mask, dummy_txt_tokens, dummy_triplet_text, dummy_triplet_kg ) loss = total_loss(logits, dummy_labels, intermediates) print(f"Logits shape: {logits.shape}") # expected (4, 2) print(f"Total loss: {loss.item():.4f}") print("Intermediate keys:", list(intermediates.keys())) print("Smoke test PASSED.")
Frequently Asked Questions
What makes KECL different from other multimodal fake-news detectors?
Most detectors measure how well the image and the text agree with each other. KECL shifts the question. For images, it asks whether the image shows signs of manipulation, drawing on a forgery-pretrained encoder. For text, it asks whether the claims in the text are consistent with commonsense knowledge from ConceptNet, using a scene-graph extraction pipeline. These two questions are answered independently before any cross-modal reasoning happens, and the cross-modal reasoning uses a weak alignment objective rather than a strict one, which means it handles cases where even real news has imperfect image-text correspondence.
Do you need GPT-4o to use this approach?
The paper includes an ablation that replaces GPT-4o with LLaMA-8B for scene-graph triplet extraction. The performance drop is marginal (about 0.6 macro F1 points on Weibo). The knowledge-deviation mechanism that drives the text-side gains does not depend on GPT-4o’s scale or proprietary training. Any sufficiently capable open-source model that can extract entity-relation-entity triplets from text in a structured format should work.
What is the weak alignment strategy and why does it matter?
Strict cross-modal reconstruction objectives penalize any distance between the aligned feature and the original shared feature, even when the distance reflects legitimate semantic differences between the image and the text. The weak alignment strategy instead enforces a relative constraint: real-news samples should have lower cross-modal reconstruction error than fake-news samples, with a margin of 0.5. This formulation only pushes back when the model violates this ordering, so it does not incorrectly penalize the natural heterogeneity present in authentic news pairs.
What datasets were used and how do the results hold up on imbalanced ones?
The three main datasets are Weibo (roughly balanced, Chinese text), Twitter (imbalanced, English), and GossipCop (heavily imbalanced at about 4 to 1 real to fake, English). On GossipCop, where accuracy can be inflated by always predicting the majority class, the macro F1 is the more informative metric. KECL reaches 0.832 macro F1, compared to 0.811 for the previous-best MIMoE-FND. The framework also outperforms three large vision-language models on the NewsCLIPpings out-of-context benchmark with 0.912 overall accuracy.
What are the main limitations of this approach?
The image-side forgery modeling currently covers copy-move manipulation, which is one specific type. AI-generated images, cropping and recomposition, and out-of-context reuse may not leave the forensic traces the encoder is trained to detect. The ConceptNet linking step works best for entities with strong coverage in that knowledge graph, and fails silently for highly specialized or recent factual claims. The weak alignment assumption is empirically supported but not formally proven to hold across all news domains and languages.
Can the disentangled representation approach be applied to domains beyond fake-news detection?
The private and shared decomposition is applicable to any task with two heterogeneous modalities providing complementary evidence about the same underlying phenomenon. Medical imaging paired with clinical notes, satellite imagery paired with field reports, and video paired with transcripts all have the same fundamental structure. The weak alignment loss in particular is relevant whenever you cannot assume that cross-modal pairs are tightly semantically coupled, which describes most real-world multimodal datasets outside carefully curated vision-language pretraining corpora.
Read the full paper and explore the benchmark results across Weibo, Twitter, GossipCop, and NewsCLIPpings.
Related Reading
Citation: Liu, Z., Gao, J., Liao, Y., and Luo, X. (2026). Knowledge-enhanced consistency learning with disentangled multimodal representation for misinformation detection. Information Fusion, 136, 104501. https://doi.org/10.1016/j.inffus.2026.104501
This analysis is based on the published paper and an independent evaluation of its claims.