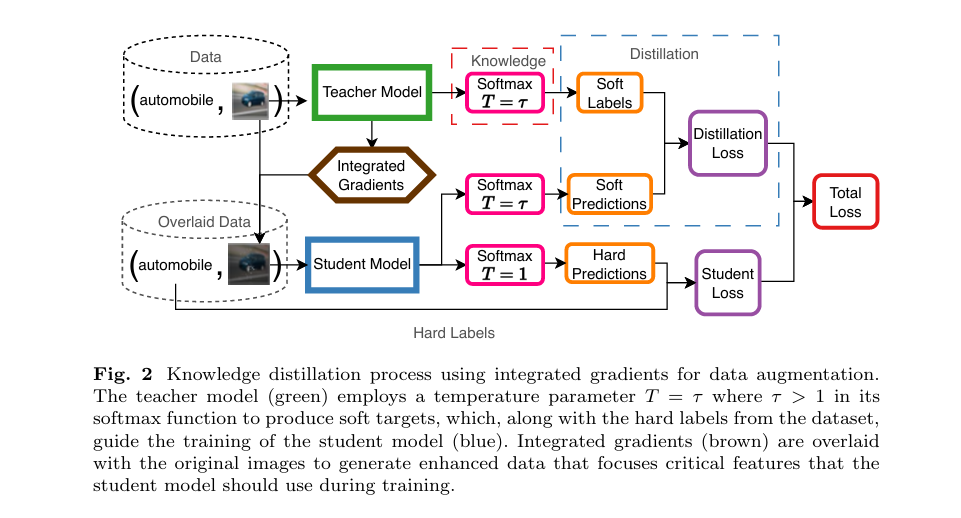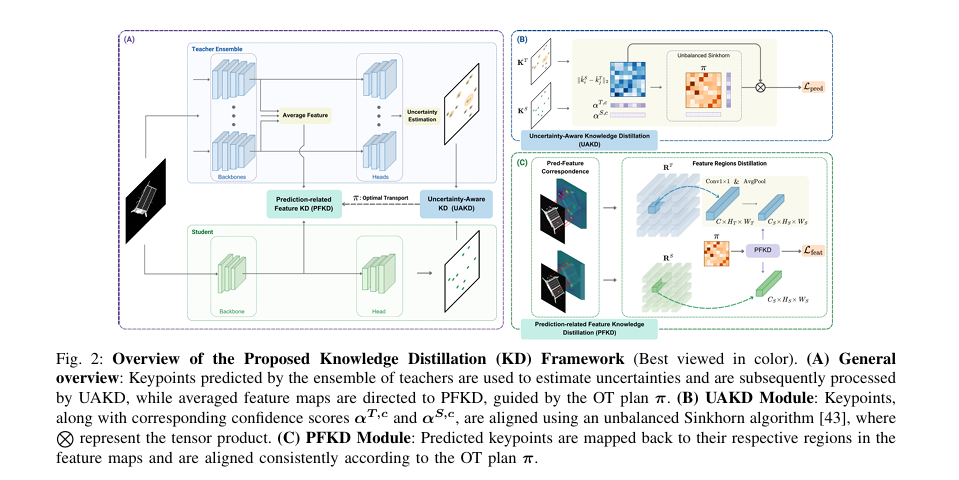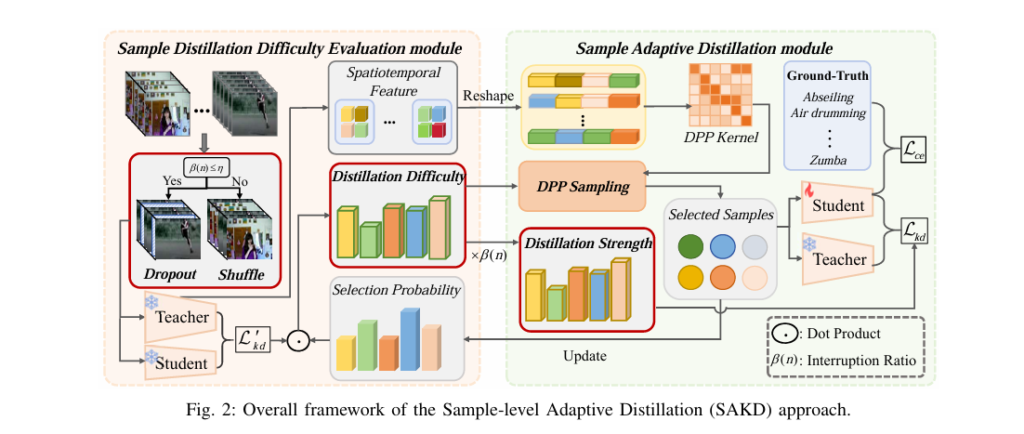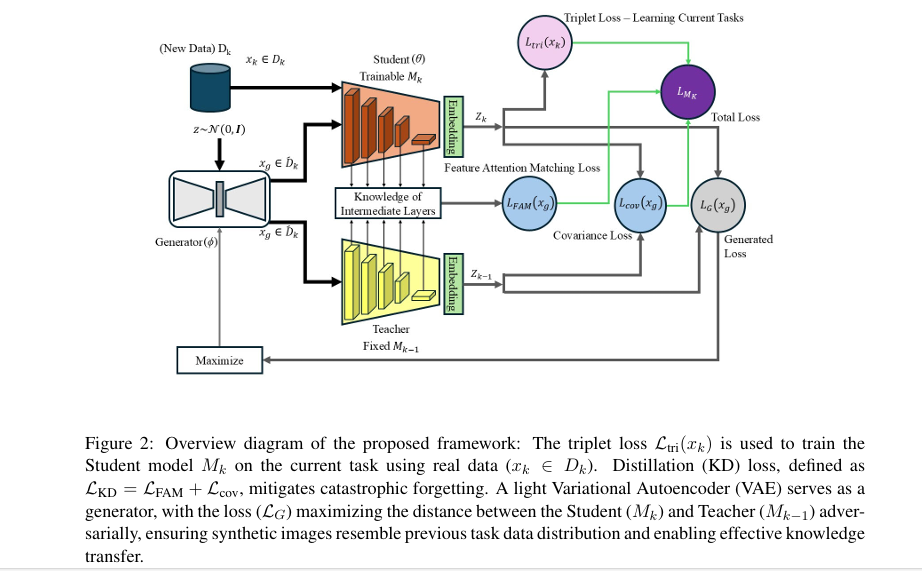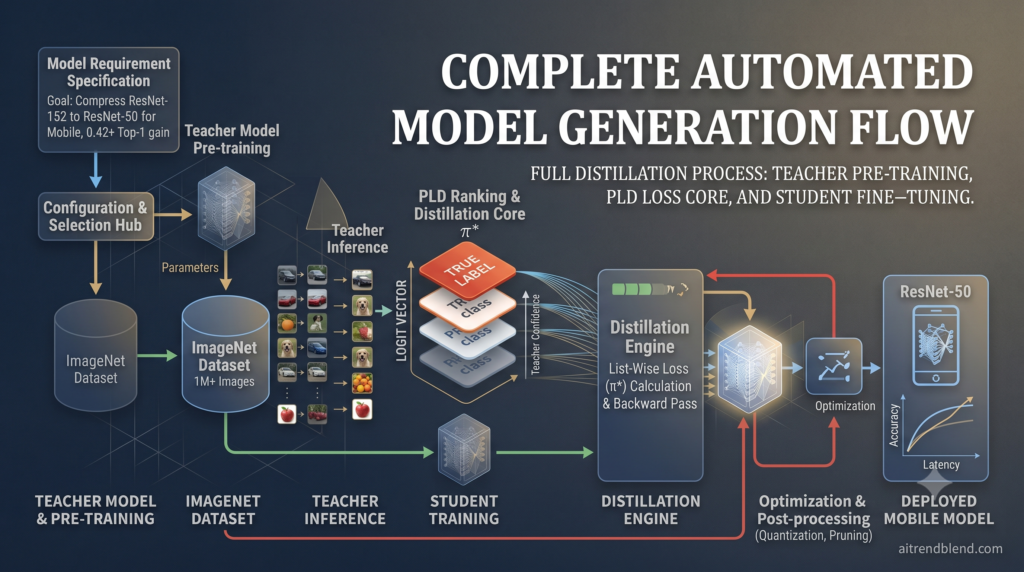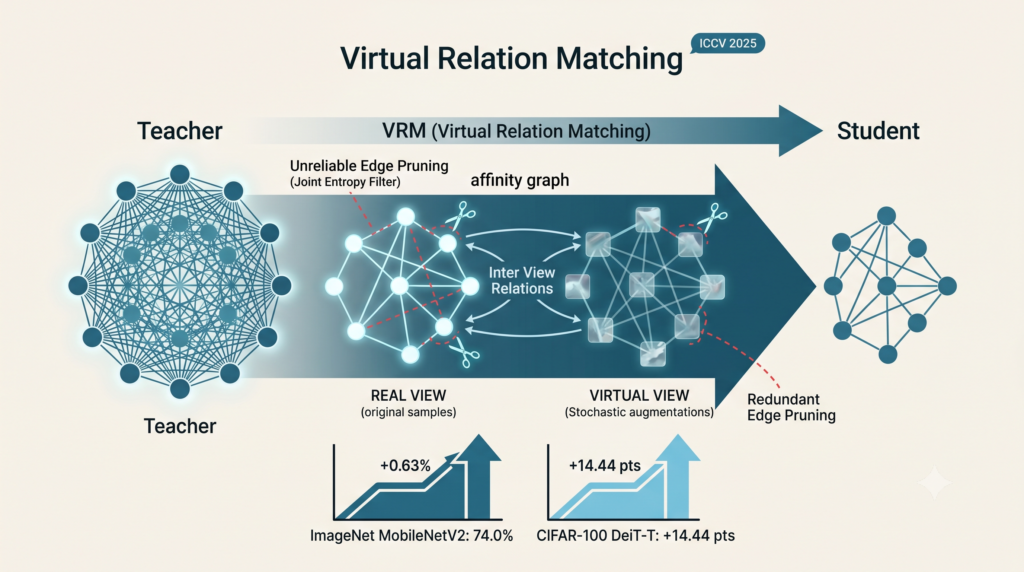
How Virtual Relations Revive Knowledge Distillation
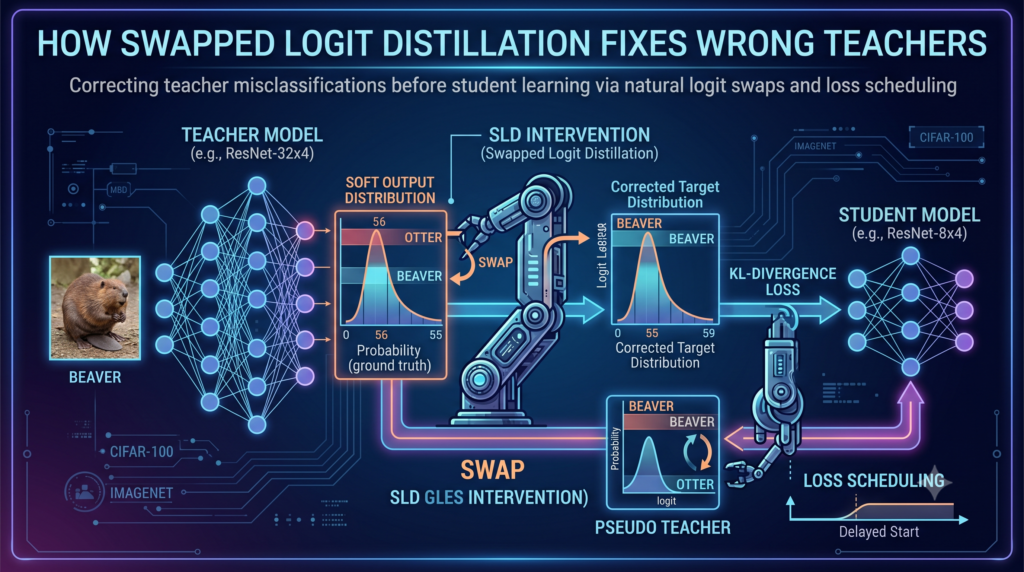
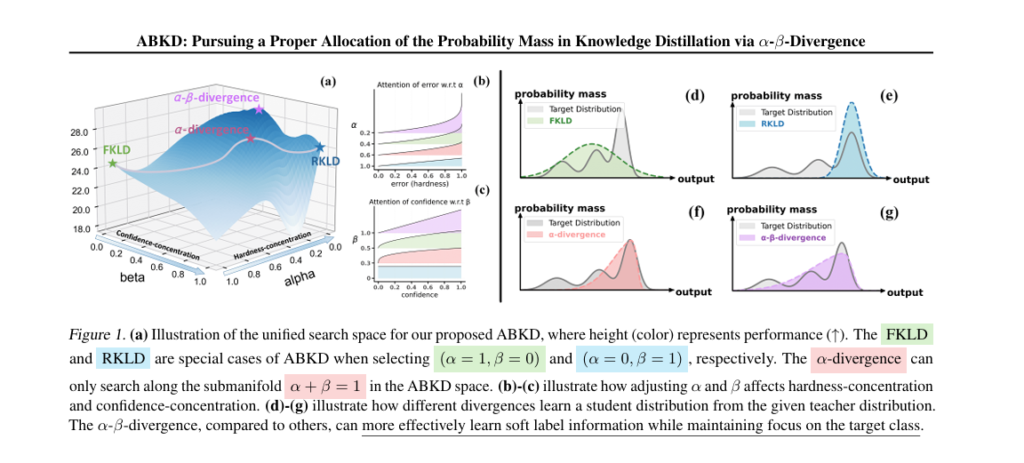
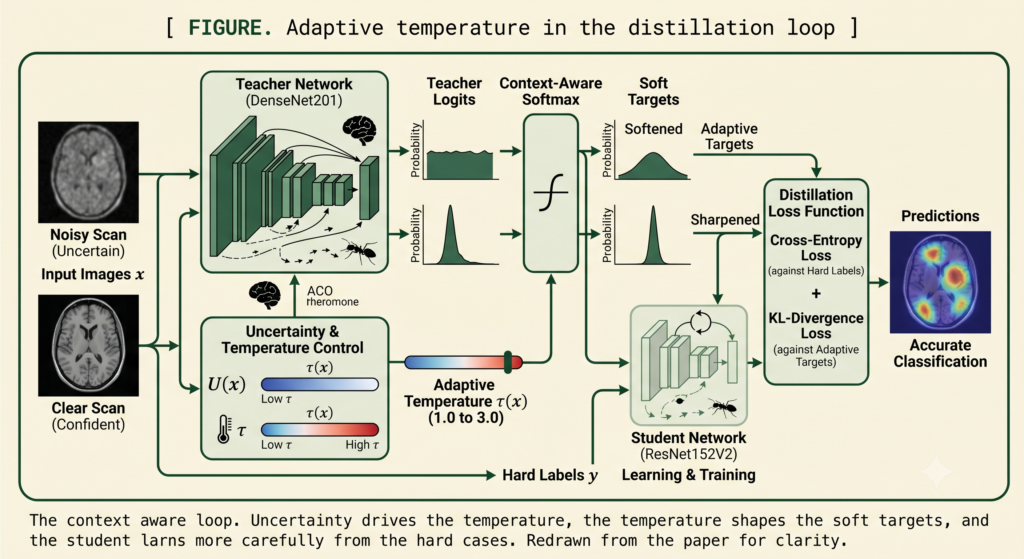
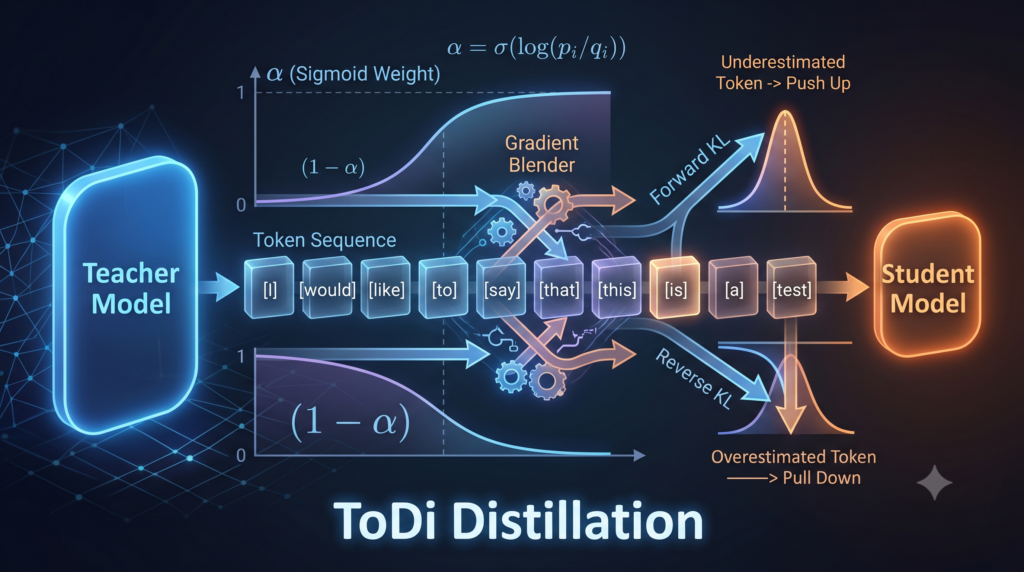
Analysis by the aitrendblend editorial team · Pillar 2, Knowledge Distillation · Reading time about 13 minutes knowledge distillation virtual relation matching VRM affinity graphs edge pruning ICCV 2025 ViT distillation relation based KD Relation matching constructs edges between sample predictions. VRM doubles the graph with virtual views and then prunes the redundant and unreliable […]
How Virtual Relations Revive Knowledge Distillation Read More »