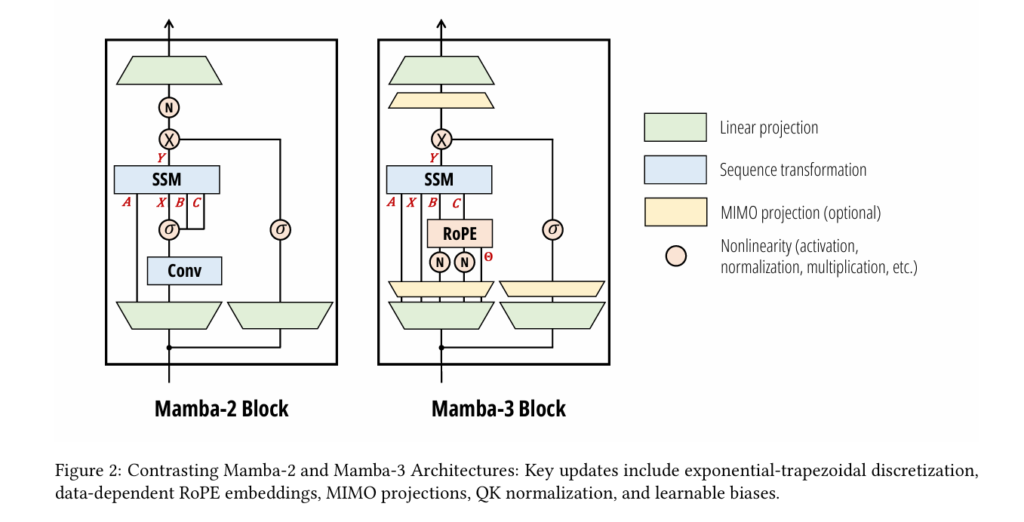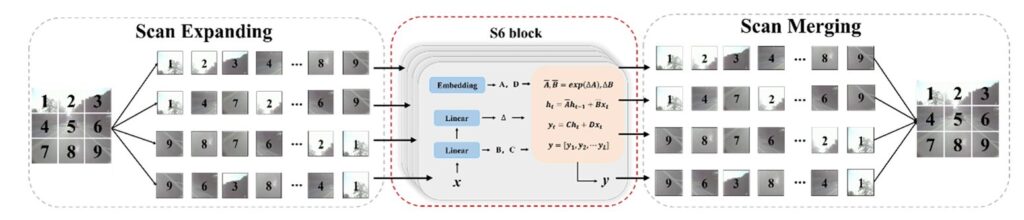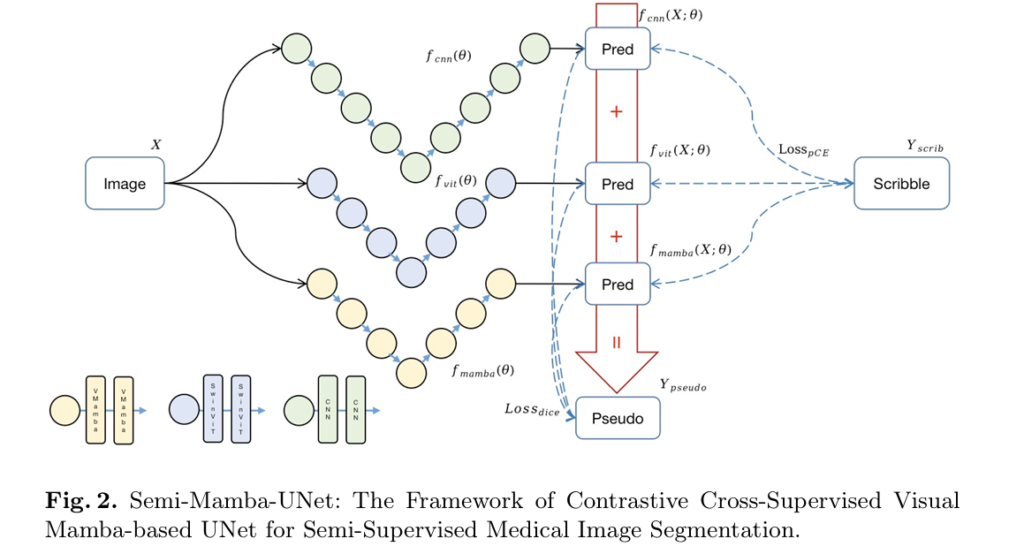
Weak-Mamba-UNet: How CNN, ViT, and Visual Mamba Collaborate to Segment Medical Images from Scribbles
Weak-Mamba-UNet: How CNN, ViT, and Visual Mamba Collaborate to Segment Medical Images from Scribbles | AI Trend Blend AITrendBlend Machine Learning Computer Vision About Medical AI & Weakly-Supervised Learning · arXiv:2402.10887 · University of Oxford / Mianyang Visual Engineering Center · 25 min read Teaching Three Different Brains to Agree — How Weak-Mamba-UNet Segments Hearts […]